 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Context Aware Query Image Representation for Particular Object Retrieval
Mar 03, 2017
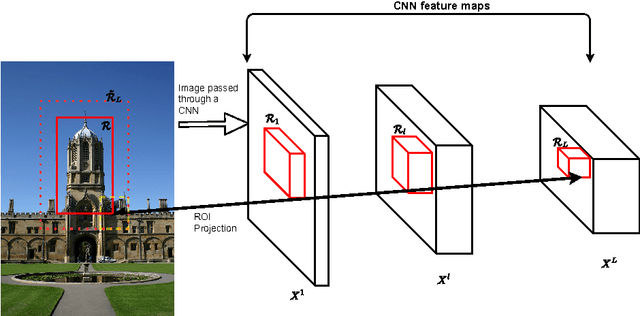

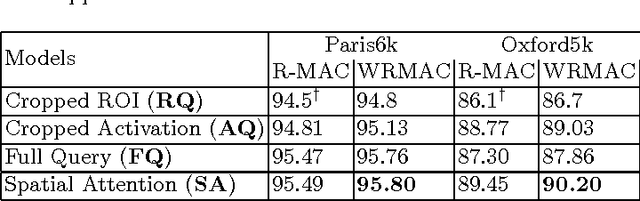
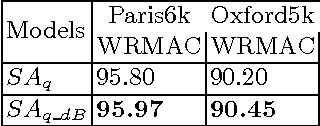
The current models of image representation based on Convolutional Neural Networks (CNN) have shown tremendous performance in image retrieval. Such models are inspired by the information flow along the visual pathway in the human visual cortex. We propose that in the field of particular object retrieval, the process of extracting CNN representations from query images with a given region of interest (ROI) can also be modelled by taking inspiration from human vision. Particularly, we show that by making the CNN pay attention on the ROI while extracting query image representation leads to significant improvement over the baseline methods on challenging Oxford5k and Paris6k datasets. Furthermore, we propose an extension to a recently introduced encoding method for CNN representations, regional maximum activations of convolutions (R-MAC). The proposed extension weights the regional representations using a novel saliency measure prior to aggregation. This leads to further improvement in retrieval accuracy.
Using PSPNet and UNet to analyze the internal parameter relationship and visualization of the convolutional neural network
Aug 08, 2020Convolutional neural network(CNN) has achieved great success in many fields, but due to the huge number of parameters, it is very difficult to study. Then, can we start from the parameters themselves to explore the relationship between the internal parameters of CNN? This paper proposes to use the convolution layer parameters substitution with the same convolution kernel setting to explore the relationship between the internal parameters of CNN and proposes to use the CNN visualization method to check the relationship. Using the visualization method, the forward propagation process of CNN is visualized. It is an intuitive representation of how CNN learns. According to the experiments, this paper believes that 1. Residual layer parameters of ResNet are correlated, and some layers can be substituted for each other; 2. Image segmentation is a process of first learning image texture features and then locating and segmentation.
