 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deep Learning Based Brain Tumor Segmentation: A Survey
Jul 18, 2020

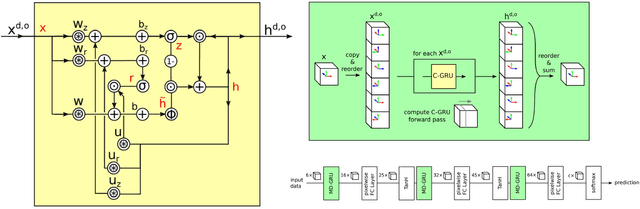
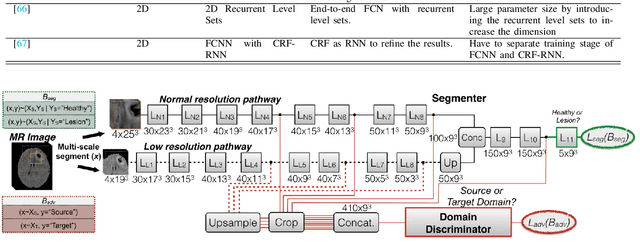
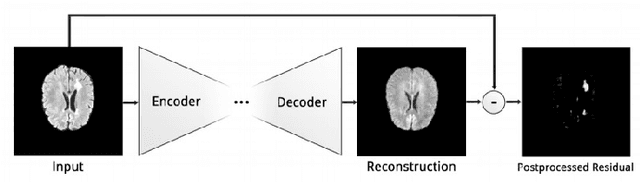
Brain tumor segmentation is a challenging problem in medical image analysis. The goal of brain tumor segmentation is to generate accurate delineation of brain tumor regions with correctly located masks. In recent years, deep learning methods have shown very promising performance in solving various computer vision problems, such as image classification, object detection and semantic segmentation. A number of deep learning based methods have been applied to brain tumor segmentation and achieved impressive system performance. Considering state-of-the-art technologies and their performance, the purpose of this paper is to provide a comprehensive survey of recently developed deep learning based brain tumor segmentation techniques. The established works included in this survey extensively cover technical aspects such as the strengths and weaknesses of different approaches, pre- and post-processing frameworks, datasets and evaluation metrics. Finally, we conclude this survey by discussing the potential development in future research work.
A note on patch-based low-rank minimization for fast image denoising
Feb 21, 2018
Patch-based low-rank minimization for image processing attracts much attention in recent years. The minimization of the matrix rank coupled with the Frobenius norm data fidelity can be solved by the hard thresholding filter with principle component analysis (PCA) or singular value decomposition (SVD). Based on this idea, we propose a patch-based low-rank minimization method for image denoising. The main denoising process is stated in three equivalent way: PCA, SVD and low-rank minimization. Compared to recent patch-based sparse representation methods, experiments demonstrate that the proposed method is rather rapid, and it is effective for a variety of natural grayscale images and color images, especially for texture parts in images. Further improvements of this method are also given. In addition, due to the simplicity of this method, we could provide an explanation of the choice of the threshold parameter, estimation of PSNR values, and give other insights into this method.
