 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Monocular Retinal Depth Estimation and Joint Optic Disc and Cup Segmentation using Adversarial Networks
Jul 15, 2020
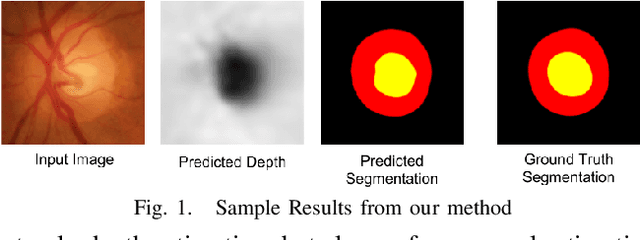
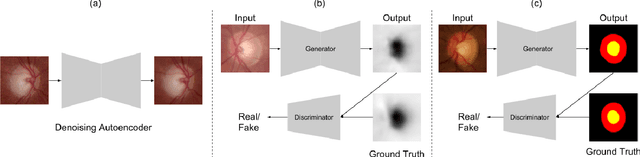
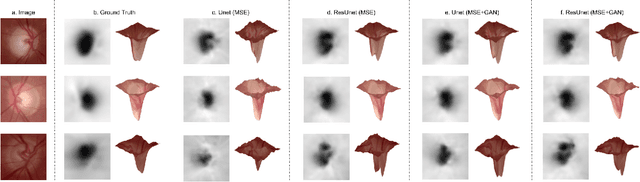

One of the important parameters for the assessment of glaucoma is optic nerve head (ONH) evaluation, which usually involves depth estimation and subsequent optic disc and cup boundary extraction. Depth is usually obtained explicitly from imaging modalities like optical coherence tomography (OCT) and is very challenging to estimate depth from a single RGB image. To this end, we propose a novel method using adversarial network to predict depth map from a single image. The proposed depth estimation technique is trained and evaluated using individual retinal images from INSPIRE-stereo dataset. We obtain a very high average correlation coefficient of 0.92 upon five fold cross validation outperforming the state of the art. We then use the depth estimation process as a proxy task for joint optic disc and cup segmentation.
Key-Nets: Optical Transformation Convolutional Networks for Privacy Preserving Vision Sensors
Sep 11, 2020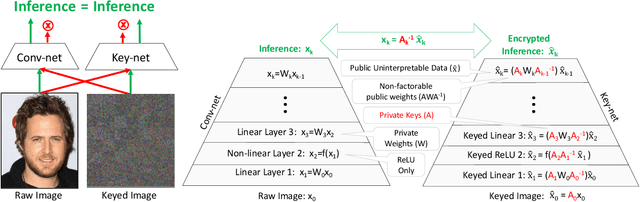
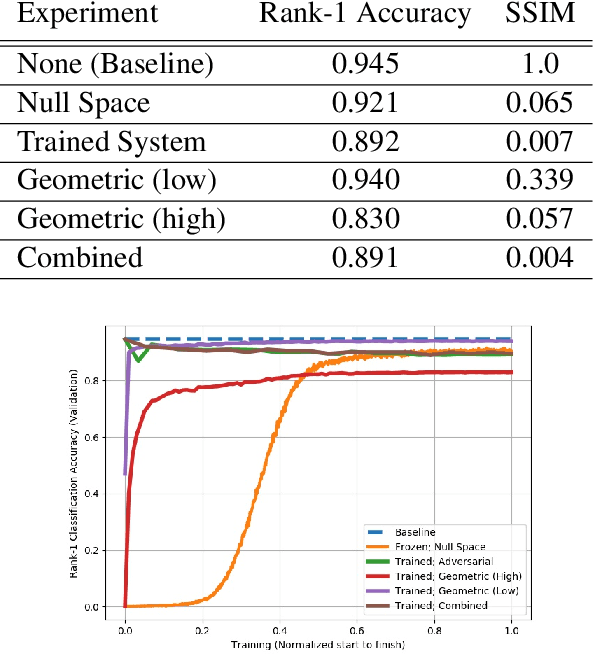

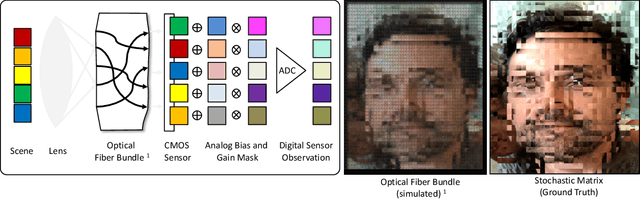
Modern cameras are not designed with computer vision or machine learning as the target application. There is a need for a new class of vision sensors that are privacy preserving by design, that do not leak private information and collect only the information necessary for a target machine learning task. In this paper, we introduce key-nets, which are convolutional networks paired with a custom vision sensor which applies an optical/analog transform such that the key-net can perform exact encrypted inference on this transformed image, but the image is not interpretable by a human or any other key-net. We provide five sufficient conditions for an optical transformation suitable for a key-net, and show that