 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
End-to-End JPEG Decoding and Artifacts Suppression Using Heterogeneous Residual Convolutional Neural Network
Jul 01, 2020
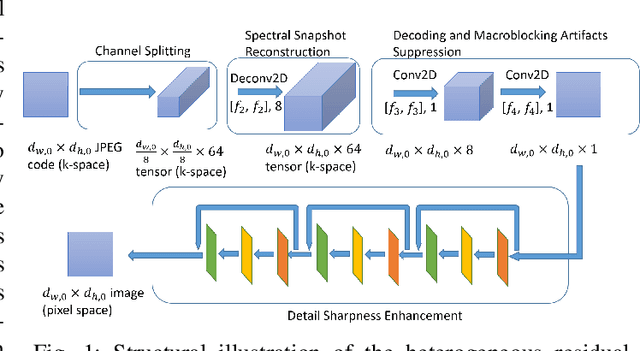
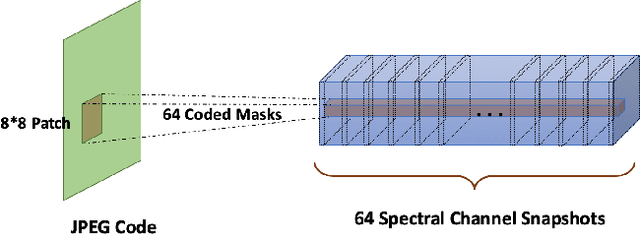
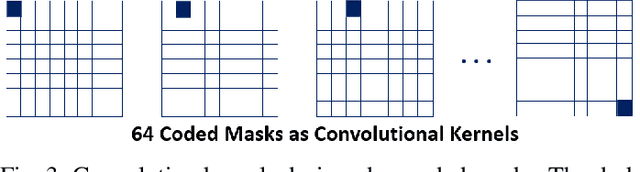

Existing deep learning models separate JPEG artifacts suppression from the decoding protocol as independent task. In this work, we take one step forward to design a true end-to-end heterogeneous residual convolutional neural network (HR-CNN) with spectrum decomposition and heterogeneous reconstruction mechanism. Benefitting from the full CNN architecture and GPU acceleration, the proposed model considerably improves the reconstruction efficiency. Numerical experiments show that the overall reconstruction speed reaches to the same magnitude of the standard CPU JPEG decoding protocol, while both decoding and artifacts suppression are completed together. We formulate the JPEG artifacts suppression task as an interactive process of decoding and image detail reconstructions. A heterogeneous, fully convolutional, mechanism is proposed to particularly address the uncorrelated nature of different spectral channels. Directly starting from the JPEG code in k-space, the network first extracts the spectral samples channel by channel, and restores the spectral snapshots with expanded throughput. These intermediate snapshots are then heterogeneously decoded and merged into the pixel space image. A cascaded residual learning segment is designed to further enhance the image details. Experiments verify that the model achieves outstanding performance in JPEG artifacts suppression, while its full convolutional operations and elegant network structure offers higher computational efficiency for practical online usage compared with other deep learning models on this topic.
Solving the Same-Different Task with Convolutional Neural Networks
Jan 22, 2021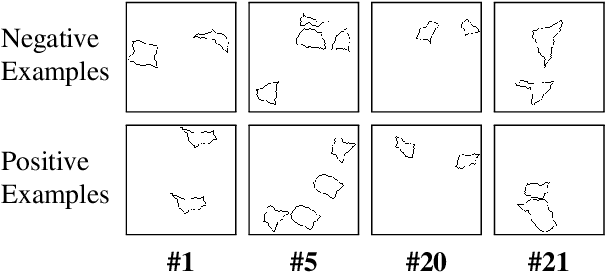
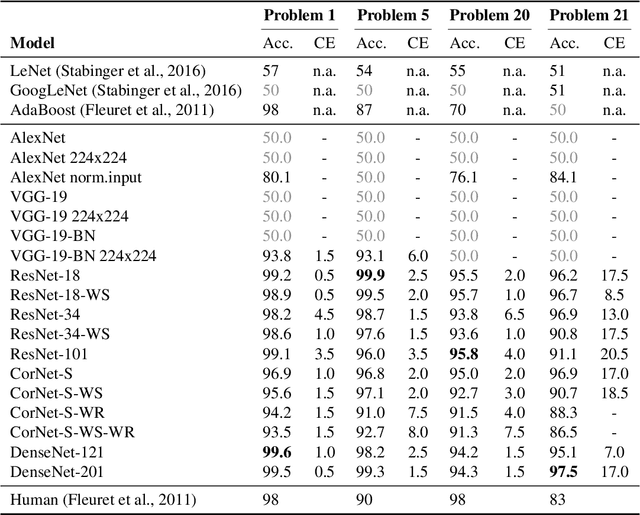
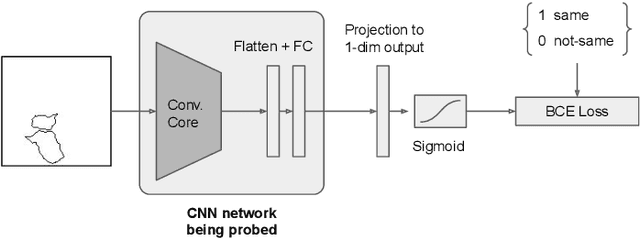
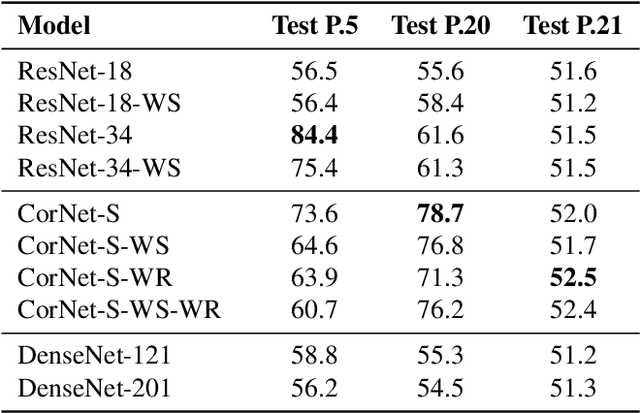
Deep learning demonstrated major abilities in solving many kinds of different real-world problems in computer vision literature. However, they are still strained by simple reasoning tasks that humans consider easy to solve. In this work, we probe current state-of-the-art convolutional neural networks on a difficult set of tasks known as the same-different problems. All the problems require the same prerequisite to be solved correctly: understanding if two random shapes inside the same image are the same or not. With the experiments carried out in this work, we demonstrate that residual connections, and more generally the skip connections, seem to have only a marginal impact on the learning of the proposed problems. In particular, we experiment with DenseNets, and we examine