 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Robustness and Overfitting Behavior of Implicit Background Models
Aug 21, 2020

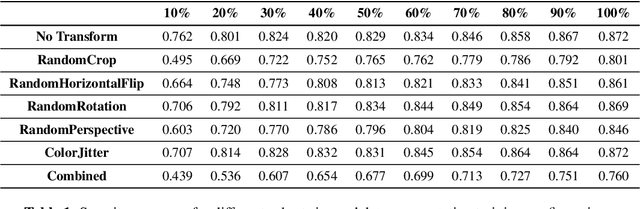
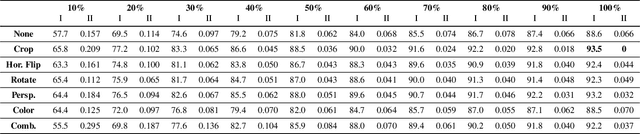
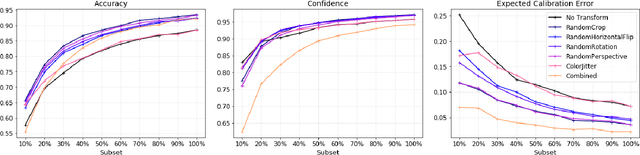
In this paper, we examine the overfitting behavior of image classification models modified with Implicit Background Estimation (SCrIBE), which transforms them into weakly supervised segmentation models that provide spatial domain visualizations without affecting performance. Using the segmentation masks, we derive an overfit detection criterion that does not require testing labels. In addition, we assess the change in model performance, calibration, and segmentation masks after applying data augmentations as overfitting reduction measures and testing on various types of distorted images.
Stochastic Bundle Adjustment for Efficient and Scalable 3D Reconstruction
Aug 02, 2020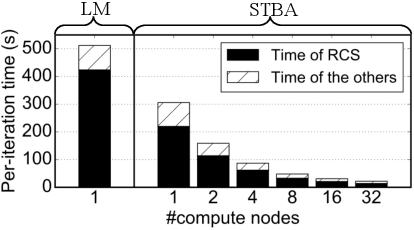
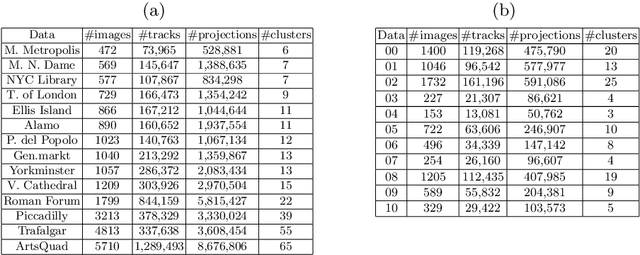
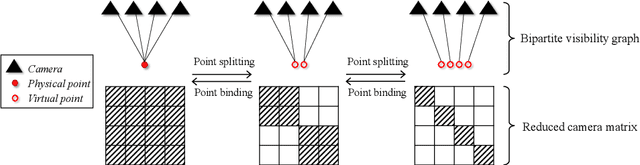

Current bundle adjustment solvers such as the Levenberg-Marquardt (LM) algorithm are limited by the bottleneck in solving the Reduced Camera System (RCS) whose dimension is proportional to the camera number. When the problem is scaled up, this step is neither efficient in computation nor manageable for a single compute node. In this work, we propose a stochastic bundle adjustment algorithm which seeks to decompose the RCS approximately inside the LM iterations to improve the efficiency and scalability. It first reformulates the quadratic programming problem of an LM iteration based on the clustering of the visibility graph by introducing the equality constraints across clusters. Then, we propose to relax it into a chance constrained problem and solve it through sampled convex program. The relaxation is intended to eliminate the interdependence between clusters embodied by the constraints, so that a large RCS can be decomposed into independent linear sub-problems. Numerical experiments on unordered Internet image sets and sequential SLAM image sets, as well as distributed experiments on large-scale datasets, have demonstrated the high efficiency and scalability of the proposed approach. Codes are released at https://github.com/zlthinker/STBA.