generalized stochastic matrices (e.g. scale, bias and fractional pixel shuffling) satisfy these conditions. We motivate the key-net by showing that without it there is a utility/privacy tradeoff for a network fine-tuned directly on optically transformed images for face identification and object detection. Finally, we show that a key-net is equivalent to homomorphic encryption using a Hill cipher, with an upper bound on memory and runtime that scales quadratically with a user specified privacy parameter. Therefore, the key-net is the first practical, efficient and privacy preserving vision sensor based on optical homomorphic encryption.
Category Level Object Pose Estimation via Neural Analysis-by-Synthesis
Aug 18, 2020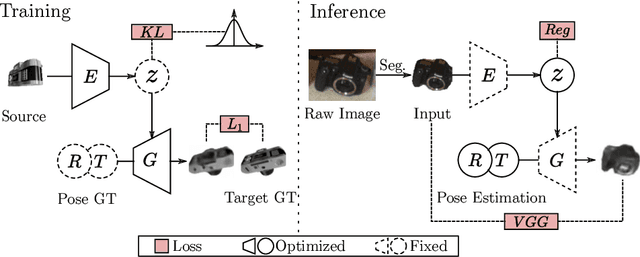

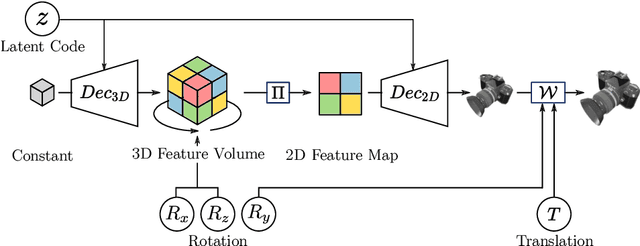
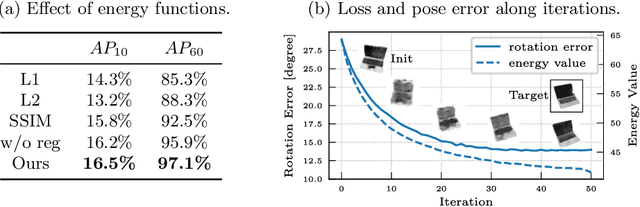
Many object pose estimation algorithms rely on the analysis-by-synthesis framework which requires explicit representations of individual object instances. In this paper we combine a gradient-based fitting procedure with a parametric neural image synthesis module that is capable of implicitly representing the appearance, shape and pose of entire object categories, thus rendering the need for explicit CAD models per object instance unnecessary. The image synthesis network is designed to efficiently span the pose configuration space so that model capacity can be used to capture the shape and local appearance (i.e., texture) variations jointly. At inference time the synthesized images are compared to the target via an appearance based loss and the error signal is backpropagated through the network to the input parameters. Keeping the network parameters fixed, this allows for iterative optimization of the object pose, shape and appearance in a joint manner and we experimentally show that the method can recover orientation of objects with high accuracy from 2D images alone. When provided with depth measurements, to overcome scale ambiguities, the method can accurately recover the full 6DOF pose successfully.
