 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
AMC: Attention guided Multi-modal Correlation Learning for Image Search
Apr 03, 2017
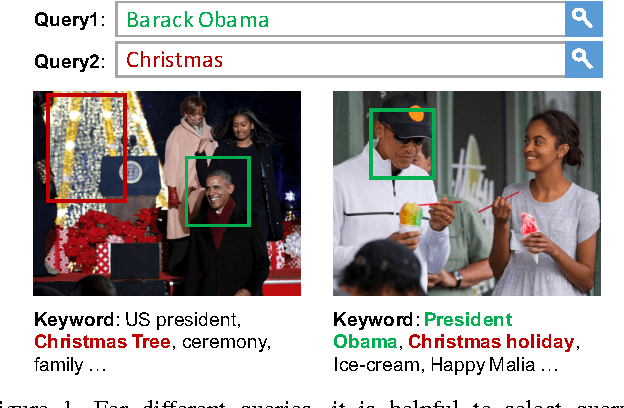

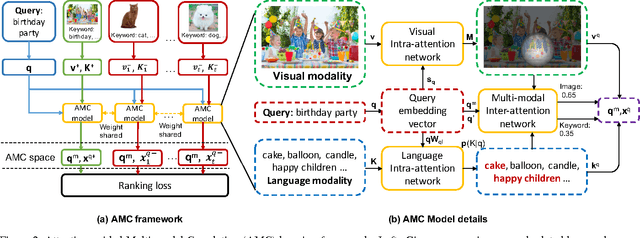
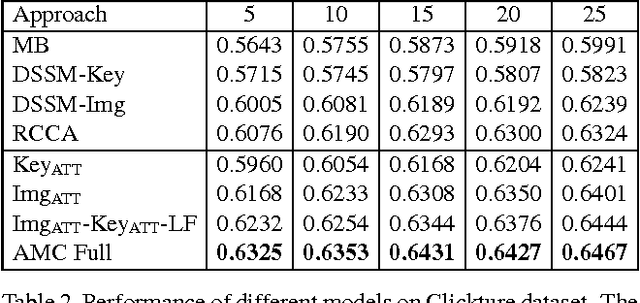
Given a user's query, traditional image search systems rank images according to its relevance to a single modality (e.g., image content or surrounding text). Nowadays, an increasing number of images on the Internet are available with associated meta data in rich modalities (e.g., titles, keywords, tags, etc.), which can be exploited for better similarity measure with queries. In this paper, we leverage visual and textual modalities for image search by learning their correlation with input query. According to the intent of query, attention mechanism can be introduced to adaptively balance the importance of different modalities. We propose a novel Attention guided Multi-modal Correlation (AMC) learning method which consists of a jointly learned hierarchy of intra and inter-attention networks. Conditioned on query's intent, intra-attention networks (i.e., visual intra-attention network and language intra-attention network) attend on informative parts within each modality; a multi-modal inter-attention network promotes the importance of the most query-relevant modalities. In experiments, we evaluate AMC models on the search logs from two real world image search engines and show a significant boost on the ranking of user-clicked images in search results. Additionally, we extend AMC models to caption ranking task on COCO dataset and achieve competitive results compared with recent state-of-the-arts.