the contribution of residual and recurrent connections in already tested architectures, ResNet-18, and CorNet-S respectively. Our experiments show that older feed-forward networks, AlexNet and VGG, are almost unable to learn the proposed problems, except in some specific scenarios. We show that recently introduced architectures can converge even in the cases where the important parts of their architecture are removed. We finally carry out some zero-shot generalization tests, and we discover that in these scenarios residual and recurrent connections can have a stronger impact on the overall test accuracy. On four difficult problems from the SVRT dataset, we can reach state-of-the-art results with respect to the previous approaches, obtaining super-human performances on three of the four problems.
* Preprint of the paper published in Patter Recognition Letters (Elsevier)
Hyperspherical embedding for novel class classification
Feb 05, 2021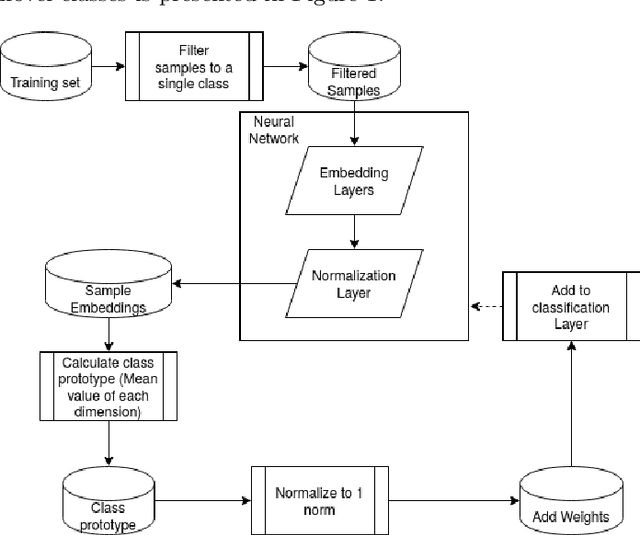
Deep learning models have become increasingly useful in many different industries. On the domain of image classification, convolutional neural networks proved the ability to learn robust features for the closed set problem, as shown in many different datasets, such as MNIST FASHIONMNIST, CIFAR10, CIFAR100, and IMAGENET. These approaches use deep neural networks with dense layers with softmax activation functions in order to learn features that can separate classes in a latent space. However, this traditional approach is not useful for identifying classes unseen on the training set, known as the open set problem. A similar problem occurs in scenarios involving learning on small data. To tackle both problems, few-shot learning has been proposed. In particular, metric learning learns features that obey constraints of a metric distance in the latent space in order to perform classification. However, while this approach proves to be useful for the open set problem, current implementation requires pair-wise training, where both positive and negative examples of similar images are presented during the training phase, which limits the applicability of these approaches in large data or large class scenarios given the combinatorial nature of the possible inputs.In this paper, we present a constraint-based approach applied to the representations in the latent space under the normalized softmax loss, proposed by[18]. We experimentally validate the proposed approach for the classification of unseen classes on different datasets using both metric learning and the normalized softmax loss, on disjoint and joint scenarios. Our results show that not only our proposed strategy can be efficiently trained on larger set of classes, as it does not require pairwise learning, but also present better classification results than the metric learning strategies surpassing its accuracy by a significant margin.
