 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Method to Classify Skin Lesions using Dermoscopic images
Aug 21, 2020
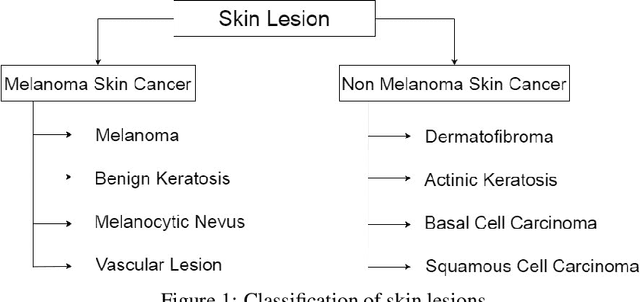
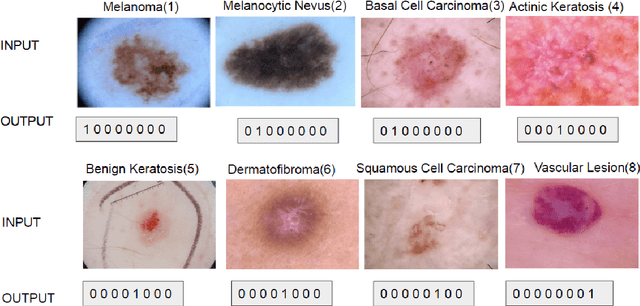

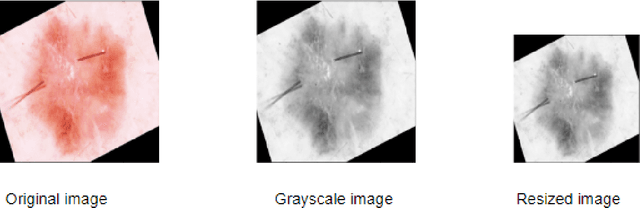
Skin cancer is the most common cancer in the existing world constituting one-third of the cancer cases. Benign skin cancers are not fatal, can be cured with proper medication. But it is not the same as the malignant skin cancers. In the case of malignant melanoma, in its peak stage, the maximum life expectancy is less than or equal to 5 years. But, it can be cured if detected in early stages. Though there are numerous clinical procedures, the accuracy of diagnosis falls between 49% to 81% and is time-consuming. So, dermoscopy has been brought into the picture. It helped in increasing the accuracy of diagnosis but could not demolish the error-prone behaviour. A quick and less error-prone solution is needed to diagnose this majorly growing skin cancer. This project deals with the usage of deep learning in skin lesion classification. In this project, an automated model for skin lesion classification using dermoscopic images has been developed with CNN(Convolution Neural Networks) as a training model. Convolution neural networks are known for capturing features of an image. So, they are preferred in analyzing medical images to find the characteristics that drive the model towards success. Techniques like data augmentation for tackling class imbalance, segmentation for focusing on the region of interest and 10-fold cross-validation to make the model robust have been brought into the picture. This project also includes usage of certain preprocessing techniques like brightening the images using piece-wise linear transformation function, grayscale conversion of the image, resize the image. This project throws a set of valuable insights on how the accuracy of the model hikes with the bringing of new input strategies, preprocessing techniques. The best accuracy this model could achieve is 0.886
Digging Deeper into CRNN Model in Chinese Text Images Recognition
Nov 17, 2020

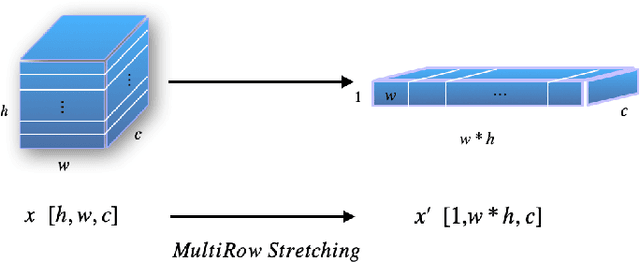
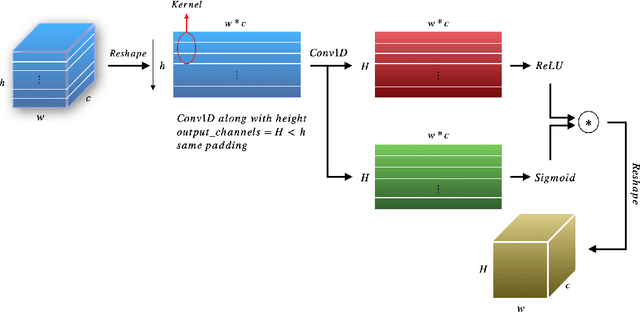
Automatic text image recognition is a prevalent application in computer vision field. One efficient way is use Convolutional Recurrent Neural Network(CRNN) to accomplish task in an end-to-end(End2End) fashion. However, CRNN notoriously fails to detect multi-row images and excel-like images. In this paper, we present one alternative to first recognize single-row images, then extend the same architecture to recognize multi-row images with proposed multiple methods. To recognize excel-like images containing box lines, we propose Line-Deep Denoising Convolutional AutoEncoder(Line-DDeCAE) to recover box lines. Finally, we present one Knowledge Distillation(KD) method to compress original CRNN model without loss of generality. To carry out experiments, we first generate artificial samples from one Chinese novel book, then conduct various experiments to verify our methods.
