 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Multi-band Weighted $l_p$ Norm Minimization for Color and Multispectral Image Denoising
Jan 14, 2019
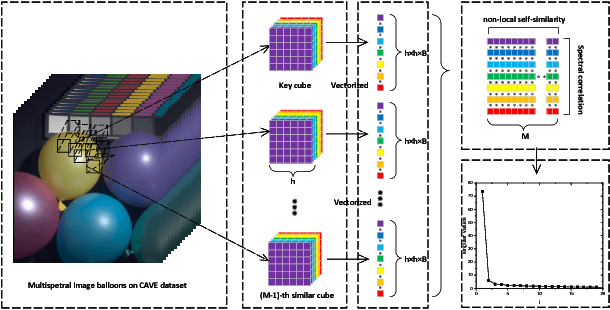

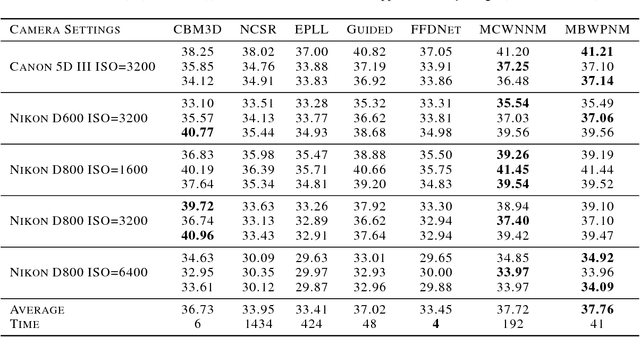
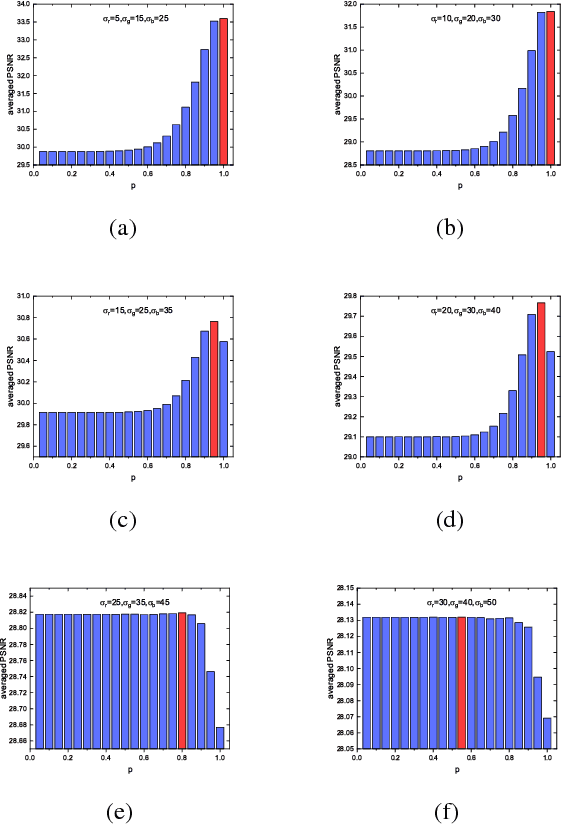
Low rank matrix approximation (LRMA) has drawn increasing attention in recent years, due to its wide range of applications in computer vision and machine learning. However, LRMA, achieved by nuclear norm minimization (NNM), tends to over-shrink the rank components with the same threshold and ignore the differences between rank components. To address this problem, we propose a flexible and precise model named multi-band weighted $l_p$ norm minimization (MBWPNM). The proposed MBWPNM not only gives more accurate approximation with a Schatten $p$-norm, but also considers the prior knowledge where different rank components have different importance. We analyze the solution of MBWPNM and prove that MBWPNM is equivalent to a non-convex $l_p$ norm subproblems under certain weight condition, whose global optimum can be solved by a generalized soft-thresholding algorithm. We then adopt the MBWPNM algorithm to color and multispectral image denoising. Extensive experiments on additive white Gaussian noise removal and realistic noise removal demonstrate that the proposed MBWPNM achieves a better performance than several state-of-art algorithms.
