 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Efficient Depth Completion Using Learned Bases
Dec 02, 2020
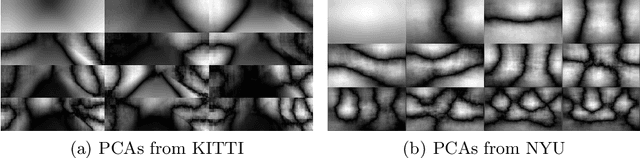



In this paper, we propose a new global geometry constraint for depth completion. By assuming depth maps often lay on low dimensional subspaces, a dense depth map can be approximated by a weighted sum of full-resolution principal depth bases. The principal components of depth fields can be learned from natural depth maps. The given sparse depth points are served as a data term to constrain the weighting process. When the input depth points are too sparse, the recovered dense depth maps are often over smoothed. To address this issue, we add a colour-guided auto-regression model as another regularization term. It assumes the reconstructed depth maps should share the same nonlocal similarity in the accompanying colour image. Our colour-guided PCA depth completion method has closed-form solutions, thus can be efficiently solved and is significantly more accurate than PCA only method. Extensive experiments on KITTI and Middlebury datasets demonstrate the superior performance of our proposed method.
3D Human Shape and Pose from a Single Low-Resolution Image with Self-Supervised Learning
Aug 09, 2020
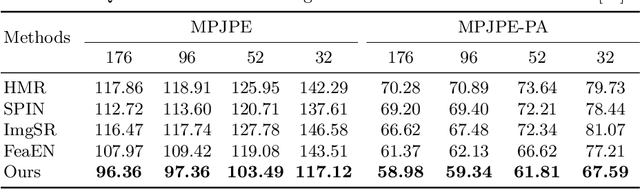
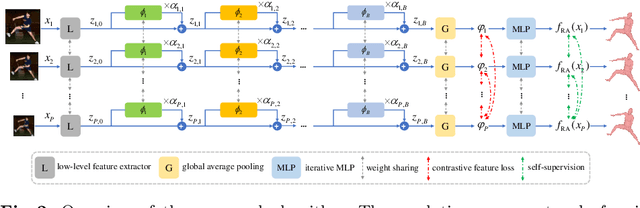
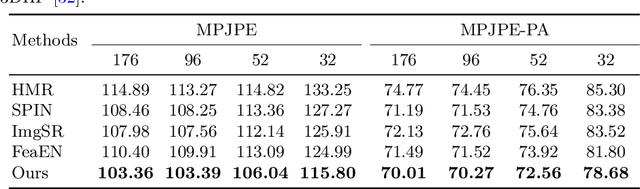
3D human shape and pose estimation from monocular images has been an active area of research in computer vision, having a substantial impact on the development of new applications, from activity recognition to creating virtual avatars. Existing deep learning methods for 3D human shape and pose estimation rely on relatively high-resolution input images; however, high-resolution visual content is not always available in several practical scenarios such as video surveillance and sports broadcasting. Low-resolution images in real scenarios can vary in a wide range of sizes, and a model trained in one resolution does not typically degrade gracefully across resolutions. Two common approaches to solve the problem of low-resolution input are applying super-resolution techniques to the input images which may result in visual artifacts, or simply training one model for each resolution, which is impractical in many realistic applications. To address the above issues, this paper proposes a novel algorithm called RSC-Net, which consists of a Resolution-aware network, a Self-supervision loss, and a Contrastive learning scheme. The proposed network is able to learn the 3D body shape and pose across different resolutions with a single model. The self-supervision loss encourages scale-consistency of the output, and the contrastive learning scheme enforces scale-consistency of the deep features. We show that both these new training losses provide robustness when learning 3D shape and pose in a weakly-supervised manner. Extensive experiments demonstrate that the RSC-Net can achieve consistently better results than the state-of-the-art methods for challenging low-resolution images.
