 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Object-Centric Image Generation with Factored Depths, Locations, and Appearances
Apr 01, 2020
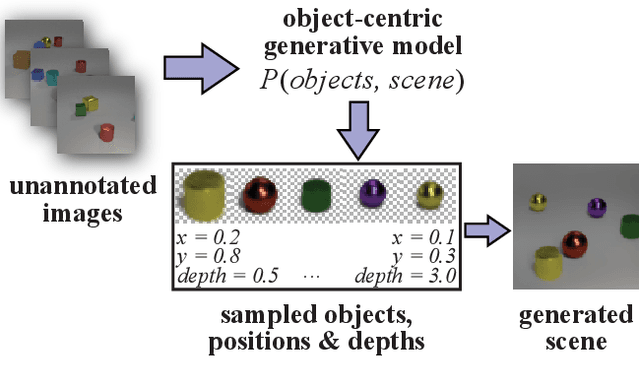
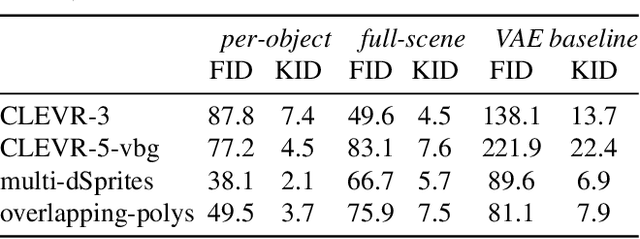
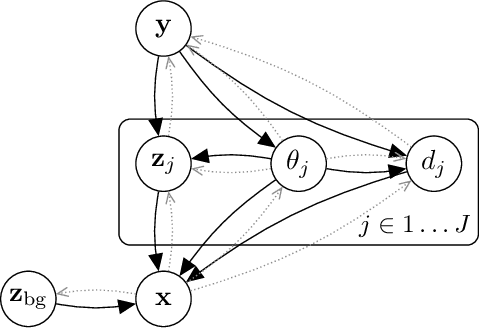
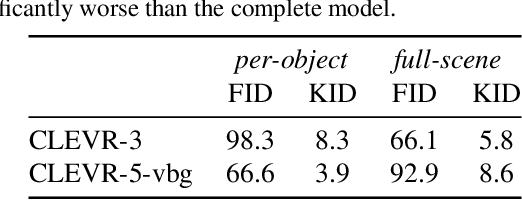
We present a generative model of images that explicitly reasons over the set of objects they show. Our model learns a structured latent representation that separates objects from each other and from the background; unlike prior works, it explicitly represents the 2D position and depth of each object, as well as an embedding of its segmentation mask and appearance. The model can be trained from images alone in a purely unsupervised fashion without the need for object masks or depth information. Moreover, it always generates complete objects, even though a significant fraction of training images contain occlusions. Finally, we show that our model can infer decompositions of novel images into their constituent objects, including accurate prediction of depth ordering and segmentation of occluded parts.
A Survey on Assessing the Generalization Envelope of Deep Neural Networks at Inference Time for Image Classification
Aug 21, 2020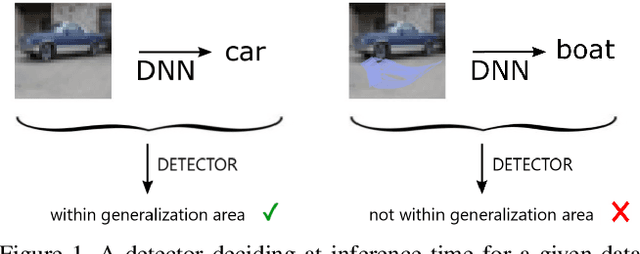

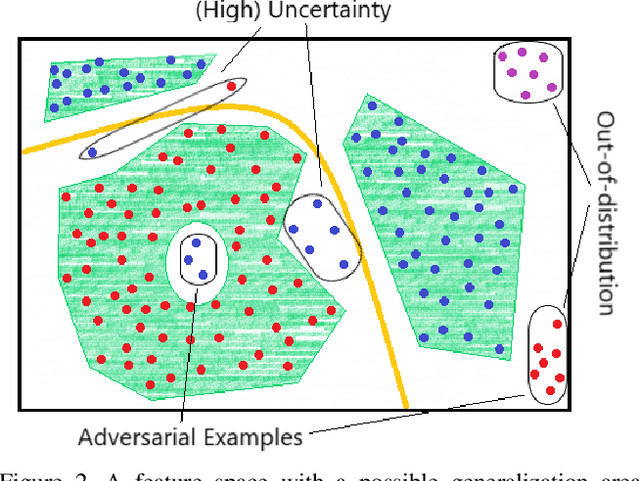
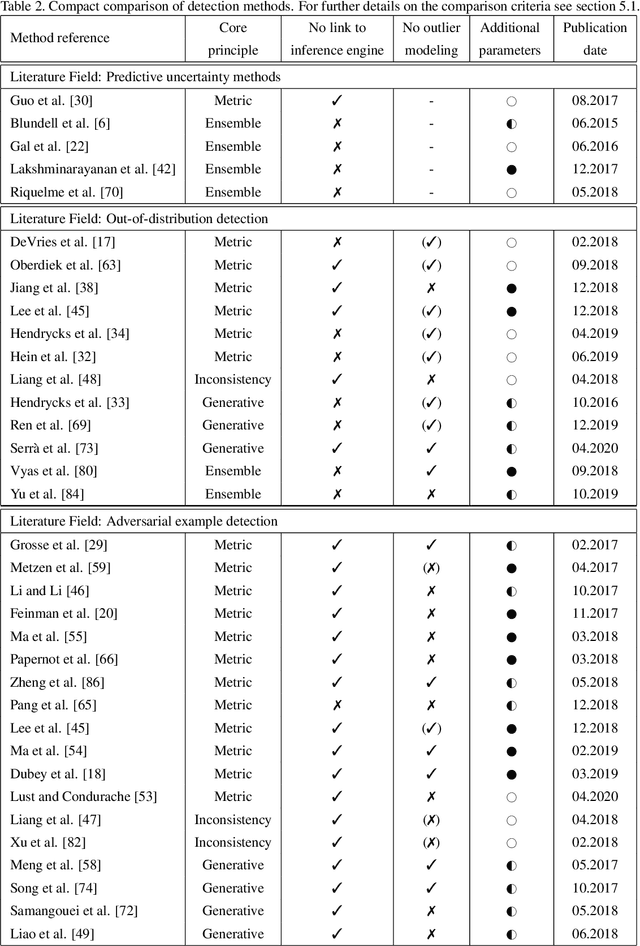
Deep Neural Networks (DNNs) achieve state-of-the-art performance on numerous problem set-ups. However, humans are not able to tell beforehand if a DNN receiving an input will deliver the desired output since their decision criteria are usually non-transparent. A DNN delivers the desired output if the input is within its generalization envelope. In this case, the information contained