 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Recovering the Imperfect: Cell Segmentation in the Presence of Dynamically Localized Proteins
Nov 20, 2020

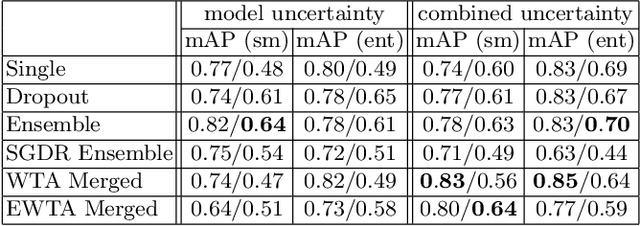
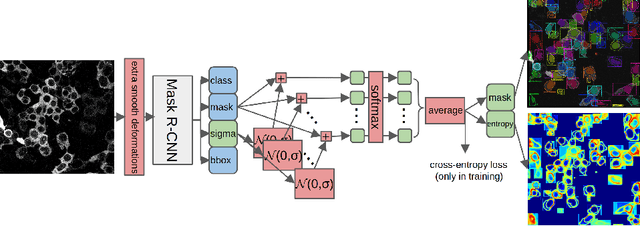
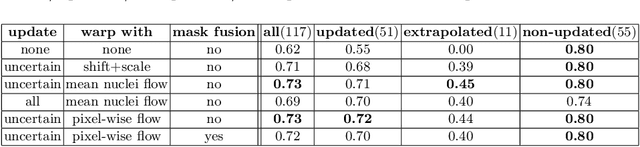
Deploying off-the-shelf segmentation networks on biomedical data has become common practice, yet if structures of interest in an image sequence are visible only temporarily, existing frame-by-frame methods fail. In this paper, we provide a solution to segmentation of imperfect data through time based on temporal propagation and uncertainty estimation. We integrate uncertainty estimation into Mask R-CNN network and propagate motion-corrected segmentation masks from frames with low uncertainty to those frames with high uncertainty to handle temporary loss of signal for segmentation. We demonstrate the value of this approach over frame-by-frame segmentation and regular temporal propagation on data from human embryonic kidney (HEK293T) cells transiently transfected with a fluorescent protein that moves in and out of the nucleus over time. The method presented here will empower microscopic experiments aimed at understanding molecular and cellular function.
CyCNN: A Rotation Invariant CNN using Polar Mapping and Cylindrical Convolution Layers
Jul 21, 2020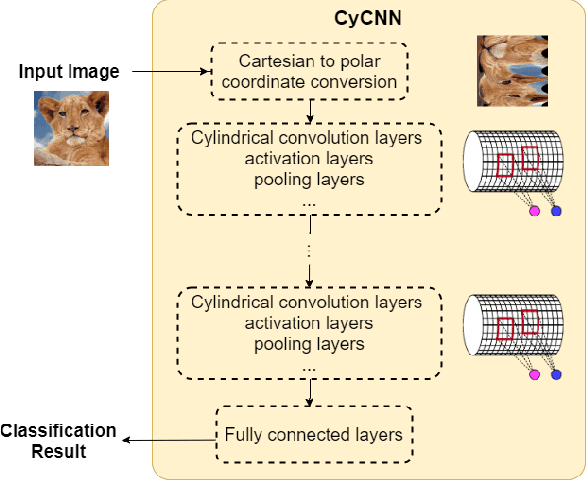
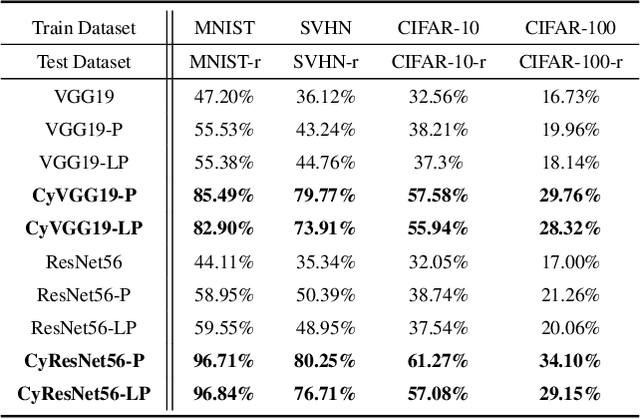
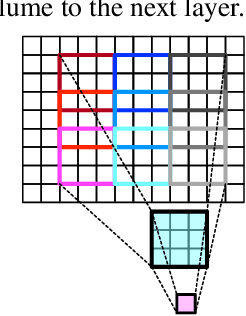
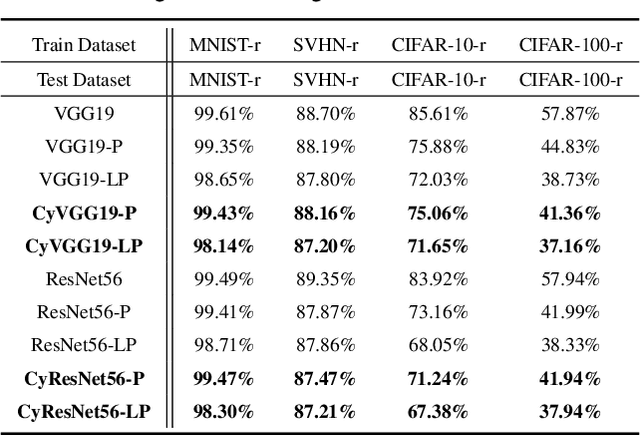