Learning to Rank for Active Learning: A Listwise Approach
Jul 31, 2020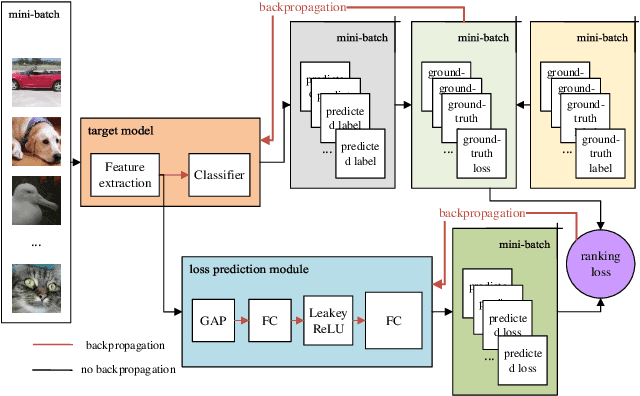
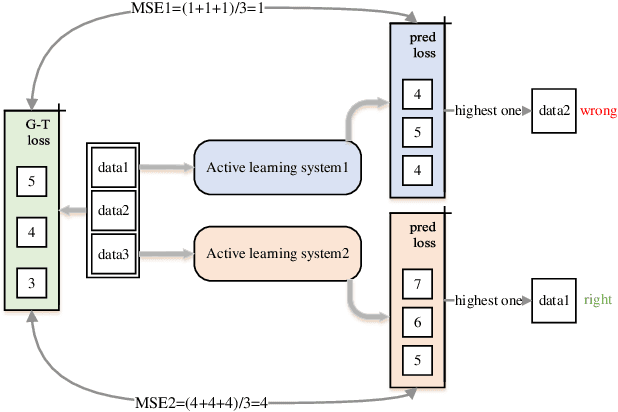
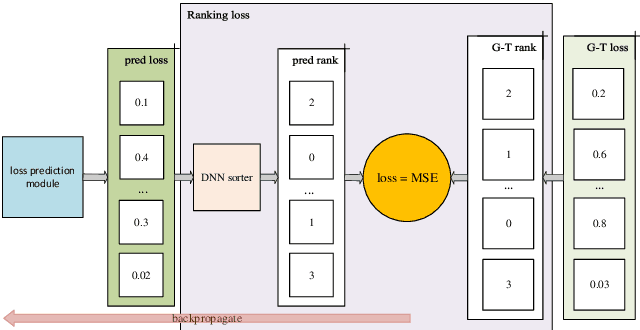
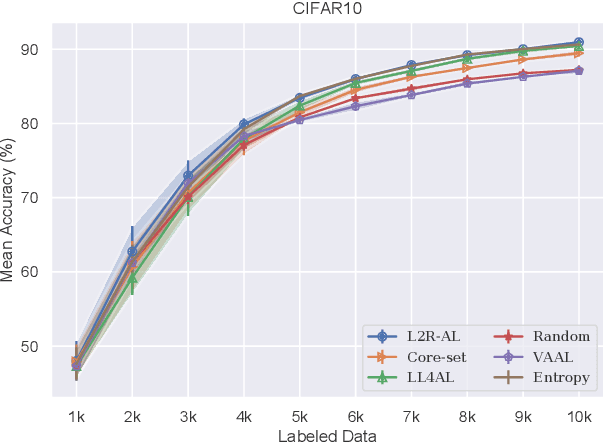
Active learning emerged as an alternative to alleviate the effort to label huge amount of data for data hungry applications (such as image/video indexing and retrieval, autonomous driving, etc.). The goal of active learning is to automatically select a number of unlabeled samples for annotation (according to a budget), based on an acquisition function, which indicates how valuable a sample is for training the model. The learning loss method is a task-agnostic approach which attaches a module to learn to predict the target loss of unlabeled data, and select data with the highest loss for labeling. In this work, we follow this strategy but we define the acquisition function as a learning to rank problem and rethink the structure of the loss prediction module, using a simple but effective listwise approach. Experimental results on four datasets demonstrate that our method outperforms recent state-of-the-art active learning approaches for both image classification and regression tasks.
Saving the Sonorine: Audio Recovery Using Image Processing and Computer Vision
May 16, 2020


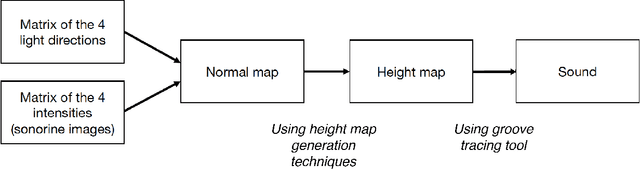
This paper presents a novel technique to recover audio from sonorines, an early 20th century form of analogue sound storage. Our method uses high resolution photographs of sonorines under different lighting conditions to observe the change in reflection behavior of the physical surface features and create a three-dimensional height map of the surface. Sound can then be extracted using height information within the surface's grooves, mimicking a physical stylus on a phonograph. Unlike traditional playback methods, our method has the advantage of being contactless: the medium will not incur damage and wear from being played repeatedly. We compare the results of our technique to a previously successful contactless method using flatbed scans of the sonorines, and conclude with future research that can be applied to this photovisual approach to audio recovery.
