 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
More Informed Random Sample Consensus
Nov 18, 2020
Random sample consensus (RANSAC) is a robust model-fitting algorithm. It is widely used in many fields including image-stitching and point cloud registration. In RANSAC, data is uniformly sampled for hypothesis generation. However, this uniform sampling strategy does not fully utilize all the information on many problems. In this paper, we propose a method that samples data with a L\'{e}vy distribution together with a data sorting algorithm. In the hypothesis sampling step of the proposed method, data is sorted with a sorting algorithm we proposed, which sorts data based on the likelihood of a data point being in the inlier set. Then, hypotheses are sampled from the sorted data with L\'{e}vy distribution. The proposed method is evaluated on both simulation and real-world public datasets. Our method shows better results compared with the uniform baseline method.
Truly shift-invariant convolutional neural networks
Dec 01, 2020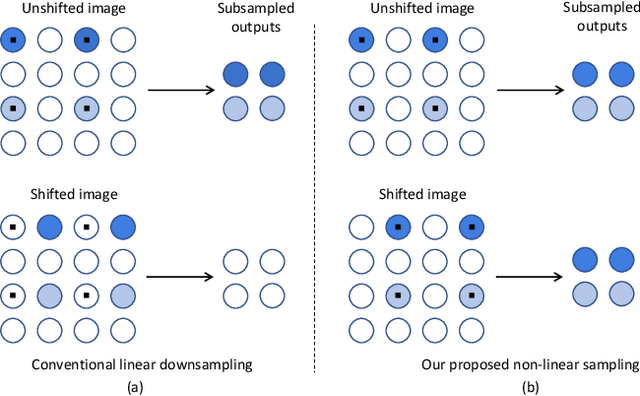
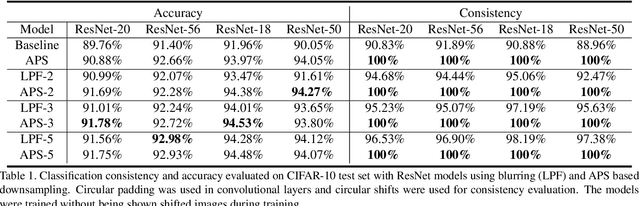
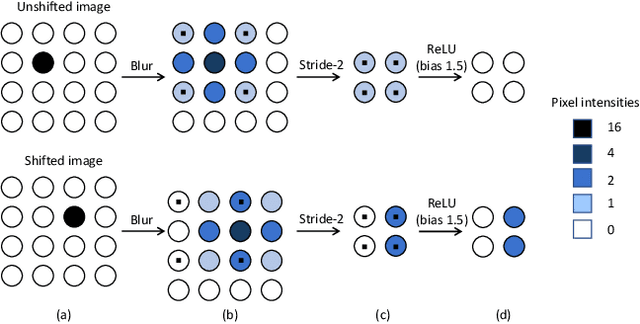
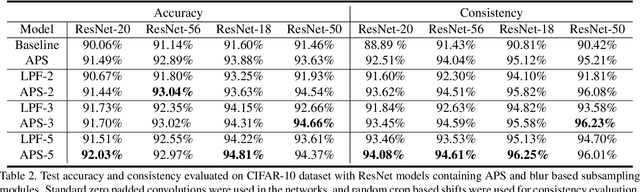
Thanks to the use of convolution and pooling layers, convolutional neural networks were for a long time thought to be shift-invariant. However, recent works have shown that the output of a CNN can change significantly with small shifts in input: a problem caused by the presence of downsampling (stride) layers. The existing solutions rely either on data augmentation or on anti-aliasing, both of which have limitations and neither of which enables perfect shift invariance. Additionally, the gains obtained from these methods do not extend to image patterns not seen during training. To address these challenges, we propose adaptive polyphase sampling (APS), a simple sub-sampling scheme that allows convolutional neural networks to achieve 100% consistency in classification performance under shifts, without any loss in accuracy. With APS the networks exhibit perfect consistency to shifts even before training, making it the first approach that makes convolutional neural networks truly shift invariant.