A Light Field Front-end for Robust SLAM in Dynamic Environments
Dec 19, 2020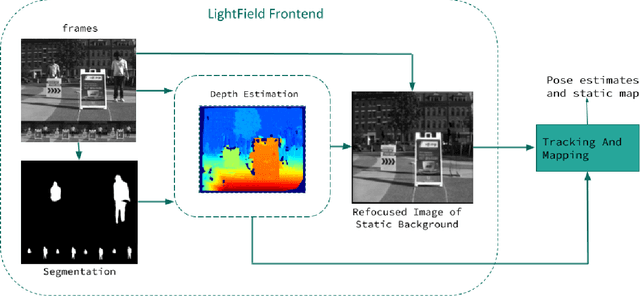
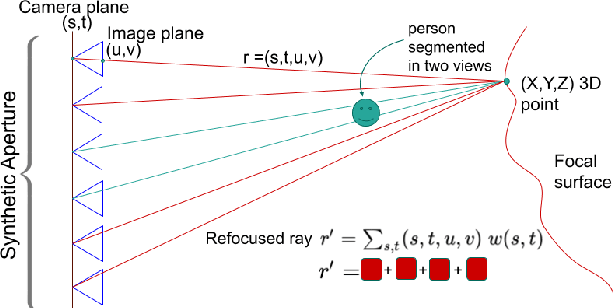
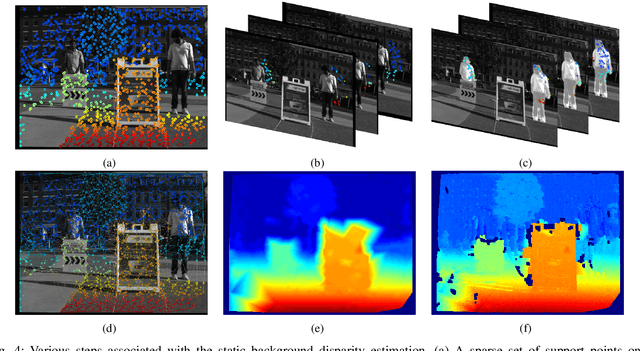
There is a general expectation that robots should operate in urban environments often consisting of potentially dynamic entities including people, furniture and automobiles. Dynamic objects pose challenges to visual SLAM algorithms by introducing errors into the front-end. This paper presents a Light Field SLAM front-end which is robust to dynamic environments. A Light Field captures a bundle of light rays emerging from a single point in space, allowing us to see through dynamic objects occluding the static background via Synthetic Aperture Imaging(SAI). We detect apriori dynamic objects using semantic segmentation and perform semantic guided SAI on the Light Field acquired from a linear camera array. We simultaneously estimate both the depth map and the refocused image of the static background in a single step eliminating the need for static scene initialization. The GPU implementation of the algorithm facilitates running at close to real time speeds of 4 fps. We demonstrate that our method results in improved robustness and accuracy of pose estimation in dynamic environments by comparing it with state of the art SLAM algorithms.
