 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Non-Convex Weighted Lp Minimization based Group Sparse Representation Framework for Image Denoising
May 23, 2017


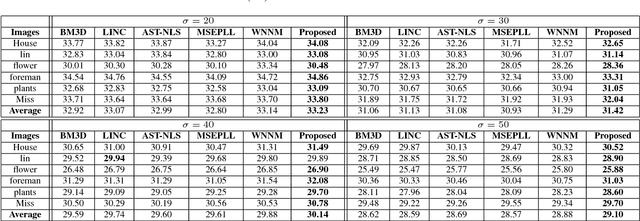
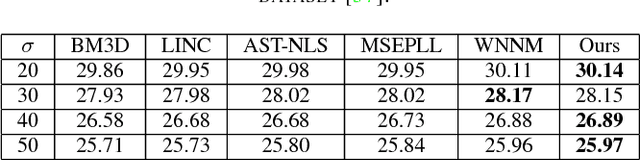
Nonlocal image representation or group sparsity has attracted considerable interest in various low-level vision tasks and has led to several state-of-the-art image denoising techniques, such as BM3D, LSSC. In the past, convex optimization with sparsity-promoting convex regularization was usually regarded as a standard scheme for estimating sparse signals in noise. However, using convex regularization can not still obtain the correct sparsity solution under some practical problems including image inverse problems. In this paper we propose a non-convex weighted $\ell_p$ minimization based group sparse representation (GSR) framework for image denoising. To make the proposed scheme tractable and robust, the generalized soft-thresholding (GST) algorithm is adopted to solve the non-convex $\ell_p$ minimization problem. In addition, to improve the accuracy of the nonlocal similar patches selection, an adaptive patch search (APS) scheme is proposed. Experimental results have demonstrated that the proposed approach not only outperforms many state-of-the-art denoising methods such as BM3D and WNNM, but also results in a competitive speed.
Seed Phenotyping on Neural Networks using Domain Randomization and Transfer Learning
Dec 24, 2020
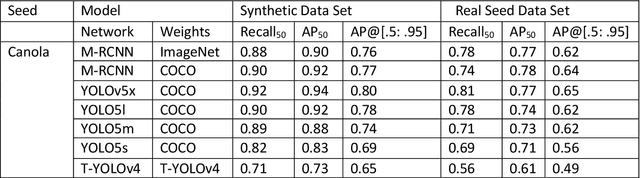
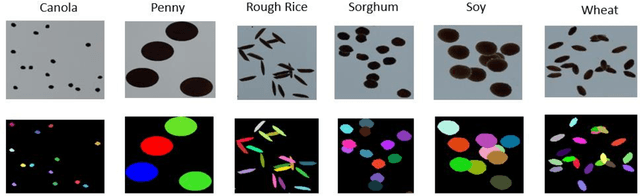
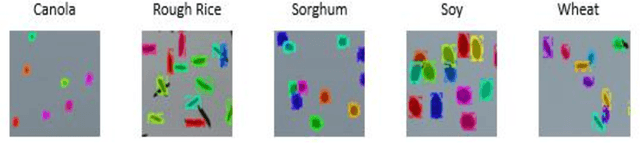
Seed phenotyping is the idea of analyzing the morphometric characteristics of a seed to predict the behavior of the seed in terms of development, tolerance and yield in various environmental conditions. The focus of the work is the application and feasibility analysis of the state-of-the-art object detection and localization neural networks, Mask R-CNN and YOLO (You Only Look Once), for seed phenotyping using Tensorflow. One of the major bottlenecks of such an endeavor is the need for large amounts of training data. While the capture of a multitude of seed images is taunting, the images are also required to be annotated to indicate the boundaries of the seeds on the image and converted to data formats that the neural networks are able to consume. Although tools to manually perform the task of annotation are available for free, the amount of time required is enormous. In order to tackle such a scenario, the idea of domain randomization i.e. the technique of applying models trained on images containing simulated objects to real-world objects, is considered. In addition, transfer learning i.e. the idea of applying the knowledge obtained while solving a problem to a different problem, is used. The networks are trained on pre-trained weights from the popular ImageNet and COCO data sets. As part of the work, experiments with different parameters are conducted on five different seed types namely, canola, rough rice, sorghum, soy, and wheat.
