 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Classification of Fracture and Normal Shoulder Bone X-Ray Images Using Ensemble and Transfer Learning With Deep Learning Models Based on Convolutional Neural Networks
Jan 31, 2021
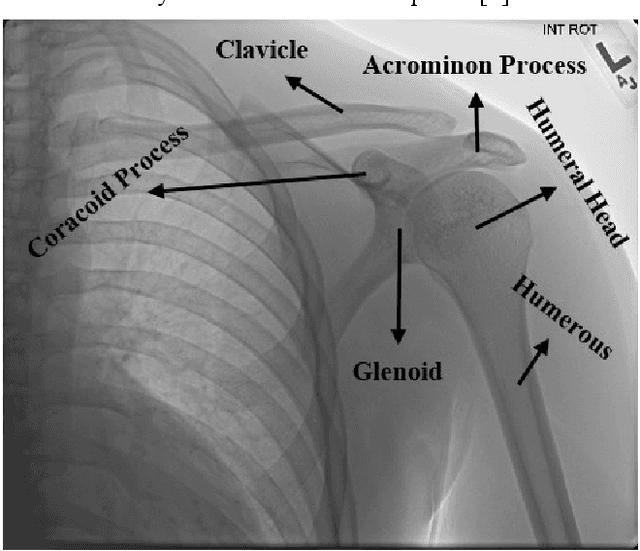
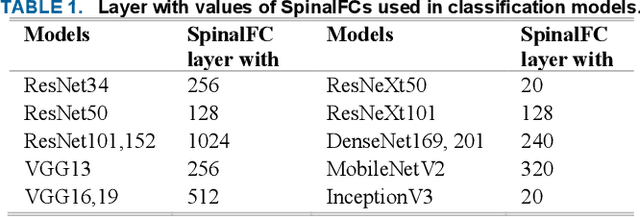
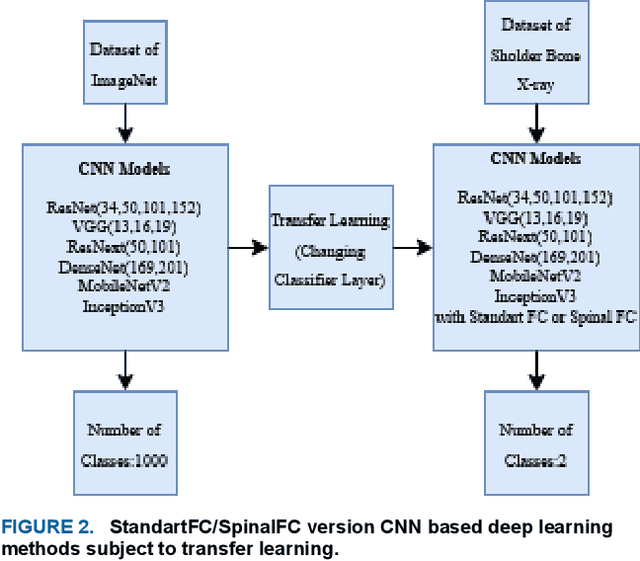
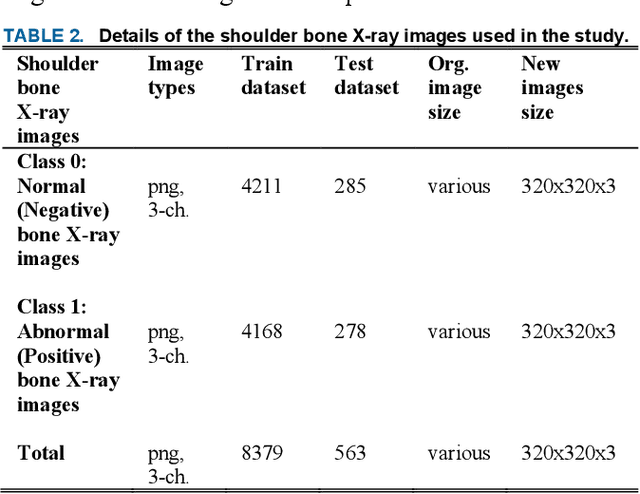
Various reasons cause shoulder fractures to occur, an area with wider and more varied range of movement than other joints in body. Firstly, images in digital imaging and communications in medicine (DICOM) format are generated for shoulder via Xradiation (Xray), magnetic resonance imaging (MRI) or computed tomography (CT) devices to diagnose and treat such fractures. Shoulder bone Xray images were classified and compared via deep learning models based on convolutional neural network (CNN) using transfer learning and ensemble learning in this study to help physicians diagnose and apply required treatment for shoulder fractures. There are a total of 8379, 4211 normal (negative, nonfracture) and 4168 abnormal (positive, fracture) 3 channel shoulder bone Xray images with png format for train data set, and a total of 563, 285 normal and 278 abnormal 3 channel shoulder bone Xray images with png format for validation and test data in classification conducted using all shoulder images in musculoskeletal radiographs (MURA) dataset, one of the largest public radiographic image datasets. CNN based built deep learning models herein are; ResNet, ResNeXt, DenseNet, VGG, Inception and MobileNet. Moreover, a classification was also performed by Spinal fully connected (Spinal FC) adaptations of all models. Transfer learning was applied for all these classification procedures. Two different ensemble learning (EL) models were established based on performance of classification results obtained herein. The highest Cohens Kappa score of 0.6942 and highest classification test accuracy of 84.72% were achieved in EL2 model, and the highest AUC score of 0.8862 in EL1.