in the input sample is processed reasonably by the network. Since common DNNs fail to provide relevant information to assess the generalization envelope at inference time, additional methods or adaptations to the DNN have to be performed. Existing methods are evaluated using different set-ups respectively connected to three literature fields: predictive uncertainty, out-of-distribution detection and adversarial example detection. This survey connects those fields and gives an overview of the adaptations and methods that provide at inference time information if the current input is within the generalization area of a DNN.
Keep Your AI-es on the Road: Tackling Distracted Driver Detection with Convolutional Neural Networks and Targeted Data Augmentation
Jun 24, 2020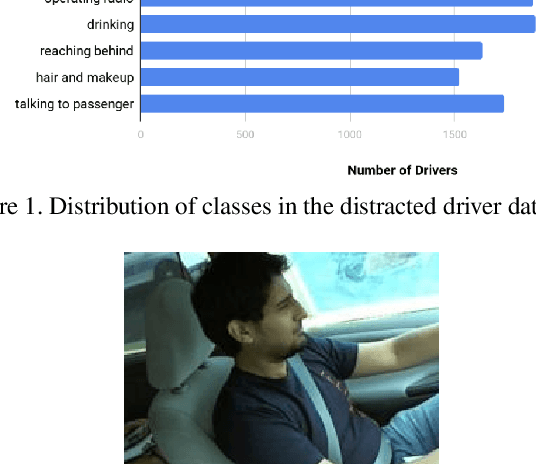

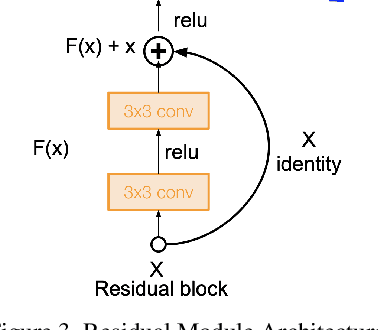

According to the World Health Organization, distracted driving is one of the leading cause of motor accidents and deaths in the world. In our study, we tackle the problem of distracted driving by aiming to build a robust multi-class classifier to detect and identify different forms of driver inattention using the State Farm Distracted Driving Dataset. We utilize combinations of pretrained image classification models, classical data augmentation, OpenCV based image preprocessing and skin segmentation augmentation approaches. Our best performing model combines several augmentation techniques, including skin segmentation, facial blurring, and classical augmentation techniques. This model achieves an approximately 15% increase in F1 score over the baseline, thus showing the promise in these techniques in enhancing the power of neural networks for the task of distracted driver detection.
