 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Dataset on Bi- and Multi-Nucleated Tumor Cells in Canine Cutaneous Mast Cell Tumors
Jan 05, 2021
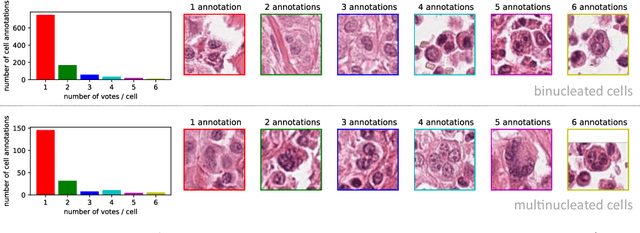
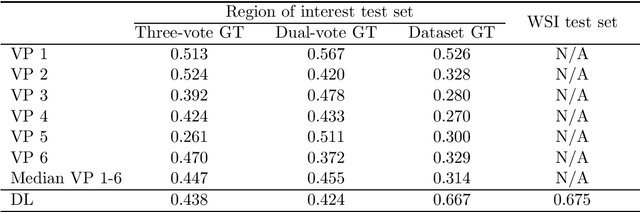
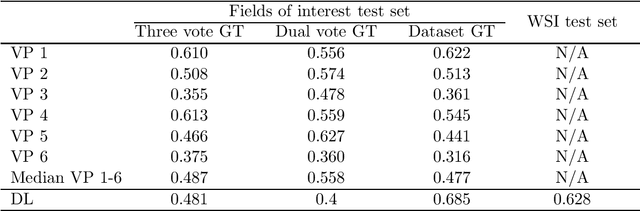
Tumor cells with two nuclei (binucleated cells, BiNC) or more nuclei (multinucleated cells, MuNC) indicate an increased amount of cellular genetic material which is thought to facilitate oncogenesis, tumor progression and treatment resistance. In canine cutaneous mast cell tumors (ccMCT), binucleation and multinucleation are parameters used in cytologic and histologic grading schemes (respectively) which correlate with poor patient outcome. For this study, we created the first open source data-set with 19,983 annotations of BiNC and 1,416 annotations of MuNC in 32 histological whole slide images of ccMCT. Labels were created by a pathologist and an algorithmic-aided labeling approach with expert review of each generated candidate. A state-of-the-art deep learning-based model yielded an $F_1$ score of 0.675 for BiNC and 0.623 for MuNC on 11 test whole slide images. In regions of interest ($2.37 mm^2$) extracted from these test images, 6 pathologists had an object detection performance between 0.270 - 0.526 for BiNC and 0.316 - 0.622 for MuNC, while our model archived an $F_1$ score of 0.667 for BiNC and 0.685 for MuNC. This open dataset can facilitate development of automated image analysis for this task and may thereby help to promote standardization of this facet of histologic tumor prognostication.
The Utility of Decorrelating Colour Spaces in Vector Quantised Variational Autoencoders
Sep 30, 2020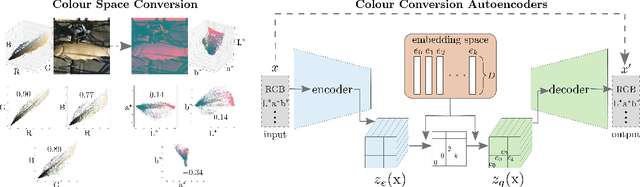
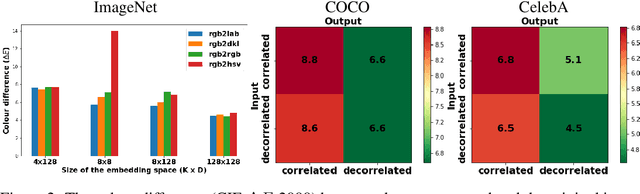
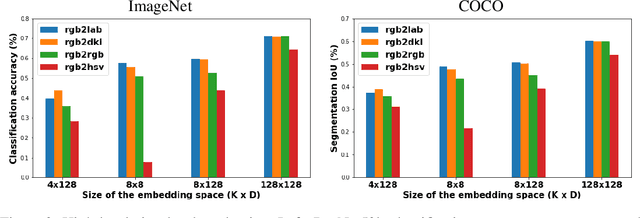
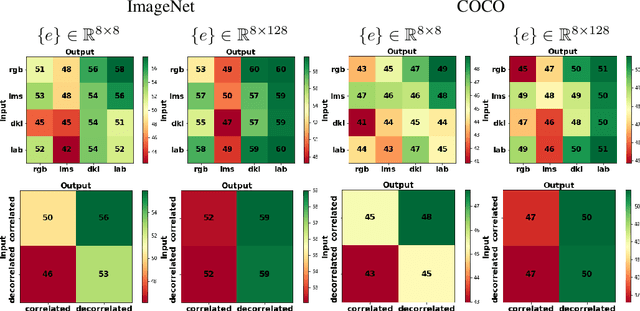
Vector quantised variational autoencoders (VQ-VAE) are characterised by three main components: 1) encoding visual data, 2) assigning $k$ different vectors in the so-called embedding space, and 3) decoding the learnt features. While images are often represented in RGB colour space, the specific organisation of colours in other spaces also offer interesting features, e.g. CIE L*a*b* decorrelates chromaticity into opponent axes. In this article, we propose colour space conversion, a simple quasi-unsupervised task, to enforce a network learning structured representations. To this end, we trained several instances