 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Image Captioning and Classification of Dangerous Situations
Nov 07, 2017
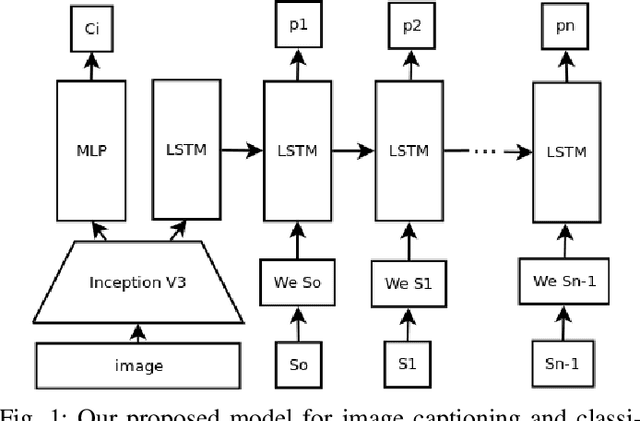



Current robot platforms are being employed to collaborate with humans in a wide range of domestic and industrial tasks. These environments require autonomous systems that are able to classify and communicate anomalous situations such as fires, injured persons, car accidents; or generally, any potentially dangerous situation for humans. In this paper we introduce an anomaly detection dataset for the purpose of robot applications as well as the design and implementation of a deep learning architecture that classifies and describes dangerous situations using only a single image as input. We report a classification accuracy of 97 % and METEOR score of 16.2. We will make the dataset publicly available after this paper is accepted.
Image Super-Resolution via Dual-State Recurrent Networks
May 07, 2018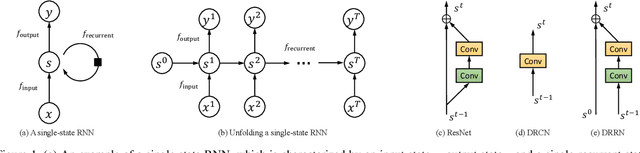
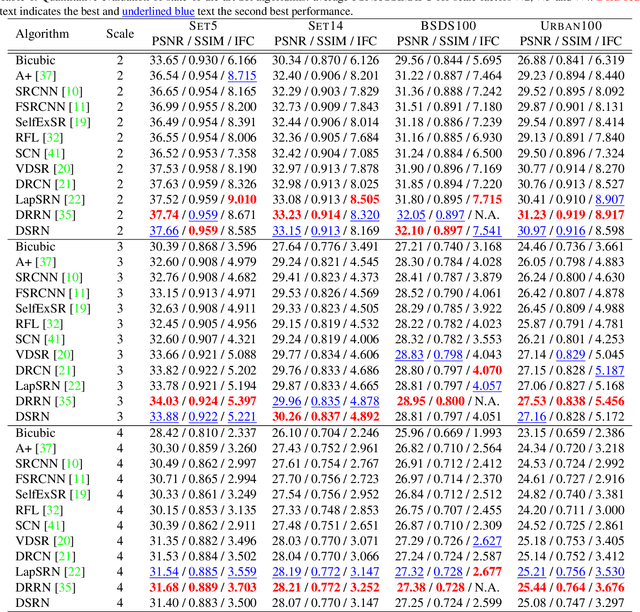
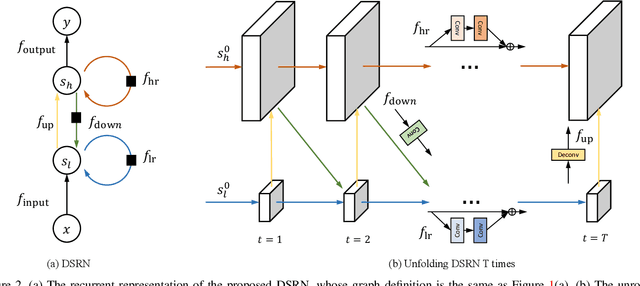
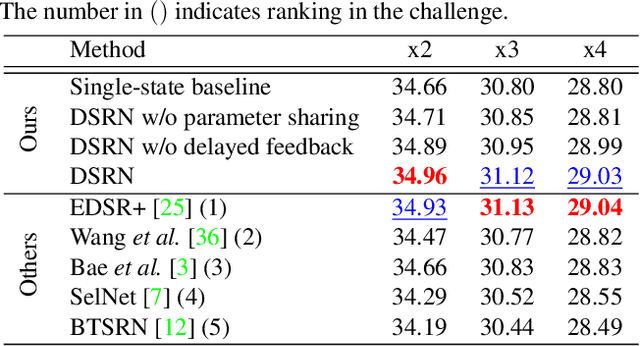
Advances in image super-resolution (SR) have recently benefited significantly from rapid developments in deep neural networks. Inspired by these recent discoveries, we note that many state-of-the-art deep SR architectures can be reformulated as a single-state recurrent neural network (RNN) with finite unfoldings. In this paper, we explore new structures for SR based on this compact RNN view, leading us to a dual-state design, the Dual-State Recurrent Network (DSRN). Compared to its single state counterparts that operate at a fixed spatial resolution, DSRN exploits both low-resolution (LR) and high-resolution (HR) signals jointly. Recurrent signals are exchanged between these states in both directions (both LR to HR and HR to LR) via delayed feedback. Extensive quantitative and qualitative evaluations on benchmark datasets and on a recent challenge demonstrate that the proposed DSRN performs favorably against state-of-the-art algorithms in terms of both memory consumption and predictive accuracy.
