 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Adversarial Examples for Semantic Image Segmentation
Mar 03, 2017

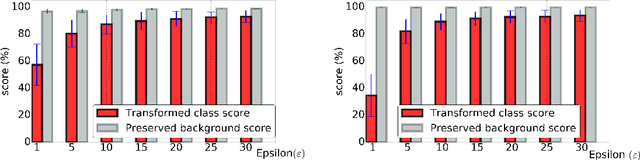
Machine learning methods in general and Deep Neural Networks in particular have shown to be vulnerable to adversarial perturbations. So far this phenomenon has mainly been studied in the context of whole-image classification. In this contribution, we analyse how adversarial perturbations can affect the task of semantic segmentation. We show how existing adversarial attackers can be transferred to this task and that it is possible to create imperceptible adversarial perturbations that lead a deep network to misclassify almost all pixels of a chosen class while leaving network prediction nearly unchanged outside this class.
Real-Time Deep Learning Approach to Visual Servo Control and Grasp Detection for Autonomous Robotic Manipulation
Oct 13, 2020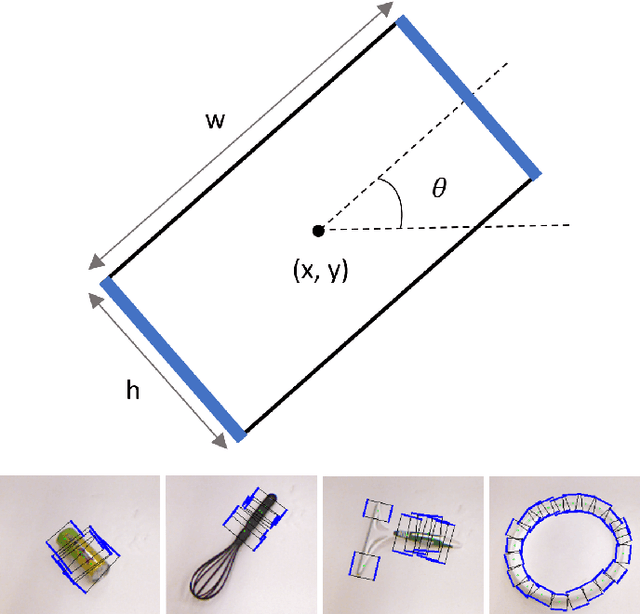
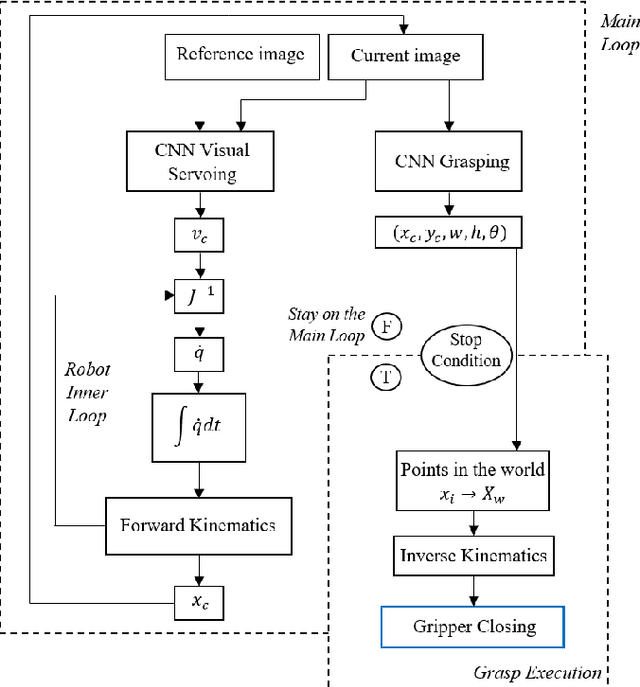
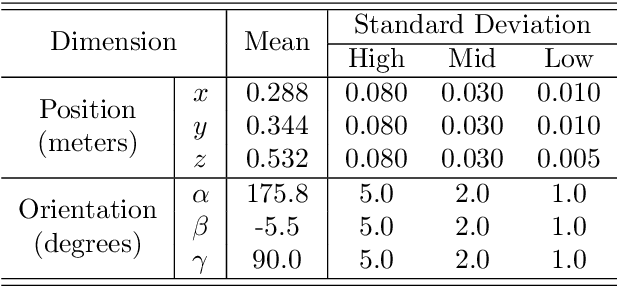
In order to explore robotic grasping in unstructured and dynamic environments, this work addresses the visual perception phase involved in the task. This phase involves the processing of visual data to obtain the location of the object to be grasped, its pose and the points at which the robot`s grippers must make contact to ensure a stable grasp. For this, the Cornell Grasping dataset is used to train a convolutional neural network that, having an image of the robot`s workspace, with a certain object, is able to predict a grasp rectangle that symbolizes the position, orientation and opening of the robot`s grippers before its closing. In addition to this network, which runs in real-time, another one is designed to deal with situations in which the object moves in the environment. Therefore, the second network is trained to perform a visual servo