 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Comprehensive Approach for Learning-based Fully-Automated Inter-slice Motion Correction for Short-Axis Cine Cardiac MR Image Stacks
Oct 03, 2018
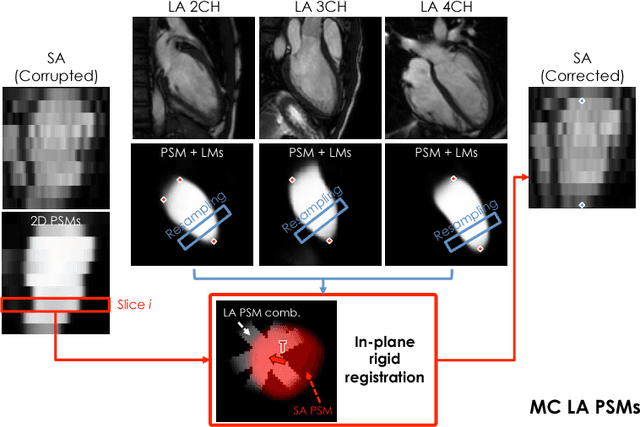
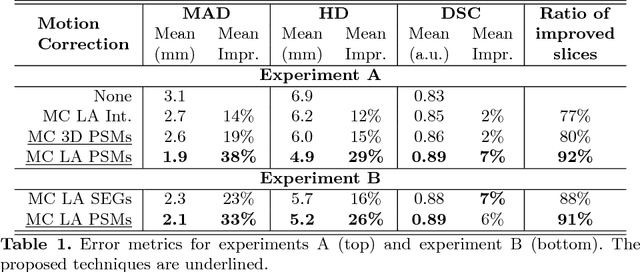
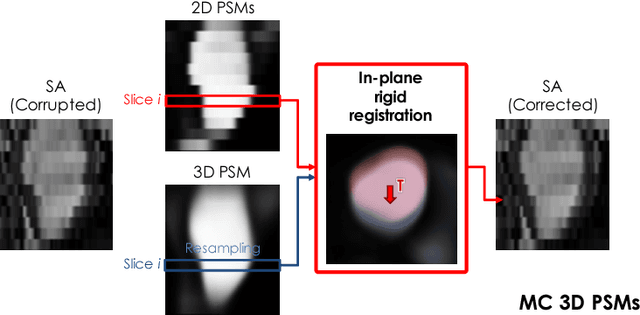
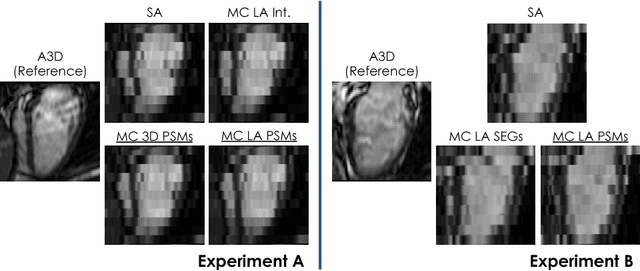
In the clinical routine, short axis (SA) cine cardiac MR (CMR) image stacks are acquired during multiple subsequent breath-holds. If the patient cannot consistently hold the breath at the same position, the acquired image stack will be affected by inter-slice respiratory motion and will not correctly represent the cardiac volume, introducing potential errors in the following analyses and visualisations. We propose an approach to automatically correct inter-slice respiratory motion in SA CMR image stacks. Our approach makes use of probabilistic segmentation maps (PSMs) of the left ventricular (LV) cavity generated with decision forests. PSMs are generated for each slice of the SA stack and rigidly registered in-plane to a target PSM. If long axis (LA) images are available, PSMs are generated for them and combined to create the target PSM; if not, the target PSM is produced from the same stack using a 3D model trained from motion-free stacks. The proposed approach was tested on a dataset of SA stacks acquired from 24 healthy subjects (for which anatomical 3D cardiac images were also available as reference) and compared to two techniques which use LA intensity images and LA segmentations as targets, respectively. The results show the accuracy and robustness of the proposed approach in motion compensation.
