 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Comprehensive Overview of Fish-Eye Camera Distortion Correction Methods
Dec 31, 2023
The fisheye camera, with its unique wide field of view and other characteristics, has found extensive applications in various fields. However, the fisheye camera suffers from significant distortion compared to pinhole cameras, resulting in distorted images of captured objects. Fish-eye camera distortion is a common issue in digital image processing, requiring effective correction techniques to enhance image quality. This review provides a comprehensive overview of various methods used for fish-eye camera distortion correction. The article explores the polynomial distortion model, which utilizes polynomial functions to model and correct radial distortions. Additionally, alternative approaches such as panorama mapping, grid mapping, direct methods, and deep learning-based methods are discussed. The review highlights the advantages, limitations, and recent advancements of each method, enabling readers to make informed decisions based on their specific needs.
Stable Messenger: Steganography for Message-Concealed Image Generation
Dec 03, 2023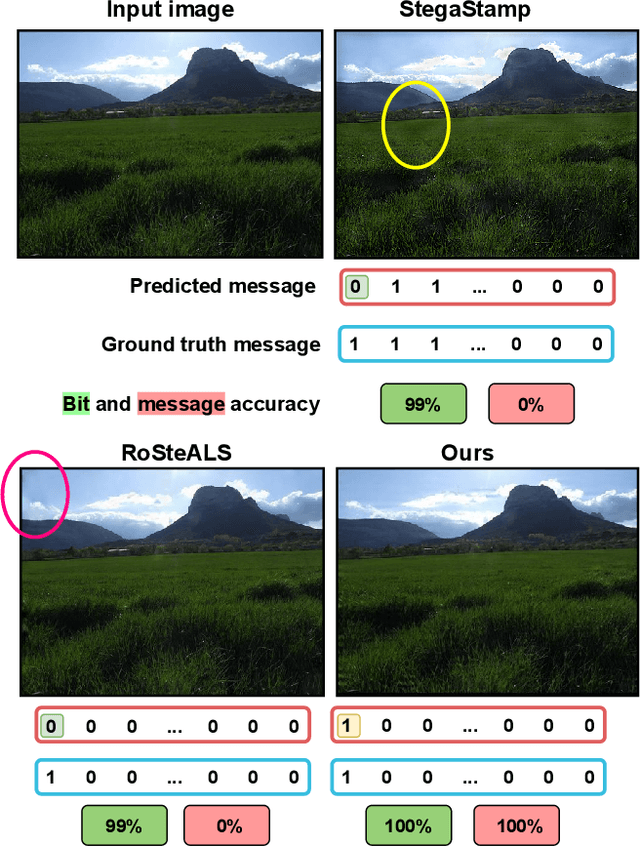
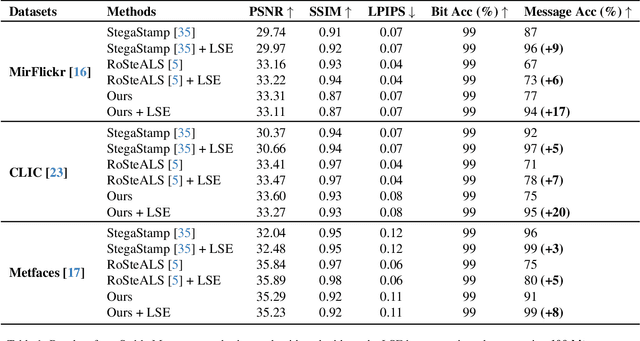
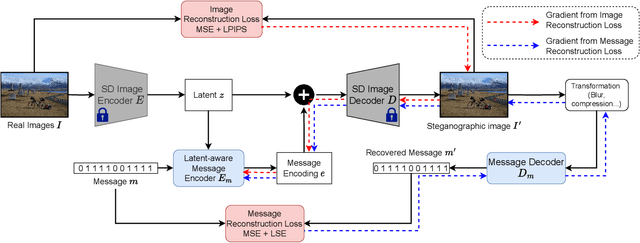

In the ever-expanding digital landscape, safeguarding sensitive information remains paramount. This paper delves deep into digital protection, specifically focusing on steganography. While prior research predominantly fixated on individual bit decoding, we address this limitation by introducing ``message accuracy'', a novel metric evaluating the entirety of decoded messages for a more holistic evaluation. In addition, we propose an adaptive universal loss tailored to enhance message accuracy, named Log-Sum-Exponential (LSE) loss, thereby significantly improving the message accuracy of recent approaches. Furthermore, we also introduce a new latent-aware encoding technique in our framework named \Approach, harnessing pretrained Stable Diffusion for advanced steganographic image generation, giving rise to a better trade-off between image quality and message recovery. Throughout experimental results, we have demonstrated the superior performance of the new LSE loss and latent-aware encoding technique. This comprehensive approach marks a significant step in evolving evaluation metrics, refining loss functions, and innovating image concealment techniques, aiming for more robust and dependable information protection.
