 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Sim2Real for Self-Supervised Monocular Depth and Segmentation
Dec 01, 2020
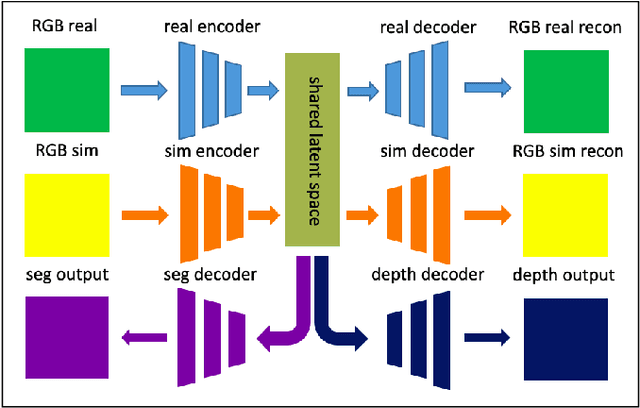
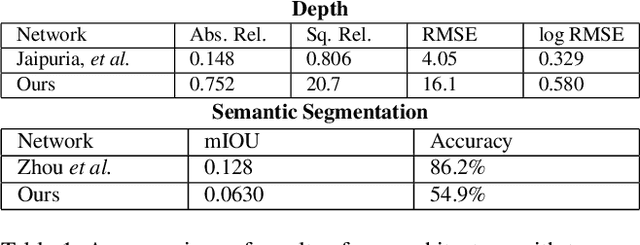
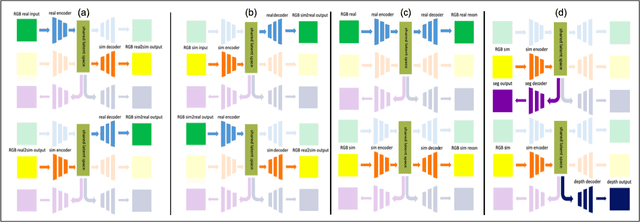
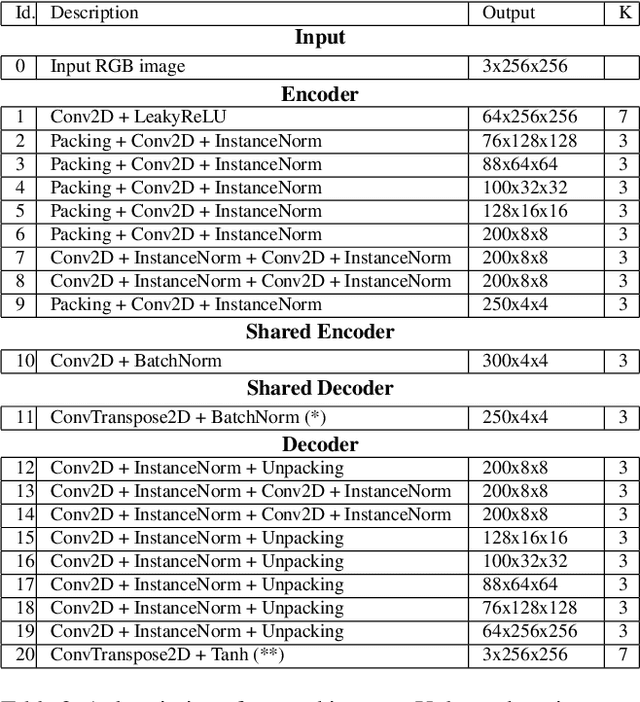
Image-based learning methods for autonomous vehicle perception tasks require large quantities of labelled, real data in order to properly train without overfitting, which can often be incredibly costly. While leveraging the power of simulated data can potentially aid in mitigating these costs, networks trained in the simulation domain usually fail to perform adequately when applied to images in the real domain. Recent advances in domain adaptation have indicated that a shared latent space assumption can help to bridge the gap between the simulation and real domains, allowing the transference of the predictive capabilities of a network from the simulation domain to the real domain. We demonstrate that a twin VAE-based architecture with a shared latent space and auxiliary decoders is able to bridge the sim2real gap without requiring any paired, ground-truth data in the real domain. Using only paired, ground-truth data in the simulation domain, this architecture has the potential to generate perception tasks such as depth and segmentation maps. We compare this method to networks trained in a supervised manner to indicate the merit of these results.
