 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
ActiveNet: A computer-vision based approach to determine lethargy
Oct 26, 2020
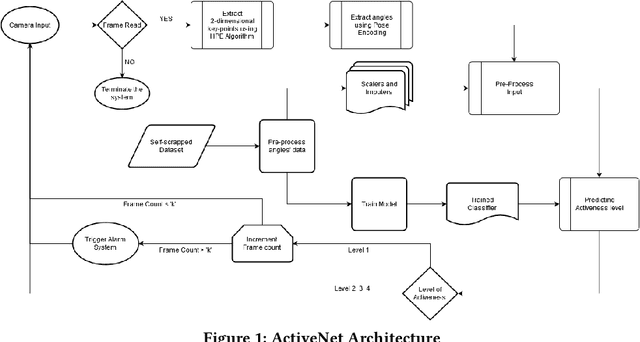


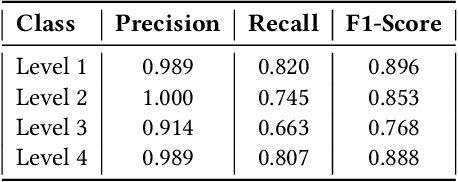
The outbreak of COVID-19 has forced everyone to stay indoors, fabricating a significant drop in physical activeness. Our work is constructed upon the idea to formulate a backbone mechanism, to detect levels of activeness in real-time, using a single monocular image of a target person. The scope can be generalized under many applications, be it in an interview, online classes, security surveillance, et cetera. We propose a Computer Vision based multi-stage approach, wherein the pose of a person is first detected, encoded with a novel approach, and then assessed by a classical machine learning algorithm to determine the level of activeness. An alerting system is wrapped around the approach to provide a solution to inhibit lethargy by sending notification alerts to individuals involved.
Physics-enhanced machine learning for virtual fluorescence microscopy
Apr 09, 2020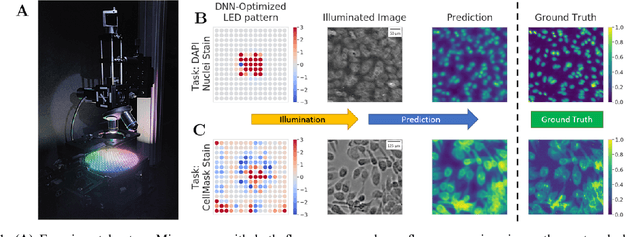
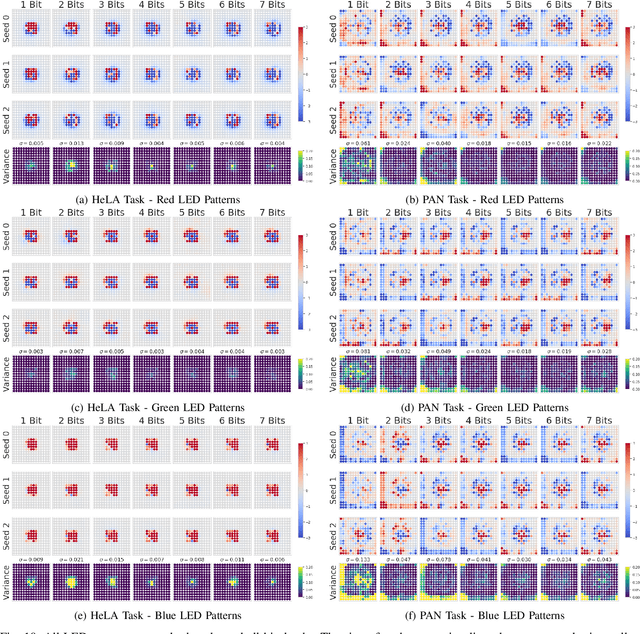
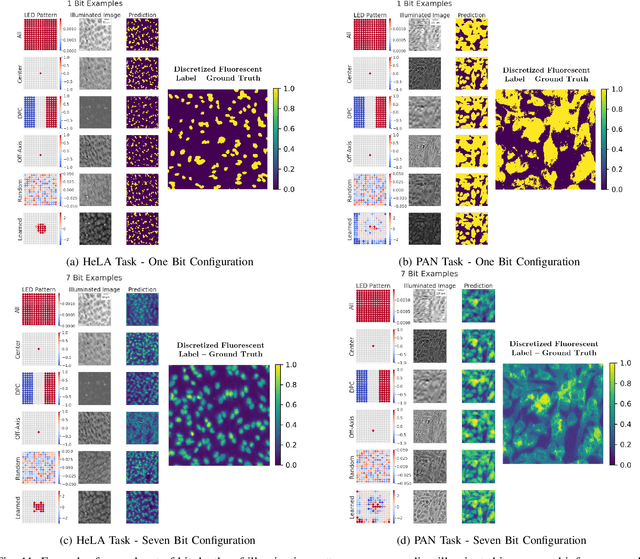

This paper introduces a supervised deep-learning network that jointly optimizes the physical setup of an optical microscope to infer fluorescence image information. Specifically, we design a bright-field microscope's illumination module to maximize the performance for inference of fluorescent cellular features from bright-field imagery. We take advantage of the wide degree of flexibility available in illuminating a sample to optimize for programmable patterns of light from a customized LED array, which produce better task-specific performance than