 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
CalliGAN: Style and Structure-aware Chinese Calligraphy Character Generator
May 26, 2020
Chinese calligraphy is the writing of Chinese characters as an art form performed with brushes so Chinese characters are rich of shapes and details. Recent studies show that Chinese characters can be generated through image-to-image translation for multiple styles using a single model. We propose a novel method of this approach by incorporating Chinese characters' component information into its model. We also propose an improved network to convert characters to their embedding space. Experiments show that the proposed method generates high-quality Chinese calligraphy characters over state-of-the-art methods measured through numerical evaluations and human subject studies.
3D Human Shape and Pose from a Single Low-Resolution Image with Self-Supervised Learning
Jul 27, 2020
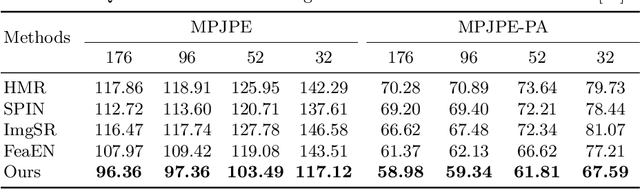
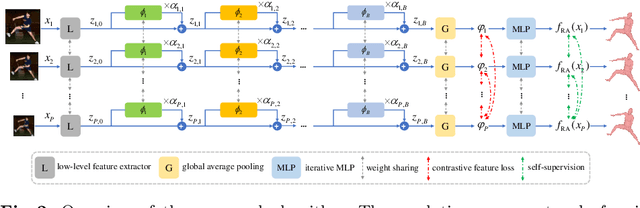
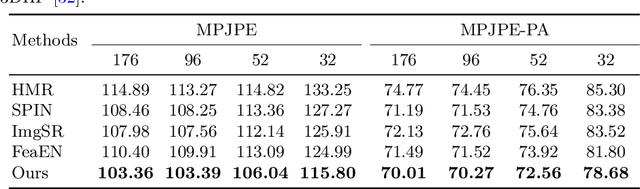
3D human shape and pose estimation from monocular images has been an active area of research in computer vision, having a substantial impact on the development of new applications, from activity recognition to creating virtual avatars. Existing deep learning methods for 3D human shape and pose estimation rely on relatively high-resolution input images; however, high-resolution visual content is not always available in several practical scenarios such as video surveillance and sports broadcasting. Low-resolution images in real scenarios can vary in a wide range of sizes, and a model trained in one resolution does not typically degrade gracefully across resolutions. Two common approaches to solve the problem of low-resolution input are applying super-resolution techniques to the input images which may result in visual artifacts, or simply training one model for each resolution, which is impractical in many realistic applications. To address the above issues, this paper proposes a novel algorithm called RSC-Net, which consists of a Resolution-aware network, a Self-supervision loss, and a Contrastive learning scheme. The proposed network is able to learn the 3D body shape and pose across different resolutions with a single model. The self-supervision loss encourages scale-consistency of the output, and the contrastive learning scheme enforces scale-consistency of the deep features. We show that both these new training losses provide robustness when learning 3D shape and pose in a weakly-supervised manner. Extensive experiments demonstrate that the RSC-Net can achieve consistently better results than the state-of-the-art methods for challenging low-resolution images.