Image-Grounded Conversations: Multimodal Context for Natural Question and Response Generation
Apr 20, 2017



The popularity of image sharing on social media and the engagement it creates between users reflects the important role that visual context plays in everyday conversations. We present a novel task, Image-Grounded Conversations (IGC), in which natural-sounding conversations are generated about a shared image. To benchmark progress, we introduce a new multiple-reference dataset of crowd-sourced, event-centric conversations on images. IGC falls on the continuum between chit-chat and goal-directed conversation models, where visual grounding constrains the topic of conversation to event-driven utterances. Experiments with models trained on social media data show that the combination of visual and textual context enhances the quality of generated conversational turns. In human evaluation, the gap between human performance and that of both neural and retrieval architectures suggests that multi-modal IGC presents an interesting challenge for dialogue research.
AI Challenger : A Large-scale Dataset for Going Deeper in Image Understanding
Nov 17, 2017
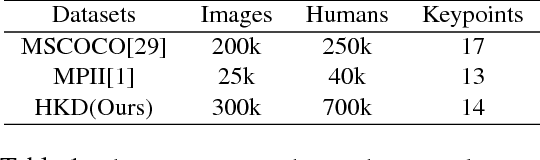
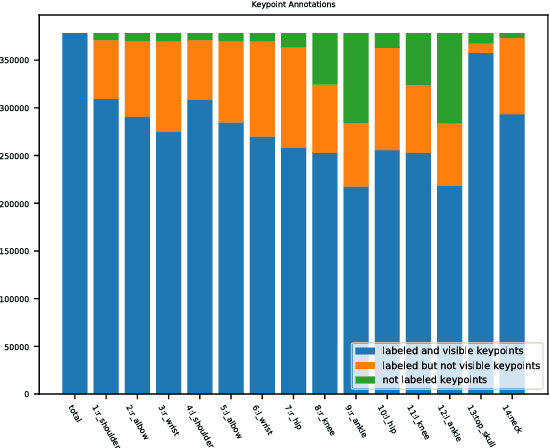
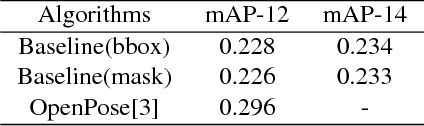
Significant progress has been achieved in Computer Vision by leveraging large-scale image datasets. However, large-scale datasets for complex Computer Vision tasks beyond classification are still limited. This paper proposed a large-scale dataset named AIC (AI Challenger) with three sub-datasets, human keypoint detection (HKD), large-scale attribute dataset (LAD) and image Chinese captioning (ICC). In this dataset, we annotate class labels (LAD), keypoint coordinate (HKD), bounding box (HKD and LAD), attribute (LAD) and caption (ICC). These rich annotations bridge the semantic gap between low-level images and high-level concepts. The proposed dataset is an effective benchmark to evaluate and improve different computational methods. In addition, for related tasks, others can also use our dataset as a new resource to pre-train their models.