Automatic counting of fission tracks in apatite and muscovite using image processing
Jun 13, 2018

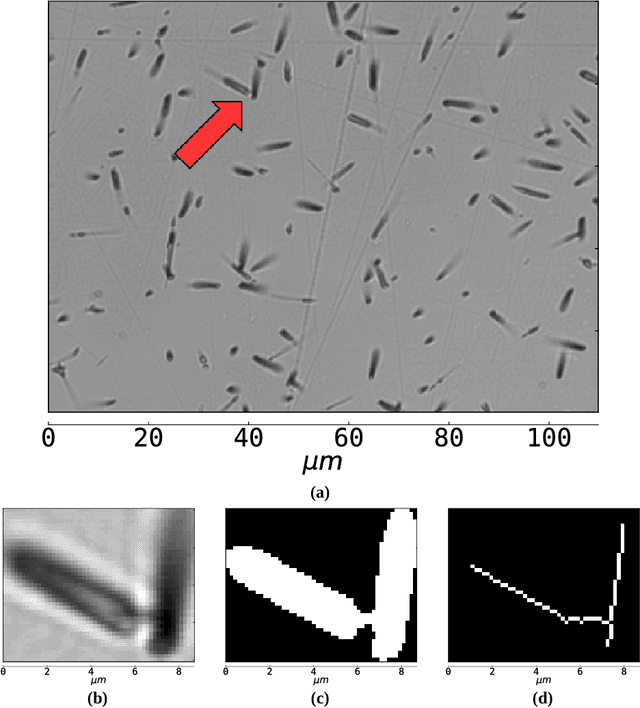
One of the major difficulties of automatic track counting using photomicrographs is separating overlapped tracks. We address this issue combining image processing algorithms such as skeletonization, and we test our algorithm with several binarization techniques. The counting algorithm was successfully applied to determine the efficiency factor GQR, necessary for standardless fission-track dating, involving counting induced tracks in apatite and muscovite with superficial densities of about $6 \times 10^5$ tracks/$cm^2$.
Mirror, Mirror, on the Wall, Who's Got the Clearest Image of Them All? - A Tailored Approach to Single Image Reflection Removal
May 29, 2018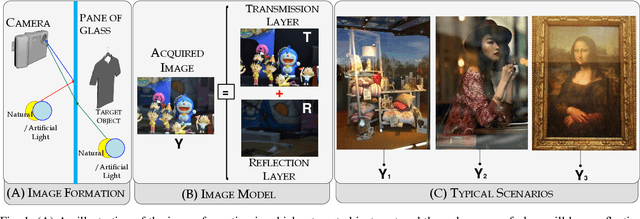



Removing reflection artefacts from a single-image is a problem of both theoretical and practical interest. Removing these artefacts still presents challenges because of the massively ill-posed nature of reflection suppression. In this work, we propose a technique based on a novel optimisation problem. Firstly, we introduce an $H^2$ fidelity term, which preserves fine detail while enforcing global colour similarity. Secondly, we introduce a spatially dependent gradient sparsity prior, which allows user guidance to prevent information loss in reflection-free areas. We show that this combination allows us to mitigate some major drawbacks of the existing methods for reflection removal. We demonstrate, through numerical and visual experiments, that our method is able to outperform the state-of-the-art methods and compete against a recent deep learning approach.
Accelerating GMM-based patch priors for image restoration: Three ingredients for a 100$\times$ speed-up
Oct 23, 2017
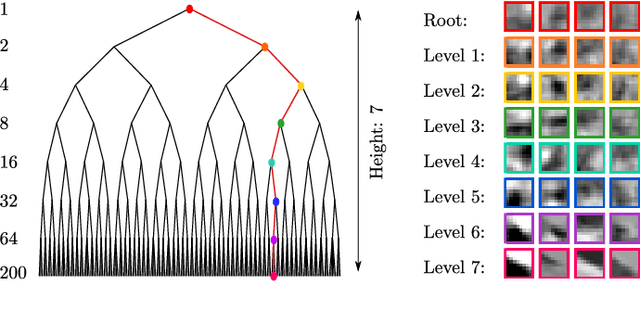
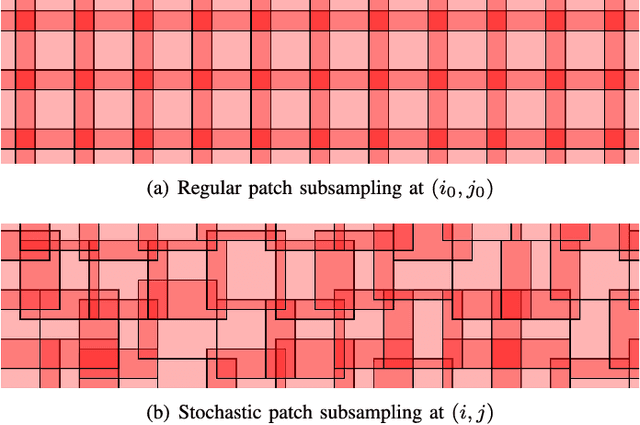