Blur, Noise, and Compression Robust Generative Adversarial Networks
Mar 17, 2020
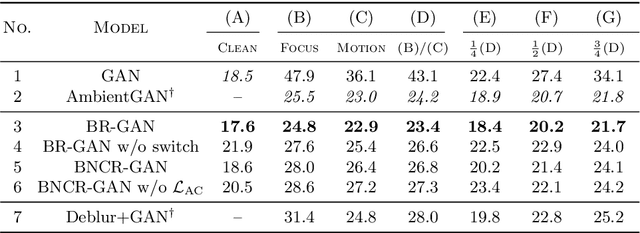
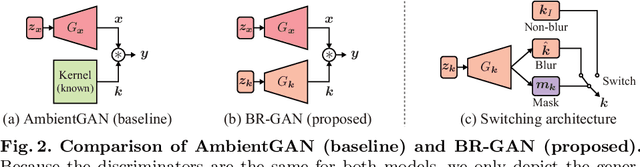
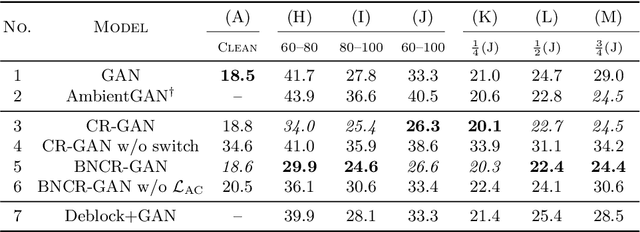
Recently, generative adversarial networks (GANs), which learn data distributions through adversarial training, have gained special attention owing to their high image reproduction ability. However, one limitation of standard GANs is that they recreate training images faithfully despite image degradation characteristics such as blur, noise, and compression. To remedy this, we address the problem of blur, noise, and compression robust image generation. Our objective is to learn a non-degraded image generator directly from degraded images without prior knowledge of image degradation. The recently proposed noise robust GAN (NR-GAN) already provides a solution to the problem of noise degradation. Therefore, we first focus on blur and compression degradations. We propose blur robust GAN (BR-GAN) and compression robust GAN (CR-GAN), which learn a kernel generator and quality factor generator, respectively, with non-degraded image generators. Owing to the irreversible blur and compression characteristics, adjusting their strengths is non-trivial. Therefore, we incorporate switching architectures that can adapt the strengths in a data-driven manner. Based on BR-GAN, NR-GAN, and CR-GAN, we further propose blur, noise, and compression robust GAN (BNCR-GAN), which unifies these three models into a single model with additionally introduced adaptive consistency losses that suppress the uncertainty caused by the combination. We provide benchmark scores through large-scale comparative studies on CIFAR-10 and a generality analysis on FFHQ dataset.
Machine-learned Regularization and Polygonization of Building Segmentation Masks
Jul 24, 2020
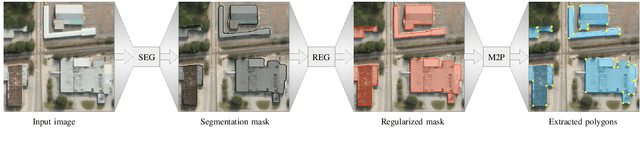
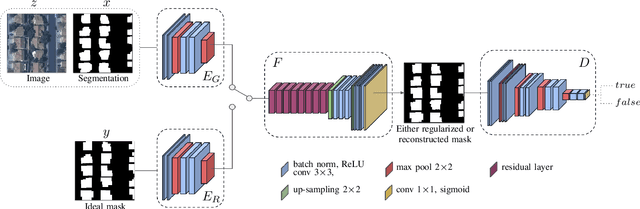
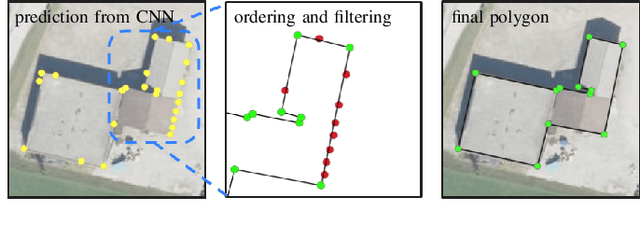
We propose a machine learning based approach for automatic regularization and polygonization of building segmentation masks. Taking an image as input, we first predict building segmentation maps exploiting generic fully convolutional network (FCN). A generative adversarial network (GAN) is then involved to perform a regularization of building boundaries to make them more realistic, i.e., having more rectilinear outlines which construct right angles if required. This is achieved through the interplay between the discriminator which gives a probability of input image being true and generator that learns from discriminator's response to create more realistic images. Finally, we train the backbone convolutional neural network (CNN) which is adapted to predict sparse outcomes corresponding to building corners out of regularized building segmentation results. Experiments on three building segmentation datasets demonstrate that the proposed method is not only capable of obtaining accurate results, but also of producing visually pleasing building outlines parameterized as polygons.
