 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Choice modelling in the age of machine learning
Jan 28, 2021

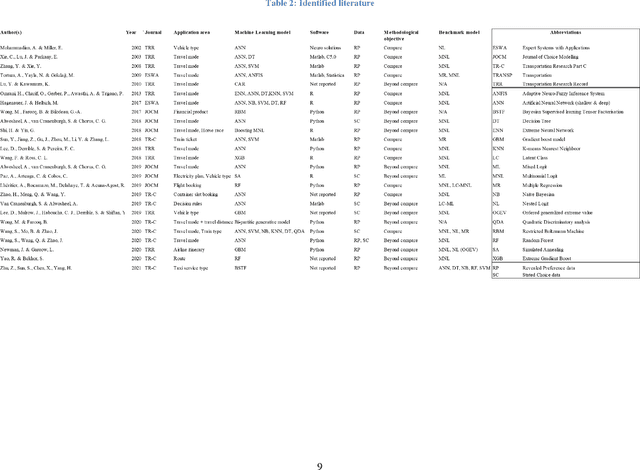
Since its inception, the choice modelling field has been dominated by theory-driven models. The recent emergence and growing popularity of machine learning models offer an alternative data-driven approach. Machine learning models, techniques and practices could help overcome problems and limitations of the current theory-driven modelling paradigm, e.g. relating to the ad-hocness in search for the optimal model specification, and theory-driven choice model's inability to work with text and image data. However, despite the potential value of machine learning to improve choice modelling practices, the choice modelling field has been somewhat hesitant to embrace machine learning. The aim of this paper is to facilitate (further) integration of machine learning in the choice modelling field. To achieve this objective, we make the case that (further) integration of machine learning in the choice modelling field is beneficial for the choice modelling field, and, we shed light on where the benefits of further integration can be found. Specifically, we take the following approach. First, we clarify the similarities and differences between the two modelling paradigms. Second, we provide a literature overview on the use of machine learning for choice modelling. Third, we reinforce the strengths of the current theory-driven modelling paradigm and compare this with the