 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SAR Image Colorization: Converting Single-Polarization to Fully Polarimetric Using Deep Neural Networks
Jul 22, 2017
A deep neural networks based method is proposed to convert single polarization grayscale SAR image to fully polarimetric. It consists of two components: a feature extractor network to extract hierarchical multi-scale spatial features of grayscale SAR image, followed by a feature translator network to map spatial feature to polarimetric feature with which the polarimetric covariance matrix of each pixel can be reconstructed. Both qualitative and quantitative experiments with real fully polarimetric data are conducted to show the efficacy of the proposed method. The reconstructed full-pol SAR image agrees well with the true full-pol image. Existing PolSAR applications such as model-based decomposition and unsupervised classification can be applied directly to the reconstructed full-pol SAR images. This framework can be easily extended to reconstruction of full-pol data from compact-pol data. The experiment results also show that the proposed method could be potentially used for interference removal on the cross-polarization channel.
Manifold Alignment for Semantically Aligned Style Transfer
May 21, 2020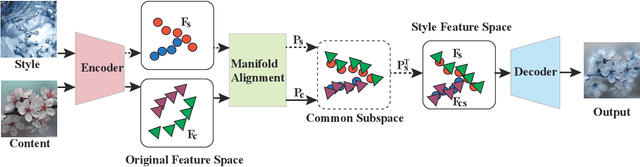
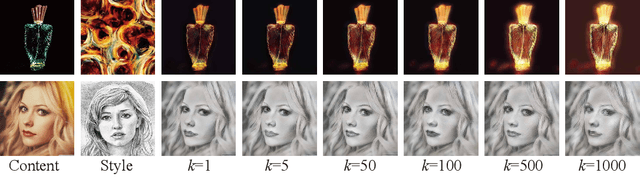
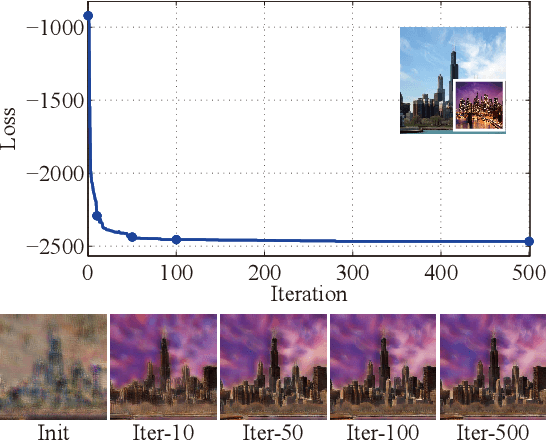

Given a content image and a style image, the goal of style transfer is to synthesize an output image by transferring the target style to the content image. Currently, most of the methods address the problem with global style transfer, assuming styles can be represented by global statistics, such as Gram matrices or covariance matrices. In this paper, we make a different assumption that local semantically aligned (or similar) regions between the content and style images should share similar style patterns. Based on this assumption, content features and style features are seen as two sets of manifolds and a manifold alignment based style transfer (MAST) method is proposed. MAST is a subspace learning method which learns a common subspace of the content and style features. In the common subspace, content and style features with larger feature similarity or the same semantic meaning are forced to be close. The learned projection matrices are added with orthogonality constraints so that the mapping can be bidirectional, which allows us to project the content features into the common subspace, and then into the original style space. By using a pre-trained decoder, promising stylized images are obtained. The method is further extended to allow users to specify corresponding semantic regions between content and style images or using semantic segmentation maps as guidance. Extensive experiments show the proposed MAST achieves appealing results in style transfer.