Pose2Mesh: Graph Convolutional Network for 3D Human Pose and Mesh Recovery from a 2D Human Pose
Aug 20, 2020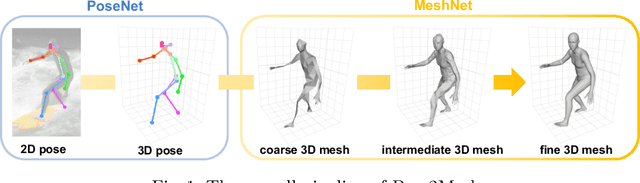



Most of the recent deep learning-based 3D human pose and mesh estimation methods regress the pose and shape parameters of human mesh models, such as SMPL and MANO, from an input image. The first weakness of these methods is an appearance domain gap problem, due to different image appearance between train data from controlled environments, such as a laboratory, and test data from in-the-wild environments. The second weakness is that the estimation of the pose parameters is quite challenging owing to the representation issues of 3D rotations. To overcome the above weaknesses, we propose Pose2Mesh, a novel graph convolutional neural network (GraphCNN)-based system that estimates the 3D coordinates of human mesh vertices directly from the 2D human pose. The 2D human pose as input provides essential human body articulation information, while having a relatively homogeneous geometric property between the two domains. Also, the proposed system avoids the representation issues, while fully exploiting the mesh topology using a GraphCNN in a coarse-to-fine manner. We show that our Pose2Mesh outperforms the previous 3D human pose and mesh estimation methods on various benchmark datasets. The codes are publicly available https://github.com/hongsukchoi/Pose2Mesh_RELEASE.
Two-Stream Deep Feature Modelling for Automated Video Endoscopy Data Analysis
Jul 12, 2020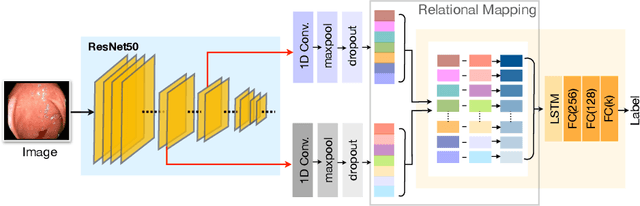
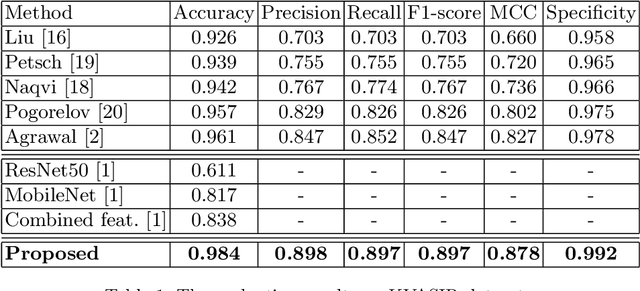
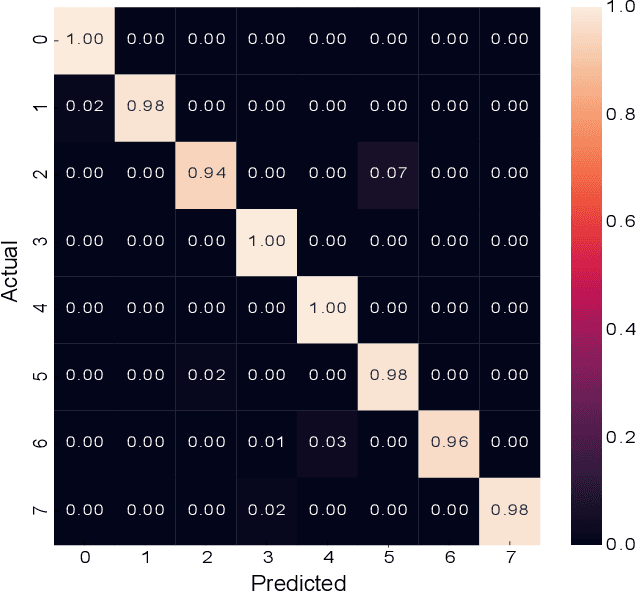
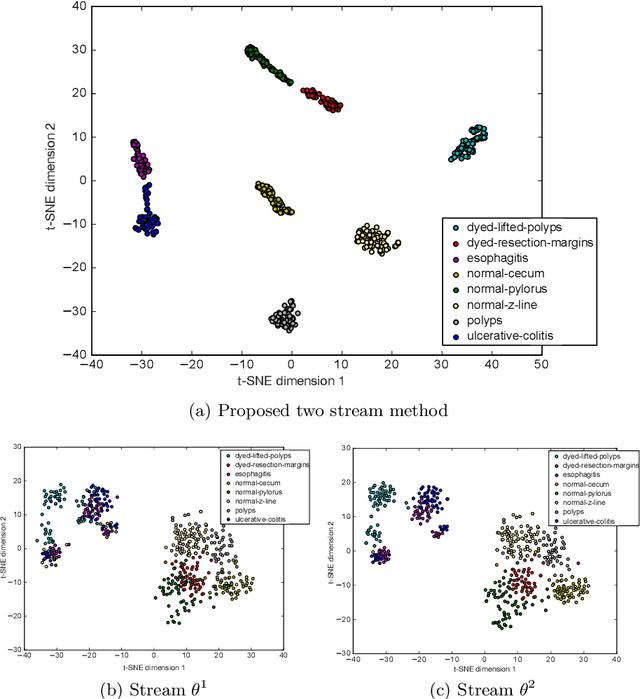
Automating the analysis of imagery of the Gastrointestinal (GI) tract captured during endoscopy procedures has substantial potential benefits for patients, as it can provide diagnostic support to medical practitioners and reduce mistakes via human error. To further the development of such methods, we propose a two-stream model for endoscopic image analysis. Our model fuses two streams of deep feature inputs by mapping their inherent relations through a novel relational network model, to better model symptoms and classify the image. In contrast to handcrafted feature-based models, our proposed network is able to learn features automatically and outperforms existing state-of-the-art methods on two public datasets: KVASIR and Nerthus. Our extensive evaluations illustrate the importance of having two streams of inputs instead of a single stream and also demonstrates the merits of the proposed relational network architecture to combine those streams.