Deep Learning on Real Geophysical Data: A Case Study for Distributed Acoustic Sensing Research
Oct 15, 2020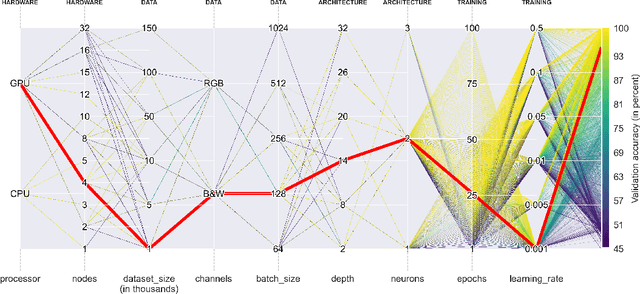
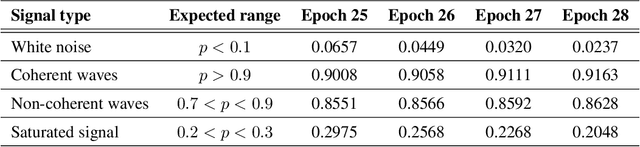
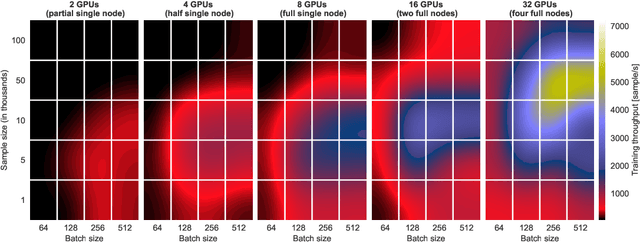
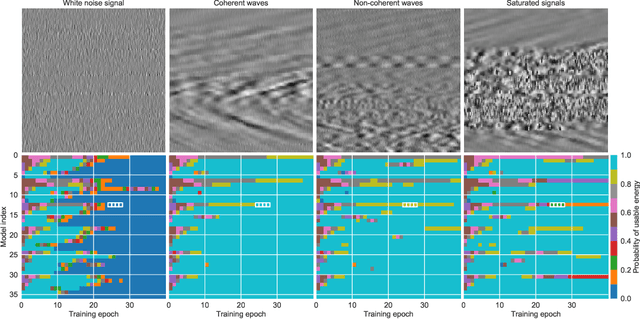
Deep Learning approaches for real, large, and complex scientific data sets can be very challenging to design. In this work, we present a complete search for a finely-tuned and efficiently scaled deep learning classifier to identify usable energy from seismic data acquired using Distributed Acoustic Sensing (DAS). While using only a subset of labeled images during training, we were able to identify suitable models that can be accurately generalized to unknown signal patterns. We show that by using 16 times more GPUs, we can increase the training speed by more than two orders of magnitude on a 50,000-image data set.
P3SGD: Patient Privacy Preserving SGD for Regularizing Deep CNNs in Pathological Image Classification
May 30, 2019
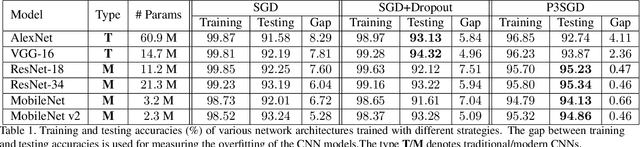
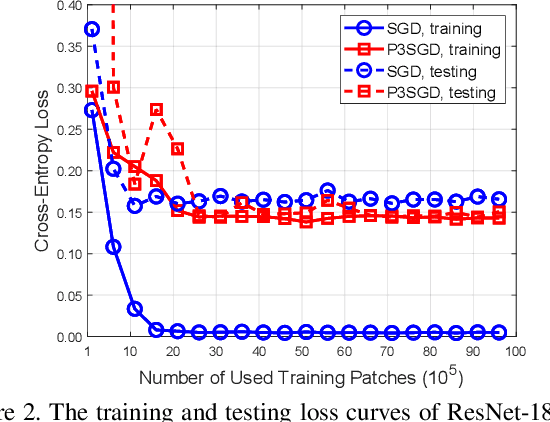
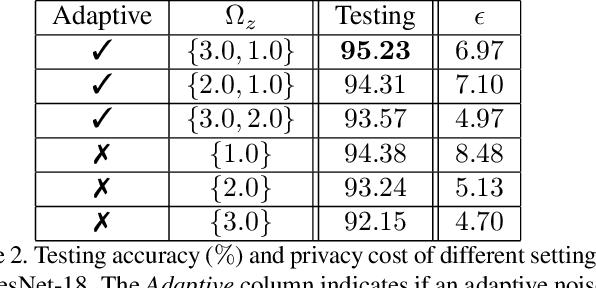
Recently, deep convolutional neural networks (CNNs) have achieved great success in pathological image classification. However, due to the limited number of labeled pathological images, there are still two challenges to be addressed: (1) overfitting: the performance of a CNN model is undermined by the overfitting due to its huge amounts of parameters and the insufficiency of labeled training data. (2) privacy leakage: the model trained using a conventional method may involuntarily reveal the private information of the patients in the training dataset. The smaller the dataset, the worse the privacy leakage. To tackle the above two challenges, we introduce a novel stochastic gradient descent (SGD) scheme, named patient privacy preserving SGD (P3SGD), which performs the model update of the SGD in the patient level via a large-step update built upon each patient's data. Specifically, to protect privacy and regularize the CNN model, we propose to inject the well-designed noise into the updates. Moreover, we equip our P3SGD with an elaborated strategy to adaptively control the scale of the injected noise. To validate the effectiveness of P3SGD, we perform extensive experiments on a real-world clinical dataset and quantitatively demonstrate the superior ability of P3SGD in reducing the risk of overfitting. We also provide a rigorous analysis of the privacy cost under differential privacy. Additionally, we find that the models trained with P3SGD are resistant to the model-inversion attack compared with those trained using non-private SGD.
