 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A general approach to compute the relevance of middle-level input features
Oct 16, 2020
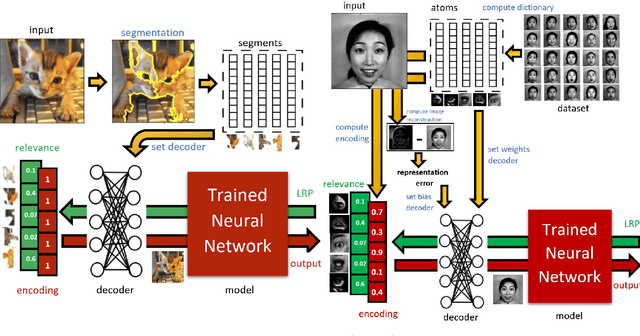


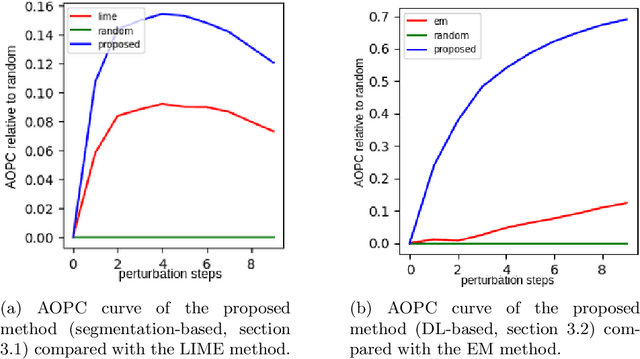
This work proposes a novel general framework, in the context of eXplainable Artificial Intelligence (XAI), to construct explanations for the behaviour of Machine Learning (ML) models in terms of middle-level features. One can isolate two different ways to provide explanations in the context of XAI: low and middle-level explanations. Middle-level explanations have been introduced for alleviating some deficiencies of low-level explanations such as, in the context of image classification, the fact that human users are left with a significant interpretive burden: starting from low-level explanations, one has to identify properties of the overall input that are perceptually salient for the human visual system. However, a general approach to correctly evaluate the elements of middle-level explanations with respect ML model responses has never been proposed in the literature.
Three-Filters-to-Normal: An Accurate and Ultrafast Surface Normal Estimator
May 17, 2020
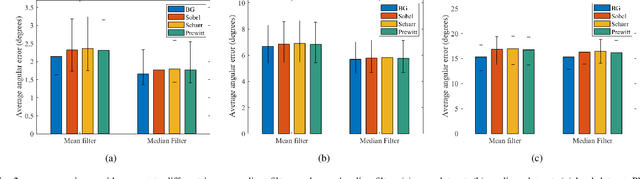
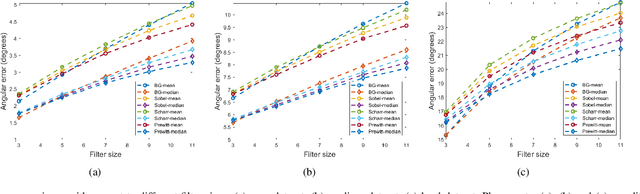
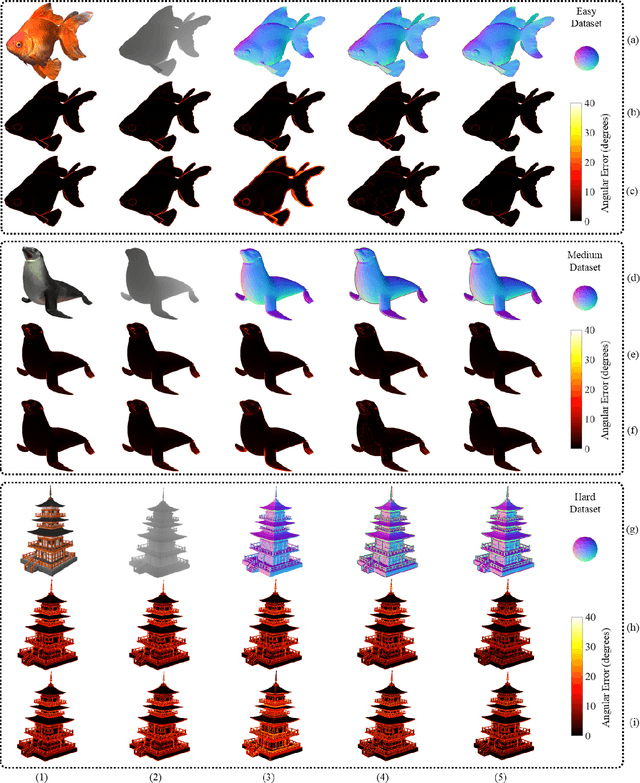
Over the past decade, significant efforts have been made to improve the trade-off between speed and accuracy of surface normal estimators (SNEs). This paper introduces an accurate and ultrafast SNE for structured range data. The proposed approach computes surface normals by simply performing three filtering operations, namely, two image gradient filters (in horizontal and vertical directions, respectively) and a mean/median filter, on an inverse depth image or a disparity image. Despite the simplicity of the method, no similar method already exists in the literature. In our experiments, we created three large-scale synthetic datasets (easy, medium and hard) using 24 3-dimensional (3D) mesh models. Each mesh model is used to generate 1800--2500 pairs of 480x640 pixel depth images and the corresponding surface normal ground truth from different views. The average angular errors with