 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
PatchMorph: A Stochastic Deep Learning Approach for Unsupervised 3D Brain Image Registration with Small Patches
Dec 12, 2023
We introduce "PatchMorph," an new stochastic deep learning algorithm tailored for unsupervised 3D brain image registration. Unlike other methods, our method uses compact patches of a constant small size to derive solutions that can combine global transformations with local deformations. This approach minimizes the memory footprint of the GPU during training, but also enables us to operate on numerous amounts of randomly overlapping small patches during inference to mitigate image and patch boundary problems. PatchMorph adeptly handles world coordinate transformations between two input images, accommodating variances in attributes such as spacing, array sizes, and orientations. The spatial resolution of patches transitions from coarse to fine, addressing both global and local attributes essential for aligning the images. Each patch offers a unique perspective, together converging towards a comprehensive solution. Experiments on human T1 MRI brain images and marmoset brain images from serial 2-photon tomography affirm PatchMorph's superior performance.
Stable Messenger: Steganography for Message-Concealed Image Generation
Dec 03, 2023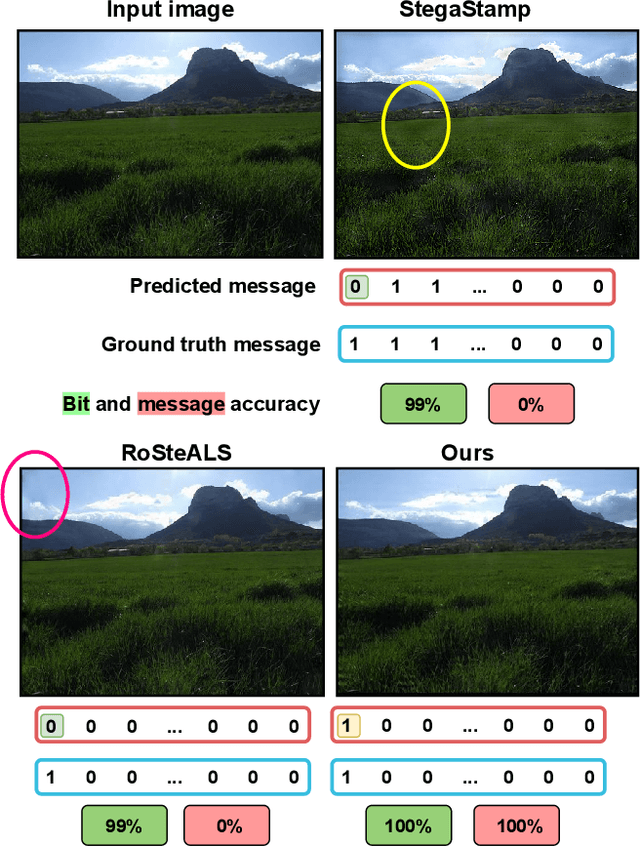
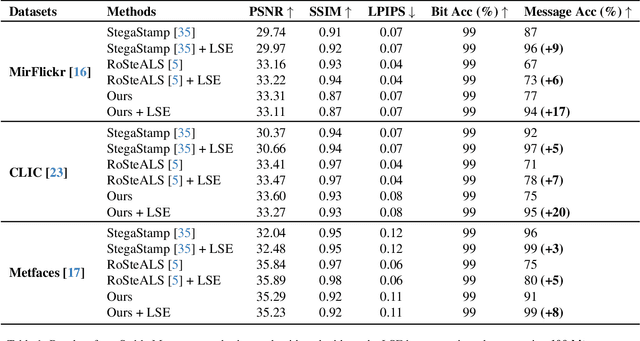
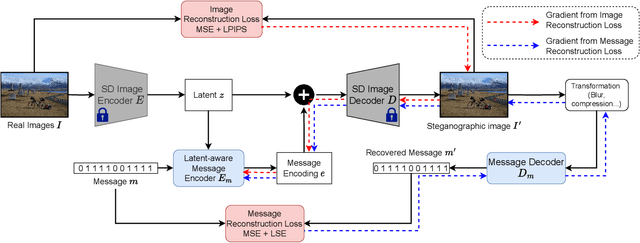

In the ever-expanding digital landscape, safeguarding sensitive information remains paramount. This paper delves deep into digital protection, specifically focusing on steganography. While prior research predominantly fixated on individual bit decoding, we address this limitation by introducing ``message accuracy'', a novel metric evaluating the entirety of decoded messages for a more holistic evaluation. In addition, we propose an adaptive universal loss tailored to enhance message accuracy, named Log-Sum-Exponential (LSE) loss, thereby significantly improving the message accuracy of recent approaches. Furthermore, we also introduce a new latent-aware encoding technique in our framework named \Approach, harnessing pretrained Stable Diffusion for advanced steganographic image generation, giving rise to a better trade-off between image quality and message recovery. Throughout experimental results, we have demonstrated the superior performance of the new LSE loss and latent-aware encoding technique. This comprehensive approach marks a significant step in evolving evaluation metrics, refining loss functions, and innovating image concealment techniques, aiming for more robust and dependable information protection.
