 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Instance Separation Emerges from Inpainting
Feb 28, 2020
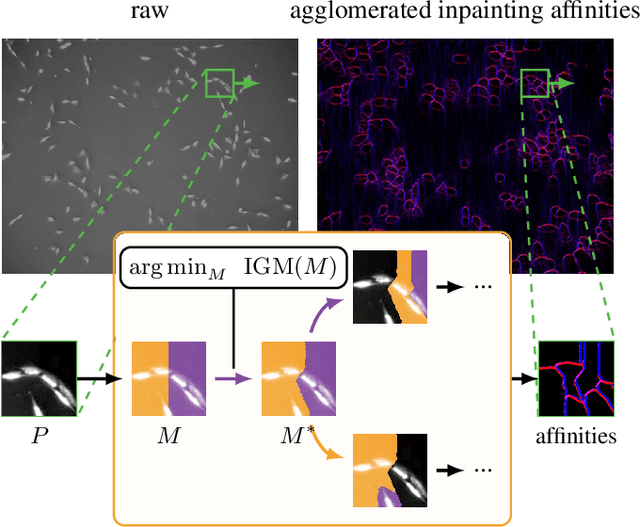

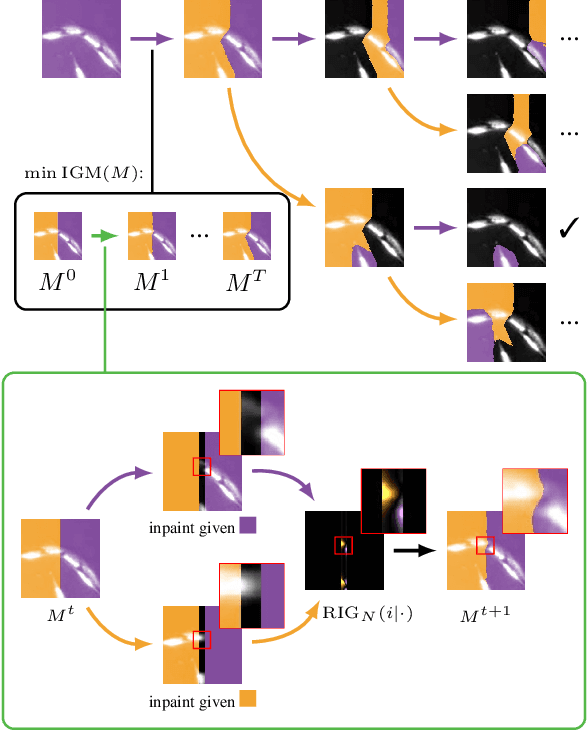

Deep neural networks trained to inpaint partially occluded images show a deep understanding of image composition and have even been shown to remove objects from images convincingly. In this work, we investigate how this implicit knowledge of image composition can be leveraged for fully self-supervised instance separation. We propose a measure for the independence of two image regions given a fully self-supervised inpainting network and separate objects by maximizing this independence. We evaluate our method on two microscopy image datasets and show that it reaches similar segmentation performance to fully supervised methods.
