 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Differential Morphed Face Detection Using Deep Siamese Networks
Dec 02, 2020
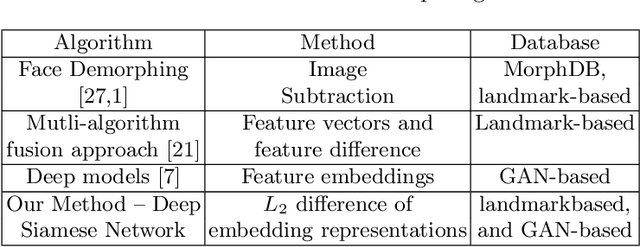

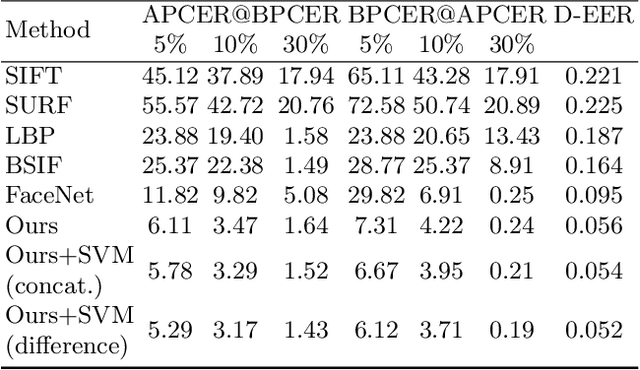
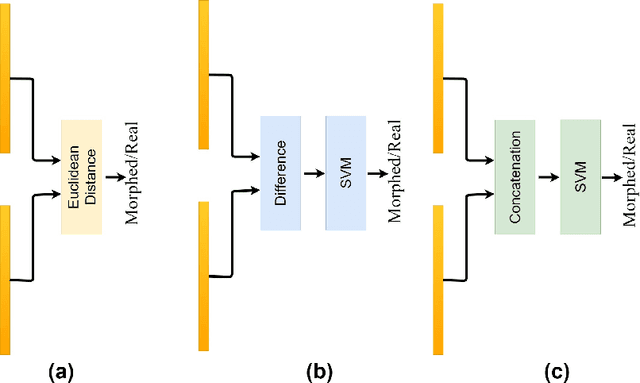
Although biometric facial recognition systems are fast becoming part of security applications, these systems are still vulnerable to morphing attacks, in which a facial reference image can be verified as two or more separate identities. In border control scenarios, a successful morphing attack allows two or more people to use the same passport to cross borders. In this paper, we propose a novel differential morph attack detection framework using a deep Siamese network. To the best of our knowledge, this is the first research work that makes use of a Siamese network architecture for morph attack detection. We compare our model with other classical and deep learning models using two distinct morph datasets, VISAPP17 and MorGAN. We explore the embedding space generated by the contrastive loss using three decision making frameworks using Euclidean distance, feature difference and a support vector machine classifier, and feature concatenation and a support vector machine classifier.
Riemannian kernel based Nyström method for approximate infinite-dimensional covariance descriptors with application to image set classification
Jun 16, 2018
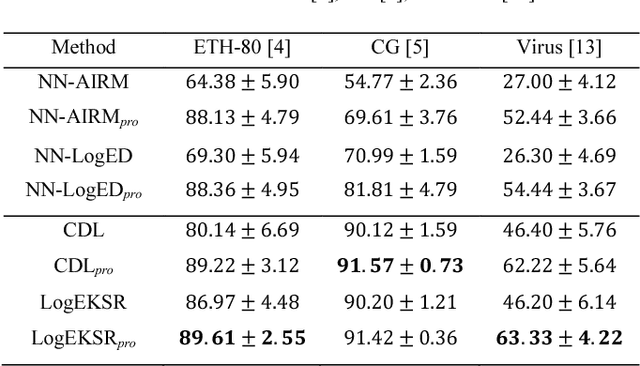
In the domain of pattern recognition, using the CovDs (Covariance Descriptors) to represent data and taking the metrics of the resulting Riemannian manifold into account have been widely adopted for the task of image set classification. Recently, it has been proven that infinite-dimensional CovDs are more discriminative than their low-dimensional counterparts. However, the form of infinite-dimensional CovDs is implicit and the computational load is high. We propose a novel framework for representing image sets by approximating infinite-dimensional CovDs in the paradigm of the Nystr\"om method based on a Riemannian kernel. We start by modeling the images via CovDs, which lie on the Riemannian manifold spanned by SPD (Symmetric Positive Definite) matrices. We then extend the Nystr\"om method to the SPD manifold and obtain the approximations of CovDs in RKHS (Reproducing Kernel Hilbert Space). Finally, we approximate infinite-dimensional CovDs via these approximations. Empirically, we apply our framework to the task of image set classification. The experimental results obtained on three benchmark datasets show that our proposed approximate infinite-dimensional CovDs outperform the original CovDs.