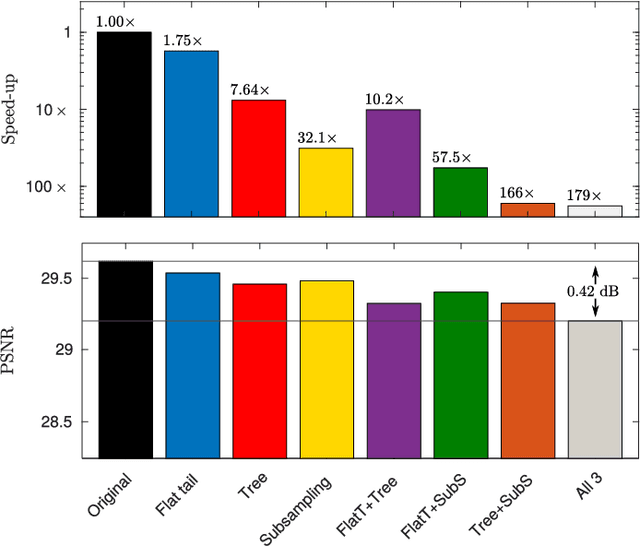
Image restoration methods aim to recover the underlying clean image from corrupted observations. The Expected Patch Log-likelihood (EPLL) algorithm is a powerful image restoration method that uses a Gaussian mixture model (GMM) prior on the patches of natural images. Although it is very effective for restoring images, its high runtime complexity makes EPLL ill-suited for most practical applications. In this paper, we propose three approximations to the original EPLL algorithm. The resulting algorithm, which we call the fast-EPLL (FEPLL), attains a dramatic speed-up of two orders of magnitude over EPLL while incurring a negligible drop in the restored image quality (less than 0.5 dB). We demonstrate the efficacy and versatility of our algorithm on a number of inverse problems such as denoising, deblurring, super-resolution, inpainting and devignetting. To the best of our knowledge, FEPLL is the first algorithm that can competitively restore a 512x512 pixel image in under 0.5s for all the degradations mentioned above without specialized code optimizations such as CPU parallelization or GPU implementation.
Joint Demosaicking and Denoising in the Wild: The Case of Training Under Ground Truth Uncertainty
Jan 12, 2021
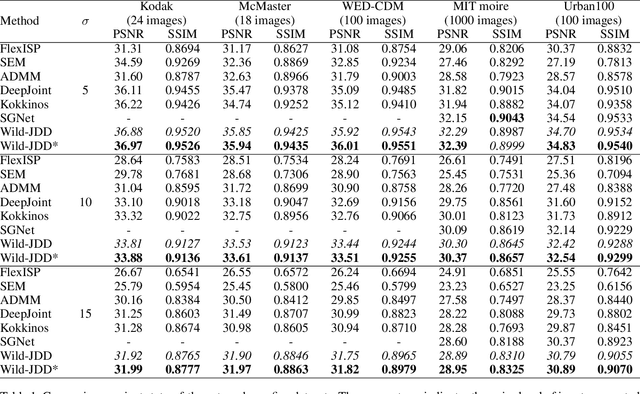
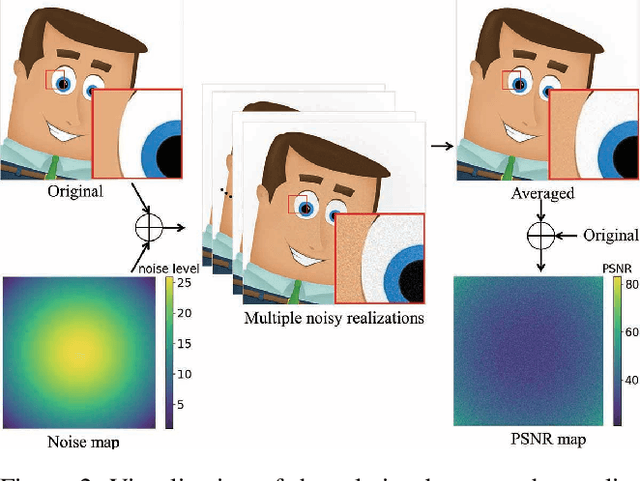
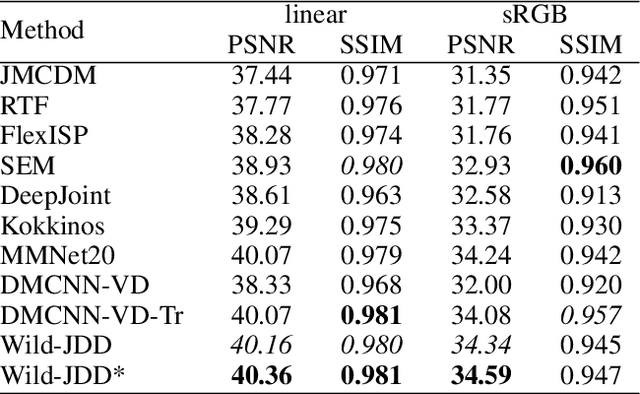
Image demosaicking and denoising are the two key fundamental steps in digital camera pipelines, aiming to reconstruct clean color images from noisy luminance readings. In this paper, we propose and study Wild-JDD, a novel learning framework for joint demosaicking and denoising in the wild. In contrast to previous works which generally assume the ground truth of training data is a perfect reflection of the reality, we consider here the more common imperfect case of ground truth uncertainty