control, ensuring that the object remains in the robot`s field of view. This network predicts the proportional values of the linear and angular velocities that the camera must have so that the object is always in the image processed by the grasp network. The dataset used for training was automatically generated by a Kinova Gen3 manipulator. The robot is also used to evaluate the applicability in real-time and obtain practical results from the designed algorithms. Moreover, the offline results obtained through validation sets are also analyzed and discussed regarding their efficiency and processing speed. The developed controller was able to achieve a millimeter accuracy in the final position considering a target object seen for the first time. To the best of our knowledge, we have not found in the literature other works that achieve such precision with a controller learned from scratch. Thus, this work presents a new system for autonomous robotic manipulation with high processing speed and the ability to generalize to several different objects.
Phase Sampling Profilometry
Sep 10, 2020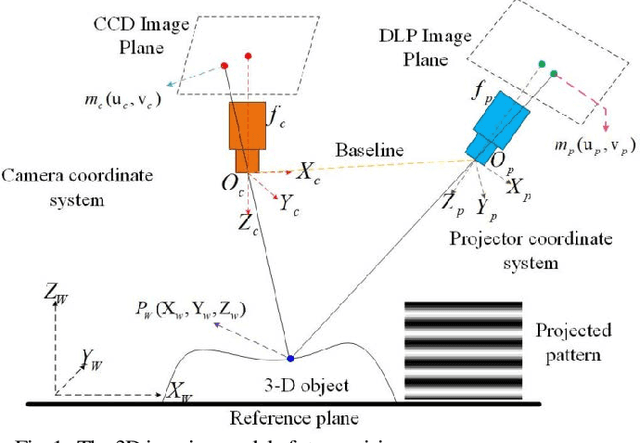
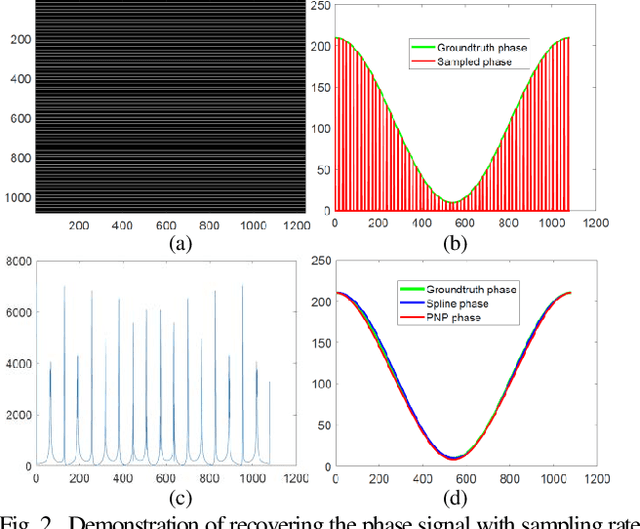
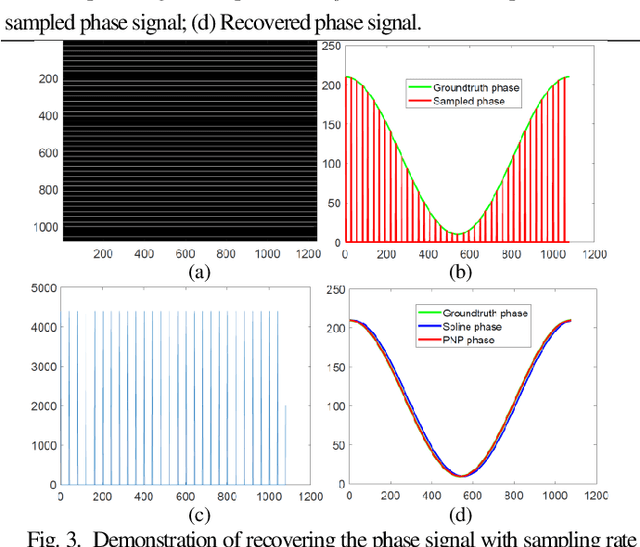
Structured light 3D surface imaging is a school of techniques in which structured light patterns are used for measuring the depth map of the object. Among all the designed structured light patterns, phase pattern has become most popular because of its high resolution and high accuracy. Accordingly, phase measuring profolimetry (PMP) has become the mainstream of structured light technology. In this letter, we introduce the concept of phase sampling profilometry (PSP) that calculates the phase unambiguously in the spatial-frequency domain with only one pattern image. Therefore, PSP is capable of measuring the 3D shapes of the moving objects robustly with single-shot.