Towards a Computed-Aided Diagnosis System in Colonoscopy: Automatic Polyp Segmentation Using Convolution Neural Networks
Jan 15, 2021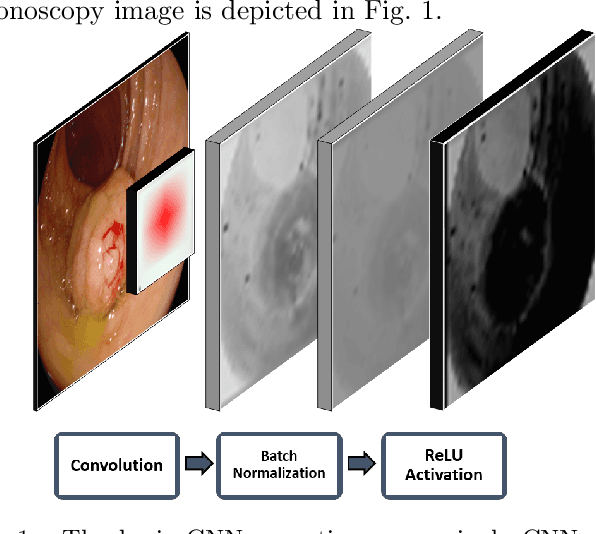
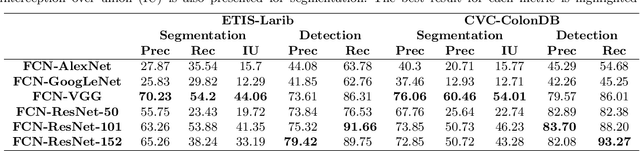
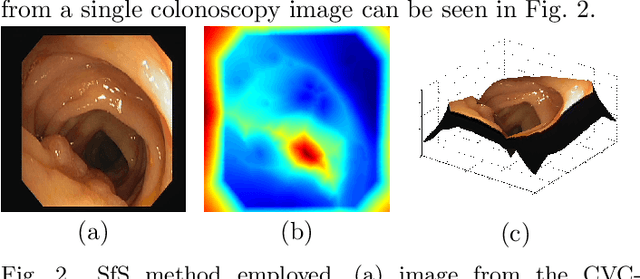

Early diagnosis is essential for the successful treatment of bowel cancers including colorectal cancer (CRC) and capsule endoscopic imaging with robotic actuation can be a valuable diagnostic tool when combined with automated image analysis. We present a deep learning rooted detection and segmentation framework for recognizing lesions in colonoscopy and capsule endoscopy images. We restructure established convolution architectures, such as VGG and ResNets, by converting them into fully-connected convolution networks (FCNs), fine-tune them and study their capabilities for polyp segmentation and detection. We additionally use Shape from-Shading (SfS) to recover depth and provide a richer representation of the tissue's structure in colonoscopy images. Depth is incorporated into our network models as an additional input channel to the RGB information and we demonstrate that the resulting network yields improved performance. Our networks are tested on publicly available datasets and the most accurate segmentation model achieved a mean segmentation IU of 47.78% and 56.95% on the ETIS-Larib and CVC-Colon datasets, respectively. For polyp detection, the top performing models we