Automated Image Captioning for Rapid Prototyping and Resource Constrained Environments
Jun 04, 2016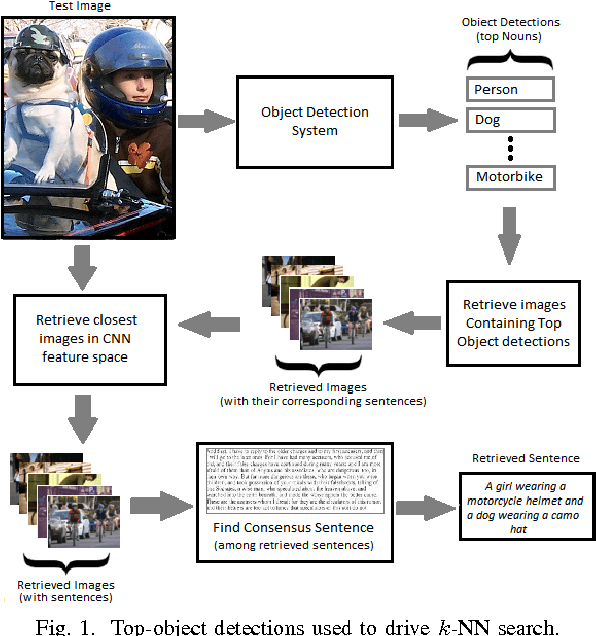

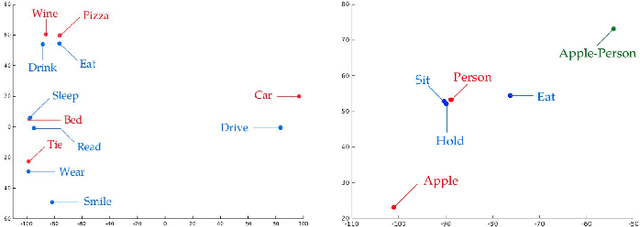

Significant performance gains in deep learning coupled with the exponential growth of image and video data on the Internet have resulted in the recent emergence of automated image captioning systems. Ensuring scalability of automated image captioning systems with respect to the ever increasing volume of image and video data is a significant challenge. This paper provides a valuable insight in that the detection of a few significant (top) objects in an image allows one to extract other relevant information such as actions (verbs) in the image. We expect this insight to be useful in the design of scalable image captioning systems. We address two parameters by which the scalability of image captioning systems could be quantified, i.e., the traditional algorithmic time complexity which is important given the resource limitations of the user device and the system development time since the programmers' time is a critical resource constraint in many real-world scenarios. Additionally, we address the issue of how word embeddings could be used to infer the verb (action) from the nouns (objects) in a given image in a zero-shot manner. Our results show that it is possible to attain reasonably good performance on predicting actions and captioning images using our approaches with the added advantage of simplicity of implementation.
Convolutional neural networks that teach microscopes how to image
Sep 21, 2017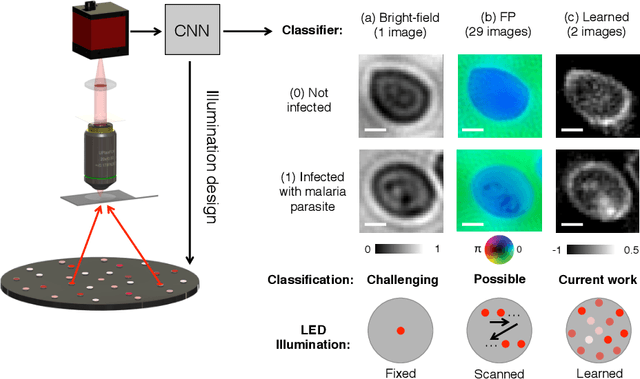
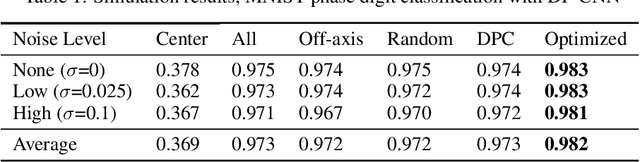
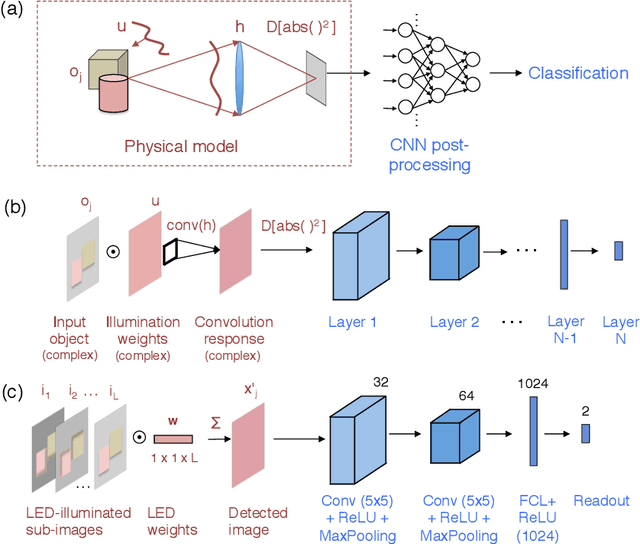
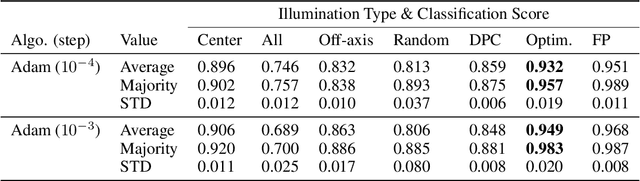
Deep learning algorithms offer a powerful means to automatically analyze the content of medical images. However, many biological samples of interest are primarily transparent to visible light and contain features that are difficult to resolve with a standard optical microscope. Here, we use a convolutional neural network (CNN) not only to classify images, but also to optimize the physical layout of the imaging device itself. We increase the classification accuracy of a microscope's recorded images by merging an optical model of image formation into the pipeline of a CNN. The resulting network simultaneously determines an ideal illumination arrangement to highlight important sample features during image acquisition, along with a set of convolutional weights to classify the detected images post-capture. We demonstrate our joint optimization technique with an experimental microscope configuration that automatically identifies malaria-infected cells with 5-10% higher accuracy than standard and alternative microscope lighting designs.