machine learning modelling paradigm, Fourth, we identify opportunities for embracing machine learning for choice modelling, while recognising the strengths of the current theory-driven paradigm. Finally, we put forward a vision on the future relationship between the theory-driven choice models and machine learning.
Vis-CRF, A Classical Receptive Field Model for VISION
Nov 17, 2020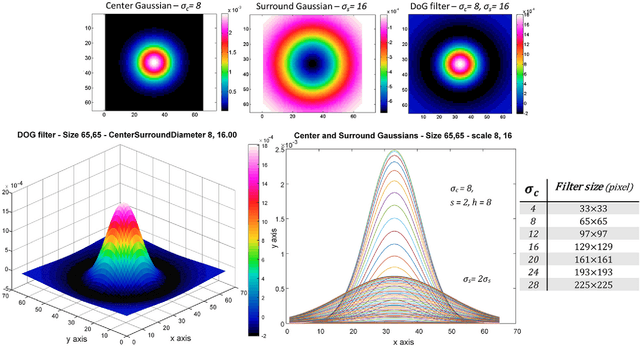
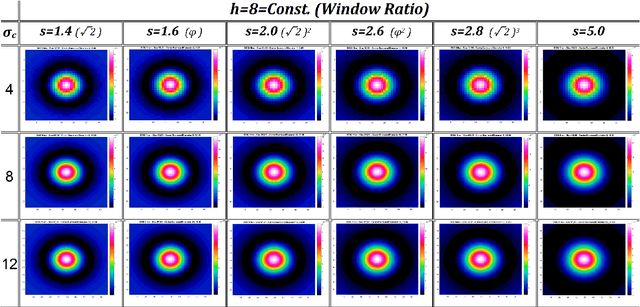
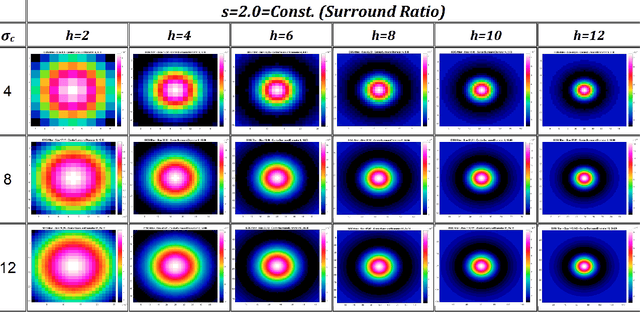
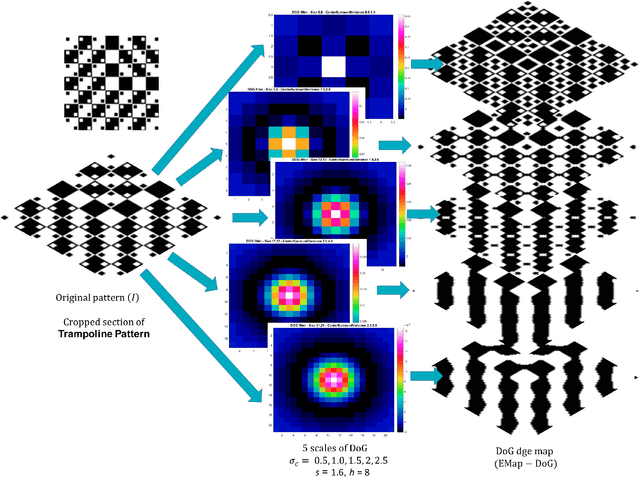
Over the last decade, a variety of new neurophysiological experiments have led to new insights as to how, when and where retinal processing takes place, and the nature of the retinal representation encoding sent to the cortex for further processing. Based on these neurobiological discoveries, in our previous work, we provided computer simulation evidence to suggest that Geometrical illusions are explained in part, by the interaction of multiscale visual processing performed in the retina. The output of our retinal stage model, named Vis-CRF, is presented here for a sample of natural image and for several types of Tilt Illusion, in which the final tilt percept arises from multiple scale processing of Difference of Gaussians (DoG) and the perceptual interaction of foreground and background elements (Nematzadeh and Powers, 2019; Nematzadeh, 2018; Nematzadeh, Powers and Lewis, 2017; Nematzadeh, Lewis and Powers, 2015).
MCL-3D: a database for stereoscopic image quality assessment using 2D-image-plus-depth source
