 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Novel Image Dehazing and Assessment Method
Jan 20, 2020


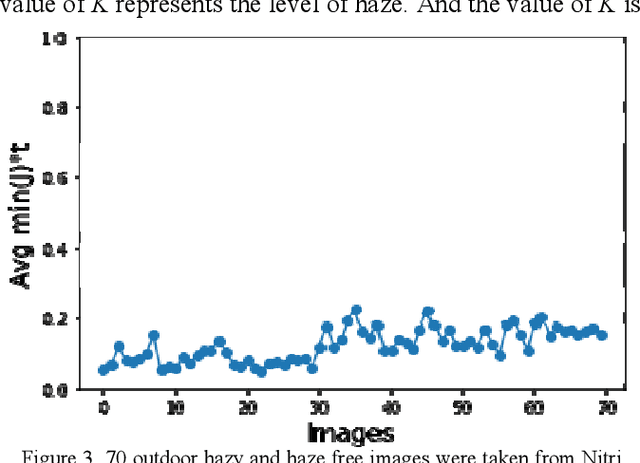

Images captured in hazy weather conditions often suffer from color contrast and color fidelity. This degradation is represented by transmission map which represents the amount of attenuation and airlight which represents the color of additive noise. In this paper, we have proposed a method to estimate the transmission map using haze levels instead of airlight color since there are some ambiguities in estimation of airlight. Qualitative and quantitative results of proposed method show competitiveness of the method given. In addition we have proposed two metrics which are based on statistics of natural outdoor images for assessment of haze removal algorithms.
Lunar Crater Identification in Digital Images
Sep 02, 2020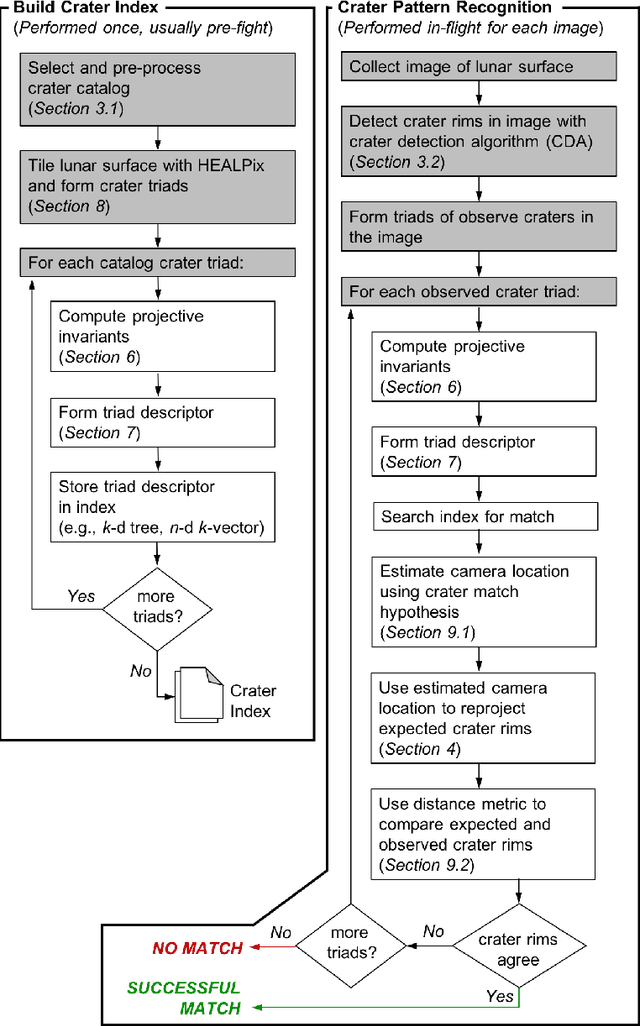

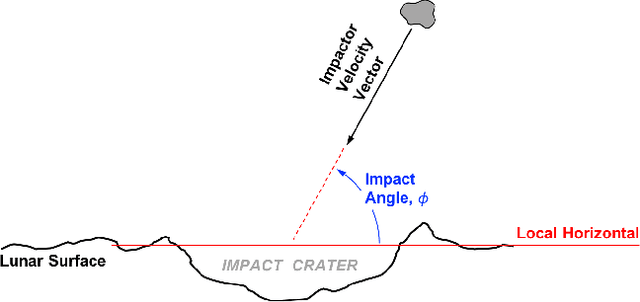
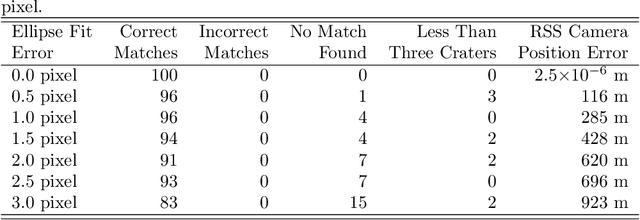
It is often necessary to identify a pattern of observed craters in a single image of the lunar surface and without any prior knowledge of the camera's location. This so-called "lost-in-space" crater identification problem is common in both crater-based terrain relative navigation (TRN) and in automatic registration of scientific imagery. Past work on crater identification has largely been based on heuristic schemes, with poor performance outside of a narrowly defined operating regime (e.g., nadir pointing images, small search areas). This work provides the first mathematically rigorous treatment of the general crater identification problem. It is shown when it is (and when it is not) possible to recognize a pattern of elliptical crater rims in an image formed by perspective projection. For the cases when it is possible to recognize a pattern, descriptors are developed using invariant theory that provably capture all of the viewpoint invariant information. These descriptors may be pre-computed for known crater patterns and placed in a searchable index for fast recognition. New techniques are also developed for computing pose from crater rim observations and for evaluating crater rim correspondences. These techniques are demonstrated on both synthetic and real images.
