 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Dense U-net for super-resolution with shuffle pooling layer
Nov 11, 2020
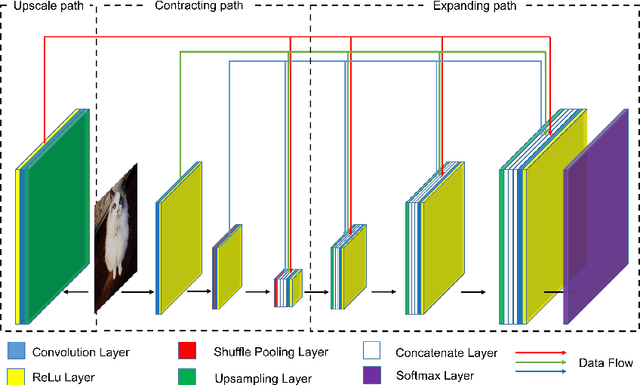
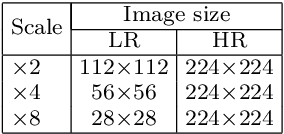
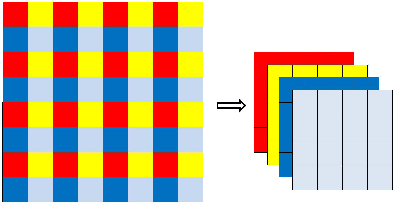
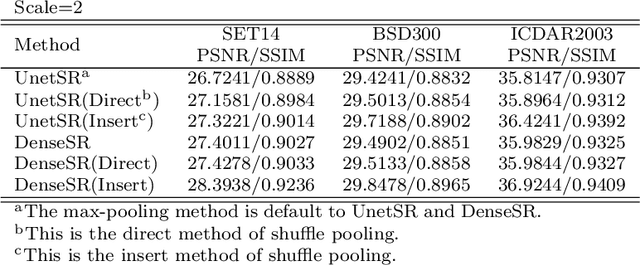
Single image super-resolution (SISR) in unconstrained environments is challenging because of various illuminations, occlusion and complex environments. Recent researches have achieved great progress on super-resolution due to the development of deep learning in the field of computer vision. In this letter, a Dense U-net with shuffle pooling method is proposed. First, a modified U-net with dense blocks, called dense U-net, is proposed for SISR. Second, a novel pooling strategy called shuffle pooling is designed, which is applied to the dense U-Net for super-resolution task. Third, a mix loss function, which combined with Mean Square Error(MSE), Structural Similarity Index (SSIM) and Mean Gradient Error (MGE), is proposed to solve the perception loss and high-frequency information loss. The proposed method achieves superior accuracy over previous state-of-the-arts on the three benchmark datasets: SET14, BSD300, ICDAR2003. Code is available online.
KRISP: Integrating Implicit and Symbolic Knowledge for Open-Domain Knowledge-Based VQA
Dec 20, 2020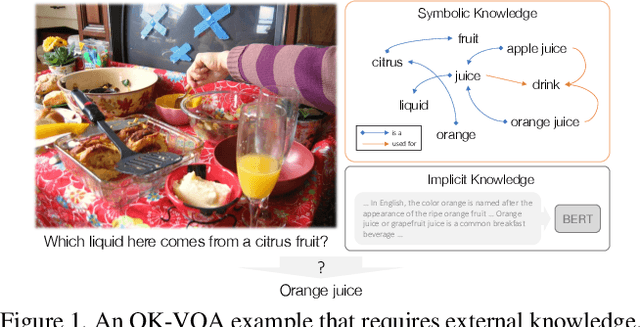



One of the most challenging question types in VQA is when answering the question requires outside knowledge not present in the image. In this work we study open-domain knowledge, the setting when the knowledge required to answer a question is not given/annotated, neither at training nor test time. We tap into two types of knowledge representations and reasoning. First, implicit knowledge which can be learned effectively from unsupervised language pre-training and supervised training data with transformer-based models. Second, explicit, symbolic knowledge encoded in knowledge bases. Our approach combines both - exploiting the powerful implicit reasoning of transformer models for answer prediction, and integrating symbolic representations from a knowledge graph, while never losing their explicit semantics to an implicit embedding. We combine diverse sources of knowledge to cover the wide variety of knowledge needed to solve knowledge-based questions. We show our approach, KRISP (Knowledge Reasoning with Implicit and Symbolic rePresentations), significantly outperforms state-of-the-art on OK-VQA, the largest available dataset for open-domain knowledge-based VQA. We show with extensive ablations that while our model successfully exploits implicit knowledge reasoning, the symbolic answer module which explicitly connects the knowledge graph to the answer vocabulary is critical to the performance of our method and generalizes to rare answers.