DAN: A Deformation-Aware Network for Consecutive Biomedical Image Interpolation
Apr 23, 2020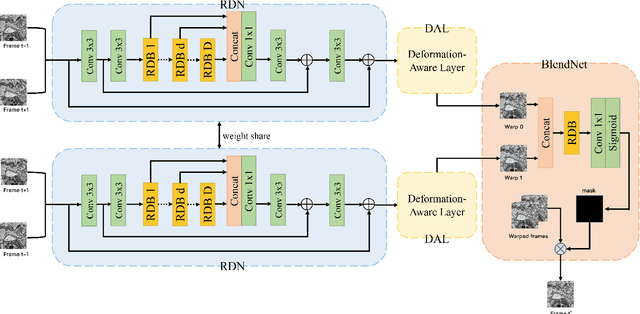
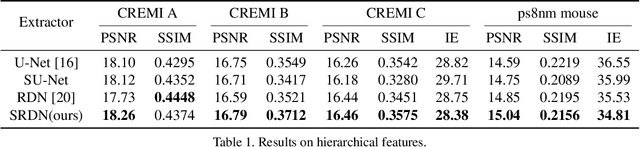
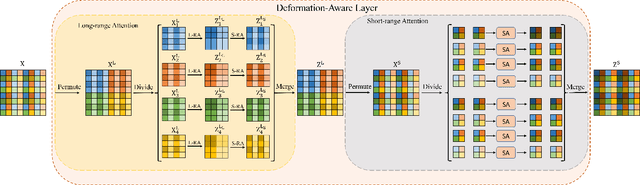
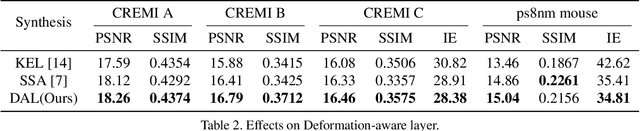
The continuity of biological tissue between consecutive biomedical images makes it possible for the video interpolation algorithm, to recover large area defects and tears that are common in biomedical images. However, noise and blur differences, large deformation, and drift between biomedical images, make the task challenging. To address the problem, this paper introduces a deformation-aware network to synthesize each pixel in accordance with the continuity of biological tissue. First, we develop a deformation-aware layer for consecutive biomedical images interpolation that implicitly adopting global perceptual deformation. Second, we present an adaptive style-balance loss to take the style differences of consecutive biomedical images such as blur and noise into consideration. Guided by the deformation-aware module, we synthesize each pixel from a global domain adaptively which further improves the performance of pixel synthesis. Quantitative and qualitative experiments on the benchmark dataset show that the proposed method is superior to the state-of-the-art approaches.
Residual-Sparse Fuzzy $C$-Means Clustering Incorporating Morphological Reconstruction and Wavelet frames
Feb 14, 2020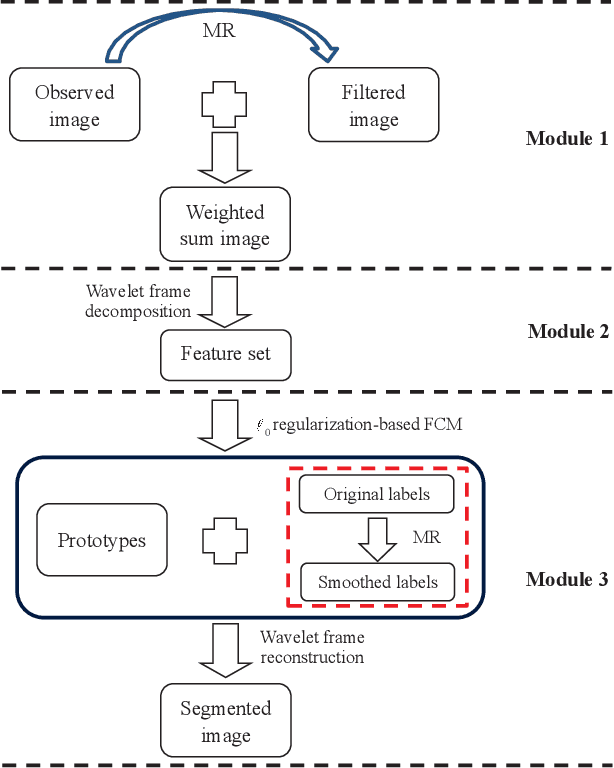
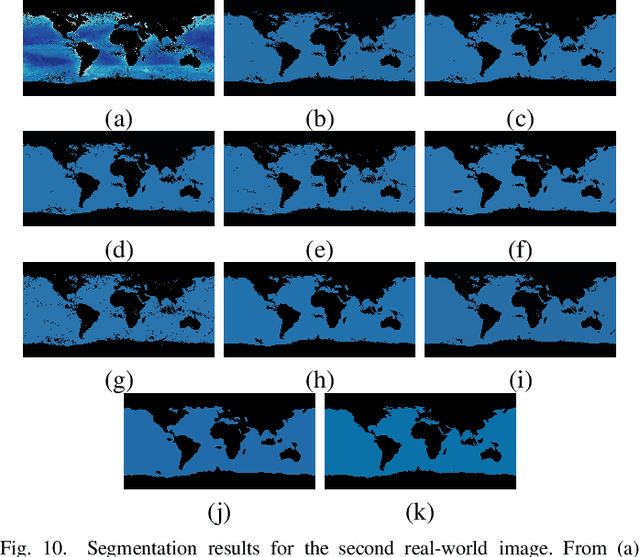
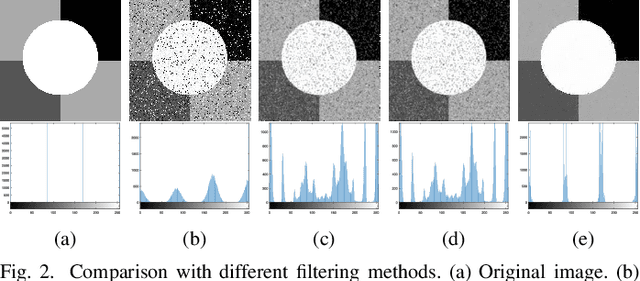