Learning Generative Models of Tissue Organization with Supervised GANs
Mar 31, 2020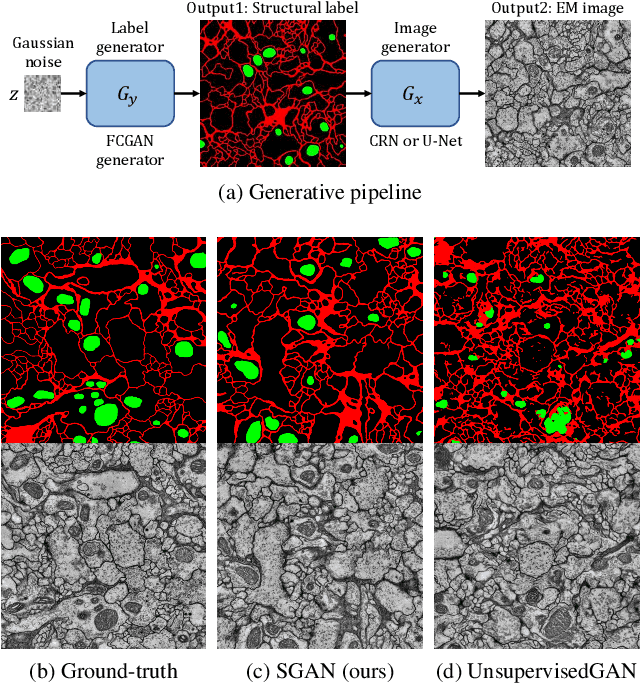
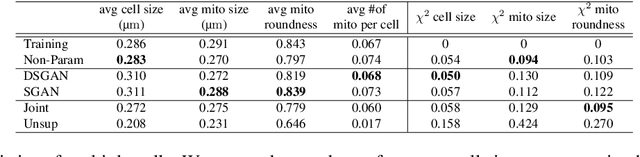
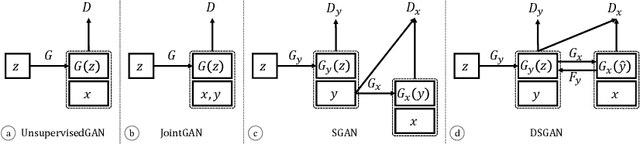
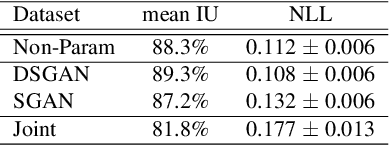
A key step in understanding the spatial organization of cells and tissues is the ability to construct generative models that accurately reflect that organization. In this paper, we focus on building generative models of electron microscope (EM) images in which the positions of cell membranes and mitochondria have been densely annotated, and propose a two-stage procedure that produces realistic images using Generative Adversarial Networks (or GANs) in a supervised way. In the first stage, we synthesize a label "image" given a noise "image" as input, which then provides supervision for EM image synthesis in the second stage. The full model naturally generates label-image pairs. We show that accurate synthetic EM images are produced using assessment via (1) shape features and global statistics, (2) segmentation accuracies, and (3) user studies. We also demonstrate further improvements by enforcing a reconstruction loss on intermediate synthetic labels and thus unifying the two stages into one single end-to-end framework.
Rendering Natural Camera Bokeh Effect with Deep Learning
Jun 10, 2020



Bokeh is an important artistic effect used to highlight the main object of interest on the photo by blurring all out-of-focus areas. While DSLR and system camera lenses can render this effect naturally, mobile cameras are unable to produce shallow depth-of-field photos due to a very small aperture diameter of their optics. Unlike the current solutions simulating bokeh by applying Gaussian blur to image background, in this paper we propose to learn a realistic shallow focus technique directly from the photos produced by DSLR cameras. For this, we present a large-scale bokeh dataset consisting of 5K shallow / wide depth-of-field image pairs captured using the Canon 7D DSLR with 50mm f/1.8 lenses. We use these images to train a deep learning model to reproduce a natural bokeh effect based on a single narrow-aperture image. The experimental results show that the proposed approach is able to render a plausible non-uniform bokeh even in case of complex input data with multiple objects. The dataset, pre-trained models and codes used in this paper are available on the project website.