propose surpass the current state of the art with detection recalls superior to 90% for all datasets tested. To our knowledge, we present the first work to use FCNs for polyp segmentation in addition to proposing a novel combination of SfS and RGB that boosts performance
* 10 pages, 6 figures
Revisiting Stereo Depth Estimation From a Sequence-to-Sequence Perspective with Transformers
Nov 06, 2020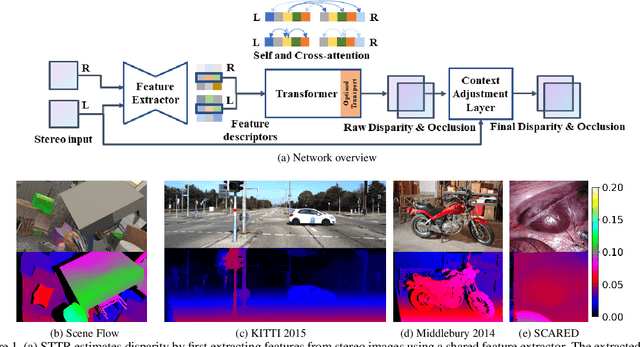
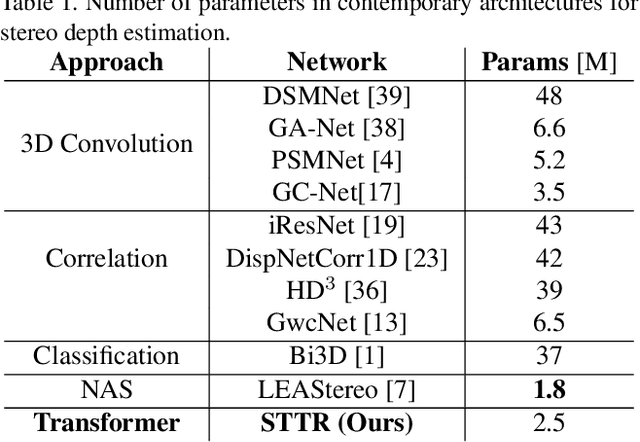
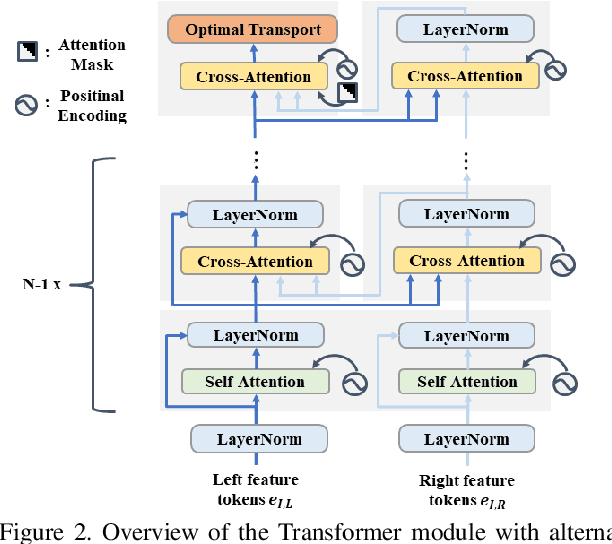
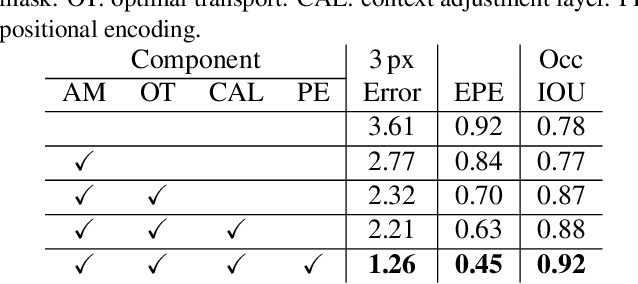
Stereo depth estimation relies on optimal correspondence matching between pixels on epipolar lines in the left and right image to infer depth. Rather than matching individual pixels, in this work, we revisit the problem from a sequence-to-sequence correspondence perspective to replace cost volume construction with dense pixel matching using position information and attention. This approach, named STereo TRansformer (STTR), has several advantages: It 1) relaxes the limitation of a fixed disparity range, 2) identifies occluded regions and provides confidence of estimation, and 3) imposes uniqueness constraints during the matching process. We report promising results on both synthetic and real-world datasets and demonstrate that STTR generalizes well across different domains, even without fine-tuning. Our code is publicly available at https://github.com/mli0603/stereo-transformer.