Supervised and Unsupervised Learning of Parameterized Color Enhancement
Dec 30, 2019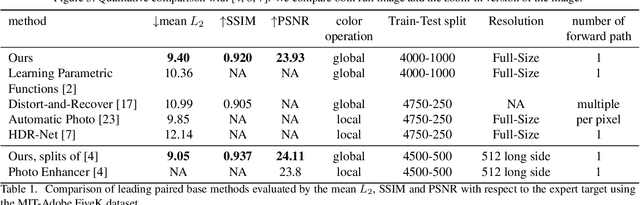
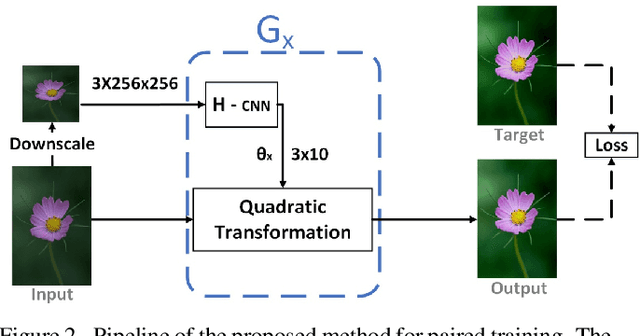

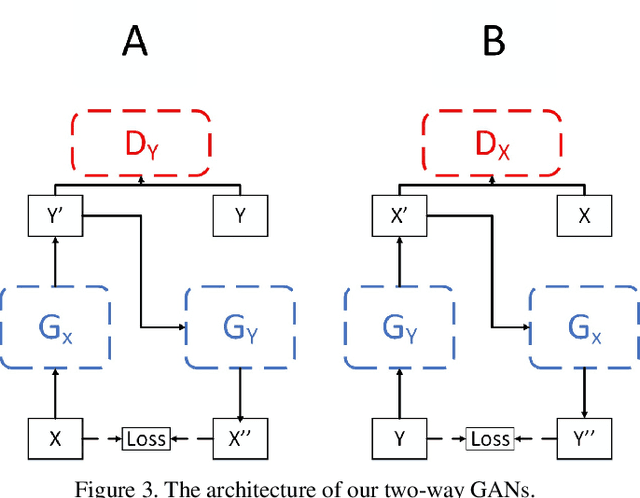
We treat the problem of color enhancement as an image translation task, which we tackle using both supervised and unsupervised learning. Unlike traditional image to image generators, our translation is performed using a global parameterized color transformation instead of learning to directly map image information. In the supervised case, every training image is paired with a desired target image and a convolutional neural network (CNN) learns from the expert retouched images the parameters of the transformation. In the unpaired case, we employ two-way generative adversarial networks (GANs) to learn these parameters and apply a circularity constraint. We achieve state-of-the-art results compared to both supervised (paired data) and unsupervised (unpaired data) image enhancement methods on the MIT-Adobe FiveK benchmark. Moreover, we show the generalization capability of our method, by applying it on photos from the early 20th century and to dark video frames.
