 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Joint reconstruction and bias field correction for undersampled MR imaging
Jul 26, 2020
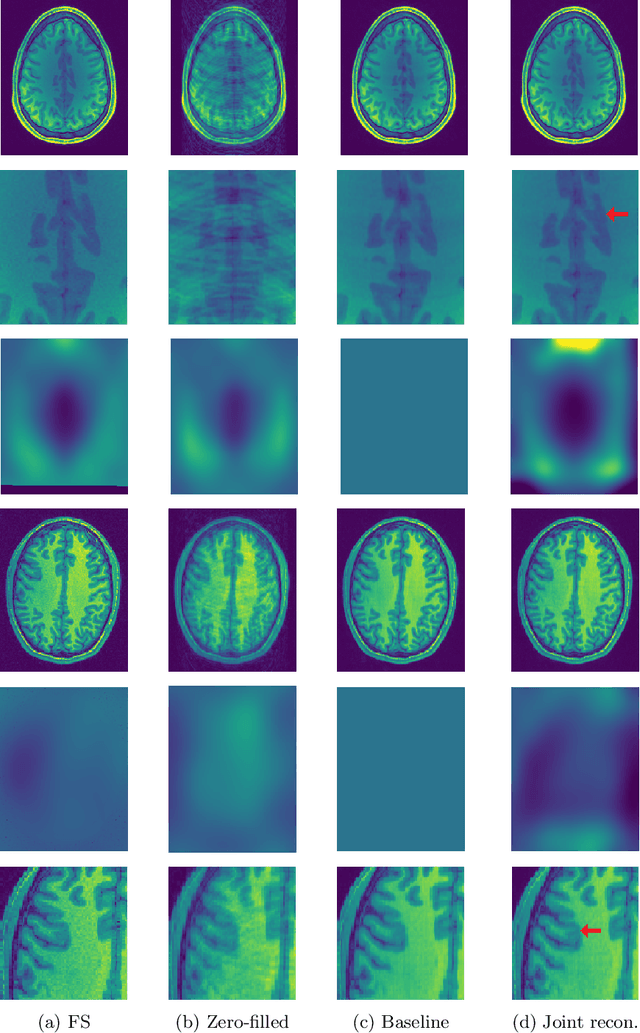
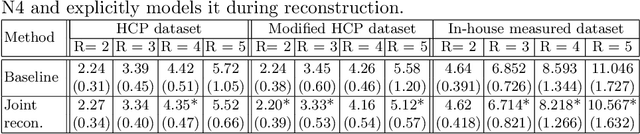
Undersampling the k-space in MRI allows saving precious acquisition time, yet results in an ill-posed inversion problem. Recently, many deep learning techniques have been developed, addressing this issue of recovering the fully sampled MR image from the undersampled data. However, these learning based schemes are susceptible to differences between the training data and the image to be reconstructed at test time. One such difference can be attributed to the bias field present in MR images, caused by field inhomogeneities and coil sensitivities. In this work, we address the sensitivity of the reconstruction problem to the bias field and propose to model it explicitly in the reconstruction, in order to decrease this sensitivity. To this end, we use an unsupervised learning based reconstruction algorithm as our basis and combine it with a N4-based bias field estimation method, in a joint optimization scheme. We use the HCP dataset as well as in-house measured images for the evaluations. We show that the proposed method improves the reconstruction quality, both visually and in terms of RMSE.