respect to the easy, medium and hard datasets are 1.6 degrees, 5.6 degrees and 15.3 degrees, respectively. Our C++ and CUDA implementations achieve a processing speed of over 260 Hz and 21 kHz, respectively. Our proposed SNE achieves a better overall performance than all other existing computer vision-based SNEs. Our datasets and source code are publicly available at: sites.google.com/view/3f2n.
Deep Learning on Point Clouds for False Positive Reduction at Nodule Detection in Chest CT Scans
May 07, 2020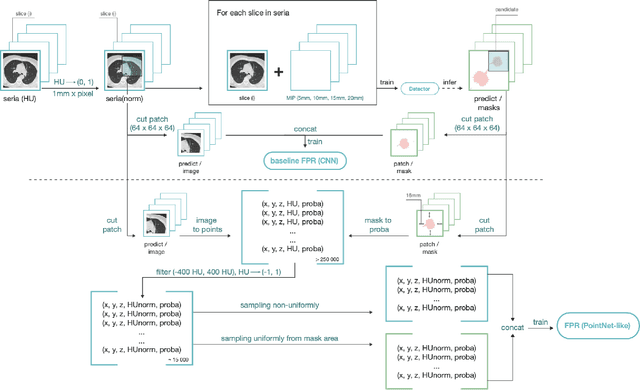

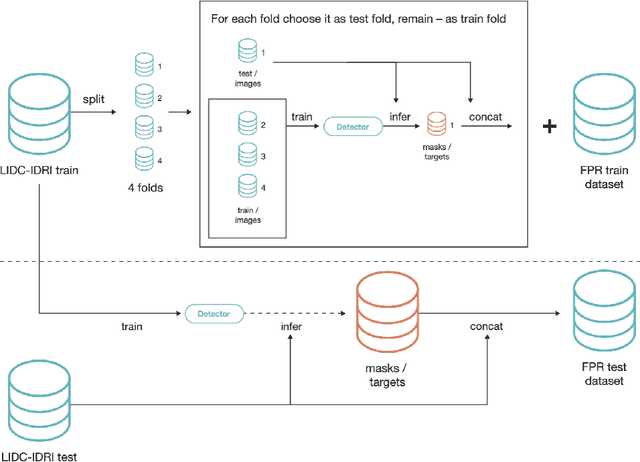
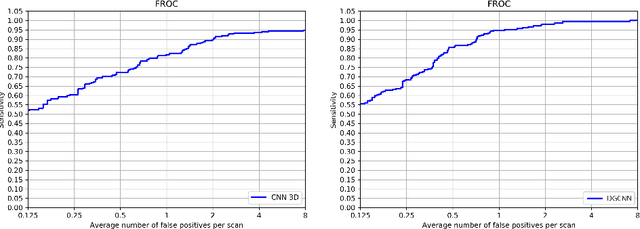
The paper focuses on a novel approach for false-positive reduction (FPR) of nodule candidates in Computer-aided detection (CADe) system after suspicious lesions proposing stage. Unlike common decisions in medical image analysis, the proposed approach considers input data not as 2d or 3d image, but as a point cloud and uses deep learning models for point clouds. We found out that models for point clouds require less memory and are faster on both training and inference than traditional CNN 3D, achieves better performance and does not impose restrictions on the size of the input image, thereby the size of the nodule candidate. We propose an algorithm for transforming 3d CT scan data to point cloud. In some cases, the volume of the nodule candidate can be much smaller than the surrounding context, for example, in the case of subpleural localization of the nodule. Therefore, we developed an algorithm for sampling points from a point cloud constructed from a 3D image of the candidate region. The algorithm guarantees to capture both context and candidate information as part of the point cloud of the nodule candidate. An experiment with creating a dataset from an open LIDC-IDRI database for a feature of the FPR task was accurately designed, set up and described in detail. The data augmentation technique was applied to avoid overfitting and as an upsampling method. Experiments are conducted with PointNet, PointNet++ and DGCNN. We show that the proposed approach outperforms baseline CNN 3D models and demonstrates 85.98 FROC versus 77.26 FROC for baseline models.