A Number Sense as an Emergent Property of the Manipulating Brain
Dec 08, 2020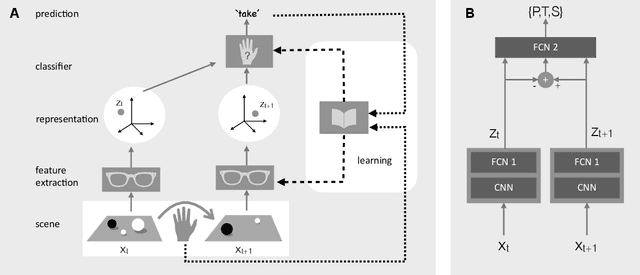
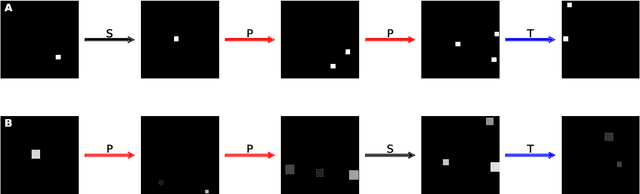
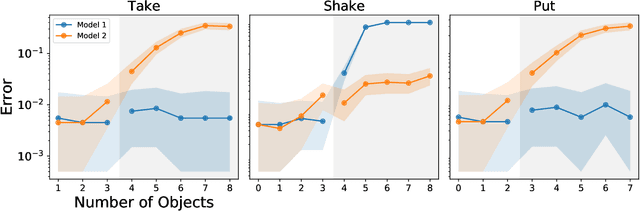
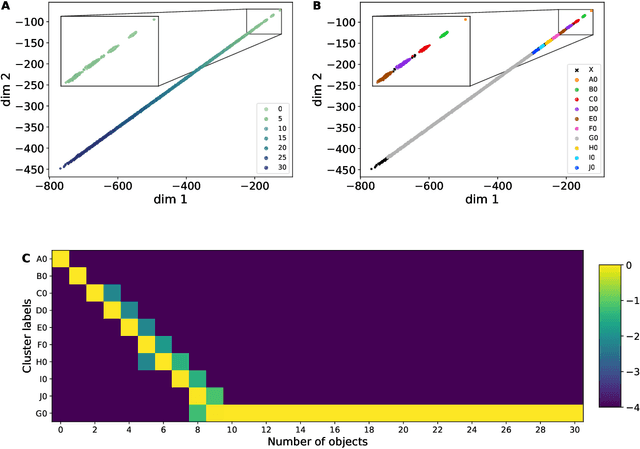
The ability to understand and manipulate numbers and quantities emerges during childhood, but the mechanism through which this ability is developed is still poorly understood. In particular, it is not known whether acquiring such a {\em number sense} is possible without supervision from a teacher. To explore this question, we propose a model in which spontaneous and undirected manipulation of small objects trains perception to predict the resulting scene changes. We find that, from this task, an image representation emerges that exhibits regularities that foreshadow numbers and quantity. These include distinct categories for zero and the first few natural numbers, a notion of order, and a signal that correlates with numerical quantity. As a result, our model acquires the ability to estimate the number of objects in the scene, as well as {\em subitization}, i.e. the ability to recognize at a glance the exact number of objects in small scenes. We conclude that important aspects of a facility with numbers and quantities may be learned without explicit teacher supervision.
A Spatially Constrained Deep Convolutional Neural Network for Nerve Fiber Segmentation in Corneal Confocal Microscopic Images using Inaccurate Annotations
Apr 20, 2020
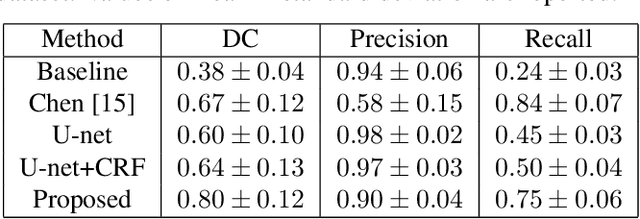
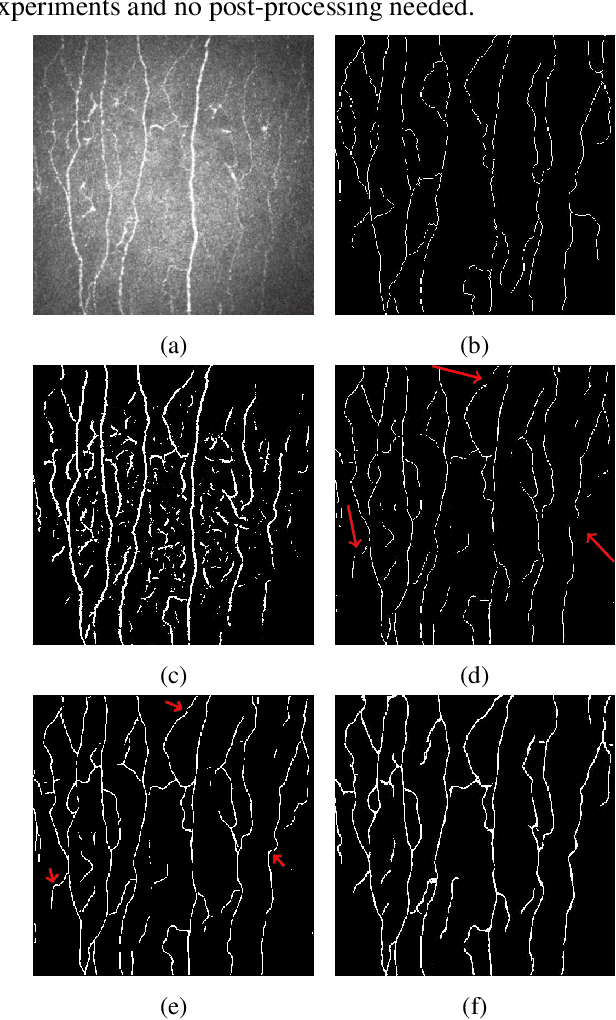
Semantic image segmentation is one of the most important tasks in medical image analysis. Most state-of-the-art deep learning methods require a large number of accurately annotated examples for model training. However, accurate annotation is difficult to obtain especially in medical applications. In this paper, we propose a spatially constrained deep convolutional neural network (DCNN) to achieve smooth and robust image segmentation using inaccurately annotated labels for training. In