Multi-Objective CNN Based Algorithm for SAR Despeckling
Jun 16, 2020
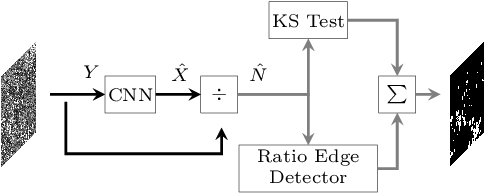

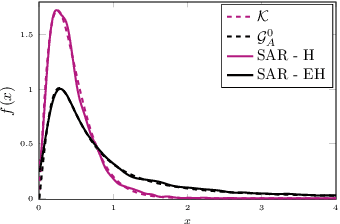
Deep learning (DL) in remote sensing has nowadays became an effective operative tool: it is largely used in applications such as change detection, image restoration, segmentation, detection and classification. With reference to synthetic aperture radar (SAR) domain the application of DL techniques is not straightforward due to non trivial interpretation of SAR images, specially caused by the presence of speckle. Several deep learning solutions for SAR despeckling have been proposed in the last few years. Most of these solutions focus on the definition of different network architectures with similar cost functions not involving SAR image properties. In this paper, a convolutional neural network (CNN) with a multi-objective cost function taking care of spatial and statistical properties of the SAR image is proposed. This is achieved by the definition of a peculiar loss function obtained by the weighted combination of three different terms. Each of this term is dedicated mainly to one of the following SAR image characteristics: spatial details, speckle statistical properties and strong scatterers preservation. Their combination allows to balance these effects. Moreover, a specifically designed architecture is proposed for effectively extract distinctive features within the considered framework. Experiments on simulated and real SAR images show the accuracy of the proposed method compared to the State-of-Art despeckling algorithms, both from quantitative and qualitative point of view. The importance of considering such SAR properties in the cost function is crucial for a correct noise rejection and object preservation in different underlined scenarios, such as homogeneous, heterogeneous and extremely heterogeneous.