ActiveNet: A computer-vision based approach to determine lethargy
Oct 26, 2020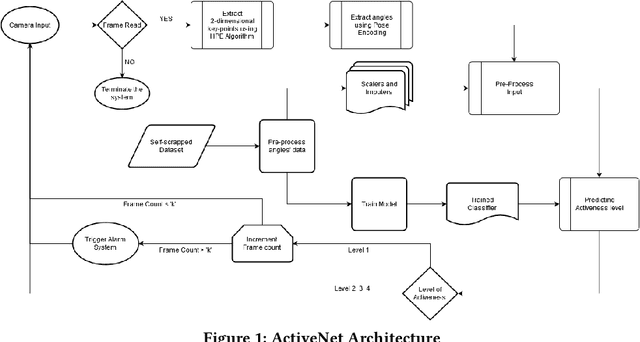


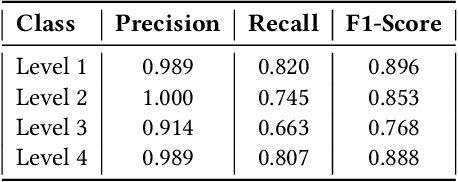
The outbreak of COVID-19 has forced everyone to stay indoors, fabricating a significant drop in physical activeness. Our work is constructed upon the idea to formulate a backbone mechanism, to detect levels of activeness in real-time, using a single monocular image of a target person. The scope can be generalized under many applications, be it in an interview, online classes, security surveillance, et cetera. We propose a Computer Vision based multi-stage approach, wherein the pose of a person is first detected, encoded with a novel approach, and then assessed by a classical machine learning algorithm to determine the level of activeness. An alerting system is wrapped around the approach to provide a solution to inhibit lethargy by sending notification alerts to individuals involved.