Extended depth-of-field in holographic image reconstruction using deep learning based auto-focusing and phase-recovery
Mar 21, 2018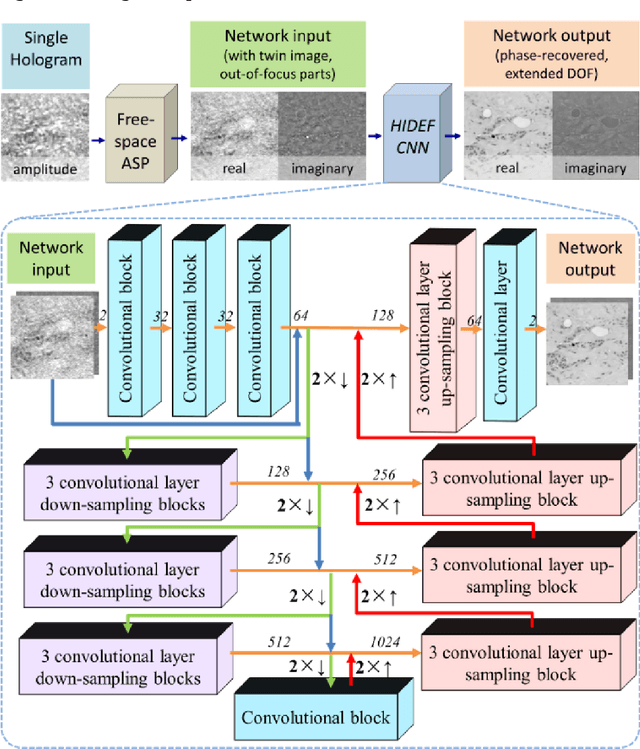
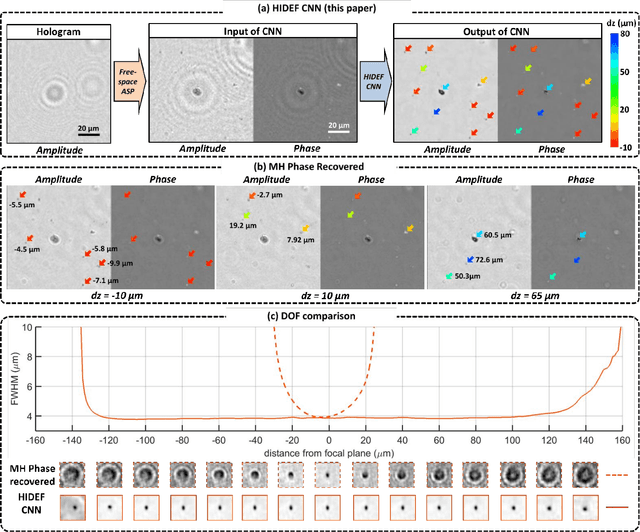

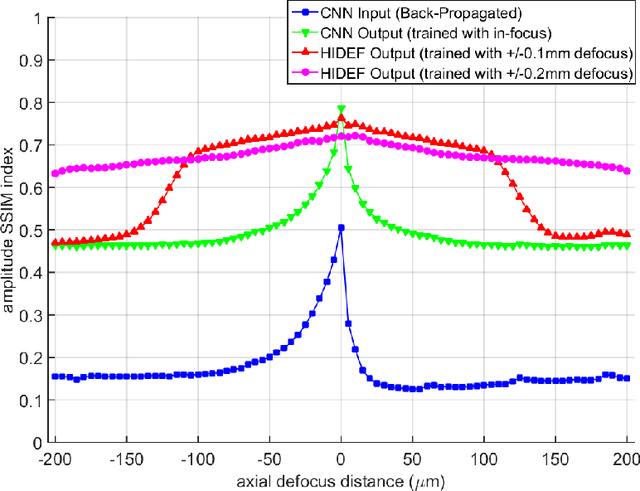
Holography encodes the three dimensional (3D) information of a sample in the form of an intensity-only recording. However, to decode the original sample image from its hologram(s), auto-focusing and phase-recovery are needed, which are in general cumbersome and time-consuming to digitally perform. Here we demonstrate a convolutional neural network (CNN) based approach that simultaneously performs auto-focusing and phase-recovery to significantly extend the depth-of-field (DOF) in holographic image reconstruction. For this, a CNN is trained by using pairs of randomly de-focused back-propagated holograms and their corresponding in-focus phase-recovered images. After this training phase, the CNN takes a single back-propagated hologram of a 3D sample as input to rapidly achieve phase-recovery and reconstruct an in focus image of the sample over a significantly extended DOF. This deep learning based DOF extension method is non-iterative, and significantly improves the algorithm time-complexity of holographic image reconstruction from O(nm) to O(1), where n refers to the number of individual object points or particles within the sample volume, and m represents the focusing search space within which each object point or particle needs to be individually focused. These results highlight some of the unique opportunities created by data-enabled statistical image reconstruction methods powered by machine learning, and we believe that the presented approach can be broadly applicable to computationally extend the DOF of other imaging modalities.
