 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Multimodal Word Sense Disambiguation in Creative Practice
Jul 15, 2020
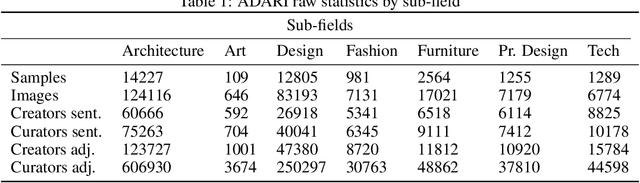

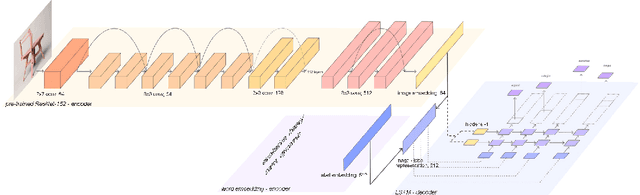
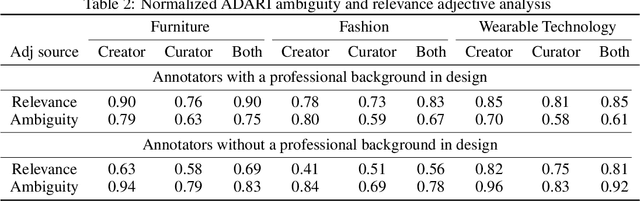
Language is ambiguous; many terms and expressions can convey the same idea. This is especially true in creative practice, where ideas and design intents are highly subjective. We present a dataset, Ambiguous Descriptions of Art Images (ADARI), of contemporary workpieces, which aims to provide a foundational resource for subjective image description and multimodal word disambiguation in the context of creative practice. The dataset contains a total of 240k images labeled with 260k descriptive sentences. It is additionally organized into sub-domains of architecture, art, design, fashion, furniture, product design and technology. In subjective image description, labels are not deterministic: for example, the ambiguous label dynamic might correspond to hundreds of different images. To understand this complexity, we analyze the ambiguity and relevance of text with respect to images using the state-of-the-art pre-trained BERT model for sentence classification. We provide a baseline for multi-label classification tasks and demonstrate the potential of multimodal approaches for understanding ambiguity in design intentions. We hope that ADARI dataset and baselines constitute a first step towards subjective label classification.
ULSAM: Ultra-Lightweight Subspace Attention Module for Compact Convolutional Neural Networks
Jun 26, 2020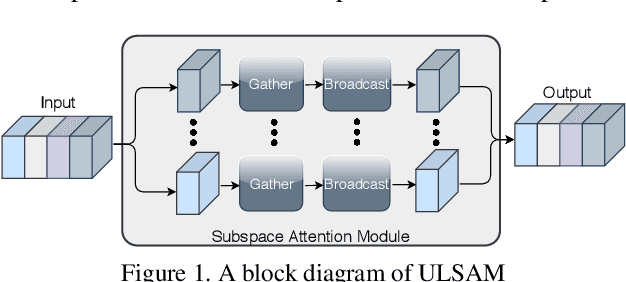

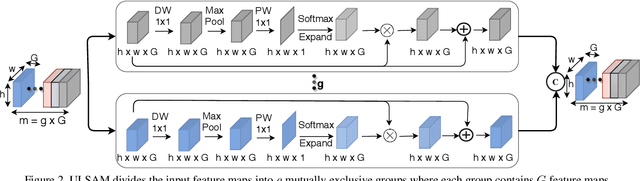
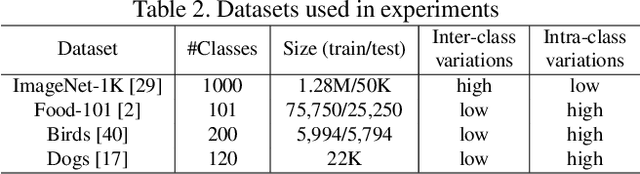
The capability of the self-attention mechanism to model the long-range dependencies has catapulted its deployment in vision models. Unlike convolution operators, self-attention offers infinite receptive field and enables compute-efficient modeling of global dependencies. However, the existing state-of-the-art attention mechanisms incur high compute and/or parameter overheads, and hence unfit for compact convolutional neural networks (CNNs). In this work, we propose a simple yet effective "Ultra-Lightweight Subspace Attention Mechanism" (ULSAM), which infers different attention maps for each feature map subspace. We argue that leaning separate attention maps for each feature subspace enables multi-scale and multi-frequency feature representation, which is more desirable for fine-grained image classification. Our method of subspace attention is orthogonal and complementary to the existing state-of-the-arts attention mechanisms used in vision models. ULSAM is end-to-end trainable and can be deployed as a plug-and-play module in the pre-existing compact CNNs. Notably, our work is the first attempt that uses a subspace attention mechanism to increase the efficiency of compact CNNs. To show the efficacy of ULSAM, we perform experiments with MobileNet-V1 and MobileNet-V2 as backbone architectures on ImageNet-1K and three fine-grained image classification datasets. We achieve $\approx$13% and $\approx$25% reduction in both the FLOPs and parameter counts of MobileNet-V2 with a 0.27% and more than 1% improvement in top-1 accuracy on the ImageNet-1K and fine-grained image classification datasets (respectively). Code and trained models are available at https://github.com/Nandan91/ULSAM.