Deep Convolutional Neural Networks (CNNs) are empirically known to be invariant to moderate translation but not to rotation in image classification. This paper proposes a deep CNN model, called CyCNN, which exploits polar mapping of input images to convert rotation to translation. To deal with the cylindrical property of the polar coordinates, we replace convolution layers in conventional CNNs to cylindrical convolutional (CyConv) layers. A CyConv layer exploits the cylindrically sliding windows (CSW) mechanism that vertically extends the input-image receptive fields of boundary units in a convolutional layer. We evaluate CyCNN and conventional CNN models for classification tasks on rotated MNIST, CIFAR-10, and SVHN datasets. We show that if there is no data augmentation during training, CyCNN significantly improves classification accuracies when compared to conventional CNN models. Our implementation of CyCNN is publicly available on https://github.com/mcrl/CyCNN.
Personalized Classifier for Food Image Recognition
Apr 08, 2018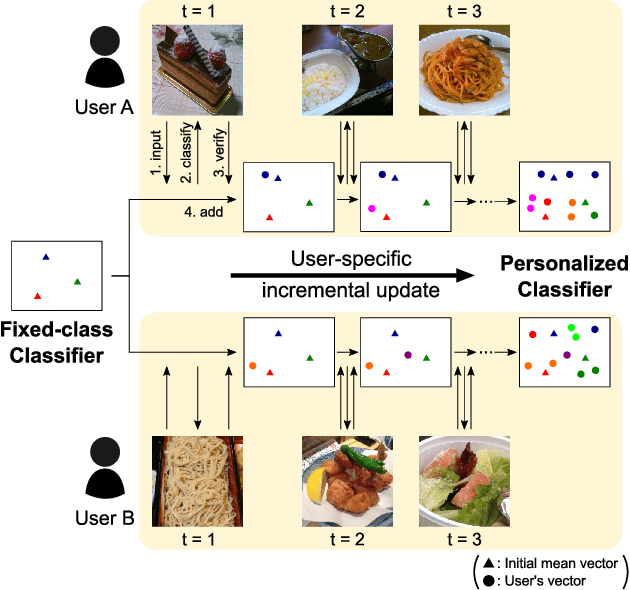
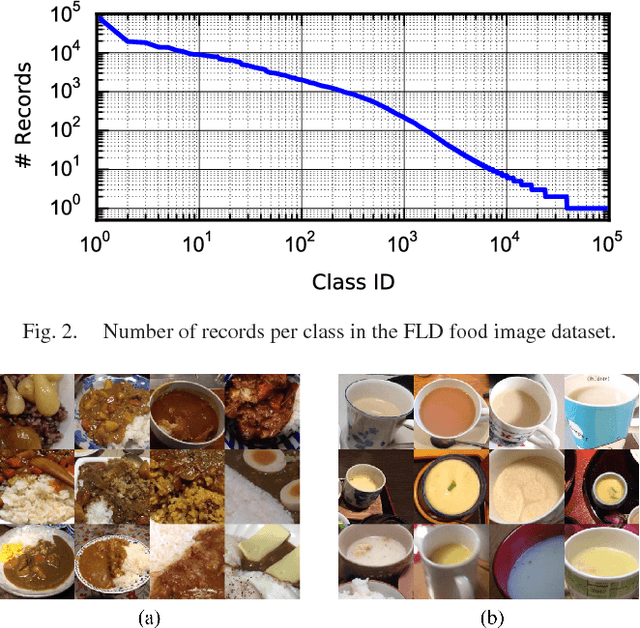


Currently, food image recognition tasks are evaluated against fixed datasets. However, in real-world conditions, there are cases in which the number of samples in each class continues to increase and samples from novel classes appear. In particular, dynamic datasets in which each individual user creates samples and continues the updating process often have content that varies considerably between different users, and the number of samples per person is very limited. A single classifier common to all users cannot handle such dynamic data. Bridging the gap between the laboratory environment and the real world has not yet been accomplished on a large scale. Personalizing a classifier