Cluster, Split, Fuse, and Update: Meta-Learning for Open Compound Domain Adaptive Semantic Segmentation
Dec 15, 2020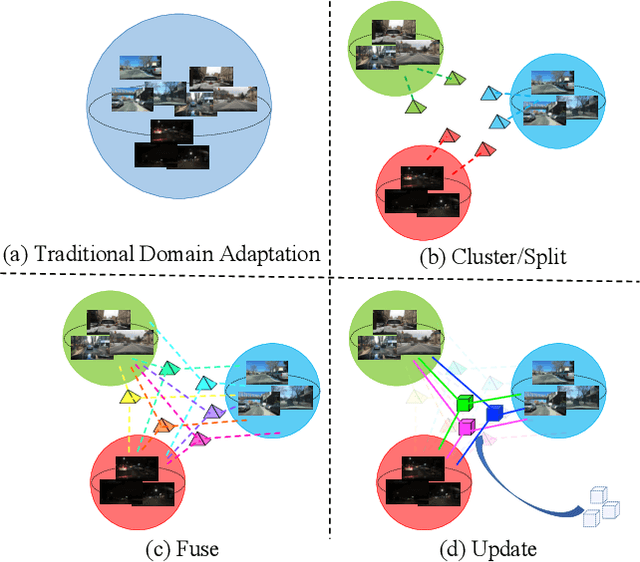
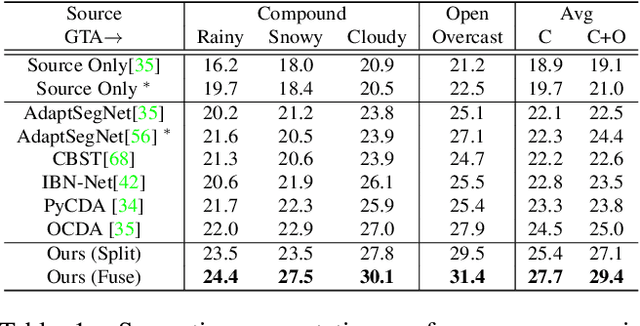
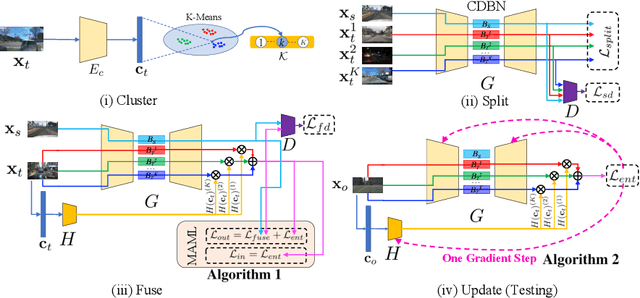
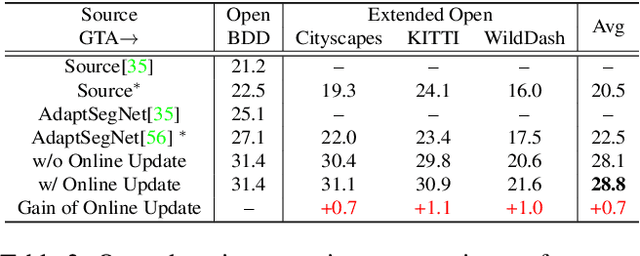
Open compound domain adaptation (OCDA) is a domain adaptation setting, where target domain is modeled as a compound of multiple unknown homogeneous domains, which brings the advantage of improved generalization to unseen domains. In this work, we propose a principled meta-learning based approach to OCDA for semantic segmentation, MOCDA, by modeling the unlabeled target domain continuously. Our approach consists of four key steps. First, we cluster target domain into multiple sub-target domains by image styles, extracted in an unsupervised manner. Then, different sub-target domains are split into independent branches, for which batch normalization parameters are learnt to treat them independently. A meta-learner is thereafter deployed to learn to fuse sub-target domain-specific predictions, conditioned upon the style code. Meanwhile, we learn to online update the model by model-agnostic meta-learning (MAML) algorithm, thus to further improve generalization. We validate the benefits of our approach by extensive experiments on synthetic-to-real knowledge transfer benchmark datasets, where we achieve the state-of-the-art performance in both compound and open domains.
Solving the functional Eigen-Problem using Neural Networks
Jul 20, 2020
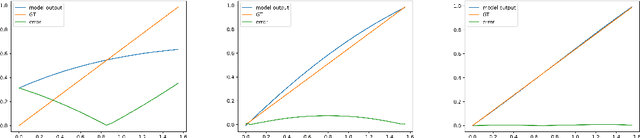
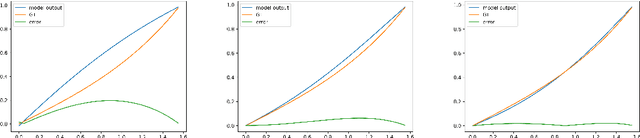
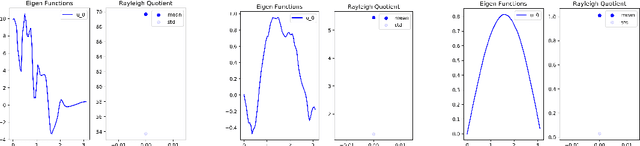
In this work, we explore the ability of NN (Neural Networks) to serve as a tool for finding eigen-pairs of ordinary differential equations. The question we aime to address is whether, given a self-adjoint operator, we can learn what are the eigenfunctions, and their matching eigenvalues. The topic of solving the eigen-problem is widely discussed in Image Processing, as many image processing algorithms can be thought of as such operators. We suggest an alternative to numeric methods of finding eigenpairs, which may potentially be more robust and have the ability to solve more complex problems. In this work, we focus on simple problems for which the analytical solution is known. This way, we are able to make initial steps in discovering the capabilities and shortcomings of DNN (Deep Neural Networks) in the given setting.