Learning a Product Relevance Model from Click-Through Data in E-Commerce
Feb 14, 2021

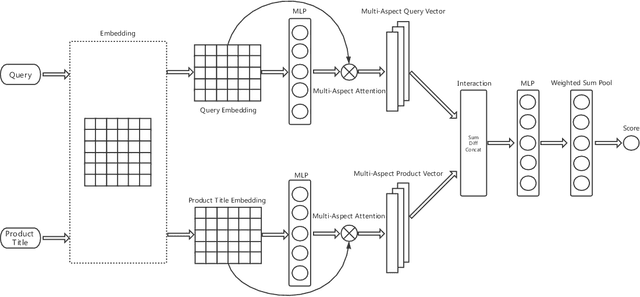

The search engine plays a fundamental role in online e-commerce systems, to help users find the products they want from the massive product collections. Relevance is an essential requirement for e-commerce search, since showing products that do not match search query intent will degrade user experience. With the existence of vocabulary gap between user language of queries and seller language of products, measuring semantic relevance is necessary and neural networks are engaged to address this task. However, semantic relevance is different from click-through rate prediction in that no direct training signal is available. Most previous attempts learn relevance models from user click-through data that are cheap and abundant. Unfortunately, click behavior is noisy and misleading, which is affected by not only relevance but also factors including price, image and attractive titles. Therefore, it is challenging but valuable to learn relevance models from click-through data. In this paper, we propose a new relevance learning framework that concentrates on how to train a relevance model from the weak supervision of click-through data. Different from previous efforts that treat samples as either relevant or irrelevant, we construct more fine-grained samples for training. We propose a novel way to consider samples of different relevance confidence, and come up with a new training objective to learn a robust relevance model with desirable score distribution. The proposed model is evaluated on offline annotated data and online A/B testing, and it achieves both promising performance and high computational efficiency. The model has already been deployed online, serving the search traffic of Taobao for over a year.
Kill Two Birds with One Stone: Weakly-Supervised Neural Network for Image Annotation and Tag Refinement
Nov 19, 2017

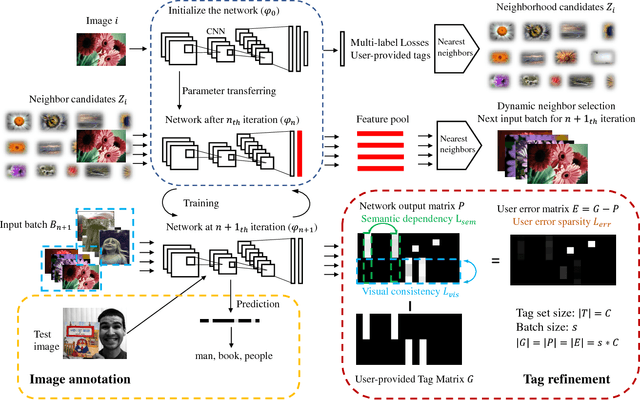
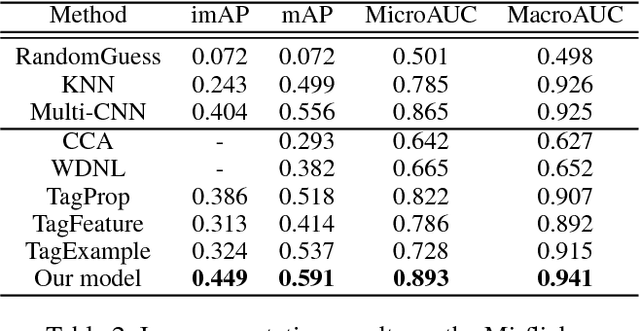
The number of social images has exploded by the wide adoption of social networks, and people like to share their comments about them. These comments can be a description of the image, or some objects, attributes, scenes in it, which are normally used as the user-provided tags. However, it is well-known that user-provided tags are incomplete and imprecise to some extent. Directly using them can damage the performance of related applications, such as the image annotation and retrieval. In this paper, we propose to learn an image annotation model and refine the user-provided tags simultaneously in a weakly-supervised manner. The deep neural network is utilized as the image feature learning and backbone annotation model, while visual consistency, semantic dependency, and user-error sparsity are introduced as the constraints at the batch level to alleviate the tag noise. Therefore, our model is highly flexible and stable to handle large-scale image sets. Experimental results on two benchmark datasets indicate that our proposed model achieves the best performance compared to the state-of-the-art methods.