Self-Supervised Physics-Guided Deep Learning Reconstruction For High-Resolution 3D LGE CMR
Nov 18, 2020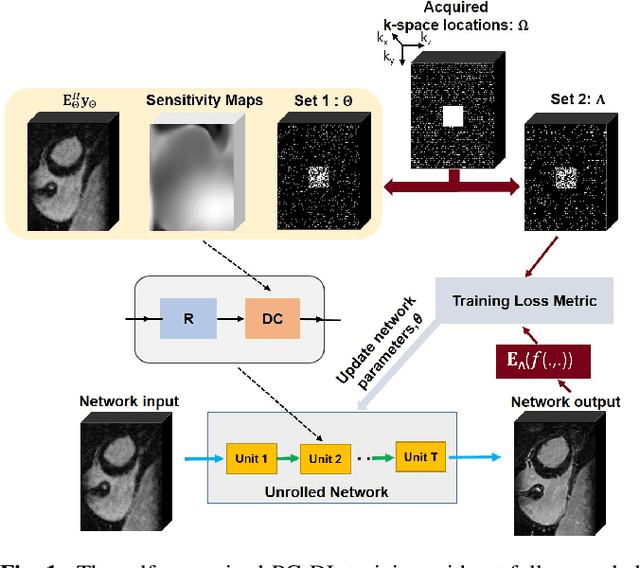
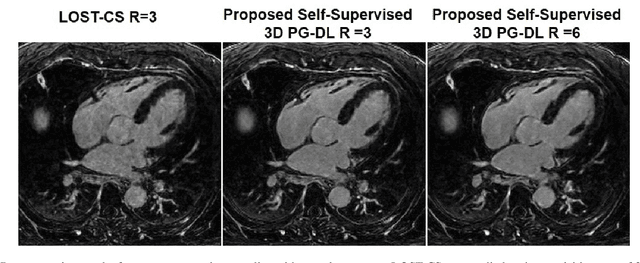
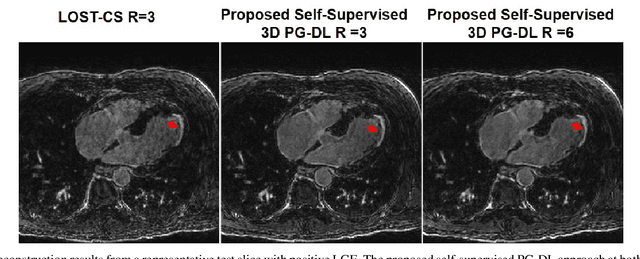
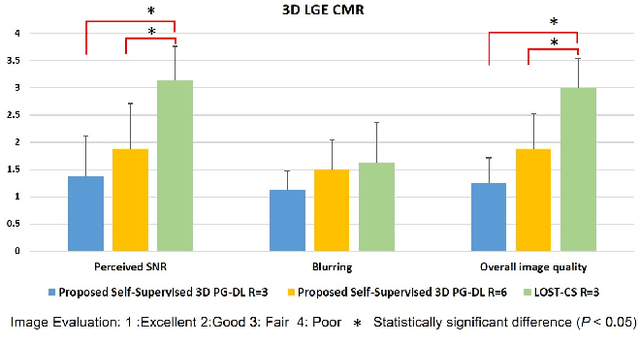
Late gadolinium enhancement (LGE) cardiac MRI (CMR) is the clinical standard for diagnosis of myocardial scar. 3D isotropic LGE CMR provides improved coverage and resolution compared to 2D imaging. However, image acceleration is required due to long scan times and contrast washout. Physics-guided deep learning (PG-DL) approaches have recently emerged as an improved accelerated MRI strategy. Training of PG-DL methods is typically performed in supervised manner requiring fully-sampled data as reference, which is challenging in 3D LGE CMR. Recently, a self-supervised learning approach was proposed to enable training PG-DL techniques without fully-sampled data. In this work, we extend this self-supervised learning approach to 3D imaging, while tackling challenges related to small training database sizes of 3D volumes. Results and a reader study on prospectively accelerated 3D LGE show that the proposed approach at 6-fold acceleration outperforms the clinically utilized compressed sensing approach at 3-fold acceleration.