Reliable Tuberculosis Detection using Chest X-ray with Deep Learning, Segmentation and Visualization
Jul 29, 2020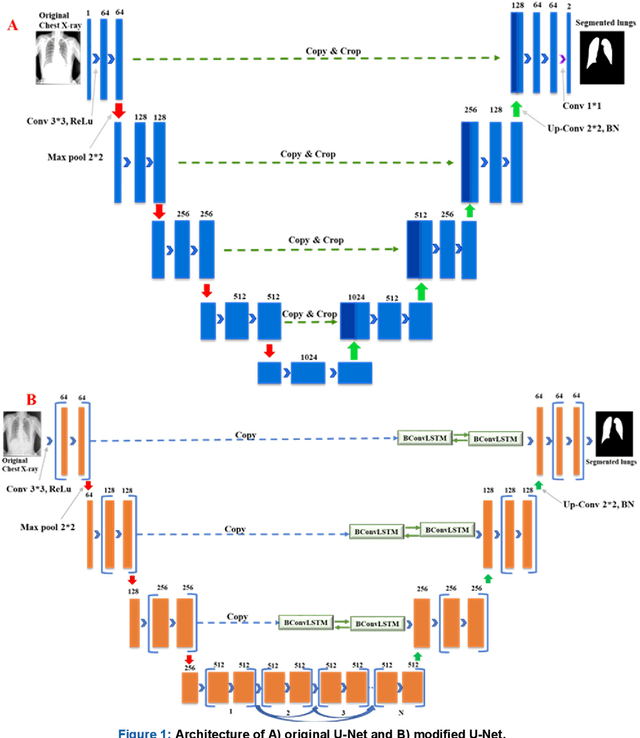
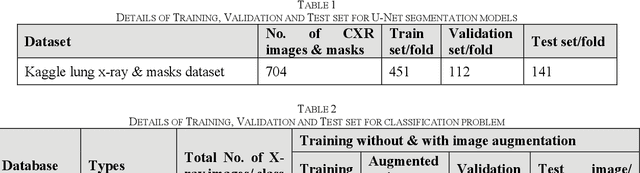
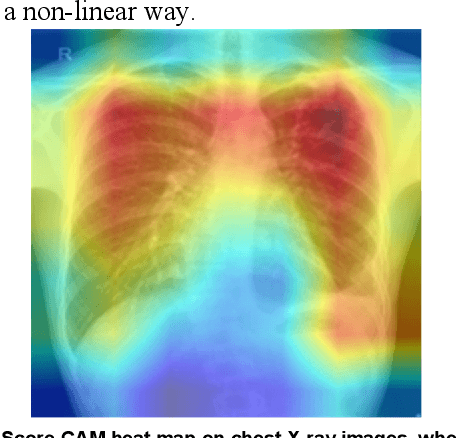
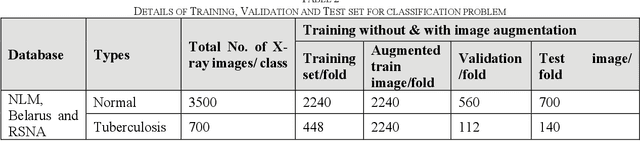
Tuberculosis (TB) is a chronic lung disease that occurs due to bacterial infection and is one of the top 10 leading causes of death. Accurate and early detection of TB is very important, otherwise, it could be life-threatening. In this work, we have detected TB reliably from the chest X-ray images using image pre-processing, data augmentation, image segmentation, and deep-learning classification techniques. Several public databases were used to create a database of 700 TB infected and 3500 normal chest X-ray images for this study. Nine different deep CNNs (ResNet18, ResNet50, ResNet101, ChexNet, InceptionV3, Vgg19, DenseNet201, SqueezeNet, and MobileNet), which were used for transfer learning from their pre-trained initial weights and trained, validated and tested for classifying TB and non-TB normal cases. Three different experiments were carried out in this work: segmentation of X-ray images using two different U-net models, classification using X-ray images, and segmented lung images. The accuracy, precision, sensitivity, F1-score, specificity in the detection of tuberculosis using X-ray images were 97.07 %, 97.34 %, 97.07 %, 97.14 % and 97.36 % respectively. However, segmented lungs for the classification outperformed than whole X-ray image-based classification and accuracy, precision, sensitivity, F1-score, specificity were 99.9 %, 99.91 %, 99.9 %, 99.9 %, and 99.52 % respectively. The paper also used a visualization technique to confirm that CNN learns dominantly from the segmented lung regions results in higher detection accuracy. The proposed method with state-of-the-art performance can be useful in the computer-aided faster diagnosis of tuberculosis.