Curious Case of Language Generation Evaluation Metrics: A Cautionary Tale
Oct 26, 2020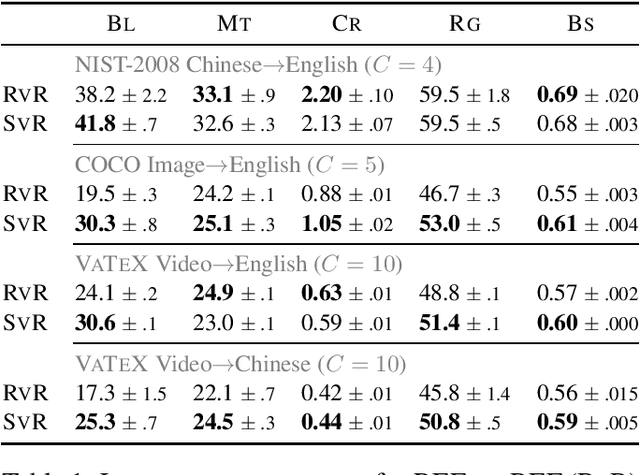
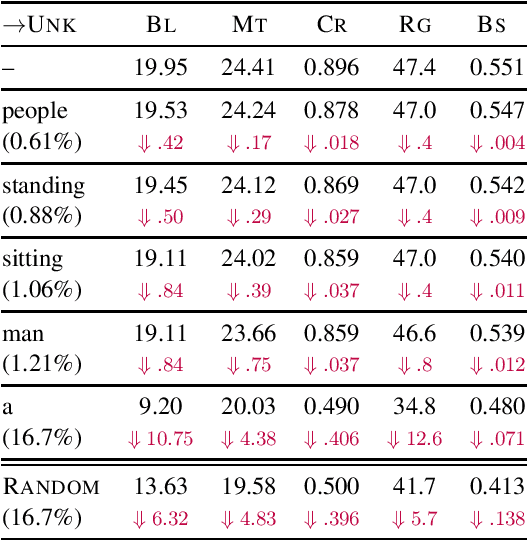
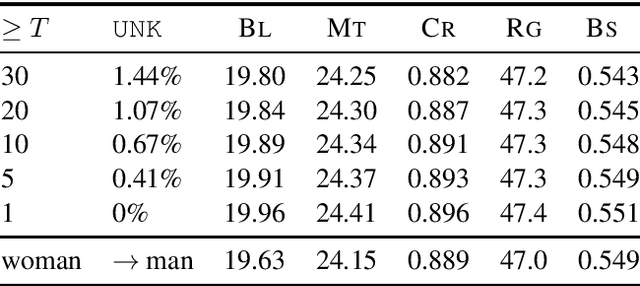
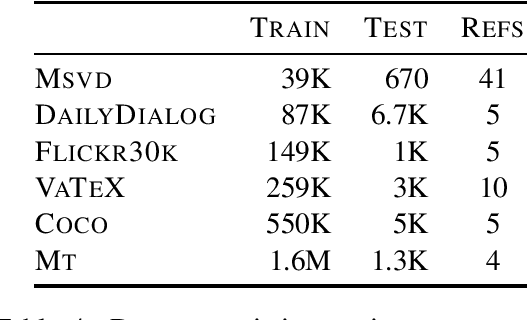
Automatic evaluation of language generation systems is a well-studied problem in Natural Language Processing. While novel metrics are proposed every year, a few popular metrics remain as the de facto metrics to evaluate tasks such as image captioning and machine translation, despite their known limitations. This is partly due to ease of use, and partly because researchers expect to see them and know how to interpret them. In this paper, we urge the community for more careful consideration of how they automatically evaluate their models by demonstrating important failure cases on multiple datasets, language pairs and tasks. Our experiments show that metrics (i) usually prefer system outputs to human-authored texts, (ii) can be insensitive to correct translations of rare words, (iii) can yield surprisingly high scores when given a single sentence as system output for the entire test set.