* Accepted as a conference paper in 2020 IEEE Winter Conference on Applications of Computer Vision (WACV)
Cross-Attention in Coupled Unmixing Nets for Unsupervised Hyperspectral Super-Resolution
Jul 15, 2020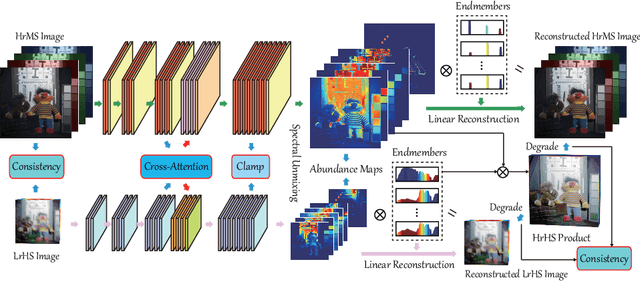
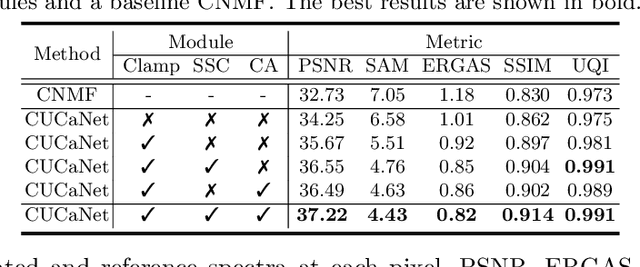
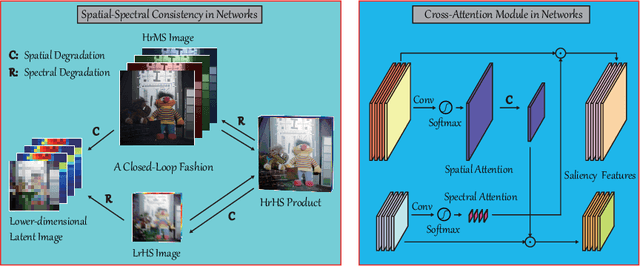
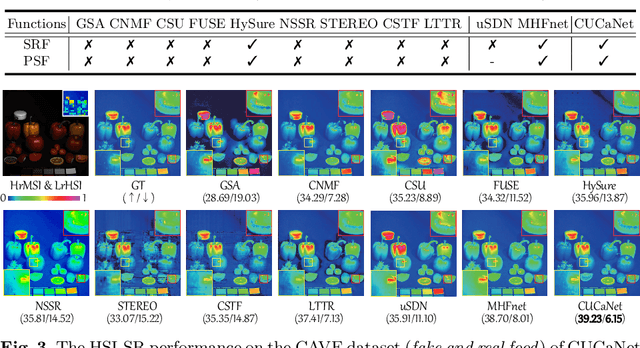
The recent advancement of deep learning techniques has made great progress on hyperspectral image super-resolution (HSI-SR). Yet the development of unsupervised deep networks remains challenging for this task. To this end, we propose a novel coupled unmixing network with a cross-attention mechanism, CUCaNet for short, to enhance the spatial resolution of HSI by means of higher-spatial-resolution multispectral image (MSI). Inspired by coupled spectral unmixing, a two-stream convolutional autoencoder framework is taken as backbone to jointly decompose MS and HS data into a spectrally meaningful basis and corresponding coefficients. CUCaNet is capable of adaptively learning spectral and spatial response functions from HS-MS correspondences by enforcing reasonable consistency assumptions on the networks. Moreover, a cross-attention module is devised to yield more effective spatial-spectral information transfer in networks. Extensive experiments are conducted on three widely-used HS-MS datasets in comparison with state-of-the-art HSI-SR models, demonstrating the superiority of the CUCaNet in the HSI-SR application. Furthermore, the codes and datasets will be available at: https://github.com/danfenghong/ECCV2020_CUCaNet.
