 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Efficient Consensus Model based on Proximal Gradient Method applied to Convolutional Sparse Problems
Nov 19, 2020
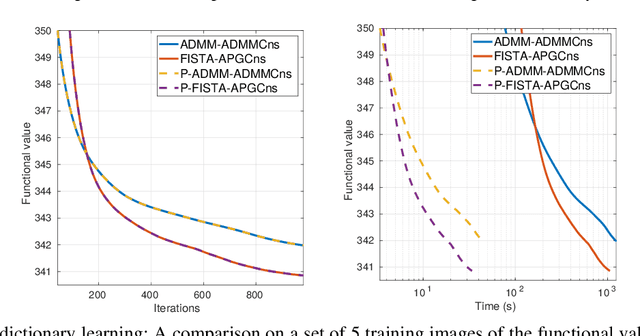
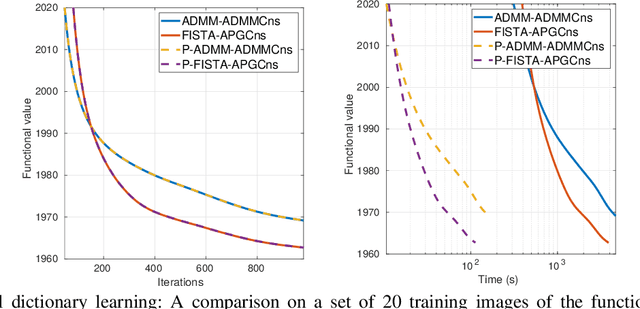
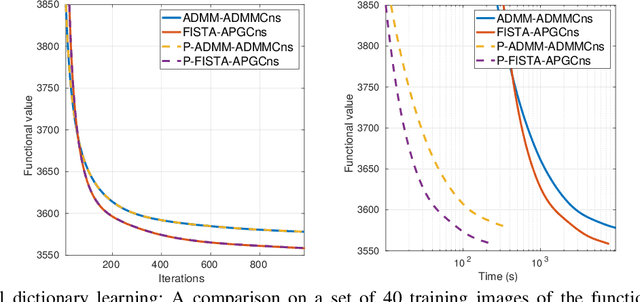
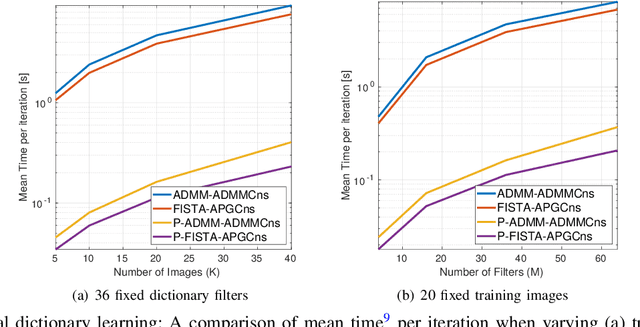
Convolutional sparse representation (CSR), shift-invariant model for inverse problems, has gained much attention in the fields of signal/image processing, machine learning and computer vision. The most challenging problems in CSR implies the minimization of a composite function of the form $min_x \sum_i f_i(x) + g(x)$, where a direct and low-cost solution can be difficult to achieve. However, it has been reported that semi-distributed formulations such as ADMM consensus can provide important computational benefits. In the present work, we derive and detail a thorough theoretical analysis of an efficient consensus algorithm based on proximal gradient (PG) approach. The effectiveness of the proposed algorithm with respect to its ADMM counterpart is primarily assessed in the classic convolutional dictionary learning problem. Furthermore, our consensus method, which is generically structured, can be used to solve other optimization problems, where a sum of convex functions with a regularization term share a single global variable. As an example, the proposed algorithm is also applied to another particular convolutional problem for the anomaly detection task.