3D Visibility-aware Generalizable Neural Radiance Fields for Interacting Hands
Jan 02, 2024Neural radiance fields (NeRFs) are promising 3D representations for scenes, objects, and humans. However, most existing methods require multi-view inputs and per-scene training, which limits their real-life applications. Moreover, current methods focus on single-subject cases, leaving scenes of interacting hands that involve severe inter-hand occlusions and challenging view variations remain unsolved. To tackle these issues, this paper proposes a generalizable visibility-aware NeRF (VA-NeRF) framework for interacting hands. Specifically, given an image of interacting hands as input, our VA-NeRF first obtains a mesh-based representation of hands and extracts their corresponding geometric and textural features. Subsequently, a feature fusion module that exploits the visibility of query points and mesh vertices is introduced to adaptively merge features of both hands, enabling the recovery of features in unseen areas. Additionally, our VA-NeRF is optimized together with a novel discriminator within an adversarial learning paradigm. In contrast to conventional discriminators that predict a single real/fake label for the synthesized image, the proposed discriminator generates a pixel-wise visibility map, providing fine-grained supervision for unseen areas and encouraging the VA-NeRF to improve the visual quality of synthesized images. Experiments on the Interhand2.6M dataset demonstrate that our proposed VA-NeRF outperforms conventional NeRFs significantly. Project Page: \url{https://github.com/XuanHuang0/VANeRF}.
MDD-UNet: Domain Adaptation for Medical Image Segmentation with Theoretical Guarantees, a Proof of Concept
Dec 19, 2023The current state-of-the art techniques for image segmentation are often based on U-Net architectures, a U-shaped encoder-decoder networks with skip connections. Despite the powerful performance, the architecture often does not perform well when used on data which has different characteristics than the data it was trained on. Many techniques for improving performance in the presence of domain shift have been developed, however typically only have loose connections to the theory of domain adaption. In this work, we propose an unsupervised domain adaptation framework for U-Nets with theoretical guarantees based on the Margin Disparity Discrepancy [1] called the MDD-UNet. We evaluate the proposed technique on the task of hippocampus segmentation, and find that the MDD-UNet is able to learn features which are domain-invariant with no knowledge about the labels in the target domain. The MDD-UNet improves performance over the standard U-Net on 11 out of 12 combinations of datasets. This work serves as a proof of concept by demonstrating an improvement on the U-Net in it's standard form without modern enhancements, which opens up a new avenue of studying domain adaptation for models with very large hypothesis spaces from both methodological and practical perspectives. Code is available at https://github.com/asbjrnmunk/mdd-unet.
EfficientSAM: Leveraged Masked Image Pretraining for Efficient Segment Anything
Dec 01, 2023Segment Anything Model (SAM) has emerged as a powerful tool for numerous vision applications. A key component that drives the impressive performance for zero-shot transfer and high versatility is a super large Transformer model trained on the extensive high-quality SA-1B dataset. While beneficial, the huge computation cost of SAM model has limited its applications to wider real-world applications. To address this limitation, we propose EfficientSAMs, light-weight SAM models that exhibits decent performance with largely reduced complexity. Our idea is based on leveraging masked image pretraining, SAMI, which learns to reconstruct features from SAM image encoder for effective visual representation learning. Further, we take SAMI-pretrained light-weight image encoders and mask decoder to build EfficientSAMs, and finetune the models on SA-1B for segment anything task. We perform evaluations on multiple vision tasks including image classification, object detection, instance segmentation, and semantic object detection, and find that our proposed pretraining method, SAMI, consistently outperforms other masked image pretraining methods. On segment anything task such as zero-shot instance segmentation, our EfficientSAMs with SAMI-pretrained lightweight image encoders perform favorably with a significant gain (e.g., ~4 AP on COCO/LVIS) over other fast SAM models.