Prediction of Object Geometry from Acoustic Scattering Using Convolutional Neural Networks
Oct 21, 2020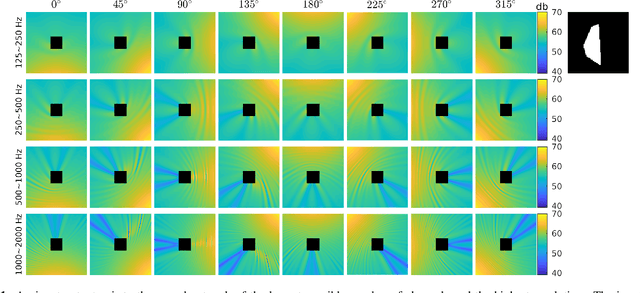
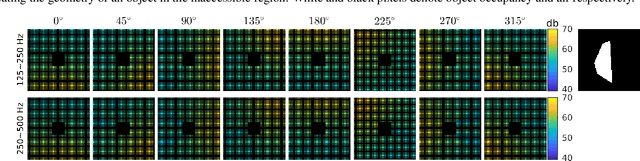
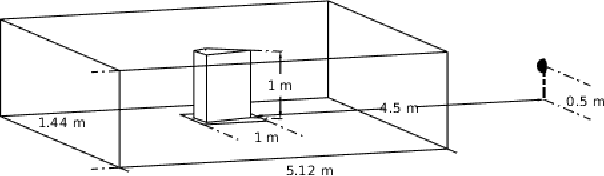
Acoustic scattering is strongly influenced by boundary geometry of objects over which sound scatters. The present work proposes a method to infer object geometry from scattering features by training convolutional neural networks. The training data is generated from a fast numerical solver developed on CUDA. The complete set of simulations is sampled to generate multiple datasets containing different amounts of channels and diverse image resolutions. The robustness of our approach in response to data degradation is evaluated by comparing the performance of networks trained using the datasets with varying levels of data degradation. The present work has found that the predictions made from our models match ground truth with high accuracy. In addition, accuracy does not degrade when fewer data channels or lower resolutions are used.
Image Super-Resolution via RL-CSC: When Residual Learning Meets Convolutional Sparse Coding
Dec 31, 2018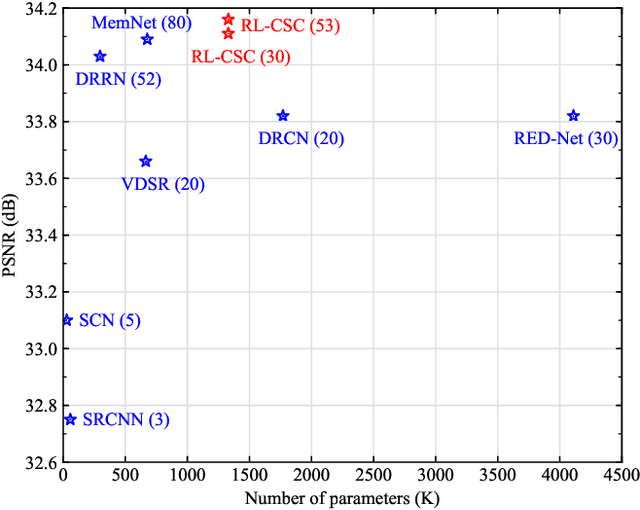
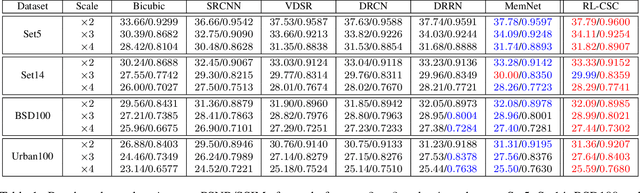
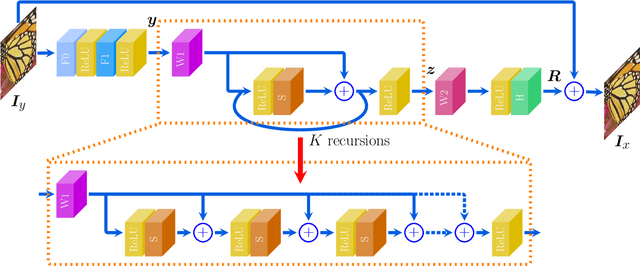
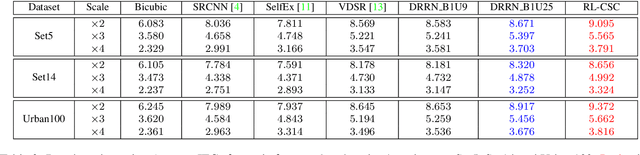
We propose a simple yet effective model for Single Image Super-Resolution (SISR), by combining the merits of Residual Learning and Convolutional Sparse Coding (RL-CSC). Our model is inspired by the Learned Iterative Shrinkage-Threshold Algorithm (LISTA). We extend LISTA to its convolutional version and build the main part of our model by strictly following the convolutional