On the Selective and Invariant Representation of DCNN for High-Resolution Remote Sensing Image Recognition
Aug 04, 2017
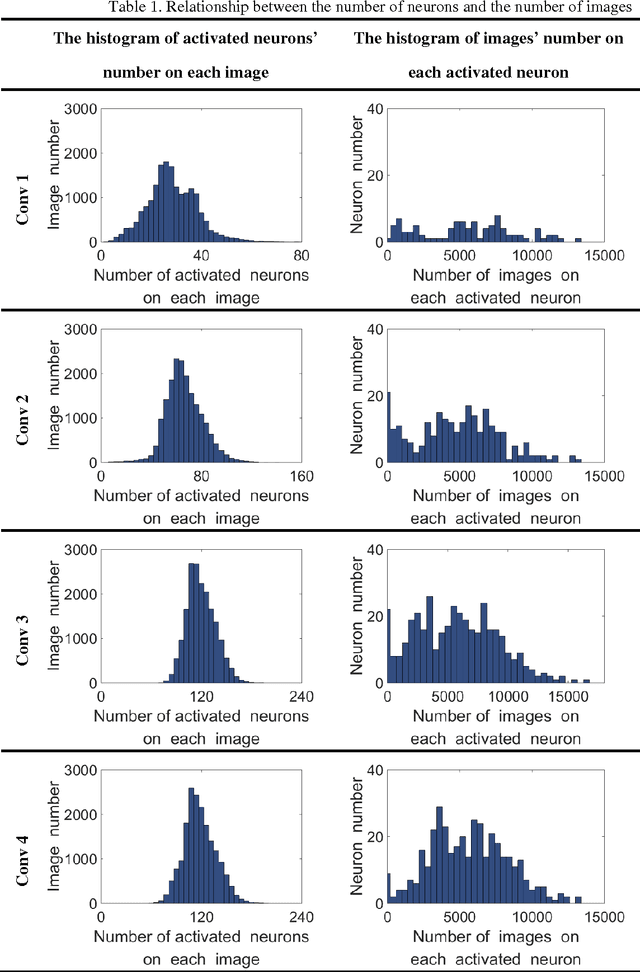
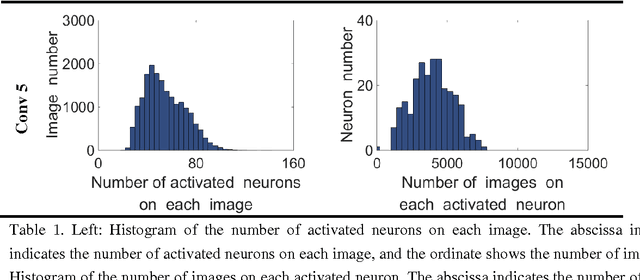
Human vision possesses strong invariance in image recognition. The cognitive capability of deep convolutional neural network (DCNN) is close to the human visual level because of hierarchical coding directly from raw image. Owing to its superiority in feature representation, DCNN has exhibited remarkable performance in scene recognition of high-resolution remote sensing (HRRS) images and classification of hyper-spectral remote sensing images. In-depth investigation is still essential for understanding why DCNN can accurately identify diverse ground objects via its effective feature representation. Thus, we train the deep neural network called AlexNet on our large scale remote sensing image recognition benchmark. At the neuron level in each convolution layer, we analyze the general properties of DCNN in HRRS image recognition by use of a framework of visual stimulation-characteristic response combined with feature coding-classification decoding. Specifically, we use histogram statistics, representational dissimilarity matrix, and class activation mapping to observe the selective and invariance representations of DCNN in HRRS image recognition. We argue that selective and invariance representations play important roles in remote sensing images tasks, such as classification, detection, and segment. Also selective and invariance representations are significant to design new DCNN liked models for analyzing and understanding remote sensing images.