Learning to Learn Parameterized Classification Networks for Scalable Input Images
Jul 13, 2020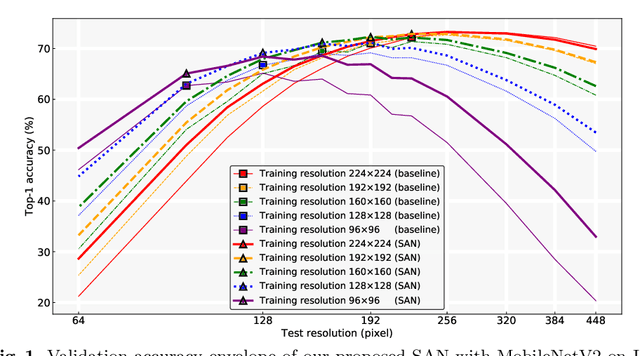
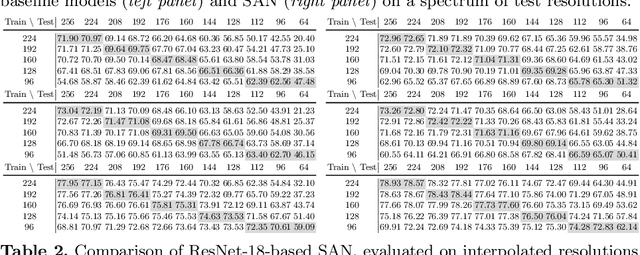
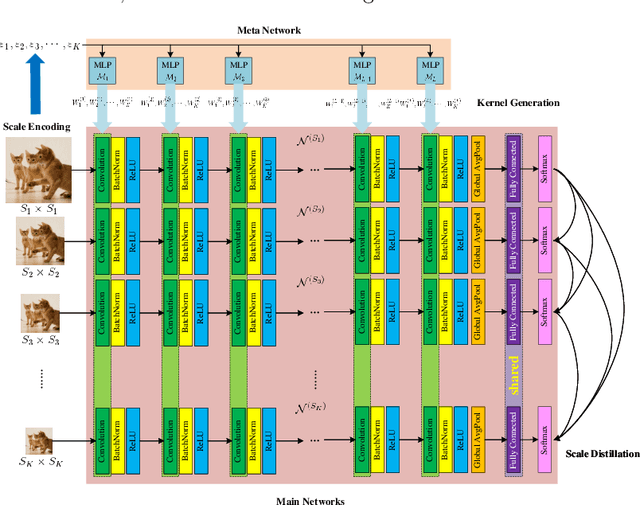

Convolutional Neural Networks (CNNs) do not have a predictable recognition behavior with respect to the input resolution change. This prevents the feasibility of deployment on different input image resolutions for a specific model. To achieve efficient and flexible image classification at runtime, we employ meta learners to generate convolutional weights of main networks for various input scales and maintain privatized Batch Normalization layers per scale. For improved training performance, we further utilize knowledge distillation on the fly over model predictions based on different input resolutions. The learned meta network could dynamically parameterize main networks to act on input images of arbitrary size with consistently better accuracy compared to individually trained models. Extensive experiments on the ImageNet demonstrate that our method achieves an improved accuracy-efficiency trade-off during the adaptive inference process. By switching executable input resolutions, our method could satisfy the requirement of fast adaption in different resource-constrained environments. Code and models are available at https://github.com/d-li14/SAN.