Instead of directly utilizing an observed image including some outliers, noise or intensity inhomogeneity, the use of its ideal value (e.g. noise-free image) has a favorable impact on clustering. Hence, the accurate estimation of the residual (e.g. unknown noise) between the observed image and its ideal value is an important task. To do so, we propose an $\ell_0$ regularization-based Fuzzy $C$-Means (FCM) algorithm incorporating a morphological reconstruction operation and a tight wavelet frame transform. To achieve a sound trade-off between detail preservation and noise suppression, morphological reconstruction is used to filter an observed image. By combining the observed and filtered images, a weighted sum image is generated. Since a tight wavelet frame system has sparse representations of an image, it is employed to decompose the weighted sum image, thus forming its corresponding feature set. Taking it as data for clustering, we present an improved FCM algorithm by imposing an $\ell_0$ regularization term on the residual between the feature set and its ideal value, which implies that the favorable estimation of the residual is obtained and the ideal value participates in clustering. Spatial information is also introduced into clustering since it is naturally encountered in image segmentation. Furthermore, it makes the estimation of the residual more reliable. To further enhance the segmentation effects of the improved FCM algorithm, we also employ the morphological reconstruction to smoothen the labels generated by clustering. Finally, based on the prototypes and smoothed labels, the segmented image is reconstructed by using a tight wavelet frame reconstruction operation. Experimental results reported for synthetic, medical, and color images show that the proposed algorithm is effective and efficient, and outperforms other algorithms.