Recurrent Exposure Generation for Low-Light Face Detection
Jul 21, 2020
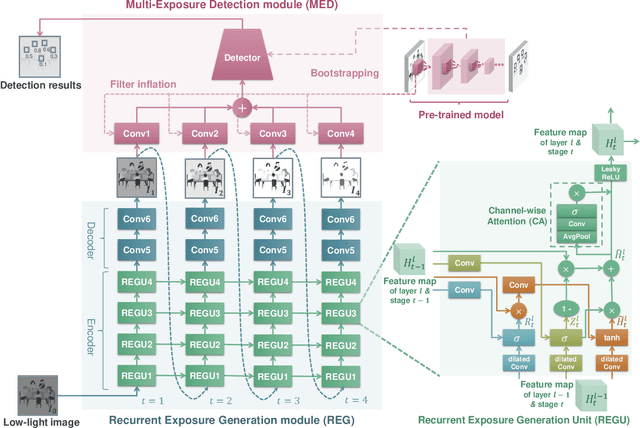
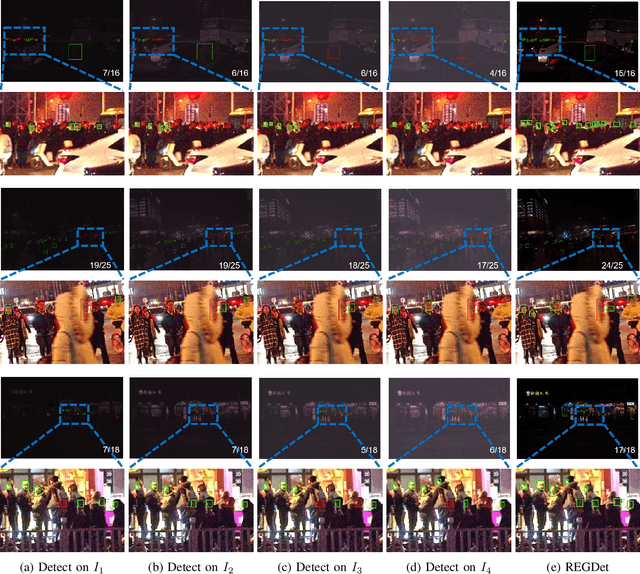
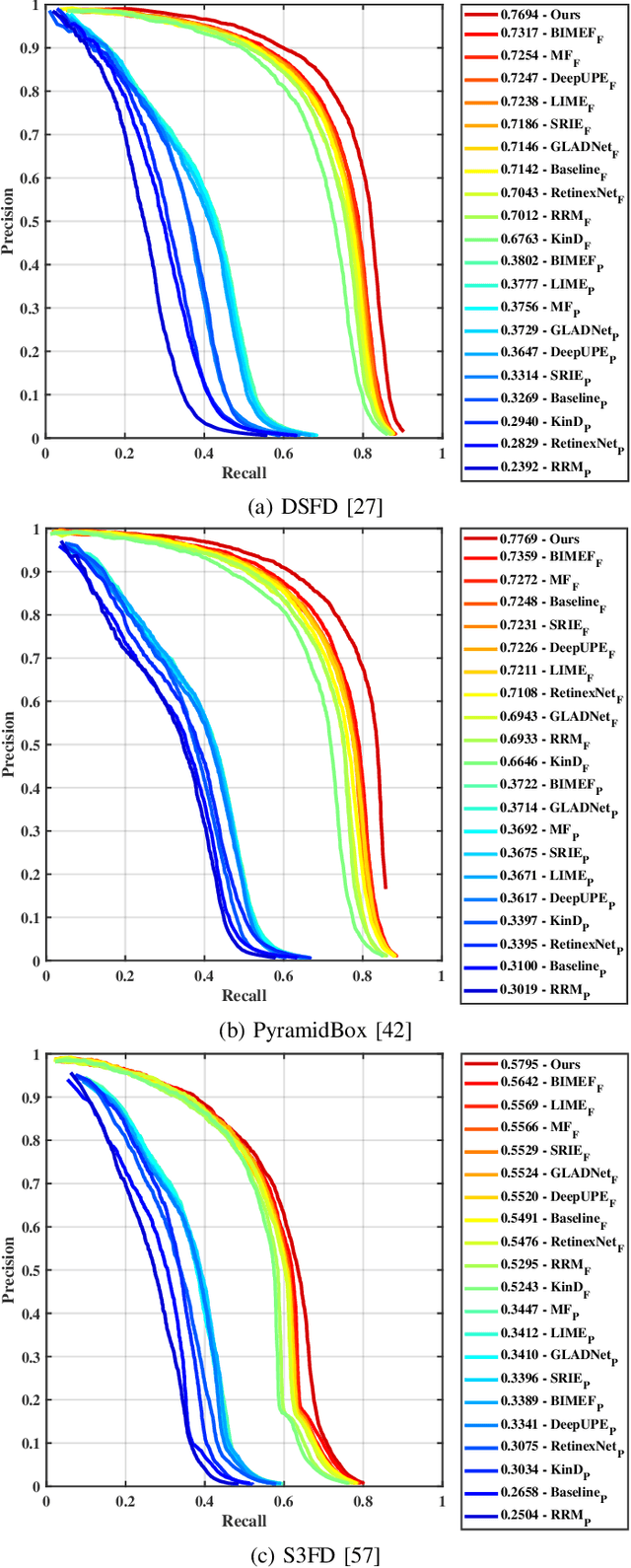
Face detection from low-light images is challenging due to limited photos and inevitable noise, which, to make the task even harder, are often spatially unevenly distributed. A natural solution is to borrow the idea from multi-exposure, which captures multiple shots to obtain well-exposed images under challenging conditions. High-quality implementation/approximation of multi-exposure from a single image is however nontrivial. Fortunately, as shown in this paper, neither is such high-quality necessary since our task is face detection rather than image enhancement. Specifically, we propose a novel Recurrent Exposure Generation (REG) module and couple it seamlessly with a Multi-Exposure Detection (MED) module, and thus significantly improve face detection performance by effectively inhibiting non-uniform illumination and noise issues. REG produces progressively and efficiently intermediate images corresponding to various exposure settings, and such pseudo-exposures are then fused by MED to detect faces across different lighting conditions. The proposed method, named REGDet, is the first `detection-with-enhancement' framework for low-light face detection. It not only encourages rich interaction and feature fusion across different illumination levels, but also enables effective end-to-end learning of the REG component to be better tailored for face detection. Moreover, as clearly shown in our experiments, REG can be flexibly coupled with different face detectors without extra low/normal-light image pairs for training. We tested REGDet on the DARK FACE low-light face benchmark with thorough ablation study, where REGDet outperforms previous state-of-the-arts by a significant margin, with only negligible extra parameters.