FPCC-Net: Fast Point Cloud Clustering for Instance Segmentation
Dec 29, 2020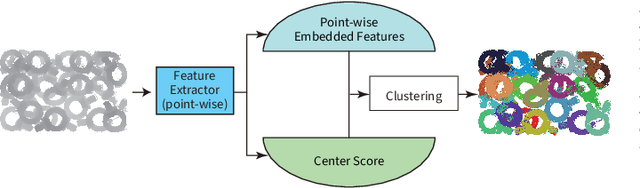

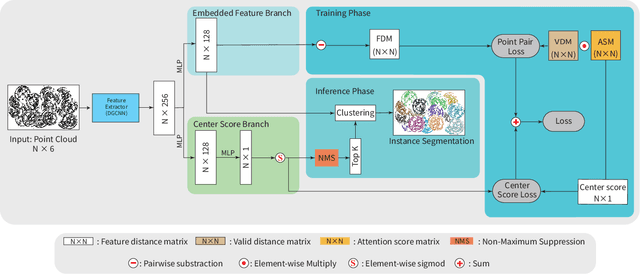
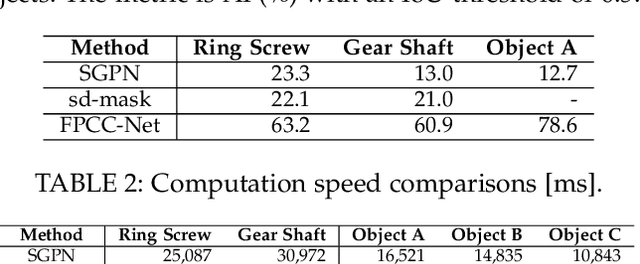
Instance segmentation is an important pre-processing task in numerous real-world applications, such as robotics, autonomous vehicles, and human-computer interaction. However, there has been little research on 3D point cloud instance segmentation of bin-picking scenes in which multiple objects of the same class are stacked together. Compared with the rapid development of deep learning for two-dimensional (2D) image tasks, deep learning-based 3D point cloud segmentation still has a lot of room for development. In such a situation, distinguishing a large number of occluded objects of the same class is a highly challenging problem. In a usual bin-picking scene, an object model is known and the number of object type is one. Thus, the semantic information can be ignored; instead, the focus is put on the segmentation of instances. Based on this task requirement, we propose a network (FPCC-Net) that infers feature centers of each instance and then clusters the remaining points to the closest feature center in feature embedding space. FPCC-Net includes two subnets, one for inferring the feature centers for clustering and the other for describing features of each point. The proposed method is compared with existing 3D point clouds and 2D segmentation methods in some bin-picking scenes. It is shown that FPCC-Net outperforms SGPN by about 40\% average precision (AP) and can process about 60,000 points in about 0.8[s]
