 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Avoiding The Double Descent Phenomenon of Random Feature Models Using Hybrid Regularization
Dec 11, 2020
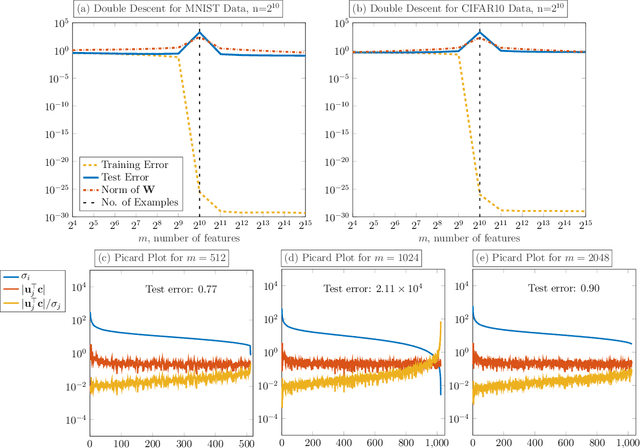
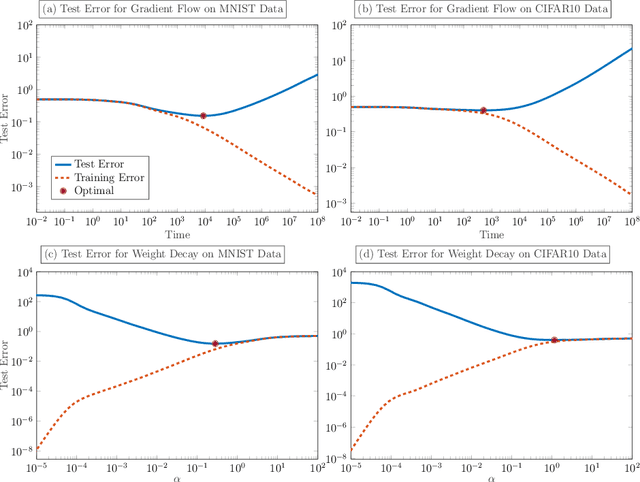
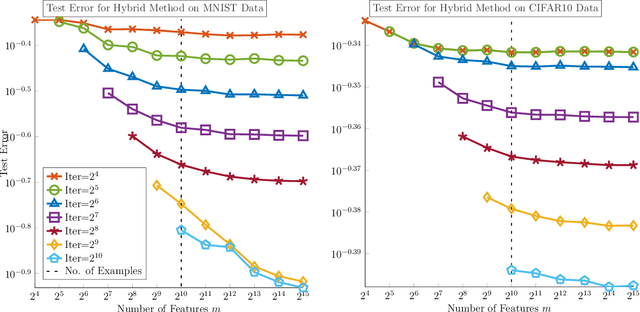
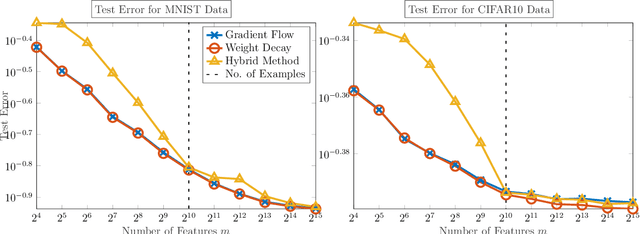
We demonstrate the ability of hybrid regularization methods to automatically avoid the double descent phenomenon arising in the training of random feature models (RFM). The hallmark feature of the double descent phenomenon is a spike in the regularization gap at the interpolation threshold, i.e. when the number of features in the RFM equals the number of training samples. To close this gap, the hybrid method considered in our paper combines the respective strengths of the two most common forms of regularization: early stopping and weight decay. The scheme does not require hyperparameter tuning as it automatically selects the stopping iteration and weight decay hyperparameter by using generalized cross-validation (GCV). This also avoids the necessity of a dedicated validation set. While the benefits of hybrid methods have been well-documented for ill-posed inverse problems, our work presents the first use case in machine learning. To expose the need for regularization and motivate hybrid methods, we perform detailed numerical experiments inspired by image classification. In those examples, the hybrid scheme successfully avoids the double descent phenomenon and yields RFMs whose generalization is comparable with classical regularization approaches whose hyperparameters are tuned optimally using the test data. We provide our MATLAB codes for implementing the numerical experiments in this paper at https://github.com/EmoryMLIP/HybridRFM.