our proposed method, image segmentation is formulated as a graph optimization problem that is solved by a DCNN model learning process. The cost function to be optimized consists of a unary term that is calculated by cross entropy measurement and a pairwise term that is based on enforcing a local label consistency. The proposed method has been evaluated based on corneal confocal microscopic (CCM) images for nerve fiber segmentation, where accurate annotations are extremely difficult to be obtained. Based on both the quantitative result of a synthetic dataset and qualitative assessment of a real dataset, the proposed method has achieved superior performance in producing high quality segmentation results even with inaccurate labels for training.
* 4 pages, accepted for publication at IEEE International Symposium on Biomedical Imaging (ISBI) 2020
Learning to Rearrange Deformable Cables, Fabrics, and Bags with Goal-Conditioned Transporter Networks
Dec 18, 2020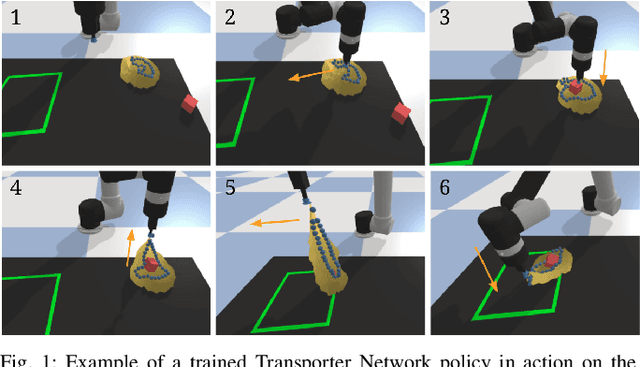
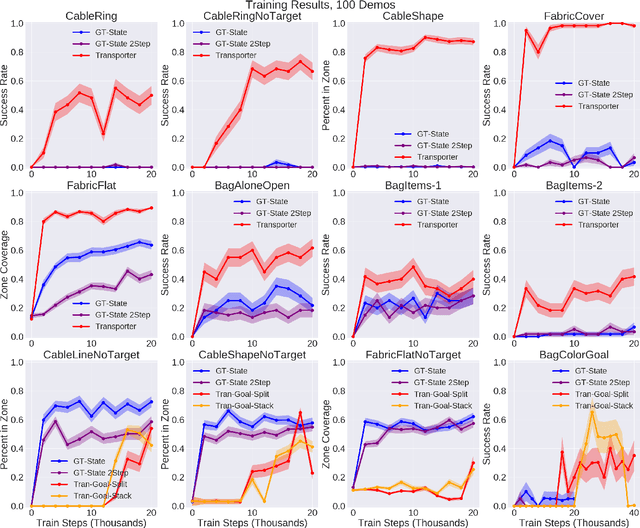
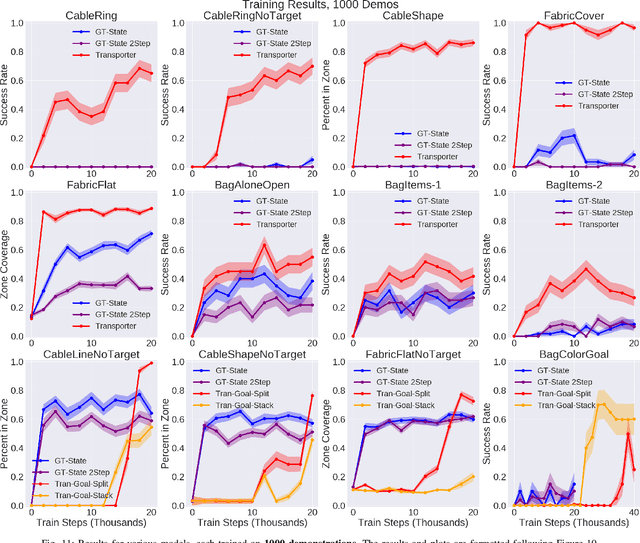
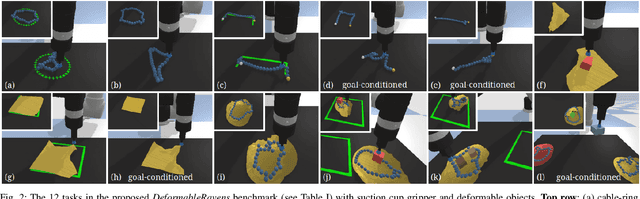
Rearranging and manipulating deformable objects such as cables, fabrics, and bags is a long-standing challenge in robotic manipulation. The complex dynamics and high-dimensional configuration spaces of deformables, compared to rigid objects, make manipulation difficult not only for multi-step planning, but even for goal specification. Goals cannot be as easily specified as rigid object poses, and may involve complex relative spatial relations such as "place the item inside the bag". In this work, we develop a suite of simulated benchmarks with 1D, 2D, and 3D deformable structures, including tasks that involve image-based goal-conditioning and multi-step deformable manipulation. We propose embedding goal-conditioning into Transporter Networks, a recently proposed model architecture for learning robotic manipulation that rearranges deep features to infer displacements that can represent pick and place actions. We demonstrate