Mar 23, 2014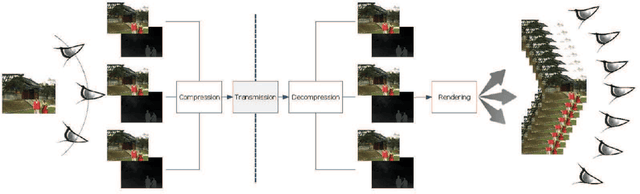
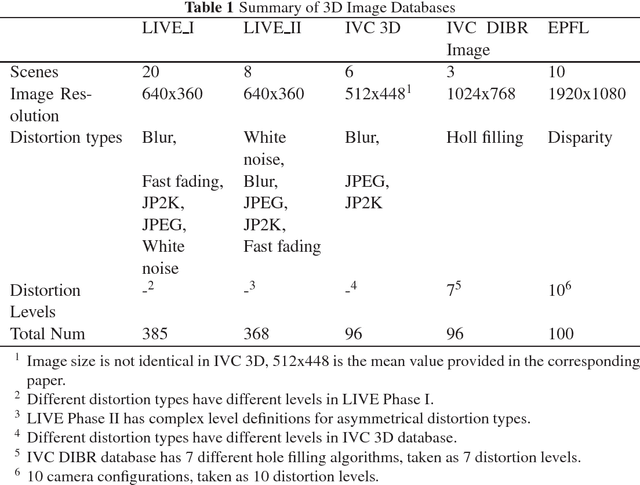
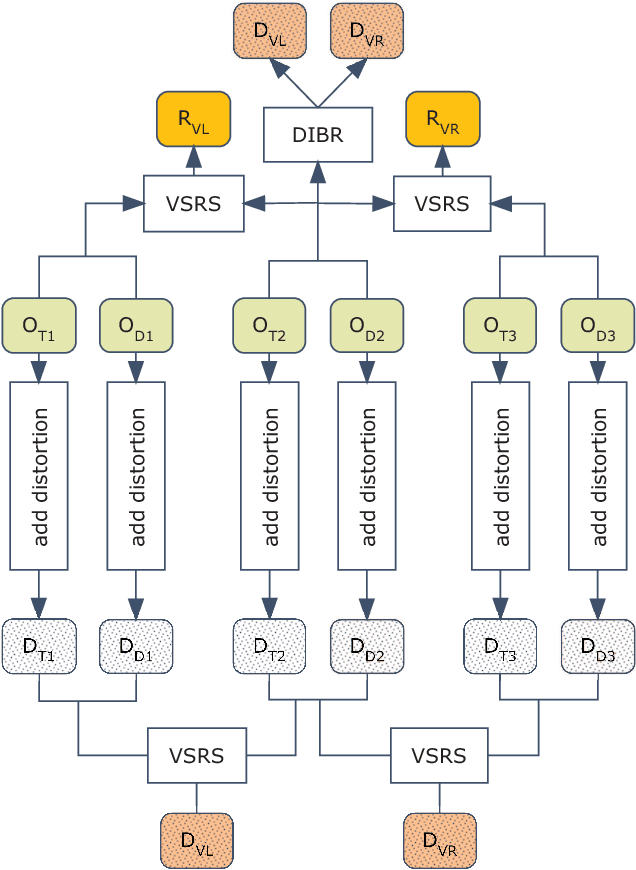
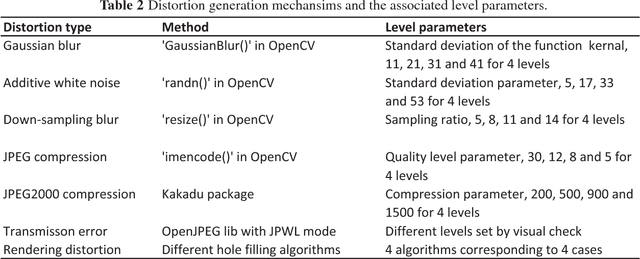
A new stereoscopic image quality assessment database rendered using the 2D-image-plus-depth source, called MCL-3D, is described and the performance benchmarking of several known 2D and 3D image quality metrics using the MCL-3D database is presented in this work. Nine image-plus-depth sources are first selected, and a depth image-based rendering (DIBR) technique is used to render stereoscopic image pairs. Distortions applied to either the texture image or the depth image before stereoscopic image rendering include: Gaussian blur, additive white noise, down-sampling blur, JPEG and JPEG-2000 (JP2K) compression and transmission error. Furthermore, the distortion caused by imperfect rendering is also examined. The MCL-3D database contains 693 stereoscopic image pairs, where one third of them are of resolution 1024x728 and two thirds are of resolution 1920x1080. The pair-wise comparison was adopted in the subjective test for user friendliness, and the Mean Opinion Score (MOS) can be computed accordingly. Finally, we evaluate the performance of several 2D and 3D image quality metrics applied to MCL-3D. All texture images, depth images, rendered image pairs in MCL-3D and their MOS values obtained in the subjective test are available to the public (http://mcl.usc.edu/mcl-3d-database/) for future research and development.