A Deep Learning Approach Based on Graphs to Detect Plantation Lines
Feb 05, 2021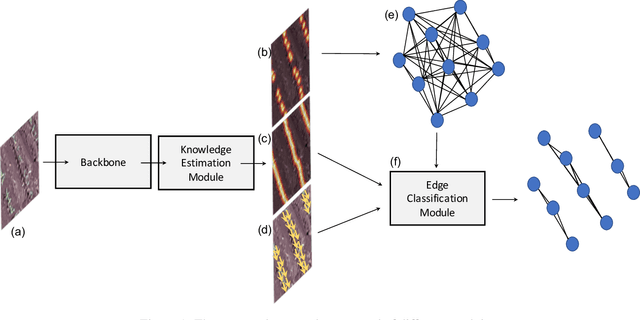
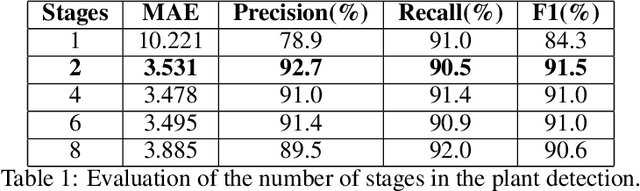
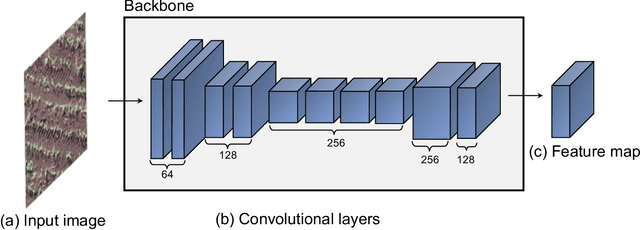
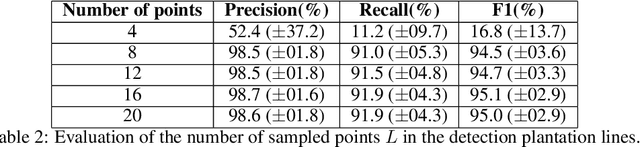
Deep learning-based networks are among the most prominent methods to learn linear patterns and extract this type of information from diverse imagery conditions. Here, we propose a deep learning approach based on graphs to detect plantation lines in UAV-based RGB imagery presenting a challenging scenario containing spaced plants. The first module of our method extracts a feature map throughout the backbone, which consists of the initial layers of the VGG16. This feature map is used as an input to the Knowledge Estimation Module (KEM), organized in three concatenated branches for detecting 1) the plant positions, 2) the plantation lines, and 3) for the displacement vectors between the plants. A graph modeling is applied considering each plant position on the image as vertices, and edges are formed between two vertices (i.e. plants). Finally, the edge is classified as pertaining to a certain plantation line based on three probabilities (higher than 0.5): i) in visual features obtained from the backbone; ii) a chance that the edge pixels belong to a line, from the KEM step; and iii) an alignment of the displacement vectors with the edge, also from KEM. Experiments were conducted in corn plantations with different growth stages and patterns with aerial RGB imagery. A total of 564 patches with 256 x 256 pixels were used and randomly divided into training, validation, and testing sets in a proportion of 60\%, 20\%, and 20\%, respectively. The