Logic Tensor Networks for Semantic Image Interpretation
May 24, 2017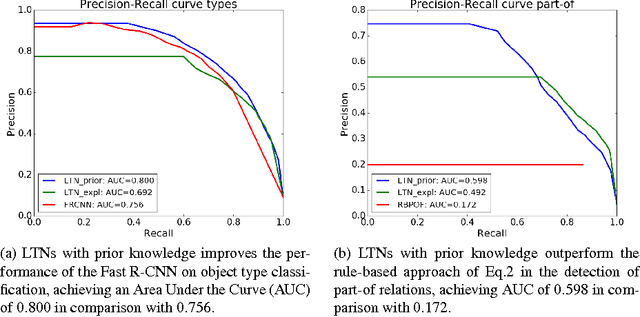
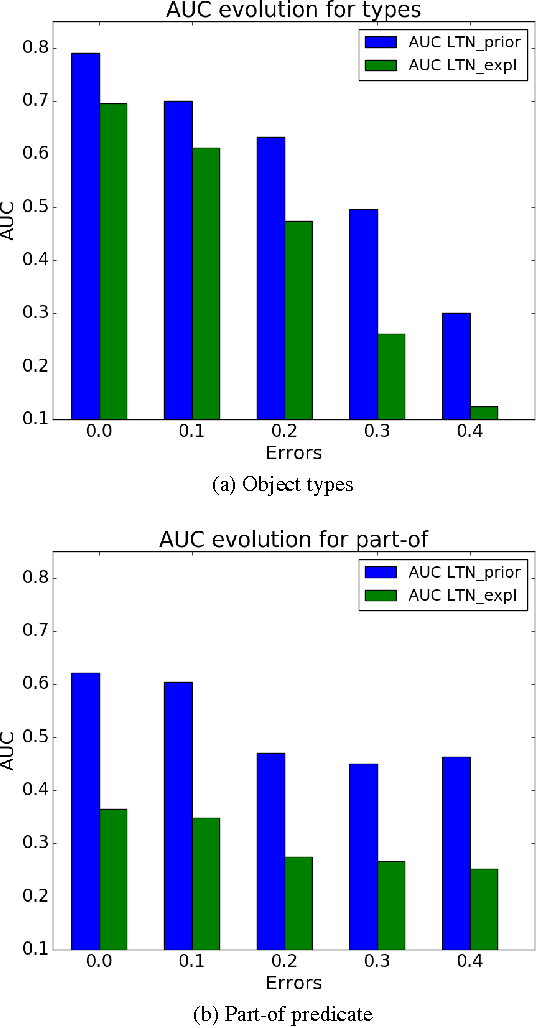
Semantic Image Interpretation (SII) is the task of extracting structured semantic descriptions from images. It is widely agreed that the combined use of visual data and background knowledge is of great importance for SII. Recently, Statistical Relational Learning (SRL) approaches have been developed for reasoning under uncertainty and learning in the presence of data and rich knowledge. Logic Tensor Networks (LTNs) are an SRL framework which integrates neural networks with first-order fuzzy logic to allow (i) efficient learning from noisy data in the presence of logical constraints, and (ii) reasoning with logical formulas describing general properties of the data. In this paper, we develop and apply LTNs to two of the main tasks of SII, namely, the classification of an image's bounding boxes and the detection of the relevant part-of relations between objects. To the best of our knowledge, this is the first successful application of SRL to such SII tasks. The proposed approach is evaluated on a standard image processing benchmark. Experiments show that the use of background knowledge in the form of logical constraints can improve the performance of purely data-driven approaches, including the state-of-the-art Fast Region-based Convolutional Neural Networks (Fast R-CNN). Moreover, we show that the use of logical background knowledge adds robustness to the learning system when errors are present in the labels of the training data.
