 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Region-Based Image Retrieval Revisited
Sep 26, 2017
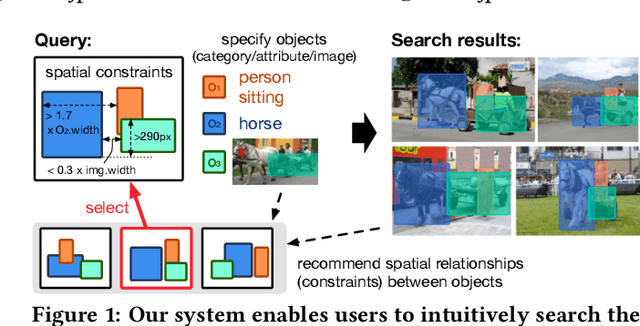
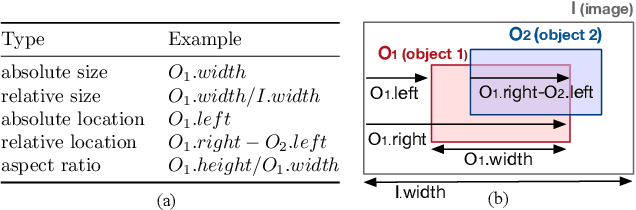
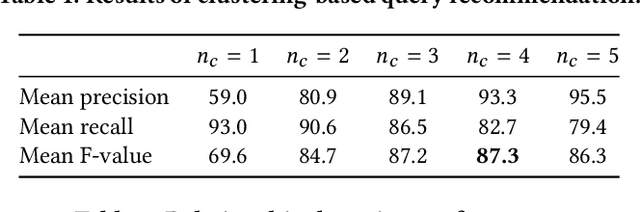
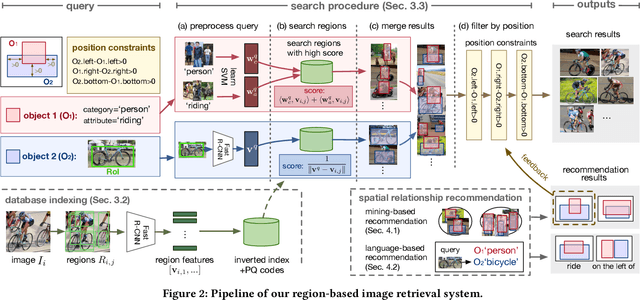
Region-based image retrieval (RBIR) technique is revisited. In early attempts at RBIR in the late 90s, researchers found many ways to specify region-based queries and spatial relationships; however, the way to characterize the regions, such as by using color histograms, were very poor at that time. Here, we revisit RBIR by incorporating semantic specification of objects and intuitive specification of spatial relationships. Our contributions are the following. First, to support multiple aspects of semantic object specification (category, instance, and attribute), we propose a multitask CNN feature that allows us to use deep learning technique and to jointly handle multi-aspect object specification. Second, to help users specify spatial relationships among objects in an intuitive way, we propose recommendation techniques of spatial relationships. In particular, by mining the search results, a system can recommend feasible spatial relationships among the objects. The system also can recommend likely spatial relationships by assigned object category names based on language prior. Moreover, object-level inverted indexing supports very fast shortlist generation, and re-ranking based on spatial constraints provides users with instant RBIR experiences.
Domain Adaptation with Morphologic Segmentation
Jun 16, 2020


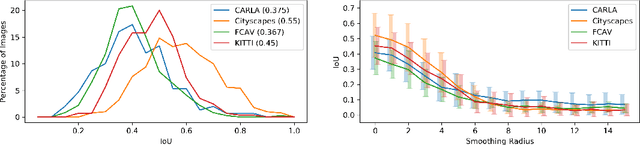
We present a novel domain adaptation framework that uses morphologic segmentation to translate images from arbitrary input domains (real and synthetic) into a uniform output domain. Our framework is based on an established image-to-image translation pipeline that allows us to first transform the input image into a generalized representation that encodes morphology and semantics - the edge-plus-segmentation map (EPS) - which is then transformed into an output domain. Images transformed into the output domain are photo-realistic and free of artifacts that are commonly present across different real (e.g. lens flare, motion blur, etc.) and synthetic (e.g. unrealistic textures, simplified geometry, etc.) data sets. Our goal is to establish a preprocessing step that unifies data from multiple sources into a common representation that facilitates training downstream tasks in computer vision. This way, neural networks for existing tasks can be trained on a larger variety of training data, while they are also less affected by overfitting to specific data sets. We showcase the effectiveness of our approach by qualitatively and quantitatively evaluating our method on four data sets of simulated and real data of urban scenes. Additional results can be found on the project website available at http://jonathank.de/research/eps/ .