Solving the Same-Different Task with Convolutional Neural Networks
Jan 22, 2021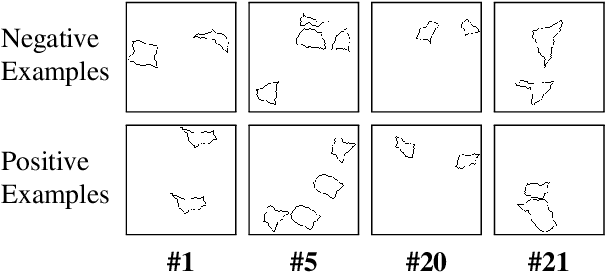
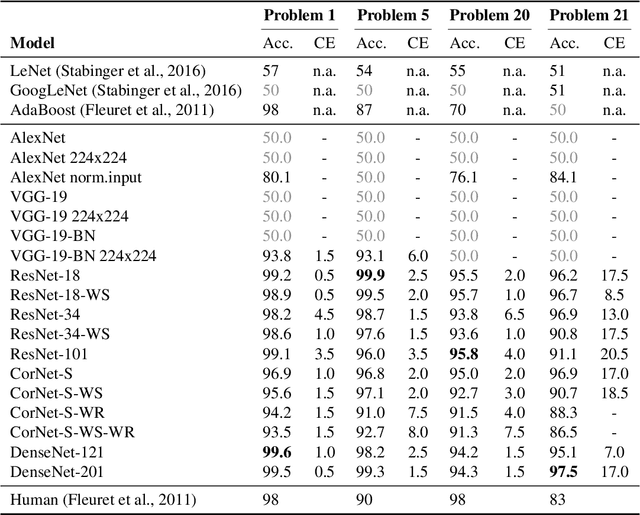
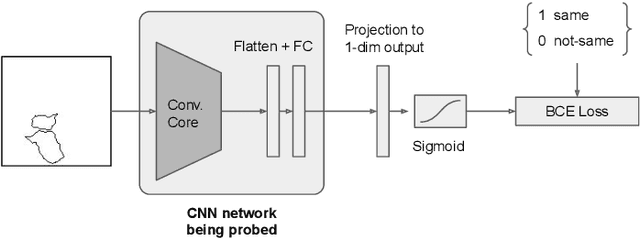
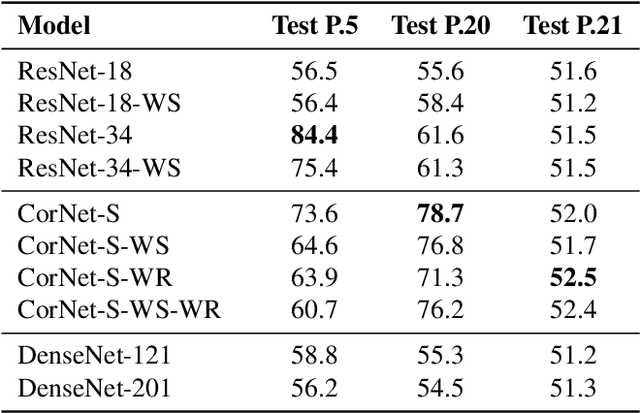
Deep learning demonstrated major abilities in solving many kinds of different real-world problems in computer vision literature. However, they are still strained by simple reasoning tasks that humans consider easy to solve. In this work, we probe current state-of-the-art convolutional neural networks on a difficult set of tasks known as the same-different problems. All the problems require the same prerequisite to be solved correctly: understanding if two random shapes inside the same image are the same or not. With the experiments carried out in this work, we demonstrate that residual connections, and more generally the skip connections, seem to have only a marginal impact on the learning of the proposed problems. In particular, we experiment with DenseNets, and we examine the contribution of residual and recurrent connections in already tested architectures, ResNet-18, and CorNet-S respectively. Our experiments show that older feed-forward networks, AlexNet and VGG, are almost unable to learn the proposed problems, except in some specific scenarios. We show that recently introduced architectures can converge even in the cases where the important parts of their architecture are removed. We finally carry out some zero-shot generalization tests, and we discover that in these scenarios residual and recurrent connections can have a stronger impact on the overall test accuracy. On four difficult problems from the SVRT dataset, we can reach state-of-the-art results with respect to the previous approaches, obtaining super-human performances on three of the four problems.
* Preprint of the paper published in Patter Recognition Letters (Elsevier)
Semantic Image Retrieval by Uniting Deep Neural Networks and Cognitive Architectures
Jun 14, 2018
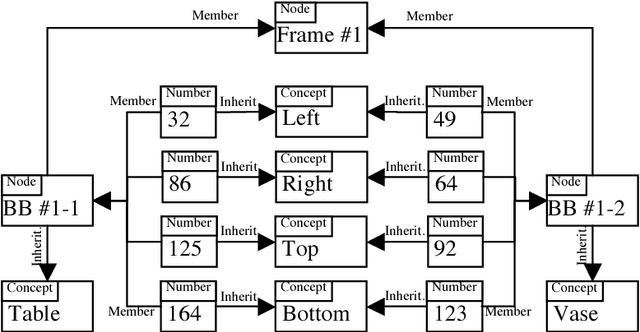
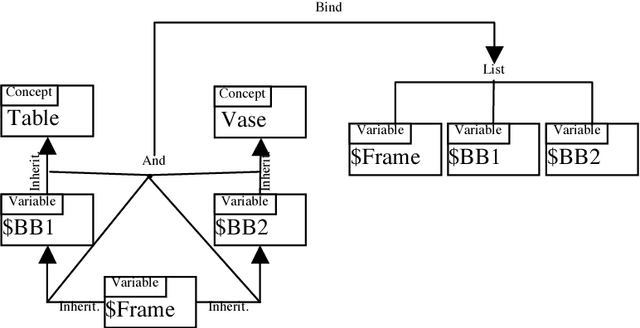

Image and video retrieval by their semantic content has been an important and challenging task for years, because it ultimately requires bridging the symbolic/subsymbolic gap. Recent successes in deep learning enabled detection of objects belonging to many classes greatly outperforming traditional computer vision techniques. However, deep learning solutions capable of executing retrieval queries are still not available. We propose a hybrid solution consisting of a deep neural network for object detection and a cognitive architecture for query execution. Specifically, we use YOLOv2 and OpenCog. Queries allowing the retrieval of video frames containing objects of specified classes and specified spatial arrangement are implemented.