A regularization-based approach for unsupervised image segmentation
Mar 08, 2016
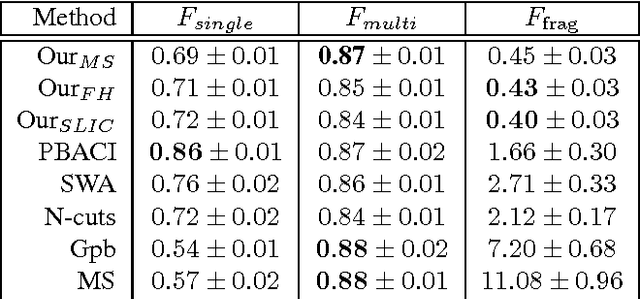

We propose a novel unsupervised image segmentation algorithm, which aims to segment an image into several coherent parts. It requires no user input, no supervised learning phase and assumes an unknown number of segments. It achieves this by first over-segmenting the image into several hundred superpixels. These are iteratively joined on the basis of a discriminative classifier trained on color and texture information obtained from each superpixel. The output of the classifier is regularized by a Markov random field that lends more influence to neighbouring superpixels that are more similar. In each iteration, similar superpixels fall under the same label, until only a few coherent regions remain in the image. The algorithm was tested on a standard evaluation data set, where it performs on par with state-of-the-art algorithms in term of precision and greatly outperforms the state of the art by reducing the oversegmentation of the object of interest.
Siamese Network of Deep Fisher-Vector Descriptors for Image Retrieval
Feb 01, 2017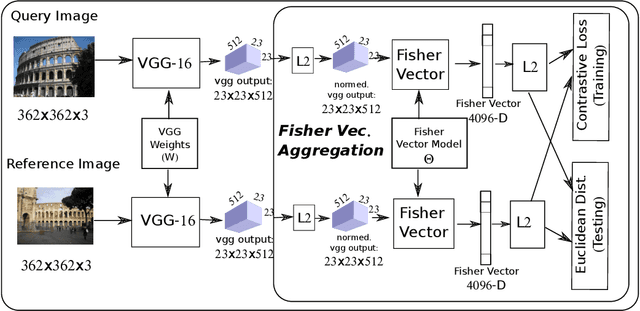
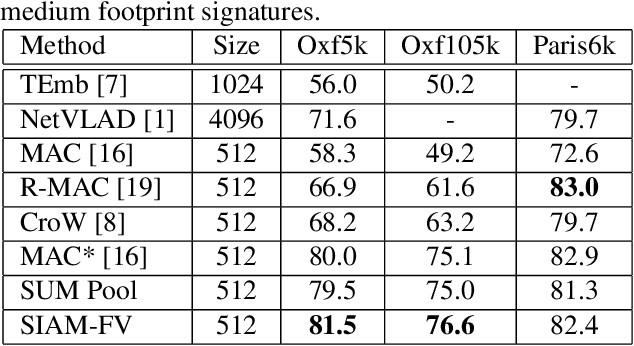
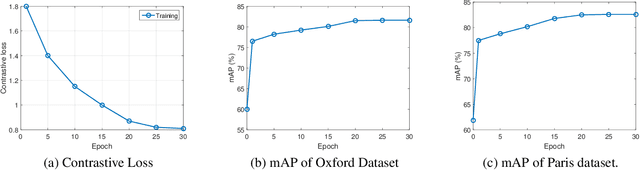
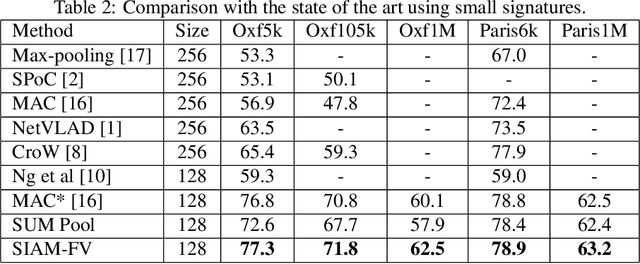
This paper addresses the problem of large scale image retrieval, with the aim of accurately ranking the similarity of a large number of images to a given query image. To achieve this, we propose a novel Siamese network. This network consists of two computational strands, each comprising of a CNN component followed by a Fisher vector component. The CNN component produces dense, deep convolutional descriptors that are then aggregated by the Fisher Vector method. Crucially, we propose to simultaneously learn both the CNN filter weights and Fisher Vector model parameters. This allows us to account for the evolving distribution of deep descriptors over the course of the learning process. We show that the proposed approach gives significant improvements over the state-of-the-art methods on the Oxford and Paris image retrieval datasets. Additionally, we provide a baseline performance measure for both these datasets with the inclusion of 1 million distractors.