standard lighting techniques. We achieve illumination pattern optimization by including a physical model of image formation within the initial layers of a deep convolutional network. Our optimized illumination patterns result in up to a 45% performance improvement as compared to standard imaging methods, and we additionally explore how the optimized patterns vary as a function of inference task. This work demonstrates the importance of optimizing the process of image capture via programmable optical elements to improve automated analysis, and offers new physical insights into expected performance gains of recent fluorescence image inference work.
Constrained Deep Weak Supervision for Histopathology Image Segmentation
Jan 03, 2017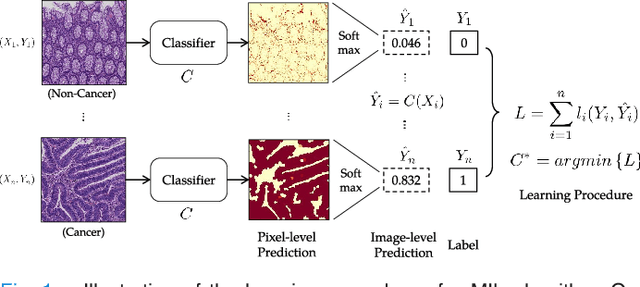

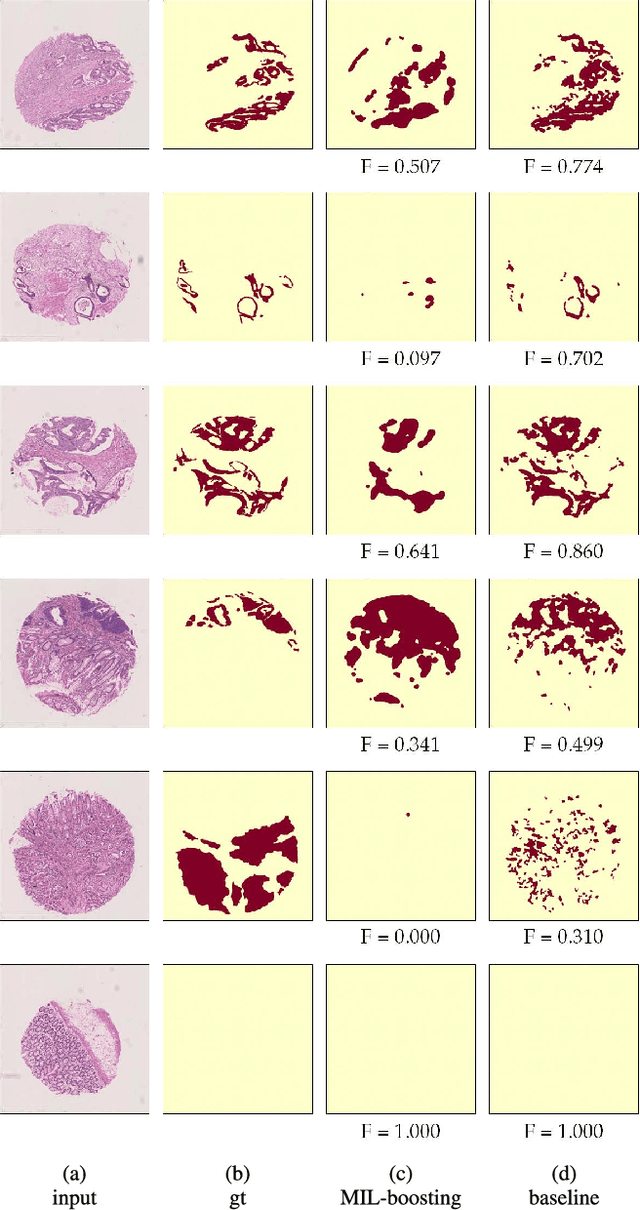
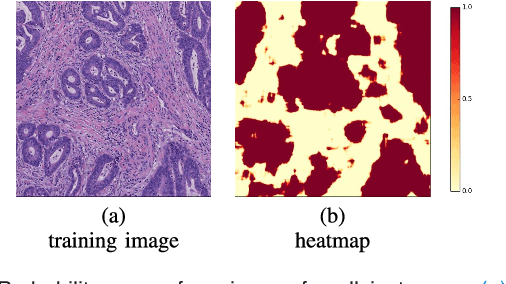
In this paper, we develop a new weakly-supervised learning algorithm to learn to segment cancerous regions in histopathology images. Our work is under a multiple instance learning framework (MIL) with a new formulation, deep weak supervision (DWS); we also propose an effective way to introduce constraints to our neural networks to assist the learning process. The contributions of our algorithm are threefold: (1) We build an end-to-end learning system that segments cancerous regions with fully convolutional networks (FCN) in which image-to-image weakly-supervised learning is performed. (2) We develop a deep week supervision formulation to exploit multi-scale learning under weak supervision within fully convolutional networks. (3) Constraints about positive instances are introduced in our approach to effectively explore additional weakly-supervised information that is easy to obtain and enjoys a significant