Deictic Image Maps: An Abstraction For Learning Pose Invariant Manipulation Policies
Sep 17, 2018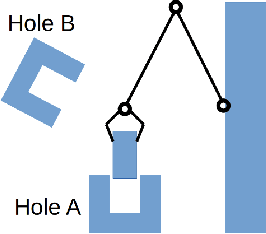

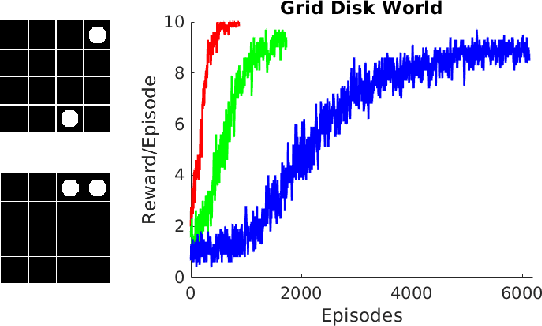
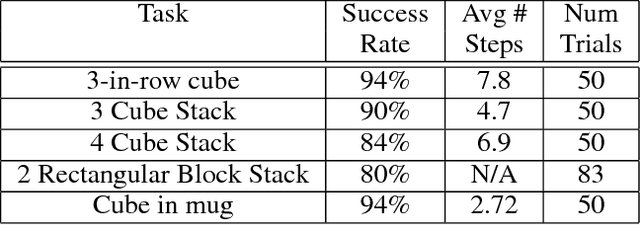
In applications of deep reinforcement learning to robotics, it is often the case that we want to learn pose invariant policies: policies that are invariant to changes in the position and orientation of objects in the world. For example, consider a peg-in-hole insertion task. If the agent learns to insert a peg into one hole, we would like that policy to generalize to holes presented in different poses. Unfortunately, this is a challenge using conventional methods. This paper proposes a novel state and action abstraction that is invariant to pose shifts called \textit{deictic image maps} that can be used with deep reinforcement learning. We provide broad conditions under which optimal abstract policies are optimal for the underlying system. Finally, we show that the method can help solve challenging robotic manipulation problems.
DIABLO: Dictionary-based Attention Block for Deep Metric Learning
Apr 30, 2020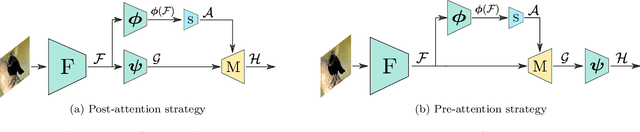
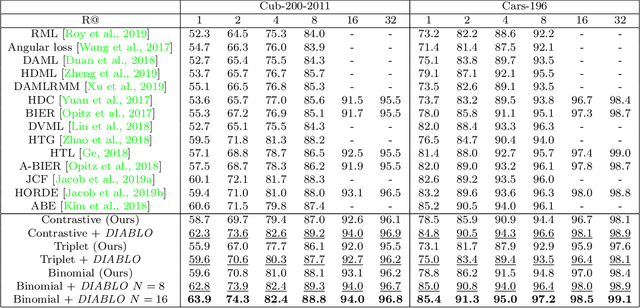
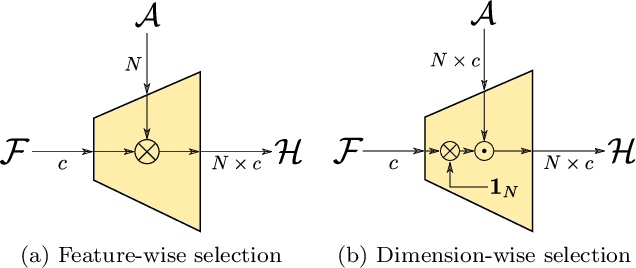
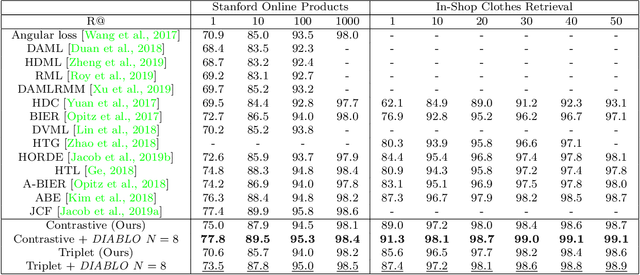
Recent breakthroughs in representation learning of unseen classes and examples have been made in deep metric learning by training at the same time the image representations and a corresponding metric with deep networks. Recent contributions mostly address the training part (loss functions, sampling strategies, etc.), while a few works focus on improving the discriminative power of the image representation. In this paper, we propose DIABLO, a dictionary-based attention method for image embedding. DIABLO produces richer representations by aggregating only visually-related features together while being easier to train than other attention-based methods in deep metric learning. This is experimentally confirmed on four deep metric learning datasets (Cub-200-2011, Cars-196, Stanford Online Products, and In-Shop Clothes Retrieval) for which DIABLO shows state-of-the-art performances.