Triad State Space Construction for Chaotic Signal Classification with Deep Learning
Mar 26, 2020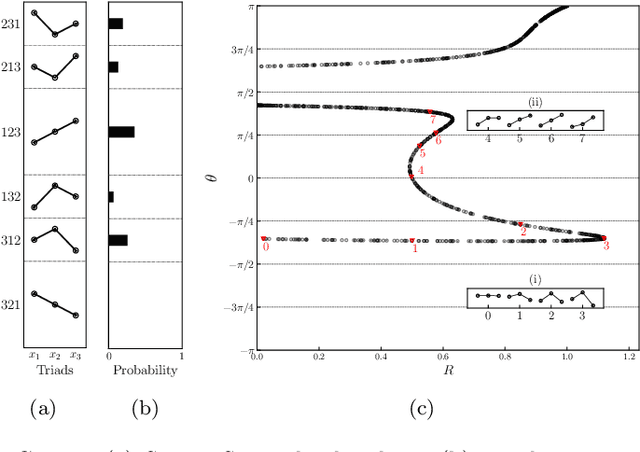
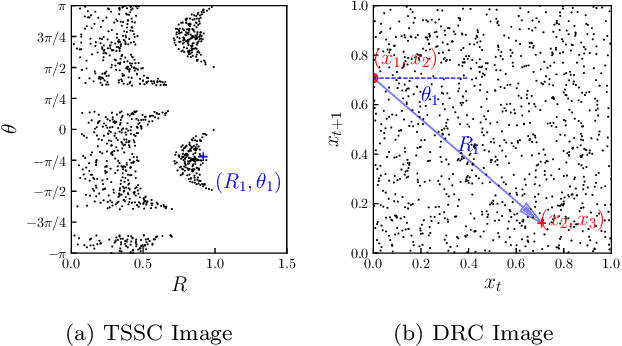
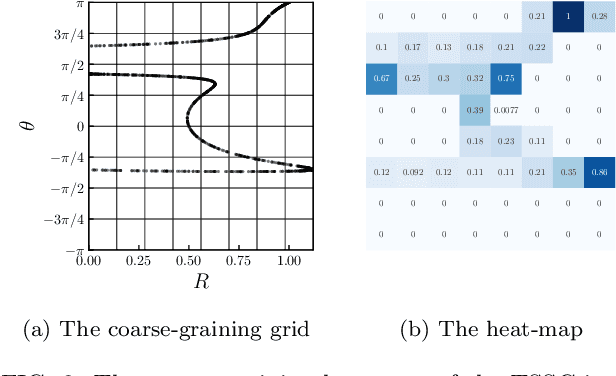
Inspired by the well-known permutation entropy (PE), an effective image encoding scheme for chaotic time series, Triad State Space Construction (TSSC), is proposed. The TSSC image can recognize higher-order temporal patterns and identify new forbidden regions in time series motifs beyond the Bandt-Pompe probabilities. The Convolutional Neural Network (ConvNet) is widely used in image classification. The ConvNet classifier based on TSSC images (TSSC-ConvNet) are highly accurate and very robust in the chaotic signal classification.
