 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Guided Open Vocabulary Image Captioning with Constrained Beam Search
Jul 19, 2017
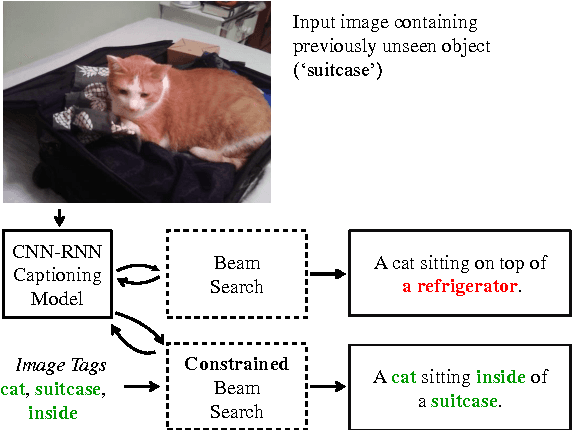
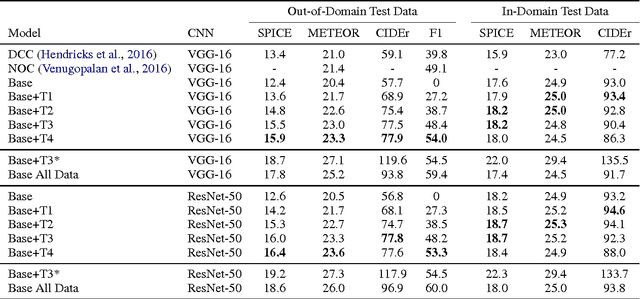
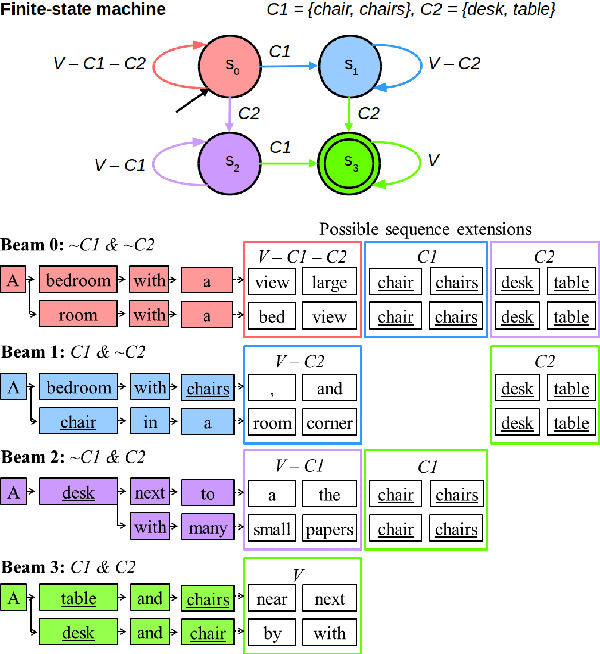

Existing image captioning models do not generalize well to out-of-domain images containing novel scenes or objects. This limitation severely hinders the use of these models in real world applications dealing with images in the wild. We address this problem using a flexible approach that enables existing deep captioning architectures to take advantage of image taggers at test time, without re-training. Our method uses constrained beam search to force the inclusion of selected tag words in the output, and fixed, pretrained word embeddings to facilitate vocabulary expansion to previously unseen tag words. Using this approach we achieve state of the art results for out-of-domain captioning on MSCOCO (and improved results for in-domain captioning). Perhaps surprisingly, our results significantly outperform approaches that incorporate the same tag predictions into the learning algorithm. We also show that we can significantly improve the quality of generated ImageNet captions by leveraging ground-truth labels.