Extension of Full and Reduced Order Observers for Image-based Depth Estimation using Concurrent Learning
Aug 12, 2020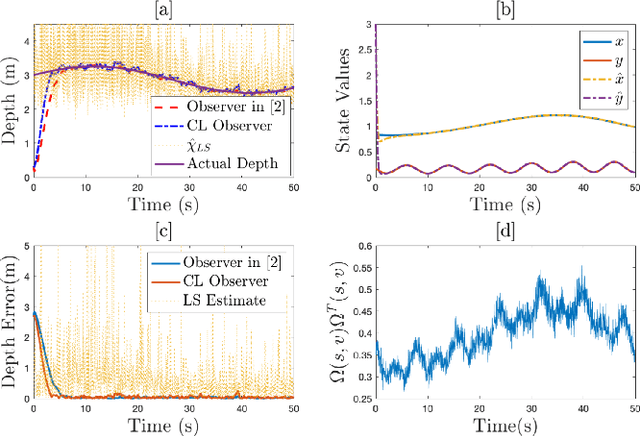
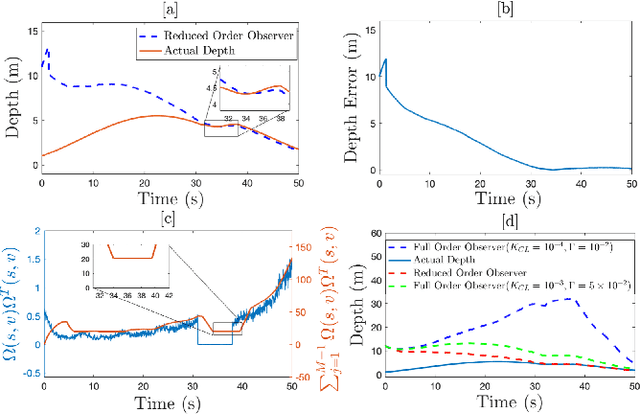
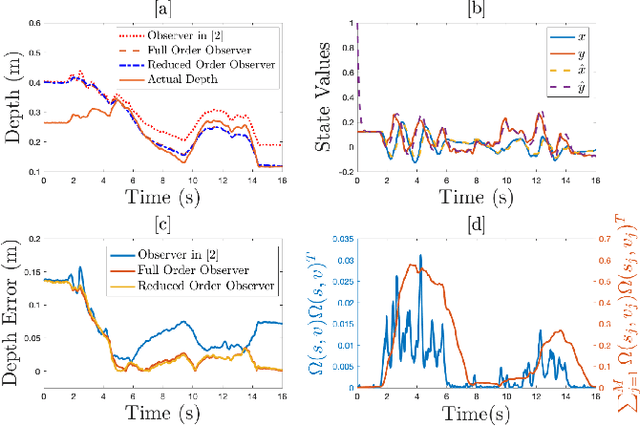
In this paper concurrent learning (CL)-based full and reduced order observers for a perspective dynamical system (PDS) are developed. The PDS is a widely used model for estimating the depth of a feature point from a sequence of camera images. Building on the current progress of CL for parameter estimation in adaptive control, a state observer is developed for the PDS model where the inverse depth appears as a time-varying parameter in the dynamics. The data recorded over a sliding time window in the near past is used in the CL term to design the full and the reduced order state observers. A Lyapunov-based stability analysis is carried out to prove the uniformly ultimately bounded (UUB) stability of the developed observers. Simulation results are presented to validate the accuracy and convergence of the developed observers in terms of convergence time, root mean square error (RMSE) and mean absolute percentage error (MAPE) metrics. Real world depth estimation experiments are performed to demonstrate the performance of the observers using aforementioned metrics on a 7-DoF manipulator with an eye-in-hand configuration.
