 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Efficient Consensus Model based on Proximal Gradient Method applied to Convolutional Sparse Problems
Nov 19, 2020
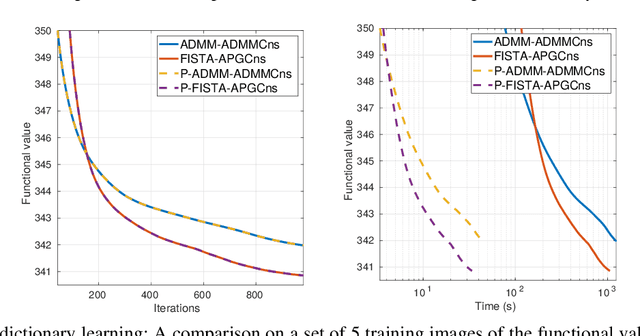
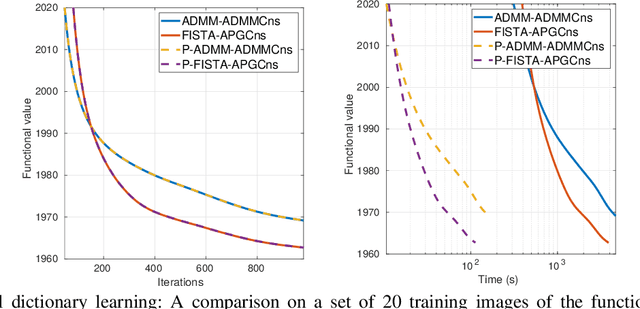
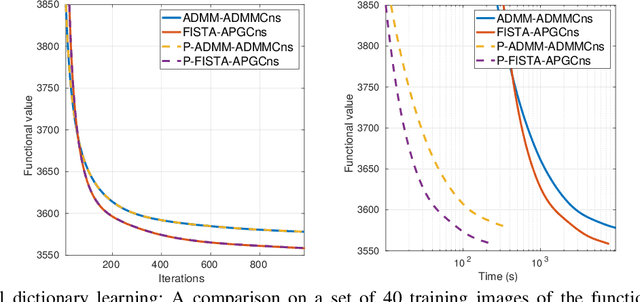
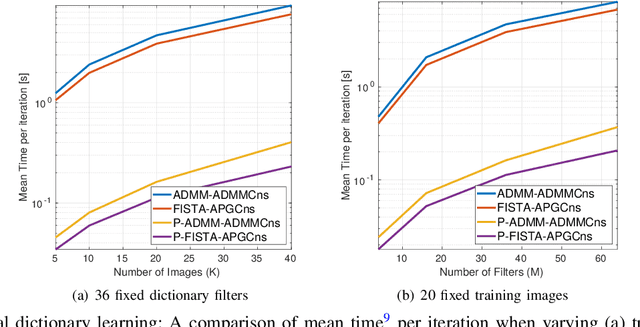
Convolutional sparse representation (CSR), shift-invariant model for inverse problems, has gained much attention in the fields of signal/image processing, machine learning and computer vision. The most challenging problems in CSR implies the minimization of a composite function of the form $min_x \sum_i f_i(x) + g(x)$, where a direct and low-cost solution can be difficult to achieve. However, it has been reported that semi-distributed formulations such as ADMM consensus can provide important computational benefits. In the present work, we derive and detail a thorough theoretical analysis of an efficient consensus algorithm based on proximal gradient (PG) approach. The effectiveness of the proposed algorithm with respect to its ADMM counterpart is primarily assessed in the classic convolutional dictionary learning problem. Furthermore, our consensus method, which is generically structured, can be used to solve other optimization problems, where a sum of convex functions with a regularization term share a single global variable. As an example, the proposed algorithm is also applied to another particular convolutional problem for the anomaly detection task.