Towards Interpretable Semantic Segmentation via Gradient-weighted Class Activation Mapping
Feb 26, 2020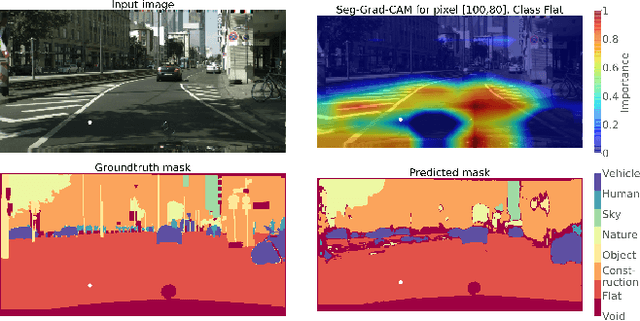
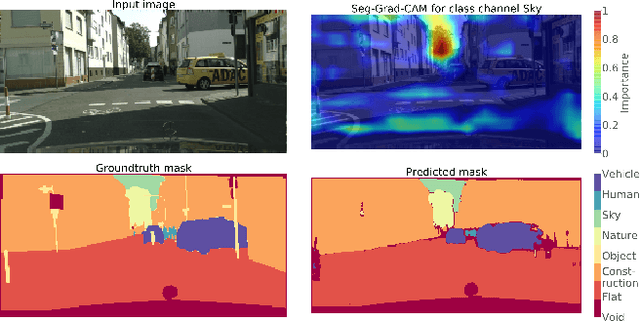
Convolutional neural networks have become state-of-the-art in a wide range of image recognition tasks. The interpretation of their predictions, however, is an active area of research. Whereas various interpretation methods have been suggested for image classification, the interpretation of image segmentation still remains largely unexplored. To that end, we propose SEG-GRAD-CAM, a gradient-based method for interpreting semantic segmentation. Our method is an extension of the widely-used Grad-CAM method, applied locally to produce heatmaps showing the relevance of individual pixels for semantic segmentation.
* 2 pages, 2 figures. AAAI 2020 camera-ready
Dynamic memory to alleviate catastrophic forgetting in continuous learning settings
Jul 06, 2020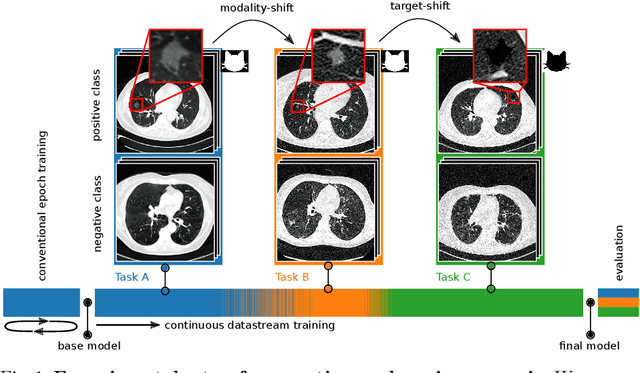
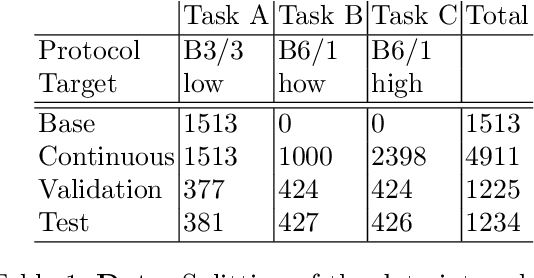
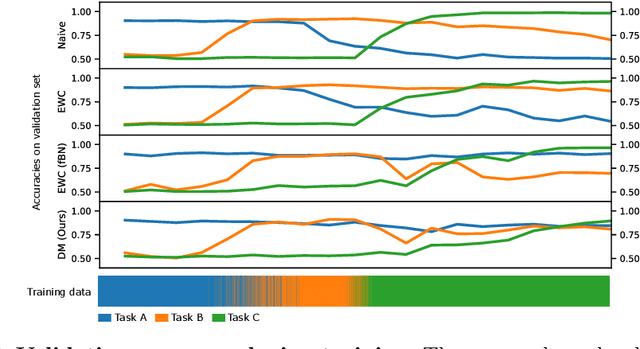
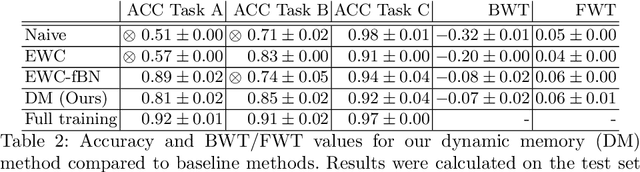
In medical imaging, technical progress or changes in diagnostic procedures lead to a continuous change in image appearance. Scanner manufacturer, reconstruction kernel, dose, other protocol specific settings or administering of contrast agents are examples that influence image content independent of the scanned biology. Such domain and task shifts limit the applicability of machine learning algorithms in the clinical routine by rendering models obsolete over time. Here, we address the problem of data shifts in a continuous learning scenario by adapting a model to unseen variations in the source domain while counteracting catastrophic forgetting effects. Our method uses a dynamic memory to facilitate