Your Student is Better Than Expected: Adaptive Teacher-Student Collaboration for Text-Conditional Diffusion Models
Dec 28, 2023Knowledge distillation methods have recently shown to be a promising direction to speedup the synthesis of large-scale diffusion models by requiring only a few inference steps. While several powerful distillation methods were recently proposed, the overall quality of student samples is typically lower compared to the teacher ones, which hinders their practical usage. In this work, we investigate the relative quality of samples produced by the teacher text-to-image diffusion model and its distilled student version. As our main empirical finding, we discover that a noticeable portion of student samples exhibit superior fidelity compared to the teacher ones, despite the ``approximate'' nature of the student. Based on this finding, we propose an adaptive collaboration between student and teacher diffusion models for effective text-to-image synthesis. Specifically, the distilled model produces the initial sample, and then an oracle decides whether it needs further improvements with a slow teacher model. Extensive experiments demonstrate that the designed pipeline surpasses state-of-the-art text-to-image alternatives for various inference budgets in terms of human preference. Furthermore, the proposed approach can be naturally used in popular applications such as text-guided image editing and controllable generation.
Understanding (Un)Intended Memorization in Text-to-Image Generative Models
Dec 06, 2023Multimodal machine learning, especially text-to-image models like Stable Diffusion and DALL-E 3, has gained significance for transforming text into detailed images. Despite their growing use and remarkable generative capabilities, there is a pressing need for a detailed examination of these models' behavior, particularly with respect to memorization. Historically, memorization in machine learning has been context-dependent, with diverse definitions emerging from classification tasks to complex models like Large Language Models (LLMs) and Diffusion models. Yet, a definitive concept of memorization that aligns with the intricacies of text-to-image synthesis remains elusive. This understanding is vital as memorization poses privacy risks yet is essential for meeting user expectations, especially when generating representations of underrepresented entities. In this paper, we introduce a specialized definition of memorization tailored to text-to-image models, categorizing it into three distinct types according to user expectations. We closely examine the subtle distinctions between intended and unintended memorization, emphasizing the importance of balancing user privacy with the generative quality of the model outputs. Using the Stable Diffusion model, we offer examples to validate our memorization definitions and clarify their application.
Towards Improved Proxy-based Deep Metric Learning via Data-Augmented Domain Adaptation
Jan 01, 2024Deep Metric Learning (DML) plays an important role in modern computer vision research, where we learn a distance metric for a set of image representations. Recent DML techniques utilize the proxy to interact with the corresponding image samples in the embedding space. However, existing proxy-based DML methods focus on learning individual proxy-to-sample distance while the overall distribution of samples and proxies lacks attention. In this paper, we present a novel proxy-based DML framework that focuses on aligning the sample and proxy distributions to improve the efficiency of proxy-based DML losses. Specifically, we propose the Data-Augmented Domain Adaptation (DADA) method to adapt the domain gap between the group of samples and proxies. To the best of our knowledge, we are the first to leverage domain adaptation to boost the performance of proxy-based DML. We show that our method can be easily plugged into existing proxy-based DML losses. Our experiments on benchmarks, including the popular CUB-200-2011, CARS196, Stanford Online Products, and In-Shop Clothes Retrieval, show that our learning algorithm significantly improves the existing proxy losses and achieves superior results compared to the existing methods.
Learning Vision from Models Rivals Learning Vision from Data
Dec 28, 2023We introduce SynCLR, a novel approach for learning visual representations exclusively from synthetic images and synthetic captions, without any real data. We synthesize a large dataset of image captions using LLMs, then use an off-the-shelf text-to-image model to generate multiple images corresponding to each synthetic caption. We perform visual representation learning on these synthetic images via contrastive learning, treating images sharing the same caption as positive pairs. The resulting representations transfer well to many downstream tasks, competing favorably with other general-purpose visual representation learners such as CLIP and DINO v2 in image classification tasks. Furthermore, in dense prediction tasks such as semantic segmentation, SynCLR outperforms previous self-supervised methods by a significant margin, e.g., improving over MAE and iBOT by 6.2 and 4.3 mIoU on ADE20k for ViT-B/16.
DreamInpainter: Text-Guided Subject-Driven Image Inpainting with Diffusion Models
Dec 05, 2023This study introduces Text-Guided Subject-Driven Image Inpainting, a novel task that combines text and exemplar images for image inpainting. While both text and exemplar images have been used independently in previous efforts, their combined utilization remains unexplored. Simultaneously accommodating both conditions poses a significant challenge due to the inherent balance required between editability and subject fidelity. To tackle this challenge, we propose a two-step approach DreamInpainter. First, we compute dense subject features to ensure accurate subject replication. Then, we employ a discriminative token selection module to eliminate redundant subject details, preserving the subject's identity while allowing changes according to other conditions such as mask shape and text prompts. Additionally, we introduce a decoupling regularization technique to enhance text control in the presence of exemplar images. Our extensive experiments demonstrate the superior performance of our method in terms of visual quality, identity preservation, and text control, showcasing its effectiveness in the context of text-guided subject-driven image inpainting.