 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Hyperspherical embedding for novel class classification
Feb 05, 2021
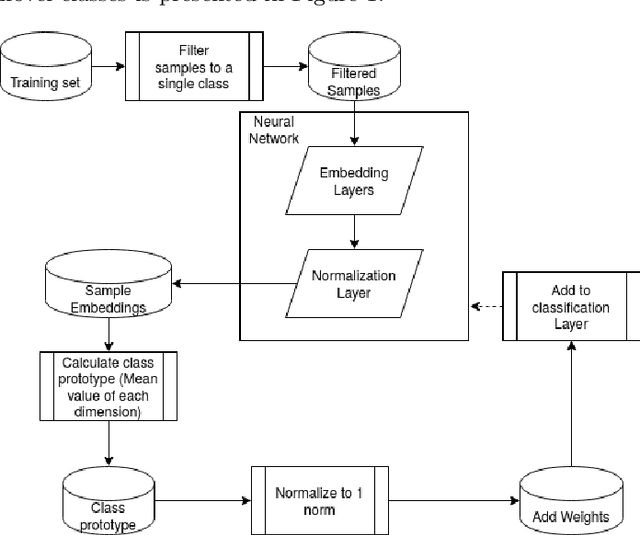
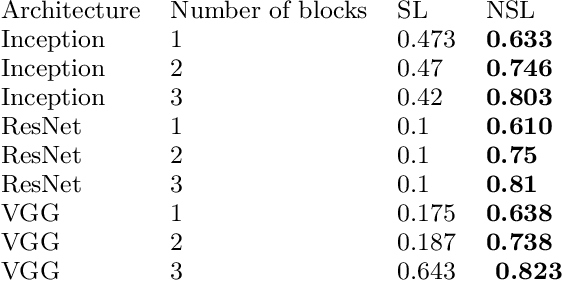
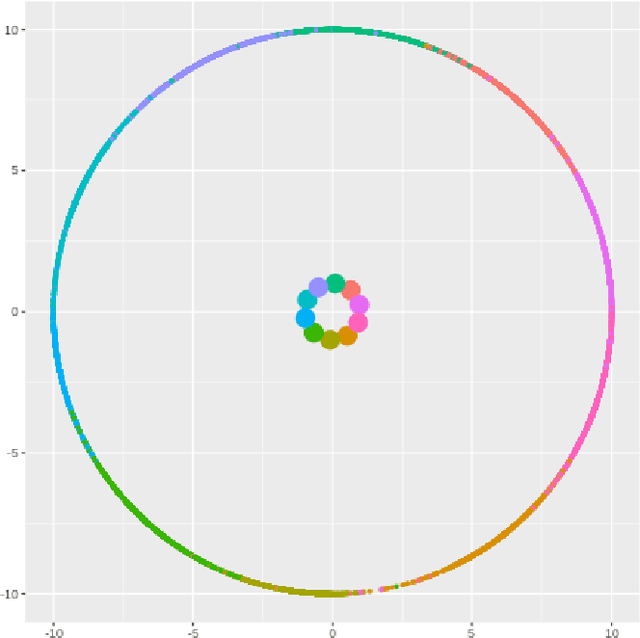
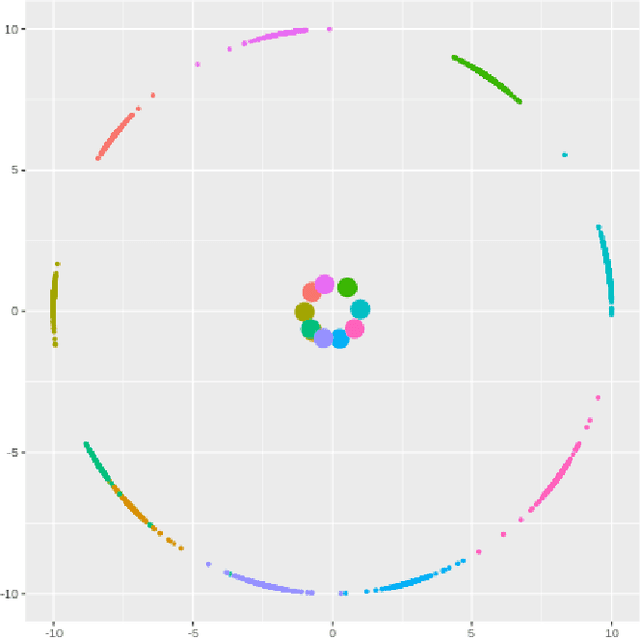
Deep learning models have become increasingly useful in many different industries. On the domain of image classification, convolutional neural networks proved the ability to learn robust features for the closed set problem, as shown in many different datasets, such as MNIST FASHIONMNIST, CIFAR10, CIFAR100, and IMAGENET. These approaches use deep neural networks with dense layers with softmax activation functions in order to learn features that can separate classes in a latent space. However, this traditional approach is not useful for identifying classes unseen on the training set, known as the open set problem. A similar problem occurs in scenarios involving learning on small data. To tackle both problems, few-shot learning has been proposed. In particular, metric learning learns features that obey constraints of a metric distance in the latent space in order to perform classification. However, while this approach proves to be useful for the open set problem, current implementation requires pair-wise training, where both positive and negative examples of similar images are presented during the training phase, which limits the applicability of these approaches in large data or large class scenarios given the combinatorial nature of the possible inputs.In this paper, we present a constraint-based approach applied to the representations in the latent space under the normalized softmax loss, proposed by[18]. We experimentally validate the proposed approach for the classification of unseen classes on different datasets using both metric learning and the normalized softmax loss, on disjoint and joint scenarios. Our results show that not only our proposed strategy can be efficiently trained on larger set of classes, as it does not require pairwise learning, but also present better classification results than the metric learning strategies surpassing its accuracy by a significant margin.