A deep learning classifier for local ancestry inference
Nov 04, 2020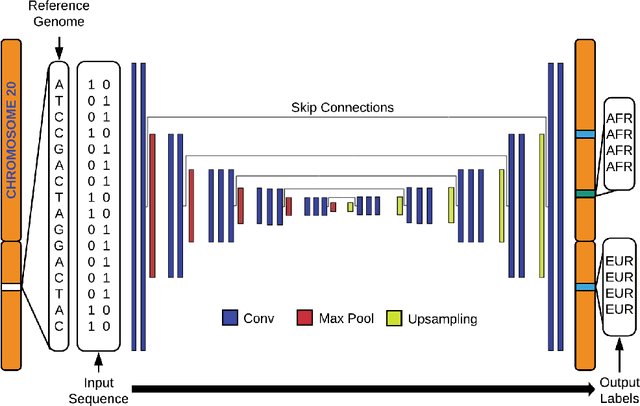
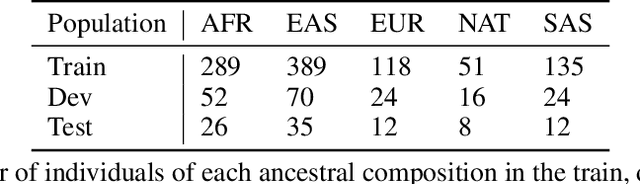
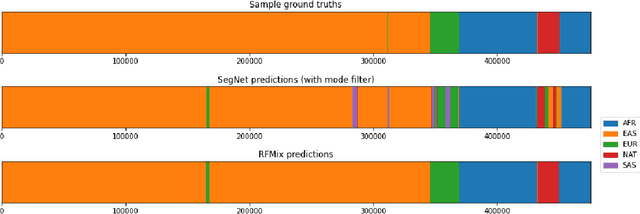
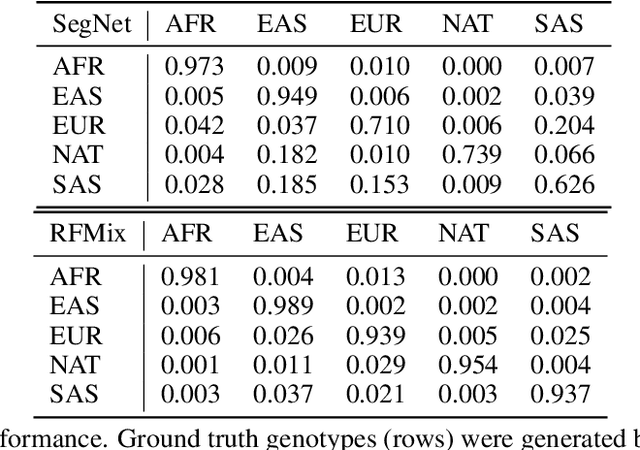
Local ancestry inference (LAI) identifies the ancestry of each segment of an individual's genome and is an important step in medical and population genetic studies of diverse cohorts. Several techniques have been used for LAI, including Hidden Markov Models and Random Forests. Here, we formulate the LAI task as an image segmentation problem and develop a new LAI tool using a deep convolutional neural network with an encoder-decoder architecture. We train our model using complete genome sequences from 982 unadmixed individuals from each of five continental ancestry groups, and we evaluate it using simulated admixed data derived from an additional 279 individuals selected from the same populations. We show that our model is able to learn admixture as a zero-shot task, yielding ancestry assignments that are nearly as accurate as those from the existing gold standard tool, RFMix.