EfficientSAM: Leveraged Masked Image Pretraining for Efficient Segment Anything
Dec 01, 2023Segment Anything Model (SAM) has emerged as a powerful tool for numerous vision applications. A key component that drives the impressive performance for zero-shot transfer and high versatility is a super large Transformer model trained on the extensive high-quality SA-1B dataset. While beneficial, the huge computation cost of SAM model has limited its applications to wider real-world applications. To address this limitation, we propose EfficientSAMs, light-weight SAM models that exhibits decent performance with largely reduced complexity. Our idea is based on leveraging masked image pretraining, SAMI, which learns to reconstruct features from SAM image encoder for effective visual representation learning. Further, we take SAMI-pretrained light-weight image encoders and mask decoder to build EfficientSAMs, and finetune the models on SA-1B for segment anything task. We perform evaluations on multiple vision tasks including image classification, object detection, instance segmentation, and semantic object detection, and find that our proposed pretraining method, SAMI, consistently outperforms other masked image pretraining methods. On segment anything task such as zero-shot instance segmentation, our EfficientSAMs with SAMI-pretrained lightweight image encoders perform favorably with a significant gain (e.g., ~4 AP on COCO/LVIS) over other fast SAM models.
SHARE: Single-view Human Adversarial REconstruction
Dec 30, 2023The accuracy of 3D Human Pose and Shape reconstruction (HPS) from an image is progressively improving. Yet, no known method is robust across all image distortion. To address issues due to variations of camera poses, we introduce SHARE, a novel fine-tuning method that utilizes adversarial data augmentation to enhance the robustness of existing HPS techniques. We perform a comprehensive analysis on the impact of camera poses on HPS reconstruction outcomes. We first generated large-scale image datasets captured systematically from diverse camera perspectives. We then established a mapping between camera poses and reconstruction errors as a continuous function that characterizes the relationship between camera poses and HPS quality. Leveraging this representation, we introduce RoME (Regions of Maximal Error), a novel sampling technique for our adversarial fine-tuning method. The SHARE framework is generalizable across various single-view HPS methods and we demonstrate its performance on HMR, SPIN, PARE, CLIFF and ExPose. Our results illustrate a reduction in mean joint errors across single-view HPS techniques, for images captured from multiple camera positions without compromising their baseline performance. In many challenging cases, our method surpasses the performance of existing models, highlighting its practical significance for diverse real-world applications.
Deep Radon Prior: A Fully Unsupervised Framework for Sparse-View CT Reconstruction
Dec 30, 2023Although sparse-view computed tomography (CT) has significantly reduced radiation dose, it also introduces severe artifacts which degrade the image quality. In recent years, deep learning-based methods for inverse problems have made remarkable progress and have become increasingly popular in CT reconstruction. However, most of these methods suffer several limitations: dependence on high-quality training data, weak interpretability, etc. In this study, we propose a fully unsupervised framework called Deep Radon Prior (DRP), inspired by Deep Image Prior (DIP), to address the aforementioned limitations. DRP introduces a neural network as an implicit prior into the iterative method, thereby realizing cross-domain gradient feedback. During the reconstruction process, the neural network is progressively optimized in multiple stages to narrow the solution space in radon domain for the under-constrained imaging protocol, and the convergence of the proposed method has been discussed in this work. Compared with the popular pre-trained method, the proposed framework requires no dataset and exhibits superior interpretability and generalization ability. The experimental results demonstrate that the proposed method can generate detailed images while effectively suppressing image artifacts.Meanwhile, DRP achieves comparable or better performance than the supervised methods.
CorresNeRF: Image Correspondence Priors for Neural Radiance Fields
Dec 11, 2023Neural Radiance Fields (NeRFs) have achieved impressive results in novel view synthesis and surface reconstruction tasks. However, their performance suffers under challenging scenarios with sparse input views. We present CorresNeRF, a novel method that leverages image correspondence priors computed by off-the-shelf methods to supervise NeRF training. We design adaptive processes for augmentation and filtering to generate dense and high-quality correspondences. The correspondences are then used to regularize NeRF training via the correspondence pixel reprojection and depth loss terms. We evaluate our methods on novel view synthesis and surface reconstruction tasks with density-based and SDF-based NeRF models on different datasets. Our method outperforms previous methods in both photometric and geometric metrics. We show that this simple yet effective technique of using correspondence priors can be applied as a plug-and-play module across different NeRF variants. The project page is at https://yxlao.github.io/corres-nerf.