On the Limitations of Denoising Strategies as Adversarial Defenses
Dec 17, 2020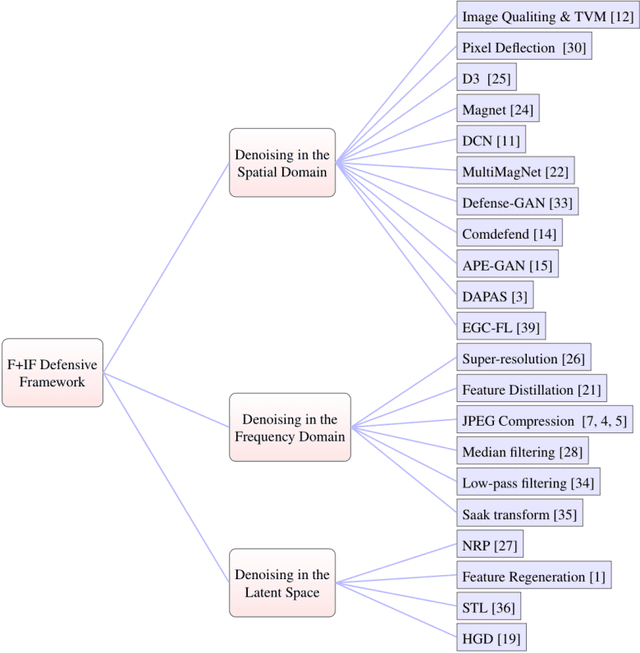
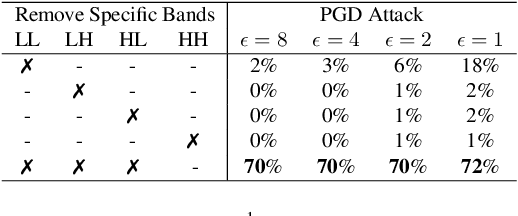
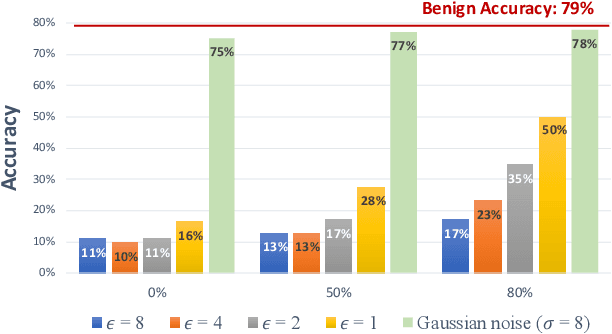
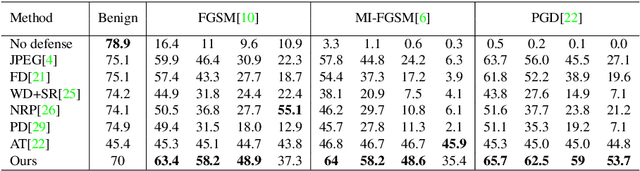
As adversarial attacks against machine learning models have raised increasing concerns, many denoising-based defense approaches have been proposed. In this paper, we summarize and analyze the defense strategies in the form of symmetric transformation via data denoising and reconstruction (denoted as $F+$ inverse $F$, $F-IF$ Framework). In particular, we categorize these denoising strategies from three aspects (i.e. denoising in the spatial domain, frequency domain, and latent space, respectively). Typically, defense is performed on the entire adversarial example, both image and perturbation are modified, making it difficult to tell how it defends against the perturbations. To evaluate the robustness of these denoising strategies intuitively, we directly apply them to defend against adversarial noise itself (assuming we have obtained all of it), which saving us from sacrificing benign accuracy. Surprisingly, our experimental results show that even if most of the perturbations in each dimension is eliminated, it is still difficult to obtain satisfactory robustness. Based on the above findings and analyses, we propose the adaptive compression strategy for different frequency