Predictive Modeling of Anatomy with Genetic and Clinical Data
Oct 09, 2020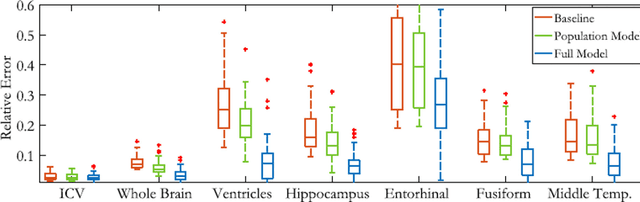
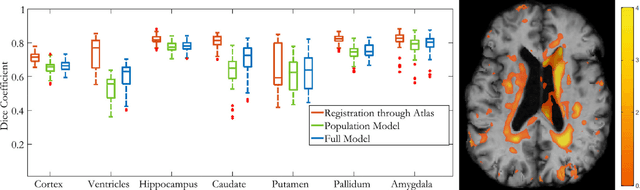
We present a semi-parametric generative model for predicting anatomy of a patient in subsequent scans following a single baseline image. Such predictive modeling promises to facilitate novel analyses in both voxel-level studies and longitudinal biomarker evaluation. We capture anatomical change through a combination of population-wide regression and a non-parametric model of the subject's health based on individual genetic and clinical indicators. In contrast to classical correlation and longitudinal analysis, we focus on predicting new observations from a single subject observation. We demonstrate prediction of follow-up anatomical scans in the ADNI cohort, and illustrate a novel analysis approach that compares a patient's scans to the predicted subject-specific healthy anatomical trajectory. The code is available at https://github.com/adalca/voxelorb.
Parrot: Data-Driven Behavioral Priors for Reinforcement Learning
Nov 19, 2020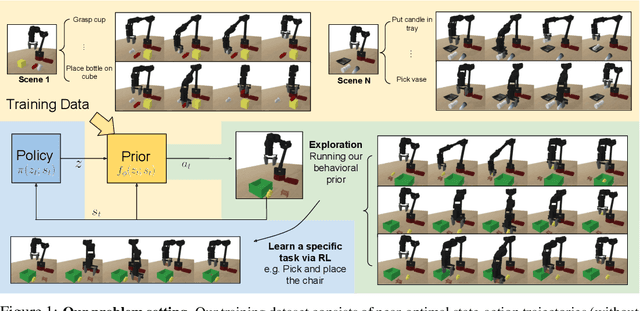
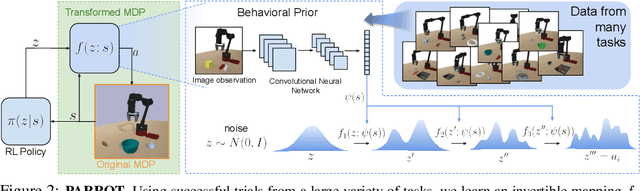
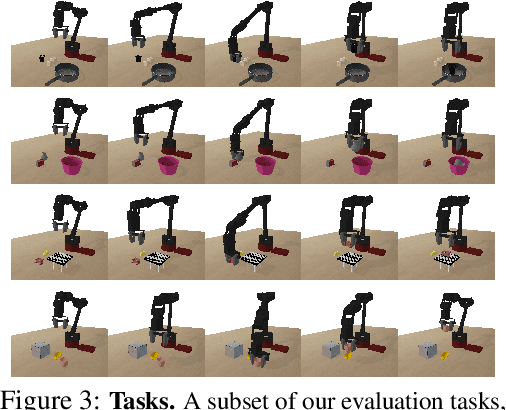

Reinforcement learning provides a general framework for flexible decision making and control, but requires extensive data collection for each new task that an agent needs to learn. In other machine learning fields, such as natural language processing or computer vision, pre-training on large, previously collected datasets to bootstrap learning for new tasks has emerged as a powerful paradigm to reduce data requirements when learning a new task. In this paper, we ask the following question: how can we enable similarly useful pre-training for RL agents? We propose a method for pre-training behavioral priors that can capture complex input-output relationships observed in successful trials from a wide range of previously seen tasks, and we show how this learned prior can be used for rapidly learning new tasks without impeding the RL agent's ability to try out novel behaviors. We demonstrate the effectiveness of our approach in challenging robotic manipulation domains involving image observations and sparse reward functions, where our method outperforms prior works by a substantial margin.