Trace-Norm Adversarial Examples
Jul 02, 2020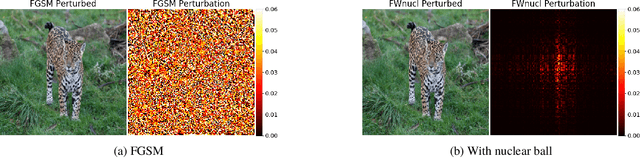
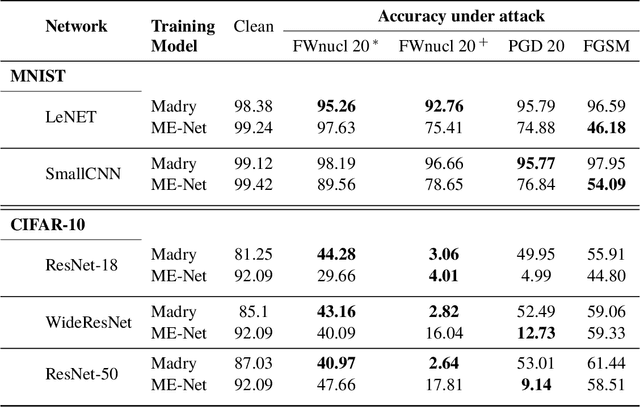

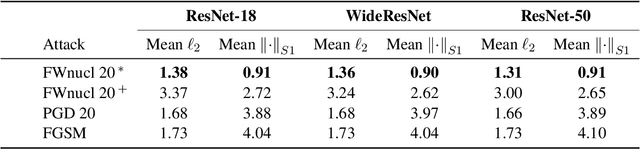
White box adversarial perturbations are sought via iterative optimization algorithms most often minimizing an adversarial loss on a $l_p$ neighborhood of the original image, the so-called distortion set. Constraining the adversarial search with different norms results in disparately structured adversarial examples. Here we explore several distortion sets with structure-enhancing algorithms. These new structures for adversarial examples, yet pervasive in optimization, are for instance a challenge for adversarial theoretical certification which again provides only $l_p$ certificates. Because adversarial robustness is still an empirical field, defense mechanisms should also reasonably be evaluated against differently structured attacks. Besides, these structured adversarial perturbations may allow for larger distortions size than their $l_p$ counter-part while remaining imperceptible or perceptible as natural slight distortions of the image. Finally, they allow some control on the generation of the adversarial perturbation, like (localized) bluriness.
FcaNet: Frequency Channel Attention Networks
Dec 22, 2020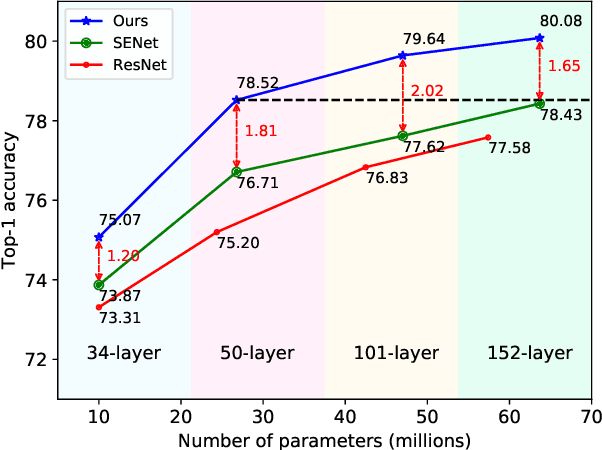
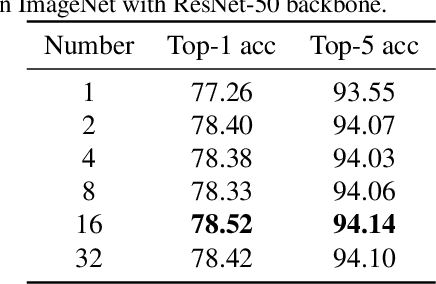
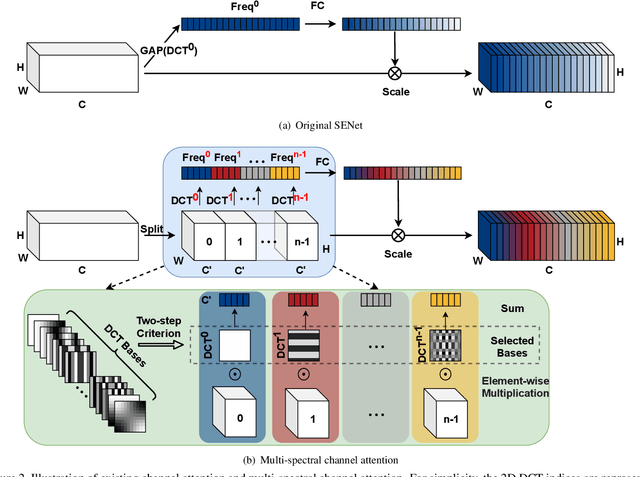
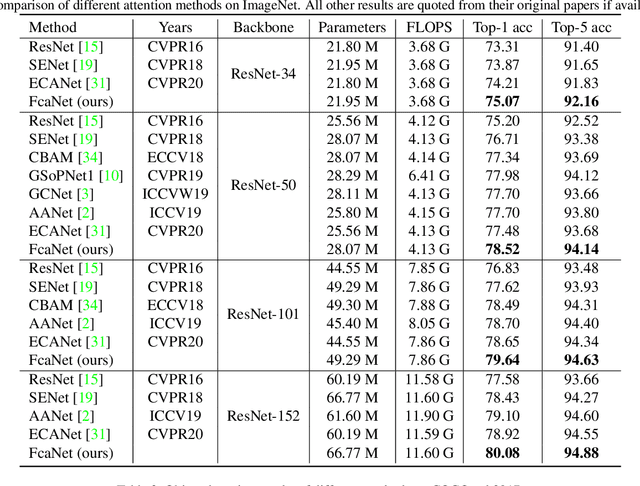
Attention mechanism, especially channel attention, has gained great success in the computer vision field. Many works focus on how to design efficient channel attention mechanisms while ignoring a fundamental problem, i.e., using global average pooling (GAP) as the unquestionable pre-processing method. In this work, we start from a different view and rethink channel attention using frequency analysis. Based on the frequency analysis, we mathematically prove that