proposed method was compared against state-of-the-art deep learning methods, and achieved superior performance with a significant margin, returning precision, recall, and F1-score of 98.7\%, 91.9\%, and 95.1\%, respectively. This approach is useful in extracting lines with spaced plantation patterns and could be implemented in scenarios where plantation gaps occur, generating lines with few-to-none interruptions.
Learning Generative Models of Tissue Organization with Supervised GANs
Mar 31, 2020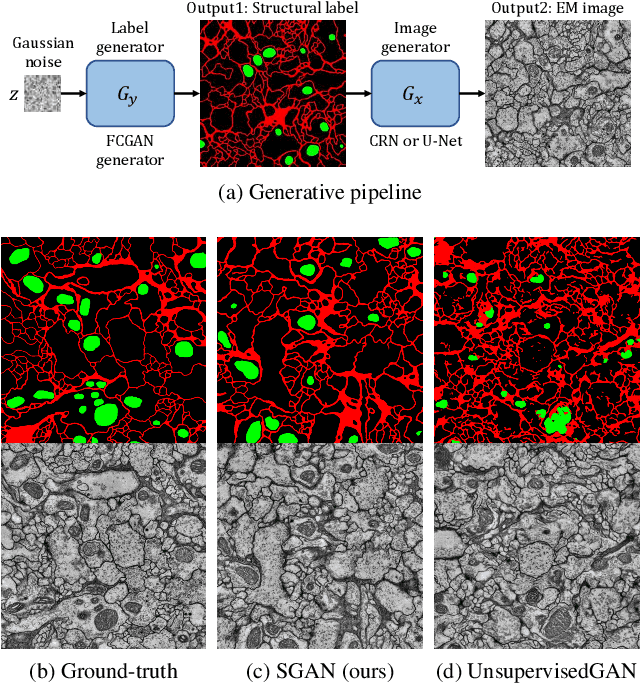
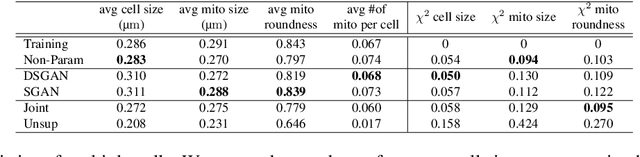
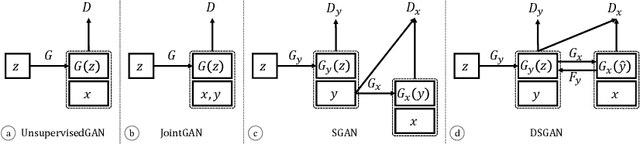
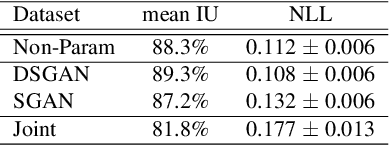
A key step in understanding the spatial organization of cells and tissues is the ability to construct generative models that accurately reflect that organization. In this paper, we focus on building generative models of electron microscope (EM) images in which the positions of cell membranes and mitochondria have been densely annotated, and propose a two-stage procedure that produces realistic images using Generative Adversarial Networks (or GANs) in a supervised way. In the first stage, we synthesize a label "image" given a noise "image" as input, which then provides supervision for EM image synthesis in the second stage. The full model naturally generates label-image pairs. We show that accurate synthetic EM images are produced using assessment via (1) shape features and global statistics, (2) segmentation accuracies, and (3) user studies. We also demonstrate further improvements by enforcing a reconstruction loss on intermediate synthetic labels and thus unifying the two stages into one single end-to-end framework.