Optical Wavelength Guided Self-Supervised Feature Learning For Galaxy Cluster Richness Estimate
Dec 04, 2020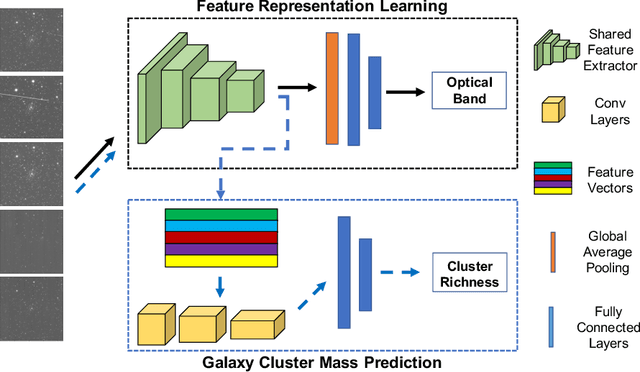
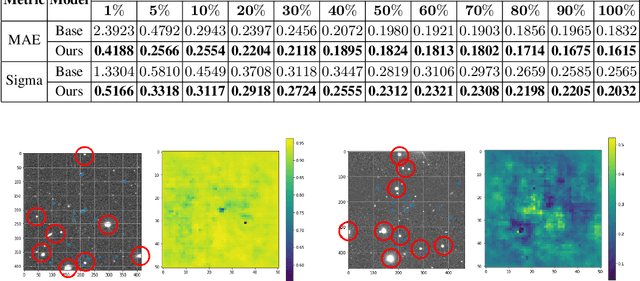
Most galaxies in the nearby Universe are gravitationally bound to a cluster or group of galaxies. Their optical contents, such as optical richness, are crucial for understanding the co-evolution of galaxies and large-scale structures in modern astronomy and cosmology. The determination of optical richness can be challenging. We propose a self-supervised approach for estimating optical richness from multi-band optical images. The method uses the data properties of the multi-band optical images for pre-training, which enables learning feature representations from a large but unlabeled dataset. We apply the proposed method to the Sloan Digital Sky Survey. The result shows our estimate of optical richness lowers the mean absolute error and intrinsic scatter by 11.84% and 20.78%, respectively, while reducing the need for labeled training data by up to 60%. We believe the proposed method will benefit astronomy and cosmology, where a large number of unlabeled multi-band images are available, but acquiring image labels is costly.
CNN Fixations: An unraveling approach to visualize the discriminative image regions
Aug 23, 2017
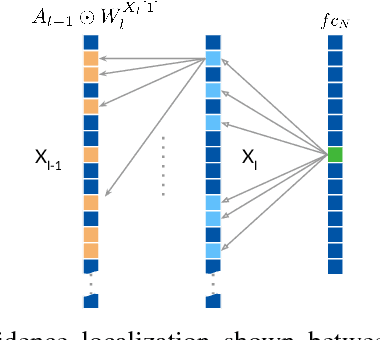
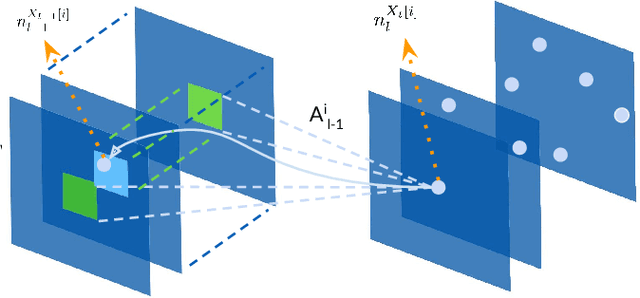
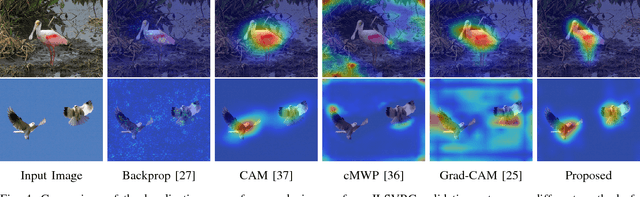
Deep convolutional neural networks (CNN) have revolutionized various fields of vision research and have seen unprecedented adoption for multiple tasks such as classification, detection, captioning, etc. However, they offer little transparency into their inner workings and are often treated as black boxes that deliver excellent performance. In this work, we aim at alleviating this opaqueness of CNNs by providing visual explanations for the network's predictions. Our approach can analyze variety of CNN based models trained for vision applications such as object recognition and caption generation. Unlike existing methods, we achieve this via unraveling the forward pass operation. Proposed method exploits feature dependencies across the layer hierarchy and uncovers the discriminative image locations that guide the network's predictions. We name these locations CNN-Fixations, loosely analogous to human eye fixations. Our approach is a generic method that requires no architectural changes, additional training or gradient computation and computes the important image locations (CNN Fixations). We demonstrate through a variety of applications that our approach is able to localize the discriminative image locations across different network architectures, diverse vision tasks and data modalities.