Aesthetics, Personalization and Recommendation: A survey on Deep Learning in Fashion
Jan 20, 2021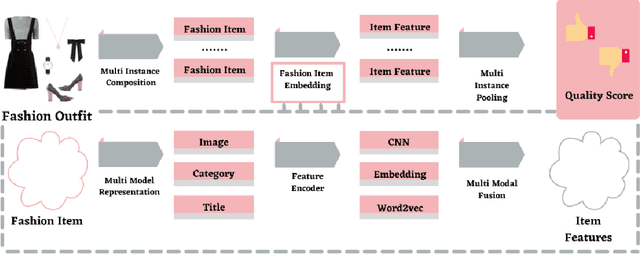


Machine learning is completely changing the trends in the fashion industry. From big to small every brand is using machine learning techniques in order to improve their revenue, increase customers and stay ahead of the trend. People are into fashion and they want to know what looks best and how they can improve their style and elevate their personality. Using Deep learning technology and infusing it with Computer Vision techniques one can do so by utilizing Brain-inspired Deep Networks, and engaging into Neuroaesthetics, working with GANs and Training them, playing around with Unstructured Data,and infusing the transformer architecture are just some highlights which can be touched with the Fashion domain. Its all about designing a system that can tell us information regarding the fashion aspect that can come in handy with the ever growing demand. Personalization is a big factor that impacts the spending choices of customers.The survey also shows remarkable approaches that encroach the subject of achieving that by divulging deep into how visual data can be interpreted and leveraged into different models and approaches. Aesthetics play a vital role in clothing recommendation as users' decision depends largely on whether the clothing is in line with their aesthetics, however the conventional image features cannot portray this directly. For that the survey also highlights remarkable models like tensor factorization model, conditional random field model among others to cater the need to acknowledge aesthetics as an important factor in Apparel recommendation.These AI inspired deep models can pinpoint exactly which certain style resonates best with their customers and they can have an understanding of how the new designs will set in with the community. With AI and machine learning your businesses can stay ahead of the fashion trends.
PULSE: Self-Supervised Photo Upsampling via Latent Space Exploration of Generative Models
Mar 08, 2020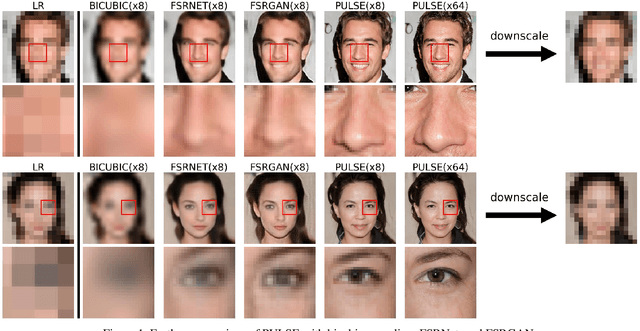
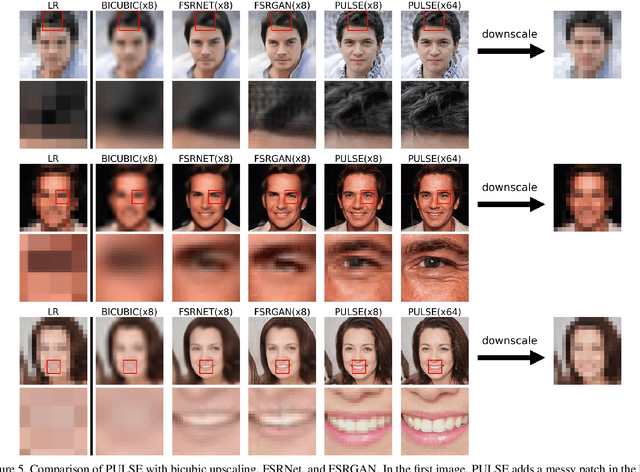


The primary aim of single-image super-resolution is to construct a high-resolution (HR) image from a corresponding low-resolution (LR) input. In previous approaches, which have generally been supervised, the training objective typically measures a pixel-wise average distance between the super-resolved (SR) and HR images. Optimizing such metrics often leads to blurring, especially in high variance (detailed) regions. We propose an alternative formulation of the super-resolution problem based on creating realistic SR images that downscale correctly. We present a novel super-resolution algorithm addressing this problem, PULSE (Photo Upsampling via Latent Space Exploration), which generates high-resolution, realistic images at resolutions previously unseen in the literature. It accomplishes this in an entirely self-supervised fashion and is not confined to a specific degradation operator used during training, unlike previous methods (which require training on databases of LR-HR image pairs for supervised learning). Instead of starting with the LR image and slowly adding detail, PULSE traverses the high-resolution natural image manifold, searching for images that downscale to the original LR image. This is formalized through the "downscaling loss," which guides exploration through the latent space of a generative model. By leveraging properties of high-dimensional Gaussians, we restrict the search space to guarantee that our outputs are realistic. PULSE thereby generates super-resolved images that both are realistic and downscale correctly. We show extensive experimental results demonstrating the efficacy of our approach in the domain of face super-resolution (also known as face hallucination). Our method outperforms state-of-the-art methods in perceptual quality at higher resolutions and scale factors than previously possible.
