 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Playing to distraction: towards a robust training of CNN classifiers through visual explanation techniques
Dec 28, 2020
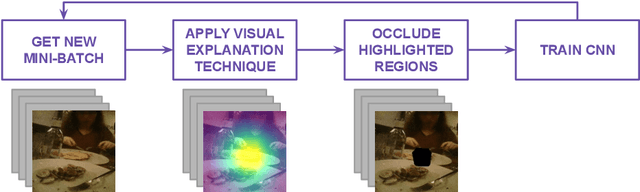
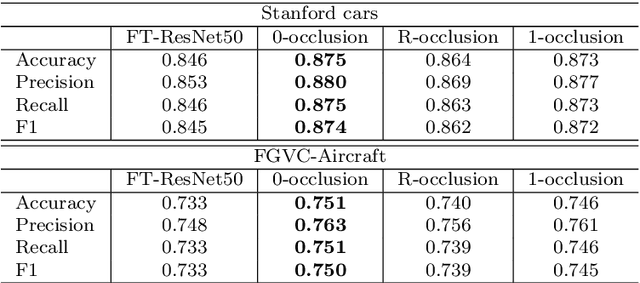

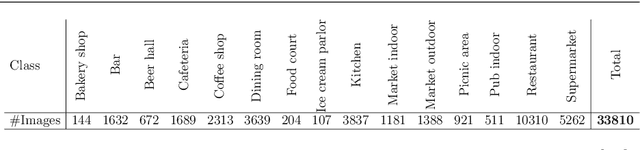
The field of deep learning is evolving in different directions, with still the need for more efficient training strategies. In this work, we present a novel and robust training scheme that integrates visual explanation techniques in the learning process. Unlike the attention mechanisms that focus on the relevant parts of images, we aim to improve the robustness of the model by making it pay attention to other regions as well. Broadly speaking, the idea is to distract the classifier in the learning process to force it to focus not only on relevant regions but also on those that, a priori, are not so informative for the discrimination of the class. We tested the proposed approach by embedding it into the learning process of a convolutional neural network for the analysis and classification of two well-known datasets, namely Stanford cars and FGVC-Aircraft. Furthermore, we evaluated our model on a real-case scenario for the classification of egocentric images, allowing us to obtain relevant information about peoples' lifestyles. In particular, we work on the challenging EgoFoodPlaces dataset, achieving state-of-the-art results with a lower level of complexity. The obtained results indicate the suitability of our proposed training scheme for image classification, improving the robustness of the final model.
Sampling possible reconstructions of undersampled acquisitions in MR imaging
Sep 30, 2020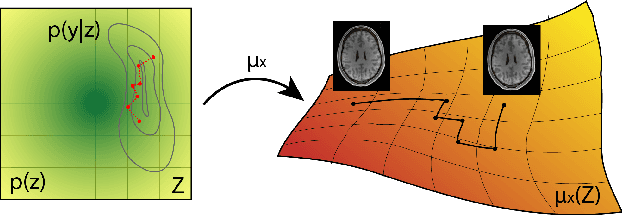
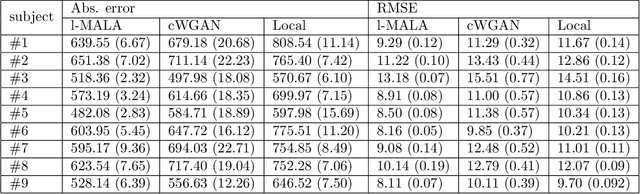
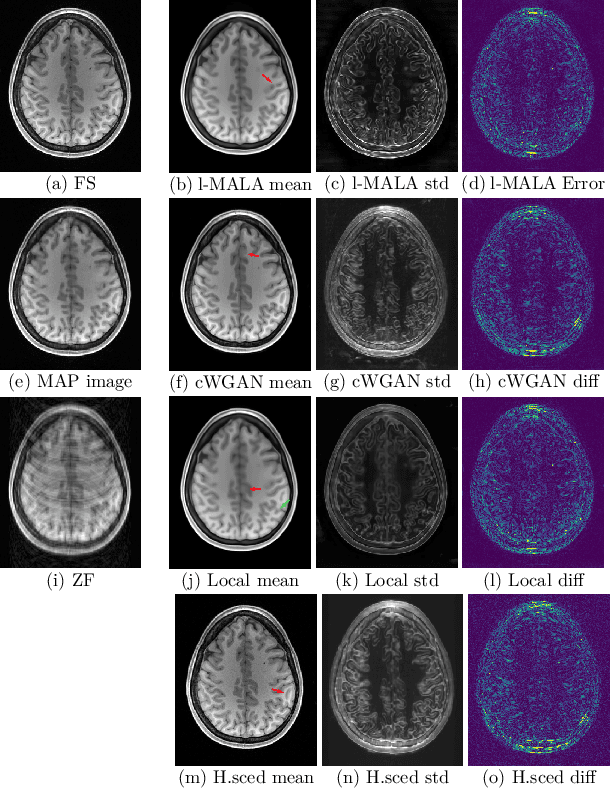
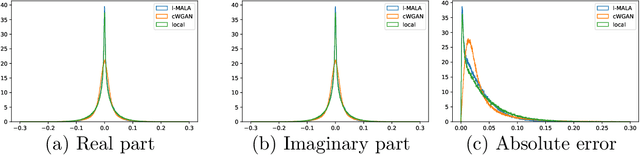
Undersampling the k-space during MR acquisitions saves time, however results in an ill-posed inversion problem, leading to an infinite set of images as possible solutions. Traditionally, this is tackled as a reconstruction problem by searching for a single "best" image out of this solution set according to some chosen regularization or prior. This approach, however, misses the possibility of other