Lunar Crater Identification in Digital Images
Sep 02, 2020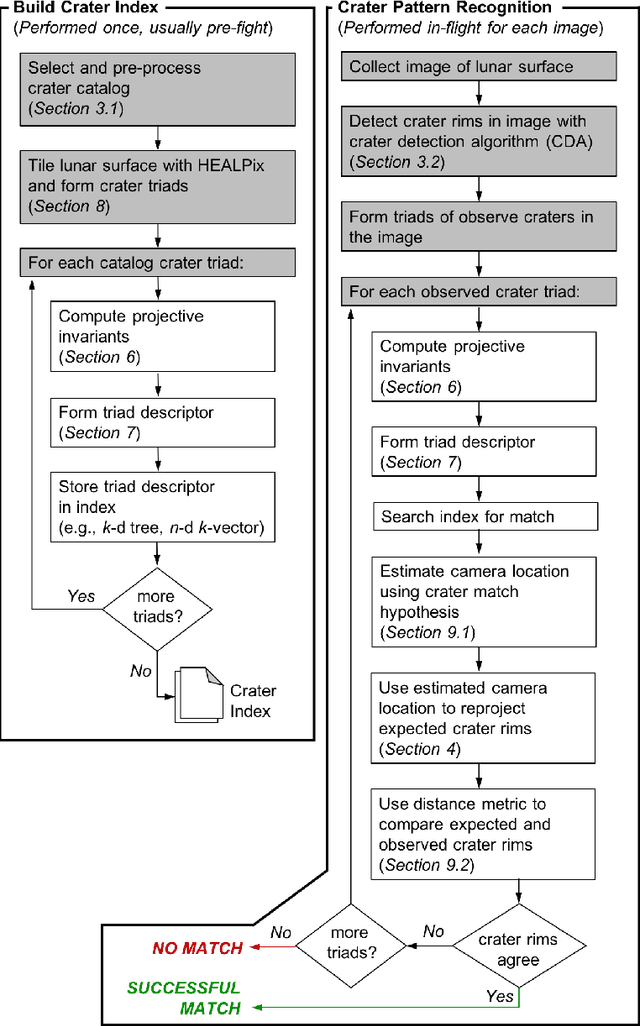

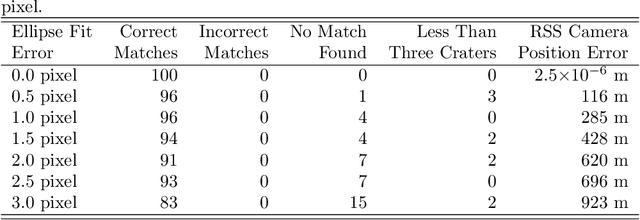
It is often necessary to identify a pattern of observed craters in a single image of the lunar surface and without any prior knowledge of the camera's location. This so-called "lost-in-space" crater identification problem is common in both crater-based terrain relative navigation (TRN) and in automatic registration of scientific imagery. Past work on crater identification has largely been based on heuristic schemes, with poor performance outside of a narrowly defined operating regime (e.g., nadir pointing images, small search areas). This work provides the first mathematically rigorous treatment of the general crater identification problem. It is shown when it is (and when it is not) possible to recognize a pattern of elliptical crater rims in an image formed by perspective projection. For the cases when it is possible to recognize a pattern, descriptors are developed using invariant theory that provably capture all of the viewpoint invariant information. These descriptors may be pre-computed for known crater patterns and placed in a searchable index for fast recognition. New techniques are also developed for computing pose from crater rim observations and for evaluating crater rim correspondences. These techniques are demonstrated on both synthetic and real images.