of VQ-VAE whose input is an image in one colour space, and its output in another, e.g. from RGB to CIE L*a*b* (in total five colour spaces were considered). We examined the finite embedding space of trained networks in order to disentangle the colour representation in VQ-VAE models. Our analysis suggests that certain vectors encode hue and others luminance information. We further evaluated the quality of reconstructed images at low-level using pixel-wise colour metrics, and at high-level by inputting them to image classification and scene segmentation networks. We conducted experiments in three benchmark datasets: ImageNet, COCO and CelebA. Our results show, with respect to the baseline network (whose input and output are RGB), colour conversion to decorrelated spaces obtains 1-2 Delta-E lower colour difference and 5-10% higher classification accuracy. We also observed that the learnt embedding space is easier to interpret in colour opponent models.
EC-GAN: Low-Sample Classification using Semi-Supervised Algorithms and GANs
Dec 26, 2020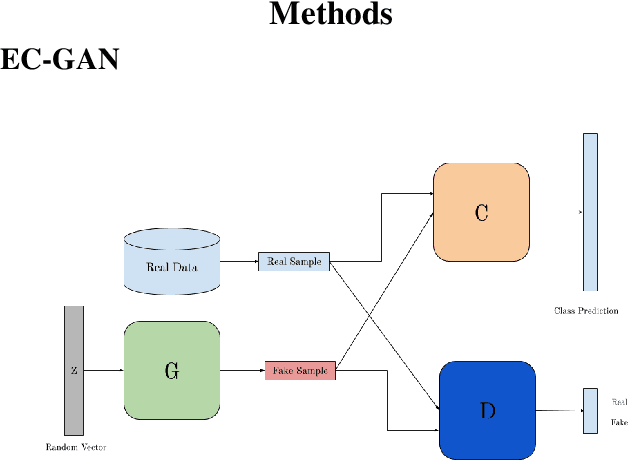
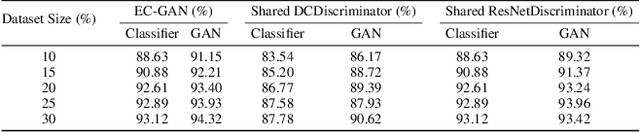
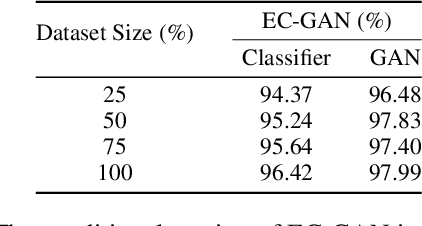
Semi-supervised learning has been gaining attention as it allows for performing image analysis tasks such as classification with limited labeled data. Some popular algorithms using Generative Adversarial Networks (GANs) for semi-supervised classification share a single architecture for classification and discrimination. However, this may require a model to converge to a separate data distribution for each task, which may reduce overall performance. While progress in semi-supervised learning has been made, less addressed are small-scale, fully-supervised tasks where even unlabeled data is unavailable and unattainable. We therefore, propose a novel GAN model namely External Classifier GAN (EC-GAN), that utilizes GANs and semi-supervised algorithms to improve classification in fully-supervised regimes. Our method leverages a GAN to generate artificial data used to supplement supervised classification. More specifically, we attach an external classifier, hence the name EC-GAN, to the GAN's generator, as opposed to sharing an architecture with the discriminator. Our experiments demonstrate that EC-GAN's performance is comparable to the shared architecture method, far superior to the standard data augmentation and regularization-based approach, and effective on a small, realistic dataset.