Word2VisualVec: Image and Video to Sentence Matching by Visual Feature Prediction
Nov 25, 2016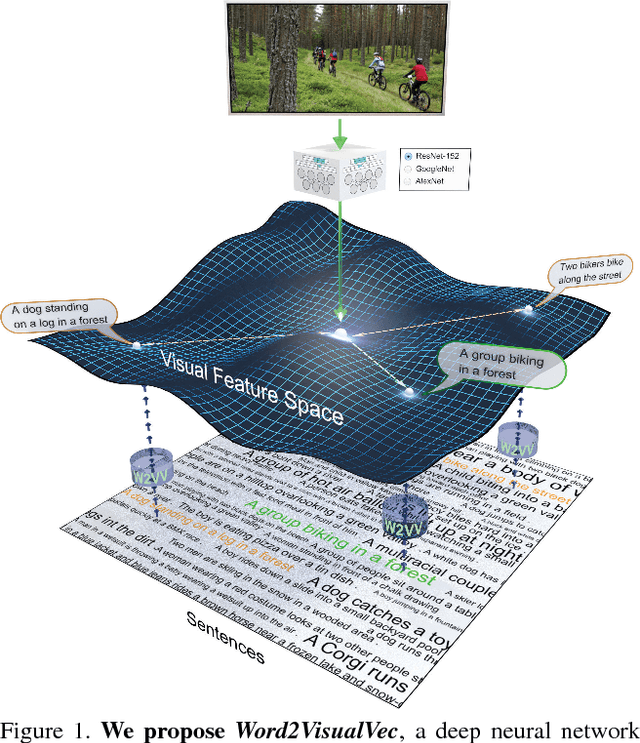
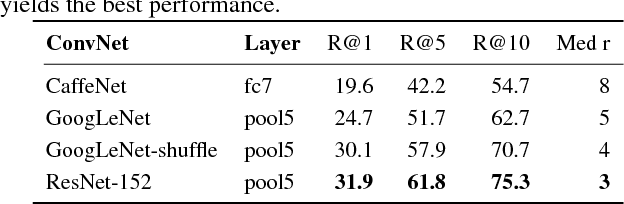
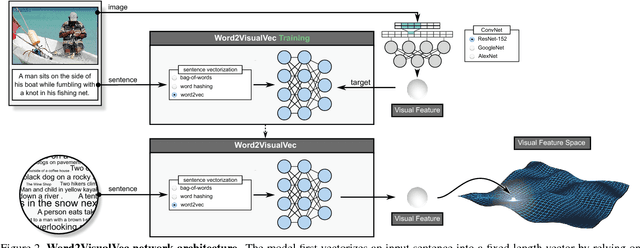
This paper strives to find the sentence best describing the content of an image or video. Different from existing works, which rely on a joint subspace for image / video to sentence matching, we propose to do so in a visual space only. We contribute Word2VisualVec, a deep neural network architecture that learns to predict a deep visual encoding of textual input based on sentence vectorization and a multi-layer perceptron. We thoroughly analyze its architectural design, by varying the sentence vectorization strategy, network depth and the deep feature to predict for image to sentence matching. We also generalize Word2VisualVec for matching a video to a sentence, by extending the predictive abilities to 3-D ConvNet features as well as a visual-audio representation. Experiments on four challenging image and video benchmarks detail Word2VisualVec's properties, capabilities for image and video to sentence matching, and on all datasets its state-of-the-art results.