Automated Pancreas Segmentation Using Multi-institutional Collaborative Deep Learning
Sep 28, 2020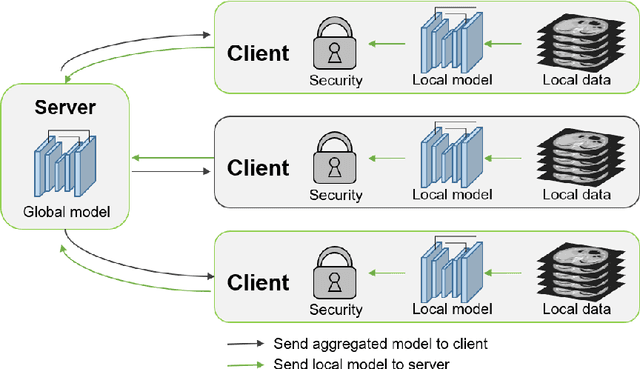
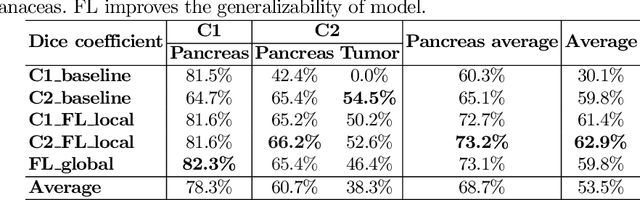

The performance of deep learning-based methods strongly relies on the number of datasets used for training. Many efforts have been made to increase the data in the medical image analysis field. However, unlike photography images, it is hard to generate centralized databases to collect medical images because of numerous technical, legal, and privacy issues. In this work, we study the use of federated learning between two institutions in a real-world setting to collaboratively train a model without sharing the raw data across national boundaries. We quantitatively compare the segmentation models obtained with federated learning and local training alone. Our experimental results show that federated learning models have higher generalizability than standalone training.
Multiclass Yeast Segmentation in Microstructured Environments with Deep Learning
Nov 16, 2020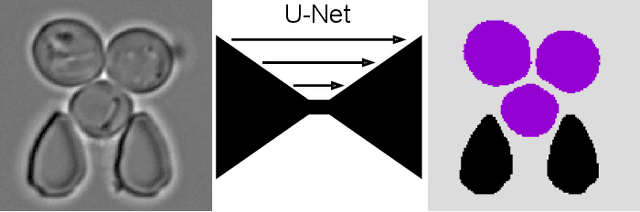
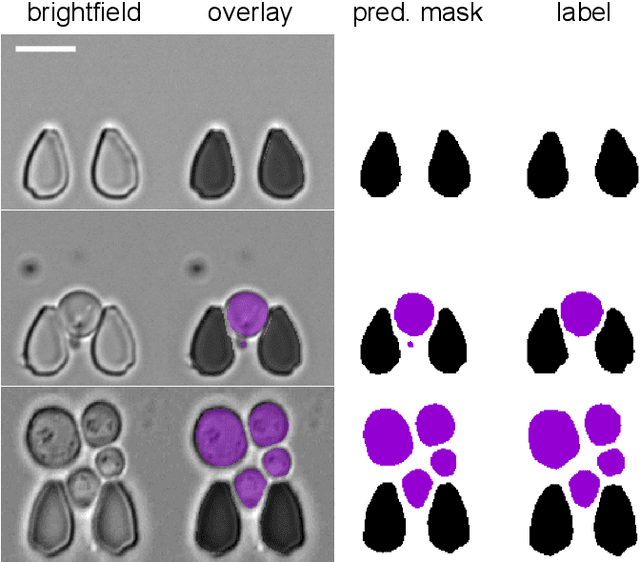
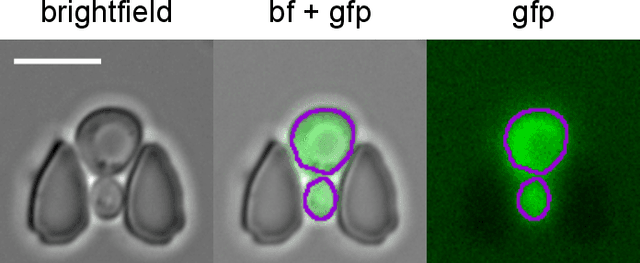

Cell segmentation is a major bottleneck in extracting quantitative single-cell information from microscopy data. The challenge is exasperated in the setting of microstructured environments. While deep learning approaches have proven useful for general cell segmentation tasks, existing segmentation tools for the yeast-microstructure setting rely on traditional machine learning approaches. Here we present convolutional neural networks trained for multiclass segmenting of individual yeast cells and discerning these from cell-similar microstructures. We give an overview of the datasets recorded for training, validating and testing