Photometric Multi-View Mesh Refinement for High-Resolution Satellite Images
May 12, 2020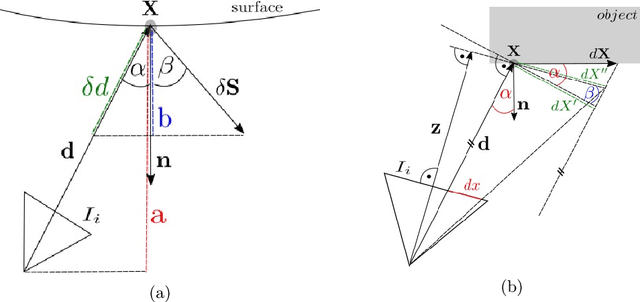
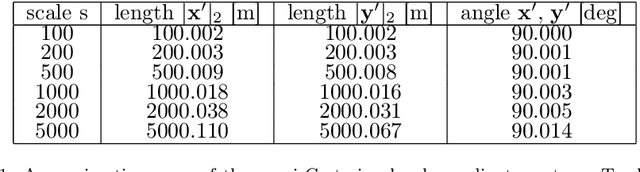

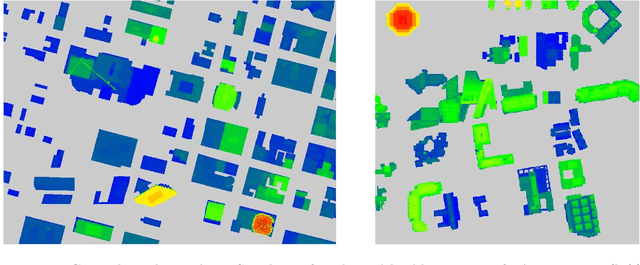
Modern high-resolution satellite sensors collect optical imagery with ground sampling distances (GSDs) of 30-50cm, which has sparked a renewed interest in photogrammetric 3D surface reconstruction from satellite data. State-of-the-art reconstruction methods typically generate 2.5D elevation data. Here, we present an approach to recover full 3D surface meshes from multi-view satellite imagery. The proposed method takes as input a coarse initial mesh and refines it by iteratively updating all vertex positions to maximize the photo-consistency between images. Photo-consistency is measured in image space, by transferring texture from one image to another via the surface. We derive the equations to propagate changes in texture similarity through the rational function model (RFM), often also referred to as rational polynomial coefficient (RPC) model. Furthermore, we devise a hierarchical scheme to optimize the surface with gradient descent. In experiments with two different datasets, we show that the refinement improves the initial digital elevation models (DEMs) generated with conventional dense image matching. Moreover, we demonstrate that our method is able to reconstruct true 3D geometry, such as facade structures, if off-nadir views are available.
A Backbone Replaceable Fine-tuning Network for Stable Face Alignment
Oct 19, 2020
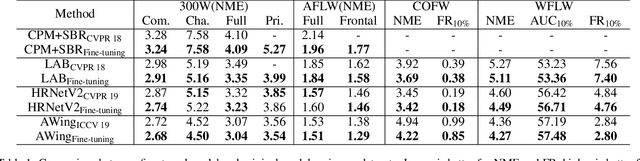
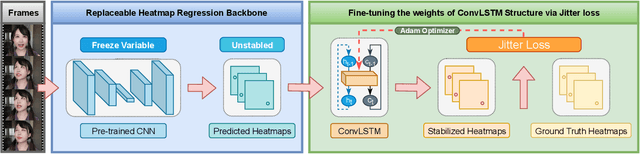
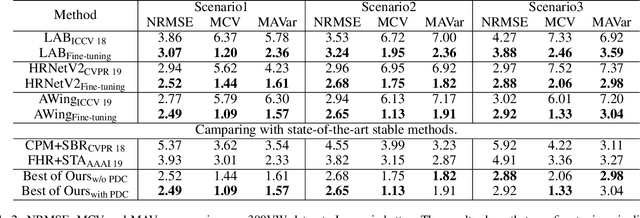
Heatmap regression based face alignment algorithms have achieved prominent performance on static images. However, when applying these methods on videos or sequential images, the stability and accuracy are remarkably discounted. The reason lies in temporal informations are not considered, which is mainly reflected in network structure and loss function. This paper presents a novel backbone replaceable fine-tuning framework, which can swiftly convert facial landmark detector designed for single image level into a better performing one that suitable for videos. On this basis, we proposed the Jitter loss, an innovative temporal information based loss function devised to impose strong penalties on prediction landmarks that jitter around the ground truth. Our framework provides capabilities to achieve at least 40% performance improvement on stability evaluation metrices while enhancing accuracy without re-training the entire model versus state-of-the-art methods.