InfoScrub: Towards Attribute Privacy by Targeted Obfuscation
May 20, 2020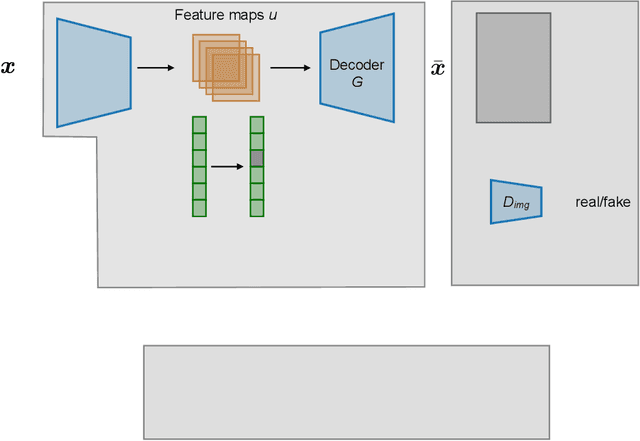

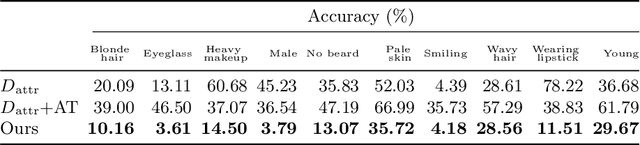
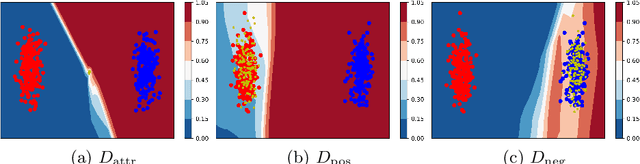
Personal photos of individuals when shared online, apart from exhibiting a myriad of memorable details, also reveals a wide range of private information and potentially entails privacy risks (e.g., online harassment, tracking). To mitigate such risks, it is crucial to study techniques that allow individuals to limit the private information leaked in visual data. We tackle this problem in a novel image obfuscation framework: to maximize entropy on inferences over targeted privacy attributes, while retaining image fidelity. We approach the problem based on an encoder-decoder style architecture, with two key novelties: (a) introducing a discriminator to perform bi-directional translation simultaneously from multiple unpaired domains; (b) predicting an image interpolation which maximizes uncertainty over a target set of attributes. We find our approach generates obfuscated images faithful to the original input images, and additionally increase uncertainty by 6.2$\times$ (or up to 0.85 bits) over the non-obfuscated counterparts.
Graph-Based Social Relation Reasoning
Jul 15, 2020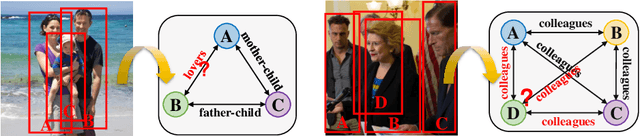
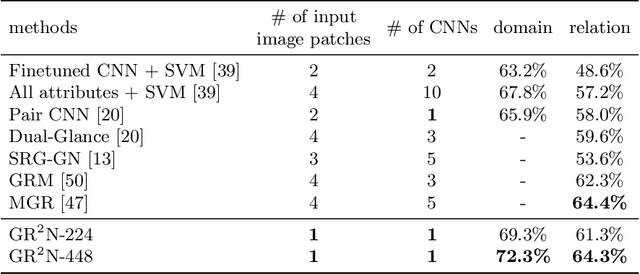
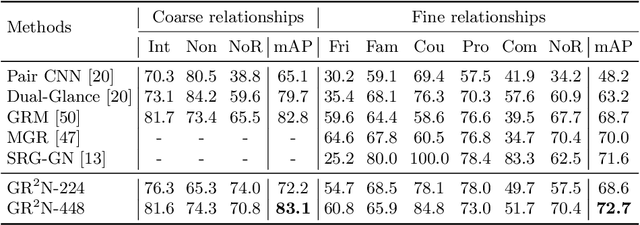
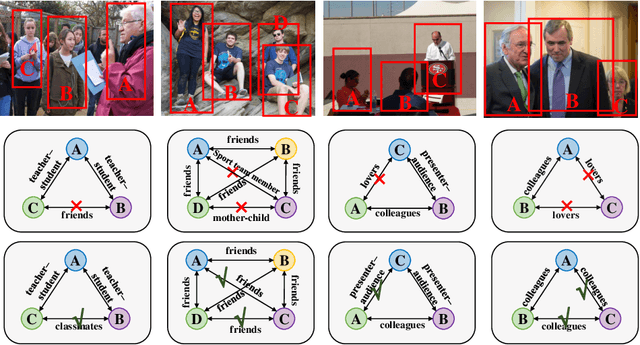
Human beings are fundamentally sociable -- that we generally organize our social lives in terms of relations with other people. Understanding social relations from an image has great potential for intelligent systems such as social chatbots and personal assistants. In this paper, we propose a simpler, faster, and more accurate method named graph relational reasoning network (GR2N) for social relation