in the wild. We first illustrate its manifestation as various kinds of artifacts including zipper effect, color moire and residual noise. Then we formulate a two-stage data degradation process to capture such ground truth uncertainty, where a conjugate prior distribution is imposed upon a base distribution. After that, we derive an evidence lower bound (ELBO) loss to train a neural network that approximates the parameters of the conjugate prior distribution conditioned on the degraded input. Finally, to further enhance the performance for out-of-distribution input, we design a simple but effective fine-tuning strategy by taking the input as a weakly informative prior. Taking into account ground truth uncertainty, Wild-JDD enjoys good interpretability during optimization. Extensive experiments validate that it outperforms state-of-the-art schemes on joint demosaicking and denoising tasks on both synthetic and realistic raw datasets.
Deformable DETR: Deformable Transformers for End-to-End Object Detection
Oct 08, 2020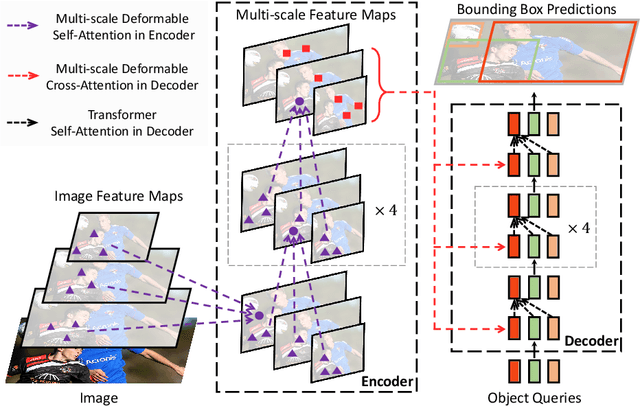
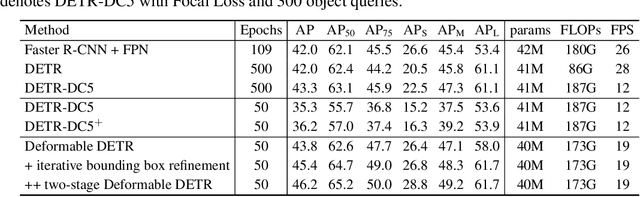
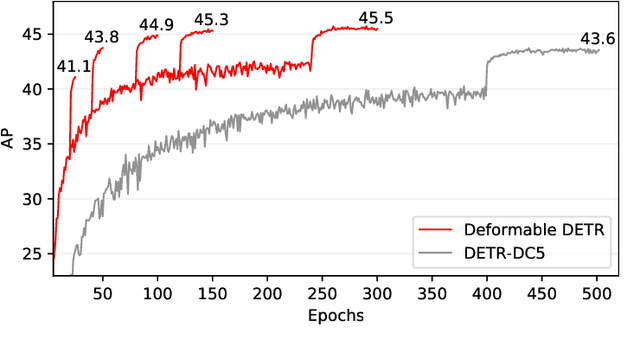
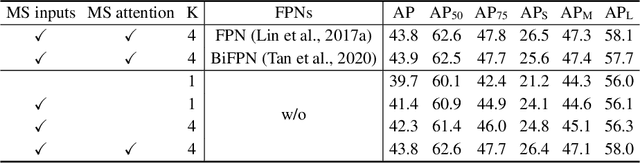
DETR has been recently proposed to eliminate the need for many hand-designed components in object detection while demonstrating good performance. However, it suffers from slow convergence and limited feature spatial resolution, due to the limitation of Transformer attention modules in processing image feature maps. To mitigate these issues, we proposed Deformable DETR, whose attention modules only attend to a small set of key sampling points around a reference. Deformable DETR can achieve better performance than DETR (especially on small objects) with 10$\times$ less training epochs. Extensive experiments on the COCO benchmark demonstrate the effectiveness of our approach. Code shall be released.