Contour Integration using Graph-Cut and Non-Classical Receptive Field
Oct 27, 2020
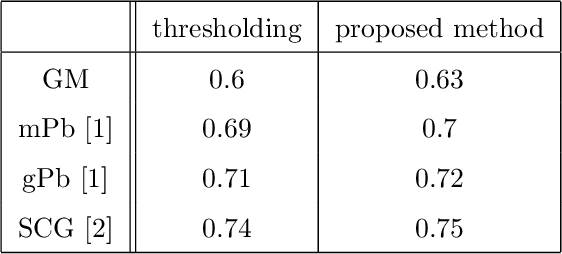
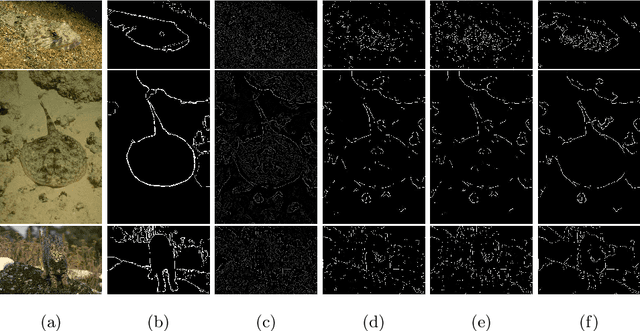

Many edge and contour detection algorithms give a soft-value as an output and the final binary map is commonly obtained by applying an optimal threshold. In this paper, we propose a novel method to detect image contours from the extracted edge segments of other algorithms. Our method is based on an undirected graphical model with the edge segments set as the vertices. The proposed energy functions are inspired by the surround modulation in the primary visual cortex that help suppressing texture noise. Our algorithm can improve extracting the binary map, because it considers other important factors such as connectivity, smoothness, and length of the contour beside the soft-values. Our quantitative and qualitative experimental results show the efficacy of the proposed method.
Usefulness of interpretability methods to explain deep learning based plant stress phenotyping
Jul 11, 2020
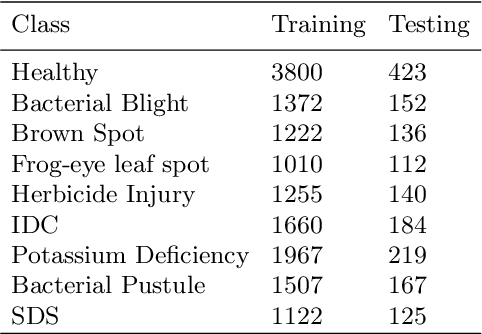
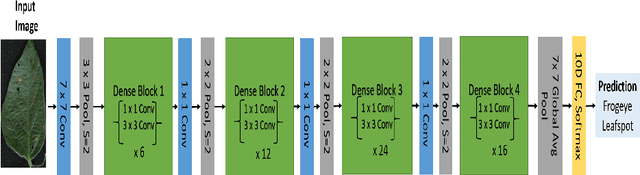
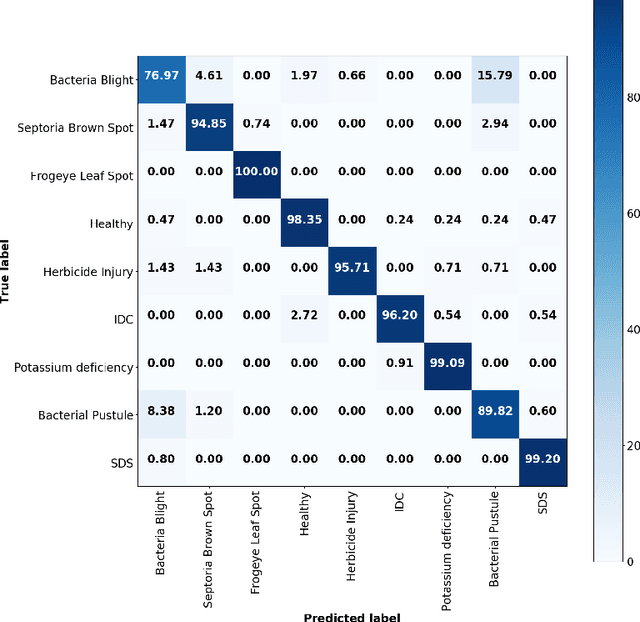
Deep learning techniques have been successfully deployed for automating plant stress identification and quantification. In recent years, there is a growing push towards training models that are interpretable -i.e. that justify their classification decisions by visually highlighting image features that were crucial for classification decisions. The expectation is that trained network models utilize image features that mimic visual cues used by plant pathologists. In this work, we compare some of the most popular interpretability methods: Saliency Maps, SmoothGrad, Guided Backpropogation, Deep Taylor Decomposition, Integrated Gradients, Layer-wise Relevance Propagation and Gradient times Input, for interpreting the deep learning model. We train a DenseNet-121 network for the classification of eight different soybean stresses (biotic and abiotic). Using a dataset consisting of 16,573 RGB images of healthy and stressed soybean leaflets captured under controlled conditions, we obtained