Deblurring by Realistic Blurring
Apr 04, 2020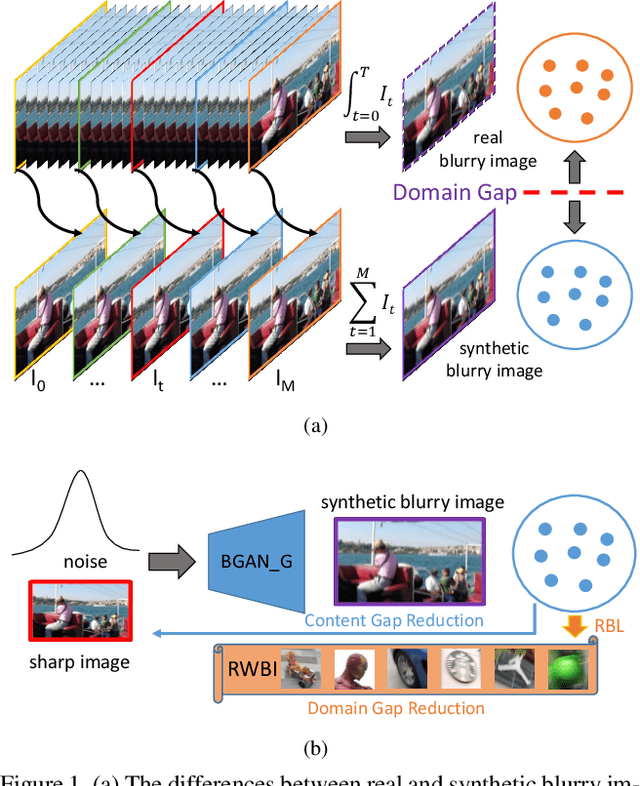

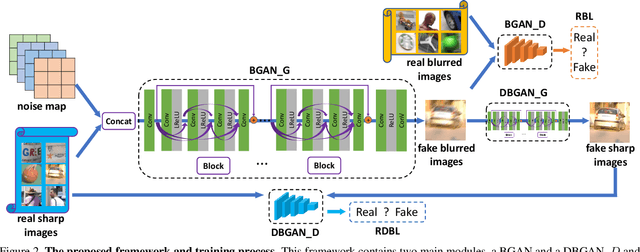
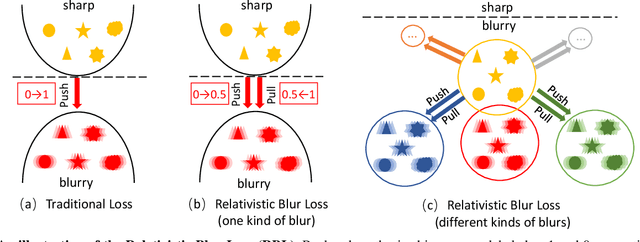
Existing deep learning methods for image deblurring typically train models using pairs of sharp images and their blurred counterparts. However, synthetically blurring images do not necessarily model the genuine blurring process in real-world scenarios with sufficient accuracy. To address this problem, we propose a new method which combines two GAN models, i.e., a learning-to-Blur GAN (BGAN) and learning-to-DeBlur GAN (DBGAN), in order to learn a better model for image deblurring by primarily learning how to blur images. The first model, BGAN, learns how to blur sharp images with unpaired sharp and blurry image sets, and then guides the second model, DBGAN, to learn how to correctly deblur such images. In order to reduce the discrepancy between real blur and synthesized blur, a relativistic blur loss is leveraged. As an additional contribution, this paper also introduces a Real-World Blurred Image (RWBI) dataset including diverse blurry images. Our experiments show that the proposed method achieves consistently superior quantitative performance as well as higher perceptual quality on both the newly proposed dataset and the public GOPRO dataset.
Aerial Imagery Pixel-level Segmentation
Dec 03, 2020
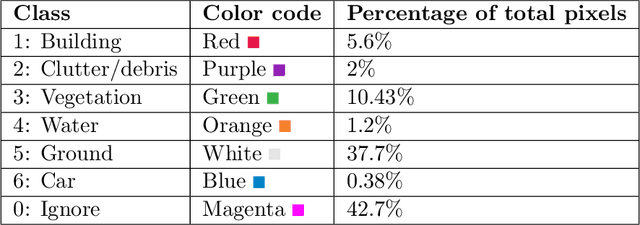

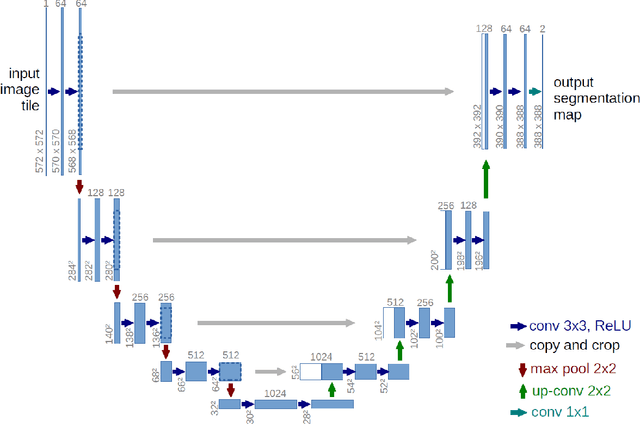
Aerial imagery can be used for important work on a global scale. Nevertheless, the analysis of this data using neural network architectures lags behind the current state-of-the-art on popular datasets such as PASCAL VOC, CityScapes and Camvid. In this paper we bridge the performance-gap between these popular datasets and aerial imagery data. Little work is done on aerial imagery with state-of-the-art neural network architectures in a multi-class setting. Our experiments concerning data augmentation, normalisation, image size and loss functions give insight into a high performance setup for aerial imagery segmentation datasets. Our work, using the state-of-the-art DeepLabv3+ Xception65 architecture, achieves a mean IOU of 70% on the DroneDeploy validation set. With this result, we clearly outperform the current publicly available state-of-the-art validation set mIOU (65%) performance with 5%. Furthermore, to our knowledge, there is no mIOU benchmark for the test set. Hence, we also propose a new benchmark on the DroneDeploy test set using the best performing DeepLabv3+ Xception65 architecture, with a mIOU score of 52.5%.