Universal Adversarial Perturbations: A Survey
May 16, 2020
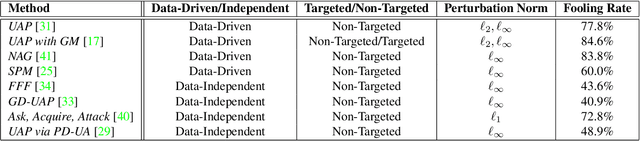


Over the past decade, Deep Learning has emerged as a useful and efficient tool to solve a wide variety of complex learning problems ranging from image classification to human pose estimation, which is challenging to solve using statistical machine learning algorithms. However, despite their superior performance, deep neural networks are susceptible to adversarial perturbations, which can cause the network's prediction to change without making perceptible changes to the input image, thus creating severe security issues at the time of deployment of such systems. Recent works have shown the existence of Universal Adversarial Perturbations, which, when added to any image in a dataset, misclassifies it when passed through a target model. Such perturbations are more practical to deploy since there is minimal computation done during the actual attack. Several techniques have also been proposed to defend the neural networks against these perturbations. In this paper, we attempt to provide a detailed discussion on the various data-driven and data-independent methods for generating universal perturbations, along with measures to defend against such perturbations. We also cover the applications of such universal perturbations in various deep learning tasks.
Anchor-Based Spatial-Temporal Attention Convolutional Networks for Dynamic 3D Point Cloud Sequences
Dec 20, 2020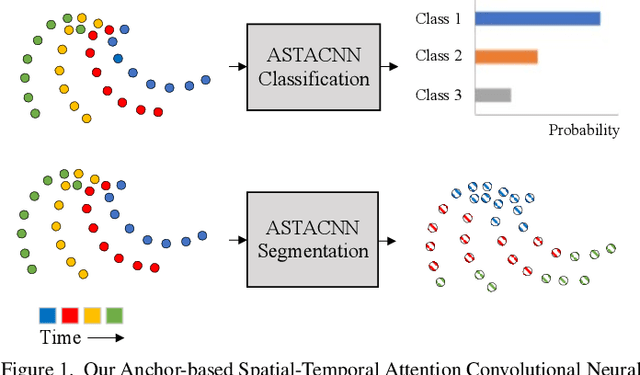
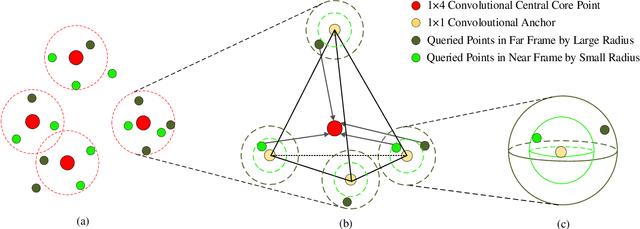
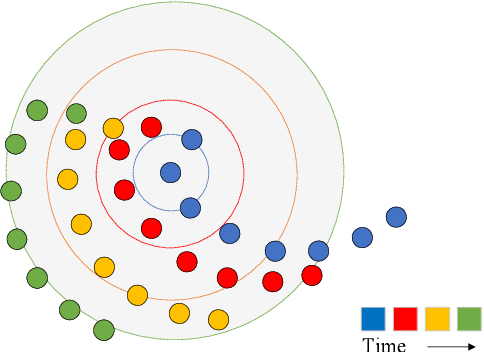
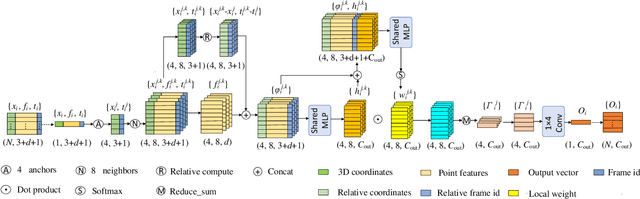
Recently, learning based methods for the robot perception from the image or video have much developed, but deep learning methods for dynamic 3D point cloud sequences are underexplored. With the widespread application of 3D sensors such as LiDAR and depth camera, efficient and accurate perception of the 3D environment from 3D sequence data is pivotal to autonomous driving and service robots. An Anchor-based Spatial-Temporal Attention Convolution operation (ASTAConv) is proposed in this paper to process dynamic 3D point cloud sequences. The proposed convolution operation builds a regular receptive field around each point by setting several virtual anchors around each point. The features of neighborhood points are firstly aggregated to each anchor based on spatial-temporal attention mechanism. Then, anchor-based sparse 3D convolution is adopted to aggregate the features of these anchors to the core points. The proposed method makes better use of the structured information within the local region, and learn spatial-temporal embedding features from dynamic 3D point cloud sequences. Then Anchor-based Spatial-Temporal Attention Convolutional Neural Networks (ASTACNNs) are proposed for classification and segmentation tasks and are evaluated on action recognition and semantic segmentation tasks. The experimental results on MSRAction3D and Synthia datasets demonstrate that the higher accuracy can be achieved than the previous state-of-the-art method by our novel strategy of multi-frame fusion.