Deep Representation Decomposition for Feature Disentanglement
Nov 02, 2020



Representation disentanglement aims at learning interpretable features, so that the output can be recovered or manipulated accordingly. While existing works like infoGAN and AC-GAN exist, they choose to derive disjoint attribute code for feature disentanglement, which is not applicable for existing/trained generative models. In this paper, we propose a decomposition-GAN (dec-GAN), which is able to achieve the decomposition of an existing latent representation into content and attribute features. Guided by the classifier pre-trained on the attributes of interest, our dec-GAN decomposes the attributes of interest from the latent representation, while data recovery and feature consistency objectives enforce the learning of our proposed method. Our experiments on multiple image datasets confirm the effectiveness and robustness of our dec-GAN over recent representation disentanglement models.
A Sequence-Oblivious Generation Method for Context-Aware Hashtag Recommendation
Dec 05, 2020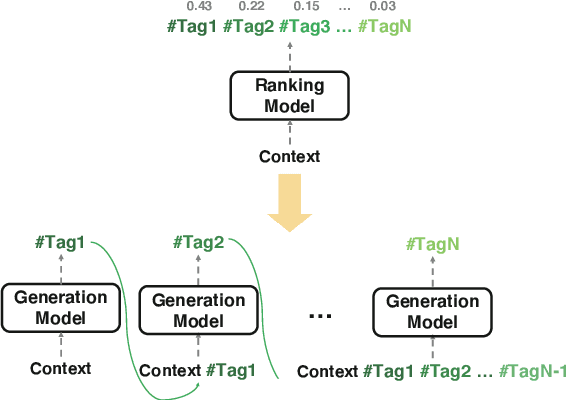
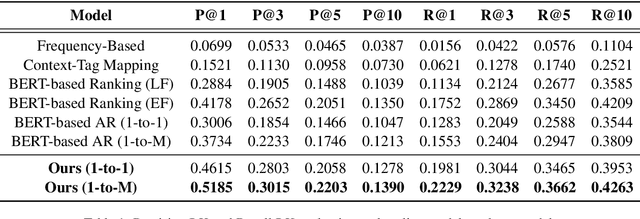
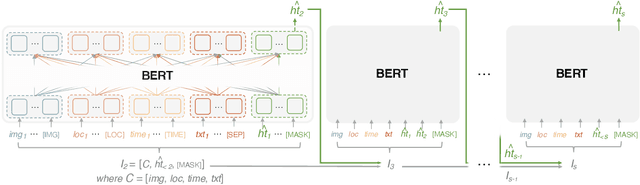
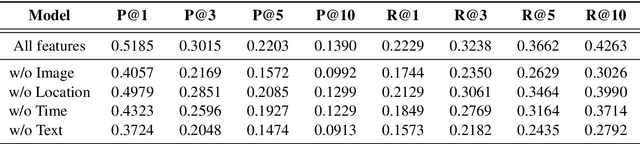
Like search, a recommendation task accepts an input query or cue and provides desirable items, often based on a ranking function. Such a ranking approach rarely considers explicit dependency among the recommended items. In this work, we propose a generative approach to tag recommendation, where semantic tags are selected one at a time conditioned on the previously generated tags to model inter-dependency among the generated tags. We apply this tag recommendation approach to an Instagram data set where an array of context feature types (image, location, time, and text) are available for posts. To exploit the inter-dependency among the distinct types of features, we adopt a simple yet effective architecture using self-attention, making deep interactions possible. Empirical results show that our method is significantly superior to not only the usual ranking schemes but also autoregressive models for tag recommendation. They indicate that it is critical to fuse mutually supporting features at an early stage to induce extensive and comprehensive view on inter-context interaction in generating tags in a recurrent feedback loop.