Adversarial Examples in Deep Learning for Multivariate Time Series Regression
Sep 24, 2020
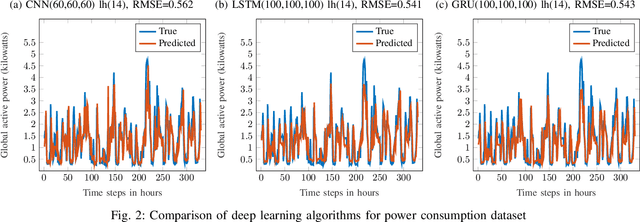
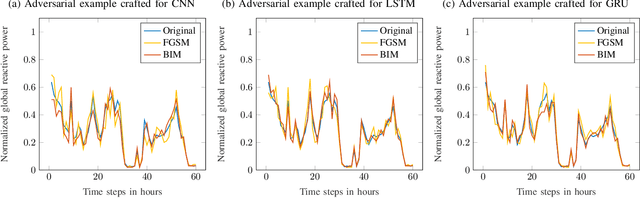
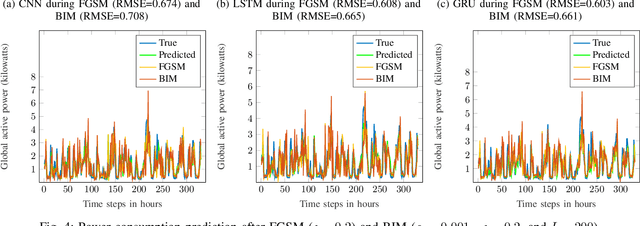
Multivariate time series (MTS) regression tasks are common in many real-world data mining applications including finance, cybersecurity, energy, healthcare, prognostics, and many others. Due to the tremendous success of deep learning (DL) algorithms in various domains including image recognition and computer vision, researchers started adopting these techniques for solving MTS data mining problems, many of which are targeted for safety-critical and cost-critical applications. Unfortunately, DL algorithms are known for their susceptibility to adversarial examples which also makes the DL regression models for MTS forecasting also vulnerable to those attacks. To the best of our knowledge, no previous work has explored the vulnerability of DL MTS regression models to adversarial time series examples, which is an important step, specifically when the forecasting from such models is used in safety-critical and cost-critical applications. In this work, we leverage existing adversarial attack generation techniques from the image classification domain and craft adversarial multivariate time series examples for three state-of-the-art deep learning regression models, specifically Convolutional Neural Network (CNN), Long Short-Term Memory (LSTM), and Gated Recurrent Unit (GRU). We evaluate our study using Google stock and household power consumption dataset. The obtained results show that all the evaluated DL regression models are vulnerable to adversarial attacks, transferable, and thus can lead to catastrophic consequences in safety-critical and cost-critical domains, such as energy and finance.