CNN Fixations: An unraveling approach to visualize the discriminative image regions
Aug 23, 2017
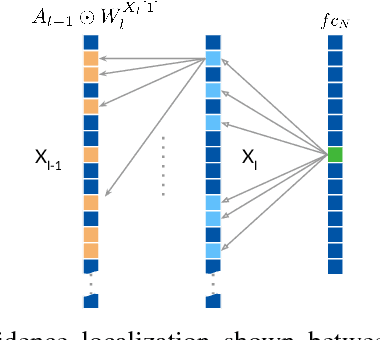
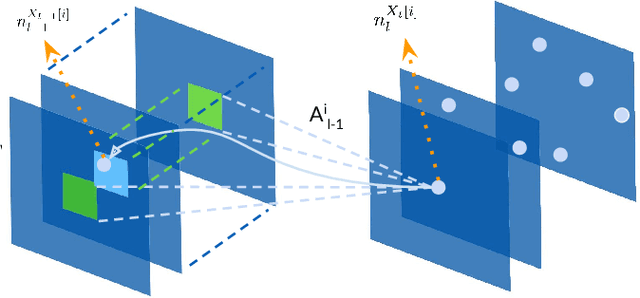
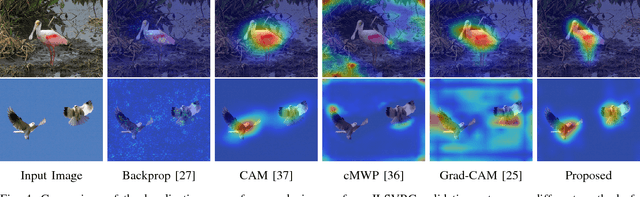
Deep convolutional neural networks (CNN) have revolutionized various fields of vision research and have seen unprecedented adoption for multiple tasks such as classification, detection, captioning, etc. However, they offer little transparency into their inner workings and are often treated as black boxes that deliver excellent performance. In this work, we aim at alleviating this opaqueness of CNNs by providing visual explanations for the network's predictions. Our approach can analyze variety of CNN based models trained for vision applications such as object recognition and caption generation. Unlike existing methods, we achieve this via unraveling the forward pass operation. Proposed method exploits feature dependencies across the layer hierarchy and uncovers the discriminative image locations that guide the network's predictions. We name these locations CNN-Fixations, loosely analogous to human eye fixations. Our approach is a generic method that requires no architectural changes, additional training or gradient computation and computes the important image locations (CNN Fixations). We demonstrate through a variety of applications that our approach is able to localize the discriminative image locations across different network architectures, diverse vision tasks and data modalities.
Realistic text replacement with non-uniform style conditioning
Jun 07, 2020

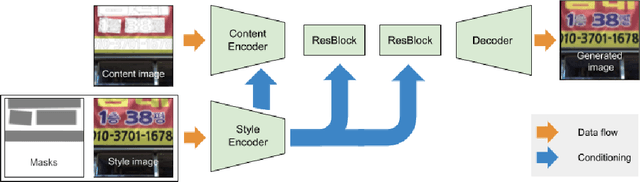

In this work, we study the possibility of realistic text replacement, the goal of which is to replace text present in the image with user-supplied text. The replacement should be performed in a way that will not allow distinguishing the resulting image from the original one. We achieve this goal by developing a novel non-uniform style conditioning layer and apply it to an encoder-decoder ResNet based architecture. The resulting model is a single-stage model, with no post-processing. The proposed model achieves realistic text replacement and outperforms existing approaches on ICDAR MLT.