Automated femur segmentation from computed tomography images using a deep neural network
Jan 27, 2021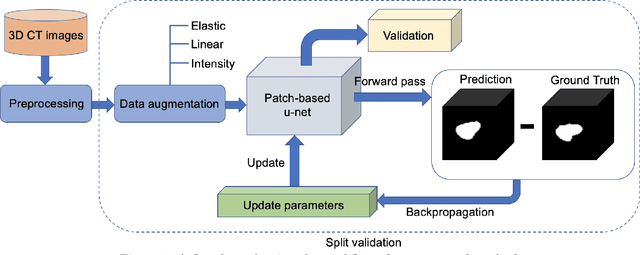
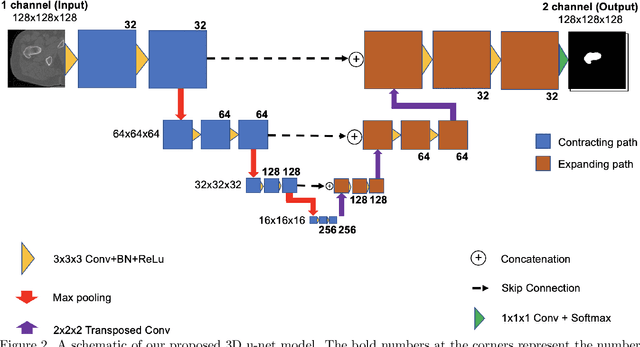
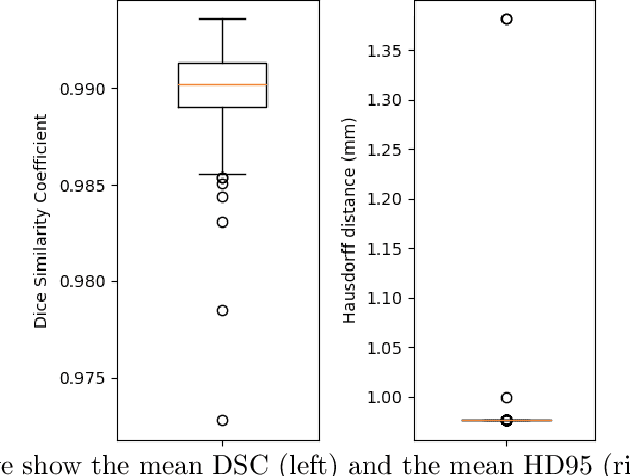

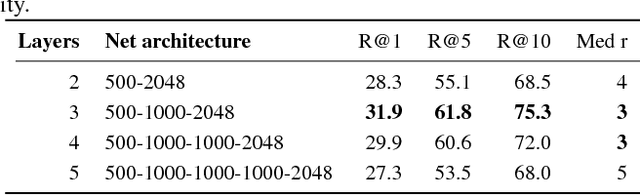
Osteoporosis is a common bone disease that occurs when the creation of new bone does not keep up with the loss of old bone, resulting in increased fracture risk. Adults over the age of 50 are especially at risk and see their quality of life diminished because of limited mobility, which can lead to isolation and depression. We are developing a robust screening method capable of identifying individuals predisposed to hip fracture to address this clinical challenge. The method uses finite element analysis and relies on segmented computed tomography (CT) images of the hip. Presently, the segmentation of the proximal femur requires manual input, which is a tedious task, prone to human error, and severely limits the practicality of the method in a clinical context. Here we present a novel approach for segmenting the proximal femur that uses a deep convolutional neural network to produce accurate, automated, robust, and fast segmentations of the femur from CT scans. The network architecture is based on the renowned u-net, which consists of a downsampling path to extract increasingly complex features of the input patch and an upsampling path to convert the acquired low resolution image into a high resolution one. Skipped connections allow us to recover critical spatial information lost during downsampling. The model was trained on 30 manually segmented CT images and was evaluated on 200 ground truth manual segmentations. Our method delivers a mean Dice similarity coefficient (DSC) and 95th percentile Hausdorff distance (HD95) of 0.990 and 0.981 mm, respectively.