Joint Face Super-Resolution and Deblurring Using a Generative Adversarial Network
Dec 22, 2019

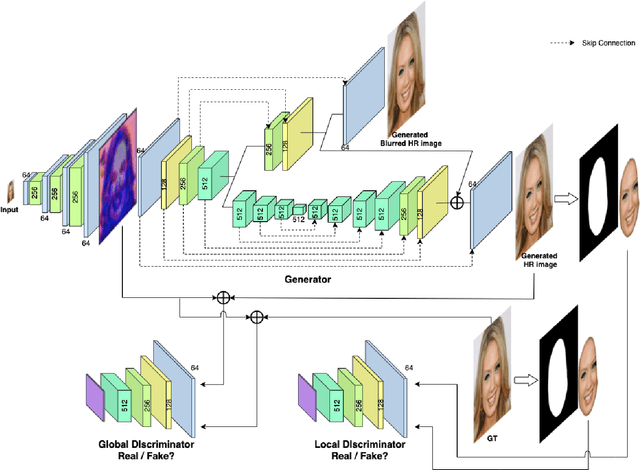

Facial image super-resolution (SR) is an important preprocessing for facial image analysis, face recognition, and image-based 3D face reconstruction. Recent convolutional neural network (CNN) based method has shown excellent performance by learning mapping relation using pairs of low-resolution (LR) and high-resolution (HR) facial images. However, since the HR facial image reconstruction using CNN is conventionally aimed to increase the PSNR and SSIM metrics, the reconstructed HR image might not be realistic even with high scores. An adversarial framework is proposed in this study to reconstruct the HR facial image by simultaneously generating an HR image with and without blur. First, the spatial resolution of the LR facial image is increased by eight times using a five-layer CNN. Then, the encoder extracts the features of the up-scaled image. These features are finally sent to two branches (decoders) to generate an HR facial image with and without blur. In addition, local and global discriminators are combined to focus on the reconstruction of HR facial structures. Experiment results show that the proposed algorithm generates a realistic HR facial image. Furthermore, the proposed method can generate a variety of different facial images.
HDR-GAN: HDR Image Reconstruction from Multi-Exposed LDR Images with Large Motions
Jul 03, 2020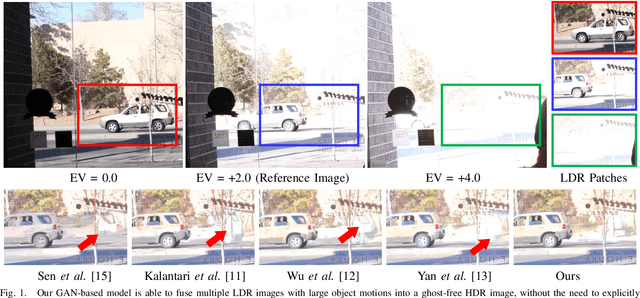
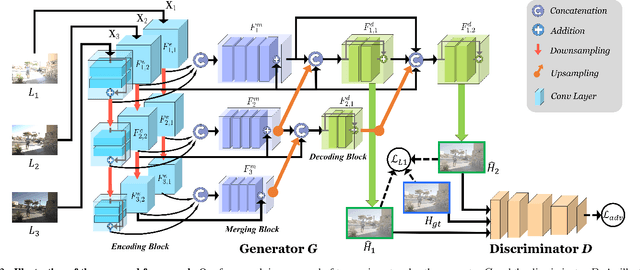

Synthesizing high dynamic range (HDR) images from multiple low-dynamic range (LDR) exposures in dynamic scenes is challenging. There are two major problems caused by the large motions of foreground objects. One is the severe misalignment among the LDR images. The other is the missing content due to the over-/under-saturated regions caused by the moving objects, which may not be easily compensated for by the multiple LDR exposures. Thus, it requires the HDR generation model to be able to properly fuse the LDR images and restore the missing details without introducing artifacts. To address these two problems, we propose in this paper a novel GAN-based model, HDR-GAN, for synthesizing HDR images from multi-exposed LDR images. To our best knowledge, this work is the first GAN-based approach for fusing multi-exposed LDR images for HDR reconstruction. By incorporating adversarial learning, our method is able to produce faithful information in the regions with missing content. In addition, we also propose a novel generator network, with a reference-based residual merging block for aligning large object motions in the feature domain, and a deep HDR supervision scheme for eliminating artifacts of the reconstructed HDR images. Experimental results demonstrate that our model achieves state-of-the-art reconstruction performance over the prior HDR methods on diverse scenes.