solutions and hence ignores the uncertainty in the inversion process. In this paper, we propose a method that instead returns multiple images which are possible under the acquisition model and the chosen prior. To this end, we introduce a low dimensional latent space and model the posterior distribution of the latent vectors given the acquisition data in k-space, from which we can sample in the latent space and obtain the corresponding images. We use a variational autoencoder for the latent model and the Metropolis adjusted Langevin algorithm for the sampling. This approach allows us to obtain multiple possible images and capture the uncertainty in the inversion process under the used prior. We evaluate our method on images from the Human Connectome Project dataset as well as in-house measured multi-coil images and compare to two different methods. The results indicate that the proposed method is capable of producing images that match the ground truth in regions where acquired k-space data is informative and construct different possible reconstructions, which show realistic structural variations, in regions where acquired k-space data is not informative. Keywords: Magnetic Resonance image reconstruction, uncertainty estimation, inverse problems, sampling, MCMC, deep learning, unsupervised learning.
Semi-supervised Learning by Latent Space Energy-Based Model of Symbol-Vector Coupling
Oct 19, 2020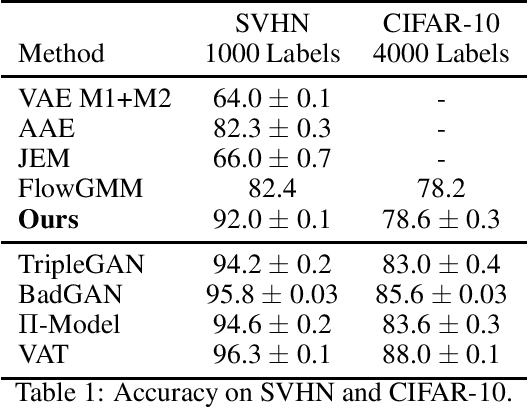
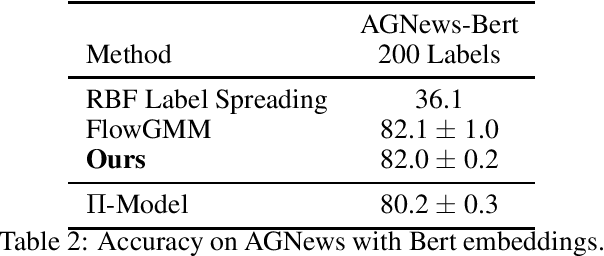
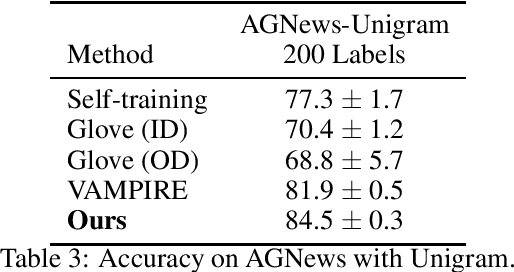
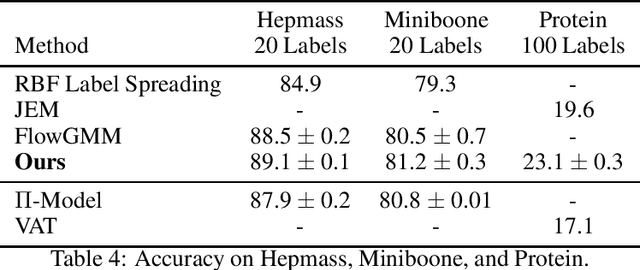
This paper proposes a latent space energy-based prior model for semi-supervised learning. The model stands on a generator network that maps a latent vector to the observed example. The energy term of the prior model couples the latent vector and a symbolic one-hot vector, so that classification can be based on the latent vector inferred from the observed example. In our learning method, the symbol-vector coupling, the generator network and the inference network are learned jointly. Our method is applicable to semi-supervised learning in various data domains such as image, text, and tabular data. Our experiments demonstrate that our method performs well on semi-supervised learning tasks.