Kaleidoscope: An Efficient, Learnable Representation For All Structured Linear Maps
Dec 29, 2020

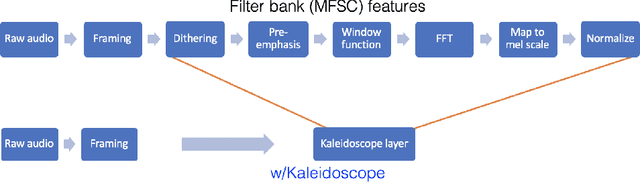

Modern neural network architectures use structured linear transformations, such as low-rank matrices, sparse matrices, permutations, and the Fourier transform, to improve inference speed and reduce memory usage compared to general linear maps. However, choosing which of the myriad structured transformations to use (and its associated parameterization) is a laborious task that requires trading off speed, space, and accuracy. We consider a different approach: we introduce a family of matrices called kaleidoscope matrices (K-matrices) that provably capture any structured matrix with near-optimal space (parameter) and time (arithmetic operation) complexity. We empirically validate that K-matrices can be automatically learned within end-to-end pipelines to replace hand-crafted procedures, in order to improve model quality. For example, replacing channel shuffles in ShuffleNet improves classification accuracy on ImageNet by up to 5%. K-matrices can also simplify hand-engineered pipelines -- we replace filter bank feature computation in speech data preprocessing with a learnable kaleidoscope layer, resulting in only 0.4% loss in accuracy on the TIMIT speech recognition task. In addition, K-matrices can capture latent structure in models: for a challenging permuted image classification task, a K-matrix based representation of permutations is able to learn the right latent structure and improves accuracy of a downstream convolutional model by over 9%. We provide a practically efficient implementation of our approach, and use K-matrices in a Transformer network to attain 36% faster end-to-end inference speed on a language translation task.
Parrot: Data-Driven Behavioral Priors for Reinforcement Learning
Nov 19, 2020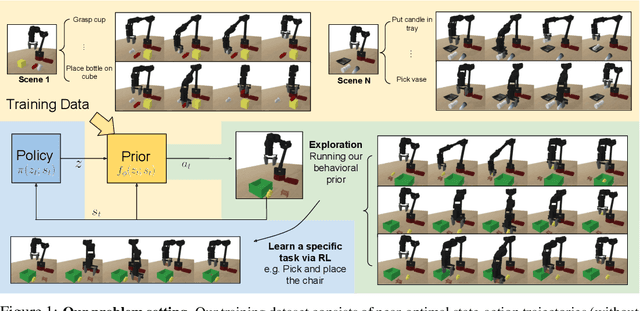
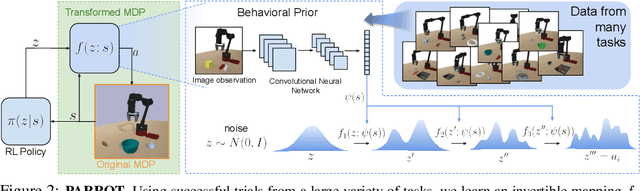
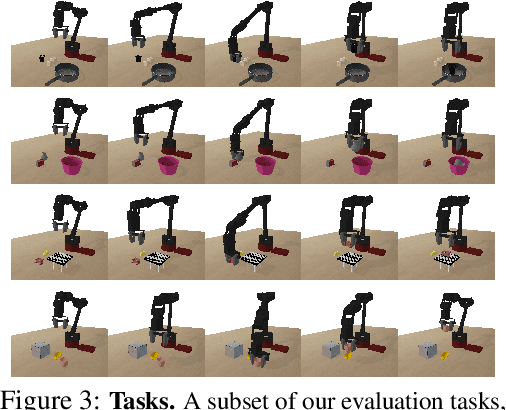

Reinforcement learning provides a general framework for flexible decision making and control, but requires extensive data collection for each new task that an agent needs to learn. In other machine learning fields, such as natural language processing or computer vision, pre-training on large, previously collected datasets to bootstrap learning for new tasks has emerged as a powerful paradigm to reduce data requirements when learning a new task. In this paper, we ask the following question: how can we enable similarly useful pre-training for RL agents? We propose a method for pre-training behavioral priors that can capture complex input-output relationships observed in successful trials from a wide range of previously seen tasks, and we show how this learned prior can be used for rapidly learning new tasks without impeding the RL agent's ability to try out novel behaviors. We demonstrate the effectiveness of our approach in challenging robotic manipulation domains involving image observations and sparse reward functions, where our method outperforms prior works by a substantial margin.