Single Image Super-Resolution via Cascaded Multi-Scale Cross Network
Feb 24, 2018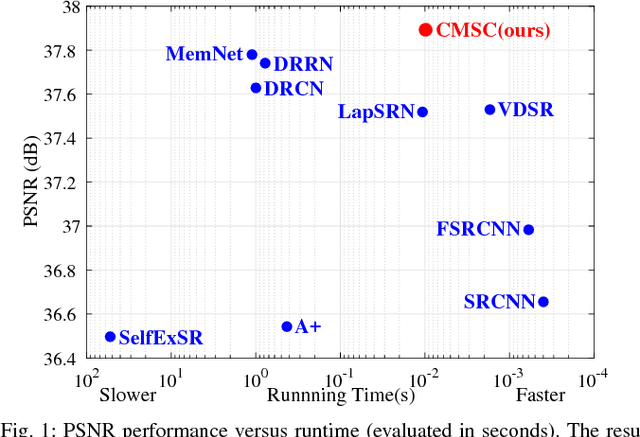

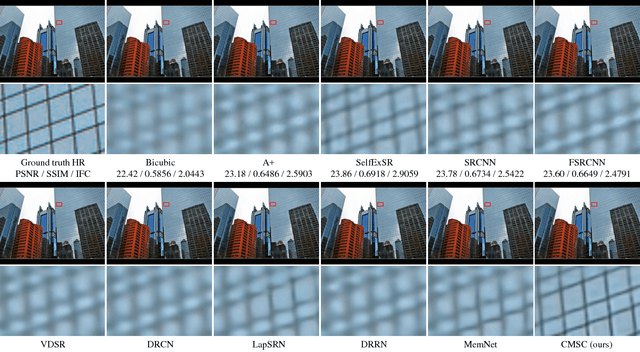
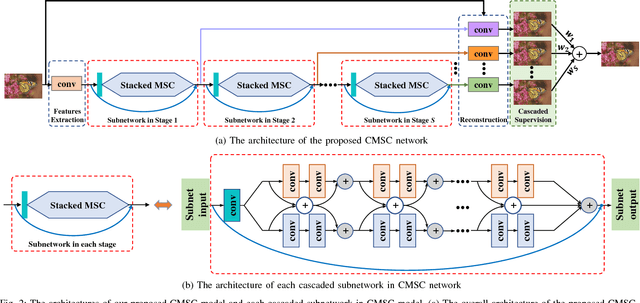
The deep convolutional neural networks have achieved significant improvements in accuracy and speed for single image super-resolution. However, as the depth of network grows, the information flow is weakened and the training becomes harder and harder. On the other hand, most of the models adopt a single-stream structure with which integrating complementary contextual information under different receptive fields is difficult. To improve information flow and to capture sufficient knowledge for reconstructing the high-frequency details, we propose a cascaded multi-scale cross network (CMSC) in which a sequence of subnetworks is cascaded to infer high resolution features in a coarse-to-fine manner. In each cascaded subnetwork, we stack multiple multi-scale cross (MSC) modules to fuse complementary multi-scale information in an efficient way as well as to improve information flow across the layers. Meanwhile, by introducing residual-features learning in each stage, the relative information between high-resolution and low-resolution features is fully utilized to further boost reconstruction performance. We train the proposed network with cascaded-supervision and then assemble the intermediate predictions of the cascade to achieve high quality image reconstruction. Extensive quantitative and qualitative evaluations on benchmark datasets illustrate the superiority of our proposed method over state-of-the-art super-resolution methods.