form, which improves the network's interpretability. Specifically, the convolutional sparse codings of input feature maps are learned in a recursive manner, and high-frequency information can be recovered from these CSCs. More importantly, residual learning is applied to alleviate the training difficulty when the network goes deeper. Extensive experiments on benchmark datasets demonstrate the effectiveness of our method. RL-CSC (30 layers) outperforms several recent state-of-the-arts, e.g., DRRN (52 layers) and MemNet (80 layers) in both accuracy and visual qualities. Codes and more results are available at https://github.com/axzml/RL-CSC.
A Survey on Assessing the Generalization Envelope of Deep Neural Networks at Inference Time for Image Classification
Aug 24, 2020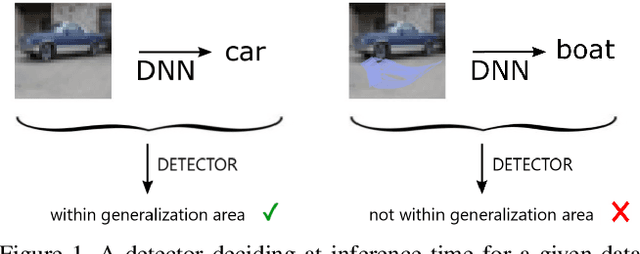

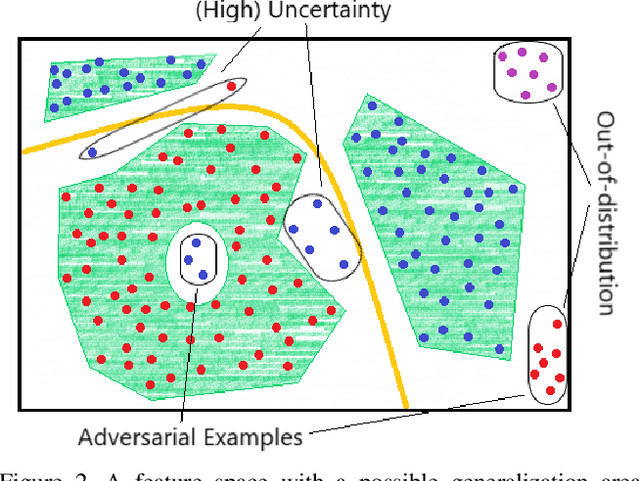
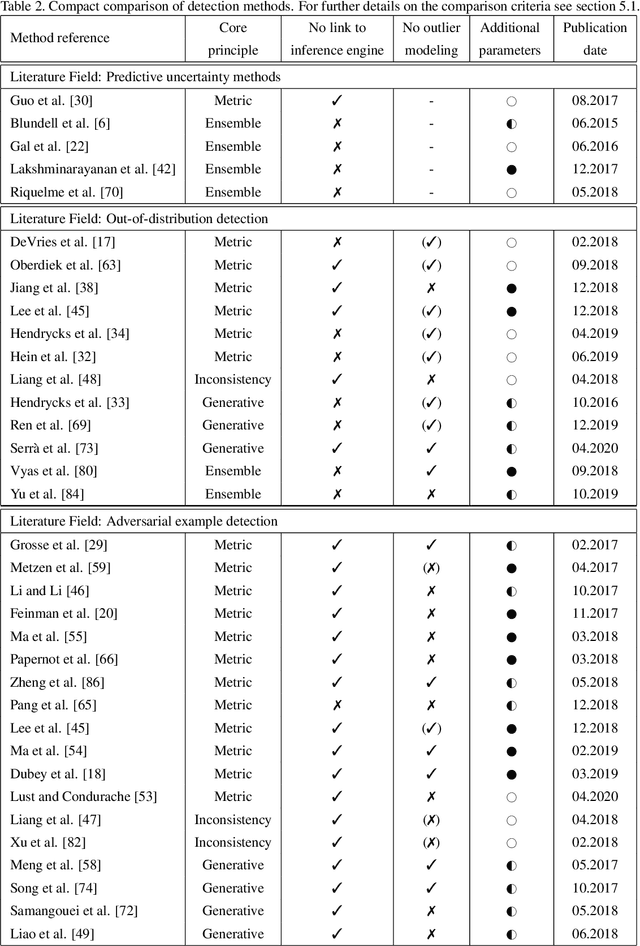
Deep Neural Networks (DNNs) achieve state-of-the-art performance on numerous applications. However, it is difficult to tell beforehand if a DNN receiving an input will deliver the correct output since their decision criteria are usually nontransparent. A DNN delivers the correct output if the input is within the area enclosed by its generalization envelope. In this case, the information contained in the input sample is processed reasonably by the network. It is of large practical importance to assess at inference time if a DNN generalizes correctly. Currently, the approaches to achieve this goal are investigated in different problem set-ups rather independently from one another, leading to three main research and literature fields: predictive uncertainty, out-of-distribution detection and