Generative Multi-Label Zero-Shot Learning
Jan 28, 2021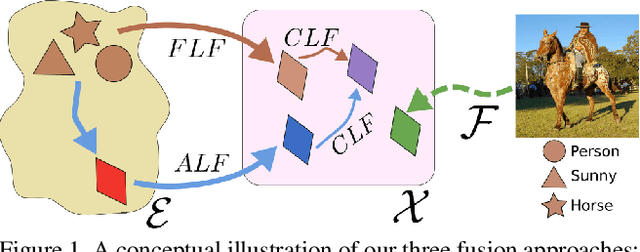
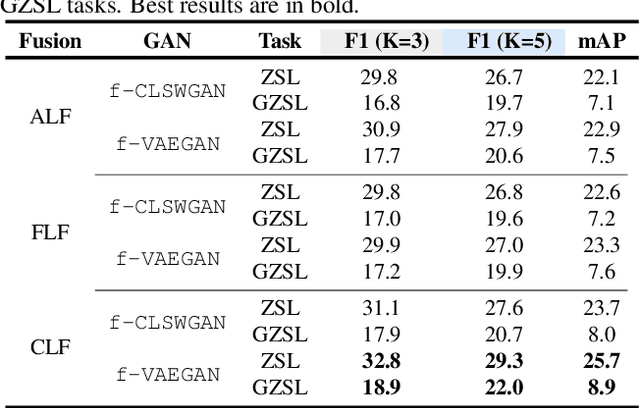
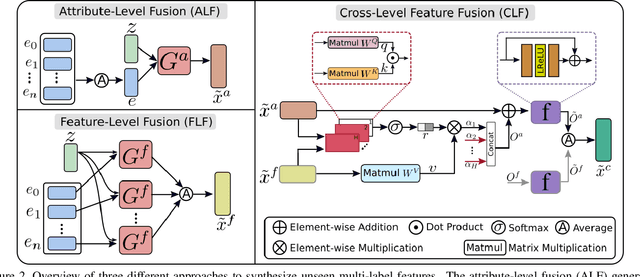
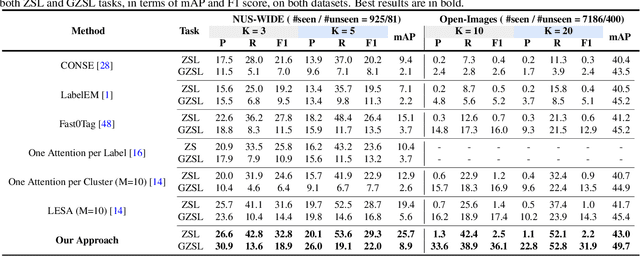
Multi-label zero-shot learning strives to classify images into multiple unseen categories for which no data is available during training. The test samples can additionally contain seen categories in the generalized variant. Existing approaches rely on learning either shared or label-specific attention from the seen classes. Nevertheless, computing reliable attention maps for unseen classes during inference in a multi-label setting is still a challenge. In contrast, state-of-the-art single-label generative adversarial network (GAN) based approaches learn to directly synthesize the class-specific visual features from the corresponding class attribute embeddings. However, synthesizing multi-label features from GANs is still unexplored in the context of zero-shot setting. In this work, we introduce different fusion approaches at the attribute-level, feature-level and cross-level (across attribute and feature-levels) for synthesizing multi-label features from their corresponding multi-label class embedding. To the best of our knowledge, our work is the first to tackle the problem of multi-label feature synthesis in the (generalized) zero-shot setting. Comprehensive experiments are performed on three zero-shot image classification benchmarks: NUS-WIDE, Open Images and MS COCO. Our cross-level fusion-based generative approach outperforms the state-of-the-art on all three datasets. Furthermore, we show the generalization capabilities of our fusion approach in the zero-shot detection task on MS COCO, achieving favorable performance against existing methods. The source code is available at https://github.com/akshitac8/Generative_MLZSL.