Cross-modal Deep Face Normals with Deactivable Skip Connections
Mar 30, 2020
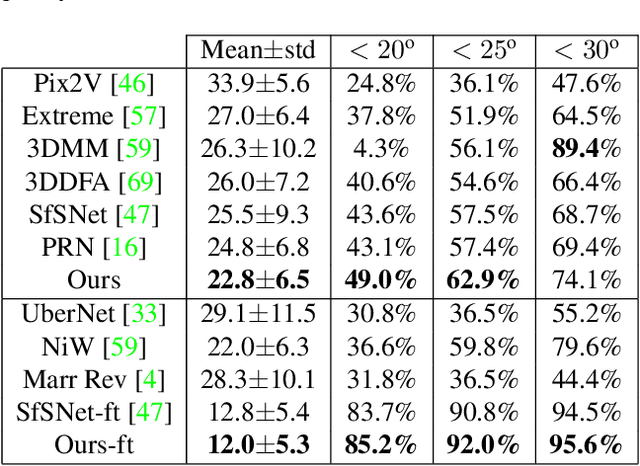
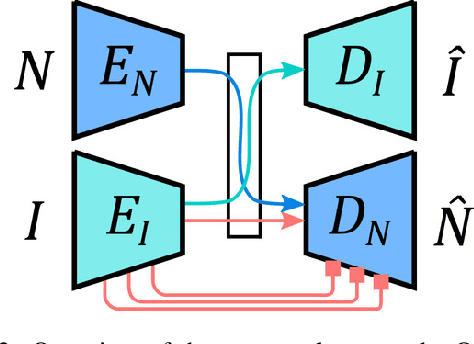
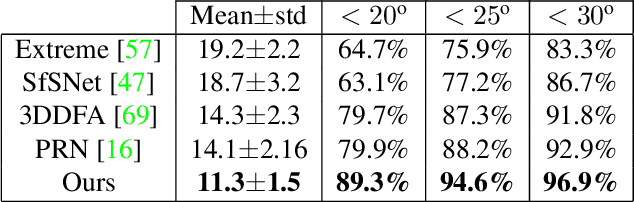
We present an approach for estimating surface normals from in-the-wild color images of faces. While data-driven strategies have been proposed for single face images, limited available ground truth data makes this problem difficult. To alleviate this issue, we propose a method that can leverage all available image and normal data, whether paired or not, thanks to a novel cross-modal learning architecture. In particular, we enable additional training with single modality data, either color or normal, by using two encoder-decoder networks with a shared latent space. The proposed architecture also enables face details to be transferred between the image and normal domains, given paired data, through skip connections between the image encoder and normal decoder. Core to our approach is a novel module that we call deactivable skip connections, which allows integrating both the auto-encoded and image-to-normal branches within the same architecture that can be trained end-to-end. This allows learning of a rich latent space that can accurately capture the normal information. We compare against state-of-the-art methods and show that our approach can achieve significant improvements, both quantitative and qualitative, with natural face images.