boost to the learning process. The proposed algorithm, abbreviated as DWS-MIL, is easy to implement and can be trained efficiently. Our system demonstrates state-of-the-art results on large-scale histopathology image datasets and can be applied to various applications in medical imaging beyond histopathology images such as MRI, CT, and ultrasound images.
Image Patch Matching Using Convolutional Descriptors with Euclidean Distance
Oct 31, 2017
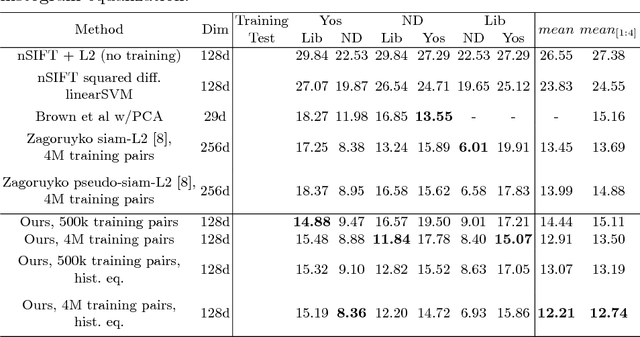
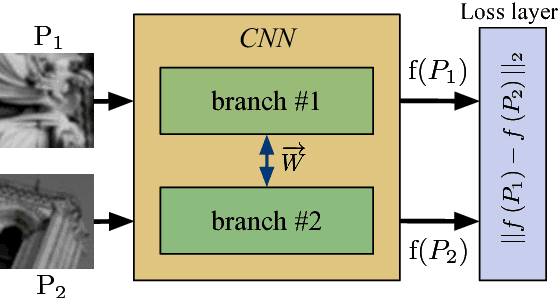
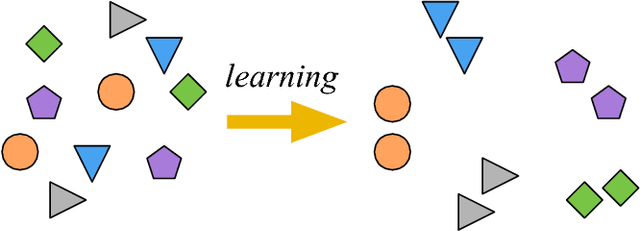
In this work we propose a neural network based image descriptor suitable for image patch matching, which is an important task in many computer vision applications. Our approach is influenced by recent success of deep convolutional neural networks (CNNs) in object detection and classification tasks. We develop a model which maps the raw input patch to a low dimensional feature vector so that the distance between representations is small for similar patches and large otherwise. As a distance metric we utilize L2 norm, i.e. Euclidean distance, which is fast to evaluate and used in most popular hand-crafted descriptors, such as SIFT. According to the results, our approach outperforms state-of-the-art L2-based descriptors and can be considered as a direct replacement of SIFT. In addition, we conducted experiments with batch normalization and histogram equalization as a preprocessing method of the input data. The results confirm that these techniques further improve the performance of the proposed descriptor. Finally, we show promising preliminary results by appending our CNNs with recently proposed spatial transformer networks and provide a visualisation and interpretation of their impact.