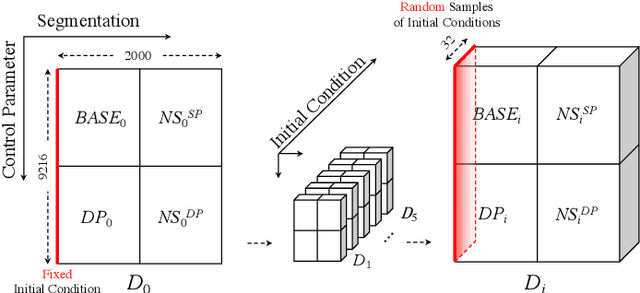
Regularized Compression of MRI Data: Modular Optimization of Joint Reconstruction and Coding
Oct 08, 2020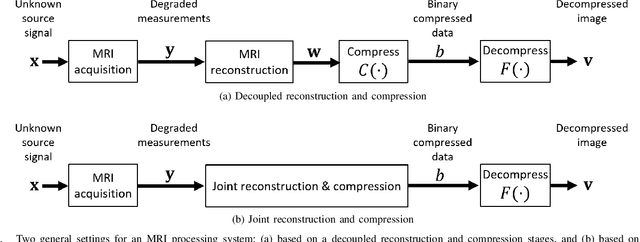
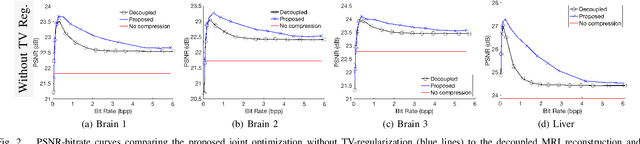
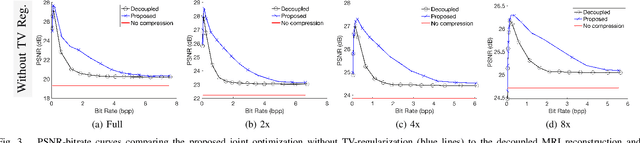
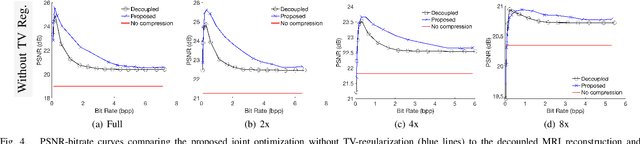
The Magnetic Resonance Imaging (MRI) processing chain starts with a critical acquisition stage that provides raw data for reconstruction of images for medical diagnosis. This flow usually includes a near-lossless data compression stage that enables digital storage and/or transmission in binary formats. In this work we propose a framework for joint optimization of the MRI reconstruction and lossy compression, producing compressed representations of medical images that achieve improved trade-offs between quality and bit-rate. Moreover, we demonstrate that lossy compression can even improve the reconstruction quality compared to settings based on lossless compression. Our method has a modular optimization structure, implemented using the alternating direction method of multipliers (ADMM) technique and the state-of-the-art image compression technique (BPG) as a black-box module iteratively applied. This establishes a medical data compression approach compatible with a lossy compression standard of choice. A main novelty of the proposed algorithm is in the total-variation regularization added to the modular compression process, leading to decompressed images of higher quality without any additional processing at/after the decompression stage. Our experiments show that our regularization-based approach for joint MRI reconstruction and compression often achieves significant PSNR gains between 4 to 9 dB at high bit-rates compared to non-regularized solutions of the joint task. Compared to regularization-based solutions, our optimization method provides PSNR gains between 0.5 to 1 dB at high bit-rates, which is the range of interest for medical image compression.