Beyond Single Instance Multi-view Unsupervised Representation Learning
Nov 26, 2020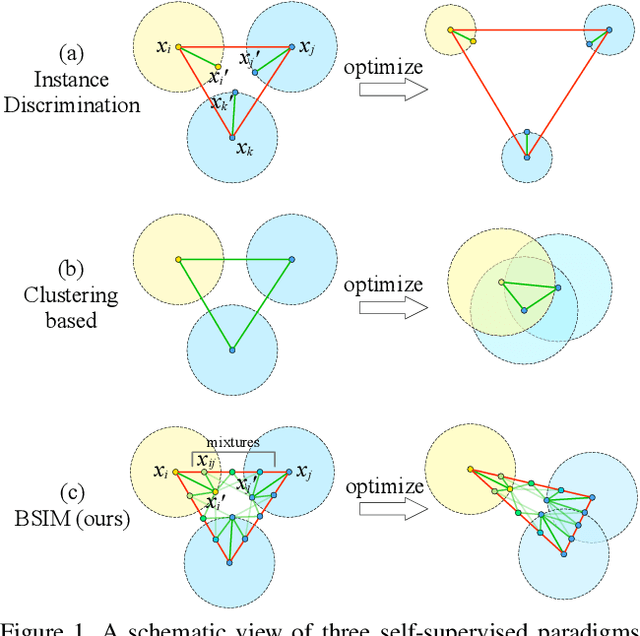
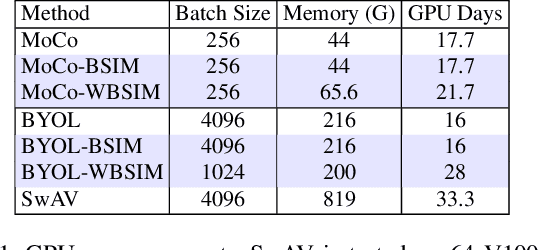
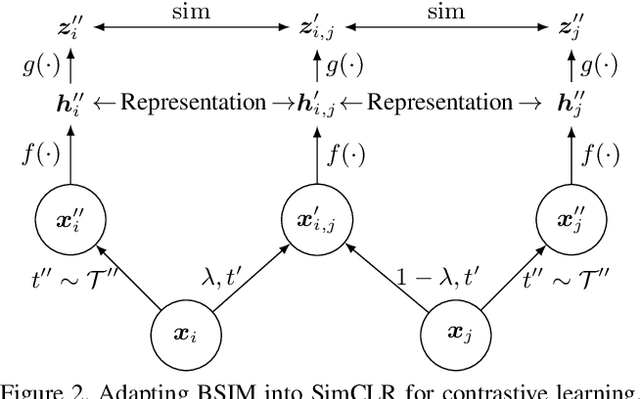
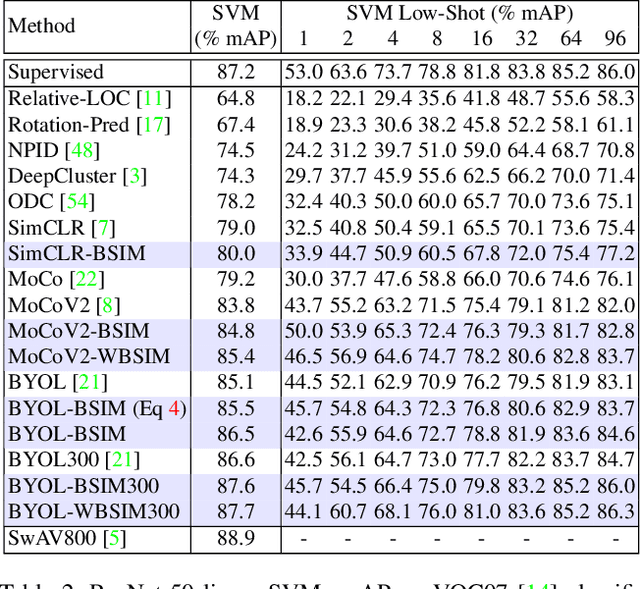
Recent unsupervised contrastive representation learning follows a Single Instance Multi-view (SIM) paradigm where positive pairs are usually constructed with intra-image data augmentation. In this paper, we propose an effective approach called Beyond Single Instance Multi-view (BSIM). Specifically, we impose more accurate instance discrimination capability by measuring the joint similarity between two randomly sampled instances and their mixture, namely spurious-positive pairs. We believe that learning joint similarity helps to improve the performance when encoded features are distributed more evenly in the latent space. We apply it as an orthogonal improvement for unsupervised contrastive representation learning, including current outstanding methods SimCLR, MoCo, and BYOL. We evaluate our learned representations on many downstream benchmarks like linear classification on ImageNet-1k and PASCAL VOC 2007, object detection on MS COCO 2017 and VOC, etc. We obtain substantial gains with a large margin almost on all these tasks compared with prior arts.