A Deep Learning Approach Based on Graphs to Detect Plantation Lines
Feb 05, 2021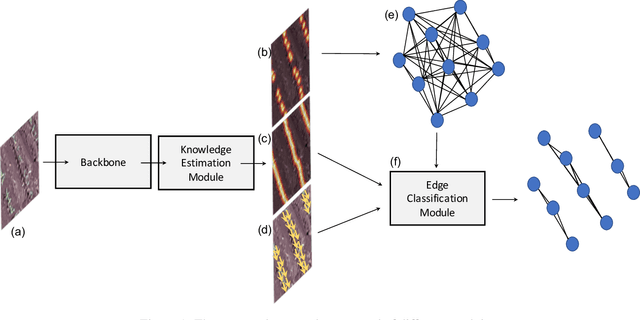
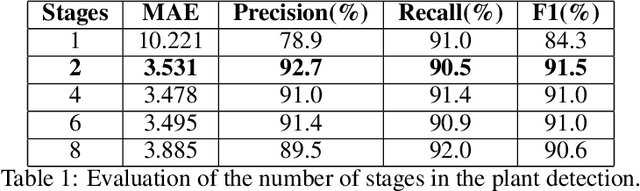
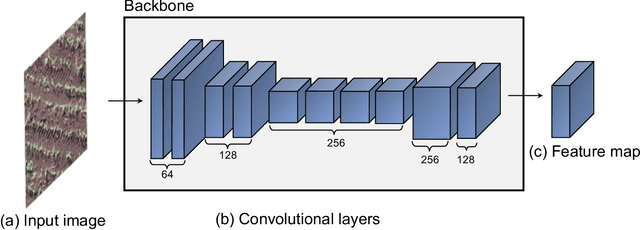
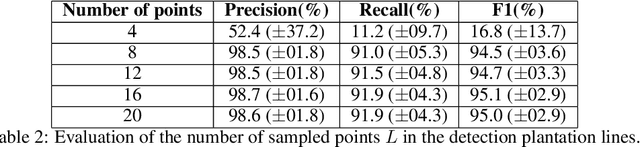
Deep learning-based networks are among the most prominent methods to learn linear patterns and extract this type of information from diverse imagery conditions. Here, we propose a deep learning approach based on graphs to detect plantation lines in UAV-based RGB imagery presenting a challenging scenario containing spaced plants. The first module of our method extracts a feature map throughout the backbone, which consists of the initial layers of the VGG16. This feature map is used as an input to the Knowledge Estimation Module (KEM), organized in three concatenated branches for detecting 1) the plant positions, 2) the plantation lines, and 3) for the displacement vectors between the plants. A graph modeling is applied considering each plant position on the image as vertices, and edges are formed between two vertices (i.e. plants). Finally, the edge is classified as pertaining to a certain plantation line based on three probabilities (higher than 0.5): i) in visual features obtained from the backbone; ii) a chance that the edge pixels belong to a line, from the KEM step; and iii) an alignment of the displacement vectors with the edge, also from KEM. Experiments were conducted in corn plantations with different growth stages and patterns with aerial RGB imagery. A total of 564 patches with 256 x 256 pixels were used and randomly divided into training, validation, and testing sets in a proportion of 60\%, 20\%, and 20\%, respectively. The proposed method was compared against state-of-the-art deep learning methods, and achieved superior performance with a significant margin, returning precision, recall, and F1-score of 98.7\%, 91.9\%, and 95.1\%, respectively. This approach is useful in extracting lines with spaced plantation patterns and could be implemented in scenarios where plantation gaps occur, generating lines with few-to-none interruptions.