an overall classification accuracy of 95.05 \%. For a diverse subset of the test data, we compared the important features with those identified by a human expert. We observed that most interpretability methods identify the infected regions of the leaf as important features for some -- but not all -- of the correctly classified images. For some images, the output of the interpretability methods indicated that spurious feature correlations may have been used to correctly classify them. Although the output explanation maps of these interpretability methods may be different from each other for a given image, we advocate the use of these interpretability methods as `hypothesis generation' mechanisms that can drive scientific insight.
An Efficient and Scalable Deep Learning Approach for Road Damage Detection
Dec 17, 2020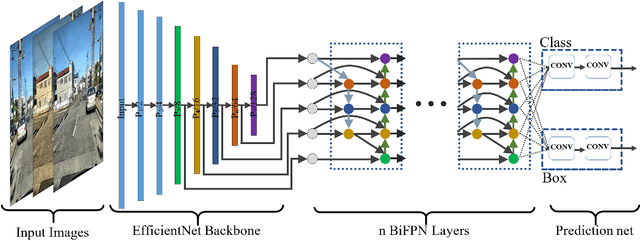

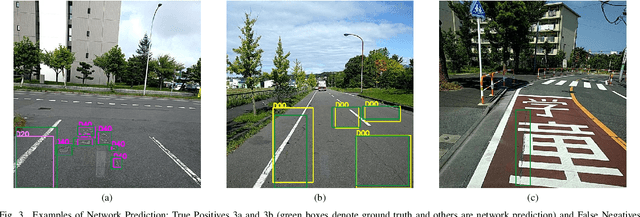

Pavement condition evaluation is essential to time the preventative or rehabilitative actions and control distress propagation. Failing to conduct timely evaluations can lead to severe structural and financial loss of the infrastructure and complete reconstructions. Automated computer-aided surveying measures can provide a database of road damage patterns and their locations. This database can be utilized for timely road repairs to gain the minimum cost of maintenance and the asphalt's maximum durability. This paper introduces a deep learning-based surveying scheme to analyze the image-based distress data in real-time. A database consisting of a diverse population of crack distress types such as longitudinal, transverse, and alligator cracks, photographed using mobile-device is used. Then, a family of efficient and scalable models that are tuned for pavement crack detection is trained, and various augmentation policies are explored. Proposed models, resulted in F1-scores, ranging from 52% to 56%, and average inference time from 178-10 images per second. Finally, the performance of the object detectors are examined, and error analysis is reported against various images. The source code is available at https://github.com/mahdi65/roadDamageDetection2020.