Deep Learning for Biomedical Image Reconstruction: A Survey
Feb 26, 2020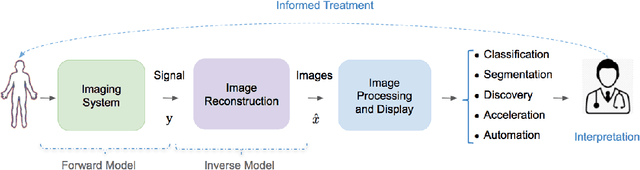
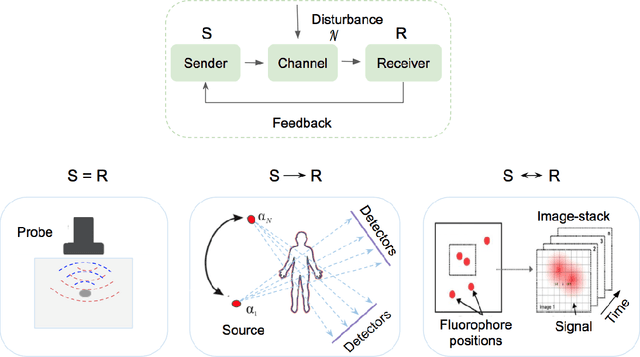
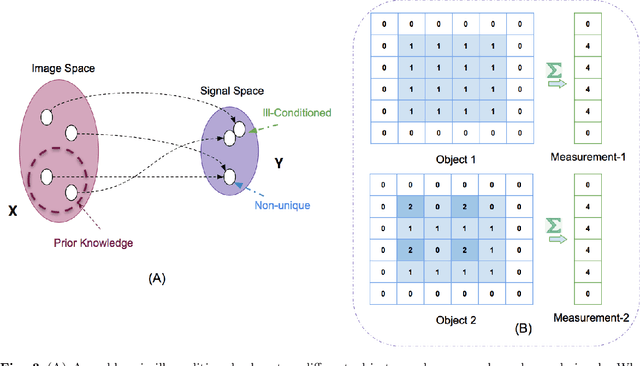
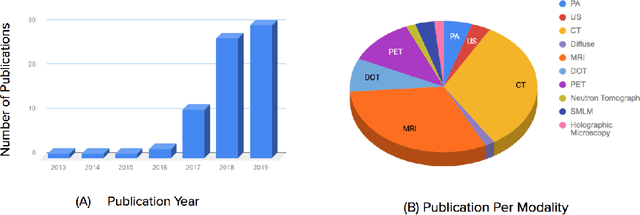
Medical imaging is an invaluable resource in medicine as it enables to peer inside the human body and provides scientists and physicians with a wealth of information indispensable for understanding, modelling, diagnosis, and treatment of diseases. Reconstruction algorithms entail transforming signals collected by acquisition hardware into interpretable images. Reconstruction is a challenging task given the ill-posed of the problem and the absence of exact analytic inverse transforms in practical cases. While the last decades witnessed impressive advancements in terms of new modalities, improved temporal and spatial resolution, reduced cost, and wider applicability, several improvements can still be envisioned such as reducing acquisition and reconstruction time to reduce patient's exposure to radiation and discomfort while increasing clinics throughput and reconstruction accuracy. Furthermore, the deployment of biomedical imaging in handheld devices with small power requires a fine balance between accuracy and latency.