Adversarial Examples in Deep Learning for Multivariate Time Series Regression
Sep 24, 2020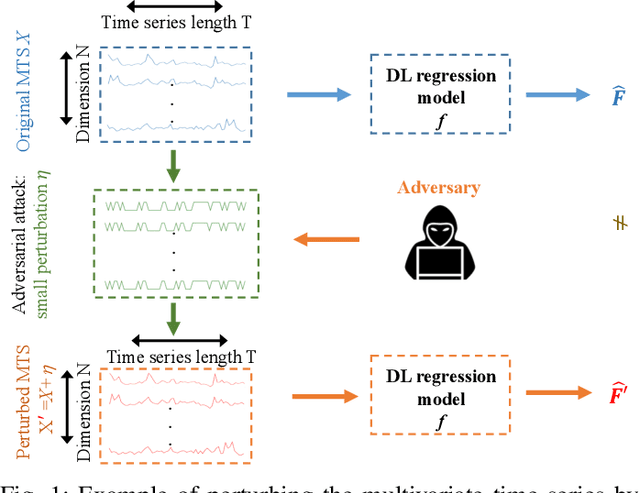
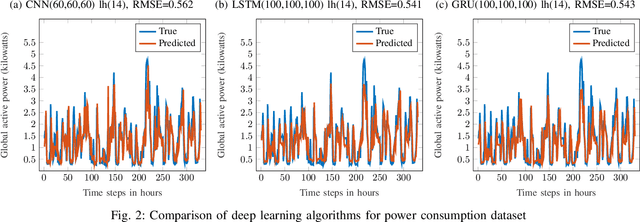
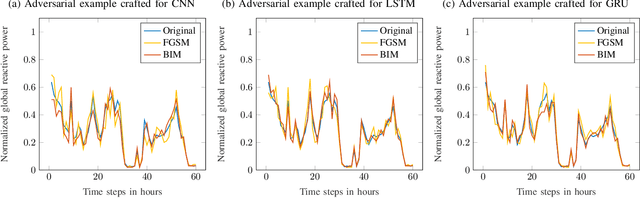
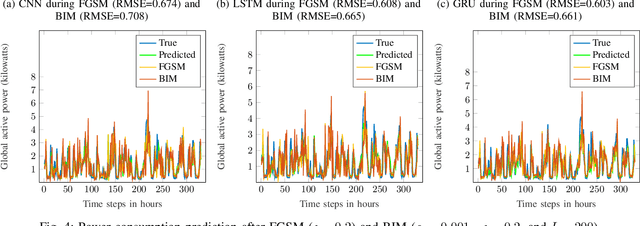
Multivariate time series (MTS) regression tasks are common in many real-world data mining applications including finance, cybersecurity, energy, healthcare, prognostics, and many others. Due to the tremendous success of deep learning (DL) algorithms in various domains including image recognition and computer vision, researchers started adopting these techniques for solving MTS data mining problems, many of which are targeted for safety-critical and cost-critical applications. Unfortunately, DL algorithms are known for their susceptibility to adversarial examples which also makes the DL regression models for MTS forecasting also vulnerable to those attacks. To the best of our knowledge, no previous work has explored the vulnerability of DL MTS regression models to adversarial time series examples, which is an important step, specifically when the forecasting from such models is used in safety-critical and cost-critical applications. In this work, we leverage existing adversarial attack generation techniques from the image classification domain and craft adversarial multivariate time series examples for three state-of-the-art deep learning regression models, specifically Convolutional Neural Network (CNN), Long Short-Term Memory (LSTM), and Gated Recurrent Unit (GRU). We evaluate our study using Google stock and household power consumption dataset. The obtained results show that all the evaluated DL regression models are vulnerable to adversarial attacks, transferable, and thus can lead to catastrophic consequences in safety-critical and cost-critical domains, such as energy and finance.