A Multi-Level Approach to Waste Object Segmentation
Jul 08, 2020

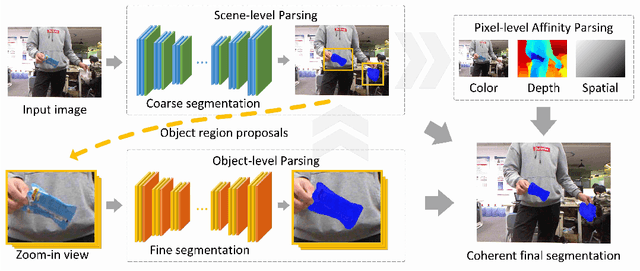
We address the problem of localizing waste objects from a color image and an optional depth image, which is a key perception component for robotic interaction with such objects. Specifically, our method integrates the intensity and depth information at multiple levels of spatial granularity. Firstly, a scene-level deep network produces an initial coarse segmentation, based on which we select a few potential object regions to zoom in and perform fine segmentation. The results of the above steps are further integrated into a densely connected conditional random field that learns to respect the appearance, depth, and spatial affinities with pixel-level accuracy. In addition, we create a new RGBD waste object segmentation dataset, MJU-Waste, that is made public to facilitate future research in this area. The efficacy of our method is validated on both MJU-Waste and the Trash Annotation in Context (TACO) dataset.
Reinforcement Learning with Latent Flow
Jan 06, 2021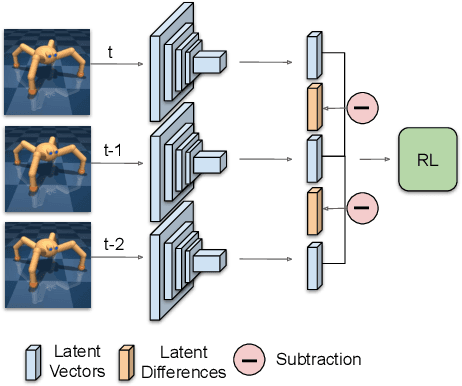

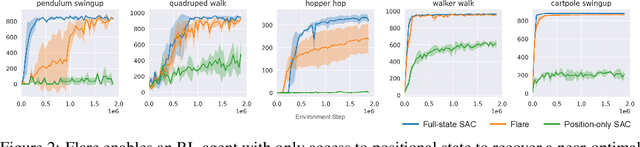

Temporal information is essential to learning effective policies with Reinforcement Learning (RL). However, current state-of-the-art RL algorithms either assume that such information is given as part of the state space or, when learning from pixels, use the simple heuristic of frame-stacking to implicitly capture temporal information present in the image observations. This heuristic is in contrast to the current paradigm in video classification architectures, which utilize explicit encodings of temporal information through methods such as optical flow and two-stream architectures to achieve state-of-the-art performance. Inspired by leading video classification architectures, we introduce the Flow of Latents for Reinforcement Learning (Flare), a network architecture for RL that explicitly encodes temporal information through latent vector differences. We show that Flare (i) recovers optimal performance in state-based RL without explicit access to the state velocity, solely with positional state information, (ii) achieves state-of-the-art performance on pixel-based challenging continuous control tasks within the DeepMind control benchmark suite, namely quadruped walk, hopper hop, finger turn hard, pendulum swing, and walker run, and is the most sample efficient model-free pixel-based RL algorithm, outperforming the prior model-free state-of-the-art by 1.9X and 1.5X on the 500k and 1M step benchmarks, respectively, and (iv), when augmented over rainbow DQN, outperforms this state-of-the-art level baseline on 5 of 8 challenging Atari games at 100M time step benchmark.