Label-Embedding for Image Classification
Oct 01, 2015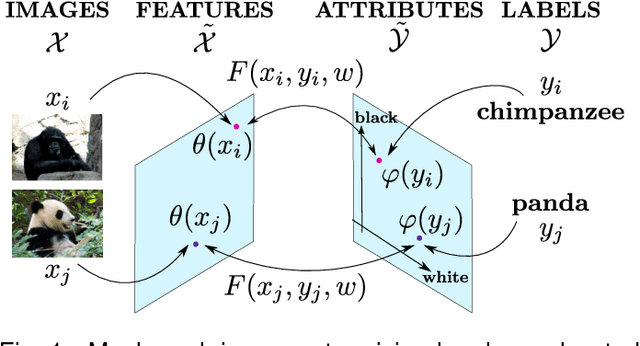
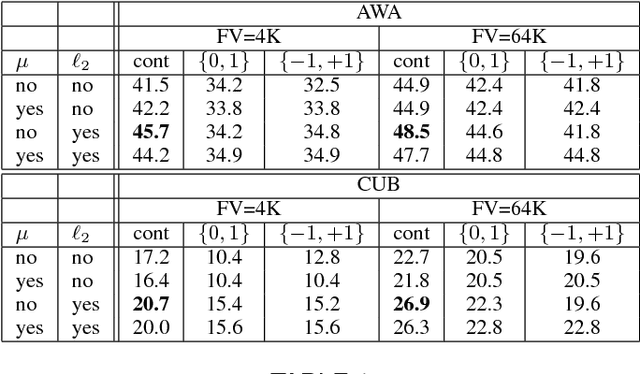
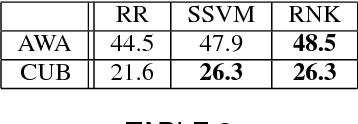
Attributes act as intermediate representations that enable parameter sharing between classes, a must when training data is scarce. We propose to view attribute-based image classification as a label-embedding problem: each class is embedded in the space of attribute vectors. We introduce a function that measures the compatibility between an image and a label embedding. The parameters of this function are learned on a training set of labeled samples to ensure that, given an image, the correct classes rank higher than the incorrect ones. Results on the Animals With Attributes and Caltech-UCSD-Birds datasets show that the proposed framework outperforms the standard Direct Attribute Prediction baseline in a zero-shot learning scenario. Label embedding enjoys a built-in ability to leverage alternative sources of information instead of or in addition to attributes, such as e.g. class hierarchies or textual descriptions. Moreover, label embedding encompasses the whole range of learning settings from zero-shot learning to regular learning with a large number of labeled examples.