that goal-conditioned Transporter Networks enable agents to manipulate deformable structures into flexibly specified configurations without test-time visual anchors for target locations. We also significantly extend prior results using Transporter Networks for manipulating deformable objects by testing on tasks with 2D and 3D deformables. Supplementary material is available at https://berkeleyautomation.github.io/bags/.
PandaNet : Anchor-Based Single-Shot Multi-Person 3D Pose Estimation
Jan 07, 2021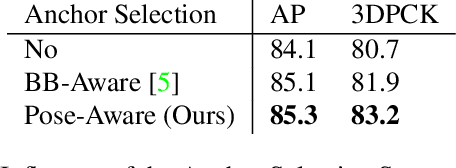

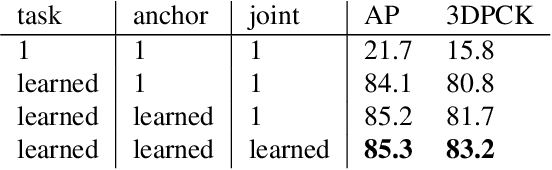

Recently, several deep learning models have been proposed for 3D human pose estimation. Nevertheless, most of these approaches only focus on the single-person case or estimate 3D pose of a few people at high resolution. Furthermore, many applications such as autonomous driving or crowd analysis require pose estimation of a large number of people possibly at low-resolution. In this work, we present PandaNet (Pose estimAtioN and Dectection Anchor-based Network), a new single-shot, anchor-based and multi-person 3D pose estimation approach. The proposed model performs bounding box detection and, for each detected person, 2D and 3D pose regression into a single forward pass. It does not need any post-processing to regroup joints since the network predicts a full 3D pose for each bounding box and allows the pose estimation of a possibly large number of people at low resolution. To manage people overlapping, we introduce a Pose-Aware Anchor Selection strategy. Moreover, as imbalance exists between different people sizes in the image, and joints coordinates have different uncertainties depending on these sizes, we propose a method to automatically optimize weights associated to different people scales and joints for efficient training. PandaNet surpasses previous single-shot methods on several challenging datasets: a multi-person urban virtual but very realistic dataset (JTA Dataset), and two real world 3D multi-person datasets (CMU Panoptic and MuPoTS-3D).