When and Why Test-Time Augmentation Works
Nov 23, 2020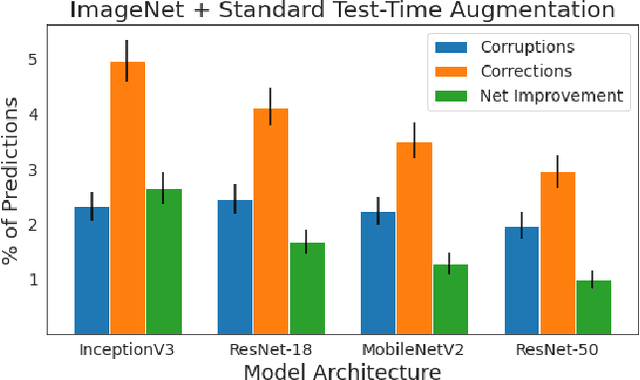
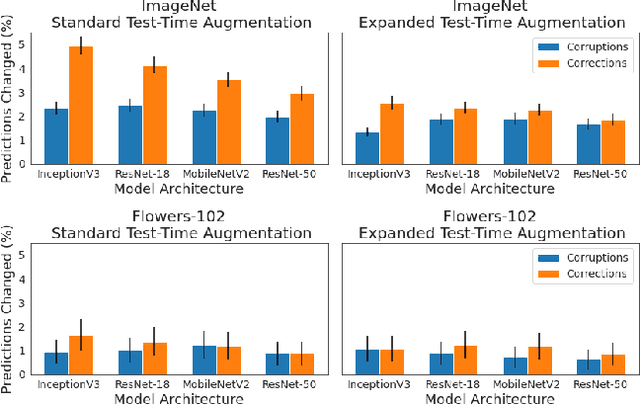
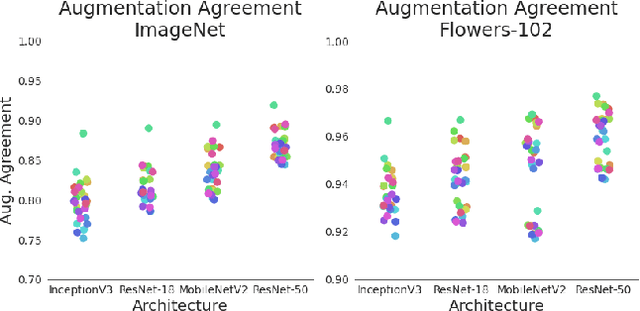
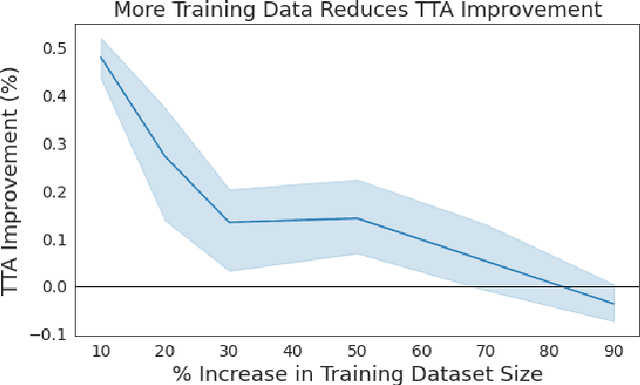
Test-time augmentation (TTA)---the aggregation of predictions across transformed versions of a test input---is a common practice in image classification. In this paper, we present theoretical and experimental analyses that shed light on 1) when test time augmentation is likely to be helpful and 2) when to use various test-time augmentation policies. A key finding is that even when TTA produces a net improvement in accuracy, it can change many correct predictions into incorrect predictions. We delve into when and why test-time augmentation changes a prediction from being correct to incorrect and vice versa. Our analysis suggests that the nature and amount of training data, the model architecture, and the augmentation policy all matter. Building on these insights, we present a learning-based method for aggregating test-time augmentations. Experiments across a diverse set of models, datasets, and augmentations show that our method delivers consistent improvements over existing approaches.