Computer Stereo Vision for Autonomous Driving
Dec 06, 2020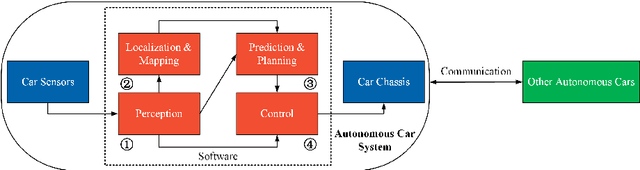
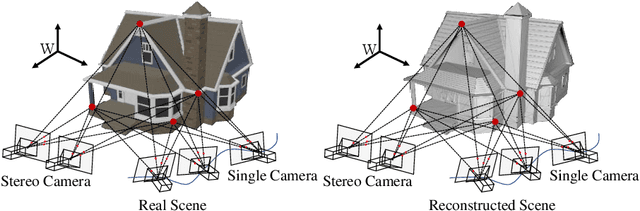

For a long time, autonomous cars were found only in science fiction movies and series but now they are becoming a reality. The opportunity to pick such a vehicle at your garage forecourt is closer than you think. As an important component of autonomous systems, autonomous car perception has had a big leap with recent advances in parallel computing architectures, such as OpenMP for multi-threading CPUs and OpenCL for GPUs. With the use of tiny but full-feature embedded supercomputers, computer stereo vision has been prevalently applied in autonomous cars for depth perception. The two key aspects of computer stereo vision are speed and accuracy. They are two desirable but conflicting properties -- the algorithms with better disparity accuracy usually have higher computational complexity. Therefore, the main aim of developing a computer stereo vision algorithm for resource-limited hardware is to improve the trade-off between speed and accuracy. In this chapter, we first introduce the autonomous car system, from the hardware aspect to the software aspect. We then discuss four autonomous car perception functionalities, including: 1) visual feature detection, description and matching, 2) 3D information acquisition, 3) object detection/recognition and 4) semantic image segmentation. Finally, we introduce the principles of computer stereo vision and parallel computing.
Accelerated Image Reconstruction for Nonlinear Diffractive Imaging
Dec 14, 2017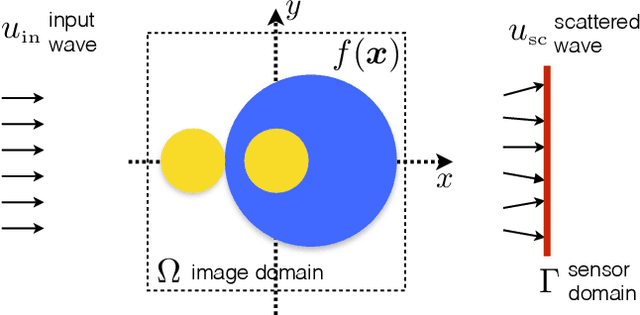
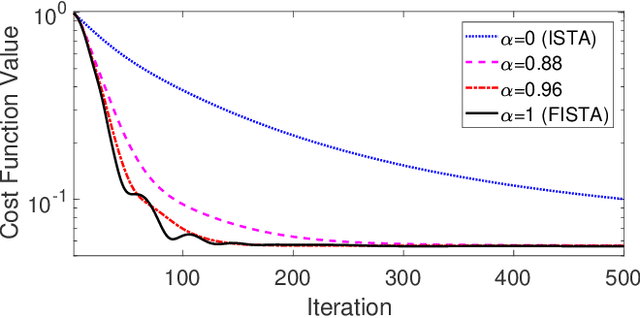
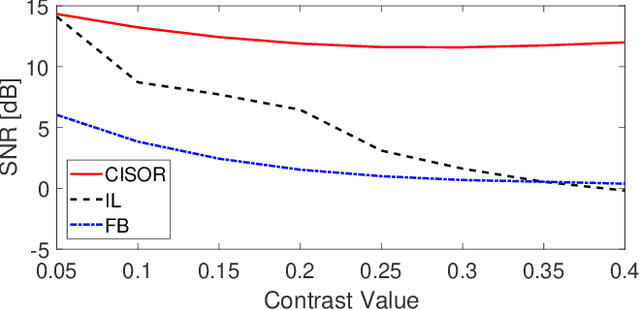
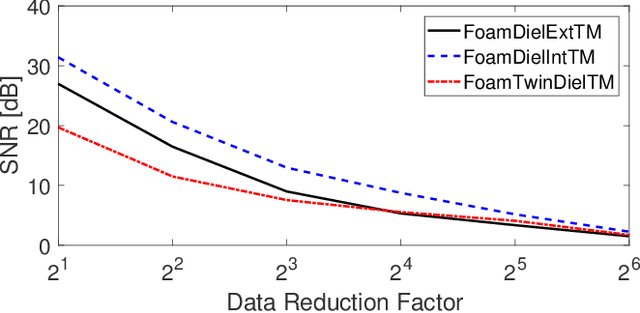
The problem of reconstructing an object from the measurements of the light it scatters is common in numerous imaging applications. While the most popular formulations of the problem are based on linearizing the object-light relationship, there is an increased interest in considering nonlinear formulations that can account for multiple light scattering. In this paper, we propose an image reconstruction method, called CISOR, for nonlinear diffractive imaging, based on a nonconvex optimization formulation with total variation (TV) regularization. The