Addressing Computational Bottlenecks in Higher-Order Graph Matching with Tensor Kronecker Product Structure
Nov 17, 2020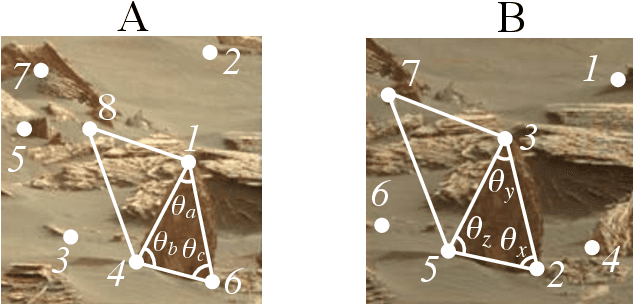
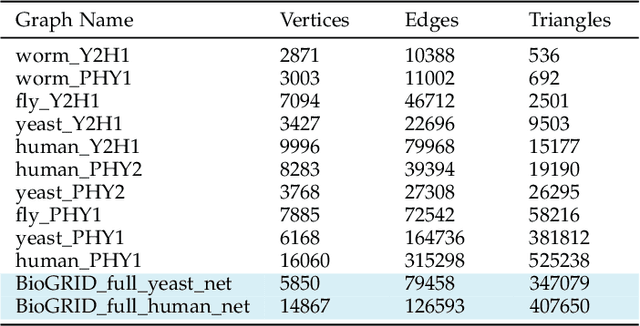
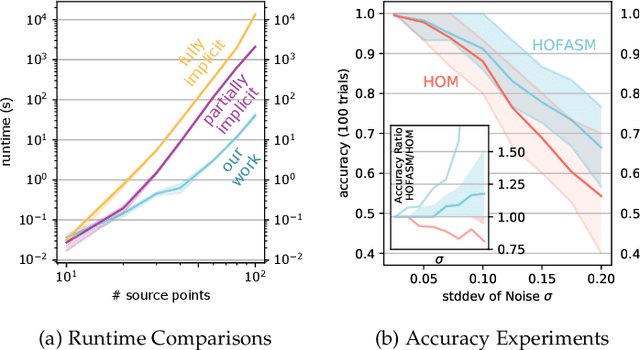
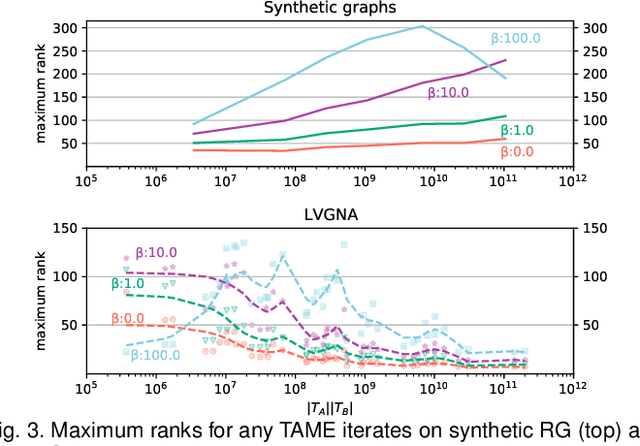
Graph matching, also known as network alignment, is the problem of finding a correspondence between the vertices of two separate graphs with strong applications in image correspondence and functional inference in protein networks. One class of successful techniques is based on tensor Kronecker products and tensor eigenvectors. A challenge with these techniques are memory and computational demands that are quadratic (or worse) in terms of problem size. In this manuscript we present and apply a theory of tensor Kronecker products to tensor based graph alignment algorithms to reduce their runtime complexity from quadratic to linear with no appreciable loss of quality. In terms of theory, we show that many matrix Kronecker product identities generalize to straightforward tensor counterparts, which is rare in tensor literature. Improved computation codes for two existing algorithms that utilize this new theory achieve a minimum 10 fold runtime improvement.