Leveraging SLIC Superpixel Segmentation and Cascaded Ensemble SVM for Fully Automated Mass Detection In Mammograms
Oct 20, 2020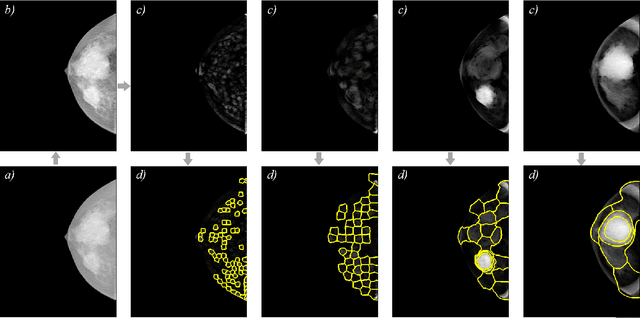

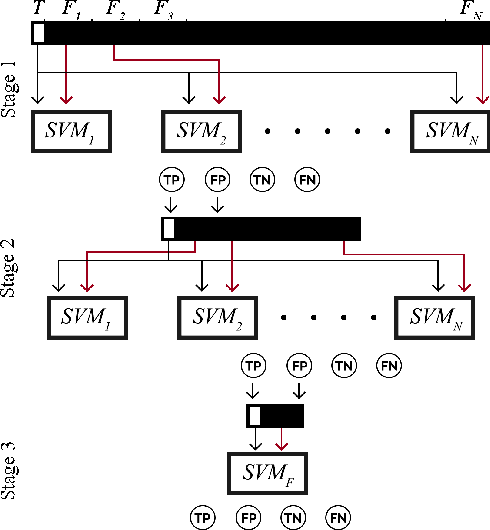
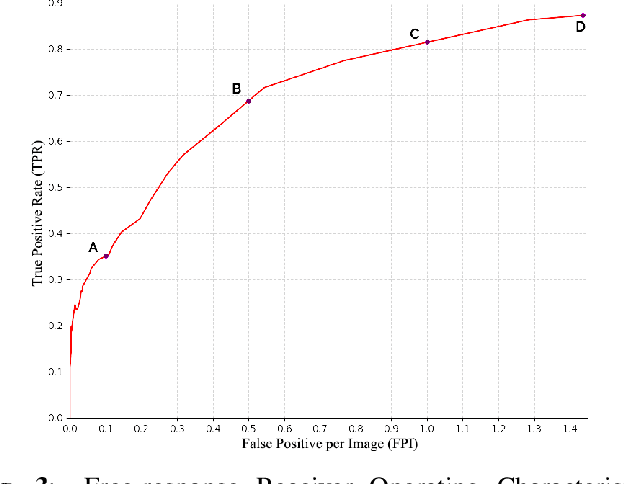
Identification and segmentation of breast masses in mammograms face complex challenges, owing to the highly variable nature of malignant densities with regards to their shape, contours, texture and orientation. Additionally, classifiers typically suffer from high class imbalance in region candidates, where normal tissue regions vastly outnumber malignant masses. This paper proposes a rigorous segmentation method, supported by morphological enhancement using grayscale linear filters. A novel cascaded ensemble of support vector machines (SVM) is used to effectively tackle the class imbalance and provide significant predictions. For True Positive Rate (TPR) of 0.35, 0.69 and 0.82, the system generates only 0.1, 0.5 and 1.0 False Positives/Image (FPI), respectively.