Automated Pancreas Segmentation Using Multi-institutional Collaborative Deep Learning
Sep 28, 2020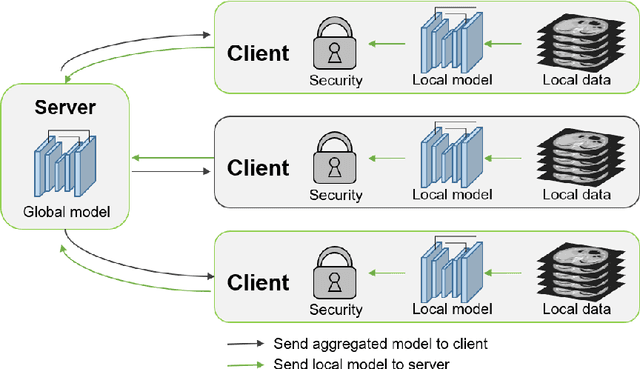
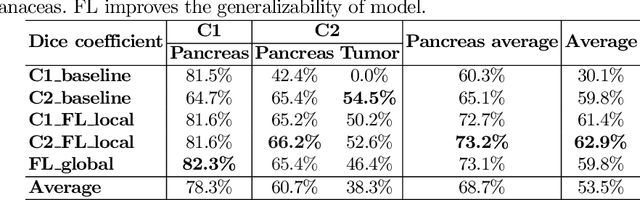

The performance of deep learning-based methods strongly relies on the number of datasets used for training. Many efforts have been made to increase the data in the medical image analysis field. However, unlike photography images, it is hard to generate centralized databases to collect medical images because of numerous technical, legal, and privacy issues. In this work, we study the use of federated learning between two institutions in a real-world setting to collaboratively train a model without sharing the raw data across national boundaries. We quantitatively compare the segmentation models obtained with federated learning and local training alone. Our experimental results show that federated learning models have higher generalizability than standalone training.
Representation learning from videos in-the-wild: An object-centric approach
Oct 06, 2020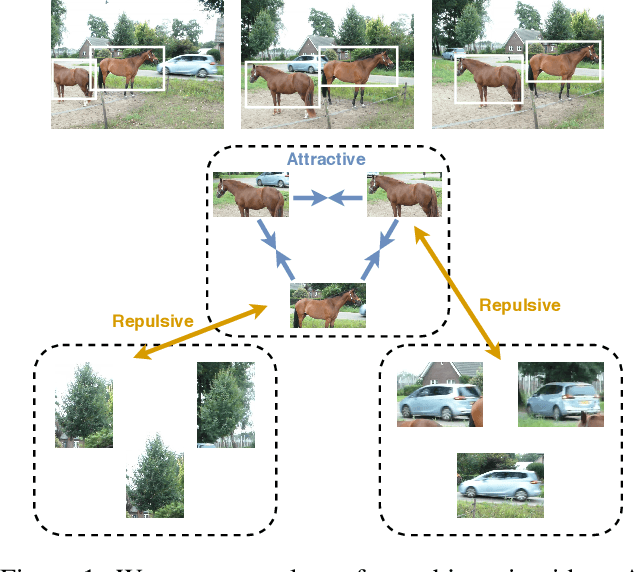
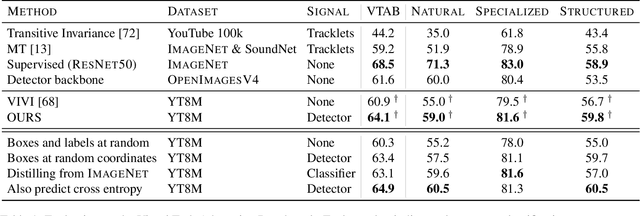

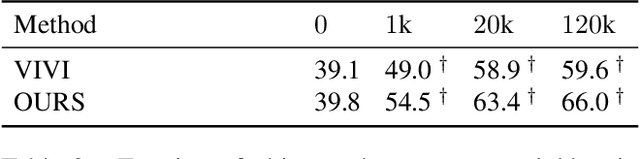
We propose a method to learn image representations from uncurated videos. We combine a supervised loss from off-the-shelf object detectors and self-supervised losses which naturally arise from the video-shot-frame-object hierarchy present in each video. We report competitive results on 19 transfer learning tasks of the Visual Task Adaptation Benchmark (VTAB), and on 8 out-of-distribution-generalization tasks, and discuss the benefits and shortcomings of the proposed approach. In particular, it improves over the baseline on all 18/19 few-shot learning tasks and 8/8 out-of-distribution generalization tasks. Finally, we perform several ablation studies and analyze the impact of the pretrained object detector on the performance across this suite of tasks.