MatryODShka: Real-time 6DoF Video View Synthesis using Multi-Sphere Images
Aug 14, 2020We introduce a method to convert stereo 360{\deg} (omnidirectional stereo) imagery into a layered, multi-sphere image representation for six degree-of-freedom (6DoF) rendering. Stereo 360{\deg} imagery can be captured from multi-camera systems for virtual reality (VR), but lacks motion parallax and correct-in-all-directions disparity cues. Together, these can quickly lead to VR sickness when viewing content. One solution is to try and generate a format suitable for 6DoF rendering, such as by estimating depth. However, this raises questions as to how to handle disoccluded regions in dynamic scenes. Our approach is to simultaneously learn depth and disocclusions via a multi-sphere image representation, which can be rendered with correct 6DoF disparity and motion parallax in VR. This significantly improves comfort for the viewer, and can be inferred and rendered in real time on modern GPU hardware. Together, these move towards making VR video a more comfortable immersive medium.
MAGNet: Multi-Region Attention-Assisted Grounding of Natural Language Queries at Phrase Level
Jun 06, 2020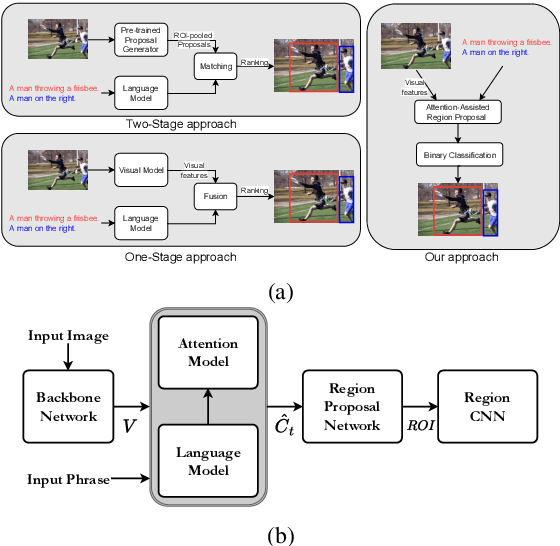
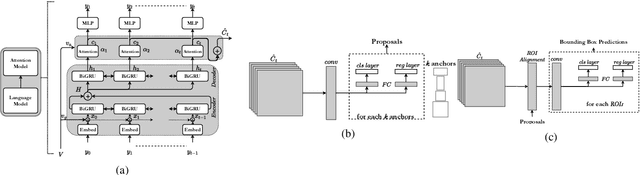


Grounding free-form textual queries necessitates an understanding of these textual phrases and its relation to the visual cues to reliably reason about the described locations. Spatial attention networks are known to learn this relationship and focus its gaze on salient objects in the image. Thus, we propose to utilize spatial attention networks for image-level visual-textual fusion preserving local (word) and global (phrase) information to refine region proposals with an in-network Region Proposal Network (RPN) and detect single or multiple regions for a phrase query. We focus only on the phrase query - ground truth pair (referring expression) for a model independent of the constraints of the datasets i.e. additional attributes, context etc. For such referring expression dataset ReferIt game, our Multi-region Attention-assisted Grounding network (MAGNet) achieves over 12\% improvement over the state-of-the-art. Without the context from image captions and attribute information in Flickr30k Entities, we still achieve competitive results compared to the state-of-the-art.