incrementally for each user is a promising way to do this. In this paper, we address the personalization problem, which involves adapting to the user's domain incrementally using a very limited number of samples. We propose a simple yet effective personalization framework which is a combination of the nearest class mean classifier and the 1-nearest neighbor classifier based on deep features. To conduct realistic experiments, we made use of a new dataset of daily food images collected by a food-logging application. Experimental results show that our proposed method significantly outperforms existing methods.
On Translation Invariance in CNNs: Convolutional Layers can Exploit Absolute Spatial Location
Mar 16, 2020

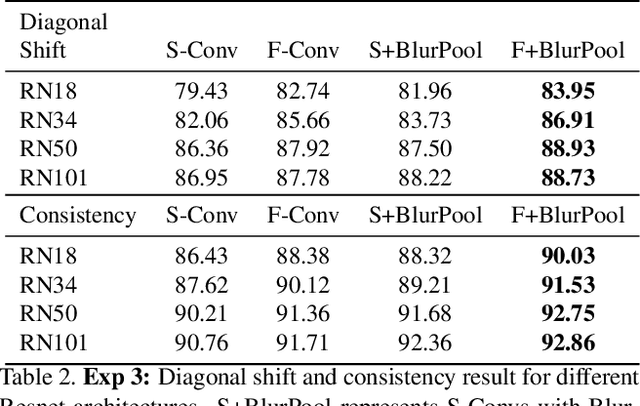
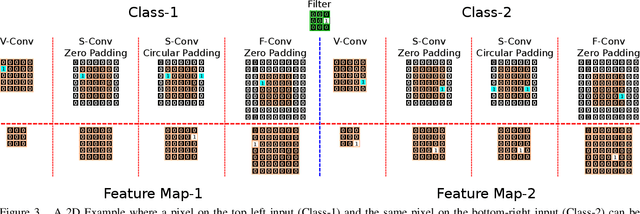
In this paper we challenge the common assumption that convolutional layers in modern CNNs are translation invariant. We show that CNNs can and will exploit the absolute spatial location by learning filters that respond exclusively to particular absolute locations by exploiting image boundary effects. Because modern CNNs filters have a huge receptive field, these boundary effects operate even far from the image boundary, allowing the network to exploit absolute spatial location all over the image. We give a simple solution to remove spatial location encoding which improves translation invariance and thus gives a stronger visual inductive bias which particularly benefits small data sets. We broadly demonstrate these benefits on several architectures and various applications such as image classification, patch matching, and two video classification datasets.