PerSIM: Multi-resolution Image Quality Assessment in the Perceptually Uniform Color Domain
Nov 18, 2018
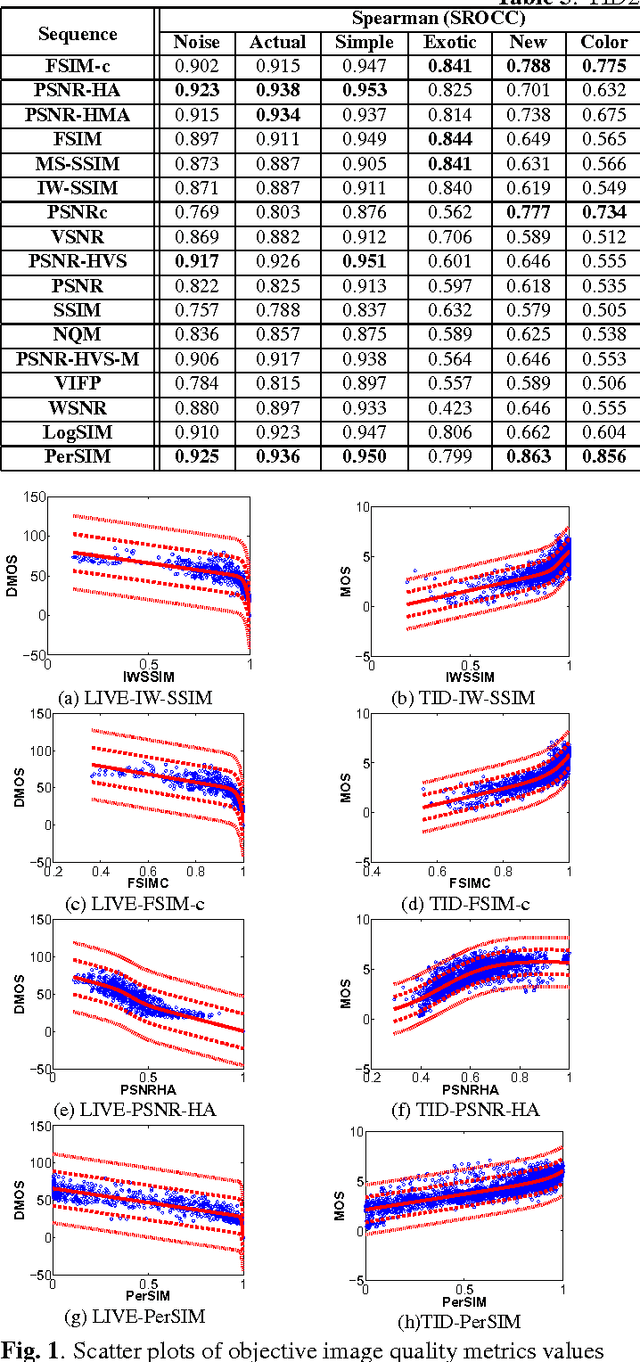
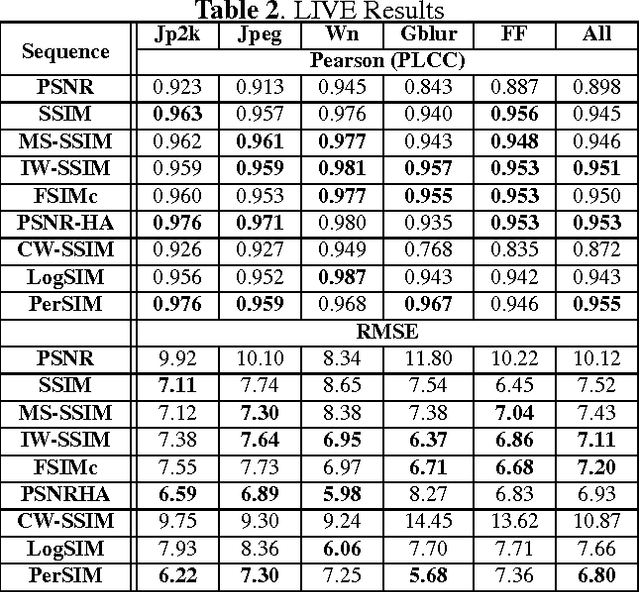
An average observer perceives the world in color instead of black and white. Moreover, the visual system focuses on structures and segments instead of individual pixels. Based on these observations, we propose a full reference objective image quality metric modeling visual system characteristics and chroma similarity in the perceptually uniform color domain (Lab). Laplacian of Gaussian features are obtained in the L channel to model the retinal ganglion cells in human visual system and color similarity is calculated over the a and b channels. In the proposed perceptual similarity index (PerSIM), a multi-resolution approach is followed to mimic the hierarchical nature of human visual system. LIVE and TID2013 databases are used in the validation and PerSIM outperforms all the compared metrics in the overall databases in terms of ranking, monotonic behavior and linearity.