rehearsal of a diverse training data subset to mitigate forgetting. We evaluated our approach on routine clinical CT data obtained with two different scanner protocols and synthetic classification tasks. Experiments show that dynamic memory counters catastrophic forgetting in a setting with multiple data shifts without the necessity for explicit knowledge about when these shifts occur.
ScalarFlow: A Large-Scale Volumetric Data Set of Real-world Scalar Transport Flows for Computer Animation and Machine Learning
Nov 20, 2020
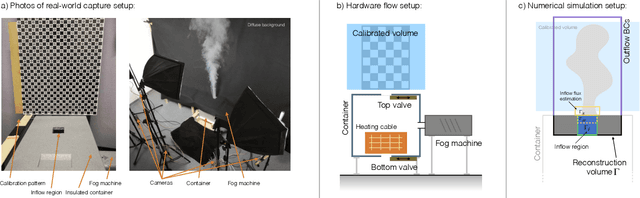
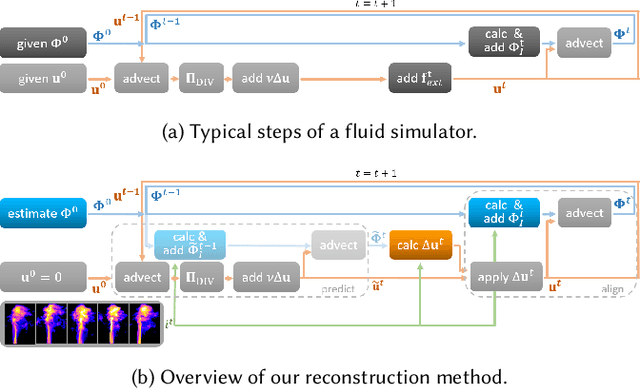
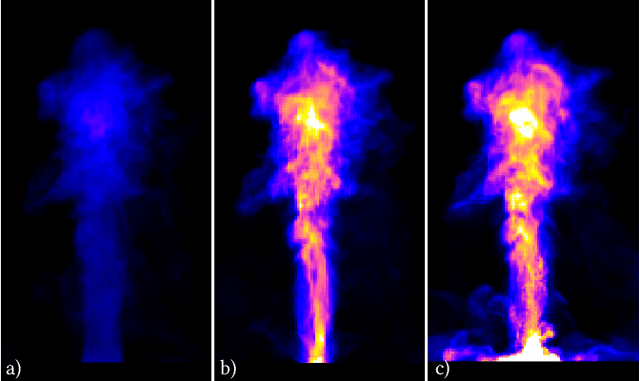
In this paper, we present ScalarFlow, a first large-scale data set of reconstructions of real-world smoke plumes. We additionally propose a framework for accurate physics-based reconstructions from a small number of video streams. Central components of our algorithm are a novel estimation of unseen inflow regions and an efficient regularization scheme. Our data set includes a large number of complex and natural buoyancy-driven flows. The flows transition to turbulent flows and contain observable scalar transport processes. As such, the ScalarFlow data set is tailored towards computer graphics, vision, and learning applications. The published data set will contain volumetric reconstructions of velocity and density, input image sequences, together with calibration data, code, and instructions how to recreate the commodity hardware capture setup. We further demonstrate one of the many potential application areas: a first perceptual evaluation study, which reveals that the complexity of the captured flows requires a huge simulation resolution for regular solvers in order to recreate at least parts of the natural complexity contained in the captured data.