Each Part Matters: Local Patterns Facilitate Cross-view Geo-localization
Aug 26, 2020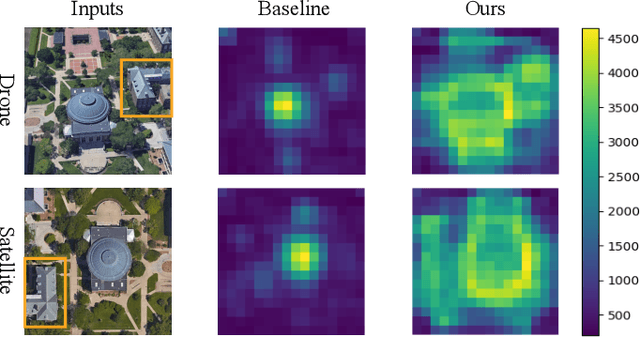

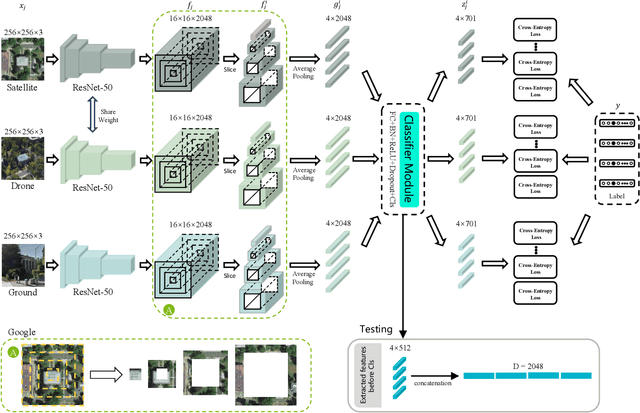
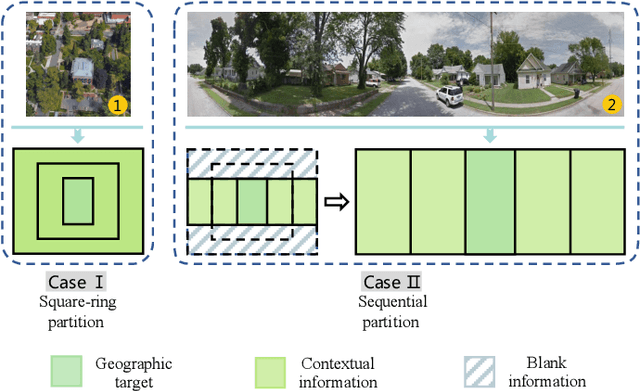
Cross-view geo-localization is to spot images of the same geographic target from different platforms, e.g., drone-view cameras and satellites. It is challenging in the large visual appearance changes caused by extreme viewpoint variations. Existing methods usually concentrate on mining the fine-grained feature of the geographic target in the image center, but underestimate the contextual information in neighbor areas. In this work, we argue that neighbor areas can be leveraged as auxiliary information, enriching discriminative clues for geo-localization. Specifically, we introduce a simple and effective deep neural network, called Local Pattern Network (LPN), to take advantage of contextual information in an end-to-end manner. Without using extra part estimators, LPN adopts a square-ring feature partition strategy, which provides the attention according to the distance to the image center. It eases the part matching and enables the part-wise representation learning. Owing to the square-ring partition design, the proposed LPN has good scalability to rotation variations and achieves competitive results on two prevailing benchmarks, i.e., University-1652 and CVUSA. Besides, we also show the proposed LPN can be easily embedded into other frameworks to further boost performance.
Realistic text replacement with non-uniform style conditioning
Jun 07, 2020

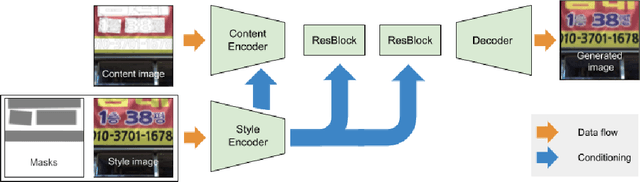

In this work, we study the possibility of realistic text replacement, the goal of which is to replace text present in the image with user-supplied text. The replacement should be performed in a way that will not allow distinguishing the resulting image from the original one. We achieve this goal by developing a novel non-uniform style conditioning layer and apply it to an encoder-decoder ResNet based architecture. The resulting model is a single-stage model, with no post-processing. The proposed model achieves realistic text replacement and outperforms existing approaches on ICDAR MLT.