ViBE: A Tool for Measuring and Mitigating Bias in Image Datasets
Apr 16, 2020
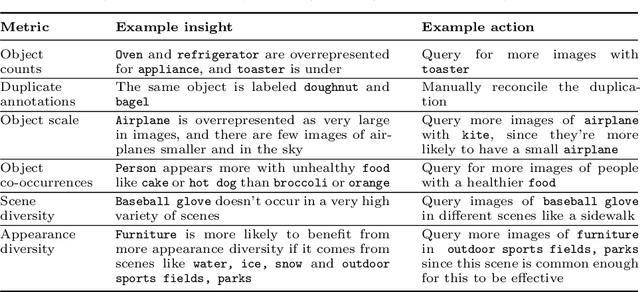

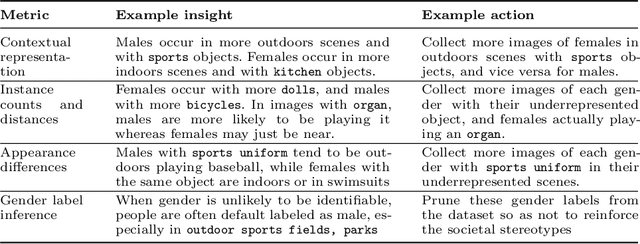
Machine learning models are known to perpetuate the biases present in the data, but oftentimes these biases aren't known until after the models are deployed. We present the Visual Bias Extraction (ViBE) Tool that assists in the investigation of a visual dataset, surfacing potential dataset biases along three dimensions: (1) object-based, (2) gender-based, and (3) geography-based. Object-based biases relate to things like size, context, or diversity of object representation in the dataset; gender-based metrics aim to reveal the stereotypical portrayal of people of different genders within the dataset, with future iterations of our tool extending the analysis to additional axes of identity; geography-based analysis considers the representation of different geographic locations. Our tool is designed to shed light on the dataset along these three axes, allowing both dataset creators and users to gain a better understanding of what exactly is portrayed in their dataset. The responsibility then lies with the tool user to determine which of the revealed biases may be problematic, taking into account the cultural and historical context, as this is difficult to determine automatically. Nevertheless, the tool also provides actionable insights that may be helpful for mitigating the revealed concerns. Overall, our work allows for the machine learning bias problem to be addressed early in the pipeline at the dataset stage. ViBE is available at https://github.com/princetonvisualai/vibe-tool.
Superpixel Segmentation Based on Spatially Constrained Subspace Clustering
Dec 11, 2020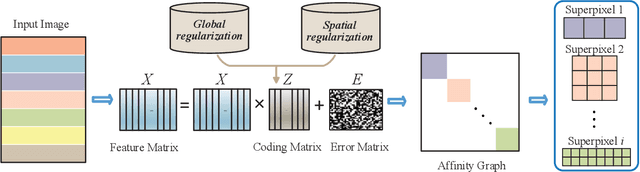
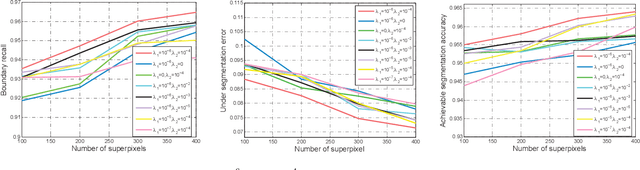

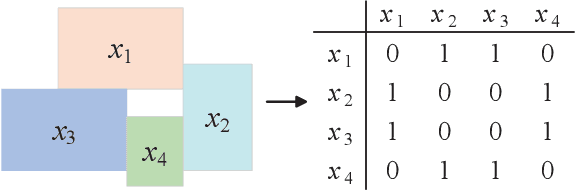
Superpixel segmentation aims at dividing the input image into some representative regions containing pixels with similar and consistent intrinsic properties, without any prior knowledge about the shape and size of each superpixel. In this paper, to alleviate the limitation of superpixel segmentation applied in practical industrial tasks that detailed boundaries are difficult to be kept, we regard each representative region with independent semantic information as a subspace, and correspondingly formulate superpixel segmentation as a subspace clustering problem to preserve more detailed content boundaries. We show that a simple integration of superpixel segmentation with the conventional subspace clustering does not effectively work due to the spatial correlation of the pixels within a superpixel, which may lead to boundary confusion and segmentation error when the correlation is ignored. Consequently, we devise a spatial regularization and propose a novel convex locality-constrained subspace clustering model that is able to constrain the spatial adjacent pixels with similar attributes to be clustered into a superpixel and generate the content-aware superpixels with more detailed boundaries. Finally, the proposed model is solved by an efficient alternating direction method of multipliers (ADMM) solver. Experiments on different standard datasets demonstrate that the proposed method achieves superior performance both quantitatively and qualitatively compared with some state-of-the-art methods.