Multimodal Convolutional Neural Networks for Matching Image and Sentence
Aug 29, 2015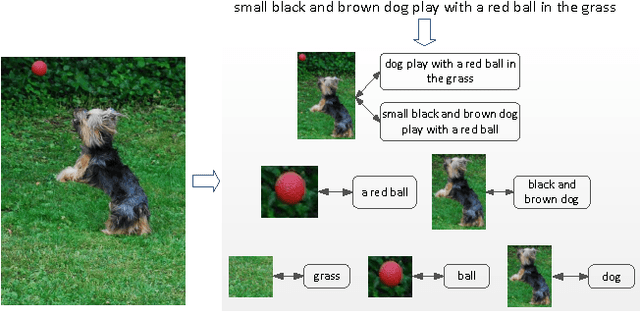
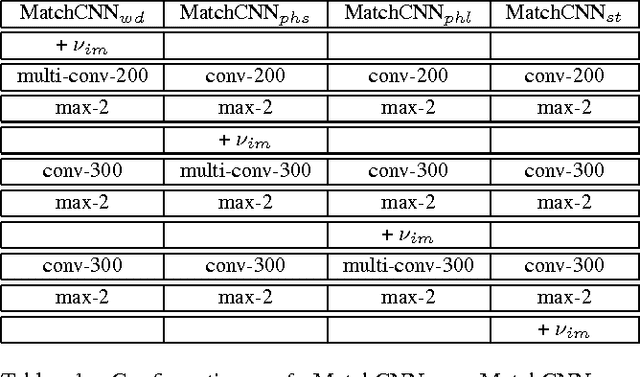
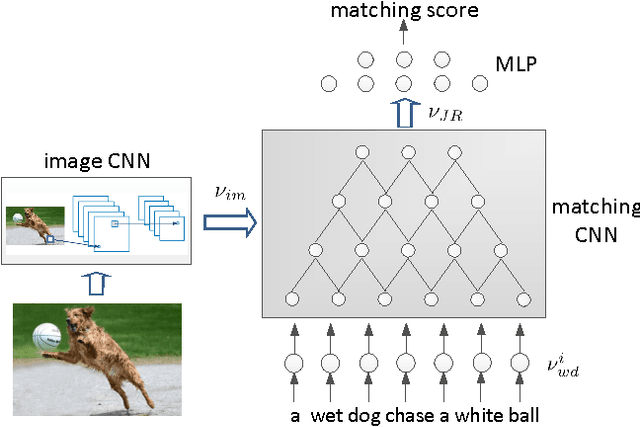
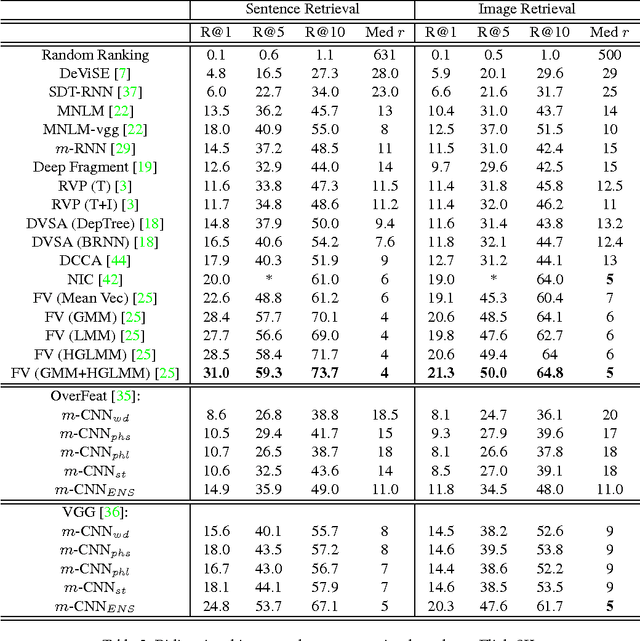
In this paper, we propose multimodal convolutional neural networks (m-CNNs) for matching image and sentence. Our m-CNN provides an end-to-end framework with convolutional architectures to exploit image representation, word composition, and the matching relations between the two modalities. More specifically, it consists of one image CNN encoding the image content, and one matching CNN learning the joint representation of image and sentence. The matching CNN composes words to different semantic fragments and learns the inter-modal relations between image and the composed fragments at different levels, thus fully exploit the matching relations between image and sentence. Experimental results on benchmark databases of bidirectional image and sentence retrieval demonstrate that the proposed m-CNNs can effectively capture the information necessary for image and sentence matching. Specifically, our proposed m-CNNs for bidirectional image and sentence retrieval on Flickr30K and Microsoft COCO databases achieve the state-of-the-art performances.