iUNets: Fully invertible U-Nets with Learnable Up- and Downsampling
May 11, 2020
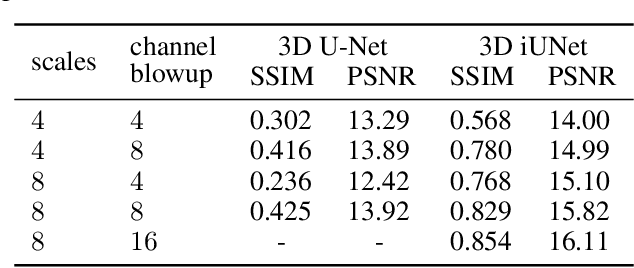
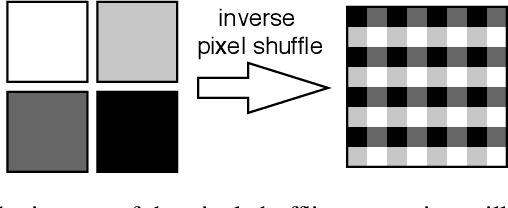
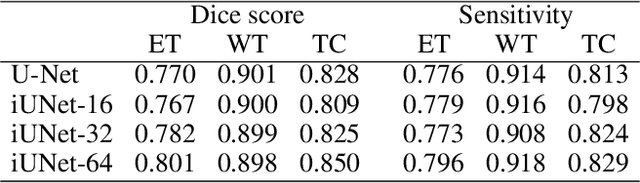
U-Nets have been established as a standard neural network design architecture for image-to-image learning problems such as segmentation and inverse problems in imaging. For high-dimensional applications, as they for example appear in 3D medical imaging, U-Nets however have prohibitive memory requirements. Here, we present a new fully-invertible U-Net-based architecture called the \emph{iUNet}, which allows for the application of highly memory-efficient backpropagation procedures. For this, we introduce learnable and invertible up- and downsampling operations. An open source library in Pytorch for 1D, 2D and 3D data is made available.
Kaleidoscope: An Efficient, Learnable Representation For All Structured Linear Maps
Dec 29, 2020

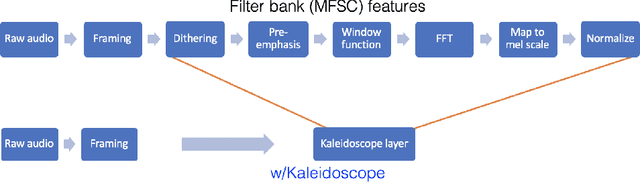

Modern neural network architectures use structured linear transformations, such as low-rank matrices, sparse matrices, permutations, and the Fourier transform, to improve inference speed and reduce memory usage compared to general linear maps. However, choosing which of the myriad structured transformations to use (and its associated parameterization) is a laborious task that requires trading off speed, space, and accuracy. We consider a different approach: we introduce a family of matrices called kaleidoscope matrices (K-matrices) that provably capture any structured matrix with near-optimal space (parameter) and time (arithmetic operation) complexity. We empirically validate that K-matrices can be automatically learned within end-to-end pipelines to replace hand-crafted procedures, in order to improve model quality. For example, replacing channel shuffles in ShuffleNet improves classification accuracy on ImageNet by up to 5%. K-matrices can also simplify hand-engineered pipelines -- we replace filter bank feature computation in speech data preprocessing with a learnable kaleidoscope layer, resulting in only 0.4% loss in accuracy on the TIMIT speech recognition task. In addition, K-matrices can capture latent structure in models: for a challenging permuted image classification task, a K-matrix based representation of permutations is able to learn the right latent structure and improves accuracy of a downstream convolutional model by over 9%. We provide a practically efficient implementation of our approach, and use K-matrices in a Transformer network to attain 36% faster end-to-end inference speed on a language translation task.