Frequency Domain-based Perceptual Loss for Super Resolution
Jul 23, 2020

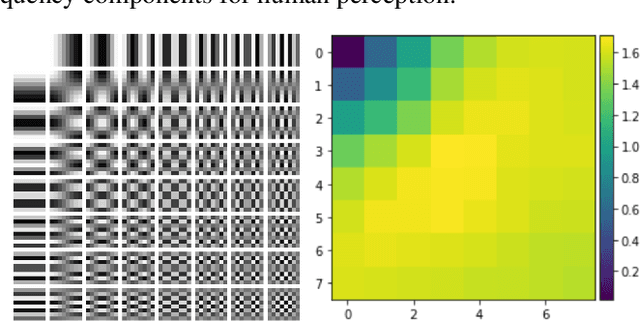
We introduce Frequency Domain Perceptual Loss (FDPL), a loss function for single image super resolution (SR). Unlike previous loss functions used to train SR models, which are all calculated in the pixel (spatial) domain, FDPL is computed in the frequency domain. By working in the frequency domain we can encourage a given model to learn a mapping that prioritizes those frequencies most related to human perception. While the goal of FDPL is not to maximize the Peak Signal to Noise Ratio (PSNR), we found that there is a correlation between decreasing FDPL and increasing PSNR. Training a model with FDPL results in a higher average PSRN (30.94), compared to the same model trained with pixel loss (30.59), as measured on the Set5 image dataset. We also show that our method achieves higher qualitative results, which is the goal of a perceptual loss function. However, it is not clear that the improved perceptual quality is due to the slightly higher PSNR or the perceptual nature of FDPL.
EXACT: A collaboration toolset for algorithm-aided annotation of almost everything
Apr 30, 2020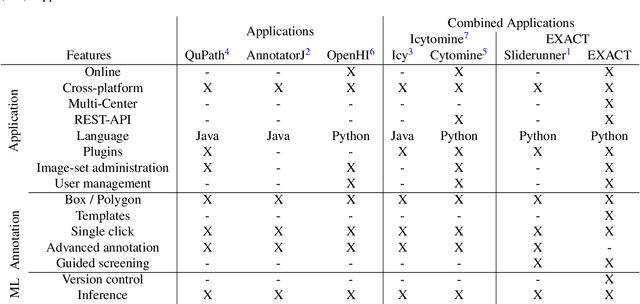
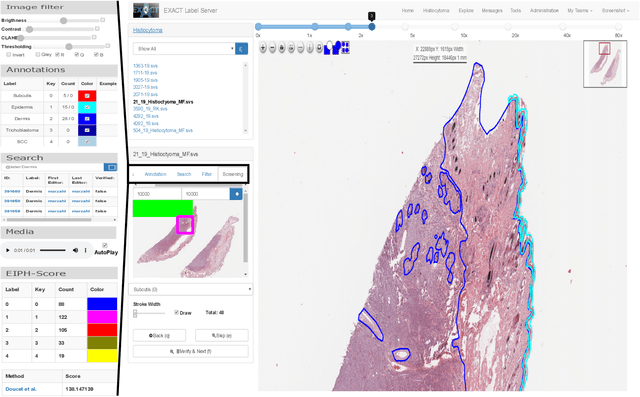
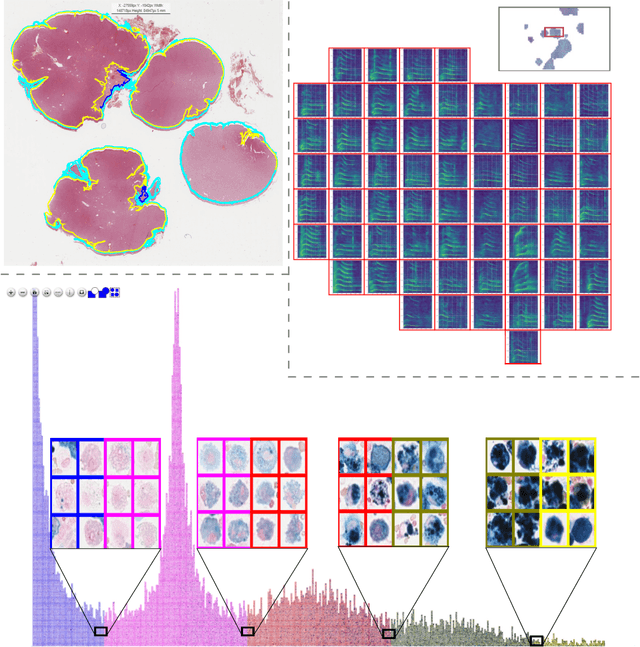
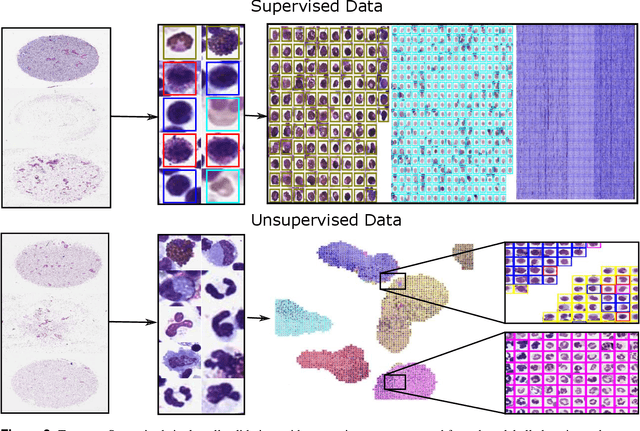
In many research areas scientific progress is accelerated by multidisciplinary access to image data and their interdisciplinary annotation. However, keeping track of these annotations to ensure a high-quality multi purpose data set is a challenging and labour intensive task. We developed the open-source online platform EXACT (EXpert Algorithm Cooperation Tool) that enables the collaborative interdisciplinary analysis of images from different domains online and offline. EXACT supports multi-gigapixel whole slide medical images, as well as image series with thousands of images. The software utilises a flexible plugin system that can be adapted to diverse applications such as counting mitotic figures with the screening mode, finding false annotations on a novel validation view, or using the latest deep learning image analysis technologies. This is combined with a version control system which makes it possible to keep track of changes in data sets and, for example, to link the results of deep learning experiments to specific data set versions. EXACT is freely available and has been applied successfully to a broad range of annotation tasks already, including highly diverse applications like deep learning supported cytology grading, interdisciplinary multi-centre whole slide image tumour annotation, and highly specialised whale sound spectroscopy clustering.