MultiON: Benchmarking Semantic Map Memory using Multi-Object Navigation
Dec 07, 2020
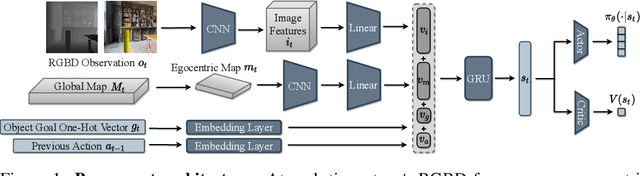

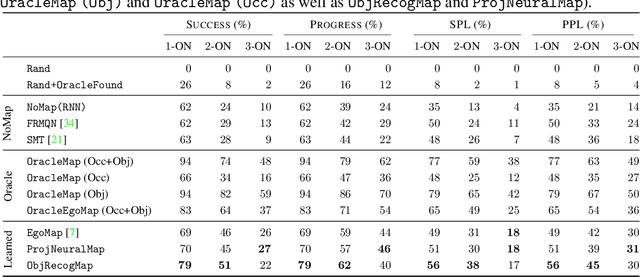
Navigation tasks in photorealistic 3D environments are challenging because they require perception and effective planning under partial observability. Recent work shows that map-like memory is useful for long-horizon navigation tasks. However, a focused investigation of the impact of maps on navigation tasks of varying complexity has not yet been performed. We propose the multiON task, which requires navigation to an episode-specific sequence of objects in a realistic environment. MultiON generalizes the ObjectGoal navigation task and explicitly tests the ability of navigation agents to locate previously observed goal objects. We perform a set of multiON experiments to examine how a variety of agent models perform across a spectrum of navigation task complexities. Our experiments show that: i) navigation performance degrades dramatically with escalating task complexity; ii) a simple semantic map agent performs surprisingly well relative to more complex neural image feature map agents; and iii) even oracle map agents achieve relatively low performance, indicating the potential for future work in training embodied navigation agents using maps. Video summary: https://youtu.be/yqTlHNIcgnY
Convolutional Point-set Representation: A Convolutional Bridge Between a Densely Annotated Image and 3D Face Alignment
Apr 02, 2018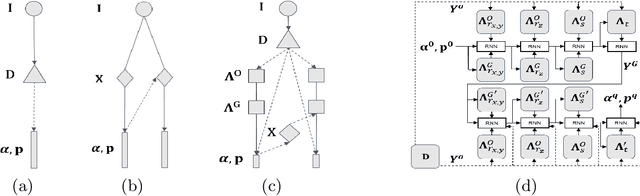
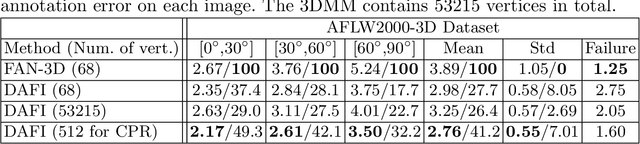
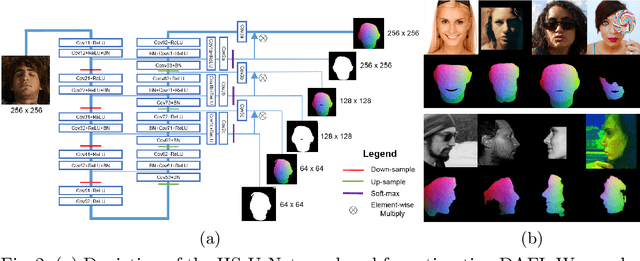
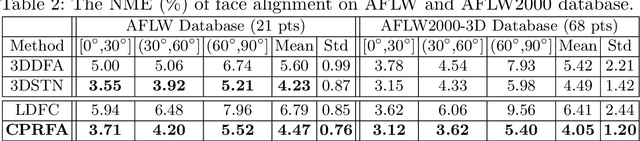
We present a robust method for estimating the facial pose and shape information from a densely annotated facial image. The method relies on Convolutional Point-set Representation (CPR), a carefully designed matrix representation to summarize different layers of information encoded in the set of detected points in the annotated image. The CPR disentangles the dependencies of shape and different pose parameters and enables updating different parameters in a sequential manner via convolutional neural networks and recurrent layers. When updating the pose parameters, we sample reprojection errors along with a predicted direction and update the parameters based on the pattern of reprojection errors. This technique boosts the model's capability in searching a local minimum under challenging scenarios. We also demonstrate that annotation from different sources can be merged under the framework of CPR and contributes to outperforming the current state-of-the-art solutions for 3D face alignment. Experiments indicate the proposed CPRFA (CPR-based Face Alignment) significantly improves 3D alignment accuracy when the densely annotated image contains noise and missing values, which is common under "in-the-wild" acquisition scenarios.