the networks, as well as a typical use-case. We showcase the method's contribution to segmenting yeast in microstructured environments with a typical synthetic biology application in mind. The models achieve robust segmentation results, outperforming the previous state-of-the-art in both accuracy and speed. The combination of fast and accurate segmentation is not only beneficial for a posteriori data processing, it also makes online monitoring of thousands of trapped cells or closed-loop optimal experimental design feasible from an image processing perspective.
Multi-channel Weighted Nuclear Norm Minimization for Real Color Image Denoising
May 28, 2017
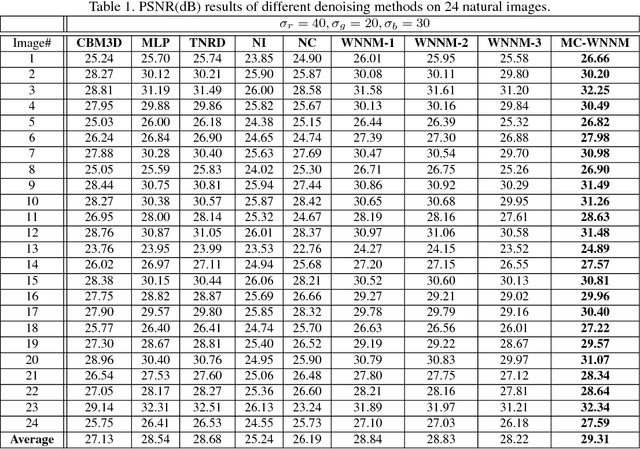

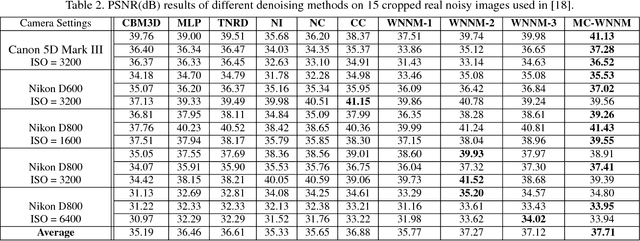
Most of the existing denoising algorithms are developed for grayscale images, while it is not a trivial work to extend them for color image denoising because the noise statistics in R, G, B channels can be very different for real noisy images. In this paper, we propose a multi-channel (MC) optimization model for real color image denoising under the weighted nuclear norm minimization (WNNM) framework. We concatenate the RGB patches to make use of the channel redundancy, and introduce a weight matrix to balance the data fidelity of the three channels in consideration of their different noise statistics. The proposed MC-WNNM model does not have an analytical solution. We reformulate it into a linear equality-constrained problem and solve it with the alternating direction method of multipliers. Each alternative updating step has closed-form solution and the convergence can be guaranteed. Extensive experiments on both synthetic and real noisy image datasets demonstrate the superiority of the proposed MC-WNNM over state-of-the-art denoising methods.