bands in the feature domain to improve the robustness. Our experiment results show that the adaptive compression strategies enable the model to better suppress adversarial perturbations, and improve robustness compared with existing denoising strategies.
A Generalizable and Accessible Approach to Machine Learning with Global Satellite Imagery
Oct 16, 2020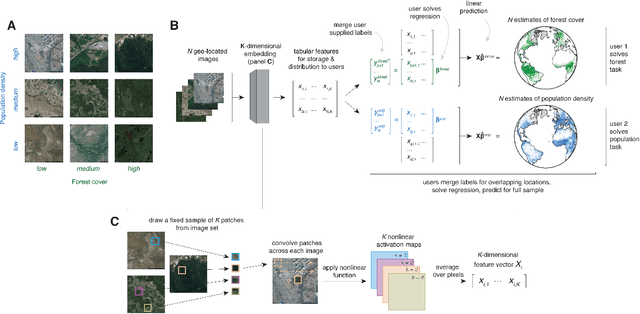
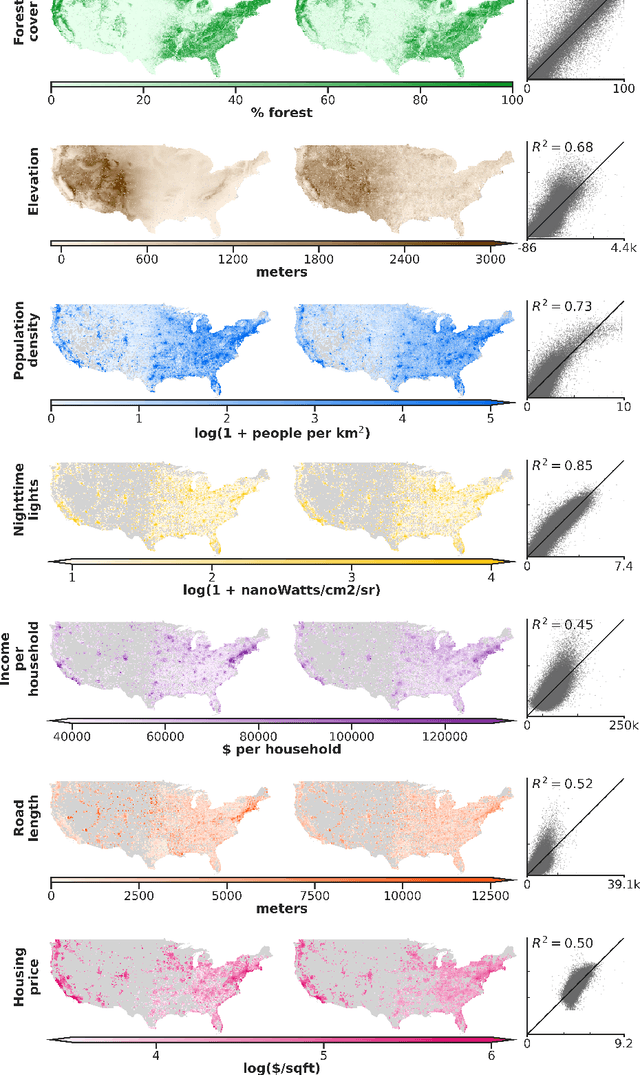
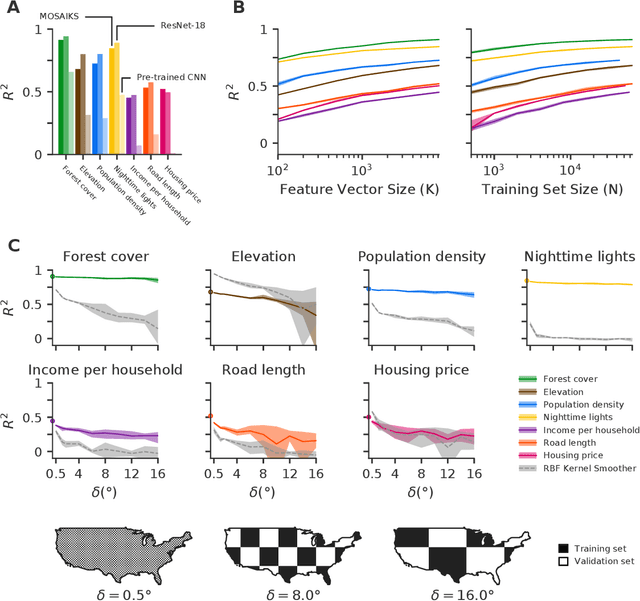
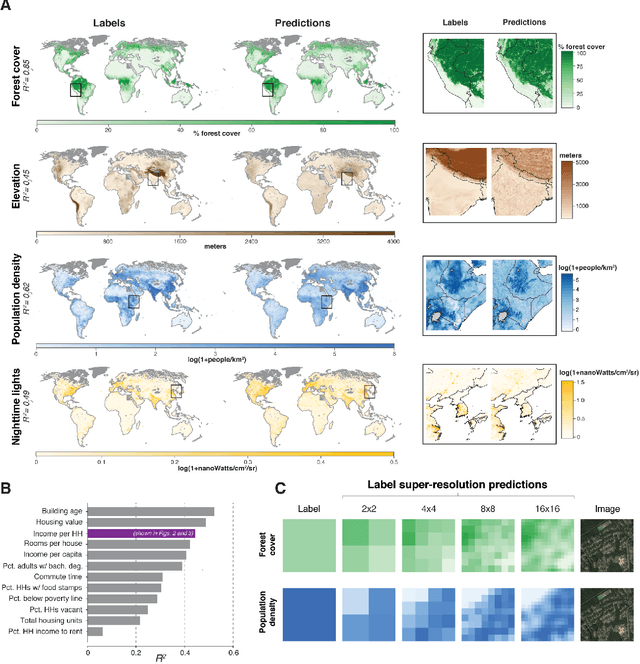
Combining satellite imagery with machine learning (SIML) has the potential to address global challenges by remotely estimating socioeconomic and environmental conditions in data-poor regions, yet the resource requirements of SIML limit its accessibility and use. We show that a single encoding of satellite imagery can generalize across diverse prediction tasks (e.g. forest cover, house price, road length). Our method achieves accuracy competitive with deep neural networks at orders of magnitude lower computational cost, scales globally, delivers label super-resolution predictions, and facilitates characterizations of uncertainty. Since image encodings are shared across tasks, they can be centrally computed and distributed to unlimited researchers, who need only fit a linear regression to their own ground truth data in order to achieve state-of-the-art SIML performance.