PadChest: A large chest x-ray image dataset with multi-label annotated reports
Feb 07, 2019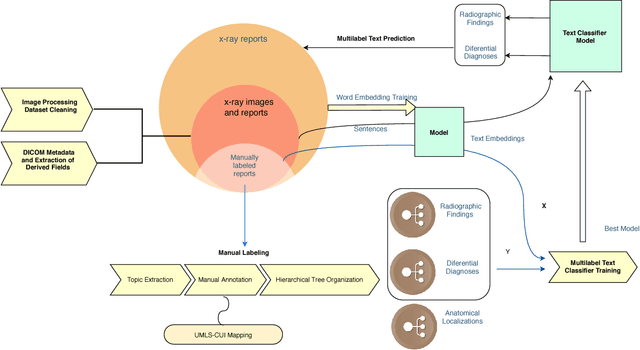

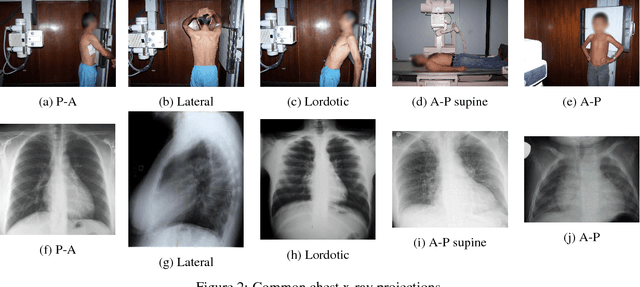
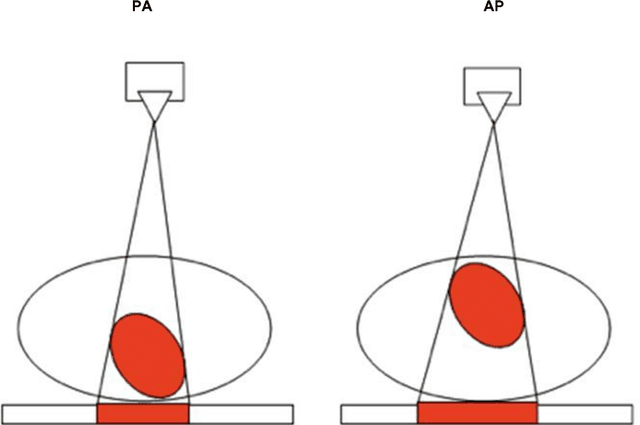
We present a labeled large-scale, high resolution chest x-ray dataset for the automated exploration of medical images along with their associated reports. This dataset includes more than 160,000 images obtained from 67,000 patients that were interpreted and reported by radiologists at Hospital San Juan Hospital (Spain) from 2009 to 2017, covering six different position views and additional information on image acquisition and patient demography. The reports were labeled with 174 different radiographic findings, 19 differential diagnoses and 104 anatomic locations organized as a hierarchical taxonomy and mapped onto standard Unified Medical Language System (UMLS) terminology. Of these reports, 27% were manually annotated by trained physicians and the remaining set was labeled using a supervised method based on a recurrent neural network with attention mechanisms. The labels generated were then validated in an independent test set achieving a 0.93 Micro-F1 score. To the best of our knowledge, this is one of the largest public chest x-ray database suitable for training supervised models concerning radiographs, and the first to contain radiographic reports in Spanish. The PadChest dataset can be downloaded from http://bimcv.cipf.es/bimcv-projects/padchest/.