ssEMnet: Serial-section Electron Microscopy Image Registration using a Spatial Transformer Network with Learned Features
Dec 05, 2017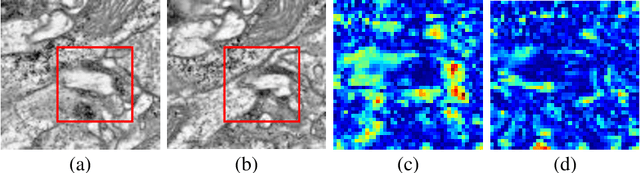
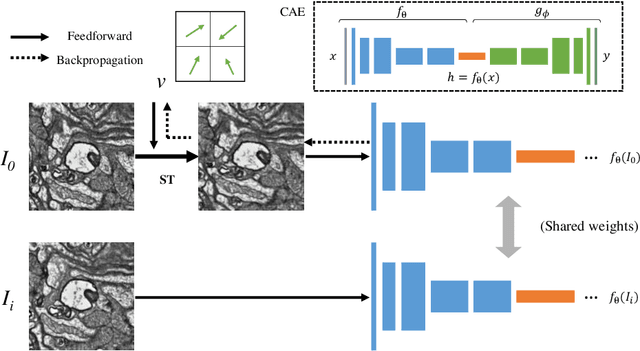

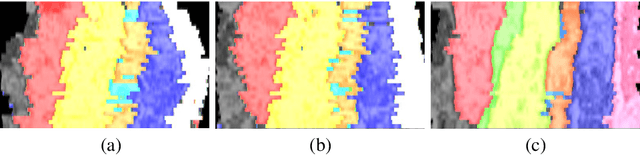
The alignment of serial-section electron microscopy (ssEM) images is critical for efforts in neuroscience that seek to reconstruct neuronal circuits. However, each ssEM plane contains densely packed structures that vary from one section to the next, which makes matching features across images a challenge. Advances in deep learning has resulted in unprecedented performance in similar computer vision problems, but to our knowledge, they have not been successfully applied to ssEM image co-registration. In this paper, we introduce a novel deep network model that combines a spatial transformer for image deformation and a convolutional autoencoder for unsupervised feature learning for robust ssEM image alignment. This results in improved accuracy and robustness while requiring substantially less user intervention than conventional methods. We evaluate our method by comparing registration quality across several datasets.