Open-Vocabulary SAM: Segment and Recognize Twenty-thousand Classes Interactively
Jan 05, 2024The CLIP and Segment Anything Model (SAM) are remarkable vision foundation models (VFMs). SAM excels in segmentation tasks across diverse domains, while CLIP is renowned for its zero-shot recognition capabilities. This paper presents an in-depth exploration of integrating these two models into a unified framework. Specifically, we introduce the Open-Vocabulary SAM, a SAM-inspired model designed for simultaneous interactive segmentation and recognition, leveraging two unique knowledge transfer modules: SAM2CLIP and CLIP2SAM. The former adapts SAM's knowledge into the CLIP via distillation and learnable transformer adapters, while the latter transfers CLIP knowledge into SAM, enhancing its recognition capabilities. Extensive experiments on various datasets and detectors show the effectiveness of Open-Vocabulary SAM in both segmentation and recognition tasks, significantly outperforming the naive baselines of simply combining SAM and CLIP. Furthermore, aided with image classification data training, our method can segment and recognize approximately 22,000 classes.
PatchMorph: A Stochastic Deep Learning Approach for Unsupervised 3D Brain Image Registration with Small Patches
Dec 12, 2023We introduce "PatchMorph," an new stochastic deep learning algorithm tailored for unsupervised 3D brain image registration. Unlike other methods, our method uses compact patches of a constant small size to derive solutions that can combine global transformations with local deformations. This approach minimizes the memory footprint of the GPU during training, but also enables us to operate on numerous amounts of randomly overlapping small patches during inference to mitigate image and patch boundary problems. PatchMorph adeptly handles world coordinate transformations between two input images, accommodating variances in attributes such as spacing, array sizes, and orientations. The spatial resolution of patches transitions from coarse to fine, addressing both global and local attributes essential for aligning the images. Each patch offers a unique perspective, together converging towards a comprehensive solution. Experiments on human T1 MRI brain images and marmoset brain images from serial 2-photon tomography affirm PatchMorph's superior performance.
GLOCALFAIR: Jointly Improving Global and Local Group Fairness in Federated Learning
Jan 07, 2024Federated learning (FL) has emerged as a prospective solution for collaboratively learning a shared model across clients without sacrificing their data privacy. However, the federated learned model tends to be biased against certain demographic groups (e.g., racial and gender groups) due to the inherent FL properties, such as data heterogeneity and party selection. Unlike centralized learning, mitigating bias in FL is particularly challenging as private training datasets and their sensitive attributes are typically not directly accessible. Most prior research in this field only focuses on global fairness while overlooking the local fairness of individual clients. Moreover, existing methods often require sensitive information about the client's local datasets to be shared, which is not desirable. To address these issues, we propose GLOCALFAIR, a client-server co-design fairness framework that can jointly improve global and local group fairness in FL without the need for sensitive statistics about the client's private datasets. Specifically, we utilize constrained optimization to enforce local fairness on the client side and adopt a fairness-aware clustering-based aggregation on the server to further ensure the global model fairness across different sensitive groups while maintaining high utility. Experiments on two image datasets and one tabular dataset with various state-of-the-art fairness baselines show that GLOCALFAIR can achieve enhanced fairness under both global and local data distributions while maintaining a good level of utility and client fairness.
DiffusionLight: Light Probes for Free by Painting a Chrome Ball
Jan 01, 2024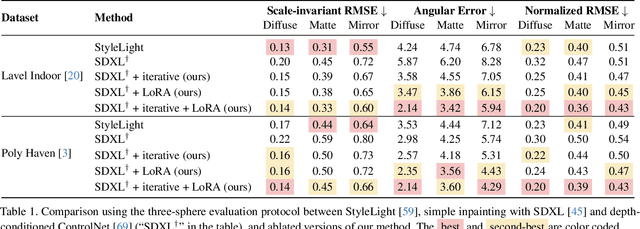


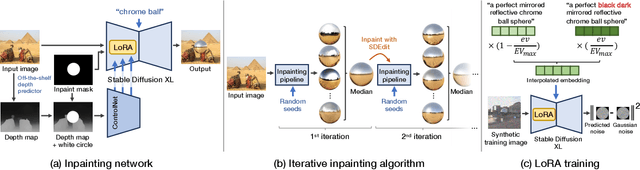
We present a simple yet effective technique to estimate lighting in a single input image. Current techniques rely heavily on HDR panorama datasets to train neural networks to regress an input with limited field-of-view to a full environment map. However, these approaches often struggle with real-world, uncontrolled settings due to the limited diversity and size of their datasets. To address this problem, we leverage diffusion models trained on billions of standard images to render a chrome ball into the input image. Despite its simplicity, this task remains challenging: the diffusion models often insert incorrect or inconsistent objects and cannot readily generate images in HDR format. Our research uncovers a surprising relationship between the appearance of chrome balls and the initial diffusion noise map, which we utilize to consistently generate high-quality chrome balls. We further fine-tune an LDR difusion model (Stable Diffusion XL) with LoRA, enabling it to perform exposure bracketing for HDR light estimation. Our method produces convincing light estimates across diverse settings and demonstrates superior generalization to in-the-wild scenarios.