Context-Aware Group Captioning via Self-Attention and Contrastive Features
Apr 07, 2020
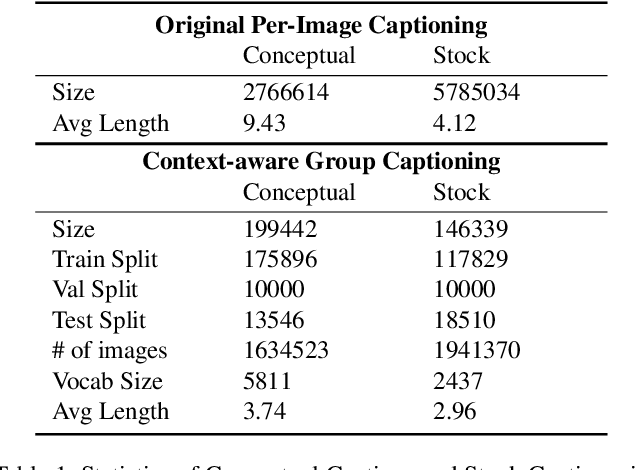
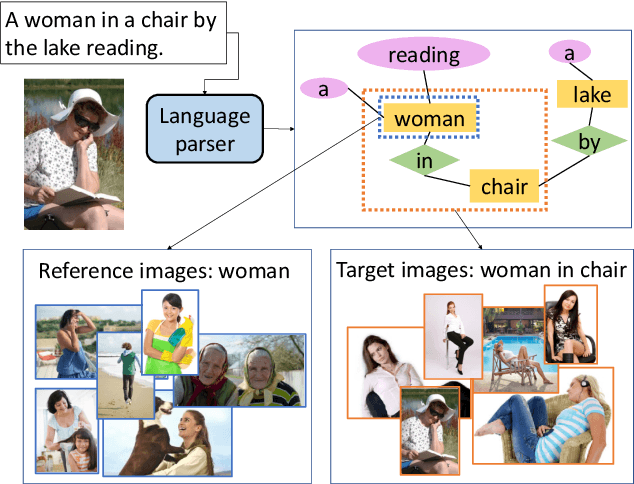
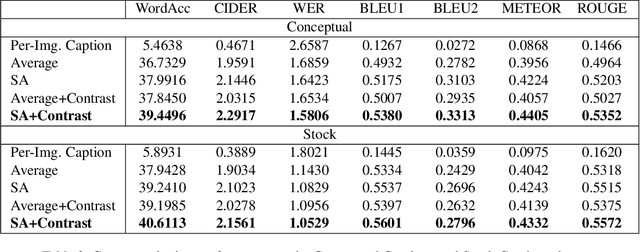
While image captioning has progressed rapidly, existing works focus mainly on describing single images. In this paper, we introduce a new task, context-aware group captioning, which aims to describe a group of target images in the context of another group of related reference images. Context-aware group captioning requires not only summarizing information from both the target and reference image group but also contrasting between them. To solve this problem, we propose a framework combining self-attention mechanism with contrastive feature construction to effectively summarize common information from each image group while capturing discriminative information between them. To build the dataset for this task, we propose to group the images and generate the group captions based on single image captions using scene graphs matching. Our datasets are constructed on top of the public Conceptual Captions dataset and our new Stock Captions dataset. Experiments on the two datasets show the effectiveness of our method on this new task. Related Datasets and code are released at https://lizw14.github.io/project/groupcap .