3D-PSRNet: Part Segmented 3D Point Cloud Reconstruction From a Single Image
Sep 30, 2018
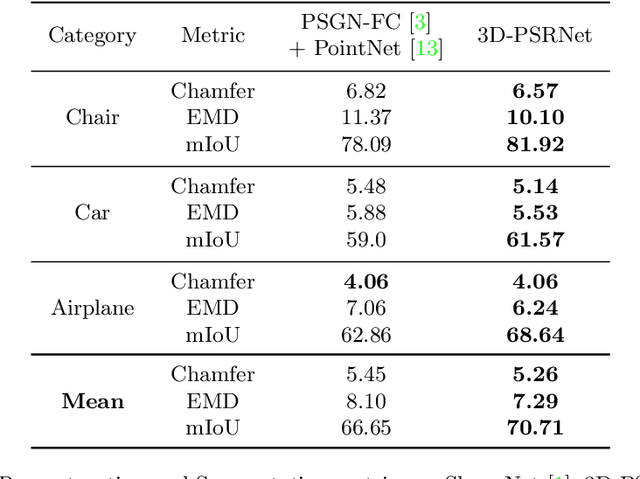
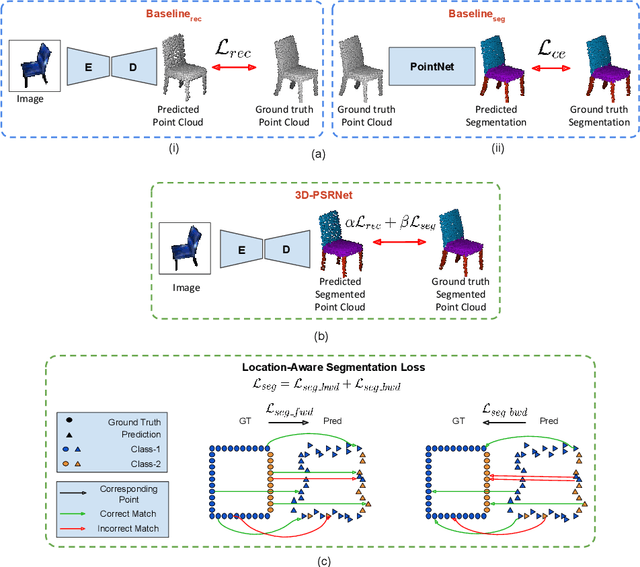
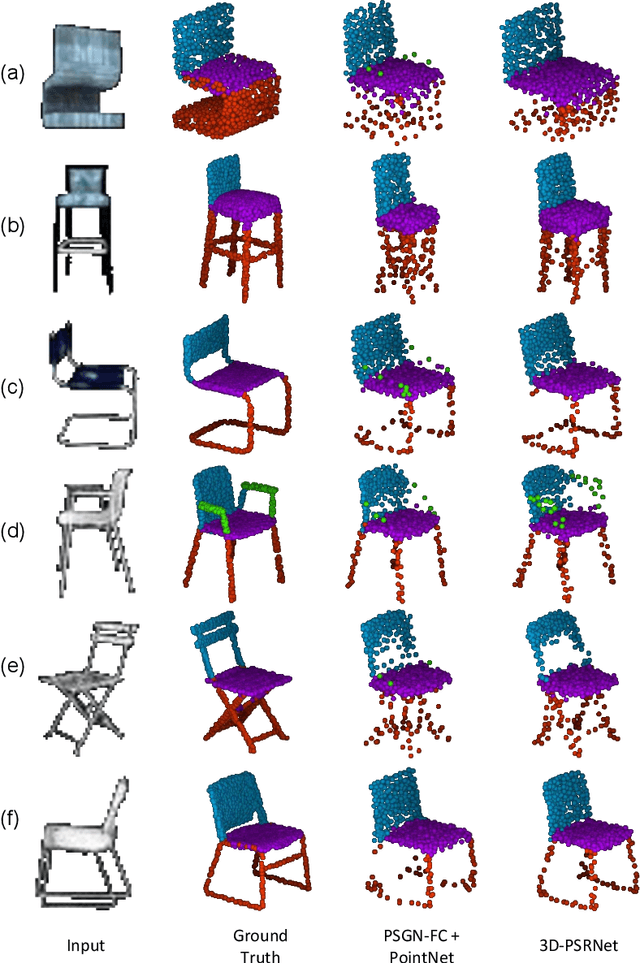
We propose a mechanism to reconstruct part annotated 3D point clouds of objects given just a single input image. We demonstrate that jointly training for both reconstruction and segmentation leads to improved performance in both the tasks, when compared to training for each task individually. The key idea is to propagate information from each task so as to aid the other during the training procedure. Towards this end, we introduce a location-aware segmentation loss in the training regime. We empirically show the effectiveness of the proposed loss in generating more faithful part reconstructions while also improving segmentation accuracy. We thoroughly evaluate the proposed approach on different object categories from the ShapeNet dataset to obtain improved results in reconstruction as well as segmentation.
Shallow Feature Based Dense Attention Network for Crowd Counting
Jun 17, 2020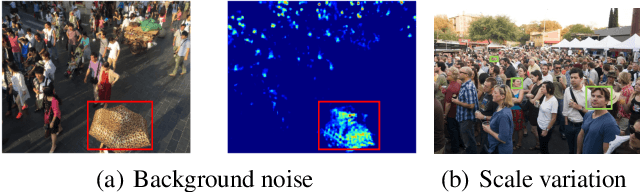
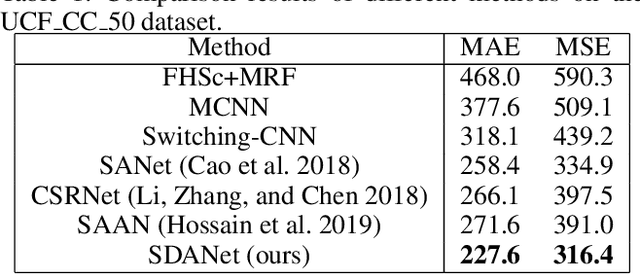
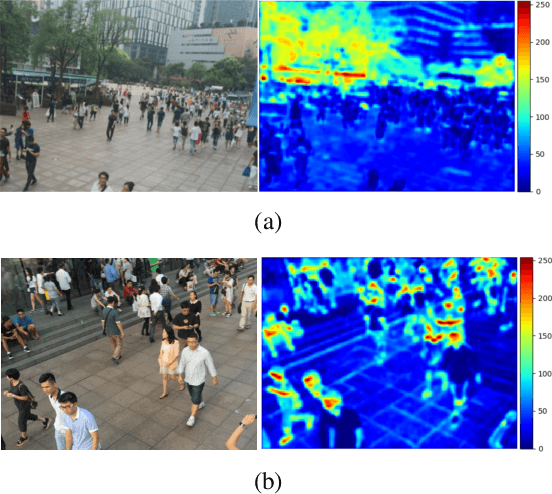
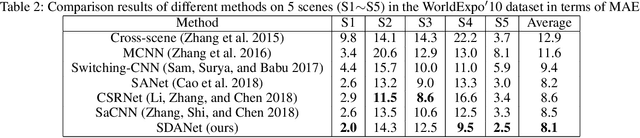
While the performance of crowd counting via deep learning has been improved dramatically in the recent years, it remains an ingrained problem due to cluttered backgrounds and varying scales of people within an image. In this paper, we propose a Shallow feature based Dense Attention Network (SDANet) for crowd counting from still images, which diminishes the impact of backgrounds via involving a shallow feature based attention model, and meanwhile, captures multi-scale information via densely connecting hierarchical image features. Specifically, inspired by the observation that backgrounds and human crowds generally have noticeably different responses in shallow features, we decide to build our attention model upon shallow-feature maps, which results in accurate background-pixel detection. Moreover, considering that the most representative features of people across different scales can appear in different layers of a feature extraction network, to better keep them all, we propose to densely connect hierarchical image features of different layers and subsequently encode them for estimating crowd density. Experimental results on three benchmark datasets clearly demonstrate the superiority of SDANet when dealing with different scenarios. Particularly, on the challenging UCF CC 50 dataset, our method outperforms other existing methods by a large margin, as is evident from a remarkable 11.9% Mean Absolute Error (MAE) drop of our SDANet.