Tensor Alignment Based Domain Adaptation for Hyperspectral Image Classification
Sep 04, 2018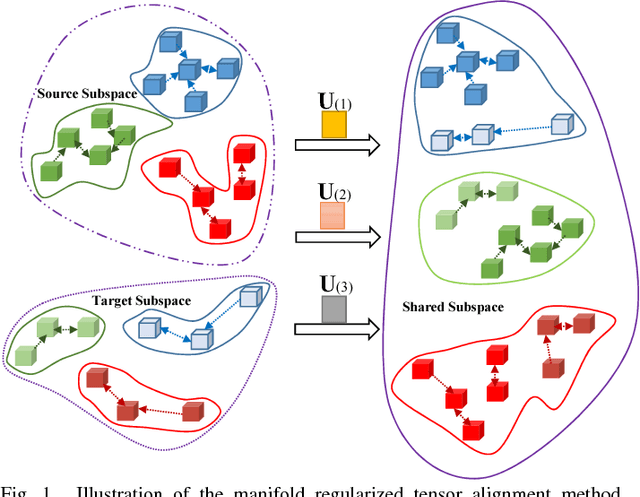
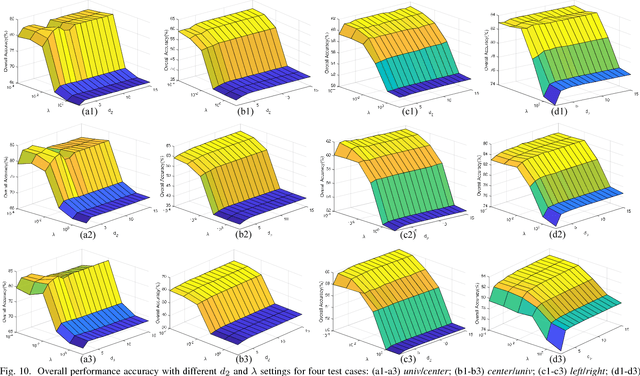
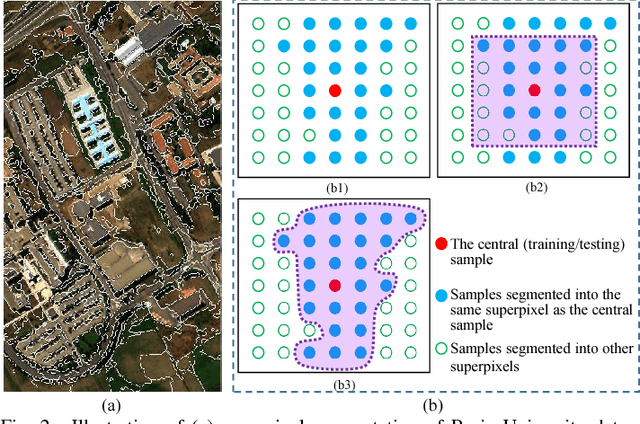
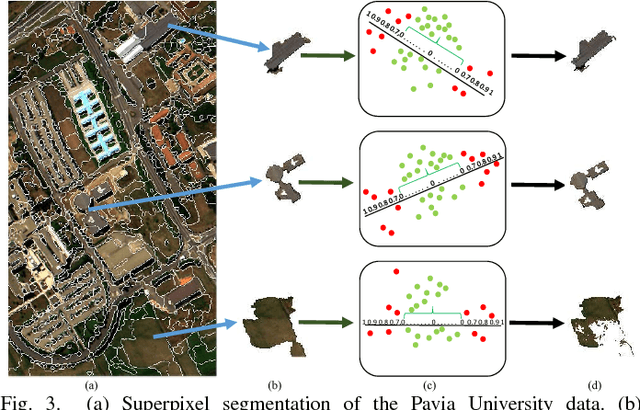
This paper presents a tensor alignment (TA) based domain adaptation method for hyperspectral image (HSI) classification. To be specific, HSIs in both domains are first segmented into superpixels and tensors of both domains are constructed to include neighboring samples from single superpixel. Then we consider the subspace invariance between two domains as projection matrices and original tensors are projected as core tensors with lower dimensions into the invariant tensor subspace by applying Tucker decomposition. To preserve geometric information in original tensors, we employ a manifold regularization term for core tensors into the decomposition progress. The projection matrices and core tensors are solved in an alternating optimization manner and the convergence of TA algorithm is analyzed. In addition, a post-processing strategy is defined via pure samples extraction for each superpixel to further improve classification performance. Experimental results on four real HSIs demonstrate that the proposed method can achieve better performance compared with the state-of-the-art subspace learning methods when a limited amount of source labeled samples are available.