LIGHTEN: Learning Interactions with Graph and Hierarchical TEmporal Networks for HOI in videos
Dec 17, 2020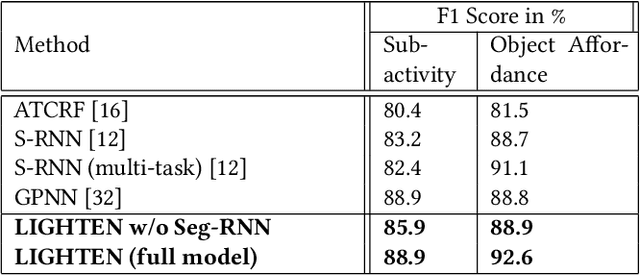
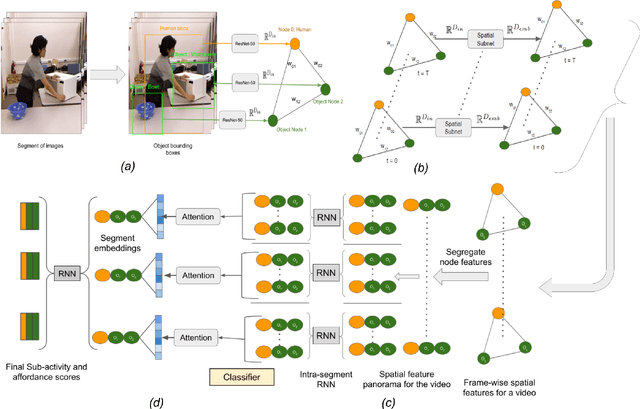

Analyzing the interactions between humans and objects from a video includes identification of the relationships between humans and the objects present in the video. It can be thought of as a specialized version of Visual Relationship Detection, wherein one of the objects must be a human. While traditional methods formulate the problem as inference on a sequence of video segments, we present a hierarchical approach, LIGHTEN, to learn visual features to effectively capture spatio-temporal cues at multiple granularities in a video. Unlike current approaches, LIGHTEN avoids using ground truth data like depth maps or 3D human pose, thus increasing generalization across non-RGBD datasets as well. Furthermore, we achieve the same using only the visual features, instead of the commonly used hand-crafted spatial features. We achieve state-of-the-art results in human-object interaction detection (88.9% and 92.6%) and anticipation tasks of CAD-120 and competitive results on image based HOI detection in V-COCO dataset, setting a new benchmark for visual features based approaches. Code for LIGHTEN is available at https://github.com/praneeth11009/LIGHTEN-Learning-Interactions-with-Graphs-and-Hierarchical-TEmporal-Networks-for-HOI
* 9 pages, 6 figures, ACM Multimedia Conference 2020
Spatial Attention Improves Iterative 6D Object Pose Estimation
Jan 05, 2021
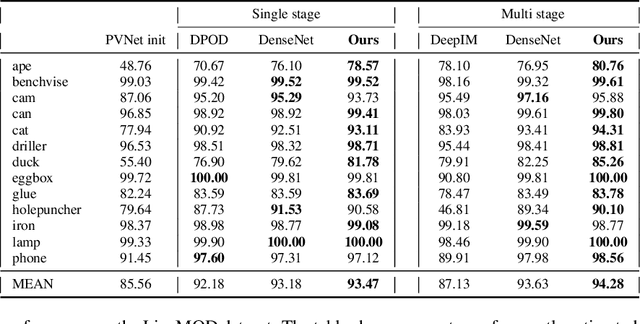
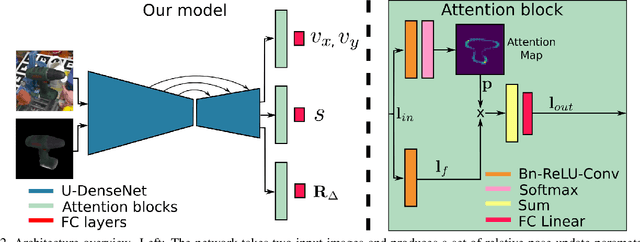
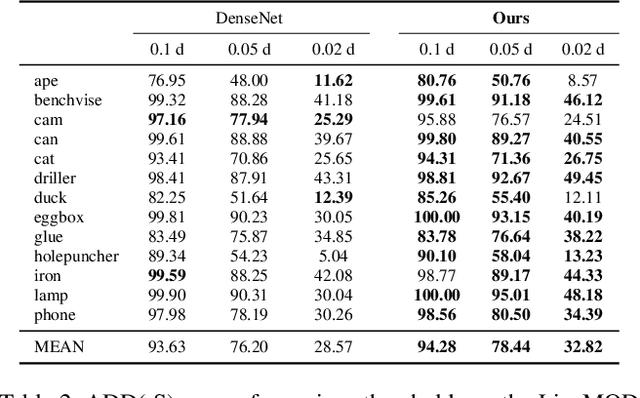
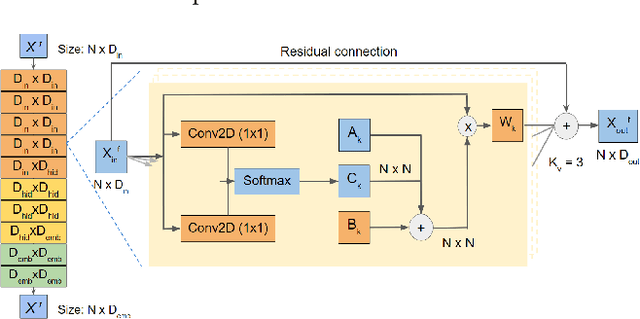
The task of estimating the 6D pose of an object from RGB images can be broken down into two main steps: an initial pose estimation step, followed by a refinement procedure to correctly register the object and its observation. In this paper, we propose a new method for 6D pose estimation refinement from RGB images. To achieve high accuracy of the final estimate, the observation and a rendered model need to be aligned. Our main insight is