Revisiting Unsupervised Meta-Learning: Amplifying or Compensating for the Characteristics of Few-Shot Tasks
Dec 01, 2020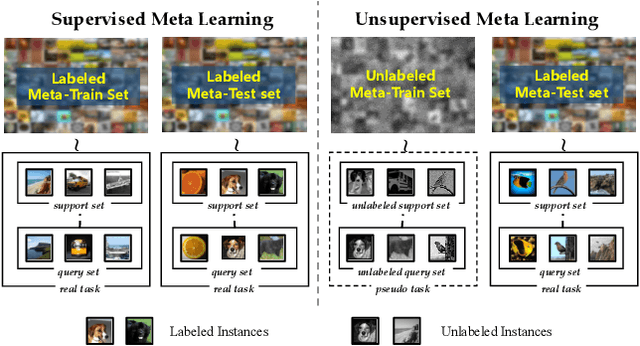
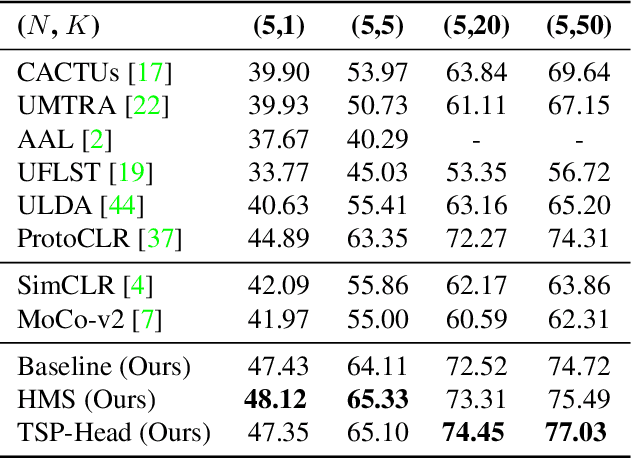
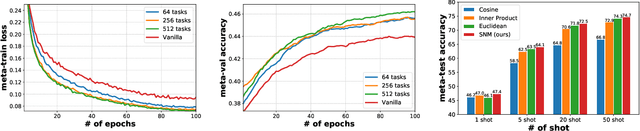
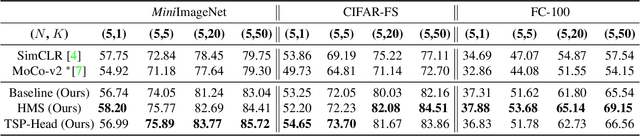
Meta-learning becomes a practical approach towards few-shot image classification, where a visual recognition system is constructed with limited annotated data. Inductive bias such as embedding is learned from a base class set with ample labeled examples and then generalizes to few-shot tasks with novel classes. Surprisingly, we find that the base class set labels are not necessary, and discriminative embeddings could be meta-learned in an unsupervised manner. Comprehensive analyses indicate two modifications -- the semi-normalized distance metric and the sufficient sampling -- improves unsupervised meta-learning (UML) significantly. Based on the modified baseline, we further amplify or compensate for the characteristic of tasks when training a UML model. First, mixed embeddings are incorporated to increase the difficulty of few-shot tasks. Next, we utilize a task-specific embedding transformation to deal with the specific properties among tasks, maintaining the generalization ability into the vanilla embeddings. Experiments on few-shot learning benchmarks verify that our approaches outperform previous UML methods by a 4-10% performance gap, and embeddings learned with our UML achieve comparable or even better performance than its supervised variants.