Transducer Adaptive Ultrasound Volume Reconstruction
Nov 17, 2020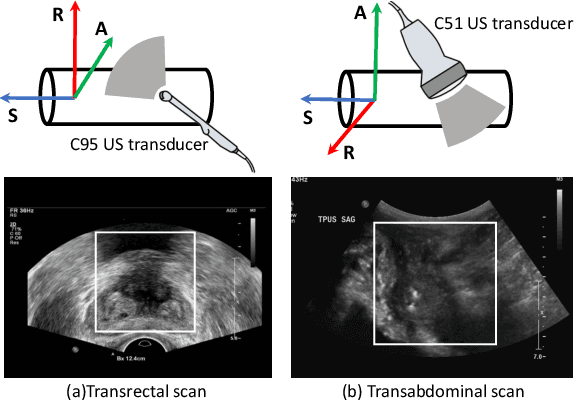

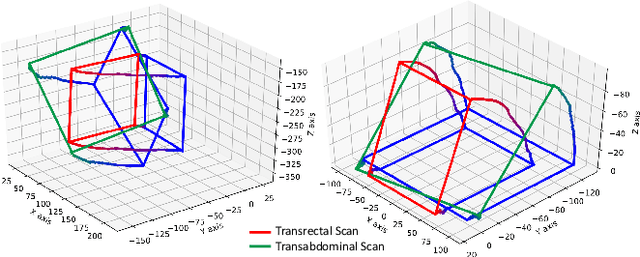
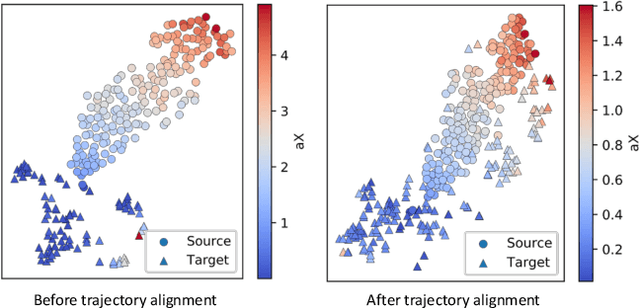
Reconstructed 3D ultrasound volume provides more context information compared to a sequence of 2D scanning frames, which is desirable for various clinical applications such as ultrasound-guided prostate biopsy. Nevertheless, 3D volume reconstruction from freehand 2D scans is a very challenging problem, especially without the use of external tracking devices. Recent deep learning based methods demonstrate the potential of directly estimating inter-frame motion between consecutive ultrasound frames. However, such algorithms are specific to particular transducers and scanning trajectories associated with the training data, which may not be generalized to other image acquisition settings. In this paper, we tackle the data acquisition difference as a domain shift problem and propose a novel domain adaptation strategy to adapt deep learning algorithms to data acquired with different transducers. Specifically, feature extractors that generate transducer-invariant features from different datasets are trained by minimizing the discrepancy between deep features of paired samples in a latent space. Our results show that the proposed domain adaptation method can successfully align different feature distributions while preserving the transducer-specific information for universal freehand ultrasound volume reconstruction.