PandaNet : Anchor-Based Single-Shot Multi-Person 3D Pose Estimation
Jan 07, 2021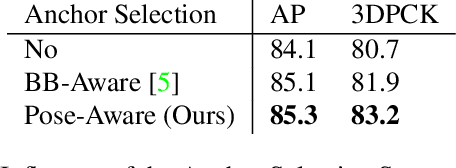

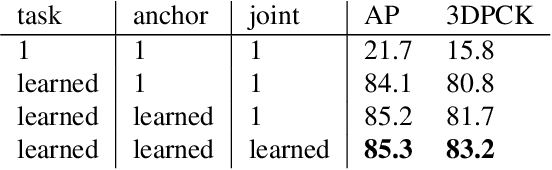

Recently, several deep learning models have been proposed for 3D human pose estimation. Nevertheless, most of these approaches only focus on the single-person case or estimate 3D pose of a few people at high resolution. Furthermore, many applications such as autonomous driving or crowd analysis require pose estimation of a large number of people possibly at low-resolution. In this work, we present PandaNet (Pose estimAtioN and Dectection Anchor-based Network), a new single-shot, anchor-based and multi-person 3D pose estimation approach. The proposed model performs bounding box detection and, for each detected person, 2D and 3D pose regression into a single forward pass. It does not need any post-processing to regroup joints since the network predicts a full 3D pose for each bounding box and allows the pose estimation of a possibly large number of people at low resolution. To manage people overlapping, we introduce a Pose-Aware Anchor Selection strategy. Moreover, as imbalance exists between different people sizes in the image, and joints coordinates have different uncertainties depending on these sizes, we propose a method to automatically optimize weights associated to different people scales and joints for efficient training. PandaNet surpasses previous single-shot methods on several challenging datasets: a multi-person urban virtual but very realistic dataset (JTA Dataset), and two real world 3D multi-person datasets (CMU Panoptic and MuPoTS-3D).