the conventional GAP is a special case of the feature decomposition in the frequency domain. With the proof, we naturally generalize the pre-processing of channel attention mechanism in the frequency domain and propose FcaNet with novel multi-spectral channel attention. The proposed method is simple but effective. We can change only one line of code in the calculation to implement our method within existing channel attention methods. Moreover, the proposed method achieves state-of-the-art results compared with other channel attention methods on image classification, object detection, and instance segmentation tasks. Our method could improve by 1.8% in terms of Top-1 accuracy on ImageNet compared with the baseline SENet-50, with the same number of parameters and the same computational cost. Our code and models will be made publicly available.
DEF: Deep Estimation of Sharp Geometric Features in 3D Shapes
Nov 30, 2020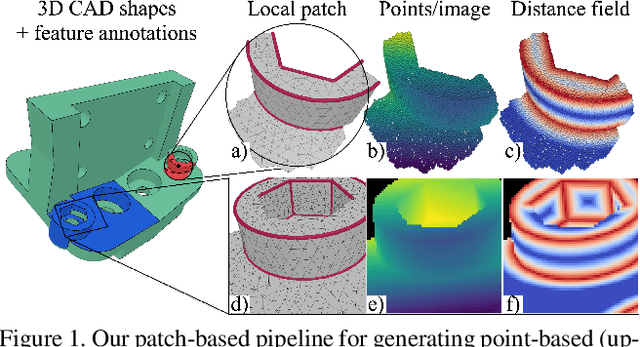
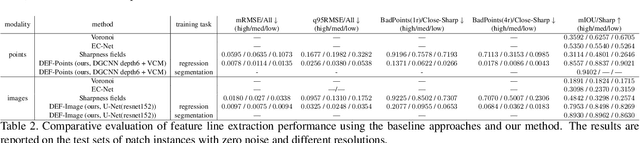
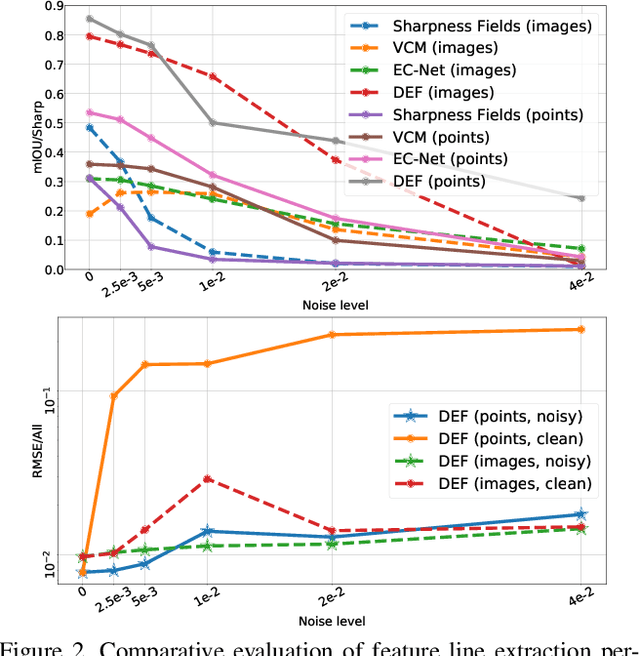
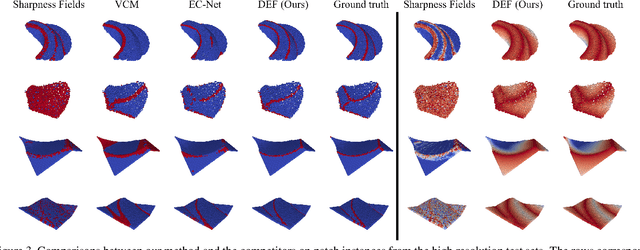
Sharp feature lines carry essential information about human-made objects, enabling compact 3D shape representations, high-quality surface reconstruction, and are a signal source for mesh processing. While extracting high-quality lines from noisy and undersampled data is challenging for traditional methods, deep learning-powered algorithms can leverage global and semantic information from the training data to aid in the process. We propose Deep Estimators of Features (DEFs), a learning-based framework for predicting sharp geometric features in sampled 3D shapes. Differently from existing data-driven methods, which reduce this problem to feature classification, we propose to regress a scalar field representing the distance from point samples to the closest feature line on local patches. By fusing the result of individual