that after the initial pose estimate, it is important to pay attention to distinct spatial features of the object in order to improve the estimation accuracy during alignment. Furthermore, parts of the object that are occluded in the image should be given less weight during the alignment process. Most state-of-the-art refinement approaches do not allow for this fine-grained reasoning and can not fully leverage the structure of the problem. In contrast, we propose a novel neural network architecture built around a spatial attention mechanism that identifies and leverages information about spatial details during pose refinement. We experimentally show that this approach learns to attend to salient spatial features and learns to ignore occluded parts of the object, leading to better pose estimation across datasets. We conduct experiments on standard benchmark datasets for 6D pose estimation (LineMOD and Occlusion LineMOD) and outperform previous state-of-the-art methods.
In Defense of Classical Image Processing: Fast Depth Completion on the CPU
Jan 31, 2018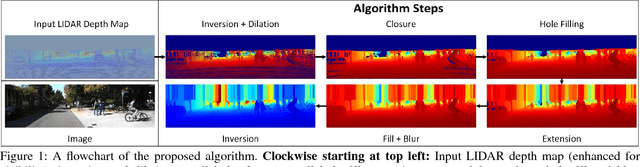
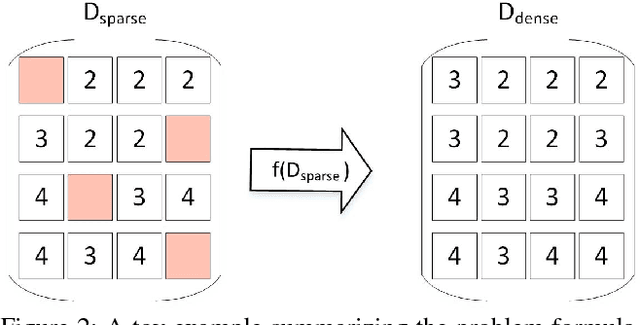
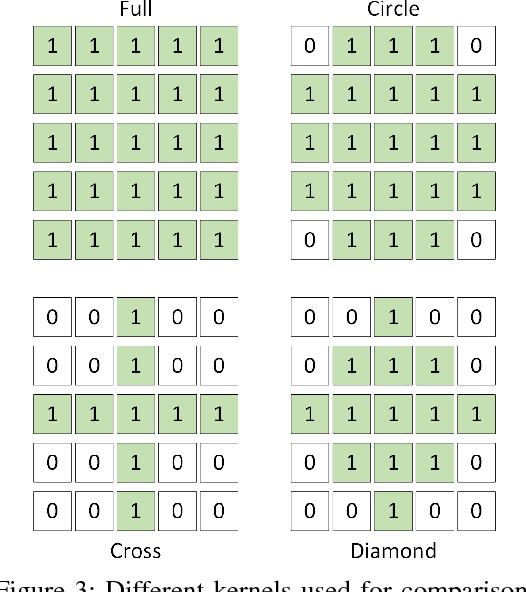
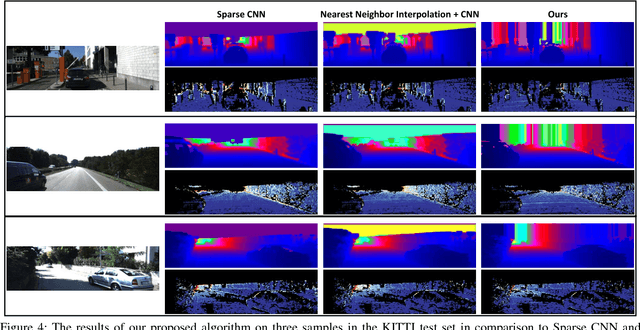
With the rise of data driven deep neural networks as a realization of universal function approximators, most research on computer vision problems has moved away from hand crafted classical image processing algorithms. This paper shows that with a well designed algorithm, we are capable of outperforming neural network based methods on the task of depth completion. The proposed algorithm is simple and fast, runs on the CPU, and relies only on basic image processing operations to perform depth completion of sparse LIDAR depth data. We evaluate our algorithm on the challenging KITTI depth completion benchmark, and at the time of submission, our method ranks first on the KITTI test server among all published methods. Furthermore, our algorithm is data independent, requiring no training data to perform the task at hand. The code written in Python will be made publicly available at https://github.com/kujason/ip_basic.