Super-resolution Variational Auto-Encoders
Jun 30, 2020

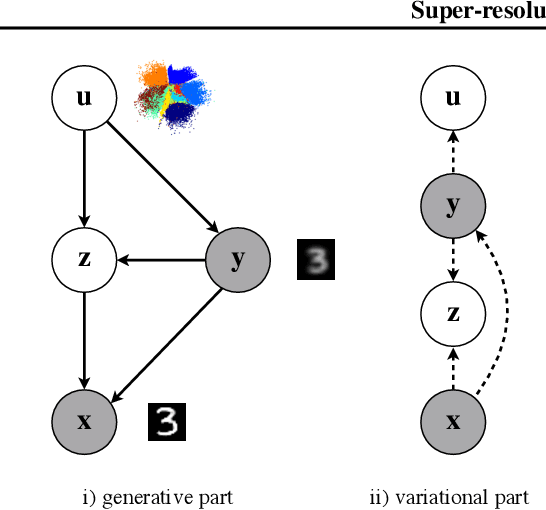
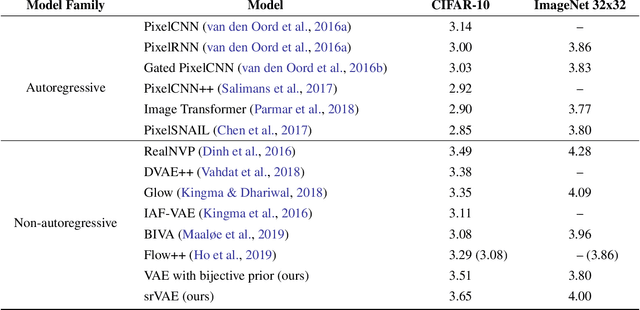
The framework of variational autoencoders (VAEs) provides a principled method for jointly learning latent-variable models and corresponding inference models. However, the main drawback of this approach is the blurriness of the generated images. Some studies link this effect to the objective function, namely, the (negative) log-likelihood. Here, we propose to enhance VAEs by adding a random variable that is a downscaled version of the original image and still use the log-likelihood function as the learning objective. Further, by providing the downscaled image as an input to the decoder, it can be used in a manner similar to the super-resolution. We present empirically that the proposed approach performs comparably to VAEs in terms of the negative log-likelihood, but it obtains a better FID score in data synthesis.
Unsupervised Cross-Modality Domain Adaptation of ConvNets for Biomedical Image Segmentations with Adversarial Loss
Jun 19, 2018
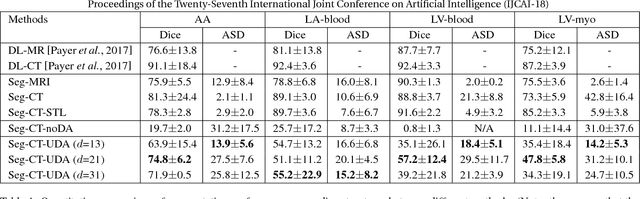
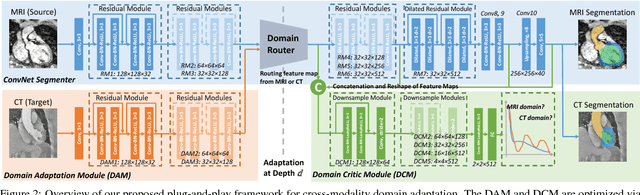
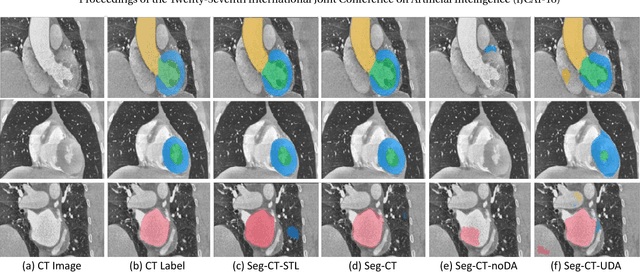
Convolutional networks (ConvNets) have achieved great successes in various challenging vision tasks. However, the performance of ConvNets would degrade when encountering the domain shift. The domain adaptation is more significant while challenging in the field of biomedical image analysis, where cross-modality data have largely different distributions. Given that annotating the medical data is especially expensive, the supervised transfer learning approaches