Phase Sampling Profilometry
Sep 10, 2020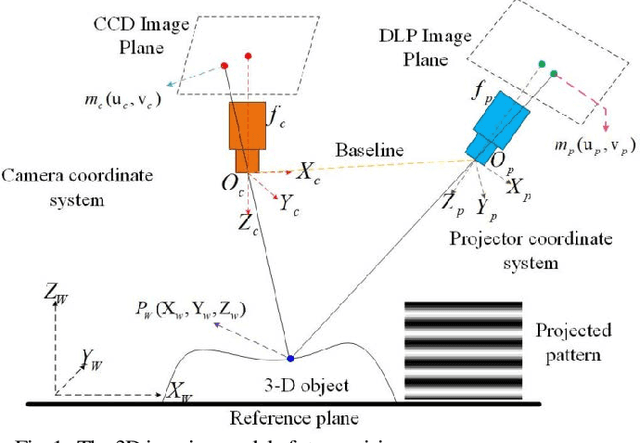
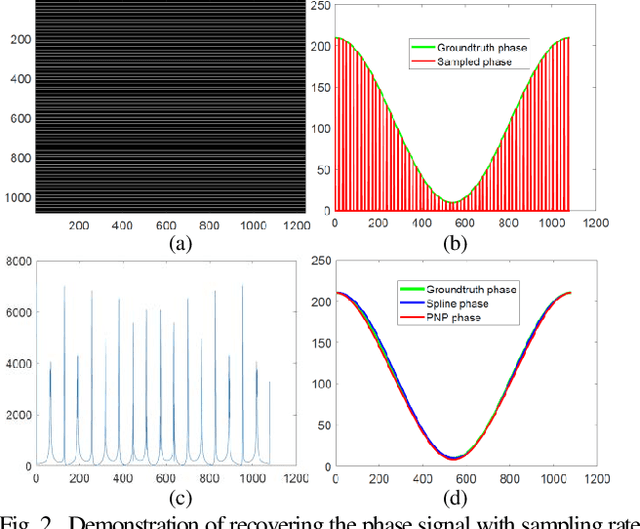
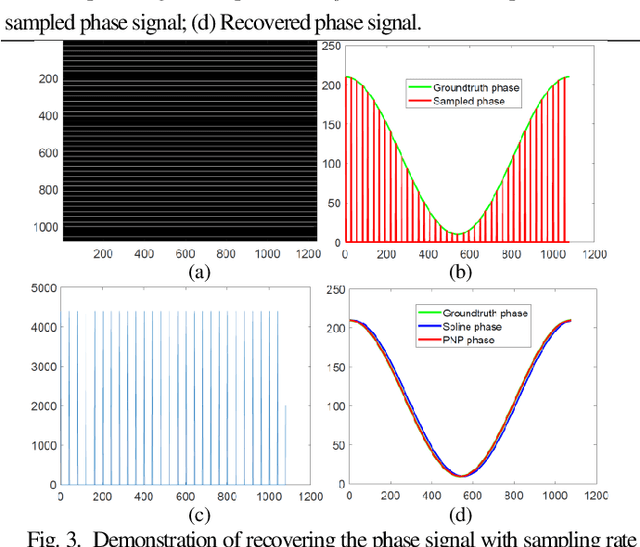
Structured light 3D surface imaging is a school of techniques in which structured light patterns are used for measuring the depth map of the object. Among all the designed structured light patterns, phase pattern has become most popular because of its high resolution and high accuracy. Accordingly, phase measuring profolimetry (PMP) has become the mainstream of structured light technology. In this letter, we introduce the concept of phase sampling profilometry (PSP) that calculates the phase unambiguously in the spatial-frequency domain with only one pattern image. Therefore, PSP is capable of measuring the 3D shapes of the moving objects robustly with single-shot.