patches, we can process large 3D models, which are impossible to process for existing data-driven methods due to their size and complexity. Extensive experimental evaluation of DEFs is implemented on synthetic and real-world 3D shape datasets and suggests advantages of our image- and point-based estimators over competitor methods, as well as improved noise robustness and scalability of our approach.
Attention-Guided Discriminative Region Localization for Bone Age Assessment
May 30, 2020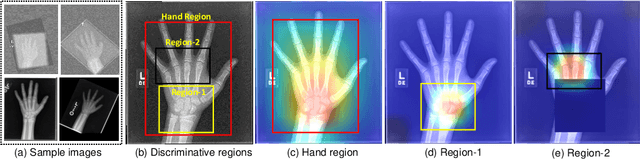

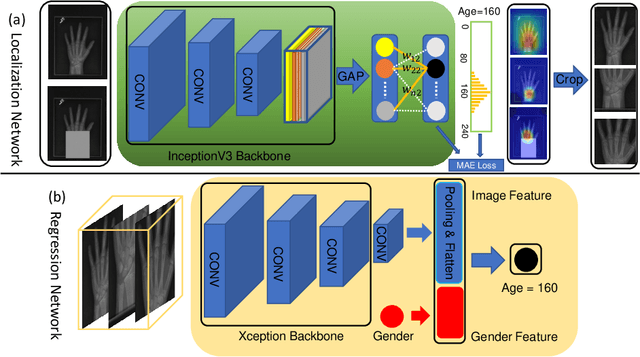

Bone age assessment (BAA) is clinically important as it can be used to diagnose endocrine and metabolic disorders during child development. Existing deep learning based methods for classifying bone age generally use the global image as input, or exploit local information by annotating extra bounding boxes or key points. Training with the global image underutilizes discriminative local information, while providing extra annotations is expensive and subjective. In this paper, we propose an attention-guided approach to automatically localize the discriminative regions for BAA without any extra annotations. Specifically, we first train a classification model to learn the attention heat maps of the discriminative regions, finding the hand region, the most discriminative region (the carpal bones), and the next most discriminative region (the metacarpal bones). We then crop these informative local regions from the original image and aggregate different regions for bone age regression. Extensive comparison experiments are conducted on the RSNA pediatric bone age data set. Using no training annotations, our method achieves competitive results compared with existing state-of-the-art semi-automatic deep learning-based methods that require manual annotation. codes are available at \url{https://github.com/chenchao666/Bone-Age-Assessment}.