Implicit Rank-Minimizing Autoencoder
Oct 01, 2020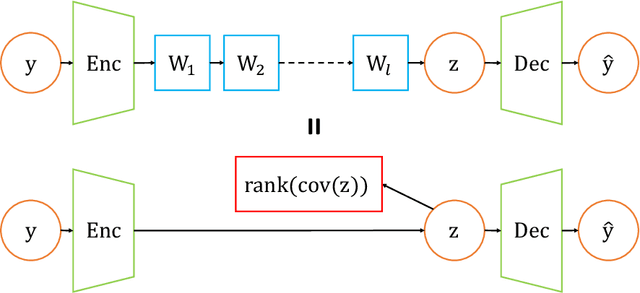
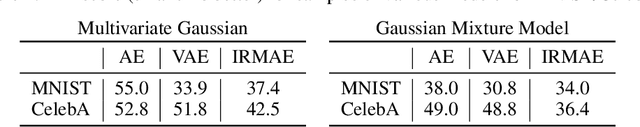
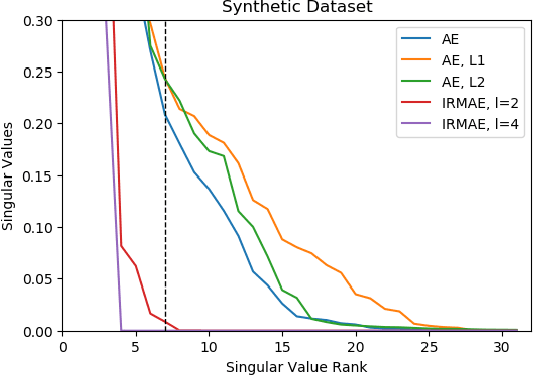
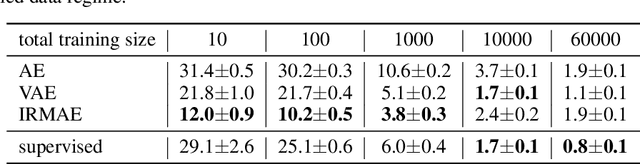
An important component of autoencoders is the method by which the information capacity of the latent representation is minimized or limited. In this work, the rank of the covariance matrix of the codes is implicitly minimized by relying on the fact that gradient descent learning in multi-layer linear networks leads to minimum-rank solutions. By inserting a number of extra linear layers between the encoder and the decoder, the system spontaneously learns representations with a low effective dimension. The model, dubbed Implicit Rank-Minimizing Autoencoder (IRMAE), is simple, deterministic, and learns compact latent spaces. We demonstrate the validity of the method on several image generation and representation learning tasks.
Screening COVID-19 Based on CT/CXR Images & Building a Publicly Available CT-scan Dataset of COVID-19
Dec 28, 2020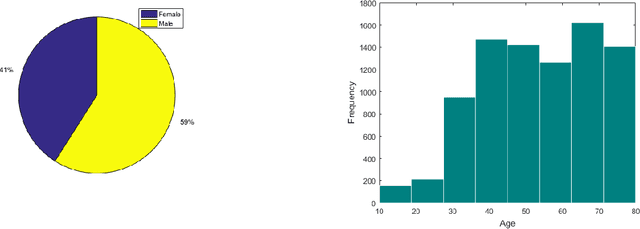
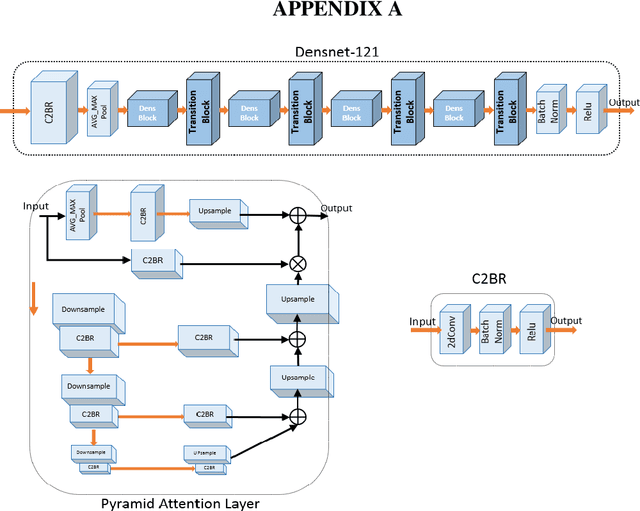
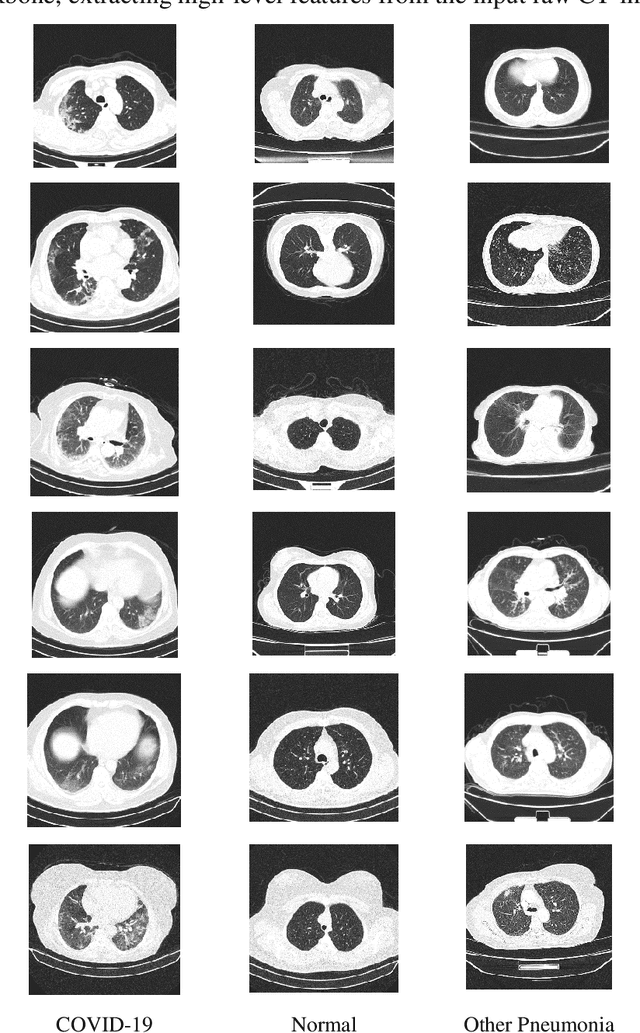
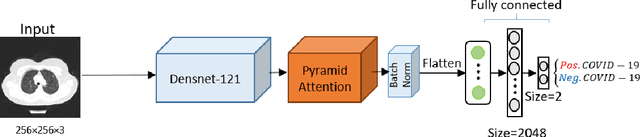
The rapid outbreak of COVID-19 threatens humans life all around the world. Due to insufficient diagnostic infrastructures, developing an accurate, efficient, inexpensive, and quick diagnostic tool is of great importance. As chest radiography, such as chest X-ray (CXR) and CT computed tomography (CT), is a possible way for screening COVID-19, developing an automatic image classification tool is immensely helpful for detecting the patients with COVID-19. To date, researchers have proposed several different screening methods; however, none of them could achieve a reliable and highly sensitive performance yet. The main drawbacks of current methods are the lack