A Learning-based Method for Online Adjustment of C-arm Cone-Beam CT Source Trajectories for Artifact Avoidance
Aug 14, 2020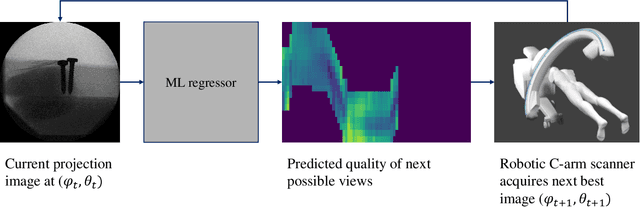
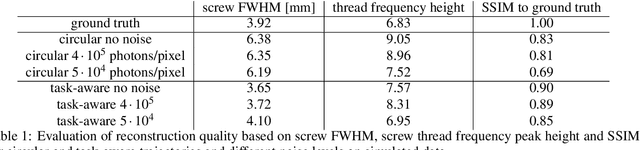
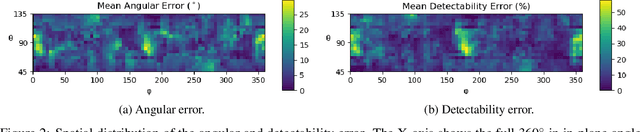
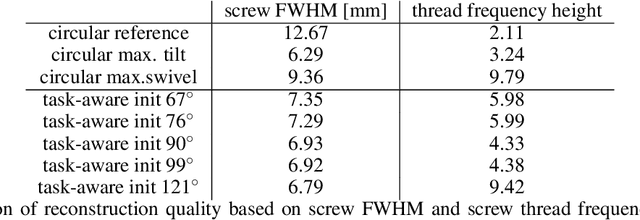
During spinal fusion surgery, screws are placed close to critical nerves suggesting the need for highly accurate screw placement. Verifying screw placement on high-quality tomographic imaging is essential. C-arm Cone-beam CT (CBCT) provides intraoperative 3D tomographic imaging which would allow for immediate verification and, if needed, revision. However, the reconstruction quality attainable with commercial CBCT devices is insufficient, predominantly due to severe metal artifacts in the presence of pedicle screws. These artifacts arise from a mismatch between the true physics of image formation and an idealized model thereof assumed during reconstruction. Prospectively acquiring views onto anatomy that are least affected by this mismatch can, therefore, improve reconstruction quality. We propose to adjust the C-arm CBCT source trajectory during the scan to optimize reconstruction quality with respect to a certain task, i.e. verification of screw placement. Adjustments are performed on-the-fly using a convolutional neural network that regresses a quality index for possible next views given the current x-ray image. Adjusting the CBCT trajectory to acquire the recommended views results in non-circular source orbits that avoid poor images, and thus, data inconsistencies. We demonstrate that convolutional neural networks trained on realistically simulated data are capable of predicting quality metrics that enable scene-specific adjustments of the CBCT source trajectory. Using both realistically simulated data and real CBCT acquisitions of a semi-anthropomorphic phantom, we show that tomographic reconstructions of the resulting scene-specific CBCT acquisitions exhibit improved image quality particularly in terms of metal artifacts. Since the optimization objective is implicitly encoded in a neural network, the proposed approach overcomes the need for 3D information at run-time.
Machine-learned Regularization and Polygonization of Building Segmentation Masks
Aug 03, 2020
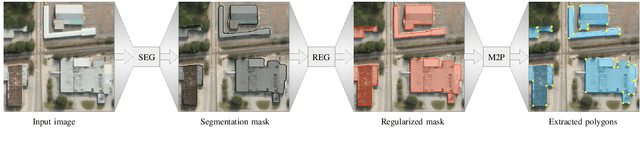
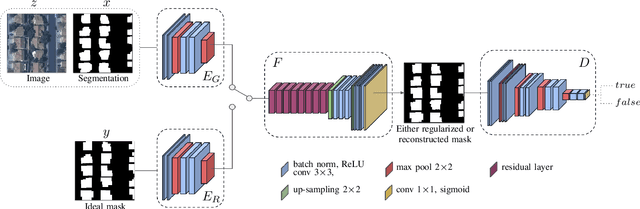
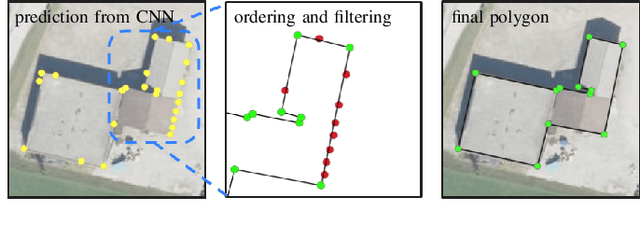
We propose a machine learning based approach for automatic regularization and polygonization of building segmentation masks. Taking an image as input, we first predict building segmentation maps exploiting generic fully convolutional network (FCN). A generative adversarial network (GAN) is then involved to perform a regularization of building boundaries to make them more realistic, i.e., having more rectilinear outlines which construct right angles if required. This is achieved through the interplay between the discriminator which gives a probability of input image being true and generator that learns from discriminator's response to create more realistic images. Finally, we train the backbone convolutional neural network (CNN) which is adapted to predict sparse outcomes corresponding to building corners out of regularized building segmentation results. Experiments on three building segmentation datasets demonstrate that the proposed method is not only capable of obtaining accurate results, but also of producing visually pleasing building outlines parameterized as polygons.