Ladybird: Quasi-Monte Carlo Sampling for Deep Implicit Field Based 3D Reconstruction with Symmetry
Jul 27, 2020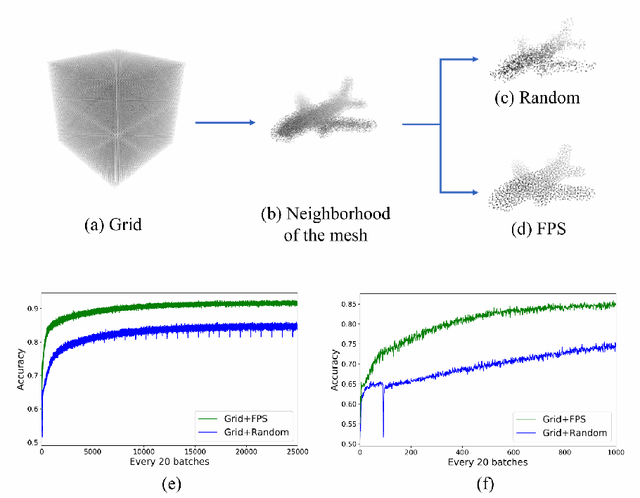
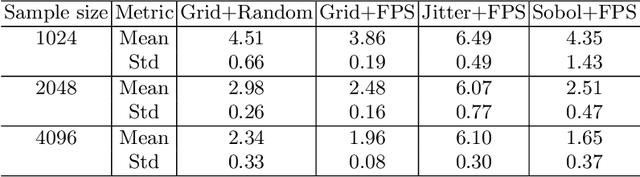
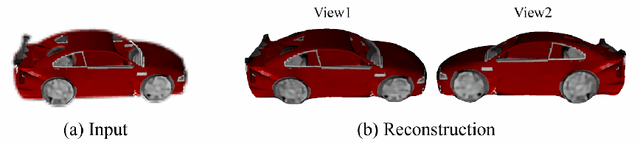
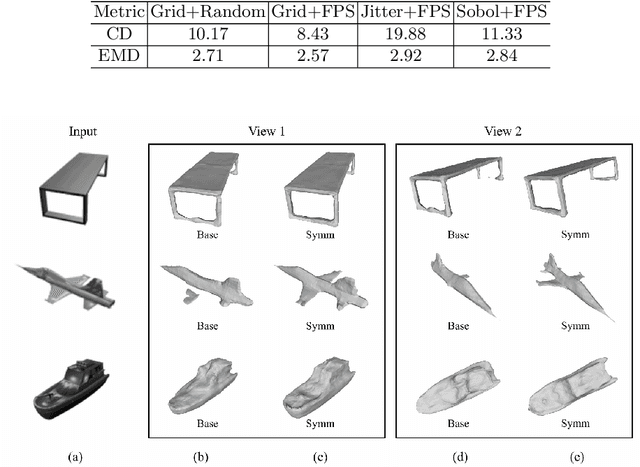
Deep implicit field regression methods are effective for 3D reconstruction from single-view images. However, the impact of different sampling patterns on the reconstruction quality is not well-understood. In this work, we first study the effect of point set discrepancy on the network training. Based on Farthest Point Sampling algorithm, we propose a sampling scheme that theoretically encourages better generalization performance, and results in fast convergence for SGD-based optimization algorithms. Secondly, based on the reflective symmetry of an object, we propose a feature fusion method that alleviates issues due to self-occlusions which makes it difficult to utilize local image features. Our proposed system Ladybird is able to create high quality 3D object reconstructions from a single input image. We evaluate Ladybird on a large scale 3D dataset (ShapeNet) demonstrating highly competitive results in terms of Chamfer distance, Earth Mover's distance and Intersection Over Union (IoU).