Multi-Scale Neural Networks for to Fluid Flow in 3D Porous Media
Feb 10, 2021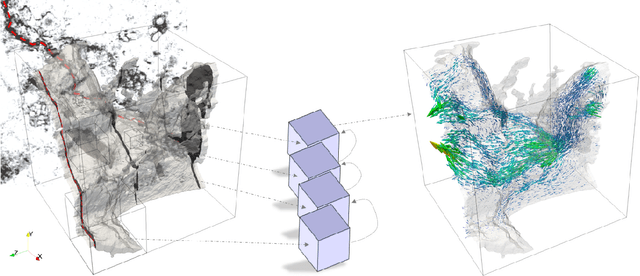
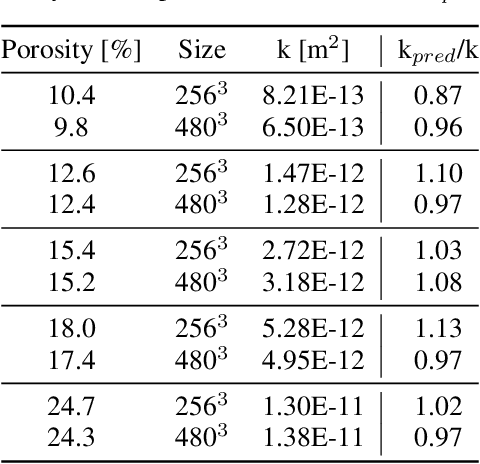
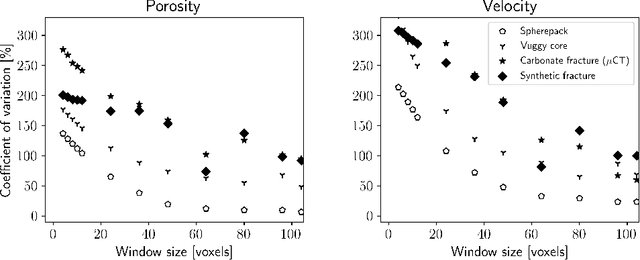
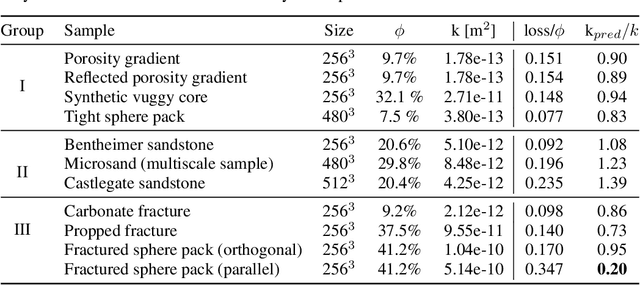
The permeability of complex porous materials can be obtained via direct flow simulation, which provides the most accurate results, but is very computationally expensive. In particular, the simulation convergence time scales poorly as simulation domains become tighter or more heterogeneous. Semi-analytical models that rely on averaged structural properties (i.e. porosity and tortuosity) have been proposed, but these features only summarize the domain, resulting in limited applicability. On the other hand, data-driven machine learning approaches have shown great promise for building more general models by virtue of accounting for the spatial arrangement of the domains solid boundaries. However, prior approaches building on the Convolutional Neural Network (ConvNet) literature concerning 2D image recognition problems do not scale well to the large 3D domains required to obtain a Representative Elementary Volume (REV). As such, most prior work focused on homogeneous samples, where a small REV entails that that the global nature of fluid flow could be mostly neglected, and accordingly, the memory bottleneck of addressing 3D domains with ConvNets was side-stepped. Therefore, important geometries such as fractures and vuggy domains could not be well-modeled. In this work, we address this limitation with a general multiscale deep learning model that is able to learn from porous media simulation data. By using a coupled set of neural networks that view the domain on different scales, we enable the evaluation of large images in approximately one second on a single Graphics Processing Unit. This model architecture opens up the possibility of modeling domain sizes that would not be feasible using traditional direct simulation tools on a desktop computer.