SAR Image Colorization: Converting Single-Polarization to Fully Polarimetric Using Deep Neural Networks
Jul 22, 2017A deep neural networks based method is proposed to convert single polarization grayscale SAR image to fully polarimetric. It consists of two components: a feature extractor network to extract hierarchical multi-scale spatial features of grayscale SAR image, followed by a feature translator network to map spatial feature to polarimetric feature with which the polarimetric covariance matrix of each pixel can be reconstructed. Both qualitative and quantitative experiments with real fully polarimetric data are conducted to show the efficacy of the proposed method. The reconstructed full-pol SAR image agrees well with the true full-pol image. Existing PolSAR applications such as model-based decomposition and unsupervised classification can be applied directly to the reconstructed full-pol SAR images. This framework can be easily extended to reconstruction of full-pol data from compact-pol data. The experiment results also show that the proposed method could be potentially used for interference removal on the cross-polarization channel.
A Convolutional Approach to Vertebrae Detection and Labelling in Whole Spine MRI
Jul 13, 2020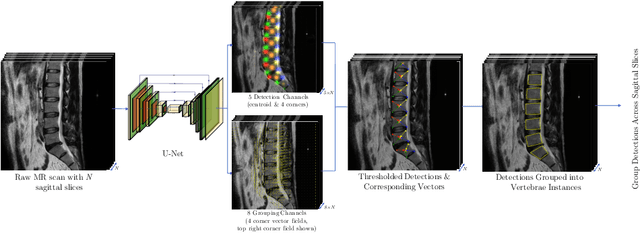
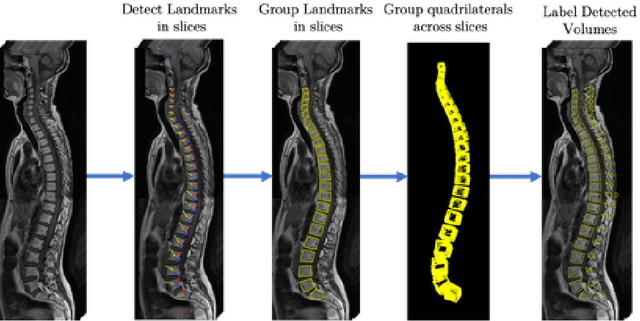

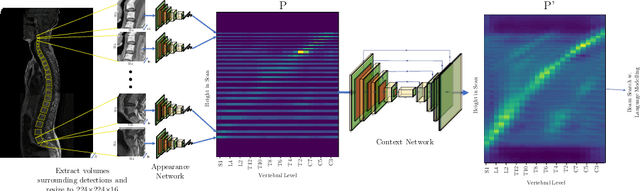
We propose a novel convolutional method for the detection and identification of vertebrae in whole spine MRIs. This involves using a learnt vector field to group detected vertebrae corners together into individual vertebral bodies and convolutional image-to-image translation followed by beam search to label vertebral levels in a self-consistent manner. The method can be applied without modification to lumbar, cervical and thoracic-only scans across a range of different MR sequences. The resulting system achieves 98.1% detection rate and 96.5% identification rate on a challenging clinical dataset of whole spine scans and matches or exceeds the performance of previous systems on lumbar-only scans. Finally, we demonstrate the clinical applicability of this method, using it for automated scoliosis detection in both lumbar and whole spine MR scans.