of having enough training data, low generalization performance, and a high rate of false-positive detection. To tackle such limitations, this study firstly builds a large-size publicly available CT-scan dataset, consisting of more than 13k CT-images of more than 1000 individuals, in which 8k images are taken from 500 patients infected with COVID-19. Secondly, we propose a deep learning model for screening COVID-19 using our proposed CT dataset and report the baseline results. Finally, we extend the proposed CT model for screening COVID-19 from CXR images using a transfer learning approach. The experimental results show that the proposed CT and CXR methods achieve the AUC scores of 0.886 and 0.984 respectively.
Defocus Deblurring Using Dual-Pixel Data
May 01, 2020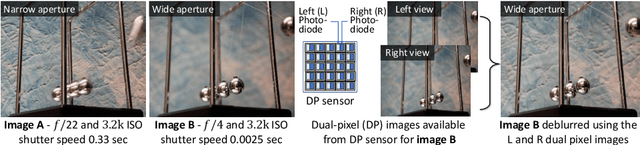
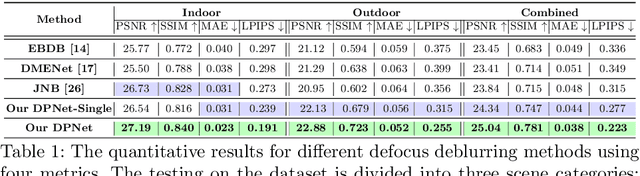
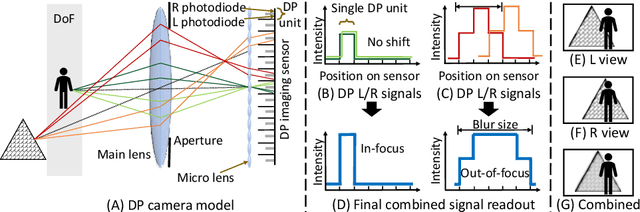
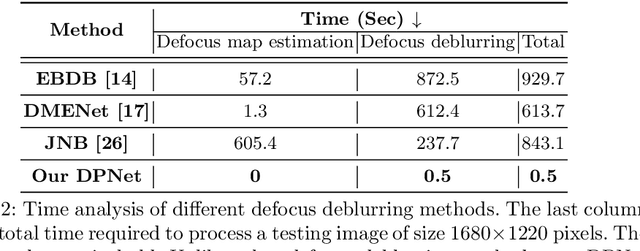
Defocus blur arises in images that are captured with a shallow depth of field due to the use of a wide aperture. Correcting defocus blur is challenging because the blur is spatially varying and difficult to estimate. We propose an effective defocus deblurring method that exploits data available on dual-pixel (DP) sensors found on most modern cameras. DP sensors are used to assist a camera's auto-focus by capturing two sub-aperture views of the scene in a single image shot. The two sub-aperture images are used to calculate the appropriate lens position to focus on a particular scene region and are discarded afterwards. We introduce a deep neural network (DNN) architecture that uses these discarded sub-aperture images to reduce defocus deblur. A key contribution of our effort is a carefully captured dataset of 500 scenes (2,000 images) where each scene has: (i) an image with defocus blur captured at a large aperture; (ii) the two associated