Efficient Spatially Adaptive Convolution and Correlation
Jun 23, 2020
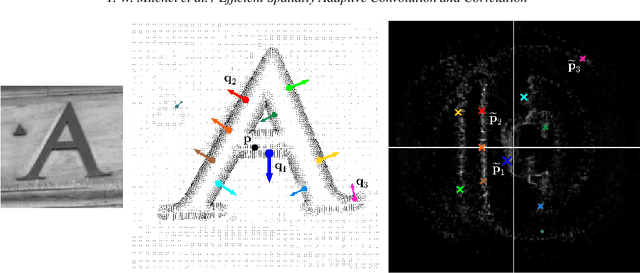

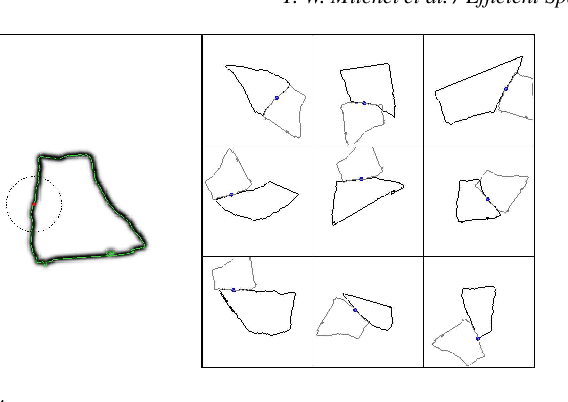
Fast methods for convolution and correlation underlie a variety of applications in computer vision and graphics, including efficient filtering, analysis, and simulation. However, standard convolution and correlation are inherently limited to fixed filters: spatial adaptation is impossible without sacrificing efficient computation. In early work, Freeman and Adelson have shown how steerable filters can address this limitation, providing a way for rotating the filter as it is passed over the signal. In this work, we provide a general, representation-theoretic, framework that allows for spatially varying linear transformations to be applied to the filter. This framework allows for efficient implementation of extended convolution and correlation for transformation groups such as rotation (in 2D and 3D) and scale, and provides a new interpretation for previous methods including steerable filters and the generalized Hough transform. We present applications to pattern matching, image feature description, vector field visualization, and adaptive image filtering.
Adaptive-Attentive Geolocalization from few queries: a hybrid approach
Oct 14, 2020

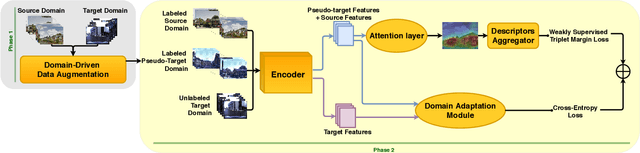
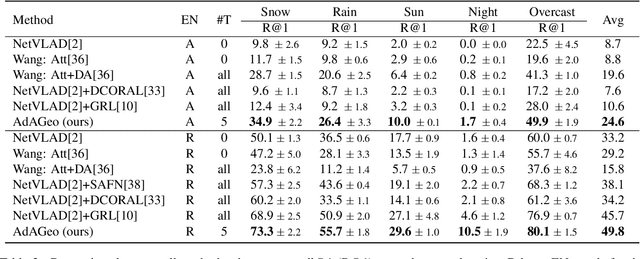
We address the task of cross-domain visual place recognition, where the goal is to geolocalize a given query image against a labeled gallery, in the case where the query and the gallery belong to different visual domains. To achieve this, we focus on building a domain robust deep network by leveraging over an attention mechanism combined with few-shot unsupervised domain adaptation techniques, where we use a small number of unlabeled target domain images to learn about the target distribution. With our method, we are able to outperform the current state of the art while using two orders of magnitude less target domain images. Finally we propose a new large-scale dataset for cross-domain visual place recognition, called SVOX. Upon acceptance of the paper, code and dataset will be released.