Learning to Rearrange Deformable Cables, Fabrics, and Bags with Goal-Conditioned Transporter Networks
Dec 06, 2020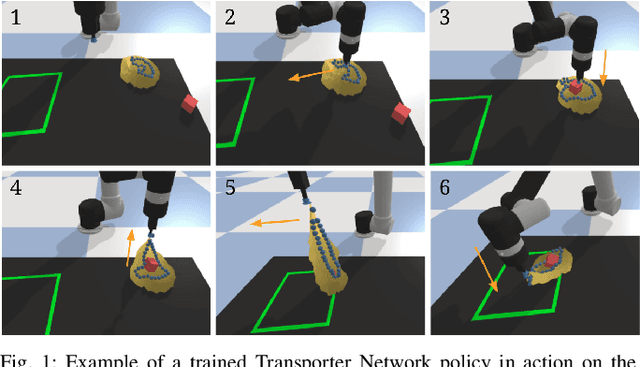
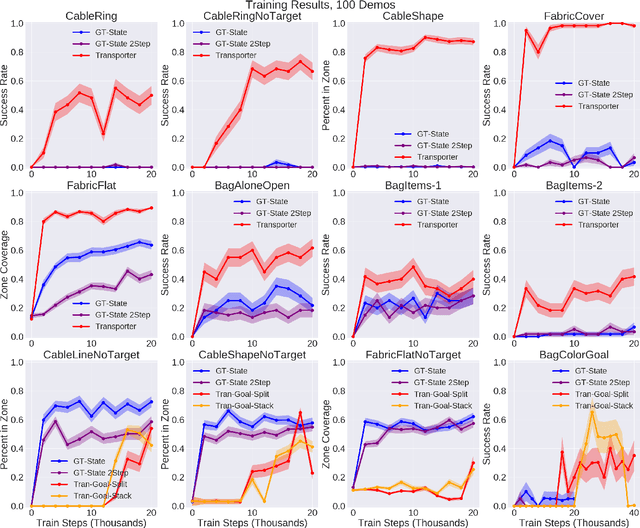
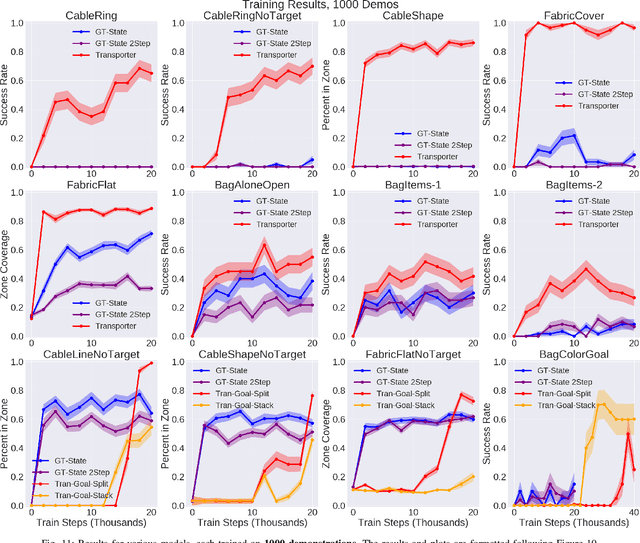
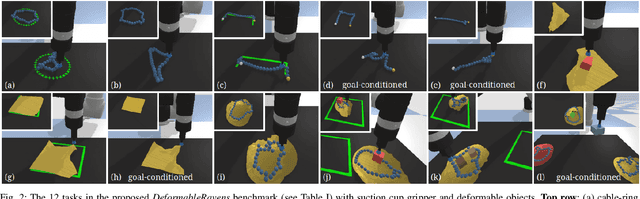
Rearranging and manipulating deformable objects such as cables, fabrics, and bags is a long-standing challenge in robotic manipulation. The complex dynamics and high-dimensional configuration spaces of deformables, compared to rigid objects, make manipulation difficult not only for multi-step planning, but even for goal specification. Goals cannot be as easily specified as rigid object poses, and may involve complex relative spatial relations such as "place the item inside the bag". In this work, we develop a suite of simulated benchmarks with 1D, 2D, and 3D deformable structures, including tasks that involve image-based goal-conditioning and multi-step deformable manipulation. We propose embedding goal-conditioning into Transporter Networks, a recently proposed model architecture for learning robotic manipulation that rearranges deep features to infer displacements that can represent pick and place actions. We demonstrate that goal-conditioned Transporter Networks enable agents to manipulate deformable structures into flexibly specified configurations without test-time visual anchors for target locations. We also significantly extend prior results using Transporter Networks for manipulating deformable objects by testing on tasks with 2D and 3D deformables. Supplementary material is available at https://berkeleyautomation.github.io/bags/.
What is the Role of Recurrent Neural Networks (RNNs) in an Image Caption Generator?