Label-Embedding for Image Classification
Oct 01, 2015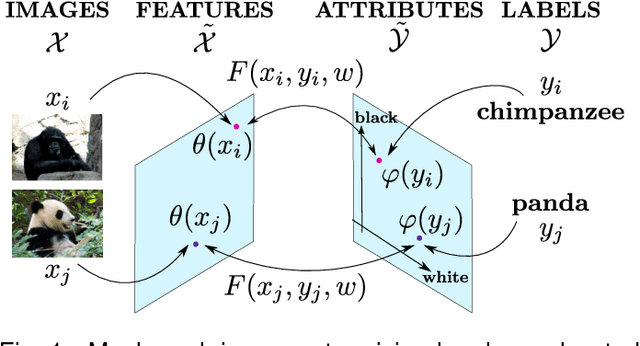
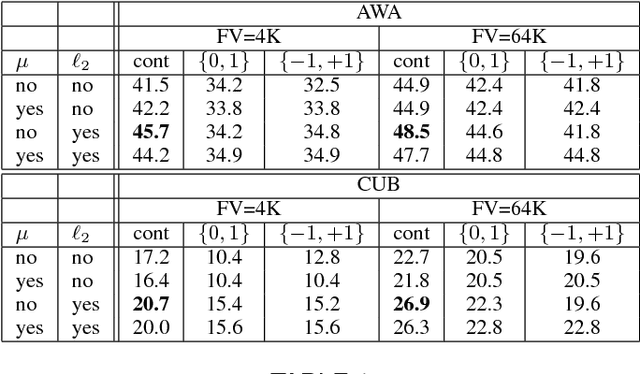
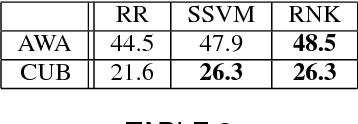
Attributes act as intermediate representations that enable parameter sharing between classes, a must when training data is scarce. We propose to view attribute-based image classification as a label-embedding problem: each class is embedded in the space of attribute vectors. We introduce a function that measures the compatibility between an image and a label embedding. The parameters of this function are learned on a training set of labeled samples to ensure that, given an image, the correct classes rank higher than the incorrect ones. Results on the Animals With Attributes and Caltech-UCSD-Birds datasets show that the proposed framework outperforms the standard Direct Attribute Prediction baseline in a zero-shot learning scenario. Label embedding enjoys a built-in ability to leverage alternative sources of information instead of or in addition to attributes, such as e.g. class hierarchies or textual descriptions. Moreover, label embedding encompasses the whole range of learning settings from zero-shot learning to regular learning with a large number of labeled examples.
Edge Network-Assisted Real-Time Object Detection Framework for Autonomous Driving
Aug 17, 2020
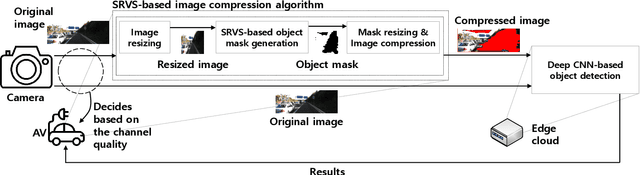
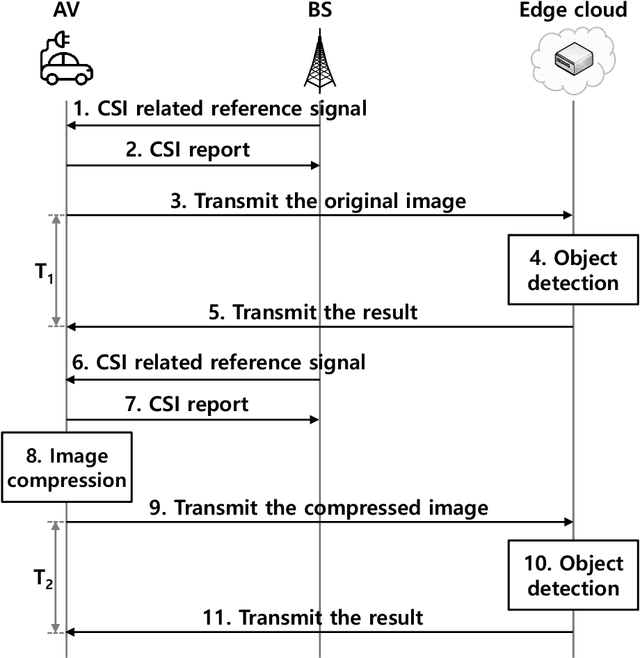
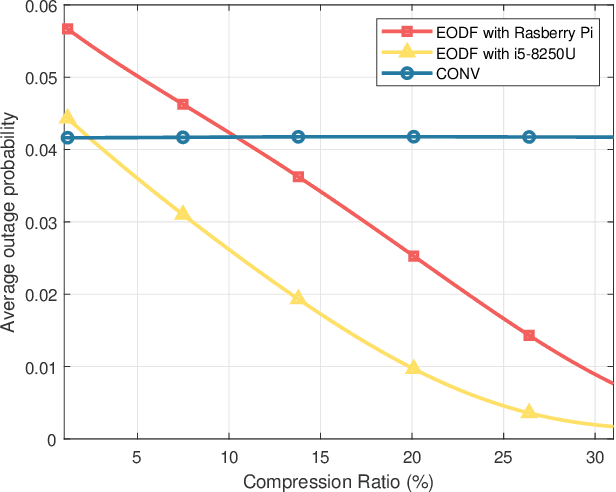
Autonomous vehicles (AVs) can achieve the desired results within a short duration by offloading tasks even requiring high computational power (e.g., object detection (OD)) to edge clouds. However, although edge clouds are exploited, real-time OD cannot always be guaranteed due to dynamic channel quality. To mitigate this problem, we propose an edge network-assisted real-time OD framework~(EODF). In an EODF, AVs extract the region of interests~(RoIs) of the captured image when the channel quality is not sufficiently good for