Automatically Generating Codes from Graphical Screenshots Based on Deep Autocoder
Jul 05, 2020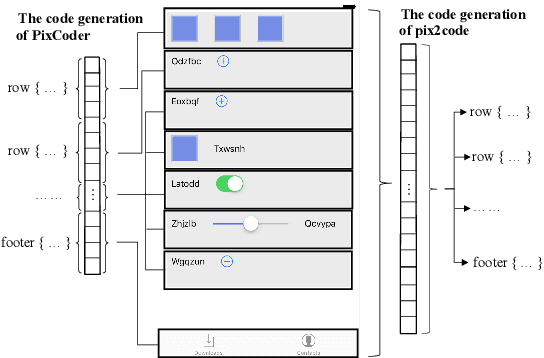
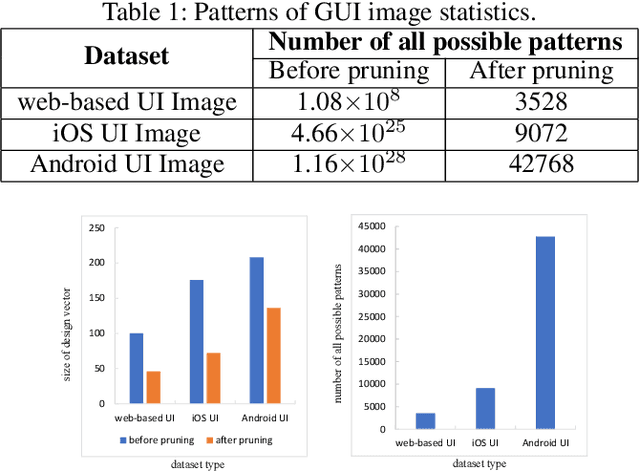
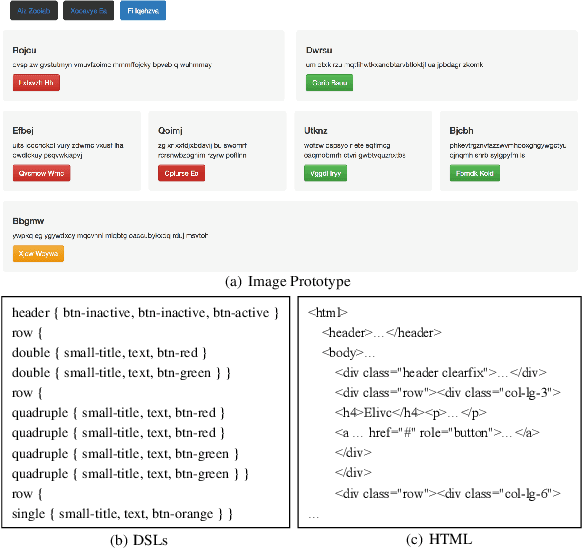
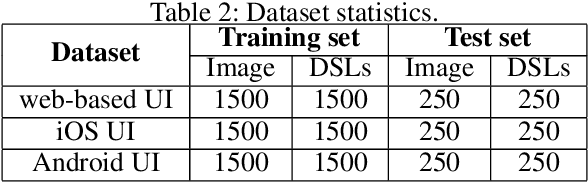
During software front-end development, the work to convert Graphical User Interface(GUI) image to the corresponding front-end code is an inevitable tedious work. There have been some attempts to make this work to be automatic. However, the GUI code generated by these models is not accurate due to the lack of attention mechanism guidance. To solve this problem, we propose PixCoder based on an artificially supervised attention mechanism. The approach is to train a neural network to predict the style sheets in the input GUI image and then output a vector. PixCoder generate the GUI code targeting specific platform according to the output vector. The experimental results have shown the accuracy of the GUI code generated by PixCoder is over 95%.