Vision-Based Shape Reconstruction of Soft Continuum Arms Using a Geometric Strain Parametrization
Nov 18, 2020
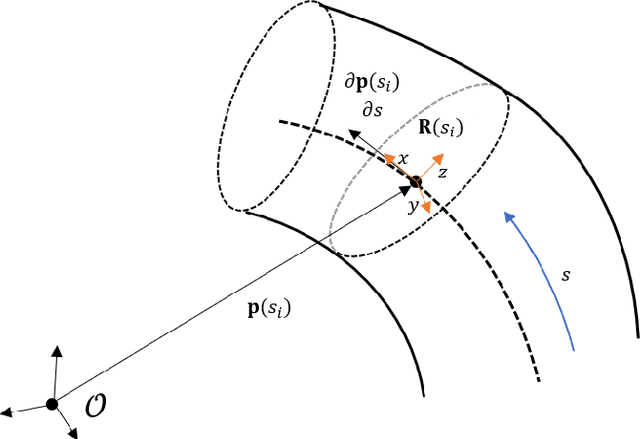

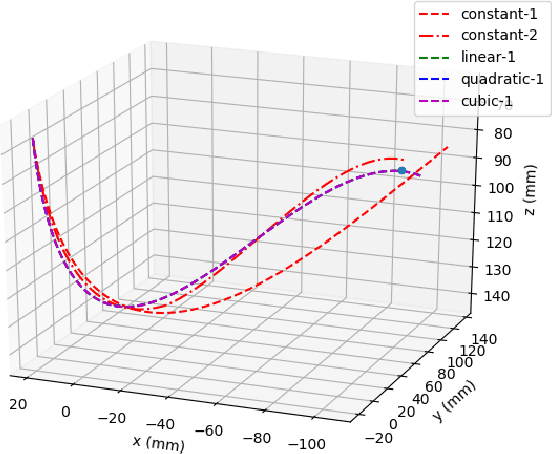
Interest in soft continuum arms has increased as their inherent material elasticity enables safe and adaptive interactions with the environment. However to achieve full autonomy in these arms, accurate three-dimensional shape sensing is needed. Vision-based solutions have been found to be effective in estimating the shape of soft continuum arms. In this paper, a vision-based shape estimator that utilizes a geometric strain based representation for the soft continuum arm's shape, is proposed. This representation reduces the dimension of the curved shape to a finite set of strain basis functions, thereby allowing for efficient optimization for the shape that best fits the observed image. Experimental results demonstrate the effectiveness of the proposed approach in estimating the end effector with accuracy less than the soft arm's radius. Multiple basis functions are also analyzed and compared for the specific soft continuum arm in use.
Tabular GANs for uneven distribution
Oct 01, 2020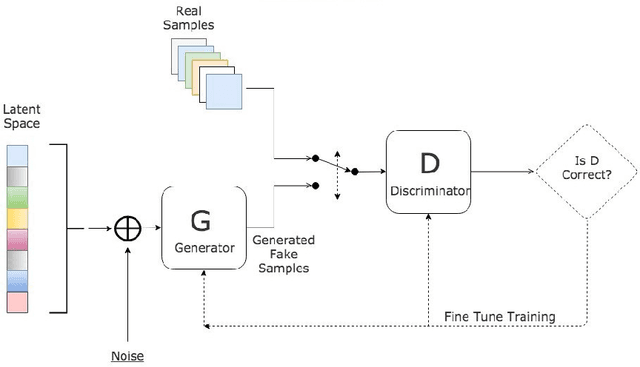
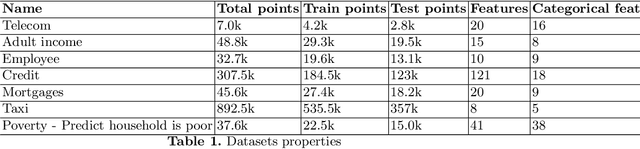
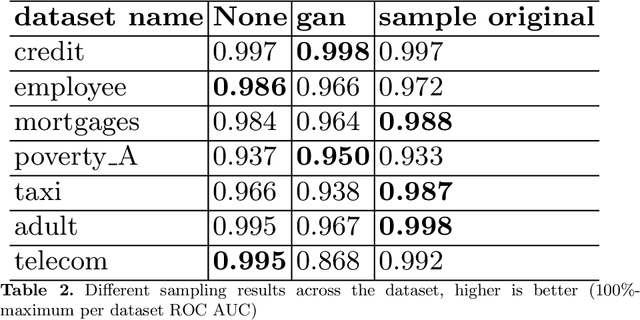
GANs are well known for success in the realistic image generation. However, they can be applied in tabular data generation as well. We will review and examine some recent papers about tabular GANs in action. We will generate data to make train distribution bring closer to the test. Then compare model performance trained on the initial train dataset, with trained on the train with GAN generated data, also we train the model by sampling train by adversarial training. We show that using GAN might be an option in case of uneven data distribution between train and test data.