Learning to Detect 3D Reflection Symmetry for Single-View Reconstruction
Jun 17, 2020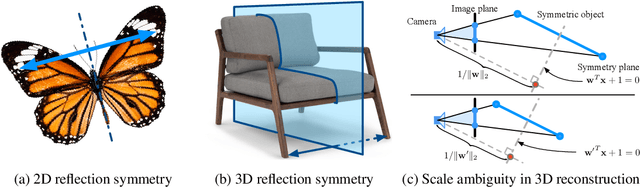
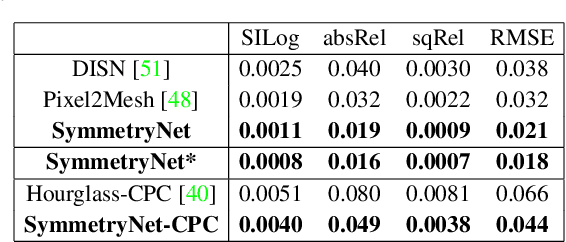
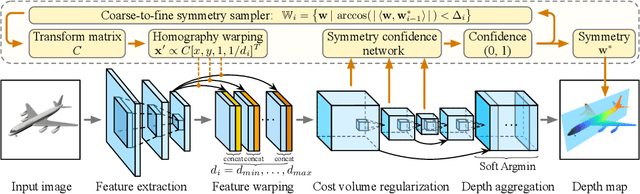
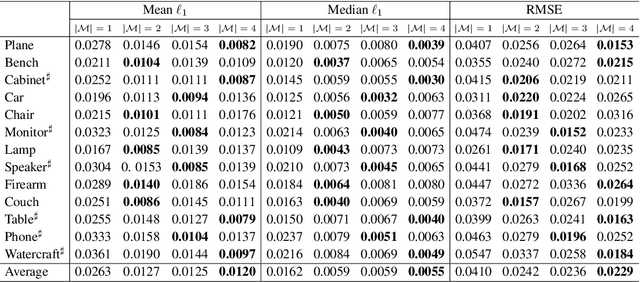
3D reconstruction from a single RGB image is a challenging problem in computer vision. Previous methods are usually solely data-driven, which lead to inaccurate 3D shape recovery and limited generalization capability. In this work, we focus on object-level 3D reconstruction and present a geometry-based end-to-end deep learning framework that first detects the mirror plane of reflection symmetry that commonly exists in man-made objects and then predicts depth maps by finding the intra-image pixel-wise correspondence of the symmetry. Our method fully utilizes the geometric cues from symmetry during the test time by building plane-sweep cost volumes, a powerful tool that has been used in multi-view stereopsis. To our knowledge, this is the first work that uses the concept of cost volumes in the setting of single-image 3D reconstruction. We conduct extensive experiments on the ShapeNet dataset and find that our reconstruction method significantly outperforms the previous state-of-the-art single-view 3D reconstruction networks in term of the accuracy of camera poses and depth maps, without requiring objects being completely symmetric. Code is available at https://github.com/zhou13/symmetrynet.