3DSNet: Unsupervised Shape-to-Shape 3D Style Transfer
Nov 30, 2020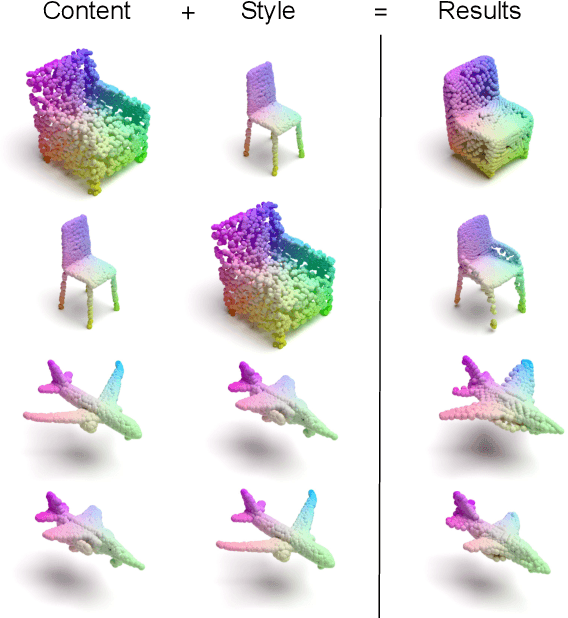
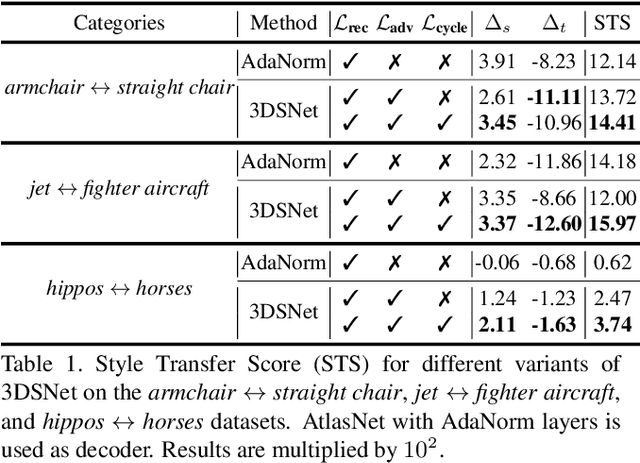
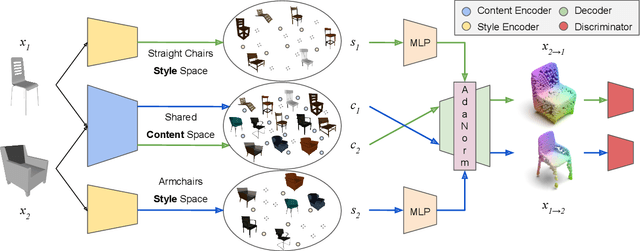

Transferring the style from one image onto another is a popular and widely studied task in computer vision. Yet, learning-based style transfer in the 3D setting remains a largely unexplored problem. To our knowledge, we propose the first learning-based generative approach for style transfer between 3D objects. Our method allows to combine the content and style of a source and target 3D model to generate a novel shape that resembles in style the target while retaining the source content. The proposed framework can synthesize new 3D shapes both in the form of point clouds and meshes. Furthermore, we extend our technique to implicitly learn the underlying multimodal style distribution of the individual category domains. By sampling style codes from the learned distributions, we increase the variety of styles that our model can confer to a given reference object. Experimental results validate the effectiveness of the proposed 3D style transfer method on a number of benchmarks.
Betrayed by Motion: Camouflaged Object Discovery via Motion Segmentation
Nov 23, 2020
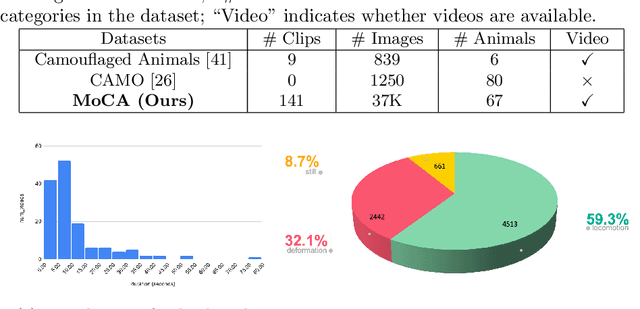
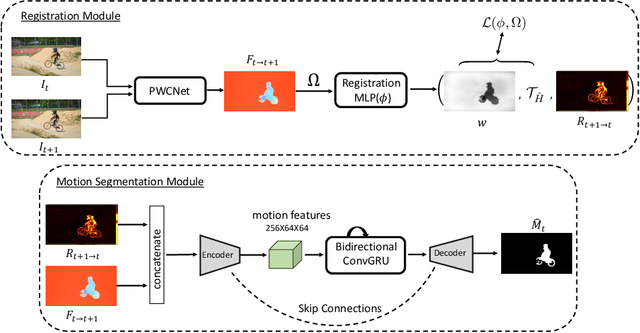
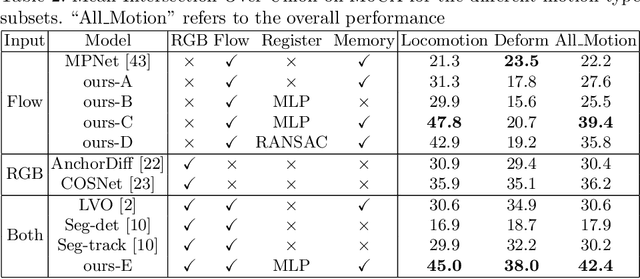
The objective of this paper is to design a computational architecture that discovers camouflaged objects in videos, specifically by exploiting motion information to perform object segmentation. We make the following three contributions: (i) We propose a novel architecture that consists of two essential components for breaking camouflage, namely, a differentiable registration module to align consecutive frames based on the background, which effectively emphasises the object boundary in the difference