From Perspective X-ray Imaging to Parallax-Robust Orthographic Stitching
Mar 05, 2020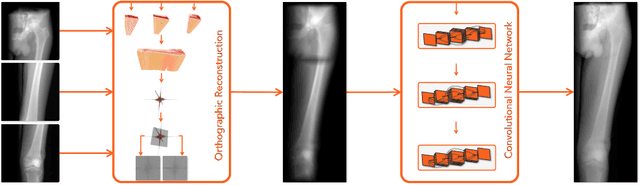


Stitching images acquired under perspective projective geometry is a relevant topic in computer vision with multiple applications ranging from smartphone panoramas to the construction of digital maps. Image stitching is an equally prominent challenge in medical imaging, where the limited field-of-view captured by single images prohibits holistic analysis of patient anatomy. The barrier that prevents straight-forward mosaicing of 2D images is depth mismatch due to parallax. In this work, we leverage the Fourier slice theorem to aggregate information from multiple transmission images in parallax-free domains using fundamental principles of X-ray image formation. The semantics of the stitched image are restored using a novel deep learning strategy that exploits similarity measures designed around frequency, as well as dense and sparse spatial image content. Our pipeline, not only stitches images, but also provides orthographic reconstruction that enables metric measurements of clinically relevant quantities directly on the 2D image plane.
Where is my hand? Deep hand segmentation for visual self-recognition in humanoid robots
Feb 09, 2021
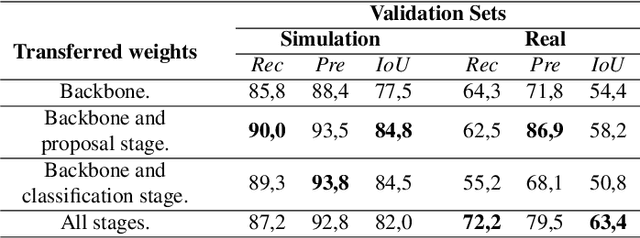
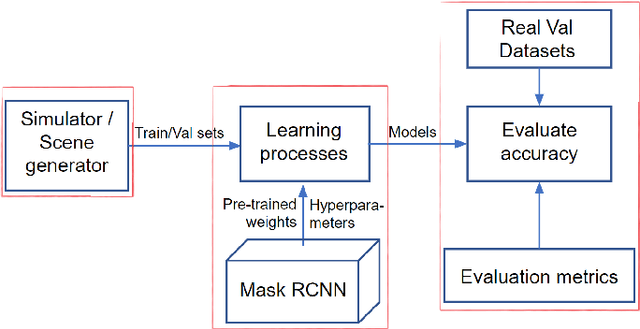
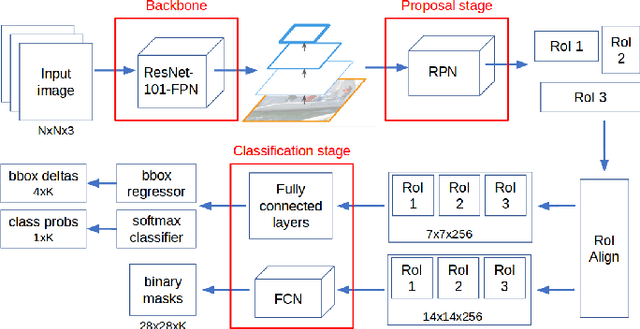
The ability to distinguish between the self and the background is of paramount importance for robotic tasks. The particular case of hands, as the end effectors of a robotic system that more often enter into contact with other elements of the environment, must be perceived and tracked with precision to execute the intended tasks with dexterity and without colliding with obstacles. They are fundamental for several applications, from Human-Robot Interaction tasks to object manipulation. Modern humanoid robots are characterized by high number of degrees of freedom which makes their forward kinematics models very sensitive to uncertainty. Thus, resorting to vision sensing can be the only solution to endow these robots with a good perception of the self, being able to localize their body parts with precision. In this paper, we propose the use of a Convolution Neural Network (CNN) to segment the robot hand from an image in an egocentric view. It is known that CNNs require a huge amount of data to be trained. To overcome the challenge of labeling real-world images, we propose the use of simulated datasets exploiting domain randomization techniques. We fine-tuned the Mask-RCNN network for the specific task of segmenting the hand of the humanoid robot Vizzy. We focus our attention on developing a methodology that requires low amounts of data to achieve reasonable performance while giving detailed insight on how to properly generate variability in the training dataset. Moreover, we analyze the fine-tuning process within the complex model of Mask-RCNN, understanding which weights should be transferred to the new task of segmenting robot hands. Our final model was trained solely on synthetic images and achieves an average IoU of 82% on synthetic validation data and 56.3% on real test data. These results were achieved with only 1000 training images and 3 hours of training time using a single GPU.