* 5 pages, 1 figure, 3 tables
Multi-Scale Neural Networks for to Fluid Flow in 3D Porous Media
Feb 10, 2021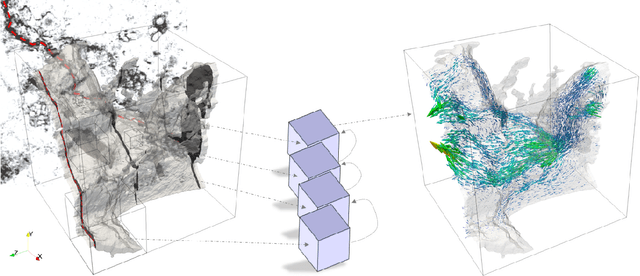
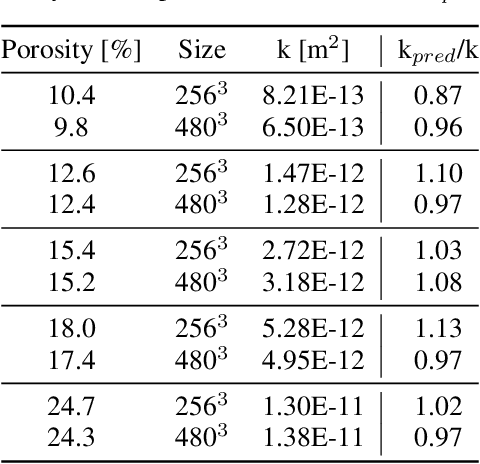
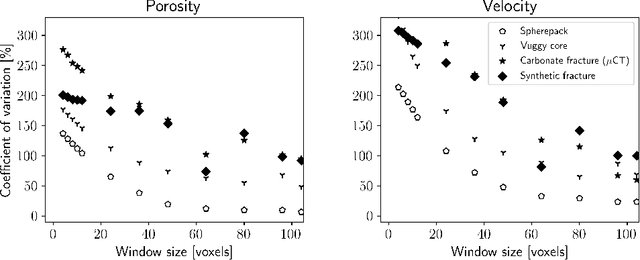
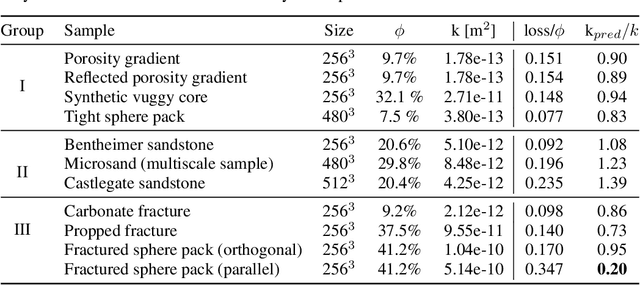
The permeability of complex porous materials can be obtained via direct flow simulation, which provides the most accurate results, but is very computationally expensive. In particular, the simulation convergence time scales poorly as simulation domains become tighter or more heterogeneous. Semi-analytical models that rely on averaged structural properties (i.e. porosity and tortuosity) have been proposed, but these features only summarize the domain, resulting in limited applicability. On the other hand, data-driven machine learning approaches have shown great promise for building more general models by virtue of accounting for the spatial arrangement of the domains solid boundaries. However, prior approaches building on the Convolutional Neural Network (ConvNet) literature concerning 2D image recognition problems do not scale well to the large 3D domains required to obtain a Representative Elementary Volume (REV). As such, most prior work focused on homogeneous samples, where a small REV entails that that the global nature of fluid flow could be mostly neglected, and accordingly, the memory bottleneck of addressing 3D domains with ConvNets was side-stepped. Therefore, important geometries such as fractures and vuggy domains could not be well-modeled. In this work, we address this limitation with a general multiscale deep learning model that is able to learn from porous media simulation data. By using a coupled set of neural networks that view the domain on different scales, we enable the evaluation of large images in approximately one second on a single Graphics Processing Unit. This model architecture opens up the possibility of modeling domain sizes that would not be feasible using traditional direct simulation tools on a desktop computer.