image, and a motion segmentation module with memory that discovers the moving objects, while maintaining the object permanence even when motion is absent at some point. (ii) We collect the first large-scale Moving Camouflaged Animals (MoCA) video dataset, which consists of over 140 clips across a diverse range of animals (67 categories). (iii) We demonstrate the effectiveness of the proposed model on MoCA, and achieve competitive performance on the unsupervised segmentation protocol on DAVIS2016 by only relying on motion.
Anomaly detection through latent space restoration using vector-quantized variational autoencoders
Dec 12, 2020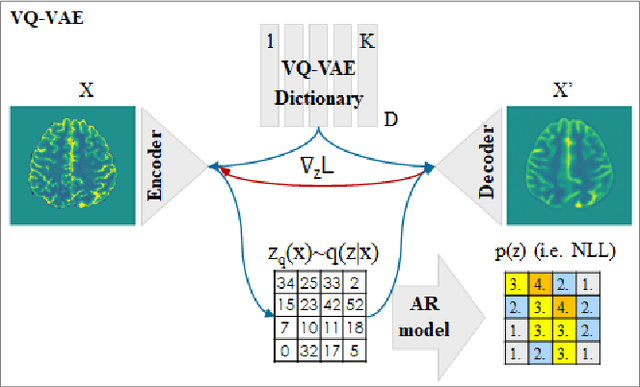
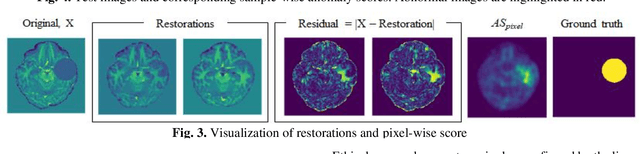
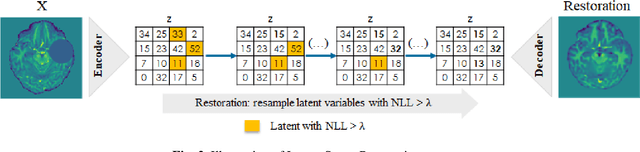
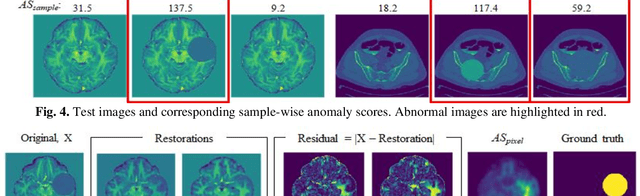
We propose an out-of-distribution detection method that combines density and restoration-based approaches using Vector-Quantized Variational Auto-Encoders (VQ-VAEs). The VQ-VAE model learns to encode images in a categorical latent space. The prior distribution of latent codes is then modelled using an Auto-Regressive (AR) model. We found that the prior probability estimated by the AR model can be useful for unsupervised anomaly detection and enables the estimation of both sample and pixel-wise anomaly scores. The sample-wise score is defined as the negative log-likelihood of the latent variables above a threshold selecting highly unlikely codes. Additionally, out-of-distribution images are restored into in-distribution images by replacing unlikely latent codes with samples from the prior model and decoding to pixel space. The average L1 distance between generated restorations and original image is used as pixel-wise anomaly score. We tested our approach on the MOOD challenge datasets, and report higher accuracies compared to a standard reconstruction-based approach with VAEs.