SRFlow: Learning the Super-Resolution Space with Normalizing Flow
Jun 25, 2020

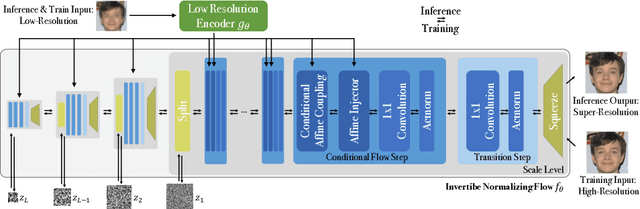
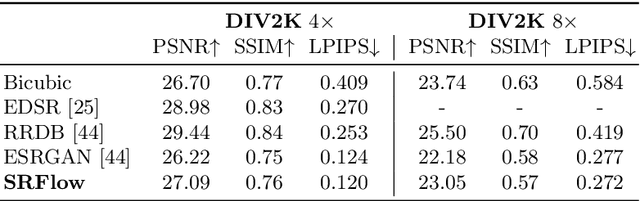
Super-resolution is an ill-posed problem, since it allows for multiple predictions for a given low-resolution image. This fundamental fact is largely ignored by state-of-the-art deep learning based approaches. These methods instead train a deterministic mapping using combinations of reconstruction and adversarial losses. In this work, we therefore propose SRFlow: a normalizing flow based super-resolution method capable of learning the conditional distribution of the output given the low-resolution input. Our model is trained in a principled manner using a single loss, namely the negative log-likelihood. SRFlow therefore directly accounts for the ill-posed nature of the problem, and learns to predict diverse photo-realistic high-resolution images. Moreover, we utilize the strong image posterior learned by SRFlow to design flexible image manipulation techniques, capable of enhancing super-resolved images by, e.g., transferring content from other images. We perform extensive experiments on faces, as well as on super-resolution in general. SRFlow outperforms state-of-the-art GAN-based approaches in terms of both PSNR and perceptual quality metrics, while allowing for diversity through the exploration of the space of super-resolved solutions.
BOP Challenge 2020 on 6D Object Localization
Sep 15, 2020
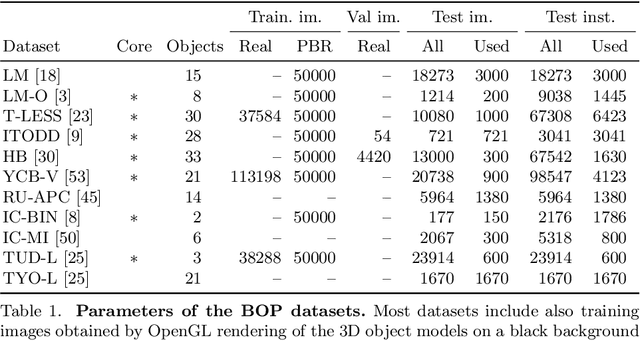

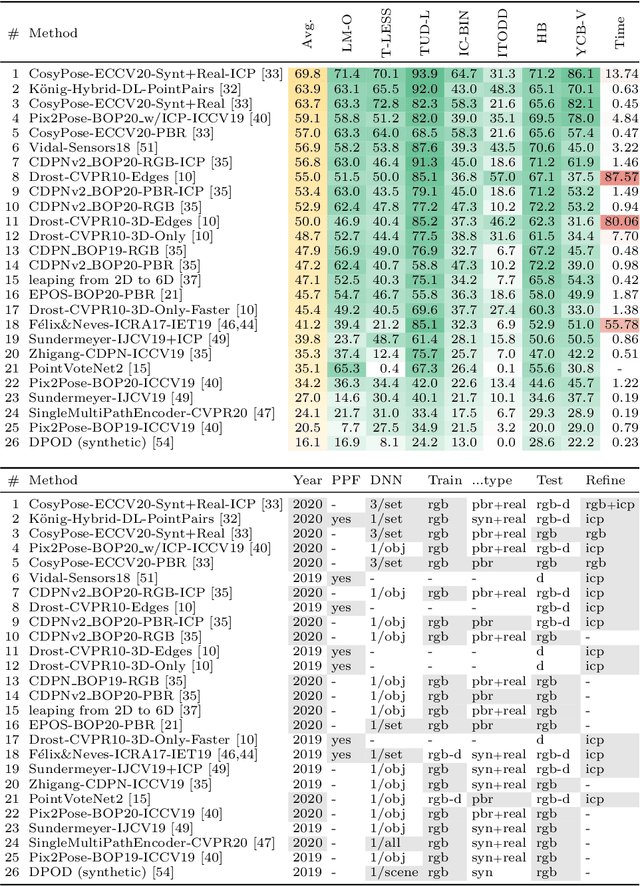
This paper presents the evaluation methodology, datasets, and results of the BOP Challenge 2020, the third in a series of public competitions organized with the goal to capture the status quo in the field of 6D object pose estimation from an RGB-D image. In 2020, to reduce the domain gap between synthetic training and real test RGB images, the participants were provided 350K photorealistic trainining images generated by BlenderProc4BOP, a~new open-source