adversarial example detection. This survey connects the three fields within the larger framework of investigating the generalization performance of machine learning methods and in particular DNNs. We underline the common ground, point at the most promising approaches and give a structured overview of the methods that provide at inference time means to establish if the current input is within the generalization envelope of a DNN.
Model Adaptation for Inverse Problems in Imaging
Nov 30, 2020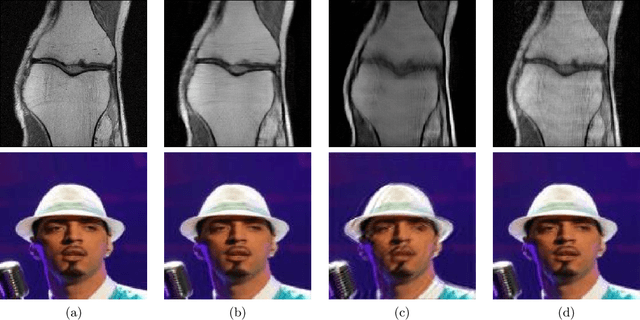

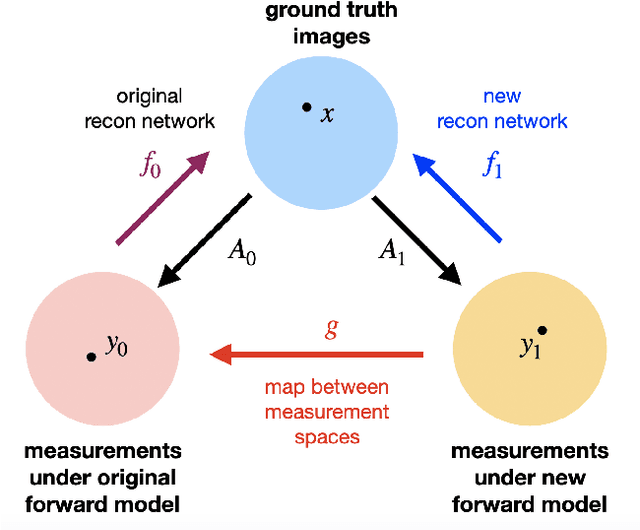

Deep neural networks have been applied successfully to a wide variety of inverse problems arising in computational imaging. These networks are typically trained using a forward model that describes the measurement process to be inverted, which is often incorporated directly into the network itself. However, these approaches lack robustness to drift of the forward model: if at test time the forward model varies (even slightly) from the one the network was trained for, the reconstruction performance can degrade substantially. Given a network trained to solve an initial inverse problem with a known forward model, we propose two novel procedures that adapt the network to a perturbed forward model, even without full knowledge of the perturbation. Our approaches do not require access to more labeled data (i.e., ground truth images), but only a small set of calibration measurements. We show these simple model adaptation procedures empirically achieve robustness to changes in the forward model in a variety of settings, including deblurring, super-resolution, and undersampled image reconstruction in magnetic resonance imaging.