Application of Structural Similarity Analysis of Visually Salient Areas and Hierarchical Clustering in the Screening of Similar Wireless Capsule Endoscopic Images
Apr 01, 2020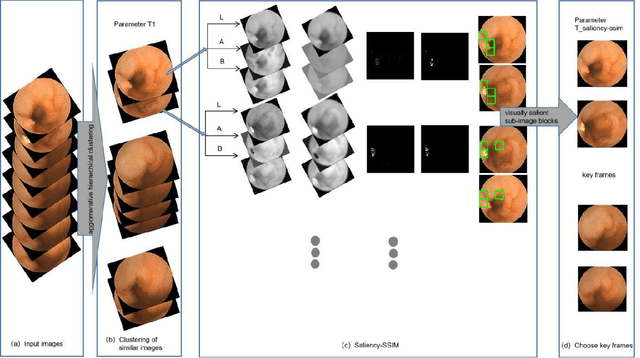

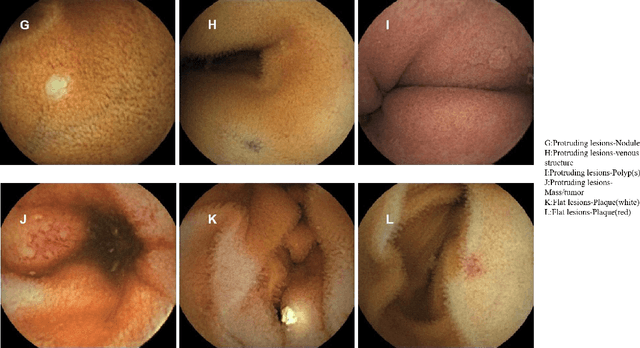
Small intestinal capsule endoscopy is the mainstream method for inspecting small intestinal lesions,but a single small intestinal capsule endoscopy will produce 60,000 - 120,000 images, the majority of which are similar and have no diagnostic value. It takes 2 - 3 hours for doctors to identify lesions from these images. This is time-consuming and increase the probability of misdiagnosis and missed diagnosis since doctors are likely to experience visual fatigue while focusing on a large number of similar images for an extended period of time.In order to solve these problems, we proposed a similar wireless capsule endoscope (WCE) image screening method based on structural similarity analysis and the hierarchical clustering of visually salient sub-image blocks. The similarity clustering of images was automatically identified by hierarchical clustering based on the hue,saturation,value (HSV) spatial color characteristics of the images,and the keyframe images were extracted based on the structural similarity of the visually salient sub-image blocks, in order to accurately identify and screen out similar small intestinal capsule endoscopic images. Subsequently, the proposed method was applied to the capsule endoscope imaging workstation. After screening out similar images in the complete data gathered by the Type I OMOM Small Intestinal Capsule Endoscope from 52 cases covering 17 common types of small intestinal lesions, we obtained a lesion recall of 100% and an average similar image reduction ratio of 76%. With similar images screened out, the average play time of the OMOM image workstation was 18 minutes, which greatly reduced the time spent by doctors viewing the images.