A Number Sense as an Emergent Property of the Manipulating Brain
Dec 08, 2020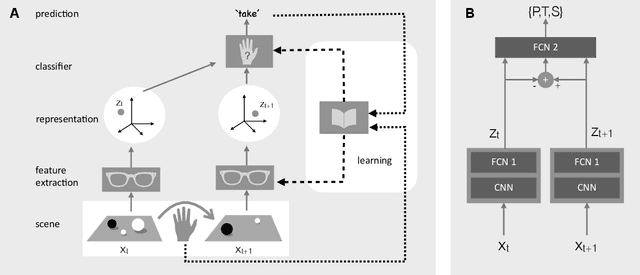
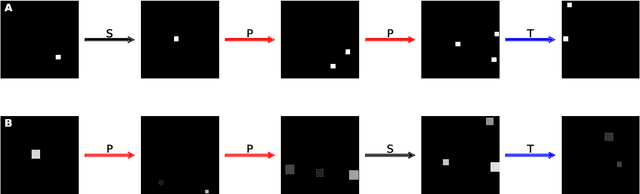
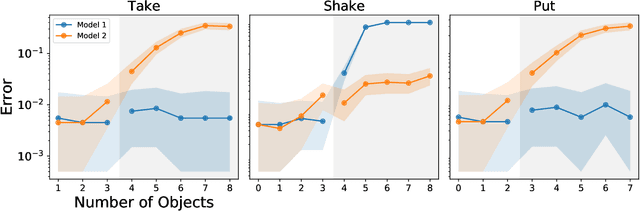
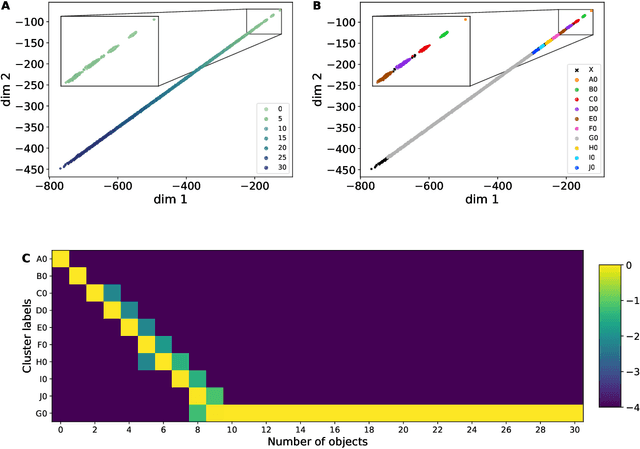
The ability to understand and manipulate numbers and quantities emerges during childhood, but the mechanism through which this ability is developed is still poorly understood. In particular, it is not known whether acquiring such a {\em number sense} is possible without supervision from a teacher. To explore this question, we propose a model in which spontaneous and undirected manipulation of small objects trains perception to predict the resulting scene changes. We find that, from this task, an image representation emerges that exhibits regularities that foreshadow numbers and quantity. These include distinct categories for zero and the first few natural numbers, a notion of order, and a signal that correlates with numerical quantity. As a result, our model acquires the ability to estimate the number of objects in the scene, as well as {\em subitization}, i.e. the ability to recognize at a glance the exact number of objects in small scenes. We conclude that important aspects of a facility with numbers and quantities may be learned without explicit teacher supervision.
ILGNet: Inception Modules with Connected Local and Global Features for Efficient Image Aesthetic Quality Classification using Domain Adaptation
Apr 29, 2018
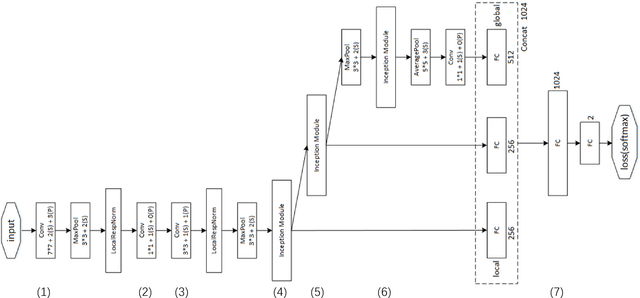
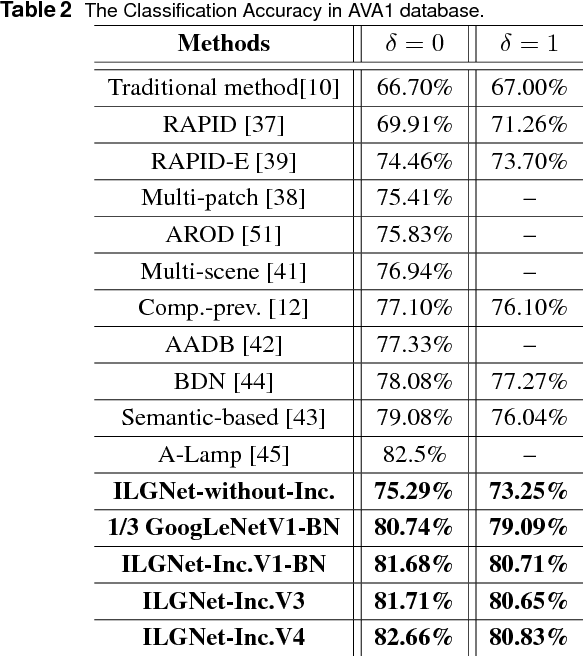
In this paper, we address a challenging problem of aesthetic image classification, which is to label an input image as high or low aesthetic quality. We take both the local and global features of images into consideration. A novel deep convolutional neural network named ILGNet is proposed, which combines both