Saving the Sonorine: Audio Recovery Using Image Processing and Computer Vision
May 16, 2020


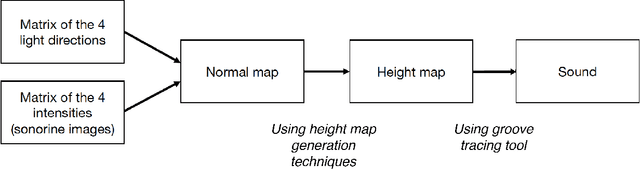
This paper presents a novel technique to recover audio from sonorines, an early 20th century form of analogue sound storage. Our method uses high resolution photographs of sonorines under different lighting conditions to observe the change in reflection behavior of the physical surface features and create a three-dimensional height map of the surface. Sound can then be extracted using height information within the surface's grooves, mimicking a physical stylus on a phonograph. Unlike traditional playback methods, our method has the advantage of being contactless: the medium will not incur damage and wear from being played repeatedly. We compare the results of our technique to a previously successful contactless method using flatbed scans of the sonorines, and conclude with future research that can be applied to this photovisual approach to audio recovery.
Unified Dynamic Convolutional Network for Super-Resolution with Variational Degradations
Apr 15, 2020

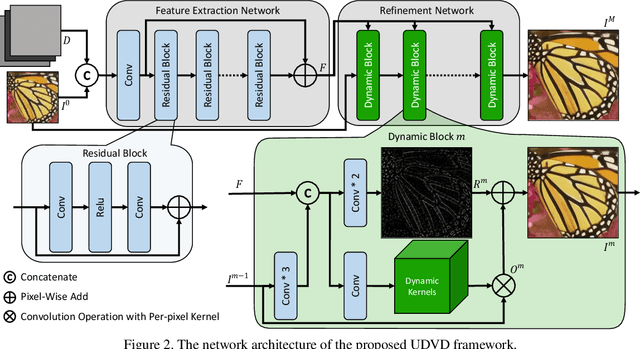
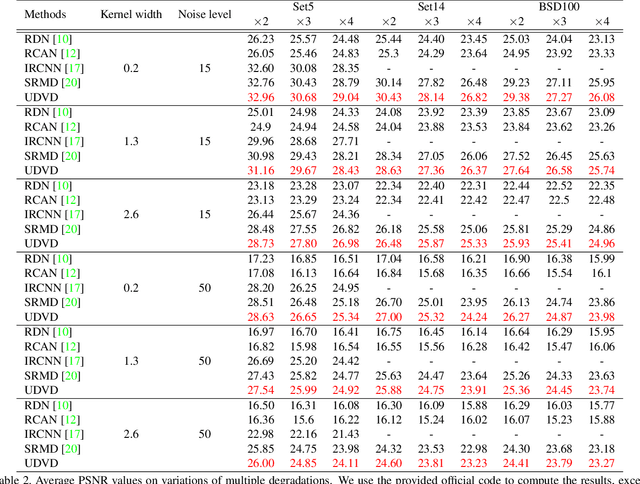
Deep Convolutional Neural Networks (CNNs) have achieved remarkable results on Single Image Super-Resolution (SISR). Despite considering only a single degradation, recent studies also include multiple degrading effects to better reflect real-world cases. However, most of the works assume a fixed combination of degrading effects, or even train an individual network for different combinations. Instead, a more practical approach is to train a single network for wide-ranging and variational degradations. To fulfill this requirement, this paper proposes a unified network to accommodate the variations from inter-image (cross-image variations) and intra-image (spatial variations). Different from the existing works, we incorporate dynamic convolution which is a far more flexible alternative to handle different variations. In SISR with non-blind setting, our Unified Dynamic Convolutional Network for Variational Degradations (UDVD) is evaluated on both synthetic and real images with an extensive set of variations. The qualitative results demonstrate the effectiveness of UDVD over various existing works. Extensive experiments show that our UDVD achieves favorable or comparable performance on both synthetic and real images.