ViBE: A Tool for Measuring and Mitigating Bias in Image Datasets
Apr 16, 2020
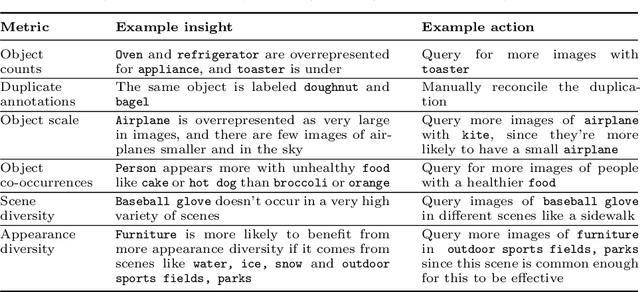

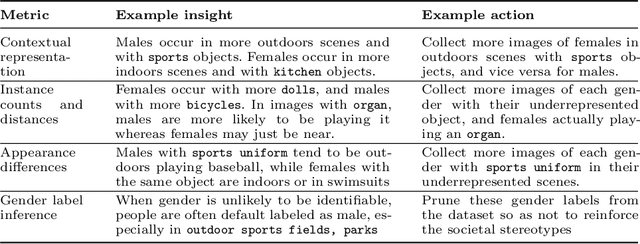
Machine learning models are known to perpetuate the biases present in the data, but oftentimes these biases aren't known until after the models are deployed. We present the Visual Bias Extraction (ViBE) Tool that assists in the investigation of a visual dataset, surfacing potential dataset biases along three dimensions: (1) object-based, (2) gender-based, and (3) geography-based. Object-based biases relate to things like size, context, or diversity of object representation in the dataset; gender-based metrics aim to reveal the stereotypical portrayal of people of different genders within the dataset, with future iterations of our tool extending the analysis to additional axes of identity; geography-based analysis considers the representation of different geographic locations. Our tool is designed to shed light on the dataset along these three axes, allowing both dataset creators and users to gain a better understanding of what exactly is portrayed in their dataset. The responsibility then lies with the tool user to determine which of the revealed biases may be problematic, taking into account the cultural and historical context, as this is difficult to determine automatically. Nevertheless, the tool also provides actionable insights that may be helpful for mitigating the revealed concerns. Overall, our work allows for the machine learning bias problem to be addressed early in the pipeline at the dataset stage. ViBE is available at https://github.com/princetonvisualai/vibe-tool.
Non-Convex Weighted Lp Minimization based Group Sparse Representation Framework for Image Denoising
May 23, 2017

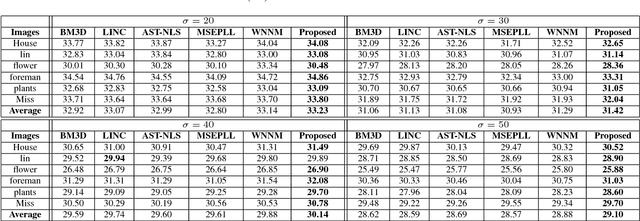
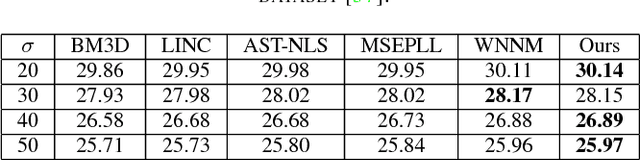
Nonlocal image representation or group sparsity has attracted considerable interest in various low-level vision tasks and has led to several state-of-the-art image denoising techniques, such as BM3D, LSSC. In the past, convex optimization with sparsity-promoting convex regularization was usually regarded as a standard scheme for estimating sparse signals in noise. However, using convex regularization can not still obtain the correct sparsity solution under some practical problems including image inverse problems. In this paper we propose a non-convex weighted $\ell_p$ minimization based group sparse representation (GSR) framework for image denoising. To make the proposed scheme tractable and robust, the generalized soft-thresholding (GST) algorithm is adopted to solve the non-convex $\ell_p$ minimization problem. In addition, to improve the accuracy of the nonlocal similar patches selection, an adaptive patch search (APS) scheme is proposed. Experimental results have demonstrated that the proposed approach not only outperforms many state-of-the-art denoising methods such as BM3D and WNNM, but also results in a competitive speed.