XCAT-GAN for Synthesizing 3D Consistent Labeled Cardiac MR Images on Anatomically Variable XCAT Phantoms
Jul 27, 2020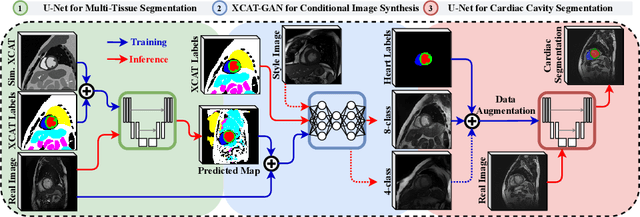
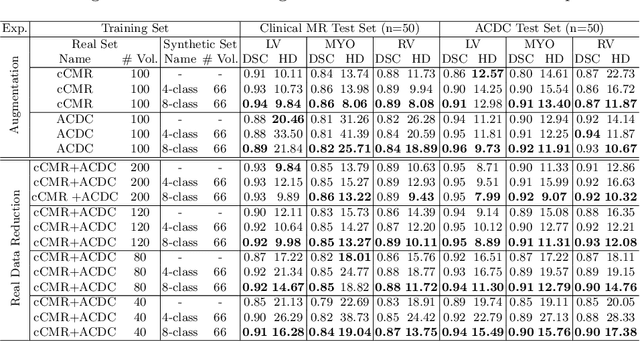
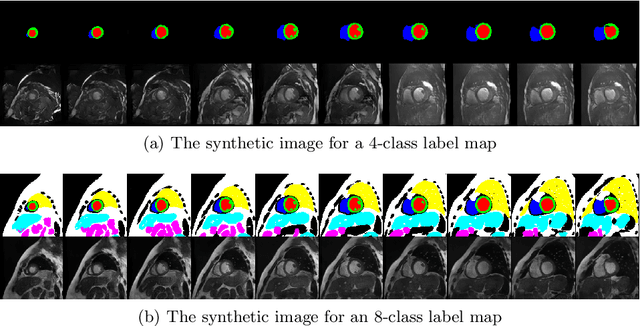
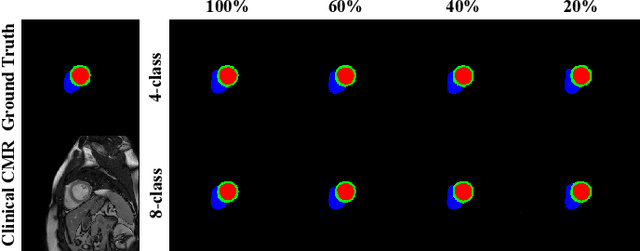
Generative adversarial networks (GANs) have provided promising data enrichment solutions by synthesizing high-fidelity images. However, generating large sets of labeled images with new anatomical variations remains unexplored. We propose a novel method for synthesizing cardiac magnetic resonance (CMR) images on a population of virtual subjects with a large anatomical variation, introduced using the 4D eXtended Cardiac and Torso (XCAT) computerized human phantom. We investigate two conditional image synthesis approaches grounded on a semantically-consistent mask-guided image generation technique: 4-class and 8-class XCAT-GANs. The 4-class technique relies on only the annotations of the heart; while the 8-class technique employs a predicted multi-tissue label map of the heart-surrounding organs and provides better guidance for our conditional image synthesis. For both techniques, we train our conditional XCAT-GAN with real images paired with corresponding labels and subsequently at the inference time, we substitute the labels with the XCAT derived ones. Therefore, the trained network accurately transfers the tissue-specific textures to the new label maps. By creating 33 virtual subjects of synthetic CMR images at the end-diastolic and end-systolic phases, we evaluate the usefulness of such data in the downstream cardiac cavity segmentation task under different augmentation strategies. Results demonstrate that even with only 20% of real images (40 volumes) seen during training, segmentation performance is retained with the addition of synthetic CMR images. Moreover, the improvement in utilizing synthetic images for augmenting the real data is evident through the reduction of Hausdorff distance up to 28% and an increase in the Dice score up to 5%, indicating a higher similarity to the ground truth in all dimensions.