A regularization-based approach for unsupervised image segmentation
Mar 08, 2016
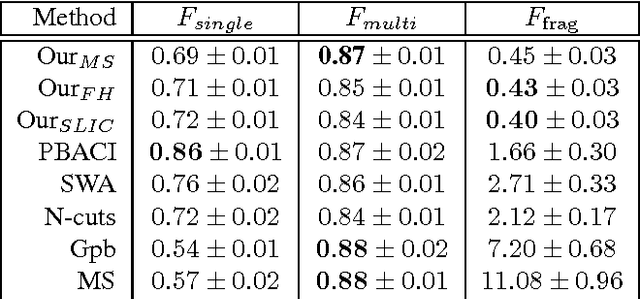

We propose a novel unsupervised image segmentation algorithm, which aims to segment an image into several coherent parts. It requires no user input, no supervised learning phase and assumes an unknown number of segments. It achieves this by first over-segmenting the image into several hundred superpixels. These are iteratively joined on the basis of a discriminative classifier trained on color and texture information obtained from each superpixel. The output of the classifier is regularized by a Markov random field that lends more influence to neighbouring superpixels that are more similar. In each iteration, similar superpixels fall under the same label, until only a few coherent regions remain in the image. The algorithm was tested on a standard evaluation data set, where it performs on par with state-of-the-art algorithms in term of precision and greatly outperforms the state of the art by reducing the oversegmentation of the object of interest.
Weakly-Supervised Arbitrary-Shaped Text Detection with Expectation-Maximization Algorithm
Dec 01, 2020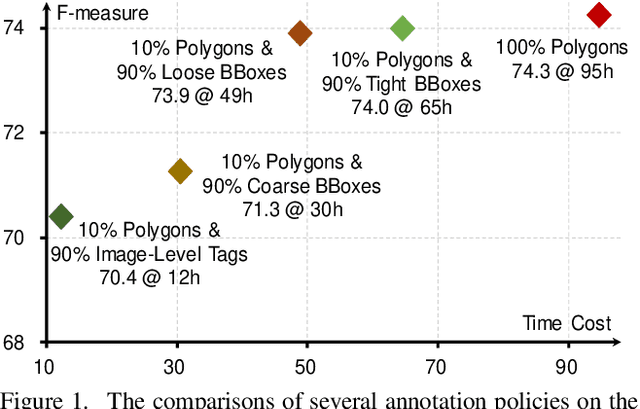
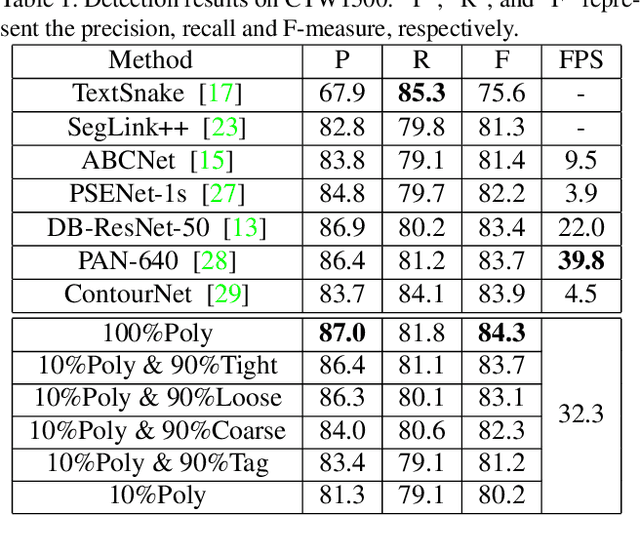
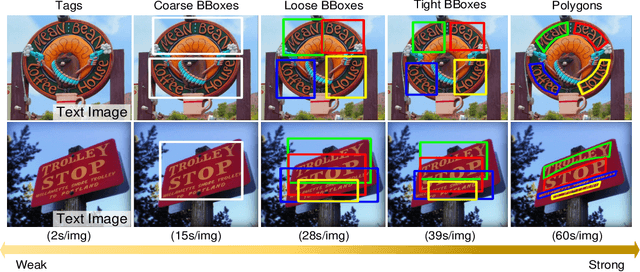
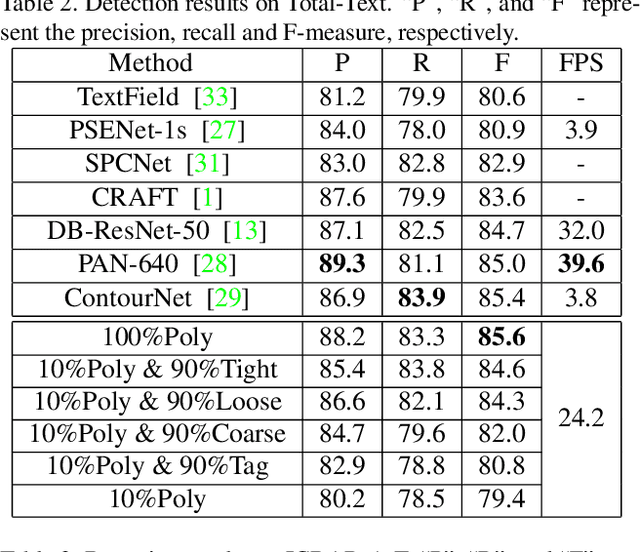
Arbitrary-shaped text detection is an important and challenging task in computer vision. Most existing methods require heavy data labeling efforts to produce polygon-level text region labels for supervised training. In order to reduce the cost in data labeling, we study weakly-supervised arbitrary-shaped text detection for combining various weak supervision forms (e.g., image-level tags, coarse, loose and tight bounding boxes), which are far easier for annotation. We propose an Expectation-Maximization (EM) based weakly-supervised learning framework to train an accurate arbitrary-shaped text detector using only a small amount of polygon-level annotated data combined with a large amount of weakly annotated data. Meanwhile, we propose a contour-based arbitrary-shaped text