Personal Privacy Protection via Irrelevant Faces Tracking and Pixelation in Video Live Streaming
Jan 05, 2021
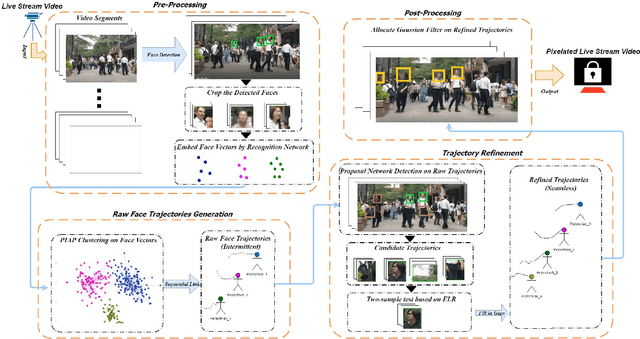
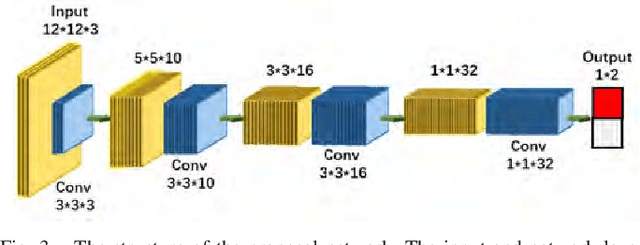
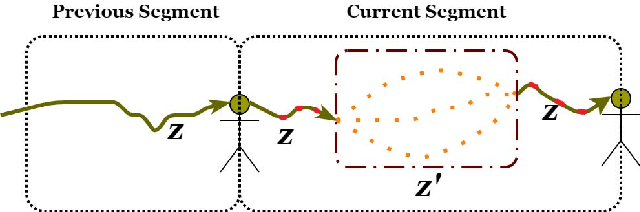
To date, the privacy-protection intended pixelation tasks are still labor-intensive and yet to be studied. With the prevailing of video live streaming, establishing an online face pixelation mechanism during streaming is an urgency. In this paper, we develop a new method called Face Pixelation in Video Live Streaming (FPVLS) to generate automatic personal privacy filtering during unconstrained streaming activities. Simply applying multi-face trackers will encounter problems in target drifting, computing efficiency, and over-pixelation. Therefore, for fast and accurate pixelation of irrelevant people's faces, FPVLS is organized in a frame-to-video structure of two core stages. On individual frames, FPVLS utilizes image-based face detection and embedding networks to yield face vectors. In the raw trajectories generation stage, the proposed Positioned Incremental Affinity Propagation (PIAP) clustering algorithm leverages face vectors and positioned information to quickly associate the same person's faces across frames. Such frame-wise accumulated raw trajectories are likely to be intermittent and unreliable on video level. Hence, we further introduce the trajectory refinement stage that merges a proposal network with the two-sample test based on the Empirical Likelihood Ratio (ELR) statistic to refine the raw trajectories. A Gaussian filter is laid on the refined trajectories for final pixelation. On the video live streaming dataset we collected, FPVLS obtains satisfying accuracy, real-time efficiency, and contains the over-pixelation problems.