are not quite optimal. In this paper, we propose an unsupervised domain adaptation framework with adversarial learning for cross-modality biomedical image segmentations. Specifically, our model is based on a dilated fully convolutional network for pixel-wise prediction. Moreover, we build a plug-and-play domain adaptation module (DAM) to map the target input to features which are aligned with source domain feature space. A domain critic module (DCM) is set up for discriminating the feature space of both domains. We optimize the DAM and DCM via an adversarial loss without using any target domain label. Our proposed method is validated by adapting a ConvNet trained with MRI images to unpaired CT data for cardiac structures segmentations, and achieved very promising results.
Generative Adversarial Networks as stochastic Nash games
Oct 17, 2020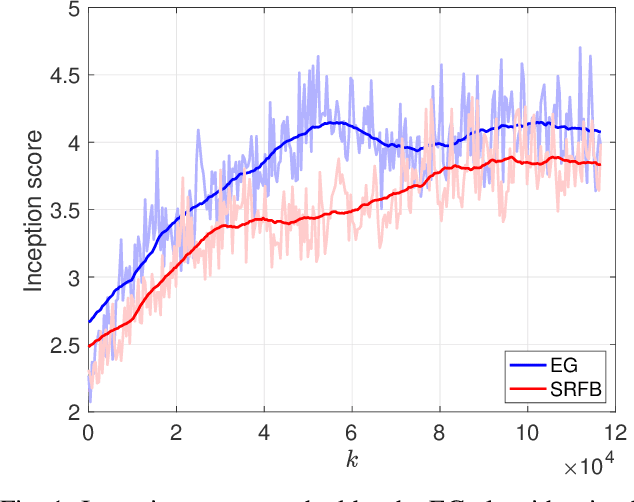


Generative adversarial networks (GANs) are a class of generative models with two antagonistic neural networks: the generator and the discriminator. These two neural networks compete against each other through an adversarial process that can be modelled as a stochastic Nash equilibrium problem. Since the associated training process is challenging, it is fundamental to design reliable algorithms to compute an equilibrium. In this paper, we propose a stochastic relaxed forward-backward algorithm for GANs and we show convergence to an exact solution or to a neighbourhood of it, if the pseudogradient mapping of the game is monotone. We apply our algorithm to the image generation problem where we observe computational advantages with respect to the extragradient scheme.