Understanding when spatial transformer networks do not support invariance, and what to do about it
May 04, 2020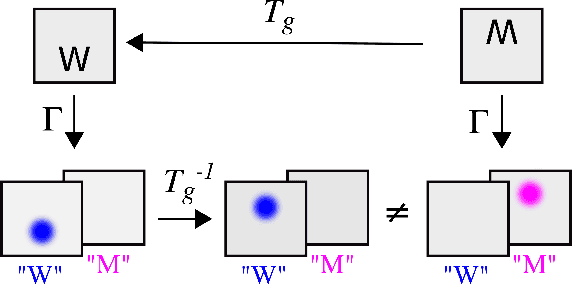
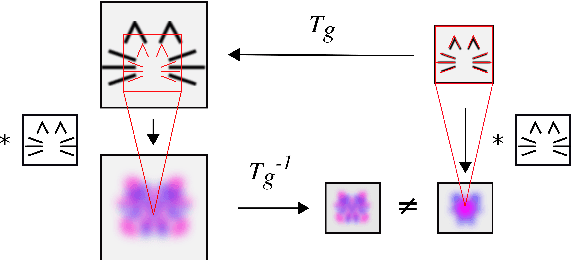
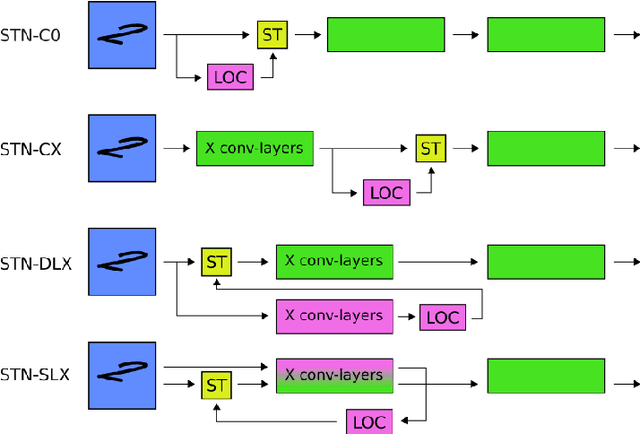
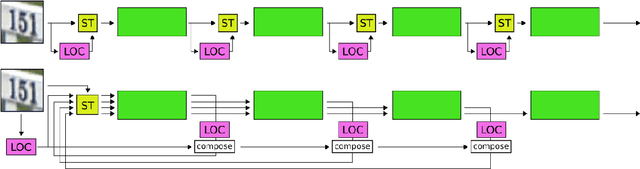
Spatial transformer networks (STNs) were designed to enable convolutional neural networks (CNNs) to learn invariance to image transformations. STNs were originally proposed to transform CNN feature maps as well as input images. This enables the use of more complex features when predicting transformation parameters. However, since STNs perform a purely spatial transformation, they do not, in the general case, have the ability to align the feature maps of a transformed image with those of its original. STNs are therefore unable to support invariance when transforming CNN feature maps. We present a simple proof for this and study the practical implications, showing that this inability is coupled with decreased classification accuracy. We therefore investigate alternative STN architectures that make use of complex features. We find that while deeper localization networks are difficult to train, localization networks that share parameters with the classification network remain stable as they grow deeper, which allows for higher classification accuracy on difficult datasets. Finally, we explore the interaction between localization network complexity and iterative image alignment.
A general approach to compute the relevance of middle-level input features
Oct 16, 2020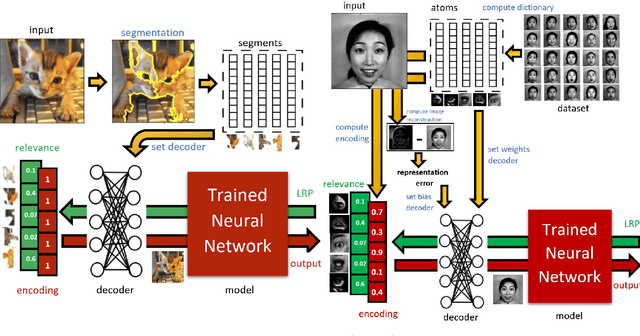


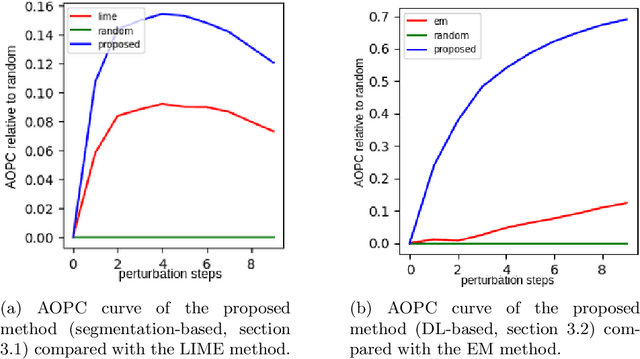
This work proposes a novel general framework, in the context of eXplainable Artificial Intelligence (XAI), to construct explanations for the behaviour of Machine Learning (ML) models in terms of middle-level features. One can isolate two different ways to provide explanations in the context of XAI: low and middle-level explanations. Middle-level explanations have been introduced for alleviating some deficiencies of low-level explanations such as, in the context of image classification, the fact that human users are left with a significant interpretive burden: starting from low-level explanations, one has to identify properties of the overall input that are perceptually salient for the human visual system. However, a general approach to correctly evaluate the elements of middle-level explanations with respect ML model responses has never been proposed in the literature.