Positive-Congruent Training: Towards Regression-Free Model Updates
Nov 20, 2020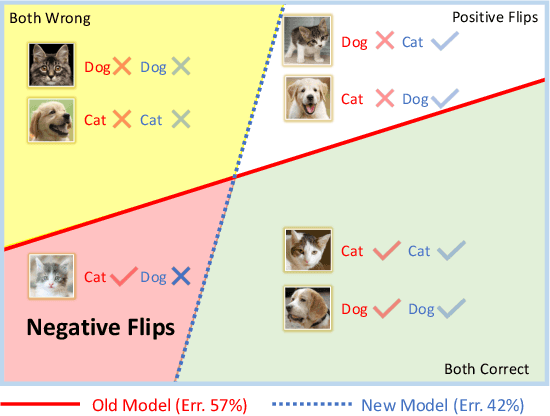
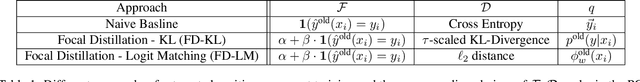
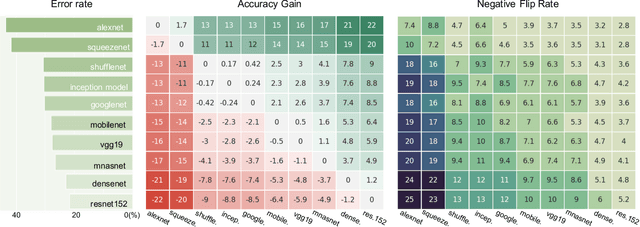
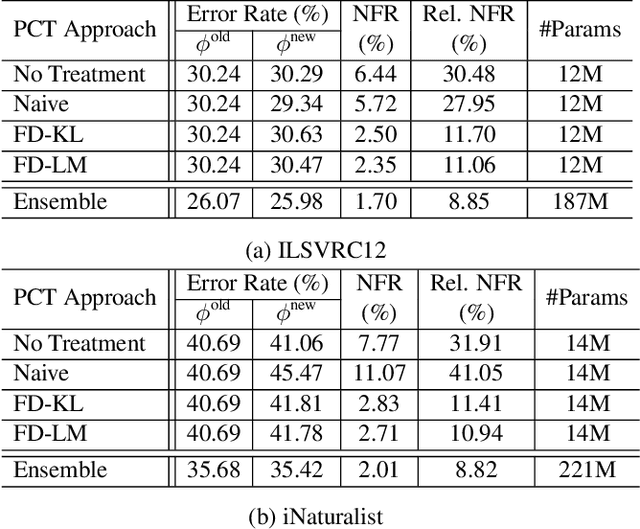
Reducing inconsistencies in the behavior of different versions of an AI system can be as important in practice as reducing its overall error. In image classification, sample-wise inconsistencies appear as "negative flips:" A new model incorrectly predicts the output for a test sample that was correctly classified by the old (reference) model. Positive-congruent (PC) training aims at reducing error rate while at the same time reducing negative flips, thus maximizing congruency with the reference model only on positive predictions, unlike model distillation. We propose a simple approach for PC training, Focal Distillation, which enforces congruence with the reference model by giving more weights to samples that were correctly classified. We also found that, if the reference model itself can be chosen as an ensemble of multiple deep neural networks, negative flips can be further reduced without affecting the new model's accuracy.