Aug 25, 2017
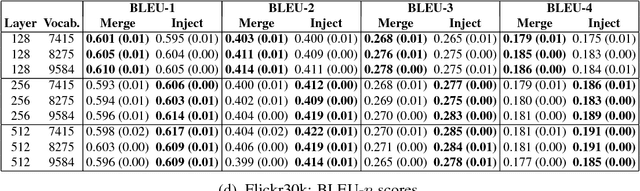
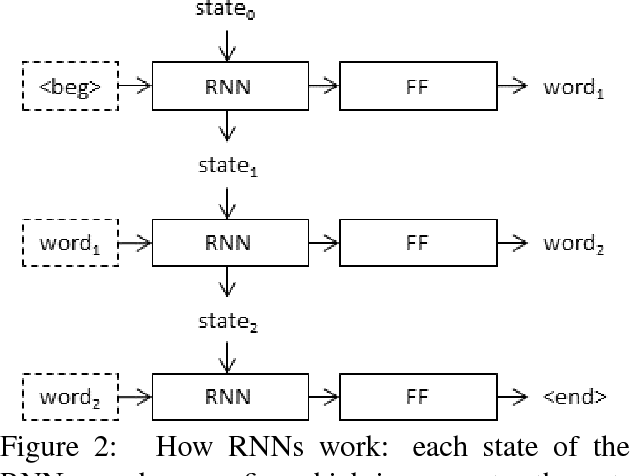
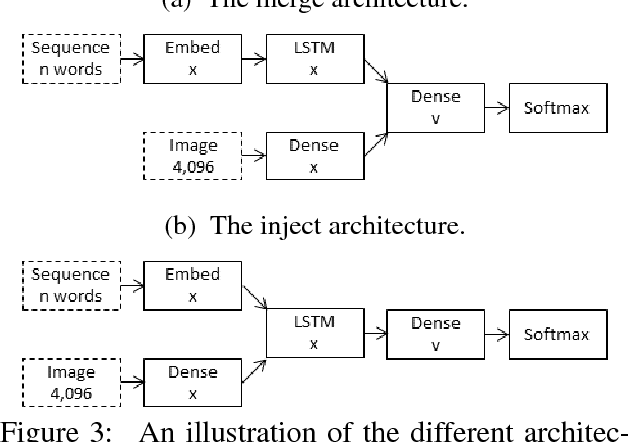
In neural image captioning systems, a recurrent neural network (RNN) is typically viewed as the primary `generation' component. This view suggests that the image features should be `injected' into the RNN. This is in fact the dominant view in the literature. Alternatively, the RNN can instead be viewed as only encoding the previously generated words. This view suggests that the RNN should only be used to encode linguistic features and that only the final representation should be `merged' with the image features at a later stage. This paper compares these two architectures. We find that, in general, late merging outperforms injection, suggesting that RNNs are better viewed as encoders, rather than generators.
MACU-Net Semantic Segmentation from High-Resolution Remote Sensing Images
Jul 26, 2020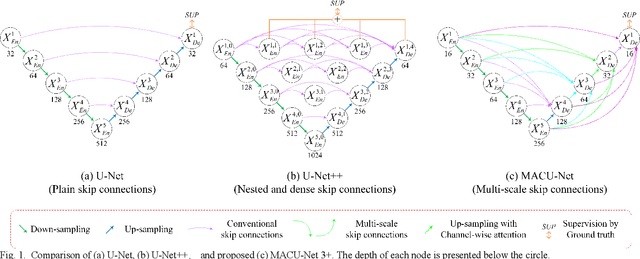
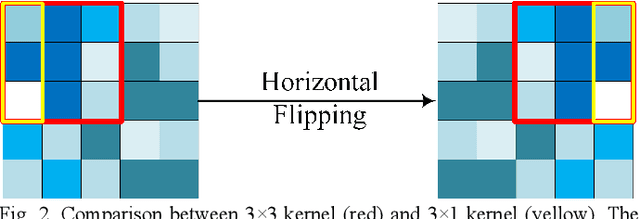
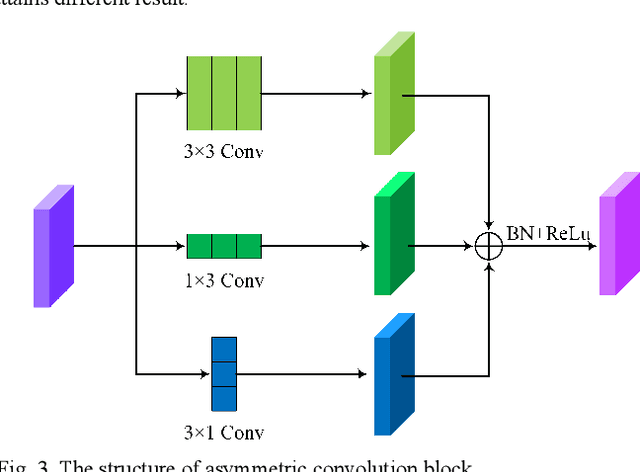
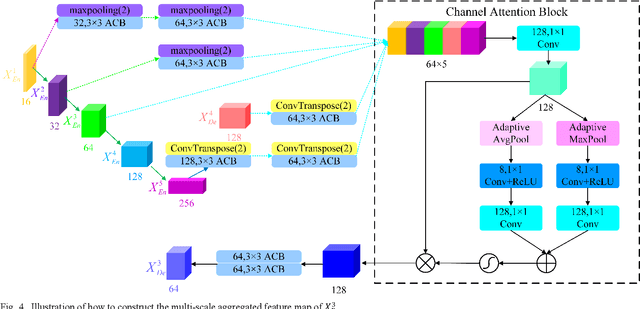
Semantic segmentation of remote sensing images plays an important role in land resource management, yield estimation, and economic assessment. U-Net is a sophisticated encoder-decoder architecture which has been frequently used in medical image segmentation and has attained prominent performance. And asymmetric convolution block can enhance the square convolution kernels using asymmetric convolutions. In this paper, based on U-Net and asymmetric convolution block, we incorporate multi-scale features generated by different layers of U-Net and design a multi-scale skip connected architecture, MACU-Net, for semantic segmentation using