ssEMnet: Serial-section Electron Microscopy Image Registration using a Spatial Transformer Network with Learned Features
Dec 05, 2017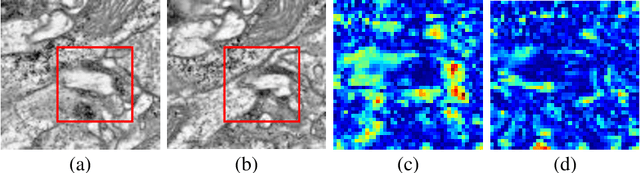
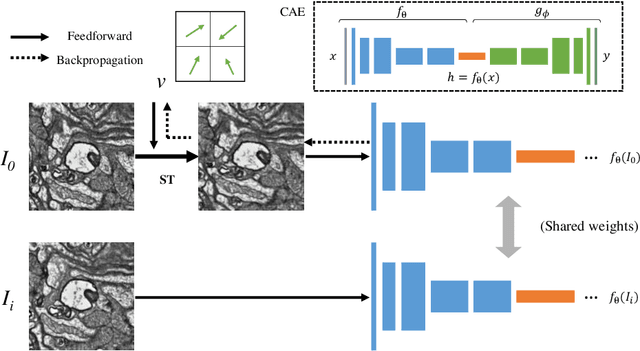

The alignment of serial-section electron microscopy (ssEM) images is critical for efforts in neuroscience that seek to reconstruct neuronal circuits. However, each ssEM plane contains densely packed structures that vary from one section to the next, which makes matching features across images a challenge. Advances in deep learning has resulted in unprecedented performance in similar computer vision problems, but to our knowledge, they have not been successfully applied to ssEM image co-registration. In this paper, we introduce a novel deep network model that combines a spatial transformer for image deformation and a convolutional autoencoder for unsupervised feature learning for robust ssEM image alignment. This results in improved accuracy and robustness while requiring substantially less user intervention than conventional methods. We evaluate our method by comparing registration quality across several datasets.
XCAT-GAN for Synthesizing 3D Consistent Labeled Cardiac MR Images on Anatomically Variable XCAT Phantoms
Jul 27, 2020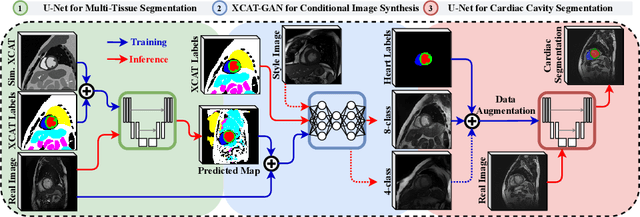
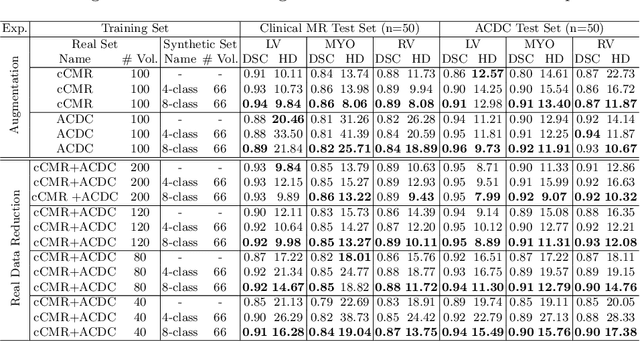
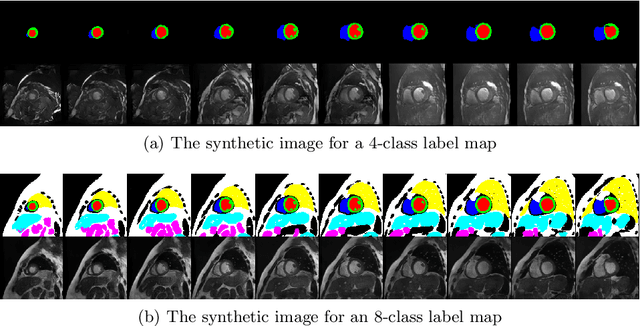
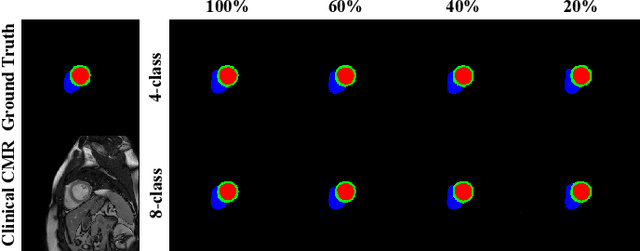
Generative adversarial networks (GANs) have provided promising data enrichment solutions by synthesizing high-fidelity images. However, generating large sets of labeled images with new anatomical variations remains unexplored. We propose a novel method for synthesizing cardiac magnetic resonance (CMR) images on a population of virtual subjects with a large anatomical variation, introduced using the 4D eXtended Cardiac and Torso (XCAT) computerized human phantom. We investigate two conditional image synthesis approaches grounded on a semantically-consistent mask-guided image generation technique: 4-class and 8-class XCAT-GANs. The 4-class technique relies on only the annotations of the heart; while the 8-class technique employs a predicted multi-tissue label map of the heart-surrounding organs and provides better guidance for our conditional image synthesis. For both techniques, we train our conditional XCAT-GAN with real images paired with corresponding labels and subsequently at the inference time, we substitute the labels with the XCAT derived ones. Therefore, the trained network accurately transfers the tissue-specific textures to the new label maps. By creating 33 virtual subjects of synthetic CMR images at the end-diastolic and end-systolic phases, we evaluate the usefulness of such data in the downstream cardiac cavity segmentation task under different augmentation strategies. Results demonstrate that even with only 20% of real images (40 volumes) seen during training, segmentation performance is retained with the addition of synthetic CMR images. Moreover, the improvement in utilizing synthetic images for augmenting the real data is evident through the reduction of Hausdorff distance up to 28% and an increase in the Dice score up to 5%, indicating a higher similarity to the ground truth in all dimensions.