nonconvex solver used in CISOR is our new variant of fast iterative shrinkage/thresholding algorithm (FISTA). We provide fast and memory-efficient implementation of the new FISTA variant and prove that it reliably converges for our nonconvex optimization problem. In addition, we systematically compare our method with other state-of-the-art methods on simulated as well as experimentally measured data in both 2D and 3D settings.
Fast, Accurate and Fully Parallelizable Digital Image Correlation
Oct 12, 2017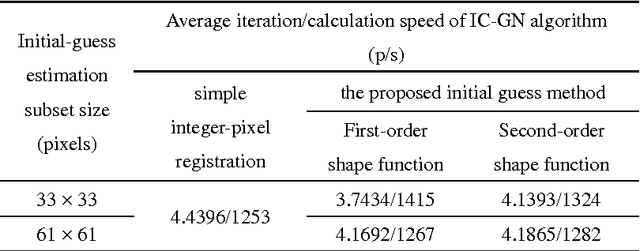

Digital image correlation (DIC) is a widely used optical metrology for surface deformation measurements. DIC relies on nonlinear optimization method. Thus an initial guess is quite important due to its influence on the converge characteristics of the algorithm. In order to obtain a reliable, accurate initial guess, a reliability-guided digital image correlation (RG-DIC) method, which is able to intelligently obtain a reliable initial guess without using time-consuming integer-pixel registration, was proposed. However, the RG-DIC and its improved methods are path-dependent and cannot be fully parallelized. Besides, it is highly possible that RG-DIC fails in the full-field analysis of deformation without manual intervention if the deformation fields contain large areas of discontinuous deformation. Feature-based initial guess is highly robust while it is relatively time-consuming. Recently, path-independent algorithm, fast Fourier transform-based cross correlation (FFT-CC) algorithm, was proposed to estimate the initial guess. Complete parallelizability is the major advantage of the FFT-CC algorithm, while it is sensitive to small deformation. Wu et al proposed an efficient integer-pixel search scheme, but the parameters of this algorithm are set by the users empirically. In this technical note, a fully parallelizable DIC method is proposed. Different from RG-DIC method, the proposed method divides DIC algorithm into two parts: full-field initial guess estimation and sub-pixel registration. The proposed method has the following benefits: 1) providing a pre-knowledge of deformation fields; 2) saving computational time; 3) reducing error propagation; 4) integratability with well-established DIC algorithms; 5) fully parallelizability.