The Ensemble Method for Thorax Diseases Classification
Aug 12, 2020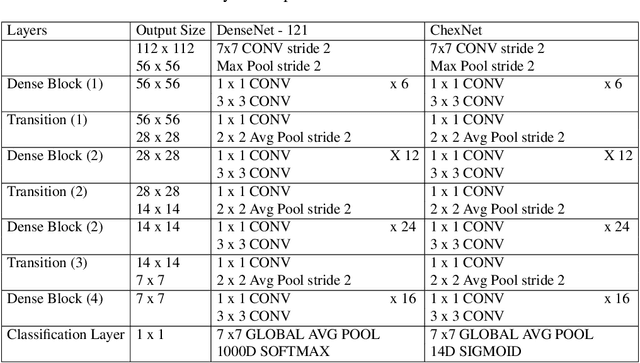
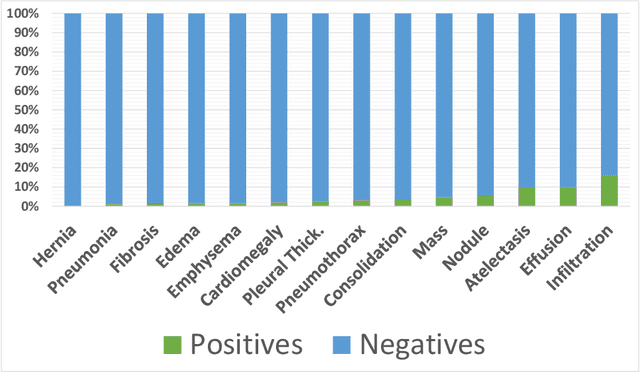
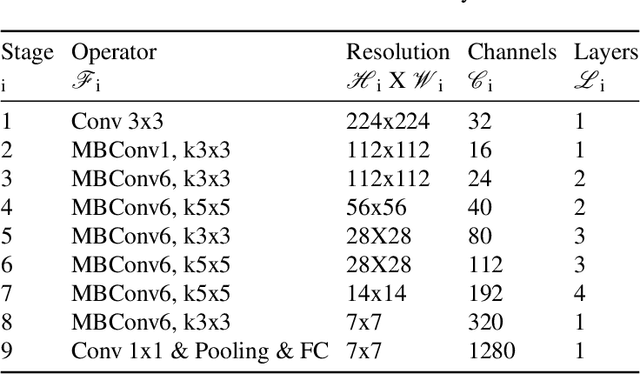
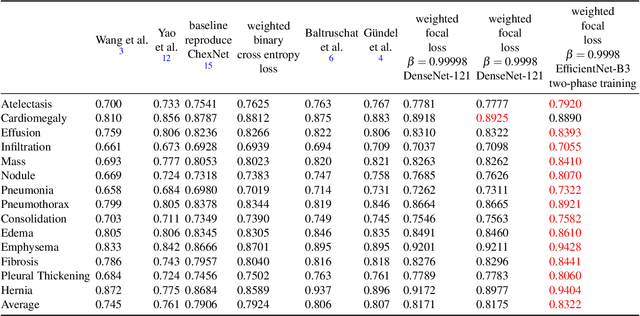
A common problem found in real-word medical image classification is the inherent imbalance of the positive and negative patterns in the dataset where positive patterns are usually rare. Moreover, in the classification of multiple classes with neural network, a training pattern is treated as a positive pattern in one output node and negative in all the remaining output nodes. In this paper, the weights of a training pattern in the loss function are designed based not only on the number of the training patterns in the class but also on the different nodes where one of them treats this training pattern as positive and the others treat it as negative. We propose a combined approach of weights calculation algorithm for deep network training and the training optimization from the state-of-the-art deep network architecture for thorax diseases classification problem. Experimental results on the Chest X-Ray image dataset demonstrate that this new weighting scheme