A CNN-Based Blind Denoising Method for Endoscopic Images
Mar 16, 2020
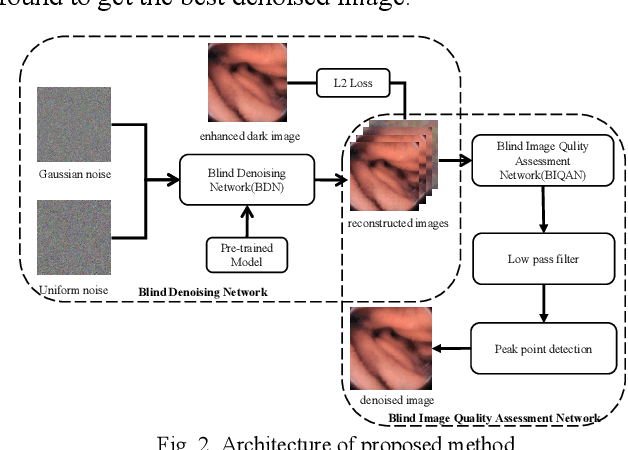
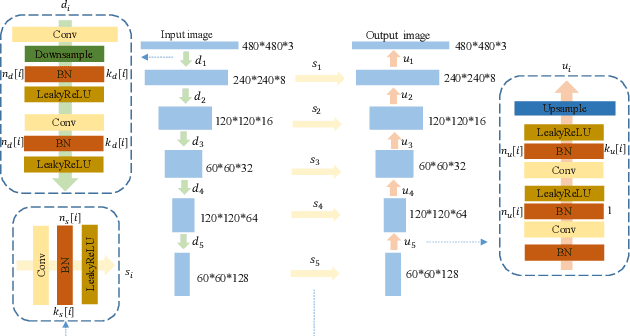
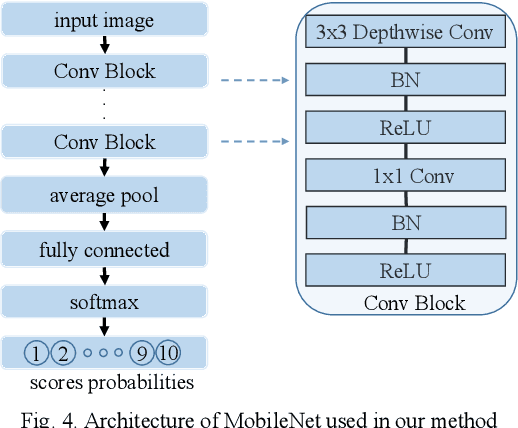
The quality of images captured by wireless capsule endoscopy (WCE) is key for doctors to diagnose diseases of gastrointestinal (GI) tract. However, there exist many low-quality endoscopic images due to the limited illumination and complex environment in GI tract. After an enhancement process, the severe noise become an unacceptable problem. The noise varies with different cameras, GI tract environments and image enhancement. And the noise model is hard to be obtained. This paper proposes a convolutional blind denoising network for endoscopic images. We apply Deep Image Prior (DIP) method to reconstruct a clean image iteratively using a noisy image without a specific noise model and ground truth. Then we design a blind image quality assessment network based on MobileNet to estimate the quality of the reconstructed images. The estimated quality is used to stop the iterative operation in DIP method. The number of iterations is reduced about 36% by using transfer learning in our DIP process. Experimental results on endoscopic images and real-world noisy images demonstrate the superiority of our proposed method over the state-of-the-art methods in terms of visual quality and quantitative metrics.
Image Dataset for Visual Objects Classification in 3D Printing
Mar 22, 2018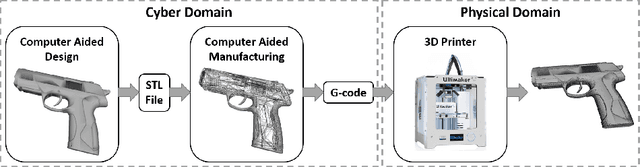

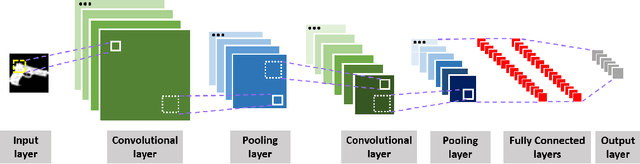
The rapid development in additive manufacturing (AM), also known as 3D printing, has brought about potential risk and security issues along with significant benefits. In order to enhance the security level of the 3D printing process, the present research aims to detect and recognize illegal components using deep learning. In this work, we collected a dataset of 61,340 2D images (28x28 for each image) of 10 classes including guns and other non-gun objects, corresponding to the projection results of the original 3D models. To validate the dataset, we train a convolutional neural network (CNN) model for gun classification which can achieve 98.16% classification accuracy.