Physics-Informed Neural Network Super Resolution for Advection-Diffusion Models
Nov 04, 2020
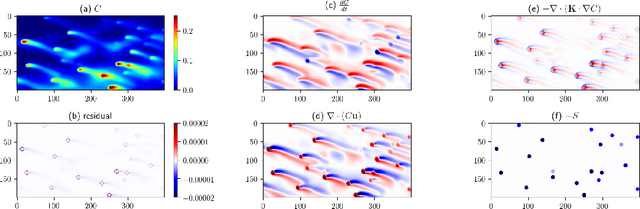
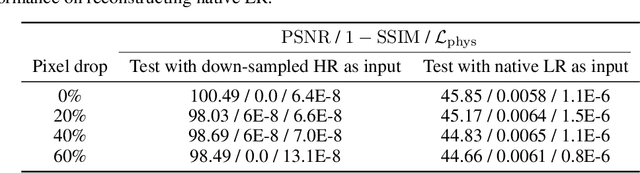
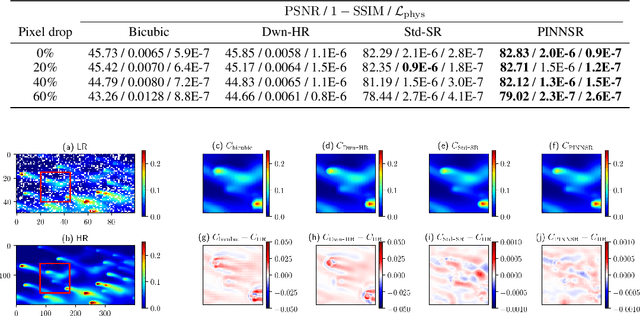
Physics-informed neural networks (NN) are an emerging technique to improve spatial resolution and enforce physical consistency of data from physics models or satellite observations. A super-resolution (SR) technique is explored to reconstruct high-resolution images ($4\times$) from lower resolution images in an advection-diffusion model of atmospheric pollution plumes. SR performance is generally increased when the advection-diffusion equation constrains the NN in addition to conventional pixel-based constraints. The ability of SR techniques to also reconstruct missing data is investigated by randomly removing image pixels from the simulations and allowing the system to learn the content of missing data. Improvements in S/N of $11\%$ are demonstrated when physics equations are included in SR with $40\%$ pixel loss. Physics-informed NNs accurately reconstruct corrupted images and generate better results compared to the standard SR approaches.
On Focal Loss for Class-Posterior Probability Estimation: A Theoretical Perspective
Nov 18, 2020
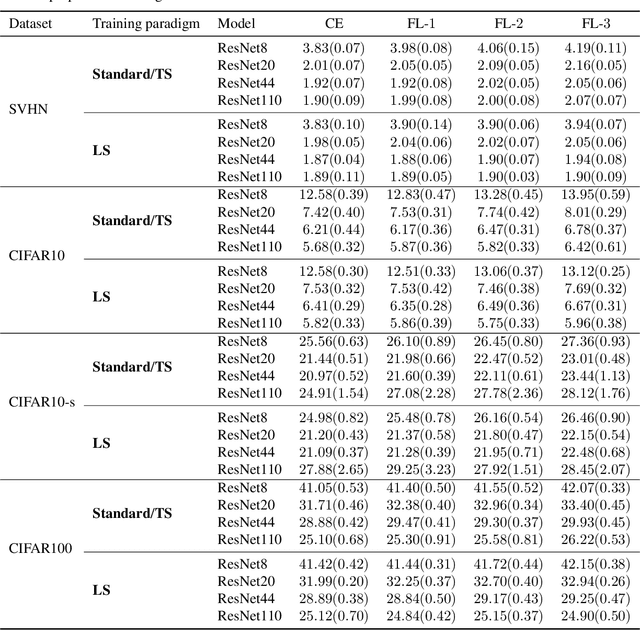
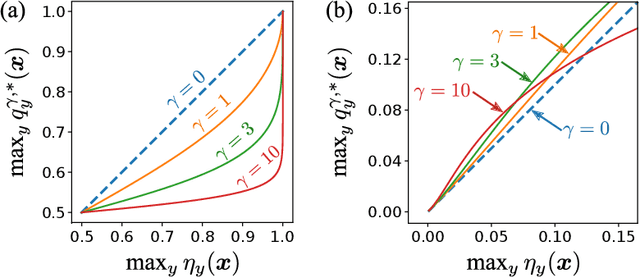
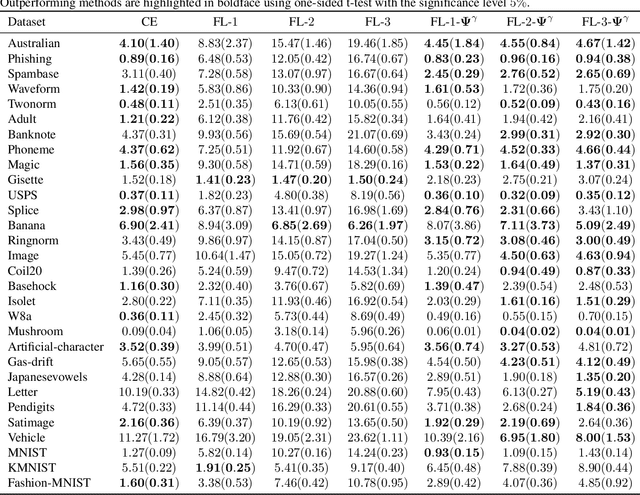
The focal loss has demonstrated its effectiveness in many real-world applications such as object detection and image classification, but its theoretical understanding has been limited so far. In this paper, we first prove that the focal loss is classification-calibrated, i.e., its minimizer surely yields the Bayes-optimal classifier and thus the use of the focal loss in classification can be theoretically justified. However, we also prove a negative fact that the focal loss is not strictly proper, i.e., the confidence score of the classifier obtained by focal loss minimization does not match the true class-posterior probability and thus it is not reliable as a class-posterior probability estimator. To mitigate this problem, we next prove that a particular closed-form transformation of the confidence score allows us to recover the true class-posterior probability. Through experiments on benchmark datasets, we demonstrate that our proposed transformation significantly improves the accuracy of class-posterior probability estimation.