GAN- vs. JPEG2000 Image Compression for Distributed Automotive Perception: Higher Peak SNR Does Not Mean Better Semantic Segmentation
Feb 12, 2019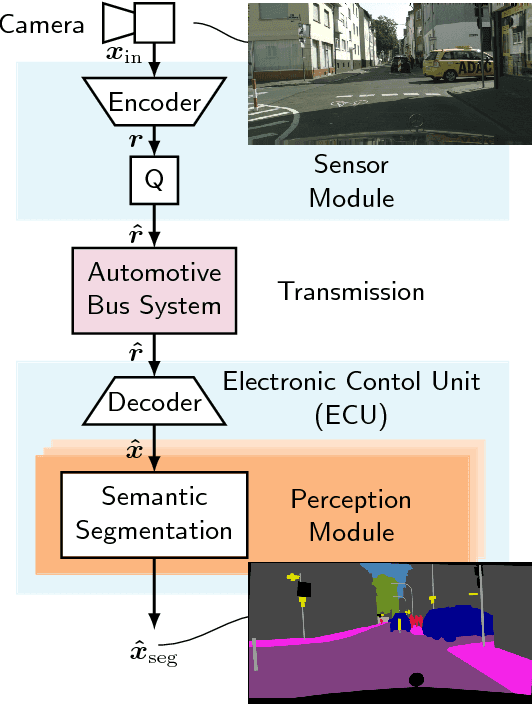
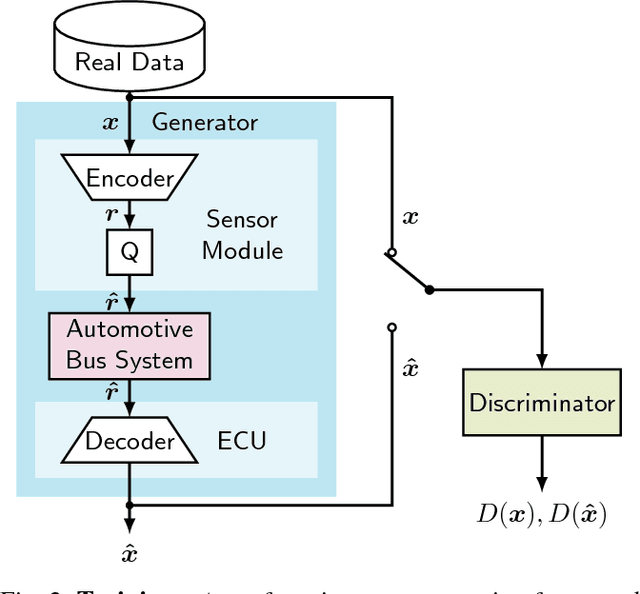
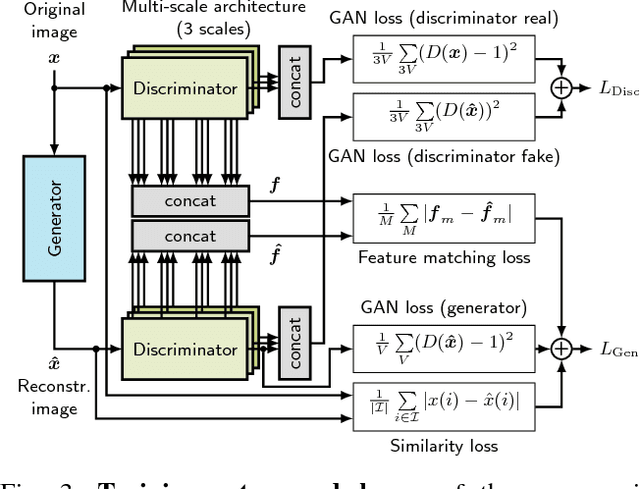

The high amount of sensors required for autonomous driving poses enormous challenges on the capacity of automotive bus systems. There is a need to understand tradeoffs between bitrate and perception performance. In this paper, we compare the image compression standards JPEG, JPEG2000, and WebP to a modern encoder/decoder image compression approach based on generative adversarial networks (GANs). We evaluate both the pure compression performance using typical metrics such as peak signal-to-noise ratio (PSNR), structural similarity (SSIM) and others, but also the performance of a subsequent perception function, namely a semantic segmentation (characterized by the mean intersection over union (mIoU) measure). Not surprisingly, for all investigated compression methods, a higher bitrate means better results in all investigated quality metrics. Interestingly, however, we show that the semantic segmentation mIoU of the GAN autoencoder in the highly relevant low-bitrate regime (at 0.0625 bit/pixel) is better by 3.9% absolute than JPEG2000, although the latter still is considerably better in terms of PSNR (5.91 dB difference). This effect can greatly be enlarged by training the semantic segmentation model with images originating from the decoder, so that the mIoU using the segmentation model trained by GAN reconstructions exceeds the use of the model trained with original images by almost 20% absolute. We conclude that distributed perception in future autonomous driving will most probably not provide a solution to the automotive bus capacity bottleneck by using standard compression schemes such as JPEG2000, but requires modern coding approaches, with the GAN encoder/decoder method being a promising candidate.