high-resolution remote sensing images. Our design has the following advantages: (1) The multi-scale skip connections combine and realign semantic features contained both in low-level and high-level feature maps with different scales; (2) the asymmetric convolution block strengthens the representational capacity of a standard convolution layer. Experiments conducted on two remote sensing image datasets captured by separate satellites demonstrate that the performance of our MACU-Net transcends the U-Net, SegNet, DeepLab V3+, and other baseline algorithms.
Temporal and Volumetric Denoising via Quantile Sparse Image (QuaSI) Prior in Optical Coherence Tomography and Beyond
Jul 05, 2018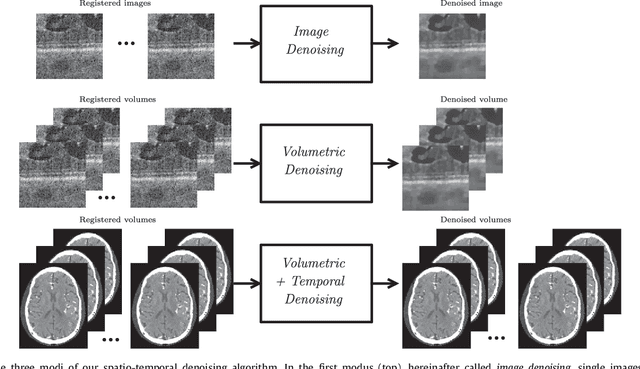


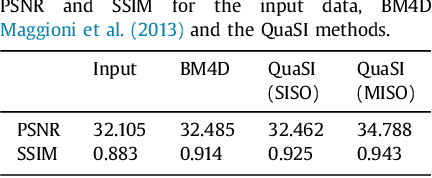
This paper introduces an universal and structure-preserving regularization term, called quantile sparse image (QuaSI) prior. The prior is suitable for denoising images from various medical imaging modalities. We demonstrate its effectiveness on volumetric optical coherence tomography (OCT) and computed tomography (CT) data, which show different noise and image characteristics. OCT offers high-resolution scans of the human retina but is inherently impaired by speckle noise. CT on the other hand has a lower resolution and shows high-frequency noise. For the purpose of denoising, we propose a variational framework based on the QuaSI prior and a Huber data fidelity model that can handle 3-D and 3-D+t data. Efficient optimization is facilitated through the use of an alternating direction method of multipliers (ADMM) scheme and the linearization of the quantile filter. Experiments on multiple datasets emphasize the excellent performance of the proposed method.