detector, which is suitable for incorporating weakly-supervised learning. Extensive experiments on three arbitrary-shaped text benchmarks (CTW1500, Total-Text and ICDAR-ArT) show that (1) using only 10% strongly annotated data and 90% weakly annotated data, our method yields comparable performance to state-of-the-art methods, (2) with 100% strongly annotated data, our method outperforms existing methods on all three benchmarks. We will make the weakly annotated datasets publicly available in the future.
BiCANet: Bi-directional Contextual Aggregating Network for Image Semantic Segmentation
Mar 21, 2020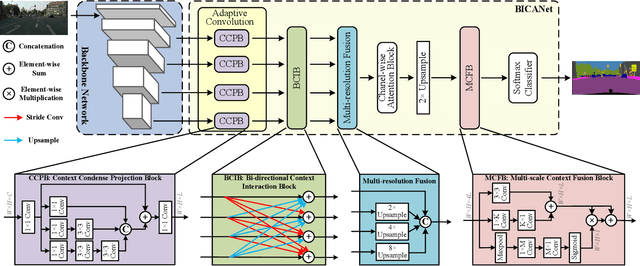
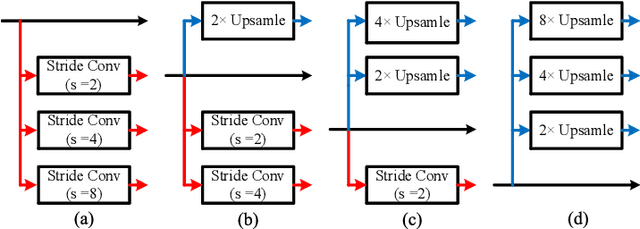
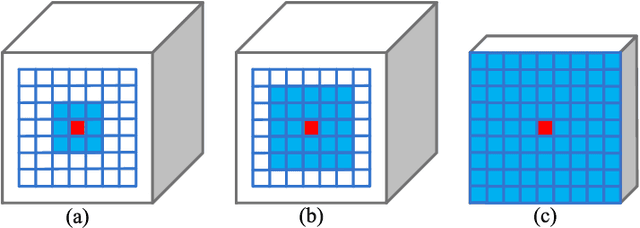

Exploring contextual information in convolution neural networks (CNNs) has gained substantial attention in recent years for semantic segmentation. This paper introduces a Bi-directional Contextual Aggregating Network, called BiCANet, for semantic segmentation. Unlike previous approaches that encode context in feature space, BiCANet aggregates contextual cues from a categorical perspective, which is mainly consist of three parts: contextual condensed projection block (CCPB), bi-directional context interaction block (BCIB), and muti-scale contextual fusion block (MCFB). More specifically, CCPB learns a category-based mapping through a split-transform-merge architecture, which condenses contextual cues with different receptive fields from intermediate layer. BCIB, on the other hand, employs dense skipped-connections to enhance the class-level context exchanging. Finally, MCFB integrates multi-scale contextual cues by investigating short- and long-ranged spatial dependencies. To evaluate BiCANet, we have conducted extensive experiments on three semantic segmentation datasets: PASCAL VOC 2012, Cityscapes, and ADE20K. The experimental results demonstrate that BiCANet outperforms recent state-of-the-art networks without any postprocess techniques. Particularly, BiCANet achieves the mIoU score of 86.7%, 82.4% and 38.66% on PASCAL VOC 2012, Cityscapes and ADE20K testset, respectively.