Structure-Aware Generation Network for Recipe Generation from Images
Sep 02, 2020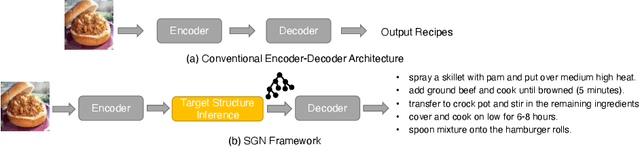
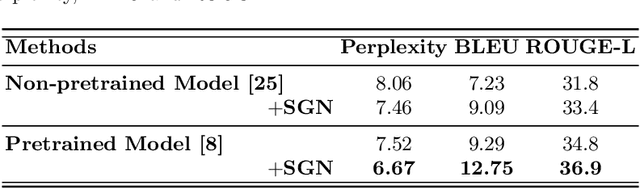
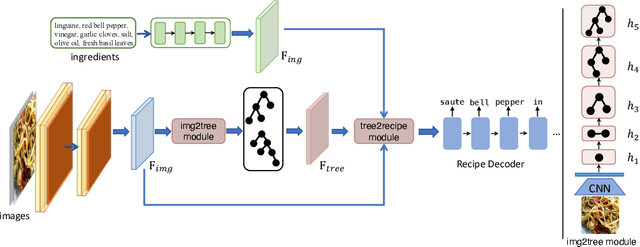
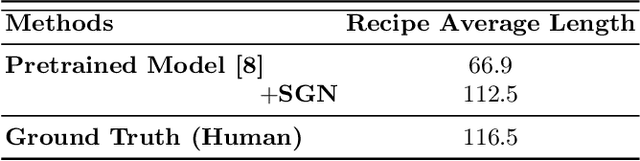
Sharing food has become very popular with the development of social media. For many real-world applications, people are keen to know the underlying recipes of a food item. In this paper, we are interested in automatically generating cooking instructions for food. We investigate an open research task of generating cooking instructions based on only food images and ingredients, which is similar to the image captioning task. However, compared with image captioning datasets, the target recipes are long-length paragraphs and do not have annotations on structure information. To address the above limitations, we propose a novel framework of Structure-aware Generation Network (SGN) to tackle the food recipe generation task. Our approach brings together several novel ideas in a systematic framework: (1) exploiting an unsupervised learning approach to obtain the sentence-level tree structure labels before training; (2) generating trees of target recipes from images with the supervision of tree structure labels learned from (1); and (3) integrating the inferred tree structures with the recipe generation procedure. Our proposed model can produce high-quality and coherent recipes, and achieve the state-of-the-art performance on the benchmark Recipe1M dataset.
Receptivity of an AI Cognitive Assistant by the Radiology Community: A Report on Data Collected at RSNA