the Inception modules and an connected layer of both Local and Global features. The ILGnet is based on GoogLeNet. Thus, it is easy to use a pre-trained GoogLeNet for large-scale image classification problem and fine tune our connected layers on an large scale database of aesthetic related images: AVA, i.e. \emph{domain adaptation}. The experiments reveal that our model achieves the state of the arts in AVA database. Both the training and testing speeds of our model are higher than those of the original GoogLeNet.
Probabilistic Pixel-Adaptive Refinement Networks
Mar 31, 2020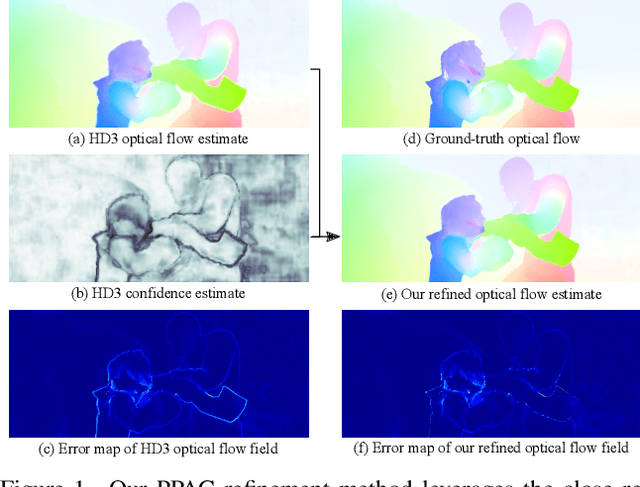
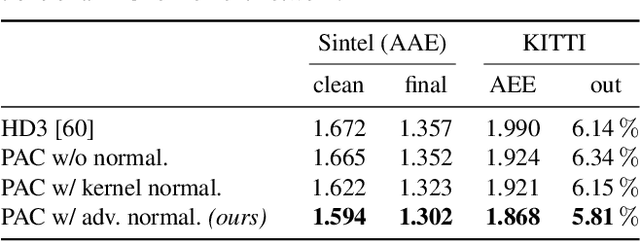
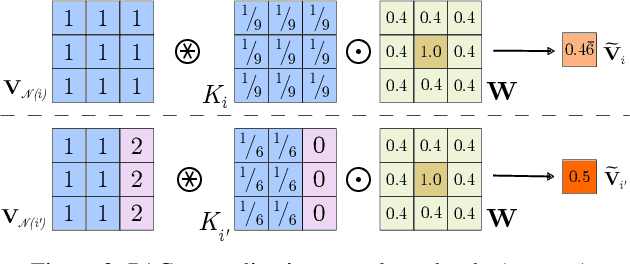
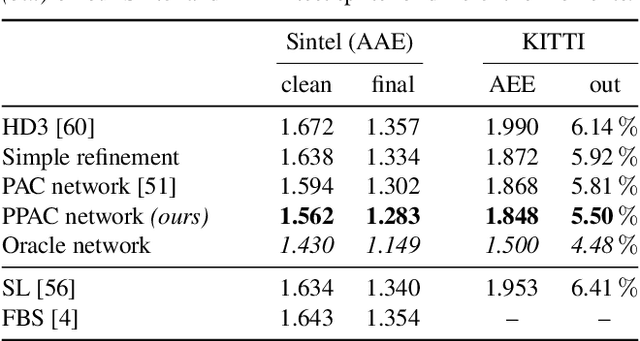
Encoder-decoder networks have found widespread use in various dense prediction tasks. However, the strong reduction of spatial resolution in the encoder leads to a loss of location information as well as boundary artifacts. To address this, image-adaptive post-processing methods have shown beneficial by leveraging the high-resolution input image(s) as guidance data. We extend such approaches by considering an important orthogonal source of information: the network's confidence in its own predictions. We introduce probabilistic pixel-adaptive convolutions (PPACs), which not only depend on image guidance data for filtering, but also respect the reliability of per-pixel predictions. As such, PPACs allow for image-adaptive smoothing and simultaneously propagating pixels of high confidence into less reliable regions, while respecting object boundaries. We demonstrate their utility in refinement networks for optical flow and semantic segmentation, where PPACs lead to a clear reduction in boundary artifacts. Moreover, our proposed refinement step is able to substantially improve the accuracy on various widely used benchmarks.