Brain Extraction from Normal and Pathological Images: A Joint PCA/Image-Reconstruction Approach
Apr 30, 2018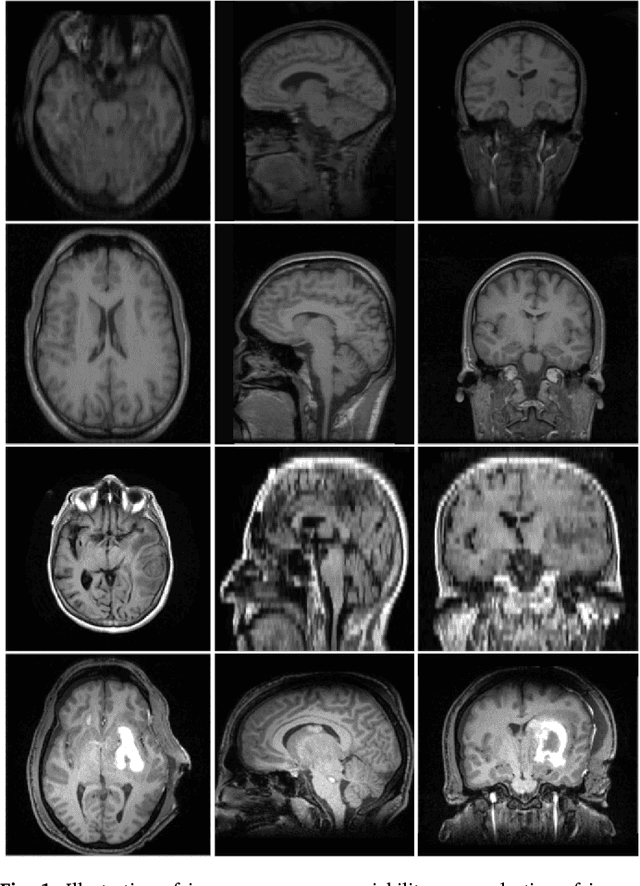
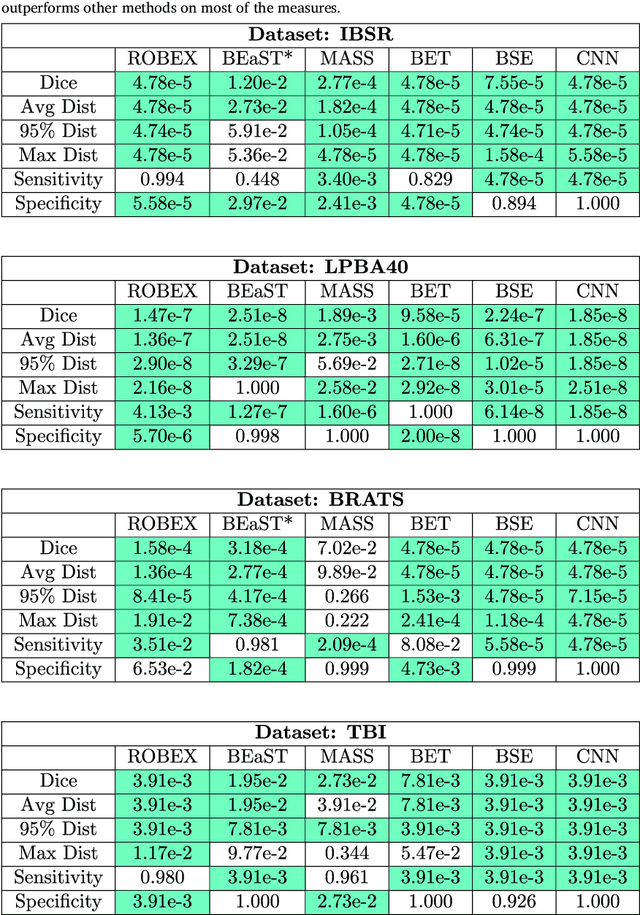
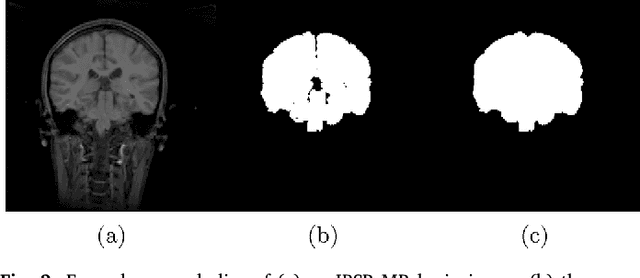
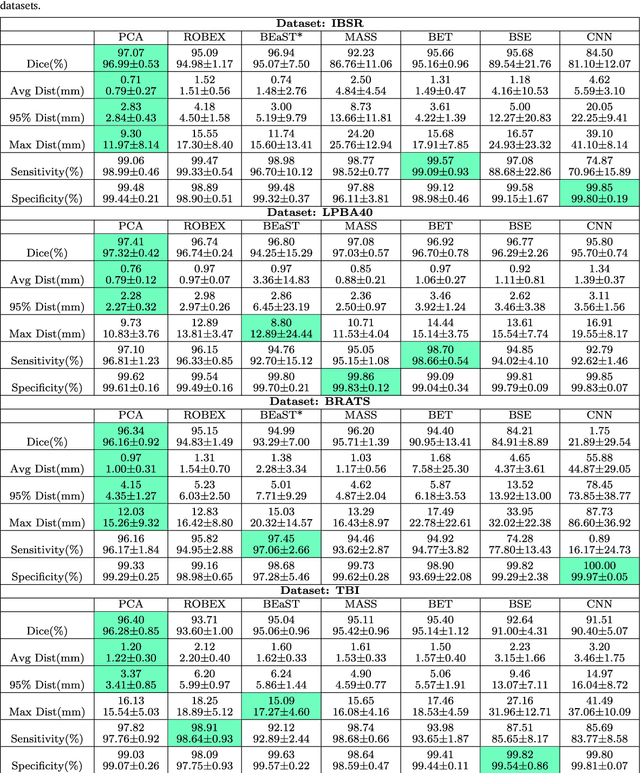
Brain extraction from images is a common pre-processing step. Many approaches exist, but they are frequently only designed to perform brain extraction from images without strong pathologies. Extracting the brain from images with strong pathologies, for example, the presence of a tumor or of a traumatic brain injury, is challenging. In such cases, tissue appearance may deviate from normal tissue and violates algorithmic assumptions for these approaches; hence, the brain may not be correctly extracted. This paper proposes a brain extraction approach which can explicitly account for pathologies by jointly modeling normal tissue and pathologies. Specifically, our model uses a three-part image decomposition: (1) normal tissue appearance is captured by principal component analysis, (2) pathologies are captured via a total variation term, and (3) non-brain tissue is captured by a sparse term. Decomposition and image registration steps are alternated to allow statistical modeling in a fixed atlas space. As a beneficial side effect, the model allows for the identification of potential pathologies and the reconstruction of a quasi-normal image in atlas space. We demonstrate the effectiveness of our method on four datasets: the IBSR and LPBA40 datasets which show normal images, the BRATS dataset containing images with brain tumors and a dataset containing clinical TBI images. We compare the performance with other popular models: ROBEX, BEaST, MASS, BET, BSE and a recently proposed deep learning approach. Our model performs better than these competing methods on all four datasets. Specifically, our model achieves the best median (97.11) and mean (96.88) Dice scores over all datasets. The two best performing competitors, ROBEX and MASS, achieve scores of 96.23/95.62 and 96.67/94.25 respectively. Hence, our approach is an effective method for high quality brain extraction on a wide variety of images.