Unsupervised Community Detection with a Potts Model Hamiltonian, an Efficient Algorithmic Solution, and Applications in Digital Pathology
Feb 05, 2020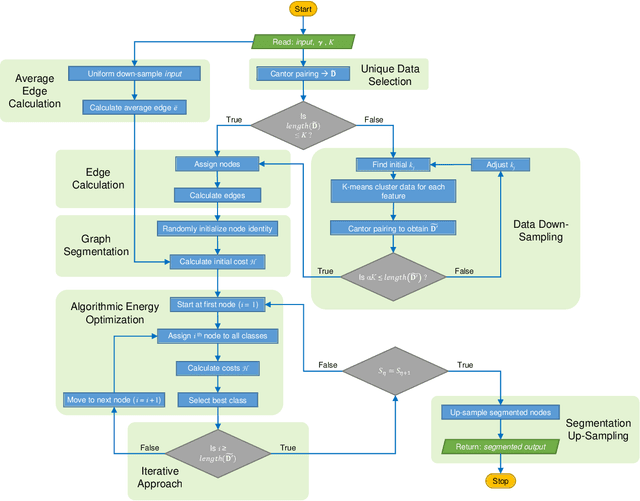
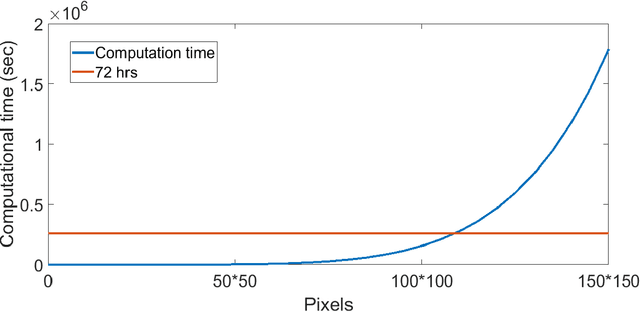
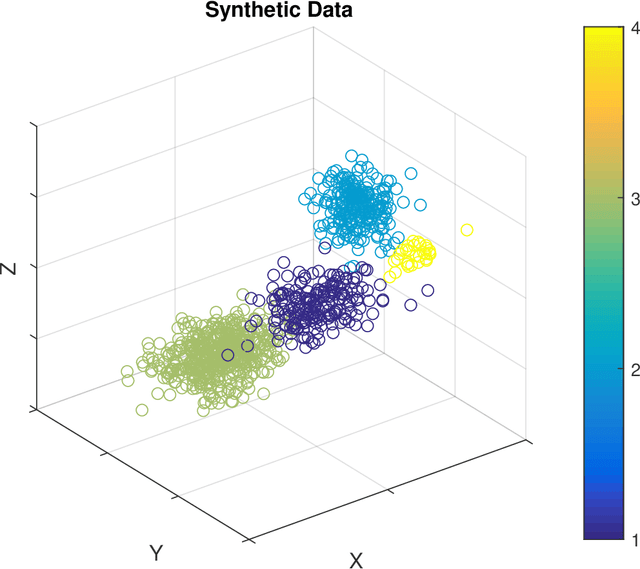
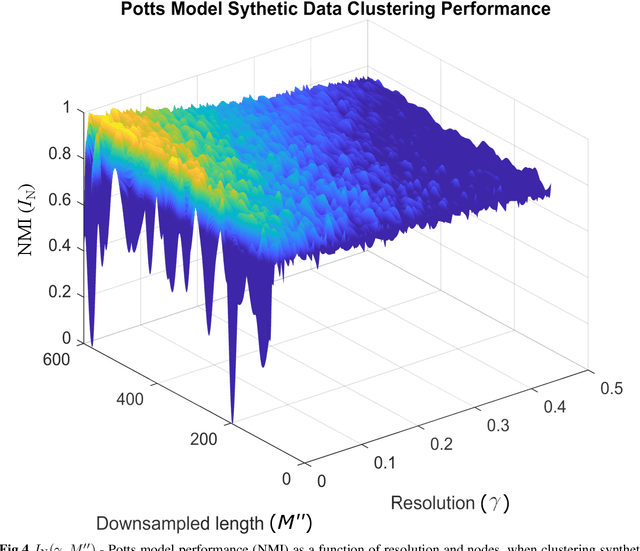
Unsupervised segmentation of large images using a Potts model Hamiltonian is unique in that segmentation is governed by a resolution parameter which scales the sensitivity to small clusters. Here, the input image is first modeled as a graph, which is then segmented by minimizing a Hamiltonian cost function defined on the graph and the respective segments. However, there exists no closed form solution of this optimization, and using previous iterative algorithmic solution techniques, the problem scales quadratically in the Input Length. Therefore, while Potts model segmentation gives accurate segmentation, it is grossly underutilized as an unsupervised learning technique. We propose a fast statistical down-sampling of input image pixels based on the respective color features, and a new iterative method to minimize the Potts model energy considering pixel to segment relationship. This method is generalizable and can be extended for image pixel texture features as well as spatial features. We demonstrate that this new method is highly efficient, and outperforms existing methods for Potts model based image segmentation. We demonstrate the application of our method in medical microscopy image segmentation; particularly, in segmenting renal glomerular micro-environment in renal pathology. Our method is not limited to image segmentation, and can be extended to any image/data segmentation/clustering task for arbitrary datasets with discrete features.