Interpretable Deep Models for Cardiac Resynchronisation Therapy Response Prediction
Jul 09, 2020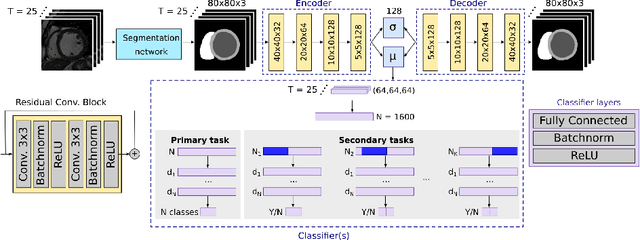

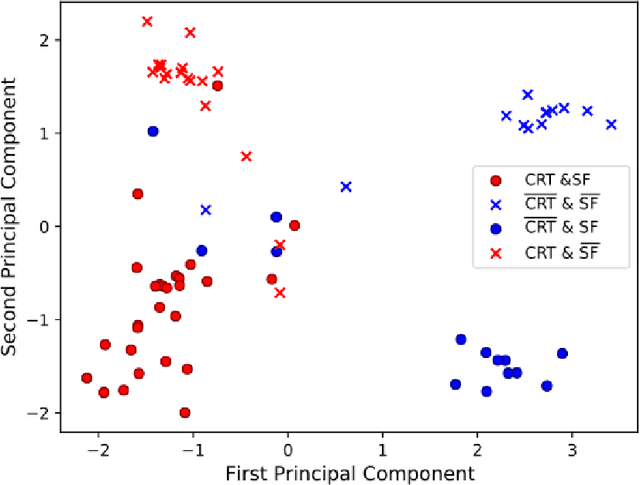

Advances in deep learning (DL) have resulted in impressive accuracy in some medical image classification tasks, but often deep models lack interpretability. The ability of these models to explain their decisions is important for fostering clinical trust and facilitating clinical translation. Furthermore, for many problems in medicine there is a wealth of existing clinical knowledge to draw upon, which may be useful in generating explanations, but it is not obvious how this knowledge can be encoded into DL models - most models are learnt either from scratch or using transfer learning from a different domain. In this paper we address both of these issues. We propose a novel DL framework for image-based classification based on a variational autoencoder (VAE). The framework allows prediction of the output of interest from the latent space of the autoencoder, as well as visualisation (in the image domain) of the effects of crossing the decision boundary, thus enhancing the interpretability of the classifier. Our key contribution is that the VAE disentangles the latent space based on `explanations' drawn from existing clinical knowledge. The framework can predict outputs as well as explanations for these outputs, and also raises the possibility of discovering new biomarkers that are separate (or disentangled) from the existing knowledge. We demonstrate our framework on the problem of predicting response of patients with cardiomyopathy to cardiac resynchronization therapy (CRT) from cine cardiac magnetic resonance images. The sensitivity and specificity of the proposed model on the task of CRT response prediction are 88.43% and 84.39% respectively, and we showcase the potential of our model in enhancing understanding of the factors contributing to CRT response.
Multiclass Yeast Segmentation in Microstructured Environments with Deep Learning
Nov 19, 2020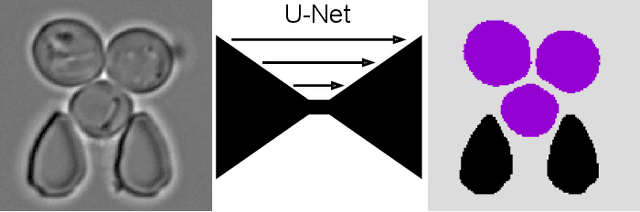
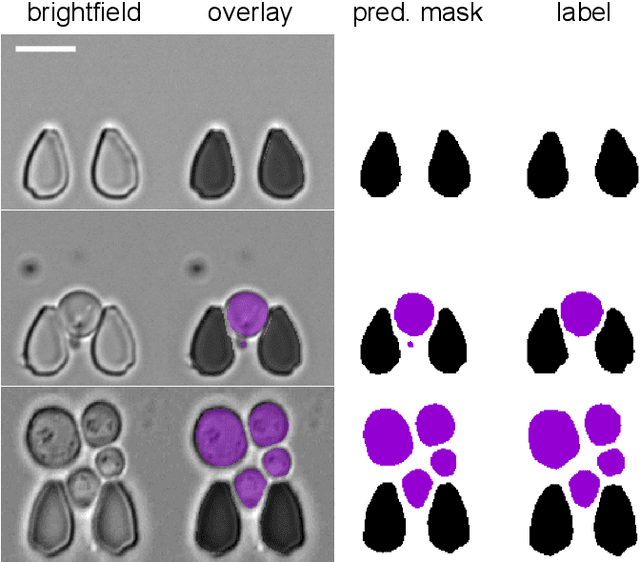
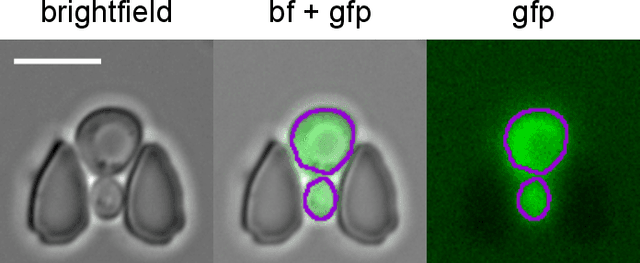

Cell segmentation is a major bottleneck in extracting quantitative single-cell information from microscopy data. The challenge is exasperated in the setting of microstructured environments. While deep learning approaches have proven useful for general cell segmentation tasks, existing segmentation tools for the yeast-microstructure setting rely on traditional machine learning approaches. Here we present convolutional neural networks trained for multiclass segmenting of individual yeast cells and discerning