Calipso: Physics-based Image and Video Editing through CAD Model Proxies
Aug 12, 2017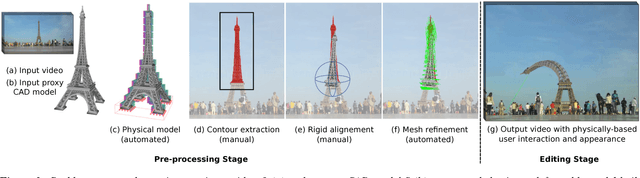
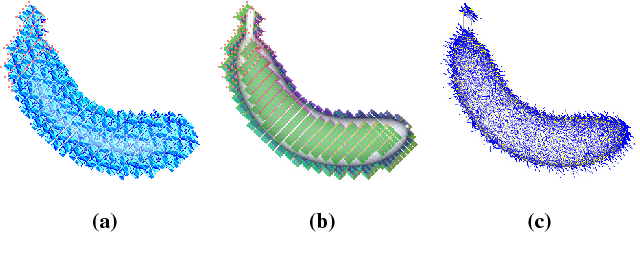
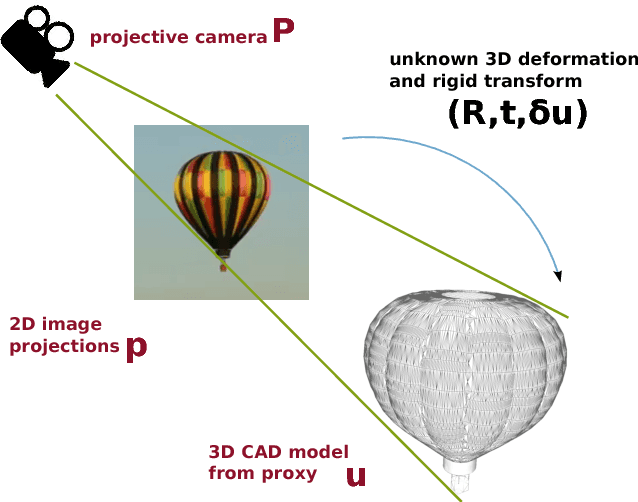
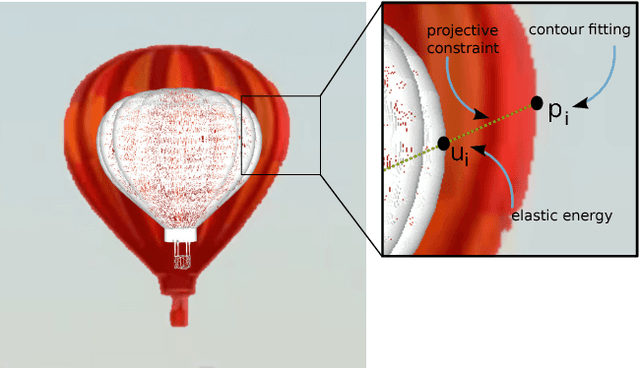
We present Calipso, an interactive method for editing images and videos in a physically-coherent manner. Our main idea is to realize physics-based manipulations by running a full physics simulation on proxy geometries given by non-rigidly aligned CAD models. Running these simulations allows us to apply new, unseen forces to move or deform selected objects, change physical parameters such as mass or elasticity, or even add entire new objects that interact with the rest of the underlying scene. In Calipso, the user makes edits directly in 3D; these edits are processed by the simulation and then transfered to the target 2D content using shape-to-image correspondences in a photo-realistic rendering process. To align the CAD models, we introduce an efficient CAD-to-image alignment procedure that jointly minimizes for rigid and non-rigid alignment while preserving the high-level structure of the input shape. Moreover, the user can choose to exploit image flow to estimate scene motion, producing coherent physical behavior with ambient dynamics. We demonstrate Calipso's physics-based editing on a wide range of examples producing myriad physical behavior while preserving geometric and visual consistency.