Blind Image Denoising via Dependent Dirichlet Process Tree
Jan 13, 2016
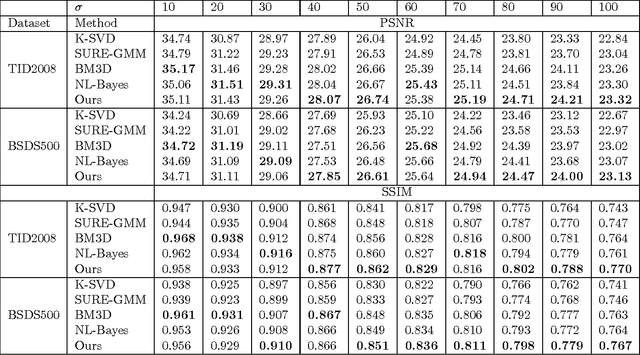
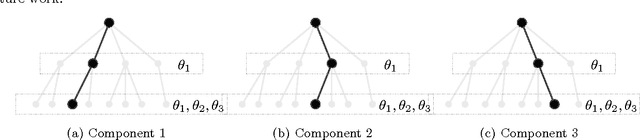
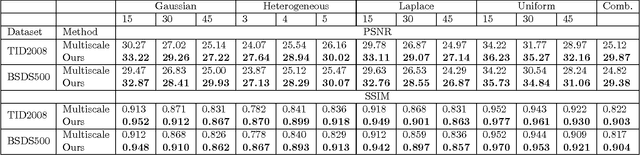
Most existing image denoising approaches assumed the noise to be homogeneous white Gaussian distributed with known intensity. However, in real noisy images, the noise models are usually unknown beforehand and can be much more complex. This paper addresses this problem and proposes a novel blind image denoising algorithm to recover the clean image from noisy one with the unknown noise model. To model the empirical noise of an image, our method introduces the mixture of Gaussian distribution, which is flexible enough to approximate different continuous distributions. The problem of blind image denoising is reformulated as a learning problem. The procedure is to first build a two-layer structural model for noisy patches and consider the clean ones as latent variable. To control the complexity of the noisy patch model, this work proposes a novel Bayesian nonparametric prior called "Dependent Dirichlet Process Tree" to build the model. Then, this study derives a variational inference algorithm to estimate model parameters and recover clean patches. We apply our method on synthesis and real noisy images with different noise models. Comparing with previous approaches, ours achieves better performance. The experimental results indicate the efficiency of the proposed algorithm to cope with practical image denoising tasks.