Sep 13, 2020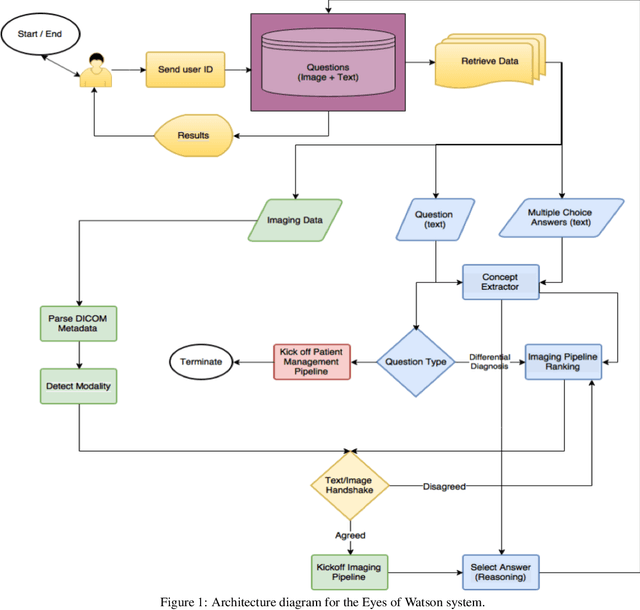
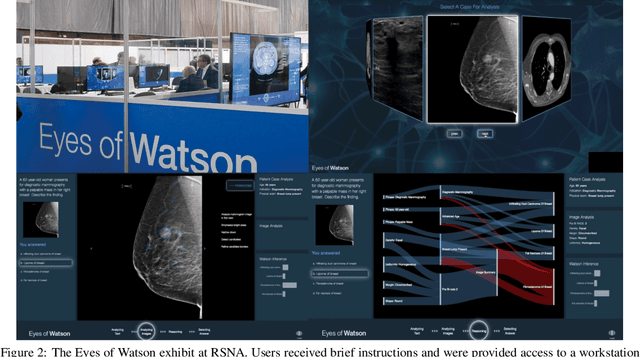
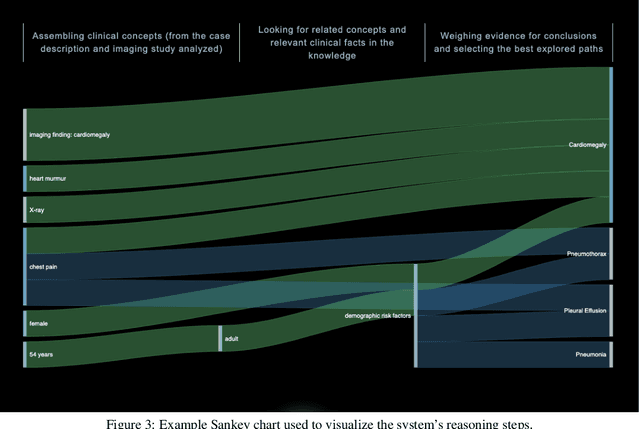
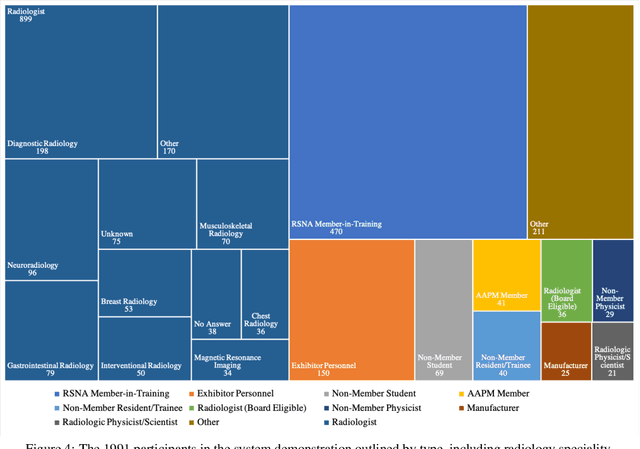
Due to advances in machine learning and artificial intelligence (AI), a new role is emerging for machines as intelligent assistants to radiologists in their clinical workflows. But what systematic clinical thought processes are these machines using? Are they similar enough to those of radiologists to be trusted as assistants? A live demonstration of such a technology was conducted at the 2016 Scientific Assembly and Annual Meeting of the Radiological Society of North America (RSNA). The demonstration was presented in the form of a question-answering system that took a radiology multiple choice question and a medical image as inputs. The AI system then demonstrated a cognitive workflow, involving text analysis, image analysis, and reasoning, to process the question and generate the most probable answer. A post demonstration survey was made available to the participants who experienced the demo and tested the question answering system. Of the reported 54,037 meeting registrants, 2,927 visited the demonstration booth, 1,991 experienced the demo, and 1,025 completed a post-demonstration survey. In this paper, the methodology of the survey is shown and a summary of its results are presented. The results of the survey show a very high level of receptiveness to cognitive computing technology and artificial intelligence among radiologists.