Dynamic radiomics: a new methodology to extract quantitative time-related features from tomographic images
Nov 01, 2020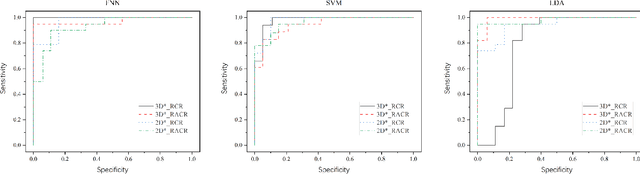
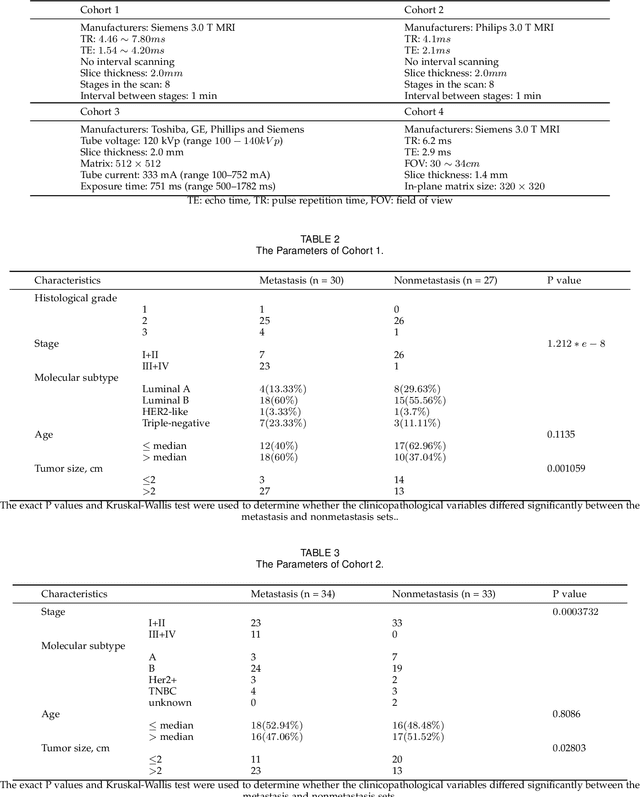
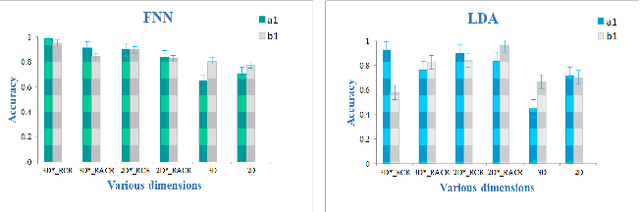
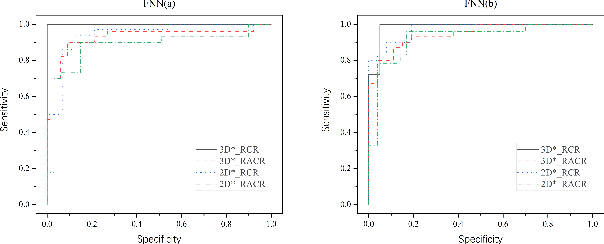
The feature extraction methods of radiomics are mainly based on static tomographic images at a certain moment, while the occurrence and development of disease is a dynamic process that cannot be fully reflected by only static characteristics. This study proposes a new dynamic radiomics feature extraction workflow that uses time-dependent tomographic images of the same patient, focuses on the changes in image features over time, and then quantifies them as new dynamic features for diagnostic or prognostic evaluation. We first define the mathematical paradigm of dynamic radiomics and introduce three specific methods that can describe the transformation process of features over time. Three different clinical problems are used to validate the performance of the proposed dynamic feature with conventional 2D and 3D static features.