Video Semantic Segmentation with Distortion-Aware Feature Correction
Jun 18, 2020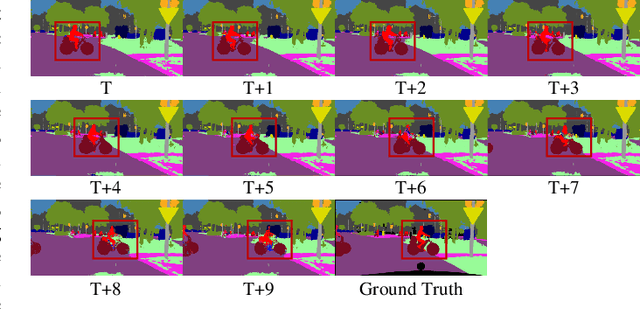
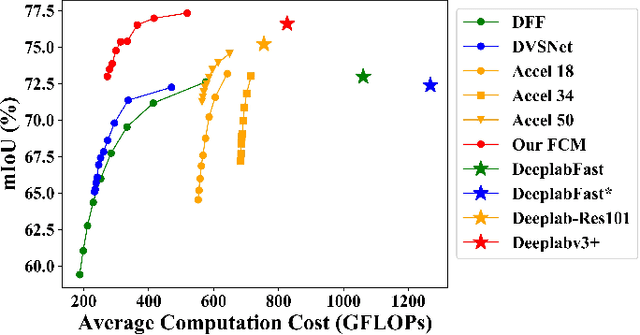
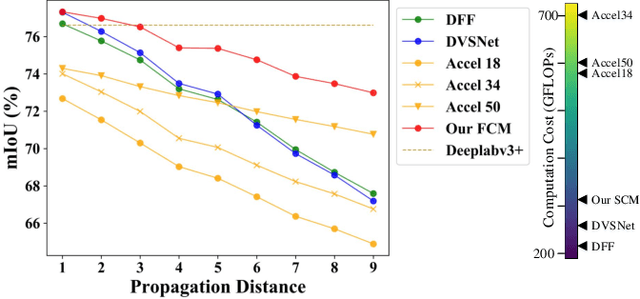
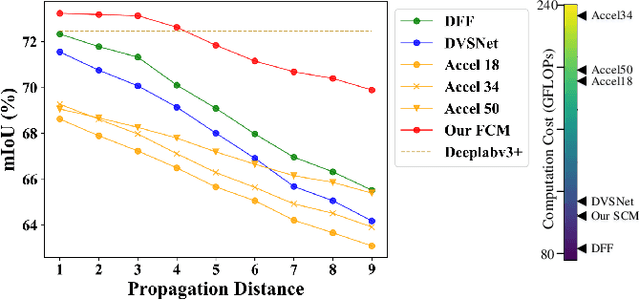
Video semantic segmentation is active in recent years benefited from the great progress of image semantic segmentation. For such a task, the per-frame image segmentation is generally unacceptable in practice due to high computation cost. To tackle this issue, many works use the flow-based feature propagation to reuse the features of previous frames. However, the optical flow estimation inevitably suffers inaccuracy and then causes the propagated features distorted. In this paper, we propose distortion-aware feature correction to alleviate the issue, which improves video segmentation performance by correcting distorted propagated features. To be specific, we firstly propose to transfer distortion patterns from feature into image space and conduct effective distortion map prediction. Benefited from the guidance of distortion maps, we proposed Feature Correction Module (FCM) to rectify propagated features in the distorted areas. Our proposed method can significantly boost the accuracy of video semantic segmentation at a low price. The extensive experimental results on Cityscapes and CamVid show that our method outperforms the recent state-of-the-art methods.