Detection and Retrieval of Out-of-Distribution Objects in Semantic Segmentation
May 14, 2020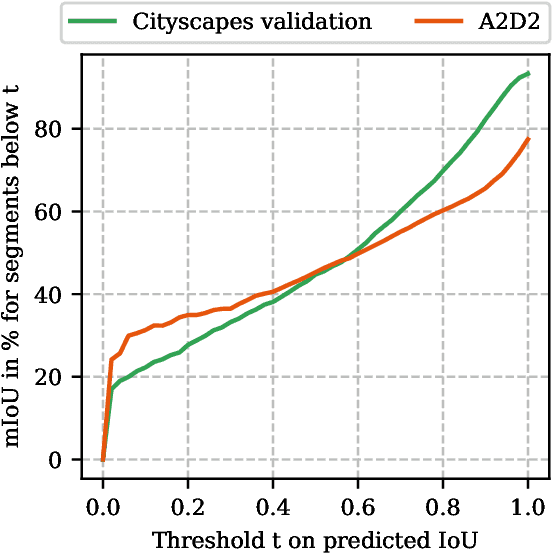

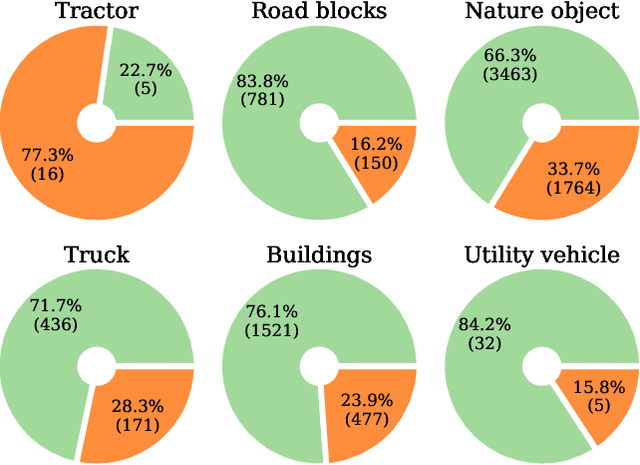
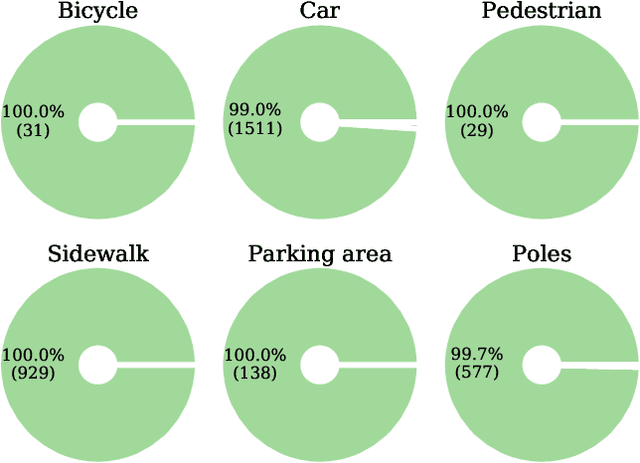
When deploying deep learning technology in self-driving cars, deep neural networks are constantly exposed to domain shifts. These include, e.g., changes in weather conditions, time of day, and long-term temporal shift. In this work we utilize a deep neural network trained on the Cityscapes dataset containing urban street scenes and infer images from a different dataset, the A2D2 dataset, containing also countryside and highway images. We present a novel pipeline for semantic segmenation that detects out-of-distribution (OOD) segments by means of the deep neural network's prediction and performs image retrieval after feature extraction and dimensionality reduction on image patches. In our experiments we demonstrate that the deployed OOD approach is suitable for detecting out-of-distribution concepts. Furthermore, we evaluate the image patch retrieval qualitatively as well as quantitatively by means of the semi-compatible A2D2 ground truth and obtain mAP values of up to 52.2%.