Real-time Plant Health Assessment Via Implementing Cloud-based Scalable Transfer Learning On AWS DeepLens
Sep 10, 2020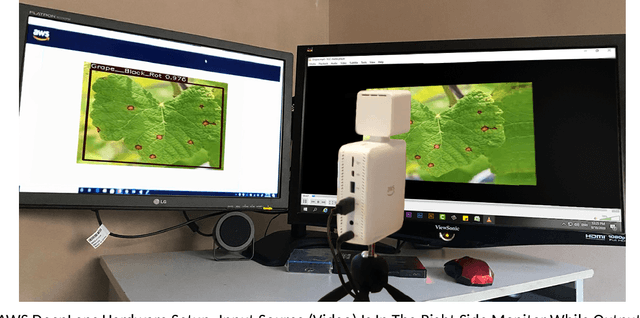
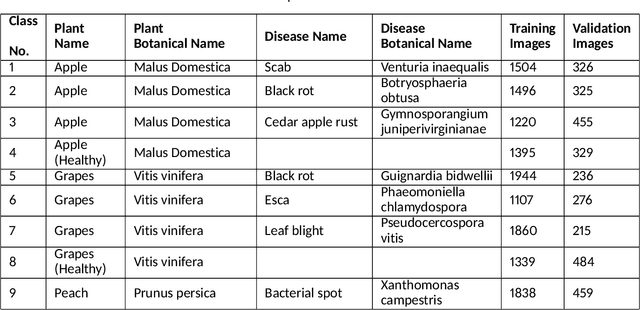
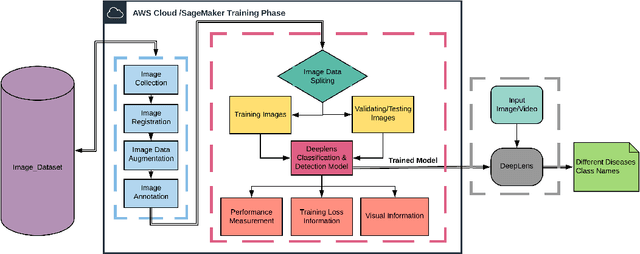

In the Agriculture sector, control of plant leaf diseases is crucial as it influences the quality and production of plant species with an impact on the economy of any country. Therefore, automated identification and classification of plant leaf disease at an early stage is essential to reduce economic loss and to conserve the specific species. Previously, to detect and classify plant leaf disease, various Machine Learning models have been proposed; however, they lack usability due to hardware incompatibility, limited scalability and inefficiency in practical usage. Our proposed DeepLens Classification and Detection Model (DCDM) approach deal with such limitations by introducing automated detection and classification of the leaf diseases in fruits (apple, grapes, peach and strawberry) and vegetables (potato and tomato) via scalable transfer learning on AWS SageMaker and importing it on AWS DeepLens for real-time practical usability. Cloud integration provides scalability and ubiquitous access to our approach. Our experiments on extensive image data set of healthy and unhealthy leaves of fruits and vegetables showed an accuracy of 98.78% with a real-time diagnosis of plant leaves diseases. We used forty thousand images for the training of deep learning model and then evaluated it on ten thousand images. The process of testing an image for disease diagnosis and classification using AWS DeepLens on average took 0.349s, providing disease information to the user in less than a second.
A Novel Approach Towards Clustering Based Image Segmentation
Jun 04, 2015In computer vision, image segmentation is always selected as a major research topic by researchers. Due to its vital rule in image processing, there always arises the need of a better image segmentation method. Clustering is an unsupervised study with its application in almost every field of science and engineering. Many researchers used clustering in image segmentation process. But still there requires improvement of such approaches. In this paper, a novel approach for clustering based image segmentation is proposed. Here, we give importance on color space and choose lab for this task. The famous hard clustering algorithm K-means is used, but as its performance is dependent on choosing a proper distance measure, so, we go for cosine distance measure. Then the segmented image is filtered with sobel filter. The filtered image is analyzed with marker watershed algorithm to have the final segmented result of our original image. The MSE and PSNR values are evaluated to observe the performance.