A Convolutional Approach to Vertebrae Detection and Labelling in Whole Spine MRI
Jul 08, 2020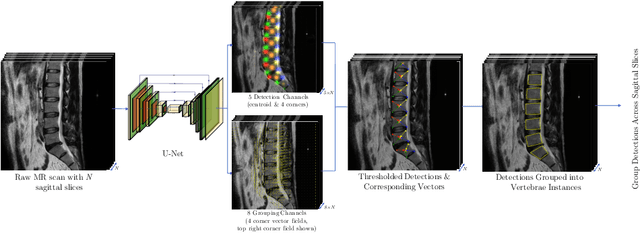
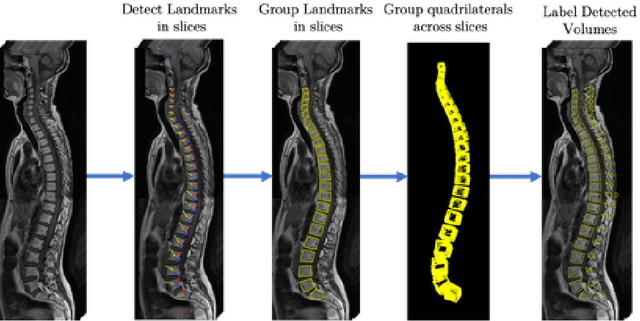

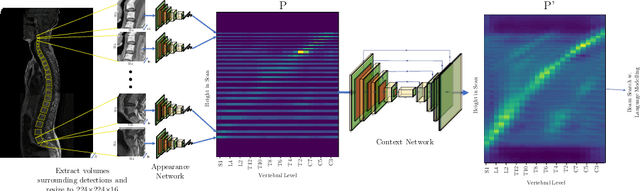
We propose a novel convolutional method for the detection and identification of vertebrae in whole spine MRIs. This involves using a learnt vector field to group detected vertebrae corners together into individual vertebral bodies and convolutional image-to-image translation followed by beam search to label vertebral levels in a self-consistent manner. The method can be applied without modification to lumbar, cervical and thoracic-only scans across a range of different MR sequences. The resulting system achieves 98.1% detection rate and 96.5% identification rate on a challenging clinical dataset of whole spine scans and matches or exceeds the performance of previous systems on lumbar-only scans. Finally, we demonstrate the clinical applicability of this method, using it for automated scoliosis detection in both lumbar and whole spine MR scans.
Deep Reinforcement Learning-based Image Captioning with Embedding Reward
Apr 12, 2017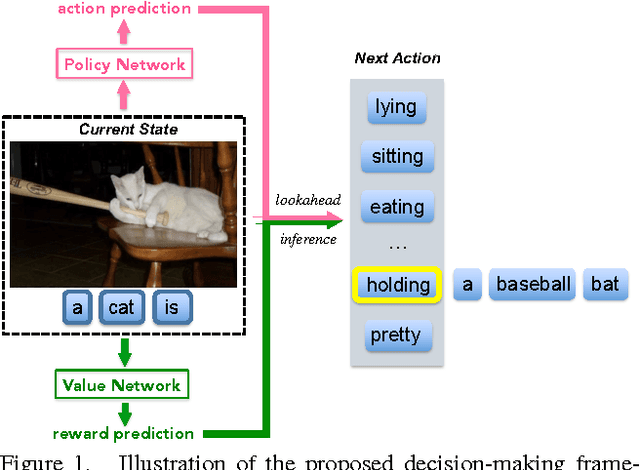
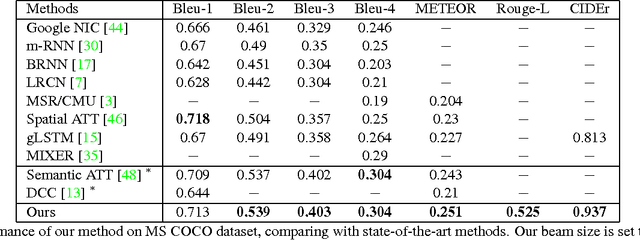
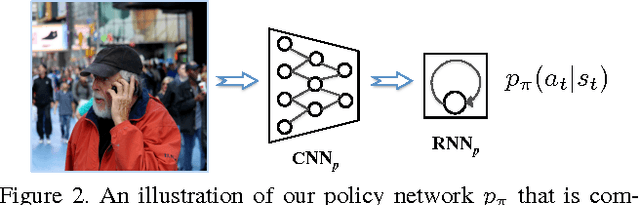
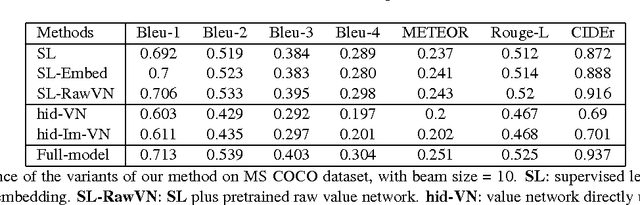
Image captioning is a challenging problem owing to the complexity in understanding the image content and diverse ways of describing it in natural language. Recent advances in deep neural networks have substantially improved the performance of this task. Most state-of-the-art approaches follow an encoder-decoder framework, which generates captions using a sequential recurrent prediction model. However, in this paper, we introduce a novel decision-making framework for image captioning. We