Grassmannian Discriminant Maps (GDM) for Manifold Dimensionality Reduction with Application to Image Set Classification
Jun 28, 2018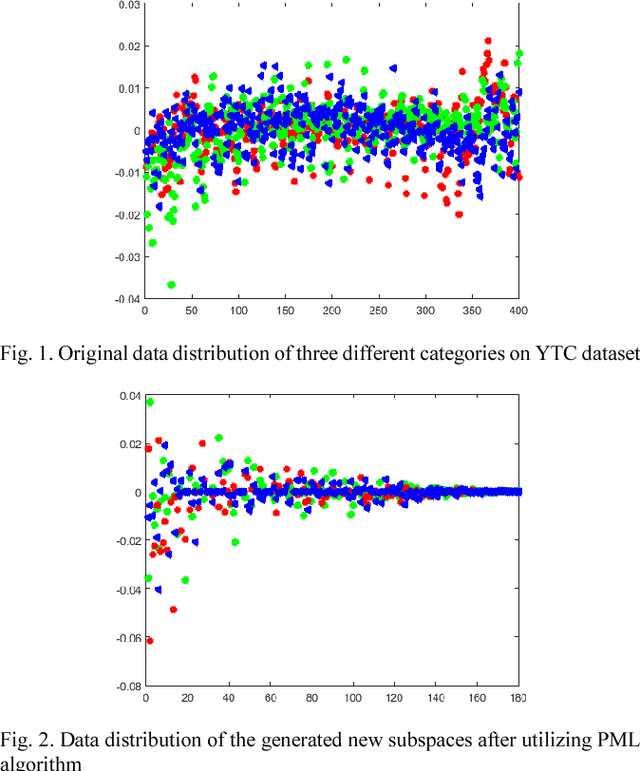
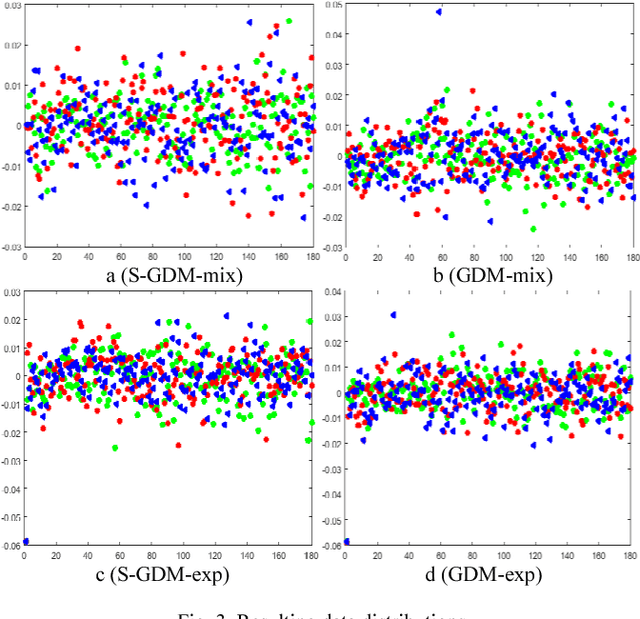
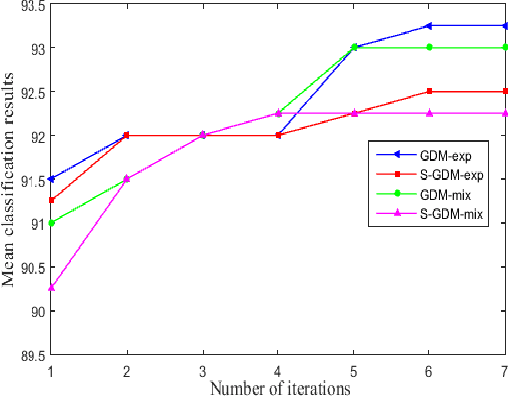
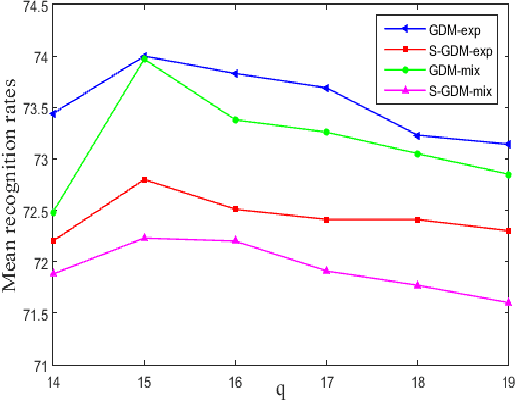
In image set classification, a considerable progress has been made by representing original image sets on Grassmann manifolds. In order to extend the advantages of the Euclidean based dimensionality reduction methods to the Grassmann Manifold, several methods have been suggested recently which jointly perform dimensionality reduction and metric learning on Grassmann manifold to improve performance. Nevertheless, when applied to complex datasets, the learned features do not exhibit enough discriminatory power. To overcome this problem, we propose a new method named Grassmannian Discriminant Maps (GDM) for manifold dimensionality reduction problems. The core of the method is a new discriminant function for metric learning and dimensionality reduction. For comparison and better understanding, we also study a simple variations to GDM. The key difference between them is the discriminant function. We experiment on data sets corresponding to three tasks: face recognition, object categorization, and hand gesture recognition to evaluate the proposed method and its simple extensions. Compared with the state of the art, the results achieved show the effectiveness of the proposed algorithm.