Online Active Proposal Set Generation for Weakly Supervised Object Detection
Jan 20, 2021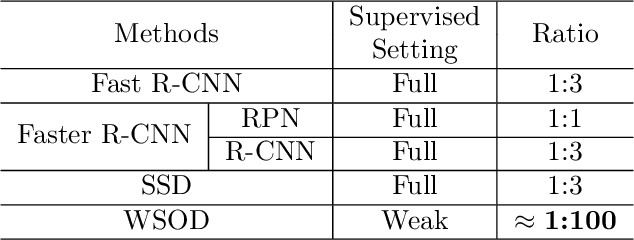

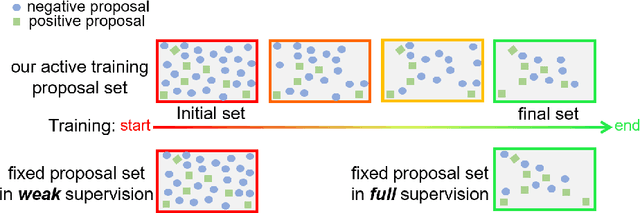
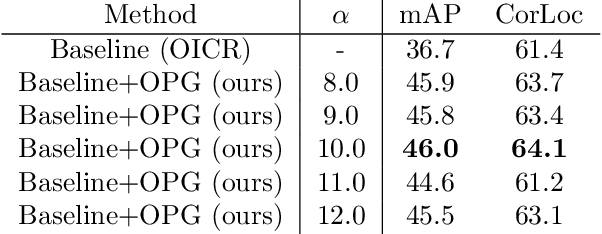
To reduce the manpower consumption on box-level annotations, many weakly supervised object detection methods which only require image-level annotations, have been proposed recently. The training process in these methods is formulated into two steps. They firstly train a neural network under weak supervision to generate pseudo ground truths (PGTs). Then, these PGTs are used to train another network under full supervision. Compared with fully supervised methods, the training process in weakly supervised methods becomes more complex and time-consuming. Furthermore, overwhelming negative proposals are involved at the first step. This is neglected by most methods, which makes the training network biased towards to negative proposals and thus degrades the quality of the PGTs, limiting the training network performance at the second step. Online proposal sampling is an intuitive solution to these issues. However, lacking of adequate labeling, a simple online proposal sampling may make the training network stuck into local minima. To solve this problem, we propose an Online Active Proposal Set Generation (OPG) algorithm. Our OPG algorithm consists of two parts: Dynamic Proposal Constraint (DPC) and Proposal Partition (PP). DPC is proposed to dynamically determine different proposal sampling strategy according to the current training state. PP is used to score each proposal, part proposals into different sets and generate an active proposal set for the network optimization. Through experiments, our proposed OPG shows consistent and significant improvement on both datasets PASCAL VOC 2007 and 2012, yielding comparable performance to the state-of-the-art results.
Nighttime sky/cloud image segmentation
May 30, 2017


Imaging the atmosphere using ground-based sky cameras is a popular approach to study various atmospheric phenomena. However, it usually focuses on the daytime. Nighttime sky/cloud images are darker and noisier, and thus harder to analyze. An accurate segmentation of sky/cloud images is already challenging because of the clouds' non-rigid structure and size, and the lower and less stable illumination of the night sky increases the difficulty. Nonetheless, nighttime cloud imaging is essential in certain applications, such as continuous weather analysis and satellite communication. In this paper, we propose a superpixel-based method to segment nighttime sky/cloud images. We also release the first nighttime sky/cloud image segmentation database to the research community. The experimental results show the efficacy of our proposed algorithm for nighttime images.