Global Context Networks
Dec 24, 2020
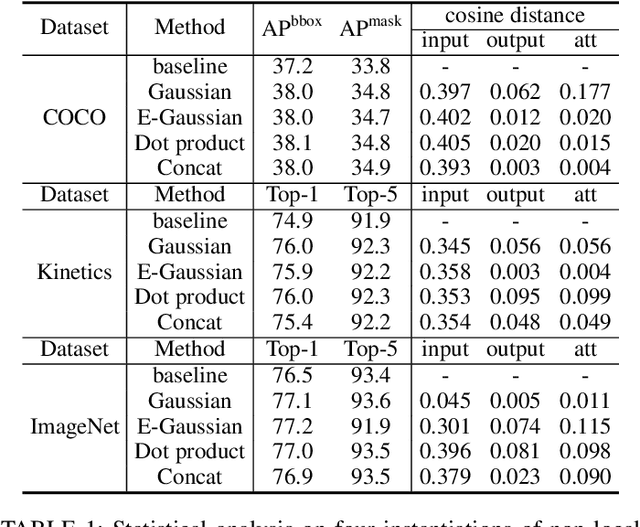

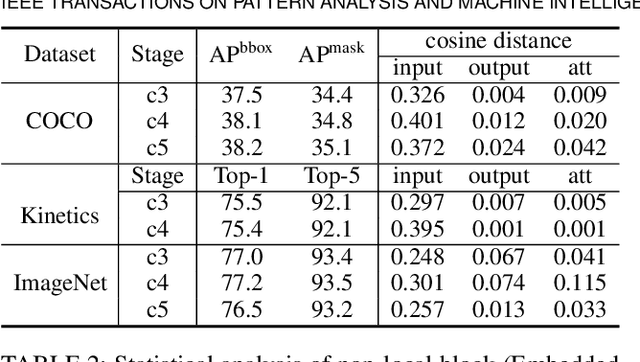
The Non-Local Network (NLNet) presents a pioneering approach for capturing long-range dependencies within an image, via aggregating query-specific global context to each query position. However, through a rigorous empirical analysis, we have found that the global contexts modeled by the non-local network are almost the same for different query positions. In this paper, we take advantage of this finding to create a simplified network based on a query-independent formulation, which maintains the accuracy of NLNet but with significantly less computation. We further replace the one-layer transformation function of the non-local block by a two-layer bottleneck, which further reduces the parameter number considerably. The resulting network element, called the global context (GC) block, effectively models global context in a lightweight manner, allowing it to be applied at multiple layers of a backbone network to form a global context network (GCNet). Experiments show that GCNet generally outperforms NLNet on major benchmarks for various recognition tasks. The code and network configurations are available at https://github.com/xvjiarui/GCNet.
Fault Location Estimation by Using Machine Learning Methods in Mixed Transmission Lines
Nov 06, 2020
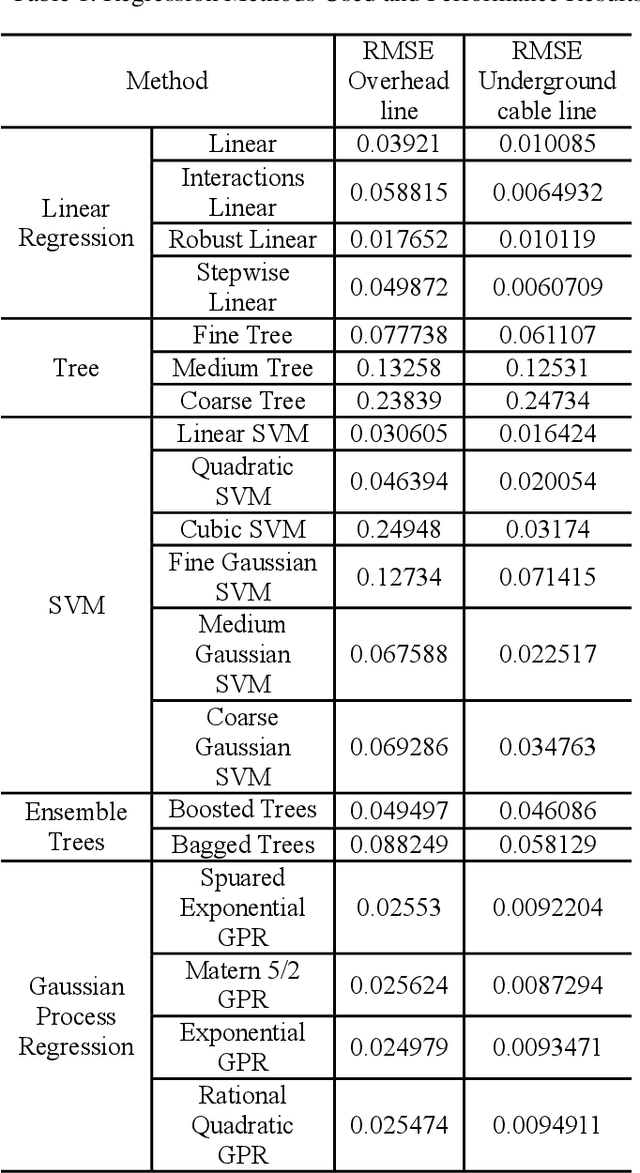
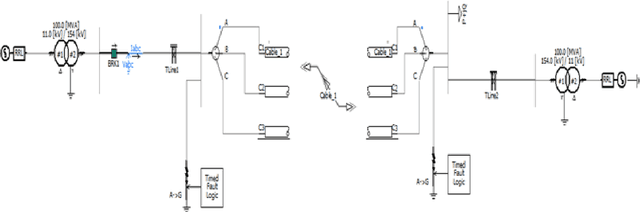
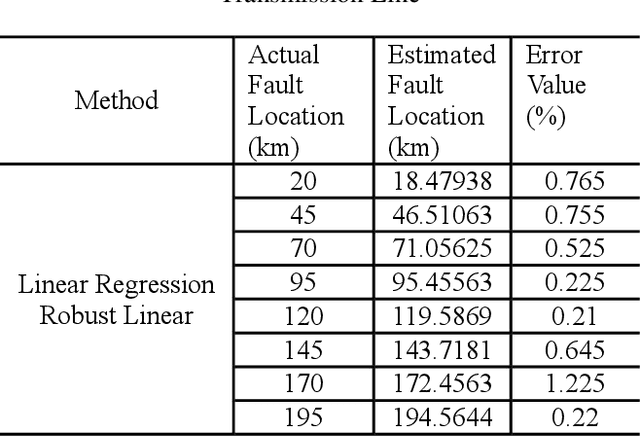
Overhead lines are generally used for electrical energy transmission. Also, XLPE underground cable lines are generally used in the city center and the crowded areas to provide electrical safety, so high voltage underground cable lines are used together with overhead line in the transmission lines, and these lines are called as the mixed lines. The distance protection relays are used to determine the impedance based fault location according to the current and voltage magnitudes in the transmission lines. However, the fault location cannot be correctly detected in mixed transmission lines due to different characteristic impedance per unit length because the characteristic impedance of high voltage cable line is significantly different from overhead line. Thus, determinations of the fault section and location with the distance protection relays are difficult in the mixed transmission lines. In this study, 154 kV overhead transmission line and underground cable line are examined as the mixed transmission line for the distance protection relays. Phase to ground faults are created in the mixed transmission line, and overhead line section and underground cable section are simulated by using PSCAD. The short circuit fault images are generated in the distance protection relay for the overhead transmission line and underground cable transmission line faults. The images include the RX impedance diagram of the fault, and the RX impedance diagram have been detected by applying image processing steps. The regression methods are used for prediction of the fault location, and the results of image processing are used as the input parameters for the training process of the regression methods. The results of regression methods are compared to select the most suitable method at the end of this study for forecasting of the fault location in transmission lines.