Improving Few-Shot Learning using Composite Rotation based Auxiliary Task
Jun 29, 2020
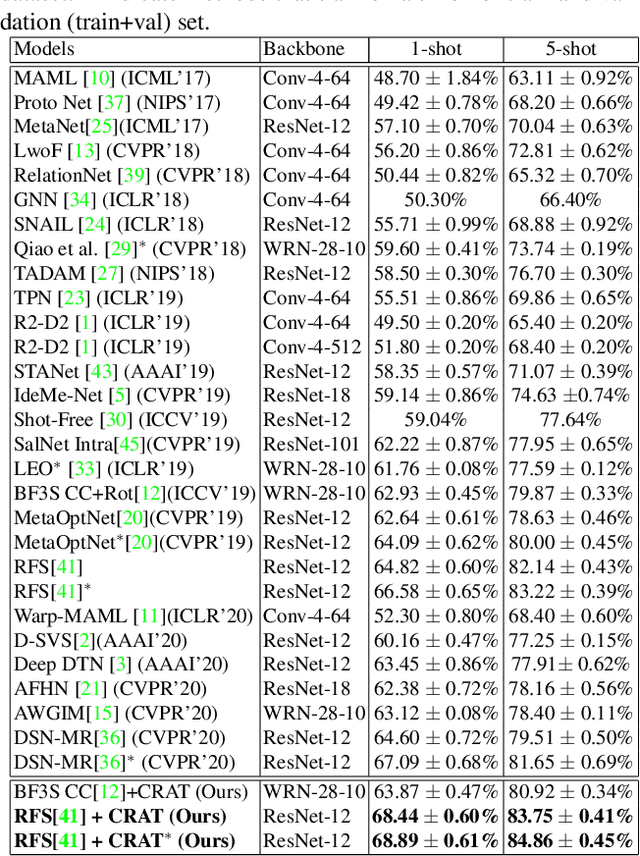
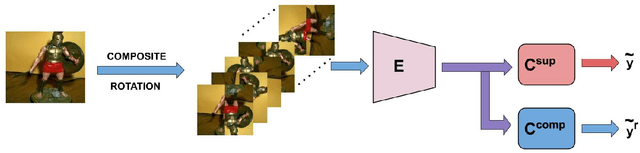
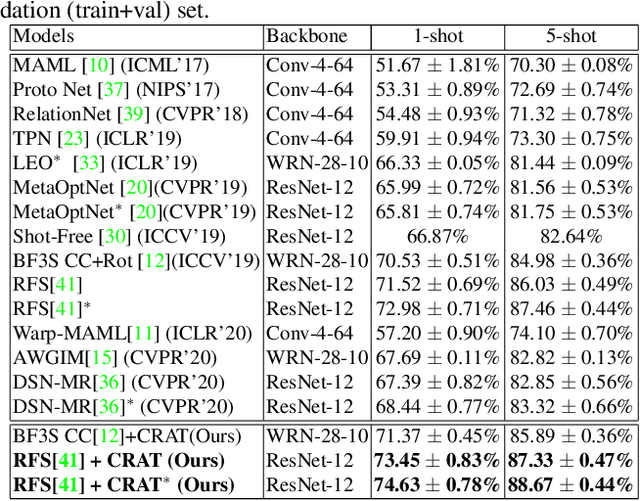
In this paper, we propose an approach to improve few-shot classification performance using a composite rotation based auxiliary task. Few-shot classification methods aim to produce neural networks that perform well for classes with a large number of training samples and classes with less number of training samples. They employ techniques to enable the network to produce highly discriminative features that are also very generic. Generally, the better the quality and generic-nature of the features produced by the network, the better is the performance of the network on few-shot learning. Our approach aims to train networks to produce such features by using a self-supervised auxiliary task. Our proposed composite rotation based auxiliary task performs rotation at two levels, i.e., rotation of patches inside the image (inner rotation) and rotation of the whole image (outer rotation) and assigns one out of 16 rotation classes to the modified image. We then simultaneously train for the composite rotation prediction task along with the original classification task, which forces the network to learn high-quality generic features that help improve the few-shot classification performance. We experimentally show that our approach performs better than existing few-shot learning methods on multiple benchmark datasets.