Joint Self-Attention and Scale-Aggregation for Self-Calibrated Deraining Network
Aug 06, 2020
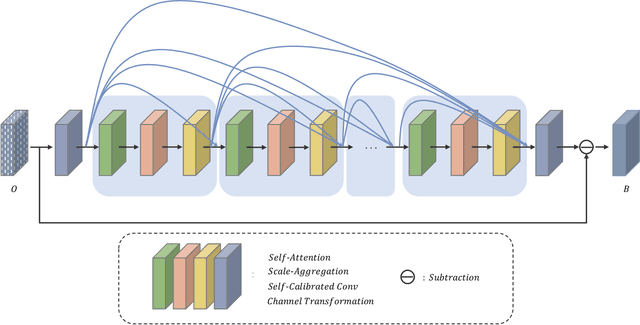
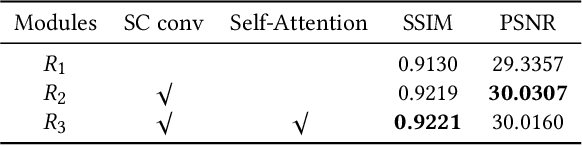
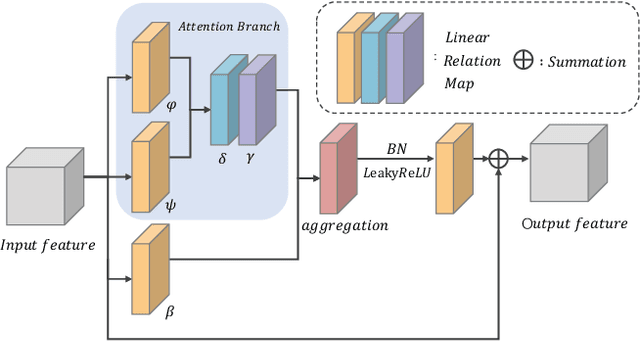
In the field of multimedia, single image deraining is a basic pre-processing work, which can greatly improve the visual effect of subsequent high-level tasks in rainy conditions. In this paper, we propose an effective algorithm, called JDNet, to solve the single image deraining problem and conduct the segmentation and detection task for applications. Specifically, considering the important information on multi-scale features, we propose a Scale-Aggregation module to learn the features with different scales. Simultaneously, Self-Attention module is introduced to match or outperform their convolutional counterparts, which allows the feature aggregation to adapt to each channel. Furthermore, to improve the basic convolutional feature transformation process of Convolutional Neural Networks (CNNs), Self-Calibrated convolution is applied to build long-range spatial and inter-channel dependencies around each spatial location that explicitly expand fields-of-view of each convolutional layer through internal communications and hence enriches the output features. By designing the Scale-Aggregation and Self-Attention modules with Self-Calibrated convolution skillfully, the proposed model has better deraining results both on real-world and synthetic datasets. Extensive experiments are conducted to demonstrate the superiority of our method compared with state-of-the-art methods. The source code will be available at \url{https://supercong94.wixsite.com/supercong94}.