Background Adaptive Faster R-CNN for Semi-Supervised Convolutional Object Detection of Threats in X-Ray Images
Oct 02, 2020Recently, progress has been made in the supervised training of Convolutional Object Detectors (e.g. Faster R-CNN) for threat recognition in carry-on luggage using X-ray images. This is part of the Transportation Security Administration's (TSA's) mission to protect air travelers in the United States. While more training data with threats may reliably improve performance for this class of deep algorithm, it is expensive to stage in realistic contexts. By contrast, data from the real world can be collected quickly with minimal cost. In this paper, we present a semi-supervised approach for threat recognition which we call Background Adaptive Faster R-CNN. This approach is a training method for two-stage object detectors which uses Domain Adaptation methods from the field of deep learning. The data sources described earlier make two "domains": a hand-collected data domain of images with threats, and a real-world domain of images assumed without threats. Two domain discriminators, one for discriminating object proposals and one for image features, are adversarially trained to prevent encoding domain-specific information. Without this penalty a Convolutional Neural Network (CNN) can learn to identify domains based on superficial characteristics, and minimize a supervised loss function without improving its ability to recognize objects. For the hand-collected data, only object proposals and image features from backgrounds are used. The losses for these domain-adaptive discriminators are added to the Faster R-CNN losses of images from both domains. This can reduce threat detection false alarm rates by matching the statistics of extracted features from hand-collected backgrounds to real world data. Performance improvements are demonstrated on two independently-collected datasets of labeled threats.