these from cell-similar microstructures. We give an overview of the datasets recorded for training, validating and testing the networks, as well as a typical use-case. We showcase the method's contribution to segmenting yeast in microstructured environments with a typical synthetic biology application in mind. The models achieve robust segmentation results, outperforming the previous state-of-the-art in both accuracy and speed. The combination of fast and accurate segmentation is not only beneficial for a posteriori data processing, it also makes online monitoring of thousands of trapped cells or closed-loop optimal experimental design feasible from an image processing perspective.
Aesthetics, Personalization and Recommendation: A survey on Deep Learning in Fashion
Jan 20, 2021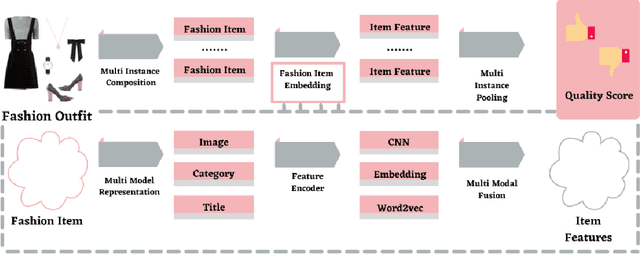


Machine learning is completely changing the trends in the fashion industry. From big to small every brand is using machine learning techniques in order to improve their revenue, increase customers and stay ahead of the trend. People are into fashion and they want to know what looks best and how they can improve their style and elevate their personality. Using Deep learning technology and infusing it with Computer Vision techniques one can do so by utilizing Brain-inspired Deep Networks, and engaging into Neuroaesthetics, working with GANs and Training them, playing around with Unstructured Data,and infusing the transformer architecture are just some highlights which can be touched with the Fashion domain. Its all about designing a system that can tell us information regarding the fashion aspect that can come in handy with the ever growing demand. Personalization is a big factor that impacts the spending choices of customers.The survey also shows remarkable approaches that encroach the subject of achieving that by divulging deep into how visual data can be interpreted and leveraged into different models and approaches. Aesthetics play a vital role in clothing recommendation as users' decision depends largely on whether the clothing is in line with their aesthetics, however the conventional image features cannot portray this directly. For that the survey also highlights remarkable models like tensor factorization model, conditional random field model among others to cater the need to acknowledge aesthetics as an important factor in Apparel recommendation.These AI inspired deep models can pinpoint exactly which certain style resonates best with their customers and they can have an understanding of how the new designs will set in with the community. With AI and machine learning your businesses can stay ahead of the fashion trends.