Image Matching Using SIFT, SURF, BRIEF and ORB: Performance Comparison for Distorted Images
Oct 07, 2017


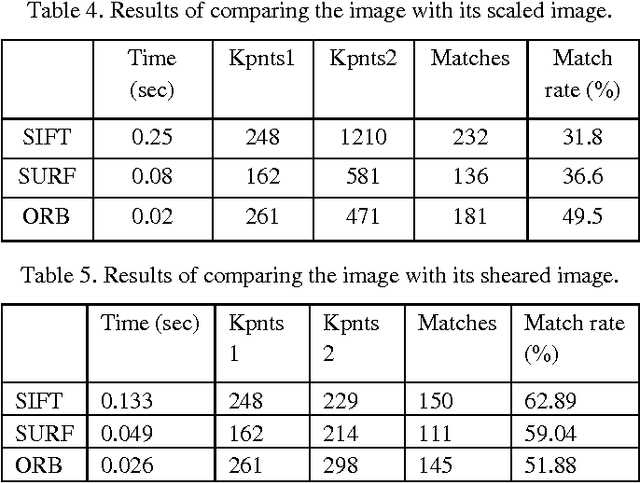
Fast and robust image matching is a very important task with various applications in computer vision and robotics. In this paper, we compare the performance of three different image matching techniques, i.e., SIFT, SURF, and ORB, against different kinds of transformations and deformations such as scaling, rotation, noise, fish eye distortion, and shearing. For this purpose, we manually apply different types of transformations on original images and compute the matching evaluation parameters such as the number of key points in images, the matching rate, and the execution time required for each algorithm and we will show that which algorithm is the best more robust against each kind of distortion. Index Terms-Image matching, scale invariant feature transform (SIFT), speed up robust feature (SURF), robust independent elementary features (BRIEF), oriented FAST, rotated BRIEF (ORB).
SESR: Single Image Super Resolution with Recursive Squeeze and Excitation Networks
Jan 31, 2018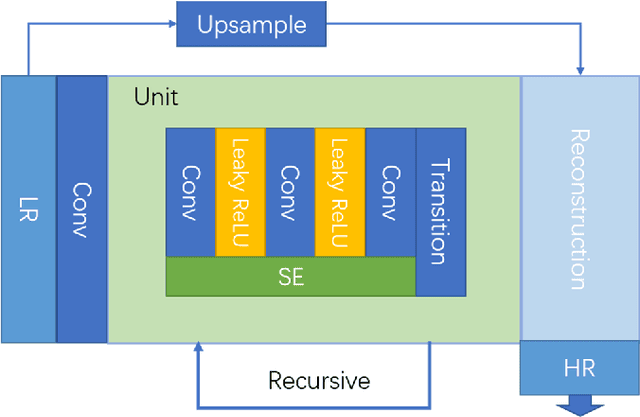
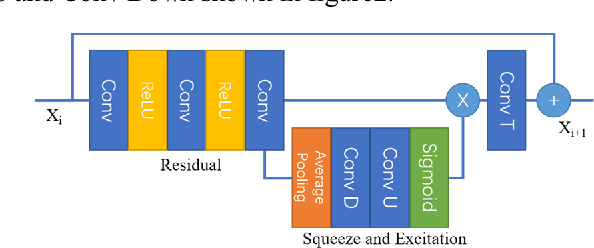
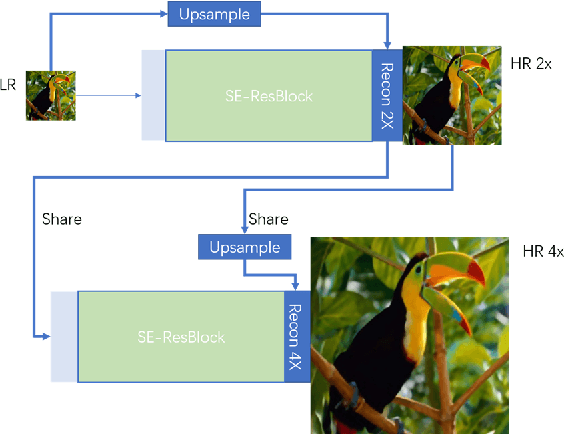

Single image super resolution is a very important computer vision task, with a wide range of applications. In recent years, the depth of the super-resolution model has been constantly increasing, but with a small increase in performance, it has brought a huge amount of computation and memory consumption. In this work, in order to make the super resolution models more effective, we proposed a novel single image super resolution method via recursive squeeze and excitation networks (SESR). By introducing the squeeze and excitation module, our SESR can model the interdependencies and relationships between channels and that makes our model more efficiency. In addition, the recursive structure and progressive reconstruction method in our model minimized the layers and parameters and enabled SESR to simultaneously train multi-scale super resolution in a single model. After evaluating on four benchmark test sets, our model is proved to be above the state-of-the-art methods in terms of speed and accuracy.