Analysis of deep machine learning algorithms in COVID-19 disease diagnosis
Aug 25, 2020
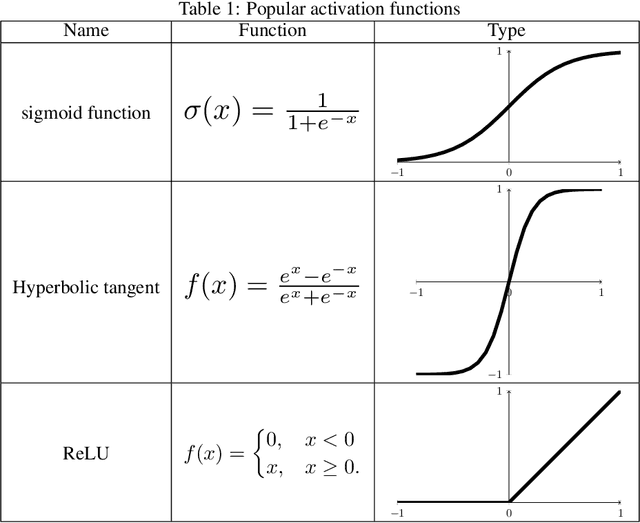
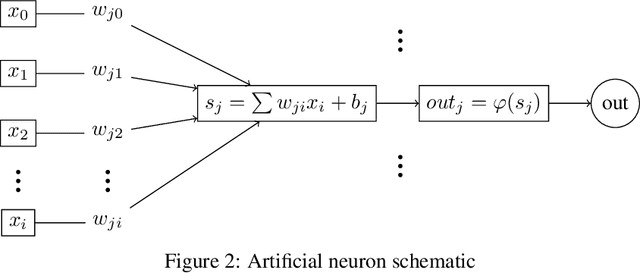
The aim of the work is to use deep neural network models for solving the problem of image recognition. These days, every human being is threatened by a harmful coronavirus disease, also called COVID-19 disease. The spread of coronavirus affects the economy of many countries in the world. To find COVID-19 patients early is very essential to avoid the spread and harm to society. Pathological tests and Chromatography(CT) scans are helpful for the diagnosis of COVID-19. However, these tests are having drawbacks such as a large number of false positives, and cost of these tests are so expensive. Hence, it requires finding an easy, accurate, and less expensive way for the detection of the harmful COVID-19 disease. Chest-x-ray can be useful for the detection of this disease. Therefore, in this work chest, x-ray images are used for the diagnosis of suspected COVID-19 patients using modern machine learning techniques. The analysis of the results is carried out and conclusions are made about the effectiveness of deep machine learning algorithms in image recognition problems.
Uncertainty-sensitive Activity Recognition: a Reliability Benchmark and the CARING Models
Jan 02, 2021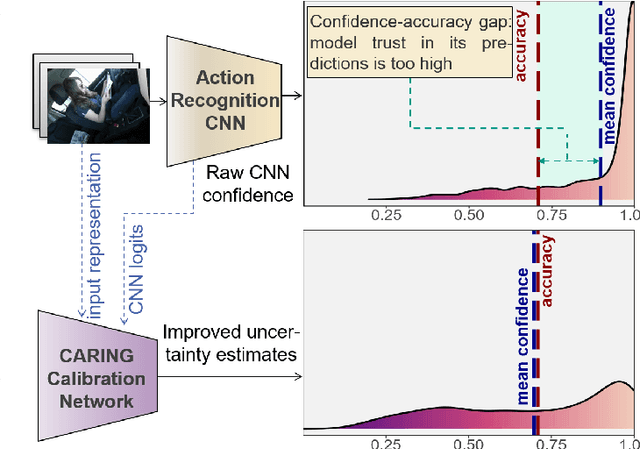
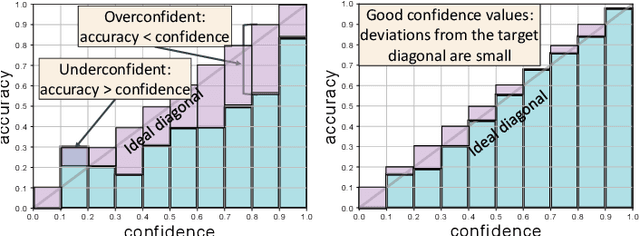
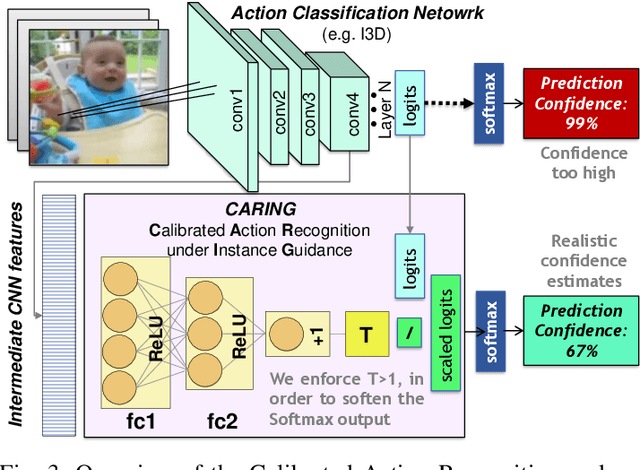
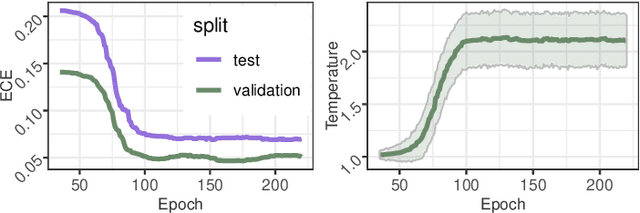
Beyond assigning the correct class, an activity recognition model should also be able to determine, how certain it is in its predictions. We present the first study of how welthe confidence values of modern action recognition architectures indeed reflect the probability of the correct outcome and propose a learning-based approach for improving it. First, we extend two popular action recognition datasets with a reliability benchmark in form of the expected calibration error and reliability diagrams. Since our evaluation highlights that confidence values of standard action