and light-weight physically-based renderer (PBR) and procedural data generator. Methods based on deep neural networks have finally caught up with methods based on point pair features, which were dominating previous editions of the challenge. Although the top-performing methods rely on RGB-D image channels, strong results were achieved when only RGB channels were used at both training and test time -- out of 26 evaluated methods, the third method was trained on RGB channels of PBR and real images, while the fifth was trained on PBR images only. Strong data augmentation was identified as a key component of the top-performing CosyPose method, and the photorealism of PBR images was demonstrated effective despite the augmentation. The online evaluation system stays open and is available at the project website: bop.felk.cvut.cz.
IntroVAC: Introspective Variational Classifiers for Learning Interpretable Latent Subspaces
Aug 03, 2020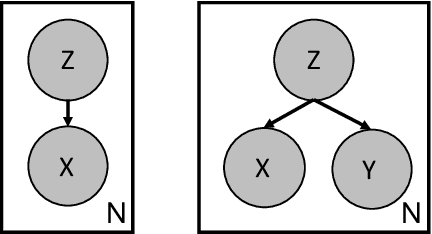

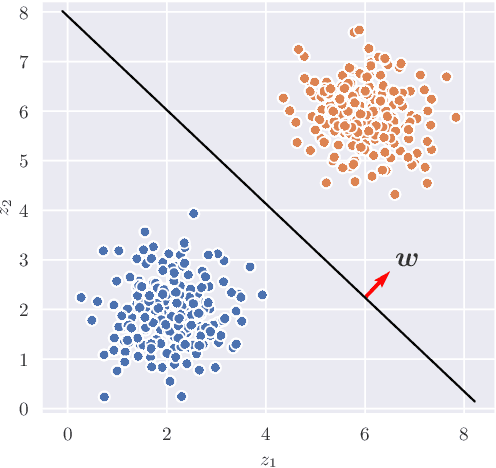

Learning useful representations of complex data has been the subject of extensive research for many years. With the diffusion of Deep Neural Networks, Variational Autoencoders have gained lots of attention since they provide an explicit model of the data distribution based on an encoder/decoder architecture which is able to both generate images and encode them in a low-dimensional subspace. However, the latent space is not easily interpretable and the generation capabilities show some limitations since images typically look blurry and lack details. In this paper, we propose the Introspective Variational Classifier (IntroVAC), a model that learns interpretable latent subspaces by exploiting information from an additional label and provides improved image quality thanks to an adversarial training strategy.We show that IntroVAC is able to learn meaningful directions in the latent space enabling fine-grained manipulation of image attributes. We validate our approach on the CelebA dataset.