The Ensemble Method for Thorax Diseases Classification
Aug 12, 2020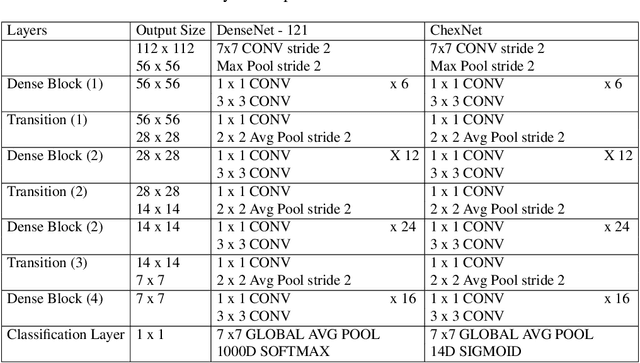
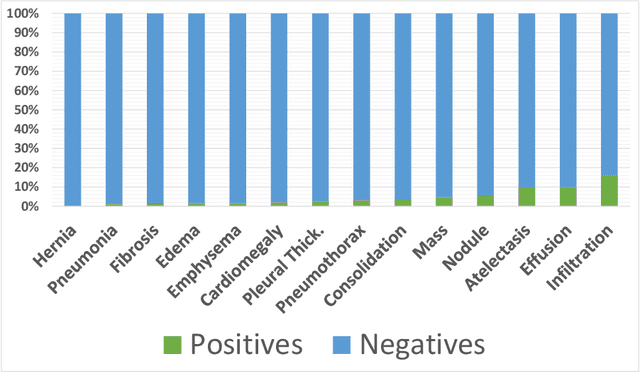
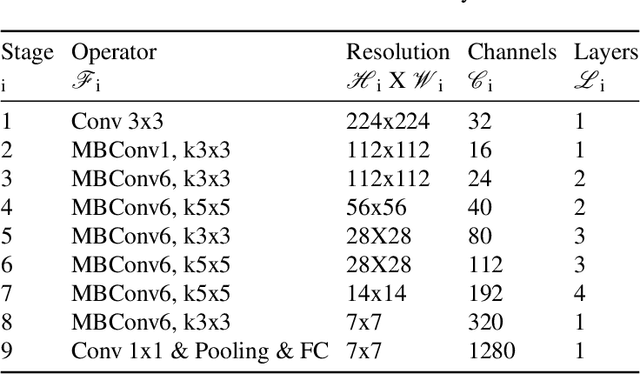
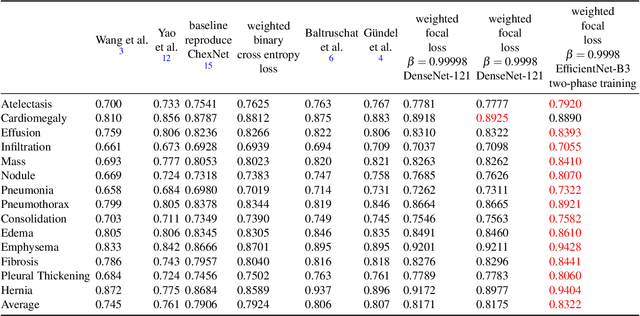
A common problem found in real-word medical image classification is the inherent imbalance of the positive and negative patterns in the dataset where positive patterns are usually rare. Moreover, in the classification of multiple classes with neural network, a training pattern is treated as a positive pattern in one output node and negative in all the remaining output nodes. In this paper, the weights of a training pattern in the loss function are designed based not only on the number of the training patterns in the class but also on the different nodes where one of them treats this training pattern as positive and the others treat it as negative. We propose a combined approach of weights calculation algorithm for deep network training and the training optimization from the state-of-the-art deep network architecture for thorax diseases classification problem. Experimental results on the Chest X-Ray image dataset demonstrate that this new weighting scheme improves classification performances, also the training optimization from the EfficientNet improves the performance furthermore. We compare the ensemble method with several performances from the previous study of thorax diseases classifications to provide the fair comparisons against the proposed method.