Machine Identification of High Impact Research through Text and Image Analysis
May 20, 2020
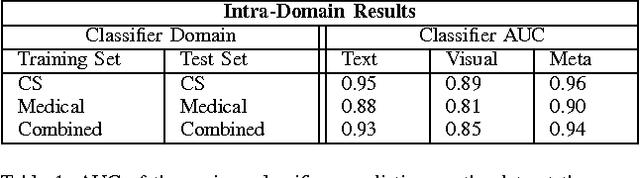
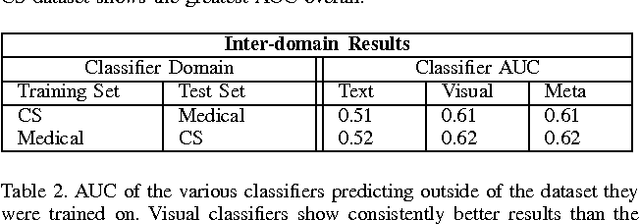
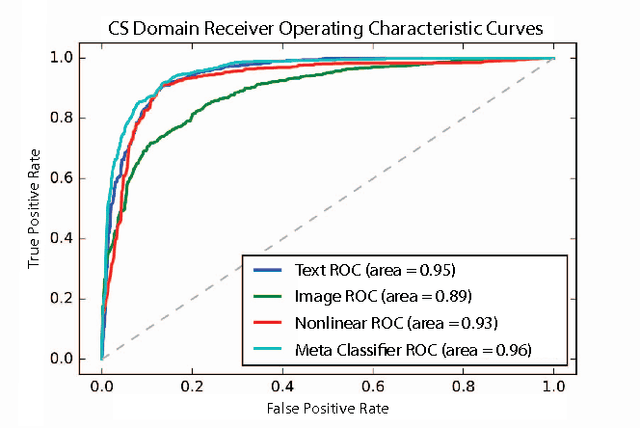
The volume of academic paper submissions and publications is growing at an ever increasing rate. While this flood of research promises progress in various fields, the sheer volume of output inherently increases the amount of noise. We present a system to automatically separate papers with a high from those with a low likelihood of gaining citations as a means to quickly find high impact, high quality research. Our system uses both a visual classifier, useful for surmising a document's overall appearance, and a text classifier, for making content-informed decisions. Current work in the field focuses on small datasets composed of papers from individual conferences. Attempts to use similar techniques on larger datasets generally only considers excerpts of the documents such as the abstract, potentially throwing away valuable data. We rectify these issues by providing a dataset composed of PDF documents and citation counts spanning a decade of output within two separate academic domains: computer science and medicine. This new dataset allows us to expand on current work in the field by generalizing across time and academic domain. Moreover, we explore inter-domain prediction models - evaluating a classifier's performance on a domain it was not trained on - to shed further insight on this important problem.
Dataset on Bi- and Multi-Nucleated Tumor Cells in Canine Cutaneous Mast Cell Tumors
Jan 05, 2021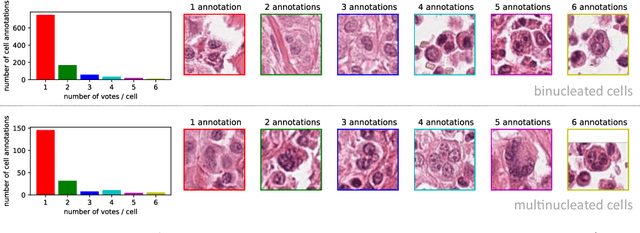
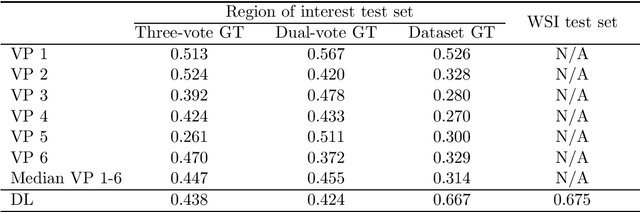
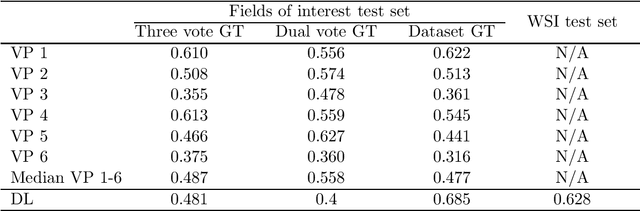
Tumor cells with two nuclei (binucleated cells, BiNC) or more nuclei (multinucleated cells, MuNC) indicate an increased amount of cellular genetic material which is thought to facilitate oncogenesis, tumor progression and treatment resistance. In canine cutaneous mast cell tumors (ccMCT), binucleation and multinucleation are parameters used in cytologic and histologic grading schemes (respectively) which correlate with poor patient outcome. For this study, we created the first open source data-set with 19,983 annotations of BiNC and 1,416 annotations of MuNC in 32 histological whole slide images of ccMCT. Labels were created by a pathologist and an algorithmic-aided labeling approach with expert review of each generated candidate. A state-of-the-art deep learning-based model yielded an $F_1$ score of 0.675 for BiNC and 0.623 for MuNC on 11 test whole slide images. In regions of interest ($2.37 mm^2$) extracted from these test images, 6 pathologists had an object detection performance between 0.270 - 0.526 for BiNC and 0.316 - 0.622 for MuNC, while our model archived an $F_1$ score of 0.667 for BiNC and 0.685 for MuNC. This open dataset can facilitate development of automated image analysis for this task and may thereby help to promote standardization of this facet of histologic tumor prognostication.