recognition architectures do not represent the uncertainty well, we introduce a new approach which learns to transform the model output into realistic confidence estimates through an additional calibration network. The main idea of our Calibrated Action Recognition with Input Guidance (CARING) model is to learn an optimal scaling parameter depending on the video representation. We compare our model with the native action recognition networks and the temperature scaling approach - a wide spread calibration method utilized in image classification. While temperature scaling alone drastically improves the reliability of the confidence values, our CARING method consistently leads to the best uncertainty estimates in all benchmark settings.
Watching the World Go By: Representation Learning from Unlabeled Videos
Mar 18, 2020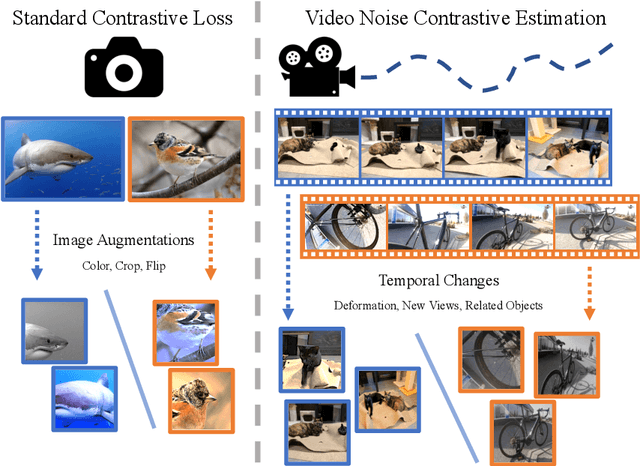


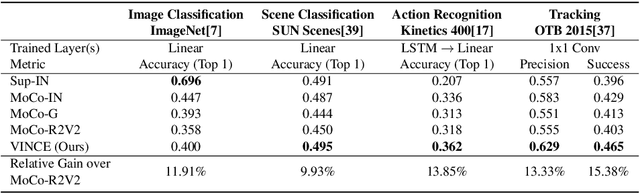
Recent single image unsupervised representation learning techniques show remarkable success on a variety of tasks. The basic principle in these works is instance discrimination: learning to differentiate between two augmented versions of the same image and a large batch of unrelated images. Networks learn to ignore the augmentation noise and extract semantically meaningful representations. Prior work uses artificial data augmentation techniques such as cropping, and color jitter which can only affect the image in superficial ways and are not aligned with how objects actually change e.g. occlusion, deformation, viewpoint change. In this paper, we argue that videos offer this natural augmentation for free. Videos can provide entirely new views of objects, show deformation, and even connect semantically similar but visually distinct concepts. We propose Video Noise Contrastive Estimation, a method for using unlabeled video to learn strong, transferable single image representations. We demonstrate improvements over recent unsupervised single image techniques, as well as over fully supervised ImageNet pretraining, across a variety of temporal and non-temporal tasks.