EDEN: Multimodal Synthetic Dataset of Enclosed GarDEN Scenes
Nov 10, 2020
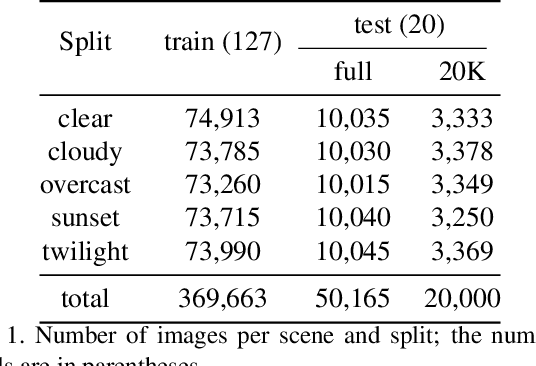

Multimodal large-scale datasets for outdoor scenes are mostly designed for urban driving problems. The scenes are highly structured and semantically different from scenarios seen in nature-centered scenes such as gardens or parks. To promote machine learning methods for nature-oriented applications, such as agriculture and gardening, we propose the multimodal synthetic dataset for Enclosed garDEN scenes (EDEN). The dataset features more than 300K images captured from more than 100 garden models. Each image is annotated with various low/high-level vision modalities, including semantic segmentation, depth, surface normals, intrinsic colors, and optical flow. Experimental results on the state-of-the-art methods for semantic segmentation and monocular depth prediction, two important tasks in computer vision, show positive impact of pre-training deep networks on our dataset for unstructured natural scenes. The dataset and related materials will be available at https://lhoangan.github.io/eden.
High-Fidelity Neural Human Motion Transfer from Monocular Video
Dec 20, 2020
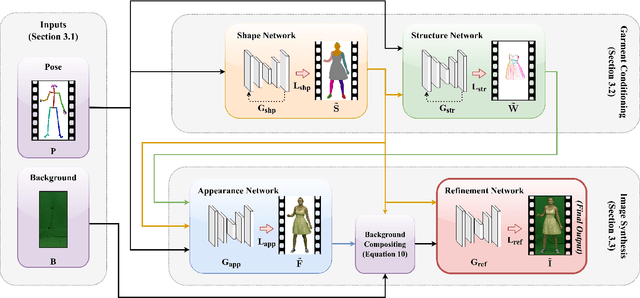


Video-based human motion transfer creates video animations of humans following a source motion. Current methods show remarkable results for tightly-clad subjects. However, the lack of temporally consistent handling of plausible clothing dynamics, including fine and high-frequency details, significantly limits the attainable visual quality. We address these limitations for the first time in the literature and present a new framework which performs high-fidelity and temporally-consistent human motion transfer with natural pose-dependent non-rigid deformations, for several types of loose garments. In contrast to the previous techniques, we perform image generation in three subsequent stages, synthesizing human shape, structure, and appearance. Given a monocular RGB video of an actor, we train a stack of recurrent deep neural networks that generate these intermediate representations from 2D poses and their temporal derivatives. Splitting the difficult motion transfer problem into subtasks that are aware of the temporal motion context helps us to synthesize results with plausible dynamics and pose-dependent detail. It also allows artistic control of results by manipulation of individual framework stages. In the experimental results, we significantly outperform the state-of-the-art in terms of video realism. Our code and data will be made publicly available.
Low Distortion Block-Resampling with Spatially Stochastic Networks
Jun 09, 2020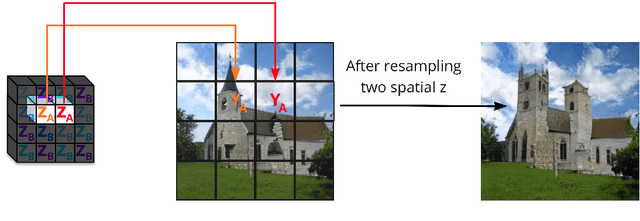


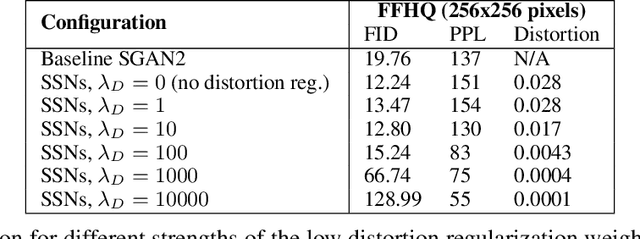
We formalize and attack the problem of generating new images from old ones that are as diverse as possible, only allowing them to change without restrictions in certain parts of the image while remaining globally consistent. This encompasses the typical situation found in generative modelling, where we are happy with parts of the generated data, but would like to resample others ("I like this generated castle overall, but this tower looks unrealistic, I would like a new one"). In order to attack this problem we build from the best conditional and unconditional generative models to introduce a new network architecture, training procedure, and algorithm for resampling parts of the image as desired.