Single Image Super-Resolution via Cascaded Multi-Scale Cross Network
Feb 24, 2018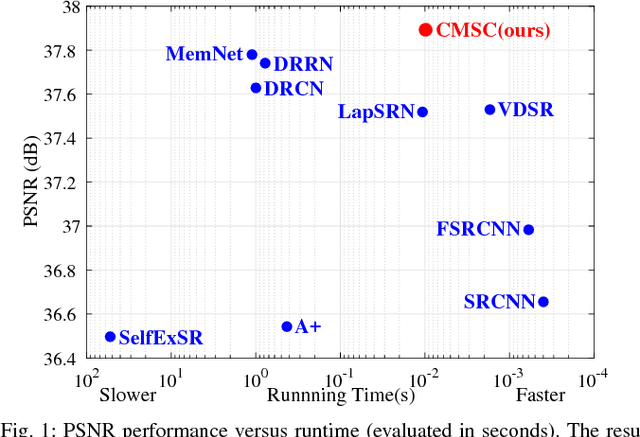

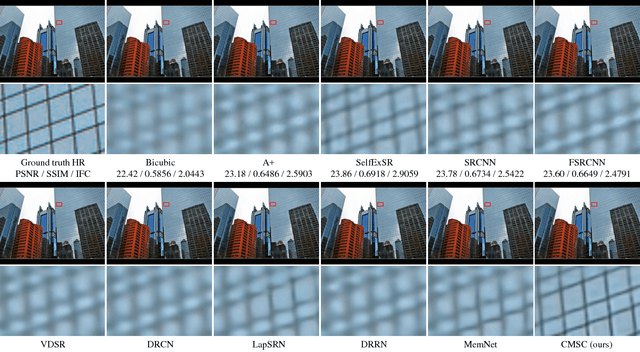
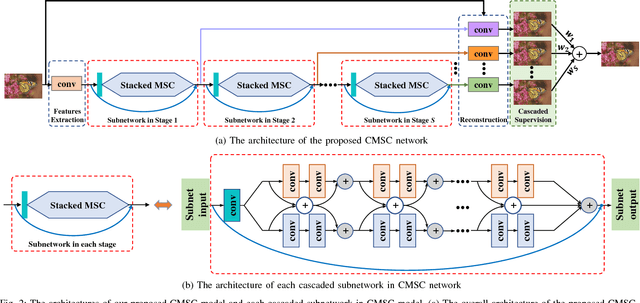
The deep convolutional neural networks have achieved significant improvements in accuracy and speed for single image super-resolution. However, as the depth of network grows, the information flow is weakened and the training becomes harder and harder. On the other hand, most of the models adopt a single-stream structure with which integrating complementary contextual information under different receptive fields is difficult. To improve information flow and to capture sufficient knowledge for reconstructing the high-frequency details, we propose a cascaded multi-scale cross network (CMSC) in which a sequence of subnetworks is cascaded to infer high resolution features in a coarse-to-fine manner. In each cascaded subnetwork, we stack multiple multi-scale cross (MSC) modules to fuse complementary multi-scale information in an efficient way as well as to improve information flow across the layers. Meanwhile, by introducing residual-features learning in each stage, the relative information between high-resolution and low-resolution features is fully utilized to further boost reconstruction performance. We train the proposed network with cascaded-supervision and then assemble the intermediate predictions of the cascade to achieve high quality image reconstruction. Extensive quantitative and qualitative evaluations on benchmark datasets illustrate the superiority of our proposed method over state-of-the-art super-resolution methods.