Key-Nets: Optical Transformation Convolutional Networks for Privacy Preserving Vision Sensors
Aug 11, 2020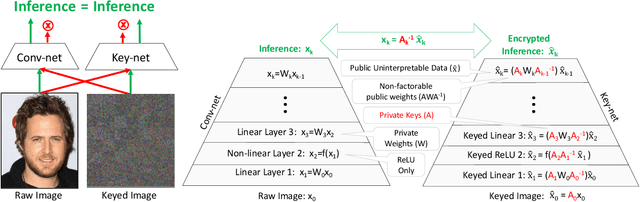
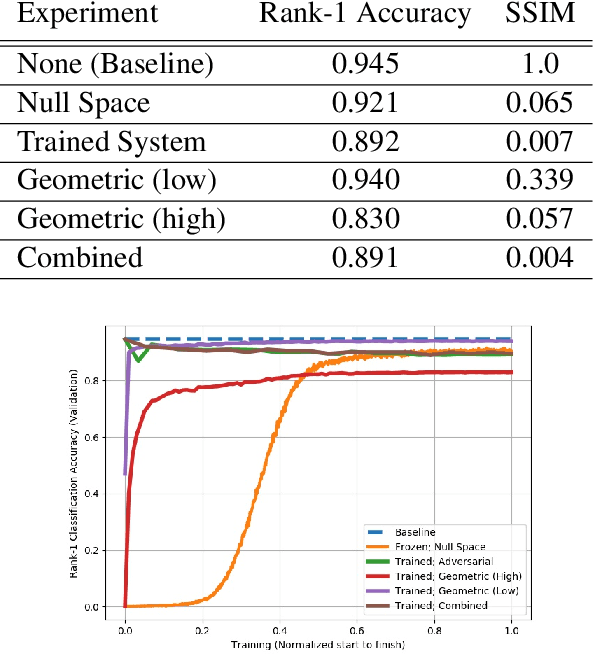

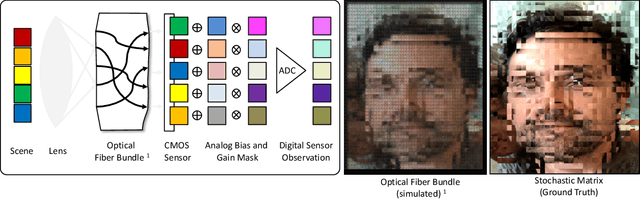
Modern cameras are not designed with computer vision or machine learning as the target application. There is a need for a new class of vision sensors that are privacy preserving by design, that do not leak private information and collect only the information necessary for a target machine learning task. In this paper, we introduce key-nets, which are convolutional networks paired with a custom vision sensor which applies an optical/analog transform such that the key-net can perform exact encrypted inference on this transformed image, but the image is not interpretable by a human or any other key-net. We provide five sufficient conditions for an optical transformation suitable for a key-net, and show that generalized stochastic matrices (e.g. scale, bias and fractional pixel shuffling) satisfy these conditions. We motivate the key-net by showing that without it there is a utility/privacy tradeoff for a network fine-tuned directly on optically transformed images for face identification and object detection. Finally, we show that a key-net is equivalent to homomorphic encryption using a Hill cipher, with an upper bound on memory and runtime that scales quadratically with a user specified privacy parameter. Therefore, the key-net is the first practical, efficient and privacy preserving vision sensor based on optical homomorphic encryption.