Self-Path: Self-supervision for Classification of Pathology Images with Limited Annotations
Aug 12, 2020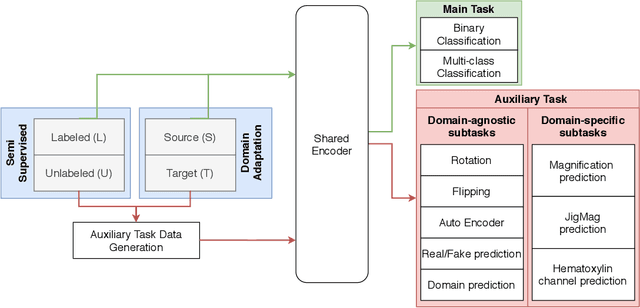
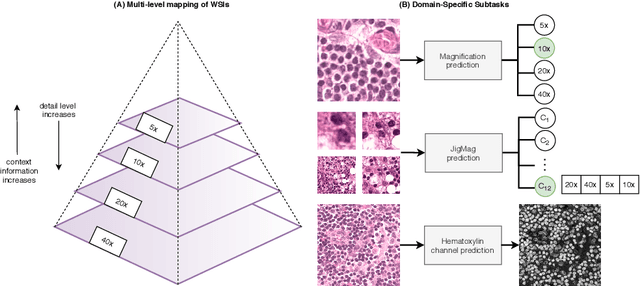
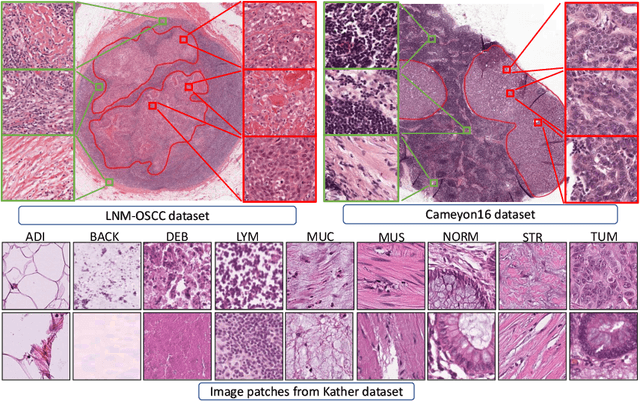
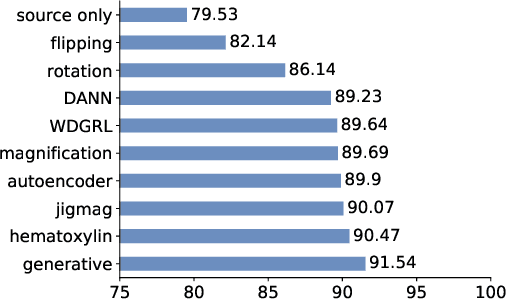
While high-resolution pathology images lend themselves well to `data hungry' deep learning algorithms, obtaining exhaustive annotations on these images is a major challenge. In this paper, we propose a self-supervised CNN approach to leverage unlabeled data for learning generalizable and domain invariant representations in pathology images. The proposed approach, which we term as Self-Path, is a multi-task learning approach where the main task is tissue classification and pretext tasks are a variety of self-supervised tasks with labels inherent to the input data. We introduce novel domain specific self-supervision tasks that leverage contextual, multi-resolution and semantic features in pathology images for semi-supervised learning and domain adaptation. We investigate the effectiveness of Self-Path on 3 different pathology datasets. Our results show that Self-Path with the domain-specific pretext tasks achieves state-of-the-art performance for semi-supervised learning when small amounts of labeled data are available. Further, we show that Self-Path improves domain adaptation for classification of histology image patches when there is no labeled data available for the target domain. This approach can potentially be employed for other applications in computational pathology, where annotation budget is often limited or large amount of unlabeled image data is available.