A Retinex based GAN Pipeline to Utilize Paired and Unpaired Datasets for Enhancing Low Light Images
Jun 27, 2020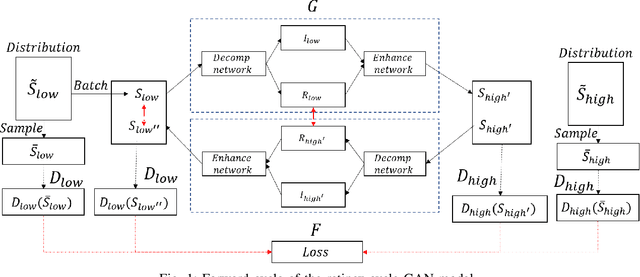
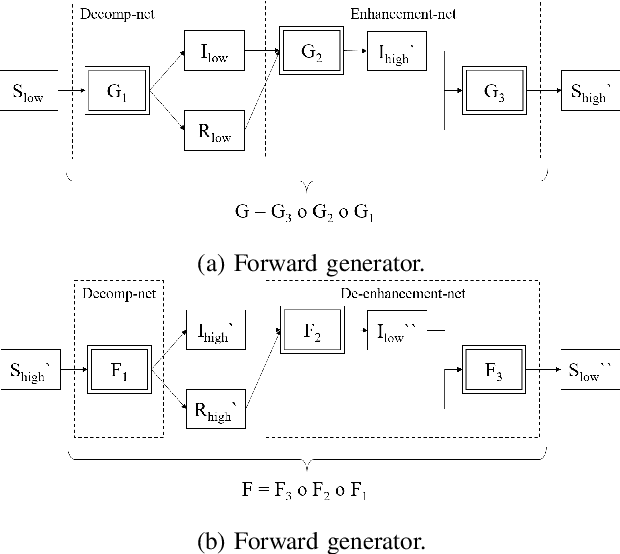
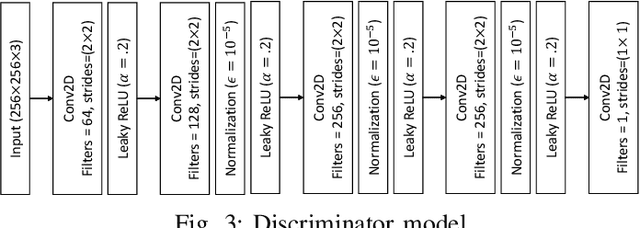

Low light image enhancement is an important challenge for the development of robust computer vision algorithms. The machine learning approaches to this have been either unsupervised, supervised based on paired dataset or supervised based on unpaired dataset. This paper presents a novel deep learning pipeline that can learn from both paired and unpaired datasets. Convolution Neural Networks (CNNs) that are optimized to minimize standard loss, and Generative Adversarial Networks (GANs) that are optimized to minimize the adversarial loss are used to achieve different steps of the low light image enhancement process. Cycle consistency loss and a patched discriminator are utilized to further improve the performance. The paper also analyses the functionality and the performance of different components, hidden layers, and the entire pipeline.