Forensic Scanner Identification Using Machine Learning
Feb 06, 2020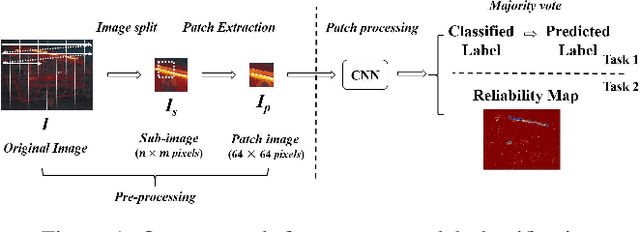
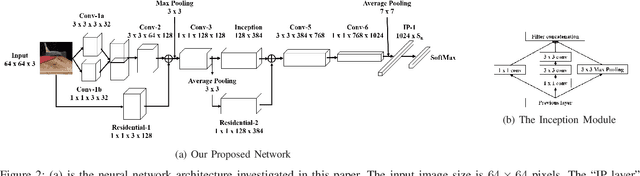
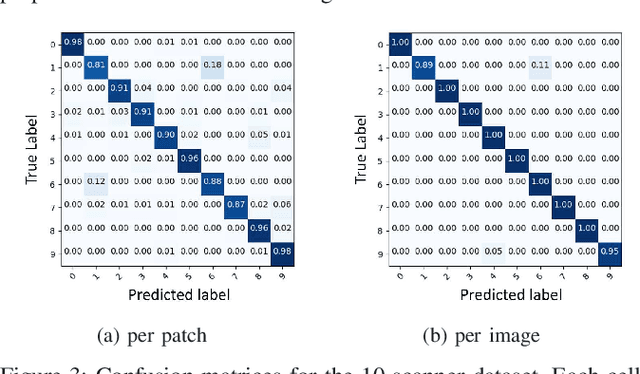

Due to the increasing availability and functionality of image editing tools, many forensic techniques such as digital image authentication, source identification and tamper detection are important for forensic image analysis. In this paper, we describe a machine learning based system to address the forensic analysis of scanner devices. The proposed system uses deep-learning to automatically learn the intrinsic features from various scanned images. Our experimental results show that high accuracy can be achieved for source scanner identification. The proposed system can also generate a reliability map that indicates the manipulated regions in an scanned image.
Inability of spatial transformations of CNN feature maps to support invariant recognition
Apr 30, 2020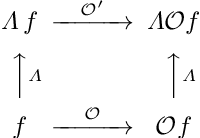
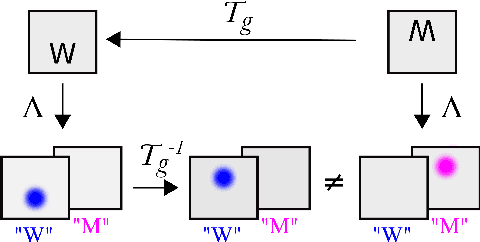
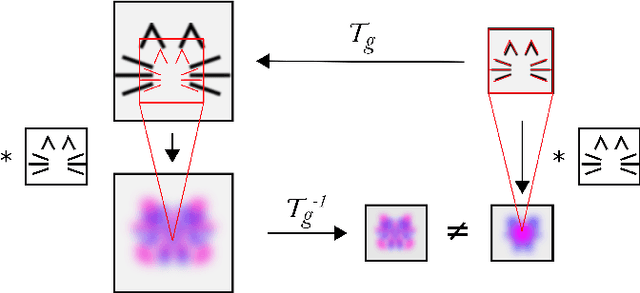
A large number of deep learning architectures use spatial transformations of CNN feature maps or filters to better deal with variability in object appearance caused by natural image transformations. In this paper, we prove that spatial transformations of CNN feature maps cannot align the feature maps of a transformed image to match those of its original, for general affine transformations, unless the extracted features are themselves invariant. Our proof is based on elementary analysis for both the single- and multi-layer network case. The results imply that methods based on spatial transformations of CNN feature maps or filters cannot replace image alignment of the input and cannot enable invariant recognition for general affine transformations, specifically not for scaling transformations or shear transformations. For rotations and reflections, spatially transforming feature maps or filters can enable invariance but only for networks with learnt or hardcoded rotation- or reflection-invariant features