BGGAN: Bokeh-Glass Generative Adversarial Network for Rendering Realistic Bokeh
Nov 04, 2020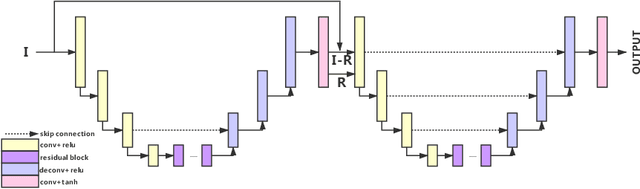
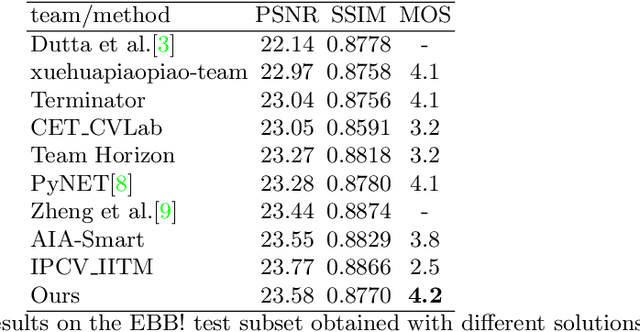
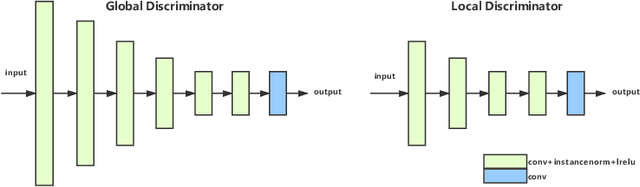
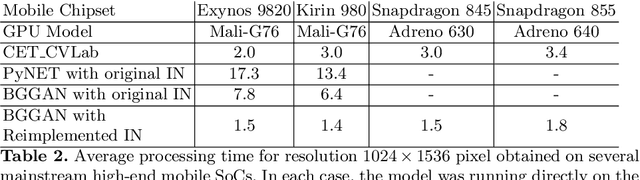
A photo captured with bokeh effect often means objects in focus are sharp while the out-of-focus areas are all blurred. DSLR can easily render this kind of effect naturally. However, due to the limitation of sensors, smartphones cannot capture images with depth-of-field effects directly. In this paper, we propose a novel generator called Glass-Net, which generates bokeh images not relying on complex hardware. Meanwhile, the GAN-based method and perceptual loss are combined for rendering a realistic bokeh effect in the stage of finetuning the model. Moreover, Instance Normalization(IN) is reimplemented in our network, which ensures our tflite model with IN can be accelerated on smartphone GPU. Experiments show that our method is able to render a high-quality bokeh effect and process one $1024 \times 1536$ pixel image in 1.9 seconds on all smartphone chipsets. This approach ranked First in AIM 2020 Rendering Realistic Bokeh Challenge Track 1 \& Track 2.
Extracurricular Learning: Knowledge Transfer Beyond Empirical Distribution
Jun 30, 2020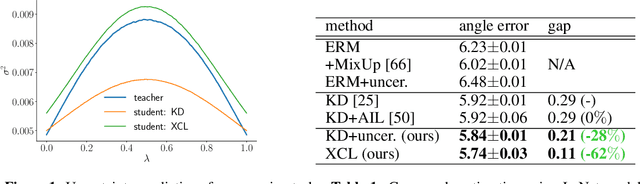
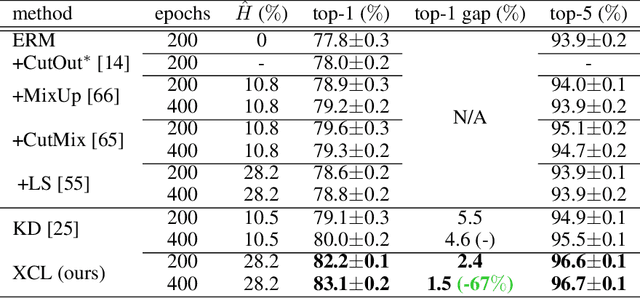
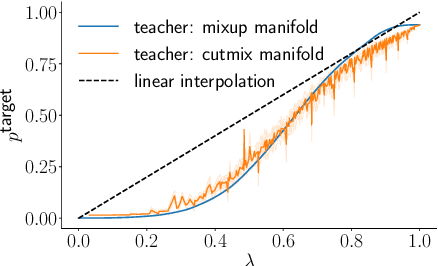

Knowledge distillation has been used to transfer knowledge learned by a sophisticated model (teacher) to a simpler model (student). This technique is widely used to compress model complexity. However, in most applications the compressed student model suffers from an accuracy gap with its teacher. We propose extracurricular learning, a novel knowledge distillation method, that bridges this gap by (1) modeling student and teacher uncertainties; (2) sampling training examples from underlying data distribution; and (3) matching student and teacher output distributions. We conduct extensive evaluations on regression and classification tasks and show that compared to the original knowledge distillation, extracurricular learning reduces the gap by 46% to 68%. This leads to major accuracy improvements compared to the empirical risk minimization-based training for various recent neural network architectures: 7.9% regression error reduction on the MPIIGaze dataset, +3.4% to +9.1% for top-1 image classification accuracy on the CIFAR100 dataset, and +2.9% for top-1 image classification accuracy on the ImageNet dataset.