Recovering the Imperfect: Cell Segmentation in the Presence of Dynamically Localized Proteins
Nov 20, 2020
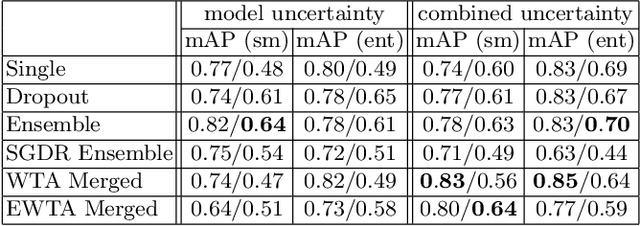
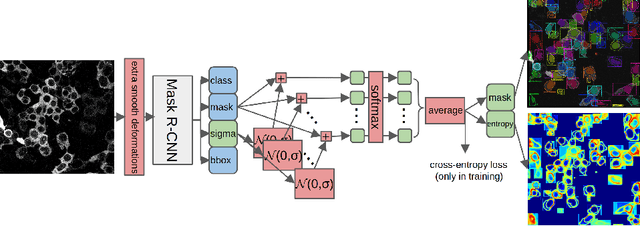
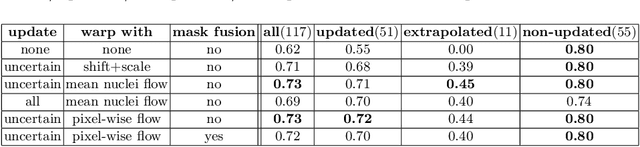
Deploying off-the-shelf segmentation networks on biomedical data has become common practice, yet if structures of interest in an image sequence are visible only temporarily, existing frame-by-frame methods fail. In this paper, we provide a solution to segmentation of imperfect data through time based on temporal propagation and uncertainty estimation. We integrate uncertainty estimation into Mask R-CNN network and propagate motion-corrected segmentation masks from frames with low uncertainty to those frames with high uncertainty to handle temporary loss of signal for segmentation. We demonstrate the value of this approach over frame-by-frame segmentation and regular temporal propagation on data from human embryonic kidney (HEK293T) cells transiently transfected with a fluorescent protein that moves in and out of the nucleus over time. The method presented here will empower microscopic experiments aimed at understanding molecular and cellular function.
Image Captioning and Visual Question Answering Based on Attributes and External Knowledge
Dec 16, 2016
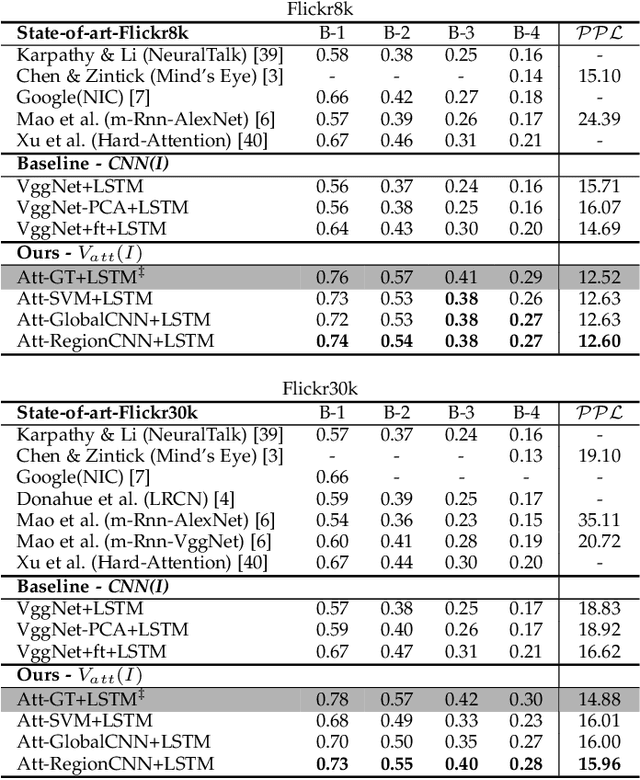
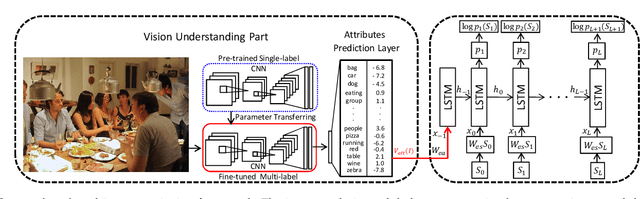
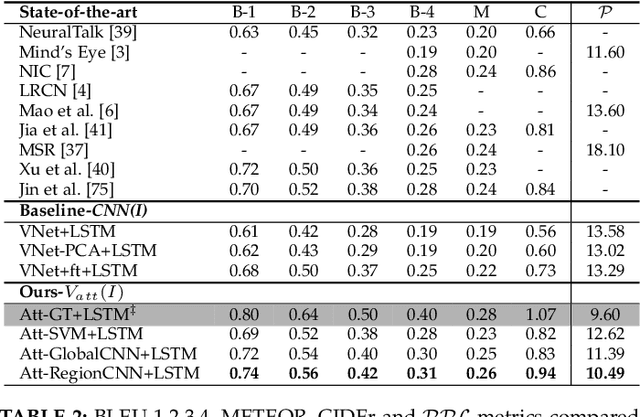
Much recent progress in Vision-to-Language problems has been achieved through a combination of Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs). This approach does not explicitly represent high-level semantic concepts, but rather seeks to progress directly from image features to text. In this paper we first propose a method of incorporating high-level concepts into the successful CNN-RNN approach, and show that it achieves a significant improvement on the state-of-the-art in both image captioning and visual question answering. We further show that the same mechanism can be used to incorporate external knowledge, which is critically important for answering high level visual questions. Specifically, we design a visual question answering model that combines an internal representation of the content of an image with information extracted from a general knowledge base to answer a broad range of image-based questions. It particularly allows questions to be asked about the contents of an image, even when the image itself does not contain a complete answer. Our final model achieves the best reported results on both image captioning and visual question answering on several benchmark datasets.