Incremental Embedding Learning via Zero-Shot Translation
Dec 31, 2020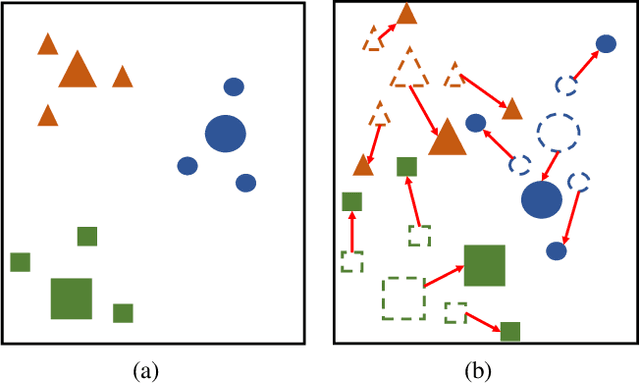
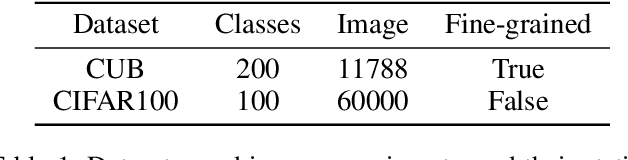
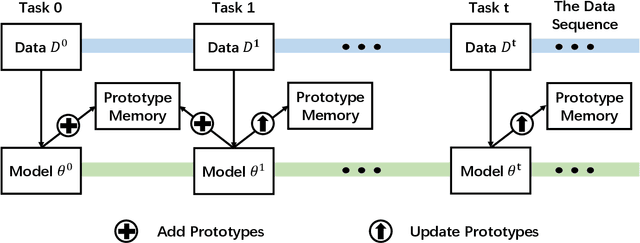
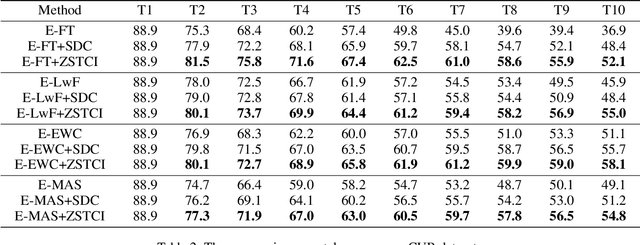
Modern deep learning methods have achieved great success in machine learning and computer vision fields by learning a set of pre-defined datasets. Howerver, these methods perform unsatisfactorily when applied into real-world situations. The reason of this phenomenon is that learning new tasks leads the trained model quickly forget the knowledge of old tasks, which is referred to as catastrophic forgetting. Current state-of-the-art incremental learning methods tackle catastrophic forgetting problem in traditional classification networks and ignore the problem existing in embedding networks, which are the basic networks for image retrieval, face recognition, zero-shot learning, etc. Different from traditional incremental classification networks, the semantic gap between the embedding spaces of two adjacent tasks is the main challenge for embedding networks under incremental learning setting. Thus, we propose a novel class-incremental method for embedding network, named as zero-shot translation class-incremental method (ZSTCI), which leverages zero-shot translation to estimate and compensate the semantic gap without any exemplars. Then, we try to learn a unified representation for two adjacent tasks in sequential learning process, which captures the relationships of previous classes and current classes precisely. In addition, ZSTCI can easily be combined with existing regularization-based incremental learning methods to further improve performance of embedding networks. We conduct extensive experiments on CUB-200-2011 and CIFAR100, and the experiment results prove the effectiveness of our method. The code of our method has been released.