recognition. Different from existing methods which process all social relations on an image independently, our method considers the paradigm of jointly inferring the relations by constructing a social relation graph. Furthermore, the proposed GR2N constructs several virtual relation graphs to explicitly grasp the strong logical constraints among different types of social relations. Experimental results illustrate that our method generates a reasonable and consistent social relation graph and improves the performance in both accuracy and efficiency.
Computer Stereo Vision for Autonomous Driving
Dec 17, 2020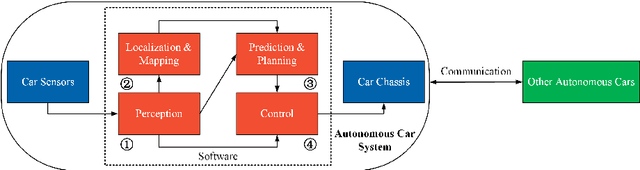
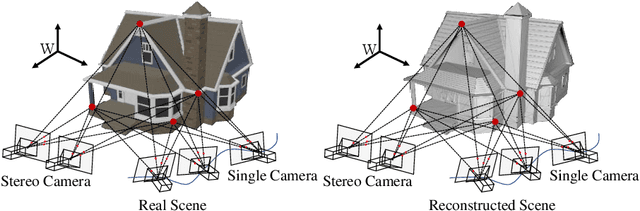

As an important component of autonomous systems, autonomous car perception has had a big leap with recent advances in parallel computing architectures. With the use of tiny but full-feature embedded supercomputers, computer stereo vision has been prevalently applied in autonomous cars for depth perception. The two key aspects of computer stereo vision are speed and accuracy. They are both desirable but conflicting properties, as the algorithms with better disparity accuracy usually have higher computational complexity. Therefore, the main aim of developing a computer stereo vision algorithm for resource-limited hardware is to improve the trade-off between speed and accuracy. In this chapter, we introduce both the hardware and software aspects of computer stereo vision for autonomous car systems. Then, we discuss four autonomous car perception tasks, including 1) visual feature detection, description and matching, 2) 3D information acquisition, 3) object detection/recognition and 4) semantic image segmentation. The principles of computer stereo vision and parallel computing on multi-threading CPU and GPU architectures are then detailed.