Deep Neural Networks for No-Reference and Full-Reference Image Quality Assessment
Dec 07, 2017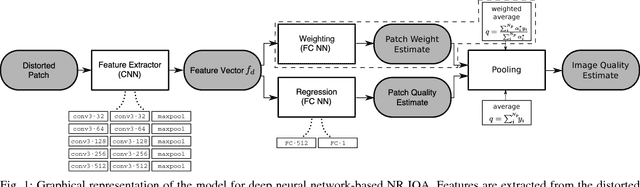
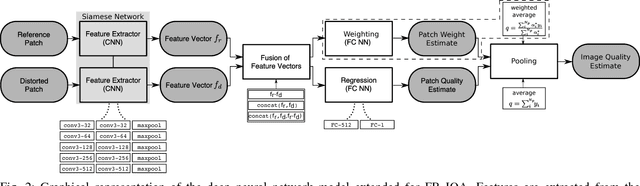
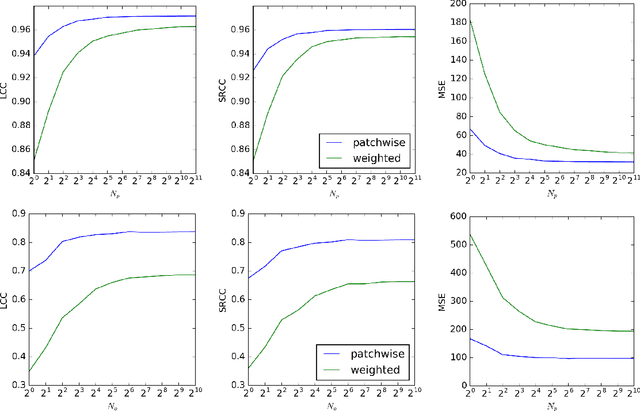
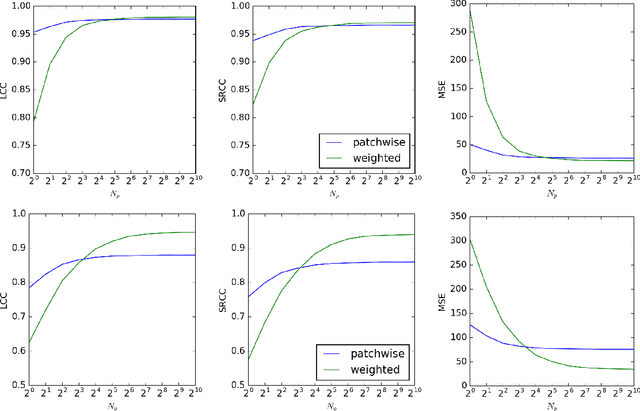
We present a deep neural network-based approach to image quality assessment (IQA). The network is trained end-to-end and comprises ten convolutional layers and five pooling layers for feature extraction, and two fully connected layers for regression, which makes it significantly deeper than related IQA models. Unique features of the proposed architecture are that: 1) with slight adaptations it can be used in a no-reference (NR) as well as in a full-reference (FR) IQA setting and 2) it allows for joint learning of local quality and local weights, i.e., relative importance of local quality to the global quality estimate, in an unified framework. Our approach is purely data-driven and does not rely on hand-crafted features or other types of prior domain knowledge about the human visual system or image statistics. We evaluate the proposed approach on the LIVE, CISQ, and TID2013 databases as well as the LIVE In the wild image quality challenge database and show superior performance to state-of-the-art NR and FR IQA methods. Finally, cross-database evaluation shows a high ability to generalize between different databases, indicating a high robustness of the learned features.