It's LeVAsa not LevioSA! Latent Encodings for Valence-Arousal Structure Alignment
Jul 20, 2020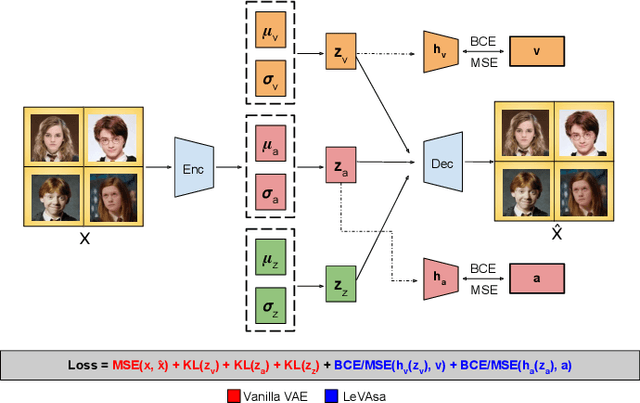
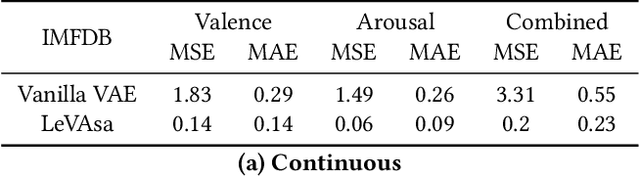
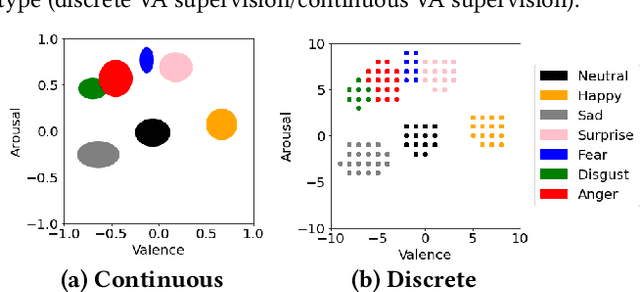
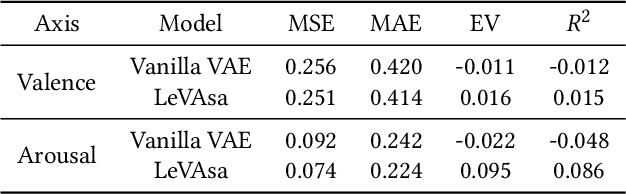
In recent years, great strides have been made in the field of affective computing. Several models have been developed to represent and quantify emotions. Two popular ones include (i) categorical models which represent emotions as discrete labels, and (ii) dimensional models which represent emotions in a Valence-Arousal (VA) circumplex domain. However, there is no standard for annotation mapping between the two labelling methods. We build a novel algorithm for mapping categorical and dimensional model labels using annotation transfer across affective facial image datasets. Further, we utilize the transferred annotations to learn rich and interpretable data representations using a variational autoencoder (VAE). We present "LeVAsa", a VAE model that learns implicit structure by aligning the latent space with the VA space. We evaluate the efficacy of LeVAsa by comparing performance with the Vanilla VAE using quantitative and qualitative analysis on two benchmark affective image datasets. Our results reveal that LeVAsa achieves high latent-circumplex alignment which leads to improved downstream categorical emotion prediction. The work also demonstrates the trade-off between degree of alignment and quality of reconstructions.