Shallow Feature Based Dense Attention Network for Crowd Counting
Jun 17, 2020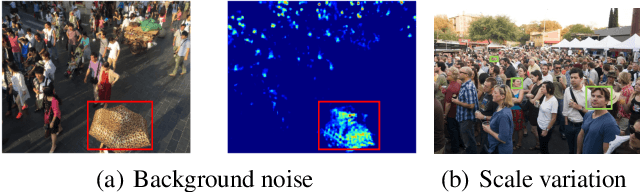
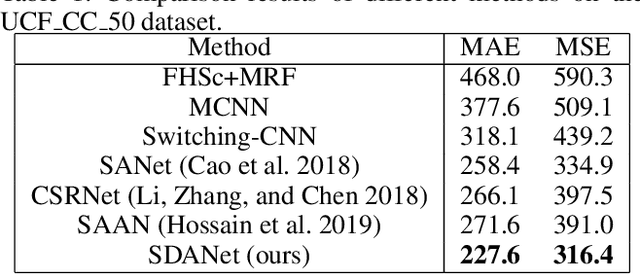
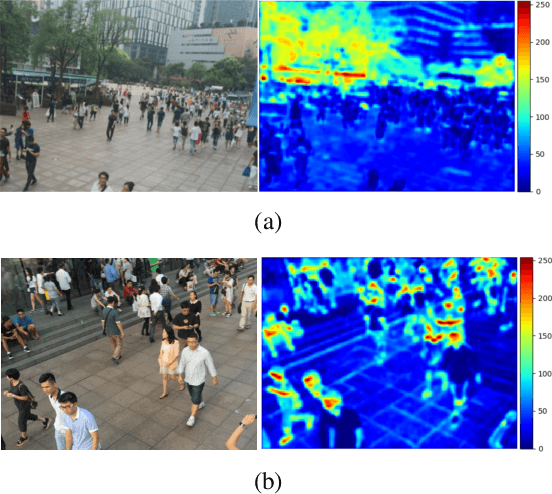
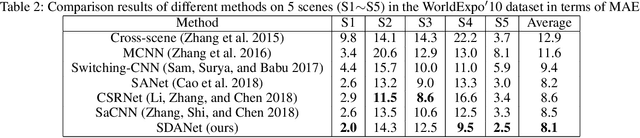
While the performance of crowd counting via deep learning has been improved dramatically in the recent years, it remains an ingrained problem due to cluttered backgrounds and varying scales of people within an image. In this paper, we propose a Shallow feature based Dense Attention Network (SDANet) for crowd counting from still images, which diminishes the impact of backgrounds via involving a shallow feature based attention model, and meanwhile, captures multi-scale information via densely connecting hierarchical image features. Specifically, inspired by the observation that backgrounds and human crowds generally have noticeably different responses in shallow features, we decide to build our attention model upon shallow-feature maps, which results in accurate background-pixel detection. Moreover, considering that the most representative features of people across different scales can appear in different layers of a feature extraction network, to better keep them all, we propose to densely connect hierarchical image features of different layers and subsequently encode them for estimating crowd density. Experimental results on three benchmark datasets clearly demonstrate the superiority of SDANet when dealing with different scenarios. Particularly, on the challenging UCF CC 50 dataset, our method outperforms other existing methods by a large margin, as is evident from a remarkable 11.9% Mean Absolute Error (MAE) drop of our SDANet.