utilize a "policy network" and a "value network" to collaboratively generate captions. The policy network serves as a local guidance by providing the confidence of predicting the next word according to the current state. Additionally, the value network serves as a global and lookahead guidance by evaluating all possible extensions of the current state. In essence, it adjusts the goal of predicting the correct words towards the goal of generating captions similar to the ground truth captions. We train both networks using an actor-critic reinforcement learning model, with a novel reward defined by visual-semantic embedding. Extensive experiments and analyses on the Microsoft COCO dataset show that the proposed framework outperforms state-of-the-art approaches across different evaluation metrics.
RAID: A Relation-Augmented Image Descriptor
Oct 06, 2015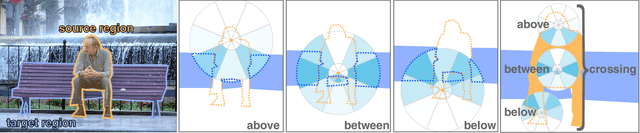
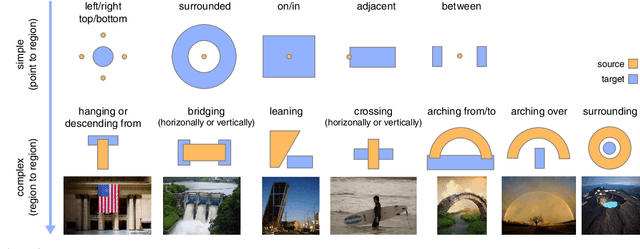
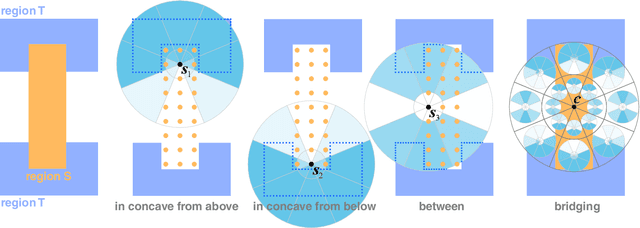
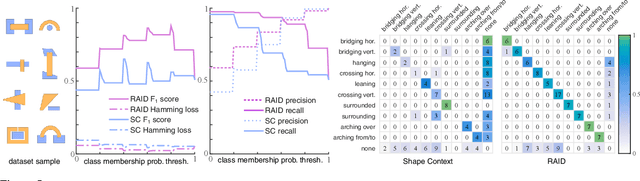
As humans, we regularly interpret images based on the relations between image regions. For example, a person riding object X, or a plank bridging two objects. Current methods provide limited support to search for images based on such relations. We present RAID, a relation-augmented image descriptor that supports queries based on inter-region relations. The key idea of our descriptor is to capture the spatial distribution of simple point-to-region relationships to describe more complex relationships between two image regions. We evaluate the proposed descriptor by querying into a large subset of the Microsoft COCO database and successfully extract nontrivial images demonstrating complex inter-region relations, which are easily missed or erroneously classified by existing methods.