Person-in-Context Synthesiswith Compositional Structural Space
Aug 28, 2020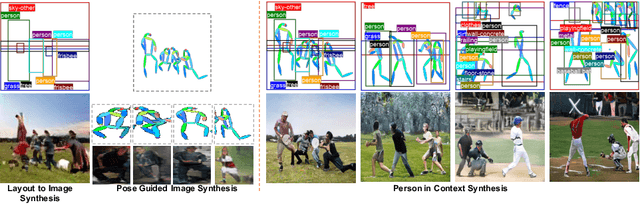
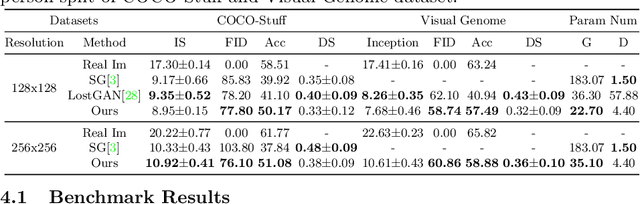
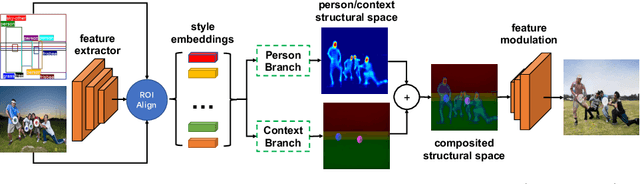

Despite significant progress, controlled generation of complex images with interacting people remains difficult. Existing layout generation methods fall short of synthesizing realistic person instances; while pose-guided generation approaches focus on a single person and assume simple or known backgrounds. To tackle these limitations, we propose a new problem, \textbf{Persons in Context Synthesis}, which aims to synthesize diverse person instance(s) in consistent contexts, with user control over both. The context is specified by the bounding box object layout which lacks shape information, while pose of the person(s) by keypoints which are sparsely annotated. To handle the stark difference in input structures, we proposed two separate neural branches to attentively composite the respective (context/person) inputs into shared ``compositional structural space'', which encodes shape, location and appearance information for both context and person structures in a disentangled manner. This structural space is then decoded to the image space using multi-level feature modulation strategy, and learned in a self supervised manner from image collections and their corresponding inputs. Extensive experiments on two large-scale datasets (COCO-Stuff \cite{caesar2018cvpr} and Visual Genome \cite{krishna2017visual}) demonstrate that our framework outperforms state-of-the-art methods w.r.t. synthesis quality.
Learning Flow-based Feature Warping for Face Frontalization with Illumination Inconsistent Supervision
Aug 16, 2020
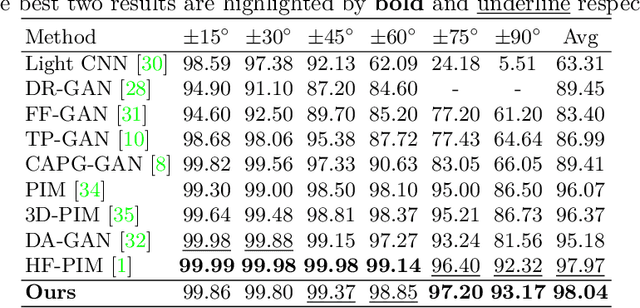
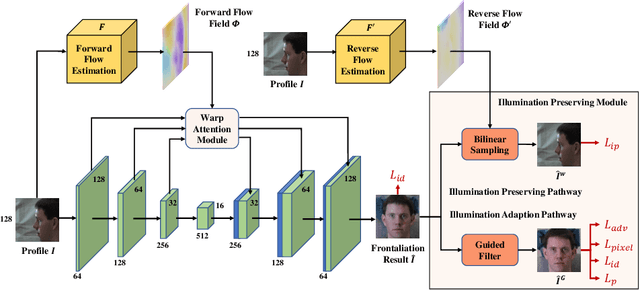

Despite recent advances in deep learning-based face frontalization methods, photo-realistic and illumination preserving frontal face synthesis is still challenging due to large pose and illumination discrepancy during training. We propose a novel Flow-based Feature Warping Model (FFWM) which can learn to synthesize photo-realistic and illumination preserving frontal images with illumination inconsistent supervision. Specifically, an Illumination Preserving Module (IPM) is proposed to learn illumination preserving image synthesis from illumination inconsistent image pairs. IPM includes two pathways which collaborate to ensure the synthesized frontal images are illumination preserving and with fine details. Moreover, a Warp Attention Module (WAM) is introduced to reduce the pose discrepancy in the feature level, and hence to synthesize frontal images more effectively and preserve more details of profile images. The attention mechanism in WAM helps reduce the artifacts caused by the displacements between the profile and the frontal images. Quantitative and qualitative experimental results show that our FFWM can synthesize photo-realistic and illumination preserving frontal images and performs favorably against the state-of-the-art results.