Multiclass Yeast Segmentation in Microstructured Environments with Deep Learning
Nov 19, 2020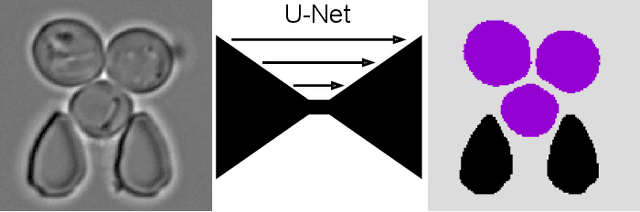
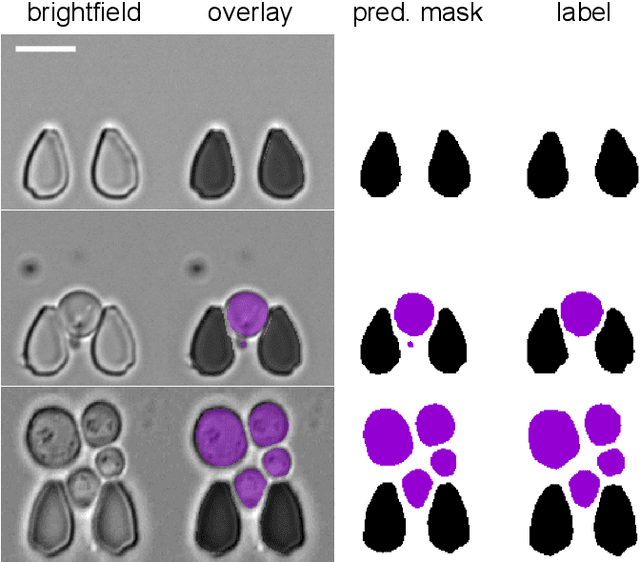
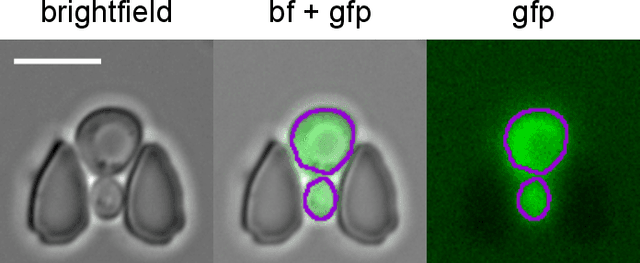

Cell segmentation is a major bottleneck in extracting quantitative single-cell information from microscopy data. The challenge is exasperated in the setting of microstructured environments. While deep learning approaches have proven useful for general cell segmentation tasks, existing segmentation tools for the yeast-microstructure setting rely on traditional machine learning approaches. Here we present convolutional neural networks trained for multiclass segmenting of individual yeast cells and discerning these from cell-similar microstructures. We give an overview of the datasets recorded for training, validating and testing the networks, as well as a typical use-case. We showcase the method's contribution to segmenting yeast in microstructured environments with a typical synthetic biology application in mind. The models achieve robust segmentation results, outperforming the previous state-of-the-art in both accuracy and speed. The combination of fast and accurate segmentation is not only beneficial for a posteriori data processing, it also makes online monitoring of thousands of trapped cells or closed-loop optimal experimental design feasible from an image processing perspective.