HATNet: An End-to-End Holistic Attention Network for Diagnosis of Breast Biopsy Images
Jul 25, 2020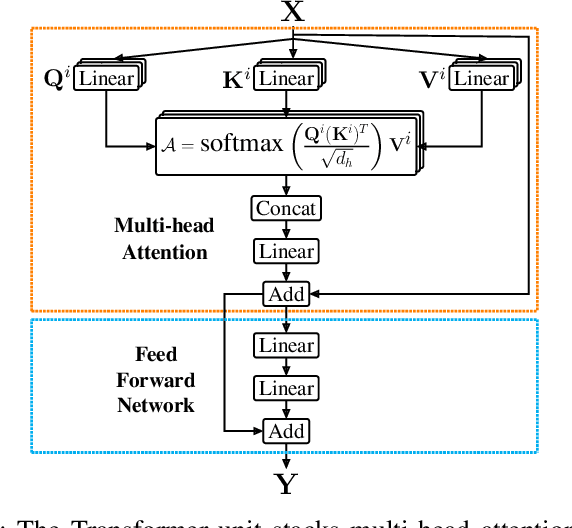
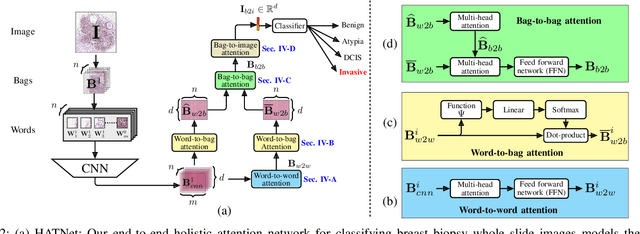
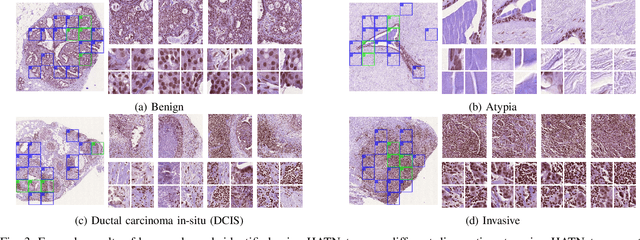
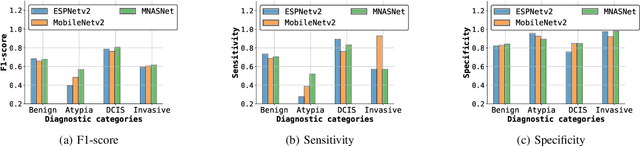
Training end-to-end networks for classifying gigapixel size histopathological images is computationally intractable. Most approaches are patch-based and first learn local representations (patch-wise) before combining these local representations to produce image-level decisions. However, dividing large tissue structures into patches limits the context available to these networks, which may reduce their ability to learn representations from clinically relevant structures. In this paper, we introduce a novel attention-based network, the Holistic ATtention Network (HATNet) to classify breast biopsy images. We streamline the histopathological image classification pipeline and show how to learn representations from gigapixel size images end-to-end. HATNet extends the bag-of-words approach and uses self-attention to encode global information, allowing it to learn representations from clinically relevant tissue structures without any explicit supervision. It outperforms the previous best network Y-Net, which uses supervision in the form of tissue-level segmentation masks, by 8%. Importantly, our analysis reveals that HATNet learns representations from clinically relevant structures, and it matches the classification accuracy of human pathologists for this challenging test set. Our source code is available at \url{https://github.com/sacmehta/HATNet}
Phase Retrieval with Holography and Untrained Priors: Tackling the Challenges of Low-Photon Nanoscale Imaging
Dec 15, 2020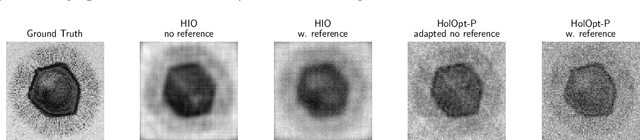


Phase retrieval is the inverse problem of recovering a signal from magnitude-only Fourier measurements, and underlies numerous imaging modalities, such as Coherent Diffraction Imaging (CDI). A variant of this setup, known as holography, includes a reference object that is placed adjacent to the specimen of interest before measurements are collected. The resulting inverse problem, known as holographic phase retrieval, is well-known to have improved problem conditioning relative to the original. This innovation, i.e. Holographic CDI, becomes crucial at the nanoscale, where imaging specimens such as viruses, proteins, and crystals require low-photon measurements. This data is highly corrupted by Poisson shot noise, and often lacks low-frequency content as well. In this work, we introduce a dataset-free deep learning framework for holographic phase retrieval adapted to these challenges. The key ingredients of our approach are the explicit and flexible incorporation of the physical forward model into an automatic differentiation procedure, the Poisson log-likelihood objective function, and an optional untrained deep image prior. We perform extensive evaluation under realistic conditions. Compared to competing classical methods, our method recovers signal from higher noise levels and is more resilient to suboptimal reference design, as well as to large missing regions of low frequencies in the observations. To the best of our knowledge, this is the first work to consider a dataset-free machine learning approach for holographic phase retrieval.