Structure Tensor Based Image Interpolation Method
Dec 26, 2014
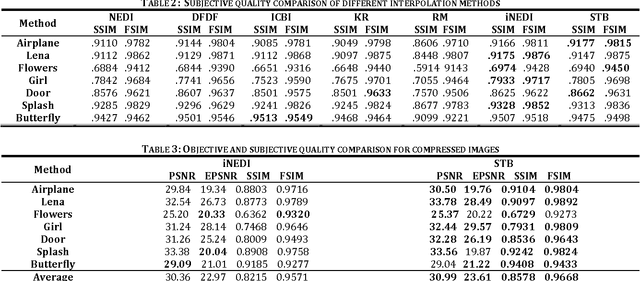


Feature preserving image interpolation is an active area in image processing field. In this paper a new direct edge directed image super-resolution algorithm based on structure tensors is proposed. Using an isotropic Gaussian filter, the structure tensor at each pixel of the input image is computed and the pixels are classified to three distinct classes; uniform region, corners and edges, according to the eigenvalues of the structure tensor. Due to application of the isotropic Gaussian filter, the classification is robust to noise presented in image. Based on the tangent eigenvector of the structure tensor, the edge direction is determined and used for interpolation along the edges. In comparison to some previous edge directed image interpolation methods, the proposed method achieves higher quality in both subjective and objective aspects. Also the proposed method outperforms previous methods in case of noisy and JPEG compressed images. Furthermore, without the need for optimization in the process, the algorithm can achieve higher speed.
Salient Object Detection via Integrity Learning
Jan 20, 2021
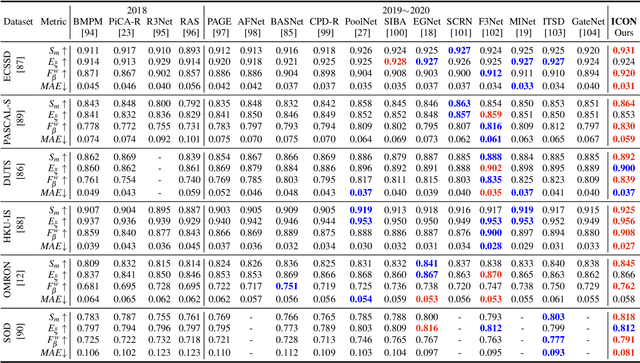
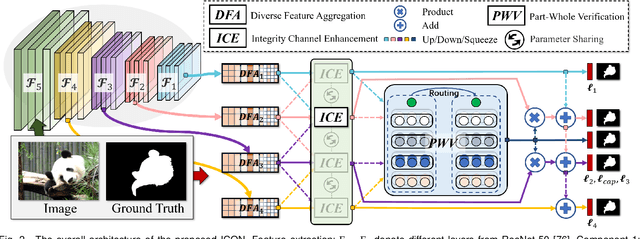
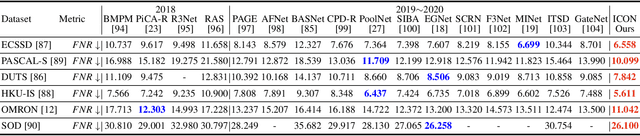
Albeit current salient object detection (SOD) works have achieved fantastic progress, they are cast into the shade when it comes to the integrity of the predicted salient regions. We define the concept of integrity at both the micro and macro level. Specifically, at the micro level, the model should highlight all parts that belong to a certain salient object, while at the macro level, the model needs to discover all salient objects from the given image scene. To facilitate integrity learning for salient object detection, we design a novel Integrity Cognition Network (ICON), which explores three important components to learn strong integrity features. 1) Unlike the existing models that focus more on feature discriminability, we introduce a diverse feature aggregation (DFA) component to aggregate features with various receptive fields (i.e.,, kernel shape and context) and increase the feature diversity. Such diversity is the foundation for mining the integral salient objects. 2) Based on the DFA features, we introduce the integrity channel enhancement (ICE) component with the goal of enhancing feature channels that highlight the integral salient objects at the macro level, while suppressing the other distracting ones. 3) After extracting the enhanced features, the part-whole verification (PWV) method is employed to determine whether the part and whole object features have strong agreement. Such part-whole agreements can further improve the micro-level integrity for each salient object. To demonstrate the effectiveness of ICON, comprehensive experiments are conducted on seven challenging benchmarks, where promising results are achieved.