BS-Nets: An End-to-End Framework For Band Selection of Hyperspectral Image
Apr 17, 2019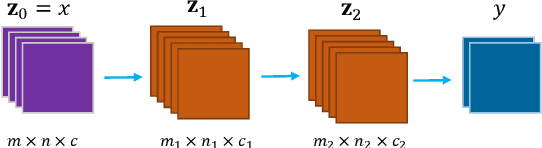
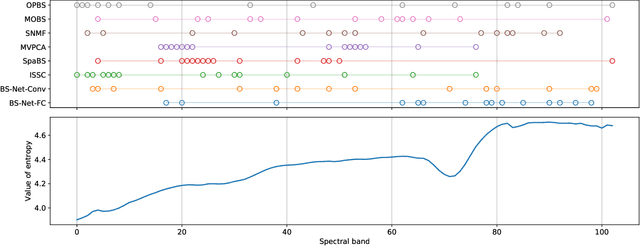
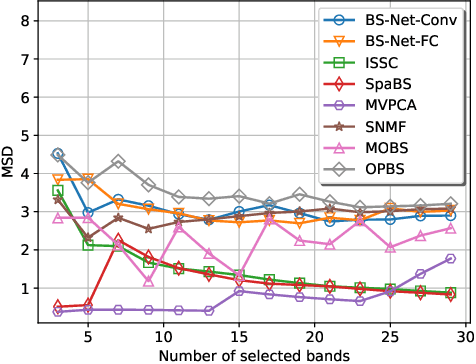
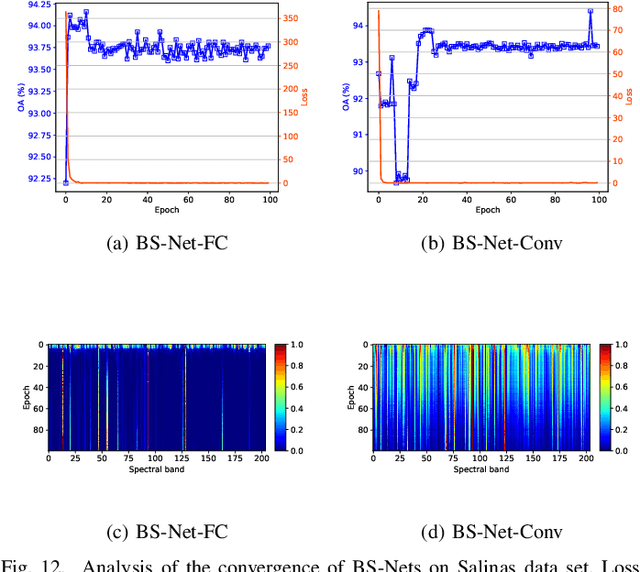
Hyperspectral image (HSI) consists of hundreds of continuous narrow bands with high spectral correlation, which would lead to the so-called Hughes phenomenon and the high computational cost in processing. Band selection has been proven effective in avoiding such problems by removing the redundant bands. However, many of existing band selection methods separately estimate the significance for every single band and cannot fully consider the nonlinear and global interaction between spectral bands. In this paper, by assuming that a complete HSI can be reconstructed from its few informative bands, we propose a general band selection framework, Band Selection Network (termed as BS-Net). The framework consists of a band attention module (BAM), which aims to explicitly model the nonlinear inter-dependencies between spectral bands, and a reconstruction network (RecNet), which is used to restore the original HSI cube from the learned informative bands, resulting in a flexible architecture. The resulting framework is end-to-end trainable, making it easier to train from scratch and to combine with existing networks. We implement two BS-Nets respectively using fully connected networks (BS-Net-FC) and convolutional neural networks (BS-Net-Conv), and compare the results with many existing band selection approaches for three real hyperspectral images, demonstrating that the proposed BS-Nets can accurately select informative band subset with less redundancy and achieve significantly better classification performance with an acceptable time cost.