DP sub-aperture views; and (iii) the corresponding all-in-focus image captured with a small aperture. Our proposed DNN produces results that are significantly better than conventional single image methods in terms of both quantitative and perceptual metrics -- all from data that is already available on the camera but ignored. The dataset, code, and the trained models will be available at https://github.com/Abdullah-Abuolaim/defocus-deblurring-dual-pixel.
IF-Net: An Illumination-invariant Feature Network
Aug 10, 2020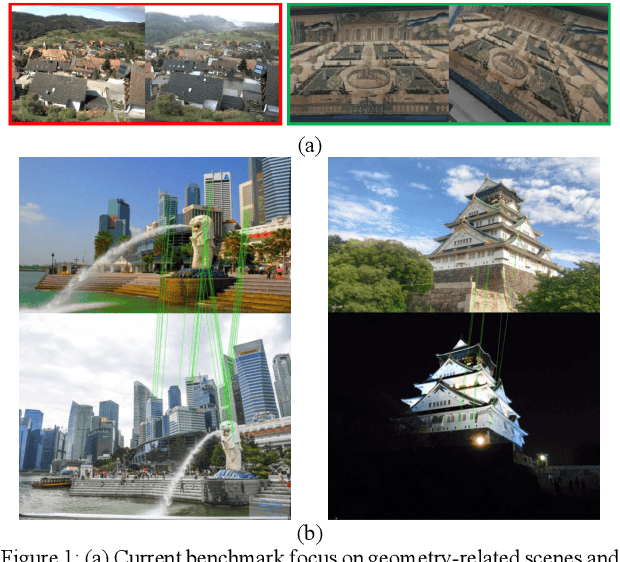
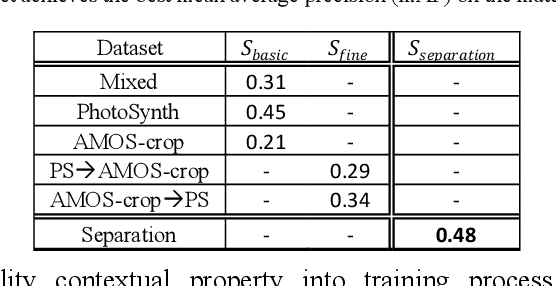


Feature descriptor matching is a critical step is many computer vision applications such as image stitching, image retrieval and visual localization. However, it is often affected by many practical factors which will degrade its performance. Among these factors, illumination variations are the most influential one, and especially no previous descriptor learning works focus on dealing with this problem. In this paper, we propose IF-Net, aimed to generate a robust and generic descriptor under crucial illumination changes conditions. We find out not only the kind of training data important but also the order it is presented. To this end, we investigate several dataset scheduling methods and propose a separation training scheme to improve the matching accuracy. Further, we propose a ROI loss and hard-positive mining strategy along with the training scheme, which can strengthen the ability of generated descriptor dealing with large illumination change conditions. We evaluate our approach on public patch matching benchmark and achieve the best results compared with several state-of-the-arts methods. To show the practicality, we further evaluate IF-Net on the task of visual localization under large illumination changes scenes, and achieves the best localization accuracy.