A Novel Image Dehazing and Assessment Method
Jan 20, 2020

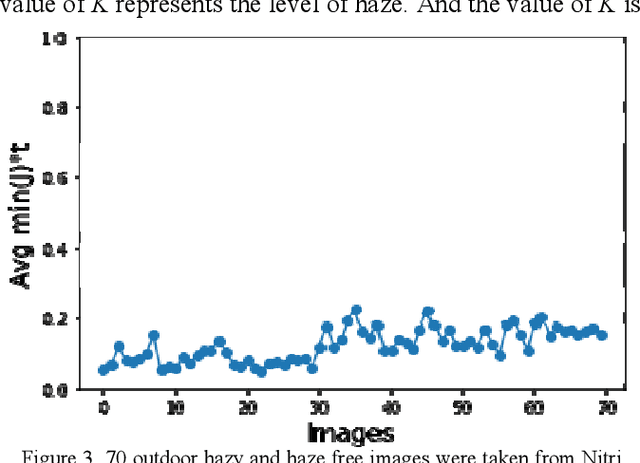

Images captured in hazy weather conditions often suffer from color contrast and color fidelity. This degradation is represented by transmission map which represents the amount of attenuation and airlight which represents the color of additive noise. In this paper, we have proposed a method to estimate the transmission map using haze levels instead of airlight color since there are some ambiguities in estimation of airlight. Qualitative and quantitative results of proposed method show competitiveness of the method given. In addition we have proposed two metrics which are based on statistics of natural outdoor images for assessment of haze removal algorithms.
Generative Counterfactuals for Neural Networks via Attribute-Informed Perturbation
Jan 18, 2021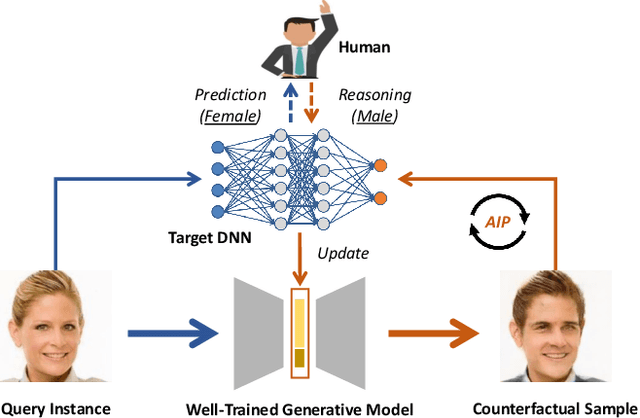

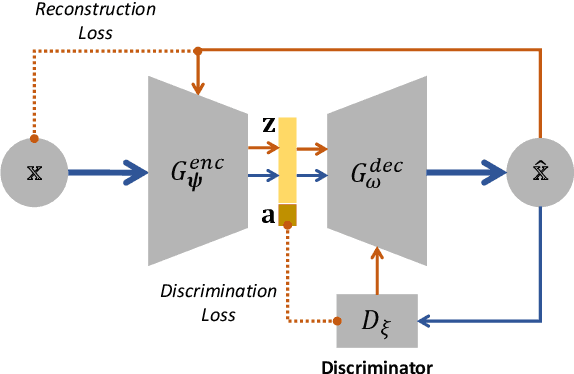
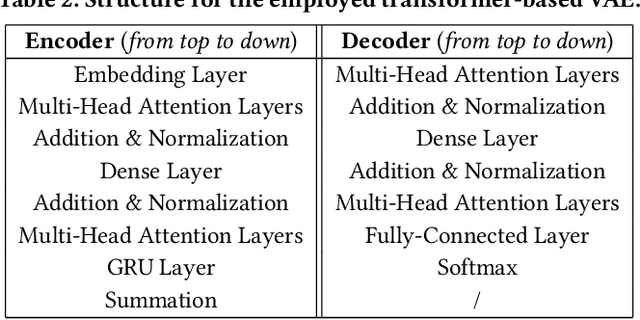
With the wide use of deep neural networks (DNN), model interpretability has become a critical concern, since explainable decisions are preferred in high-stake scenarios. Current interpretation techniques mainly focus on the feature attribution perspective, which are limited in indicating why and how particular explanations are related to the prediction. To this end, an intriguing class of explanations, named counterfactuals, has been developed to further explore the "what-if" circumstances for interpretation, and enables the reasoning capability on black-box models. However, generating counterfactuals for raw data instances (i.e., text and image) is still in the early stage due to its challenges on high data dimensionality and unsemantic raw features. In this paper, we design a framework to generate counterfactuals specifically for raw data instances with the proposed Attribute-Informed Perturbation (AIP). By utilizing generative models conditioned with different attributes, counterfactuals with desired labels can be obtained effectively and efficiently. Instead of directly modifying instances in the data space, we iteratively optimize the constructed attribute-informed latent space, where features are more robust and semantic. Experimental results on real-world texts and images demonstrate the effectiveness, sample quality as well as efficiency of our designed framework, and show the superiority over other alternatives. Besides, we also introduce some practical applications based on our framework, indicating its potential beyond the model interpretability aspect.