Improving Automated Visual Fault Detection by Combining a Biologically Plausible Model of Visual Attention with Deep Learning
Feb 13, 2021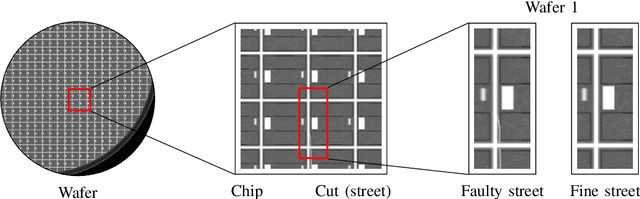
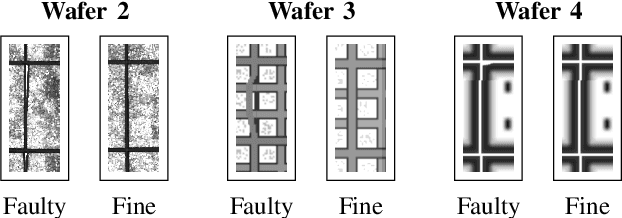
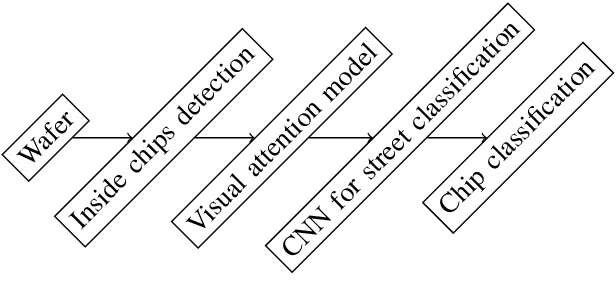
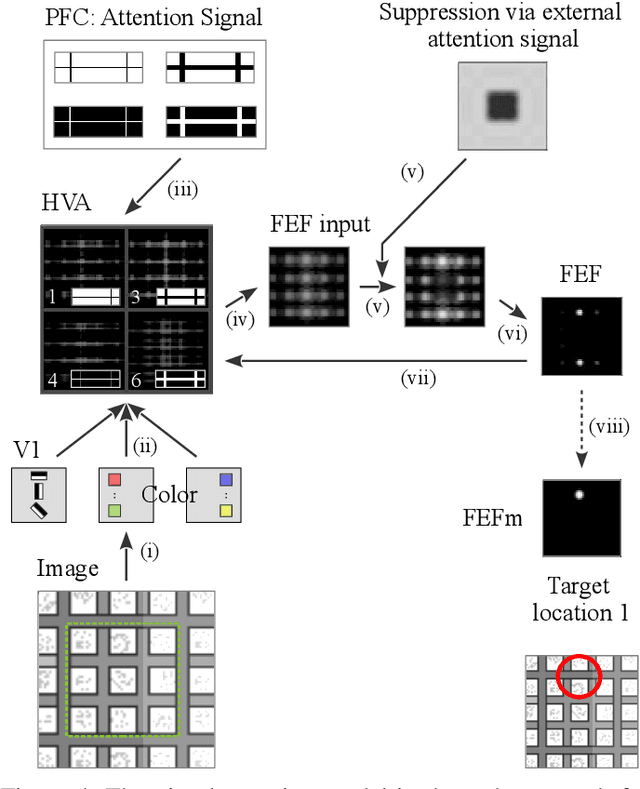
It is a long-term goal to transfer biological processing principles as well as the power of human recognition into machine vision and engineering systems. One of such principles is visual attention, a smart human concept which focuses processing on a part of a scene. In this contribution, we utilize attention to improve the automatic detection of defect patterns for wafers within the domain of semiconductor manufacturing. Previous works in the domain have often utilized classical machine learning approaches such as KNNs, SVMs, or MLPs, while a few have already used modern approaches like deep neural networks (DNNs). However, one problem in the domain is that the faults are often very small and have to be detected within a larger size of the chip or even the wafer. Therefore, small structures in the size of pixels have to be detected in a vast amount of image data. One interesting principle of the human brain for solving this problem is visual attention. Hence, we employ here a biologically plausible model of visual attention for automatic visual inspection. We propose a hybrid system of visual attention and a deep neural network. As demonstrated, our system achieves among other decisive advantages an improvement in accuracy from 81% to 92%, and an increase in accuracy for detecting faults from 67% to 88%. Hence, the error rates are reduced from 19% to 8%, and notably from 33% to 12% for detecting a fault in a chip. These results show that attention can greatly improve the performance of visual inspection systems. Furthermore, we conduct a broad evaluation, identifying specific advantages of the biological attention model in this application, and benchmarks standard deep learning approaches as an alternative with and without attention. This work is an extended arXiv version of the original conference article published in "IECON 2020", which has been extended regarding visual attention.