HyperFaceNet: A Hyperspectral Face Recognition Method Based on Deep Fusion
Aug 02, 2020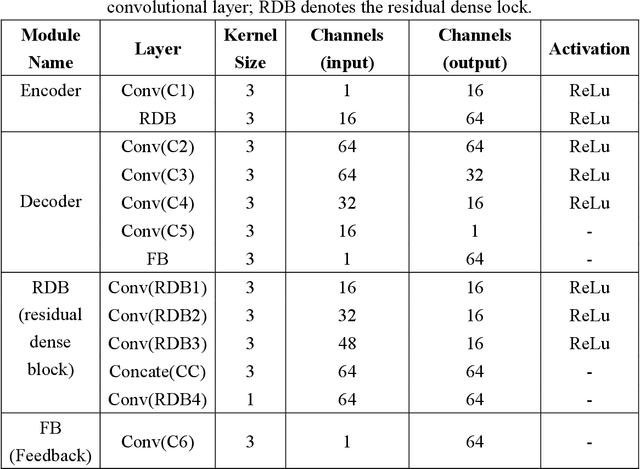
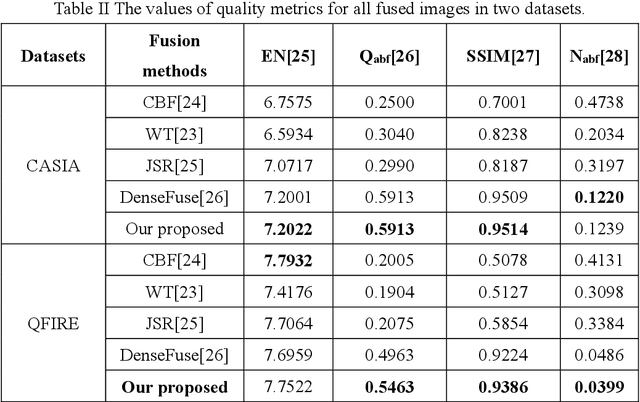
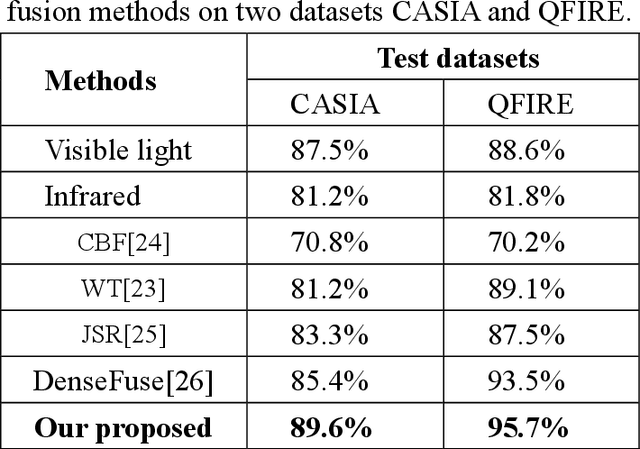
Face recognition has already been well studied under the visible light and the infrared,in both intra-spectral and cross-spectral cases. However, how to fuse different light bands, i.e., hyperspectral face recognition, is still an open research problem, which has the advantages of richer information retaining and all-weather functionality over single band face recognition. Among the very few works for hyperspectral face recognition, traditional non-deep learning techniques are largely used. Thus, we in this paper bring deep learning into the topic of hyperspectral face recognition, and propose a new fusion model (termed HyperFaceNet) especially for hyperspectral faces. The proposed fusion model is characterized by residual dense learning, a feedback style encoder and a recognition-oriented loss function. During the experiments, our method is proved to be of higher recognition rates than face recognition using either visible light or the infrared. Moreover, our fusion model is shown to be superior to other general-purposed image fusion methods including state-of-the-arts, in terms of both image quality and recognition performance.
Breaking certified defenses: Semantic adversarial examples with spoofed robustness certificates
Mar 19, 2020

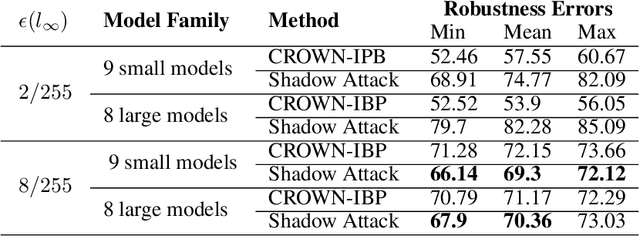

To deflect adversarial attacks, a range of "certified" classifiers have been proposed. In addition to labeling an image, certified classifiers produce (when possible) a certificate guaranteeing that the input image is not an $\ell_p$-bounded adversarial example. We present a new attack that exploits not only the labelling function of a classifier, but also the certificate generator. The proposed method applies large perturbations that place images far from a class boundary while maintaining the imperceptibility property of adversarial examples. The proposed "Shadow Attack" causes certifiably robust networks to mislabel an image and simultaneously produce a "spoofed" certificate of robustness.