multi-patch aggregation models for resampling detection
Mar 03, 2020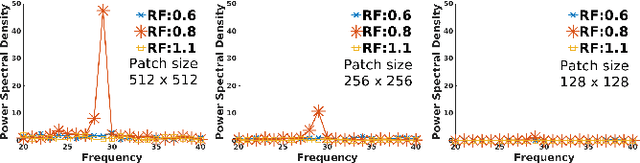

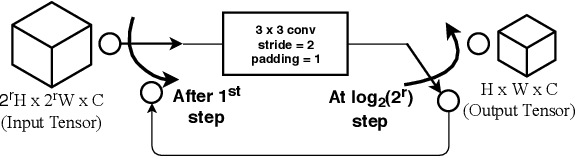
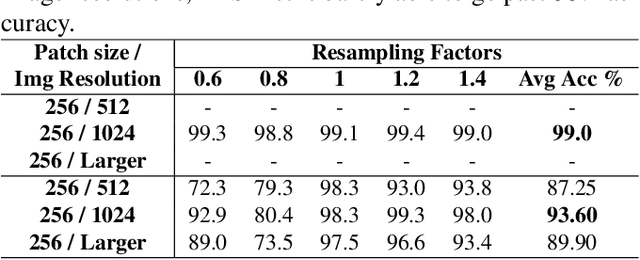
Images captured nowadays are of varying dimensions with smartphones and DSLR's allowing users to choose from a list of available image resolutions. It is therefore imperative for forensic algorithms such as resampling detection to scale well for images of varying dimensions. However, in our experiments, we observed that many state-of-the-art forensic algorithms are sensitive to image size and their performance quickly degenerates when operated on images of diverse dimensions despite re-training them using multiple image sizes. To handle this issue, we propose a novel pooling strategy called ITERATIVE POOLING. This pooling strategy can dynamically adjust input tensors in a discrete without much loss of information as in ROI Max-pooling. This pooling strategy can be used with any of the existing deep models and for demonstration purposes, we show its utility on Resnet-18 for the case of resampling detection a fundamental operation for any image sought of image manipulation. Compared to existing strategies and Max-pooling it gives up to 7-8% improvement on public datasets.
Dense open-set recognition with synthetic outliers generated by Real NVP
Nov 22, 2020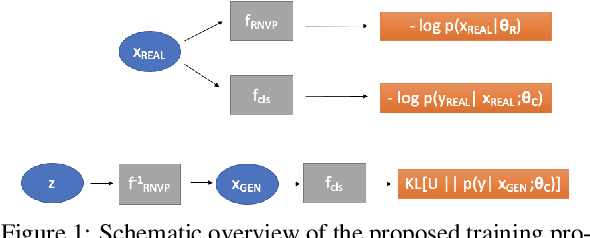

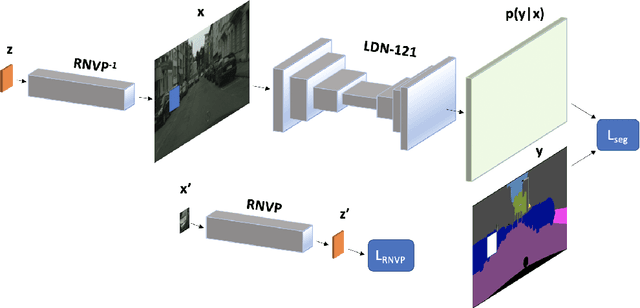
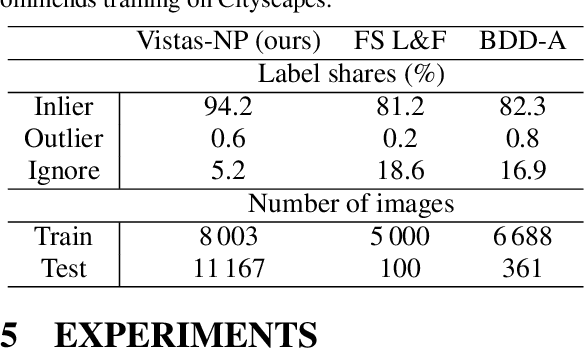
Today's deep models are often unable to detect inputs which do not belong to the training distribution. This gives rise to confident incorrect predictions which could lead to devastating consequences in many important application fields such as healthcare and autonomous driving. Interestingly, both discriminative and generative models appear to be equally affected. Consequently, this vulnerability represents an important research challenge. We consider an outlier detection approach based on discriminative training with jointly learned synthetic outliers. We obtain the synthetic outliers by sampling an RNVP model which is jointly trained to generate datapoints at the border of the training distribution. We show that this approach can be adapted for simultaneous semantic segmentation and dense outlier detection. We present image classification experiments on CIFAR-10, as well as semantic segmentation experiments on three existing datasets (StreetHazards, WD-Pascal, Fishyscapes Lost & Found), and one contributed dataset. Our models perform competitively with respect to the state of the art despite producing predictions with only one forward pass.