A Deep Learning Framework for Recognizing both Static and Dynamic Gestures
Jun 11, 2020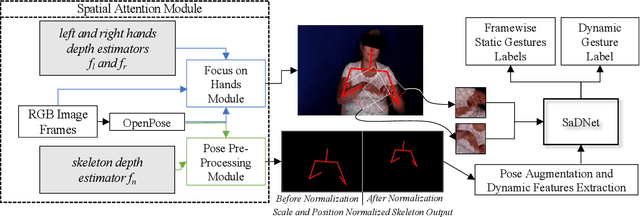
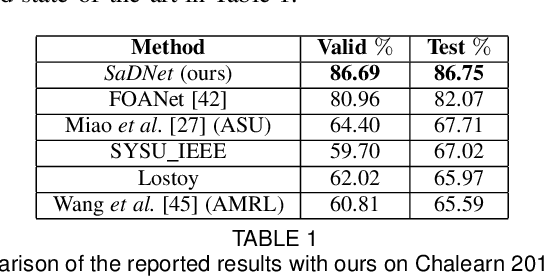


Intuitive user interfaces are indispensable to interact with human centric smart environments. In this paper, we propose a unified framework that recognizes both static and dynamic gestures, using simple RGB vision (without depth sensing). This feature makes it suitable for inexpensive human-machine interaction (HMI). We rely on a spatial attention-based strategy, which employs SaDNet, our proposed Static and Dynamic gestures Network. From the image of the human upper body, we estimate his/her depth, along with the region-of-interest around his/her hands. The Convolutional Neural Networks in SaDNet are fine-tuned on a background-substituted hand gestures dataset. They are utilized to detect 10 static gestures for each hand and to obtain hand image-embeddings from the last Fully Connected layer, which are subsequently fused with the augmented pose vector and then passed to stacked Long Short-Term Memory blocks. Thus, human-centered frame-wise information from the augmented pose vector and left/right hands image-embeddings are aggregated in time to predict the dynamic gestures of the performing person. In a number of experiments we show that the proposed approach surpasses the state-of-the-art results on large-scale Chalearn 2016 dataset. Moreover, we also transfer the knowledge learned through the proposed methodology to the Praxis gestures dataset, and the obtained results also outscore the state-of-the-art on this dataset.
Ensemble Soft-Margin Softmax Loss for Image Classification
May 10, 2018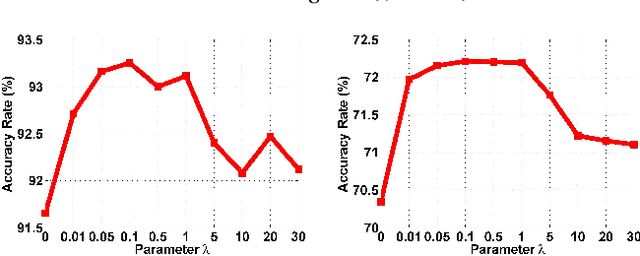
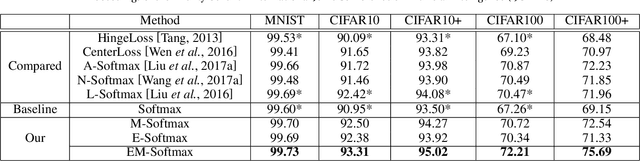
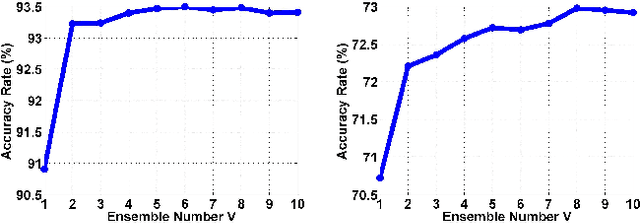

Softmax loss is arguably one of the most popular losses to train CNN models for image classification. However, recent works have exposed its limitation on feature discriminability. This paper casts a new viewpoint on the weakness of softmax loss. On the one hand, the CNN features learned using the softmax loss are often inadequately discriminative. We hence introduce a soft-margin softmax function to explicitly encourage the discrimination between different classes. On the other hand, the learned classifier of softmax loss is weak. We propose to assemble multiple these weak classifiers to a strong one, inspired by the recognition that the diversity among weak classifiers is critical to a good ensemble. To achieve the diversity, we adopt the Hilbert-Schmidt Independence Criterion (HSIC). Considering these two aspects in one framework, we design a novel loss, named as Ensemble soft-Margin Softmax (EM-Softmax). Extensive experiments on benchmark datasets are conducted to show the superiority of our design over the baseline softmax loss and several state-of-the-art alternatives.