On Robustness and Transferability of Convolutional Neural Networks
Jul 16, 2020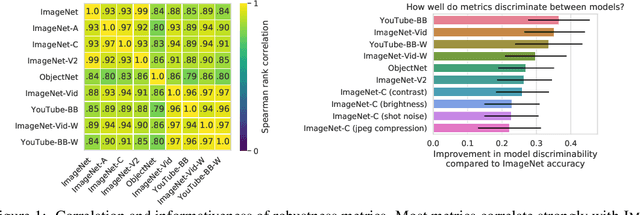

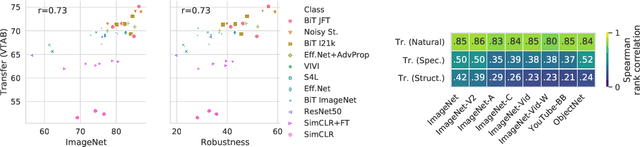
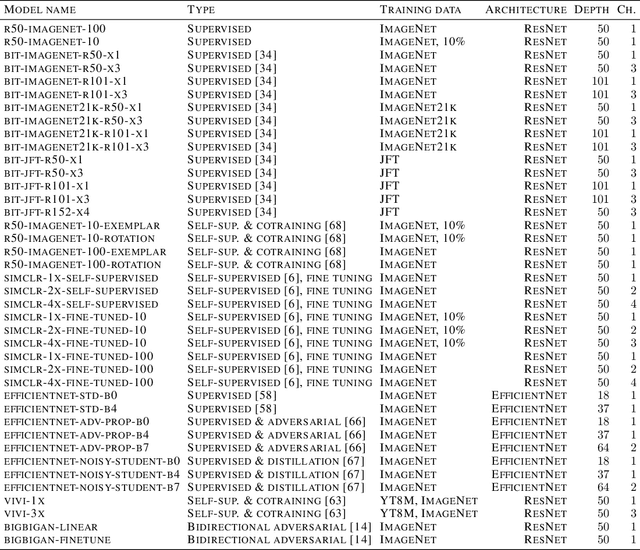
Modern deep convolutional networks (CNNs) are often criticized for not generalizing under distributional shifts. However, several recent breakthroughs in transfer learning suggest that these networks can cope with severe distribution shifts and successfully adapt to new tasks from a few training examples. In this work we revisit the out-of-distribution and transfer performance of modern image classification CNNs and investigate the impact of the pre-training data size, the model scale, and the data preprocessing pipeline. We find that increasing both the training set and model sizes significantly improve the distributional shift robustness. Furthermore, we show that, perhaps surprisingly, simple changes in the preprocessing such as modifying the image resolution can significantly mitigate robustness issues in some cases. Finally, we outline the shortcomings of existing robustness evaluation datasets and introduce a synthetic dataset we use for a systematic analysis across common factors of variation. \end{abstract}