Context-Aware Refinement Network Incorporating Structural Connectivity Prior for Brain Midline Delineation
Jul 10, 2020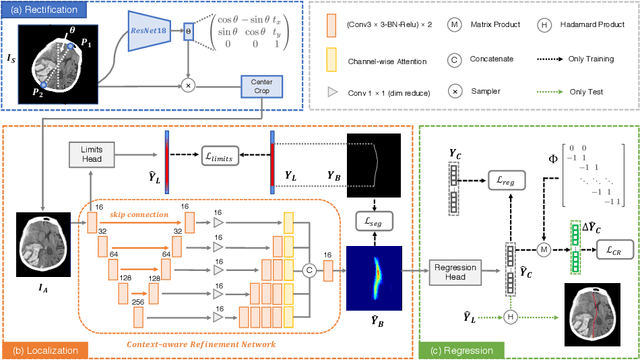
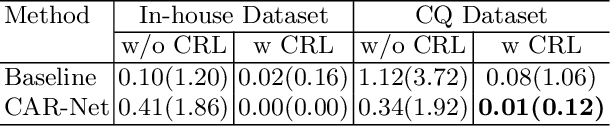
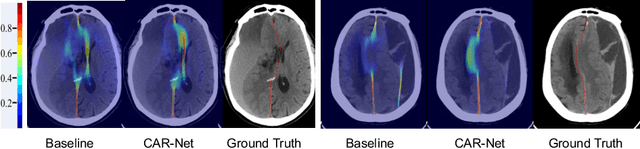
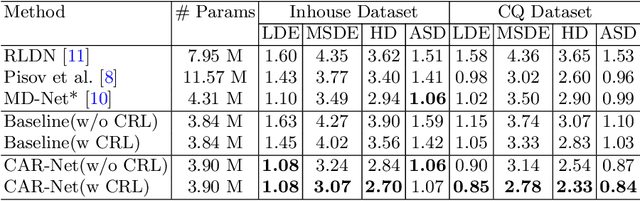
Brain midline delineation can facilitate the clinical evaluation of brain midline shift, which plays an important role in the diagnosis and prognosis of various brain pathology. Nevertheless, there are still great challenges with brain midline delineation, such as the largely deformed midline caused by the mass effect and the possible morphological failure that the predicted midline is not a connected curve. To address these challenges, we propose a context-aware refinement network (CAR-Net) to refine and integrate the feature pyramid representation generated by the UNet. Consequently, the proposed CAR-Net explores more discriminative contextual features and a larger receptive field, which is of great importance to predict largely deformed midline. For keeping the structural connectivity of the brain midline, we introduce a novel connectivity regular loss (CRL) to punish the disconnectivity between adjacent coordinates. Moreover, we address the ignored prerequisite of previous regression-based methods that the brain CT image must be in the standard pose. A simple pose rectification network is presented to align the source input image to the standard pose image. Extensive experimental results on the CQ dataset and one inhouse dataset show that the proposed method requires fewer parameters and outperforms three state-of-the-art methods in terms of four evaluation metrics. Code is available at https://github.com/ShawnBIT/Brain-Midline-Detection.