Disentangling images with Lie group transformations and sparse coding
Dec 11, 2020

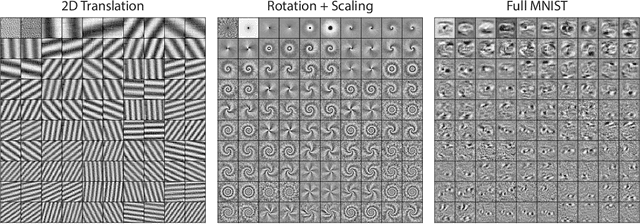

Discrete spatial patterns and their continuous transformations are two important regularities contained in natural signals. Lie groups and representation theory are mathematical tools that have been used in previous works to model continuous image transformations. On the other hand, sparse coding is an important tool for learning dictionaries of patterns in natural signals. In this paper, we combine these ideas in a Bayesian generative model that learns to disentangle spatial patterns and their continuous transformations in a completely unsupervised manner. Images are modeled as a sparse superposition of shape components followed by a transformation that is parameterized by n continuous variables. The shape components and transformations are not predefined, but are instead adapted to learn the symmetries in the data, with the constraint that the transformations form a representation of an n-dimensional torus. Training the model on a dataset consisting of controlled geometric transformations of specific MNIST digits shows that it can recover these transformations along with the digits. Training on the full MNIST dataset shows that it can learn both the basic digit shapes and the natural transformations such as shearing and stretching that are contained in this data.
Dependency Decomposition and a Reject Option for Explainable Models
Dec 11, 2020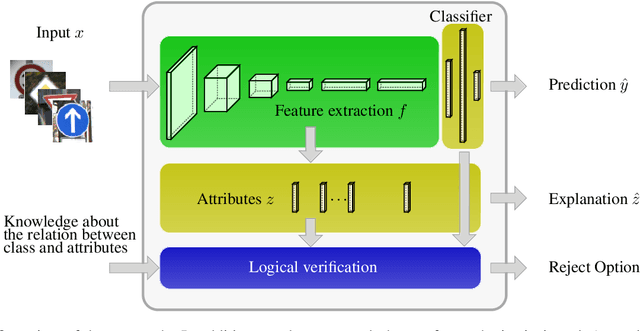
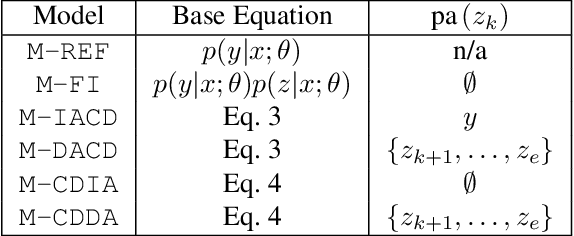
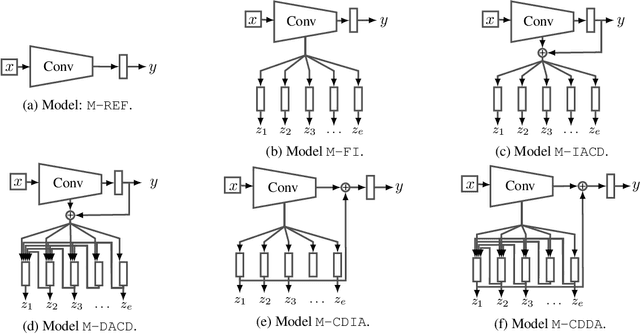
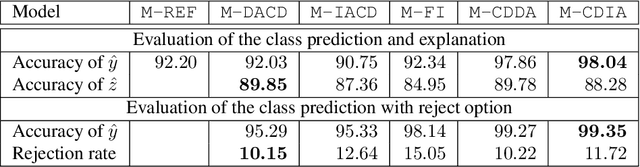
Deploying machine learning models in safety-related do-mains (e.g. autonomous driving, medical diagnosis) demands for approaches that are explainable, robust against adversarial attacks and aware of the model uncertainty. Recent deep learning models perform extremely well in various inference tasks, but the black-box nature of these approaches leads to a weakness regarding the three requirements mentioned above. Recent advances offer methods to visualize features, describe attribution of the input (e.g.heatmaps), provide textual explanations or reduce dimensionality. However,are explanations for classification tasks dependent or are they independent of each other? For in-stance, is the shape of an object dependent on the color? What is the effect of using the predicted class for generating explanations and vice versa? In the context of explainable deep learning models, we present the first analysis of dependencies regarding the probability distribution over the desired image classification outputs and the explaining variables (e.g. attributes, texts, heatmaps). Therefore, we perform an Explanation Dependency Decomposition (EDD). We analyze the implications of the different dependencies and propose two ways of generating the explanation. Finally, we use the explanation to verify (accept or reject) the prediction