Learning to Rearrange Deformable Cables, Fabrics, and Bags with Goal-Conditioned Transporter Networks
Dec 18, 2020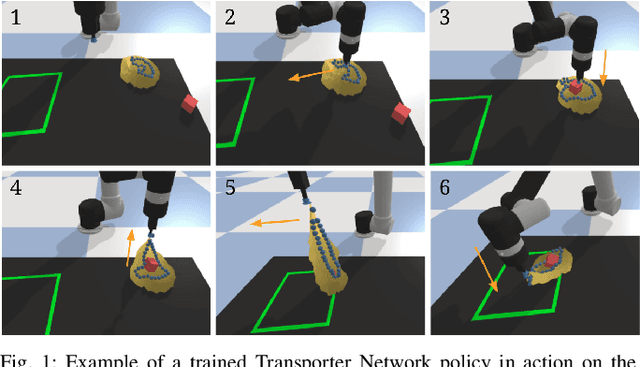
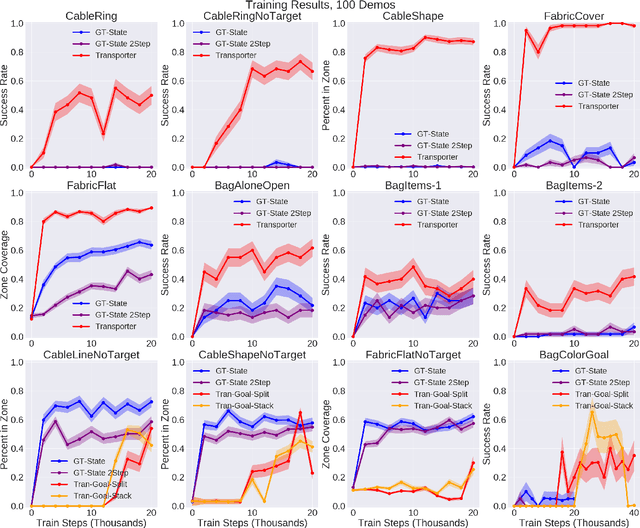
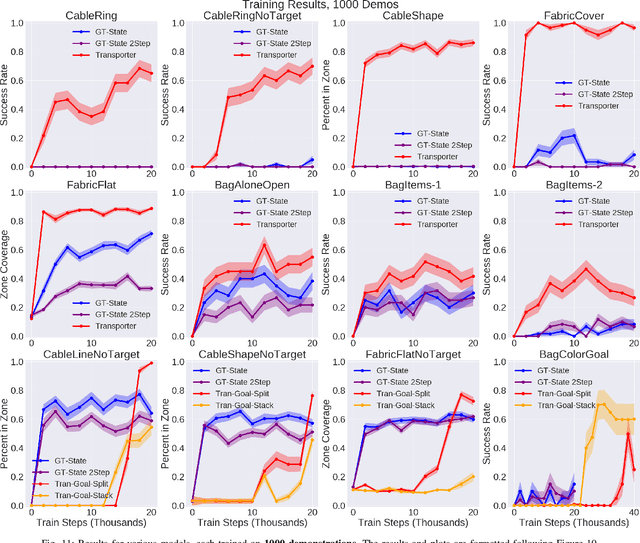
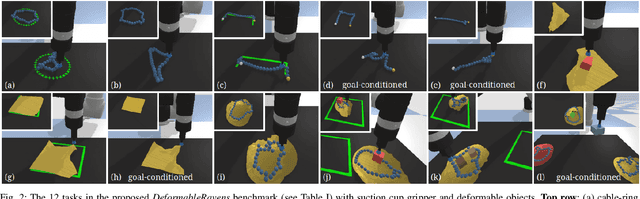
Rearranging and manipulating deformable objects such as cables, fabrics, and bags is a long-standing challenge in robotic manipulation. The complex dynamics and high-dimensional configuration spaces of deformables, compared to rigid objects, make manipulation difficult not only for multi-step planning, but even for goal specification. Goals cannot be as easily specified as rigid object poses, and may involve complex relative spatial relations such as "place the item inside the bag". In this work, we develop a suite of simulated benchmarks with 1D, 2D, and 3D deformable structures, including tasks that involve image-based goal-conditioning and multi-step deformable manipulation. We propose embedding goal-conditioning into Transporter Networks, a recently proposed model architecture for learning robotic manipulation that rearranges deep features to infer displacements that can represent pick and place actions. We demonstrate that goal-conditioned Transporter Networks enable agents to manipulate deformable structures into flexibly specified configurations without test-time visual anchors for target locations. We also significantly extend prior results using Transporter Networks for manipulating deformable objects by testing on tasks with 2D and 3D deformables. Supplementary material is available at https://berkeleyautomation.github.io/bags/.