supporting real-time OD. Then, AVs compress the image data on the basis of the RoIs and transmit the compressed one to the edge cloud. In so doing, real-time OD can be achieved owing to the reduced transmission latency. To verify the feasibility of our framework, we evaluate the probability that the results of OD are not received within the inter-frame duration (i.e., outage probability) and their accuracy. From the evaluation, we demonstrate that the proposed EODF provides the results to AVs in real-time and achieves satisfactory accuracy.
AutoDropout: Learning Dropout Patterns to Regularize Deep Networks
Jan 05, 2021

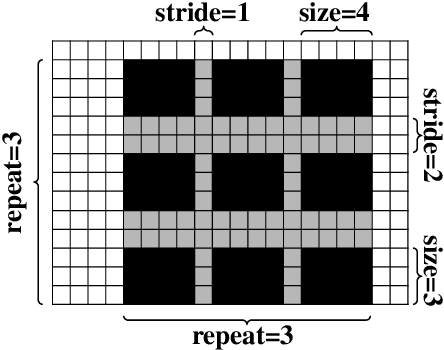
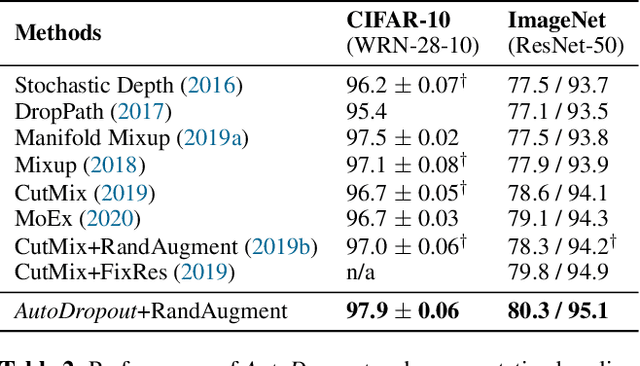
Neural networks are often over-parameterized and hence benefit from aggressive regularization. Conventional regularization methods, such as Dropout or weight decay, do not leverage the structures of the network's inputs and hidden states. As a result, these conventional methods are less effective than methods that leverage the structures, such as SpatialDropout and DropBlock, which randomly drop the values at certain contiguous areas in the hidden states and setting them to zero. Although the locations of dropout areas random, the patterns of SpatialDropout and DropBlock are manually designed and fixed. Here we propose to learn the dropout patterns. In our method, a controller learns to generate a dropout pattern at every channel and layer of a target network, such as a ConvNet or a Transformer. The target network is then trained with the dropout pattern, and its resulting validation performance is used as a signal for the controller to learn from. We show that this method works well for both image recognition on CIFAR-10 and ImageNet, as well as language modeling on Penn Treebank and WikiText-2. The learned dropout patterns also transfers to different tasks and datasets, such as from language model on Penn Treebank to Engligh-French translation on WMT 2014. Our code will be available.