Training Convolutional Neural Networks With Hebbian Principal Component Analysis
Dec 22, 2020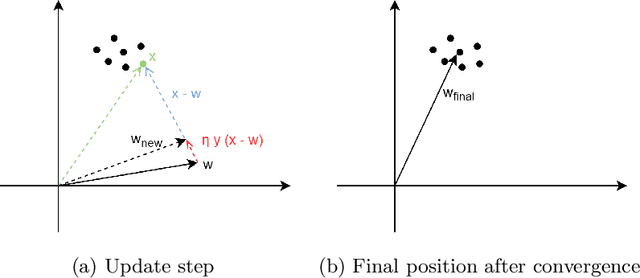
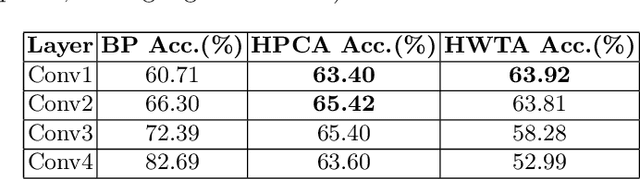
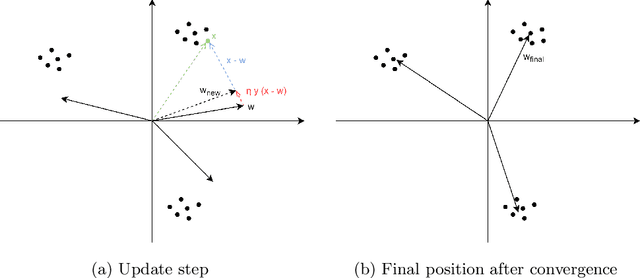
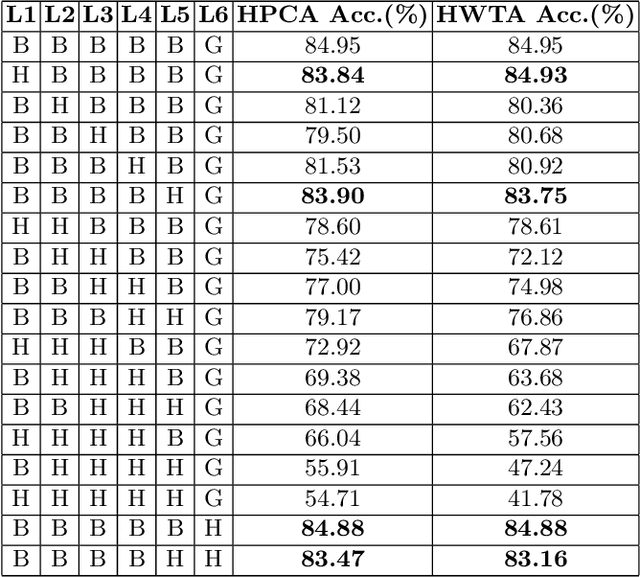
Recent work has shown that biologically plausible Hebbian learning can be integrated with backpropagation learning (backprop), when training deep convolutional neural networks. In particular, it has been shown that Hebbian learning can be used for training the lower or the higher layers of a neural network. For instance, Hebbian learning is effective for re-training the higher layers of a pre-trained deep neural network, achieving comparable accuracy w.r.t. SGD, while requiring fewer training epochs, suggesting potential applications for transfer learning. In this paper we build on these results and we further improve Hebbian learning in these settings, by using a nonlinear Hebbian Principal Component Analysis (HPCA) learning rule, in place of the Hebbian Winner Takes All (HWTA) strategy used in previous work. We test this approach in the context of computer vision. In particular, the HPCA rule is used to train Convolutional Neural Networks in order to extract relevant features from the CIFAR-10 image dataset. The HPCA variant that we explore further improves the previous results, motivating further interest towards biologically plausible learning algorithms.