MirrorNet: A Deep Bayesian Approach to Reflective 2D Pose Estimation from Human Images
Apr 08, 2020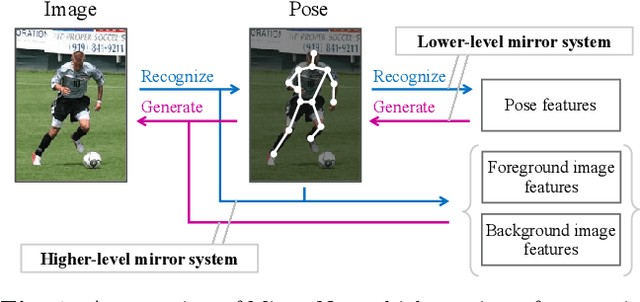

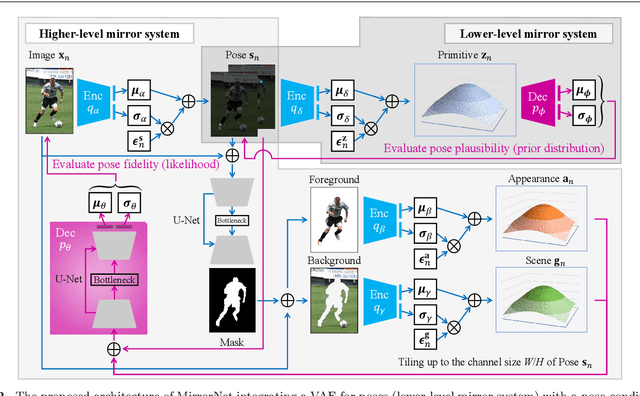
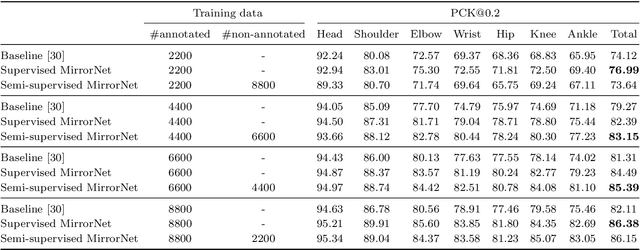
This paper proposes a statistical approach to 2D pose estimation from human images. The main problems with the standard supervised approach, which is based on a deep recognition (image-to-pose) model, are that it often yields anatomically implausible poses, and its performance is limited by the amount of paired data. To solve these problems, we propose a semi-supervised method that can make effective use of images with and without pose annotations. Specifically, we formulate a hierarchical generative model of poses and images by integrating a deep generative model of poses from pose features with that of images from poses and image features. We then introduce a deep recognition model that infers poses from images. Given images as observed data, these models can be trained jointly in a hierarchical variational autoencoding (image-to-pose-to-feature-to-pose-to-image) manner. The results of experiments show that the proposed reflective architecture makes estimated poses anatomically plausible, and the performance of pose estimation improved by integrating the recognition and generative models and also by feeding non-annotated images.
A Simple Framework to Leverage State-Of-The-Art Single-Image Super-Resolution Methods to Restore Light Fields
Sep 27, 2018

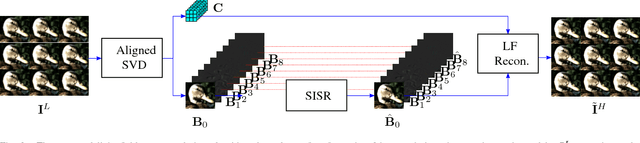
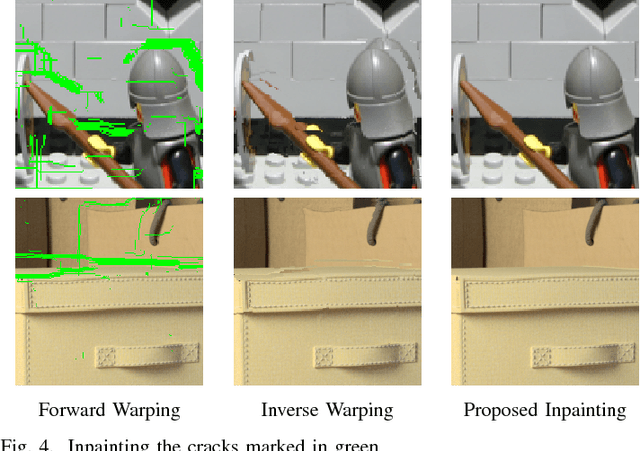
Plenoptic cameras offer a cost effective solution to capture light fields by multiplexing multiple views on a single image sensor. However, the high angular resolution is achieved at the expense of reducing the spatial resolution of each view by orders of magnitude compared to the raw sensor image. While light field super-resolution is still at an early stage, the field of single image super-resolution (SISR) has recently known significant advances with the use of deep learning techniques. This paper describes a simple framework allowing us to leverage state-of-the-art SISR techniques into light fields, while taking into account specific light field geometrical constraints. The idea is to first compute a representation compacting most of the light field energy into as few components as possible. This is achieved by aligning the light field using optical flows and then by decomposing the aligned light field using singular value decomposition (SVD). The principal basis captures the information that is coherent across all the views, while the other basis contain the high angular frequencies. Super-resolving this principal basis using an SISR method allows us to super-resolve all the information that is coherent across the entire light field. This framework allows the proposed light field super-resolution method to inherit the benefits of the SISR method used. Experimental results show that the proposed method is competitive, and most of the time superior, to recent light field super-resolution methods in terms of both PSNR and SSIM quality metrics, with a lower complexity.