Fast initial guess estimation for digital image correlation
Oct 12, 2017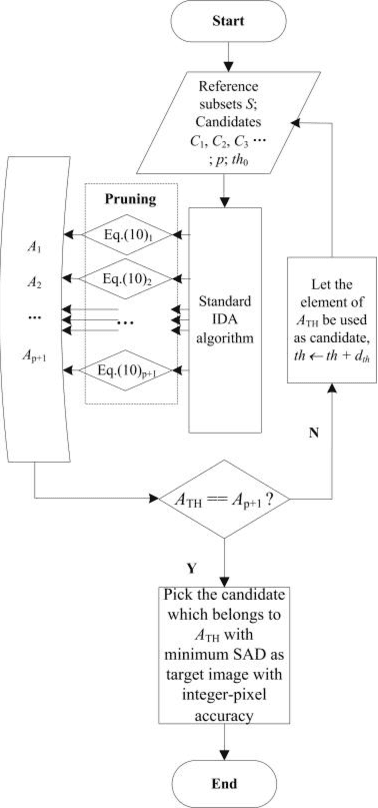
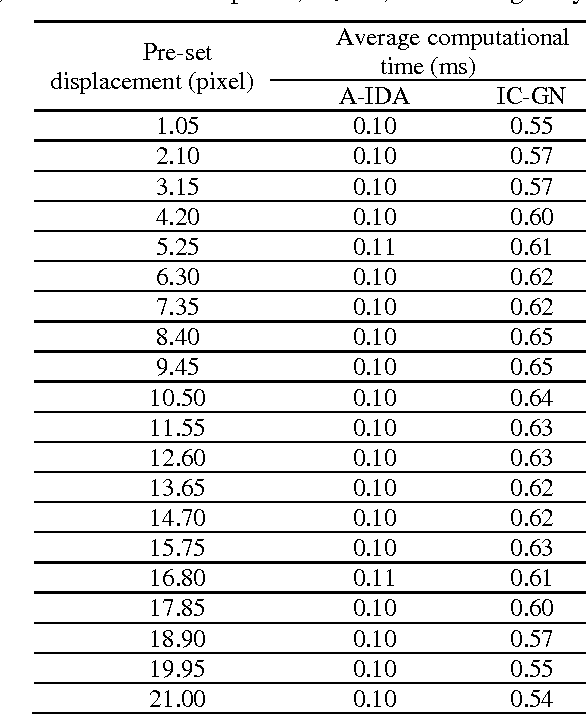


Digital image correlation (DIC) is a widely used optical metrology for quantitative deformation measurement due to its non-contact, low-cost, highly precise feature. DIC relies on nonlinear optimization algorithm. Thus it is quite important to efficiently obtain a reliable initial guess. The most widely used method for obtaining initial guess is reliability-guided digital image correlation (RG-DIC) method, which is reliable but path-dependent. This path-dependent method limits the further improvement of computation speed of DIC using parallel computing technology, and error of calculation may be spread out along the calculation path. Therefore, a reliable and path-independent algorithm which is able to provide reliable initial guess is desirable to reach full potential of the ability of parallel computing. In this paper, an algorithm used for initial guess estimation is proposed. Numerical and real experiments show that the proposed algorithm, adaptive incremental dissimilarity approximations algorithm (A-IDA), has the following characteristics: 1) Compared with inverse compositional Gauss-Newton (IC-GN) sub-pixel registration algorithm, the computational time required by A-IDA algorithm is negligible, especially when subset size is relatively large; 2) the efficiency of A-IDA algorithm is less influenced by search range; 3) the efficiency is less influenced by subset size; 4) it is easy to select the threshold for the proposed algorithm.