Image Generation and Recognition (Emotions)
Oct 13, 2019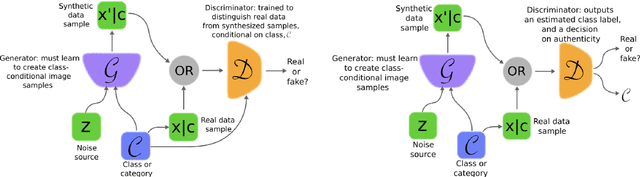

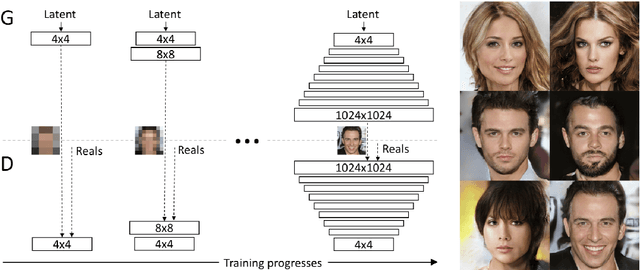
Generative Adversarial Networks (GANs) were proposed in 2014 by Goodfellow et al., and have since been extended into multiple computer vision applications. This report provides a thorough survey of recent GAN research, outlining the various architectures and applications, as well as methods for training GANs and dealing with latent space. This is followed by a discussion of potential areas for future GAN research, including: evaluating GANs, better understanding GANs, and techniques for training GANs. The second part of this report outlines the compilation of a dataset of images `in the wild' representing each of the 7 basic human emotions, and analyses experiments done when training a StarGAN on this dataset combined with the FER2013 dataset.
Deep Co-Attention Network for Multi-View Subspace Learning
Feb 15, 2021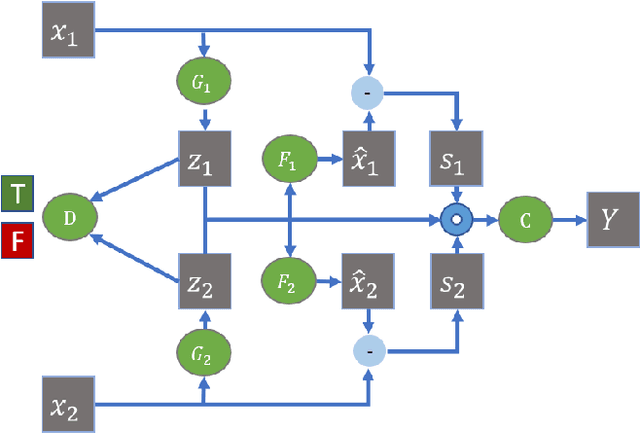
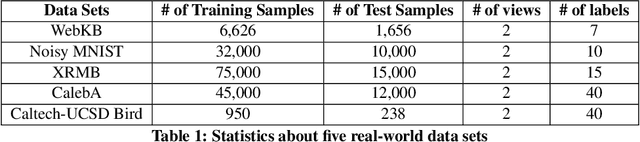
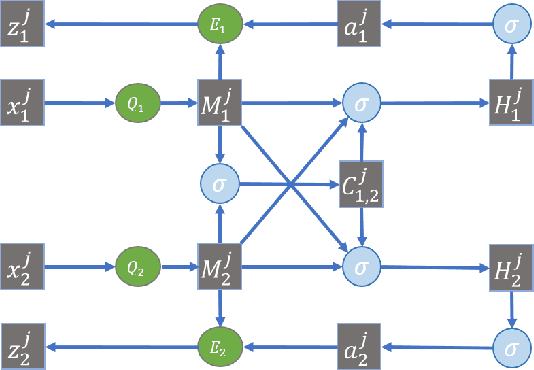
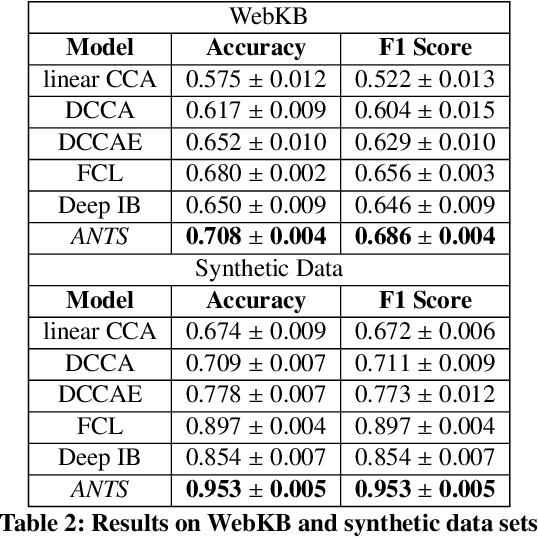
Many real-world applications involve data from multiple modalities and thus exhibit the view heterogeneity. For example, user modeling on social media might leverage both the topology of the underlying social network and the content of the users' posts; in the medical domain, multiple views could be X-ray images taken at different poses. To date, various techniques have been proposed to achieve promising results, such as canonical correlation analysis based methods, etc. In the meanwhile, it is critical for decision-makers to be able to understand the prediction results from these methods. For example, given the diagnostic result that a model provided based on the X-ray images of a patient at different poses, the doctor needs to know why the model made such a prediction. However, state-of-the-art techniques usually suffer from the inability to utilize the complementary information of each view and to explain the predictions in an interpretable manner. To address these issues, in this