improves classification performances, also the training optimization from the EfficientNet improves the performance furthermore. We compare the ensemble method with several performances from the previous study of thorax diseases classifications to provide the fair comparisons against the proposed method.
TAnoGAN: Time Series Anomaly Detection with Generative Adversarial Networks
Sep 25, 2020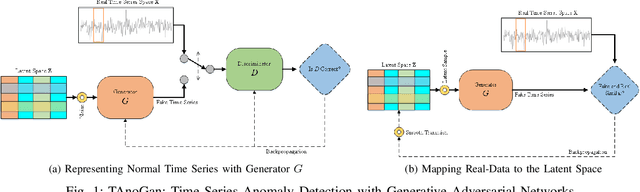
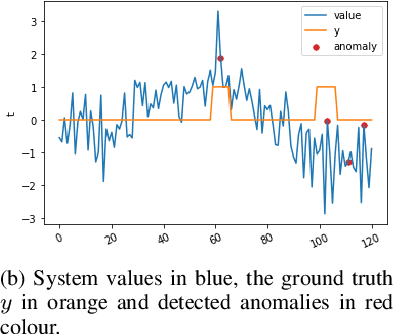
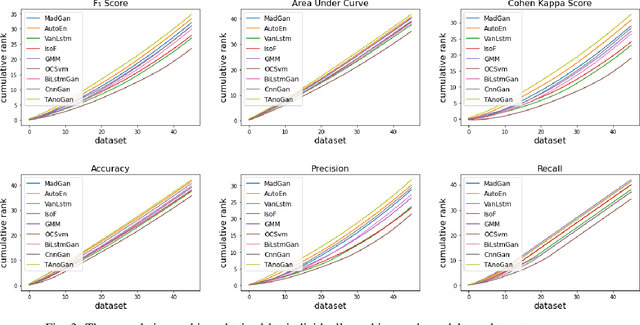
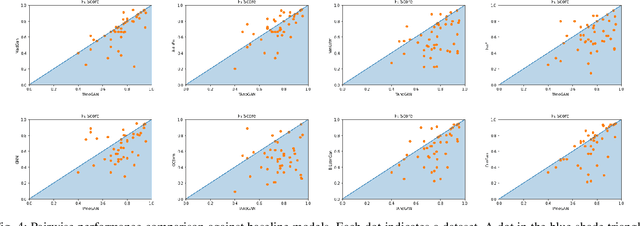
Anomaly detection in time series data is a significant problem faced in many application areas such as manufacturing, medical imaging and cyber-security. Recently, Generative Adversarial Networks (GAN) have gained attention for generation and anomaly detection in image domain. In this paper, we propose a novel GAN-based unsupervised method called TAnoGan for detecting anomalies in time series when a small number of data points are available. We evaluate TAnoGan with 46 real-world time series datasets that cover a variety of domains. Extensive experimental results show that TAnoGan performs better than traditional and neural network models.