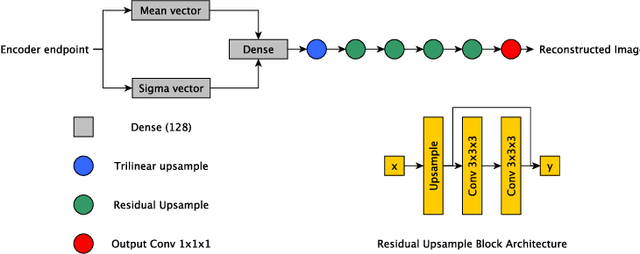
Super-resolution Variational Auto-Encoders
Jun 09, 2020

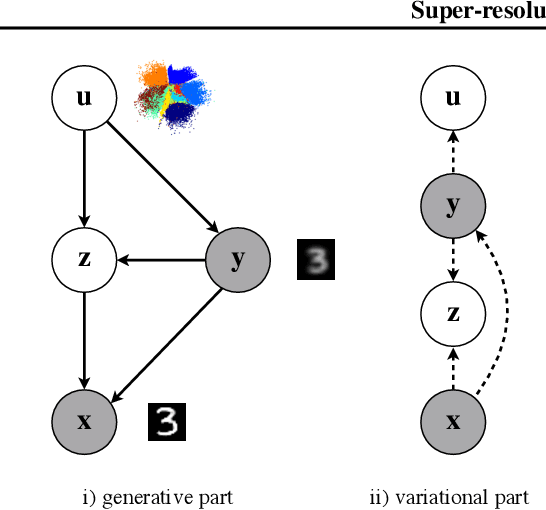
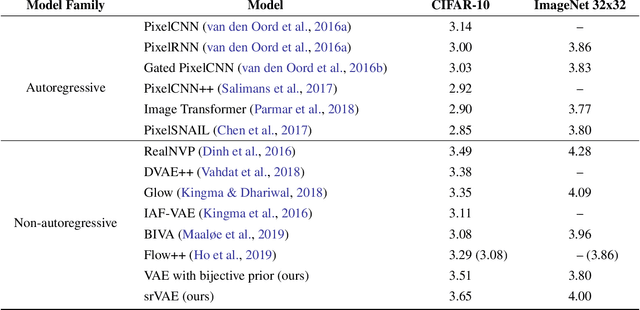
The framework of variational autoencoders (VAEs) provides a principled method for jointly learning latent-variable models and corresponding inference models. However, the main drawback of this approach is the blurriness of the generated images. Some studies link this effect to the objective function, namely, the (negative) log-likelihood. Here, we propose to enhance VAEs by adding a random variable that is a downscaled version of the original image and still use the log-likelihood function as the learning objective. Further, by providing the downscaled image as an input to the decoder, it can be used in a manner similar to the super-resolution. We present empirically that the proposed approach performs comparably to VAEs in terms of the negative log-likelihood function, but it obtains a better FID score.
Interpreting Context of Images using Scene Graphs
Dec 01, 2019
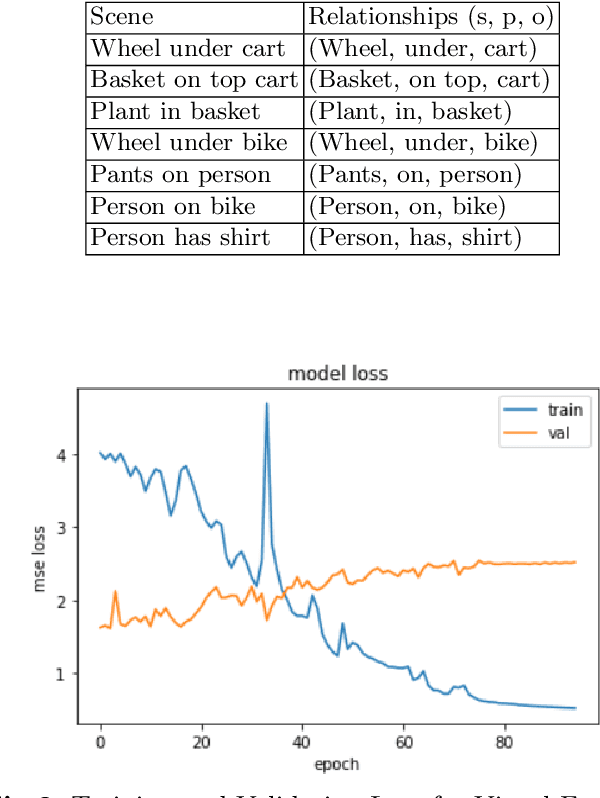

Understanding a visual scene incorporates objects, relationships, and context. Traditional methods working on an image mostly focus on object detection and fail to capture the relationship between the objects. Relationships can give rich semantic information about the objects in a scene. The context can be conducive to comprehending an image since it will help us to perceive the relation between the objects and thus, give us a deeper insight into the image. Through this idea, our project delivers a model that focuses on finding the context present in an image by representing the image as a graph, where the nodes will the objects and edges will be the relation between them. The context is found using the visual and semantic cues which are further concatenated and given to the Support Vector Machines (SVM) to detect the relation between two objects. This presents us with the context of the image which can be further used in applications such as similar image retrieval, image captioning, or story generation.