paper, we propose a deep co-attention network for multi-view subspace learning, which aims to extract both the common information and the complementary information in an adversarial setting and provide robust interpretations behind the prediction to the end-users via the co-attention mechanism. In particular, it uses a novel cross reconstruction loss and leverages the label information to guide the construction of the latent representation by incorporating the classifier into our model. This improves the quality of latent representation and accelerates the convergence speed. Finally, we develop an efficient iterative algorithm to find the optimal encoders and discriminator, which are evaluated extensively on synthetic and real-world data sets. We also conduct a case study to demonstrate how the proposed method robustly interprets the predictions on an image data set.
Multi-head Knowledge Distillation for Model Compression
Dec 05, 2020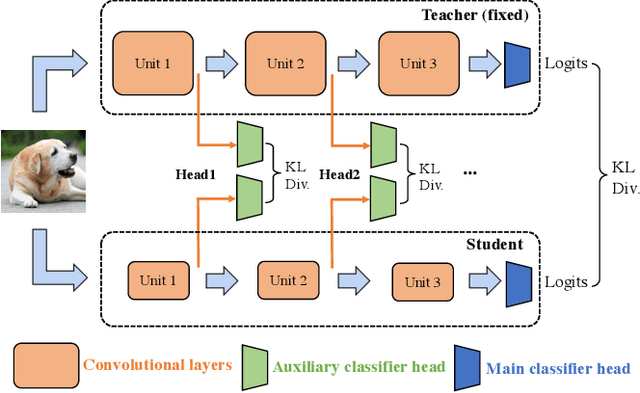
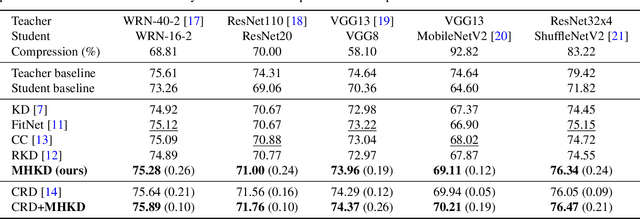

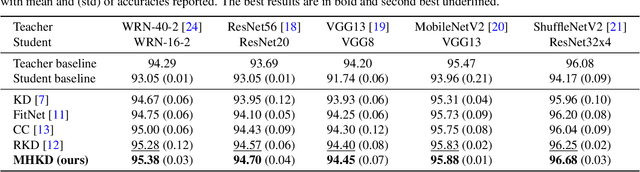
Several methods of knowledge distillation have been developed for neural network compression. While they all use the KL divergence loss to align the soft outputs of the student model more closely with that of the teacher, the various methods differ in how the intermediate features of the student are encouraged to match those of the teacher. In this paper, we propose a simple-to-implement method using auxiliary classifiers at intermediate layers for matching features, which we refer to as multi-head knowledge distillation (MHKD). We add loss terms for training the student that measure the dissimilarity between student and teacher outputs of the auxiliary classifiers. At the same time, the proposed method also provides a natural way to measure differences at the intermediate layers even though the dimensions of the internal teacher and student features may be different. Through several experiments in image classification on multiple datasets we show that the proposed method outperforms prior relevant approaches presented in the literature.