Disrupting Deepfakes with an Adversarial Attack that Survives Training
Jun 17, 2020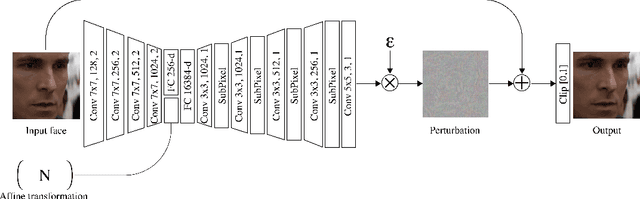



The rapid progress in generative models and autoencoders has given rise to effective video tampering techniques, used for generating deepfakes. Mitigation research is mostly focused on post-factum deepfake detection and not prevention. We complement these efforts by proposing a prevention technique against face-swapping autoencoders. Our technique consists of a novel training-resistant adversarial attack that can be applied to a video to disrupt face-swapping manipulations. Our attack introduces spatial-temporal distortions to the output of the face-swapping autoencoders, and it holds whether or not our adversarial images have been included in the training set of said autoencoders. To implement the attack, we construct a bilevel optimization problem, where we train a generator and a face-swapping model instance against each other. Specifically, we pair each input image with a target distortion, and feed them into a generator that produces an adversarial image. This image will exhibit the distortion when a face-swapping autoencoder is applied to it. We solve the optimization problem by training the generator and the face-swapping model simultaneously using an iterative process of alternating optimization. Finally, we validate our attack using a popular implementation of FaceSwap, and show that our attack transfers across different models and target faces. More broadly, these results demonstrate the existence of training-resistant adversarial attacks, potentially applicable to a wide range of domains.
Guided Open Vocabulary Image Captioning with Constrained Beam Search
Jul 19, 2017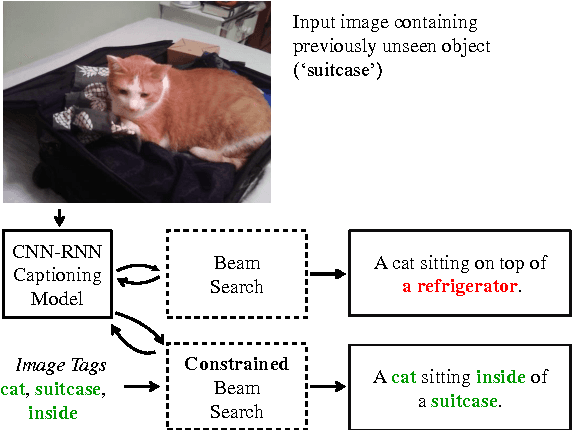
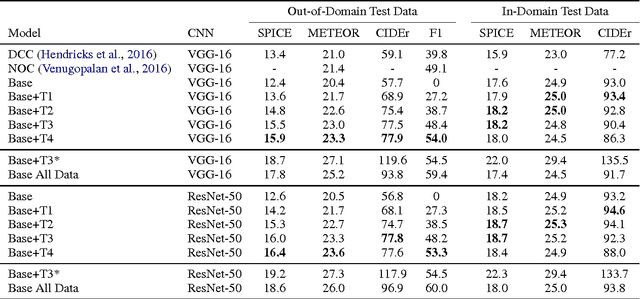
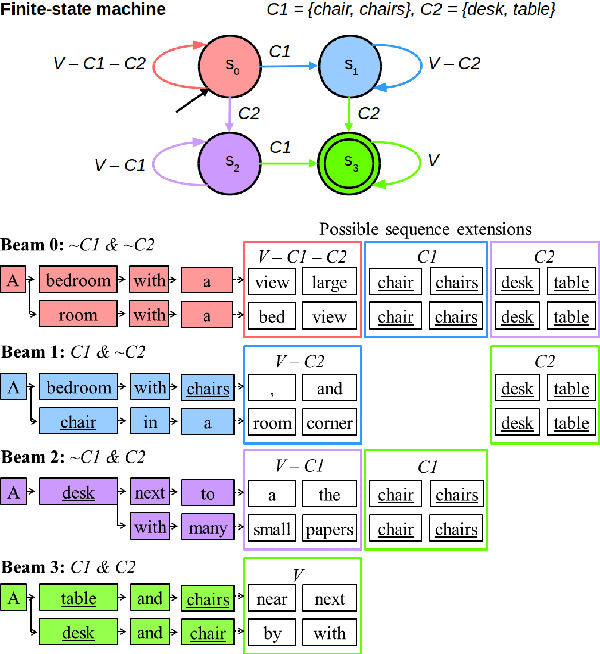

Existing image captioning models do not generalize well to out-of-domain images containing novel scenes or objects. This limitation severely hinders the use of these models in real world applications dealing with images in the wild. We address this problem using a flexible approach that enables existing deep captioning architectures to take advantage of image taggers at test time, without re-training. Our method uses constrained beam search to force the inclusion of selected tag words in the output, and fixed, pretrained word embeddings to facilitate vocabulary expansion to previously unseen tag words. Using this approach we achieve state of the art results for out-of-domain captioning on MSCOCO (and improved results for in-domain captioning). Perhaps surprisingly, our results significantly outperform approaches that incorporate the same tag predictions into the learning algorithm. We also show that we can significantly improve the quality of generated ImageNet captions by leveraging ground-truth labels.