Remote Sensing Image Classification with Large Scale Gaussian Processes
Oct 03, 2017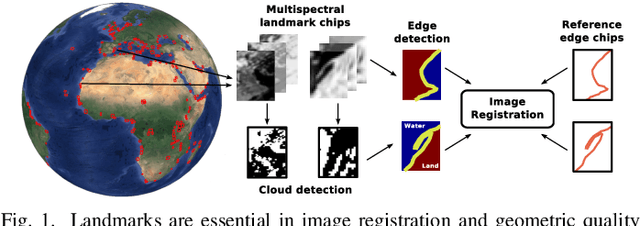
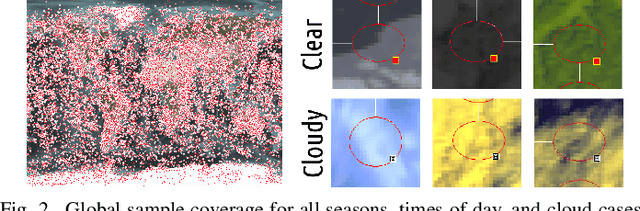
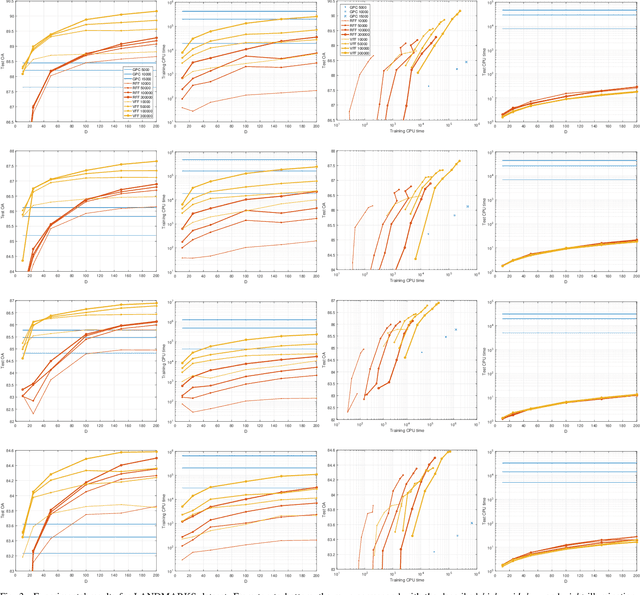
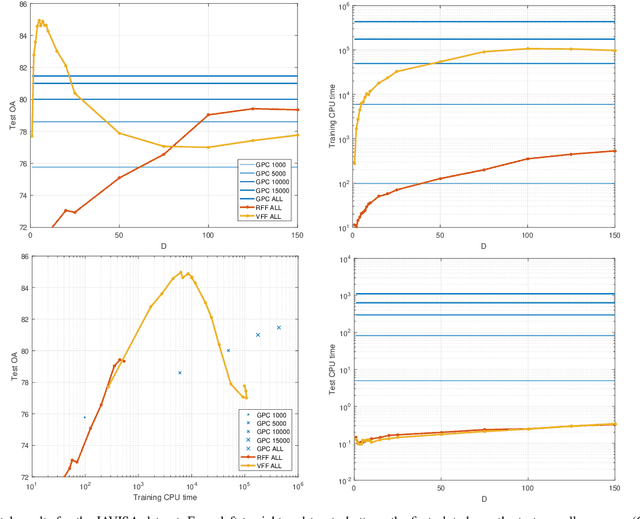
Current remote sensing image classification problems have to deal with an unprecedented amount of heterogeneous and complex data sources. Upcoming missions will soon provide large data streams that will make land cover/use classification difficult. Machine learning classifiers can help at this, and many methods are currently available. A popular kernel classifier is the Gaussian process classifier (GPC), since it approaches the classification problem with a solid probabilistic treatment, thus yielding confidence intervals for the predictions as well as very competitive results to state-of-the-art neural networks and support vector machines. However, its computational cost is prohibitive for large scale applications, and constitutes the main obstacle precluding wide adoption. This paper tackles this problem by introducing two novel efficient methodologies for Gaussian Process (GP) classification. We first include the standard random Fourier features approximation into GPC, which largely decreases its computational cost and permits large scale remote sensing image classification. In addition, we propose a model which avoids randomly sampling a number of Fourier frequencies, and alternatively learns the optimal ones within a variational Bayes approach. The performance of the proposed methods is illustrated in complex problems of cloud detection from multispectral imagery and infrared sounding data. Excellent empirical results support the proposal in both computational cost and accuracy.