Give Me Something to Eat: Referring Expression Comprehension with Commonsense Knowledge
Jun 02, 2020
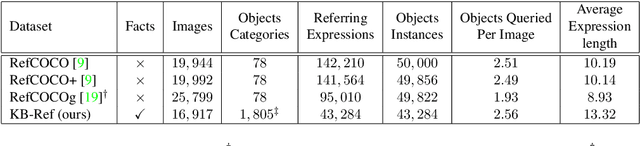
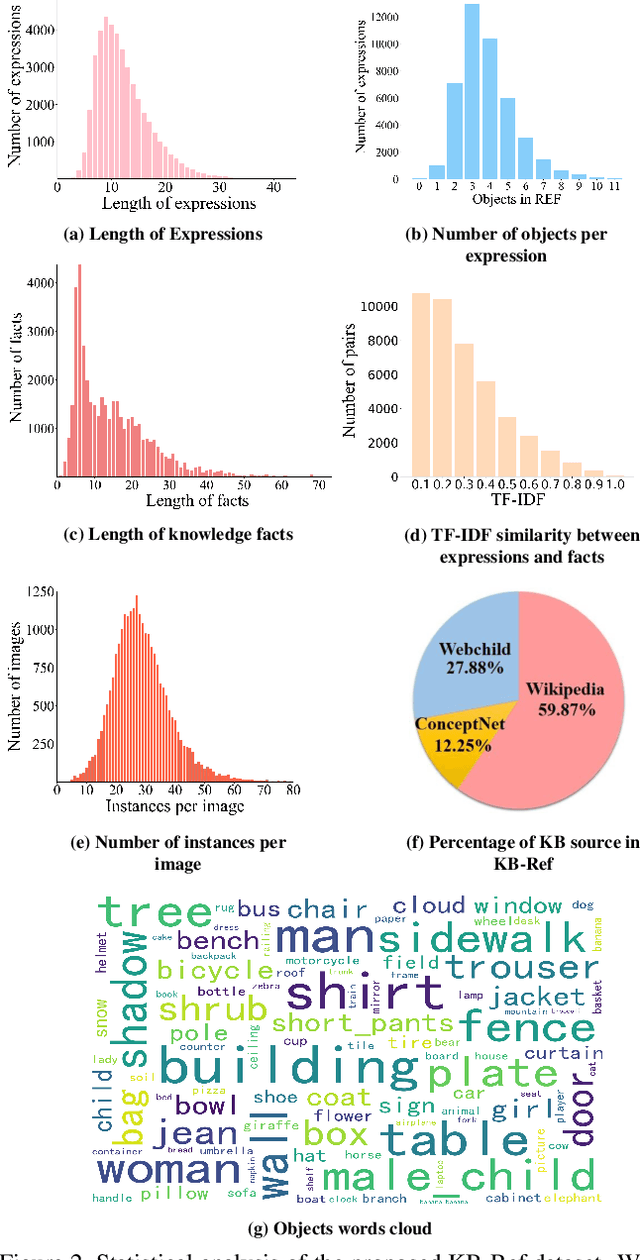
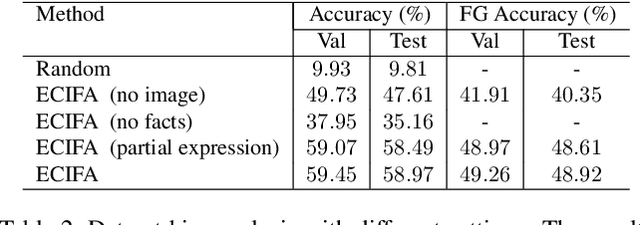
Conventional referring expression comprehension (REF) assumes people to query something from an image by describing its visual appearance and spatial location, but in practice, we often ask for an object by describing its affordance or other non-visual attributes, especially when we do not have a precise target. For example, sometimes we say 'Give me something to eat'. In this case, we need to use commonsense knowledge to identify the objects in the image. Unfortunately, these is no existing referring expression dataset reflecting this requirement, not to mention a model to tackle this challenge. In this paper, we collect a new referring expression dataset, called KB-Ref, containing 43k expressions on 16k images. In KB-Ref, to answer each expression (detect the target object referred by the expression), at least one piece of commonsense knowledge must be required. We then test state-of-the-art (SoTA) REF models on KB-Ref, finding that all of them present a large drop compared to their outstanding performance on general REF datasets. We also present an expression conditioned image and fact attention (ECIFA) network that extract information from correlated image regions and commonsense knowledge facts. Our method leads to a significant improvement over SoTA REF models, although there is still a gap between this strong baseline and human performance. The dataset and baseline models will be released.