Semantic Segmentation of highly class imbalanced fully labelled 3D volumetric biomedical images and unsupervised Domain Adaptation of the pre-trained Segmentation Network to segment another fully unlabelled Biomedical 3D Image stack
Mar 13, 2020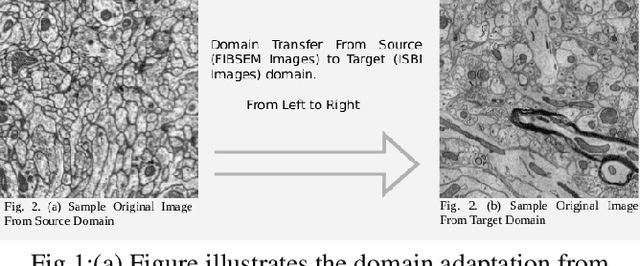
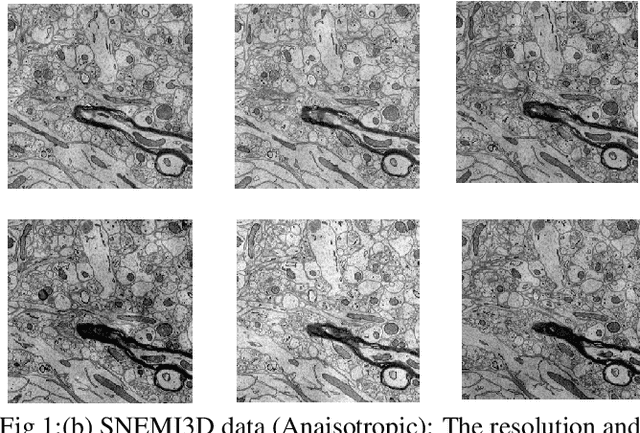
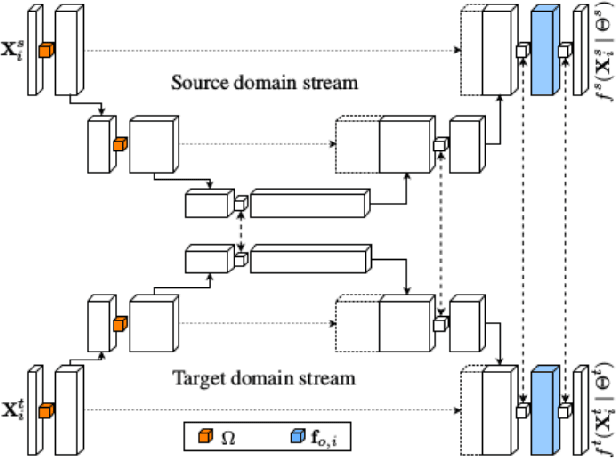

The goal of our work is to perform pixel label semantic segmentation on 3D biomedical volumetric data. Manual annotation is always difficult for a large bio-medical dataset. So, we consider two cases where one dataset is fully labeled and the other dataset is assumed to be fully unlabelled. We first perform Semantic Segmentation on the fully labeled isotropic biomedical source data (FIBSEM) and try to incorporate the the trained model for segmenting the target unlabelled dataset(SNEMI3D)which shares some similarities with the source dataset in the context of different types of cellular bodies and other cellular components. Although, the cellular components vary in size and shape. So in this paper, we have proposed a novel approach in the context of unsupervised domain adaptation while classifying each pixel of the target volumetric data into cell boundary and cell body. Also, we have proposed a novel approach to giving non-uniform weights to different pixels in the training images while performing the pixel-level semantic segmentation in the presence of the corresponding pixel-wise label map along with the training original images in the source domain. We have used the Entropy Map or a Distance Transform matrix retrieved from the given ground truth label map which has helped to overcome the class imbalance problem in the medical image data where the cell boundaries are extremely thin and hence, extremely prone to be misclassified as non-boundary.
Understanding Spatial Relations through Multiple Modalities
Jul 19, 2020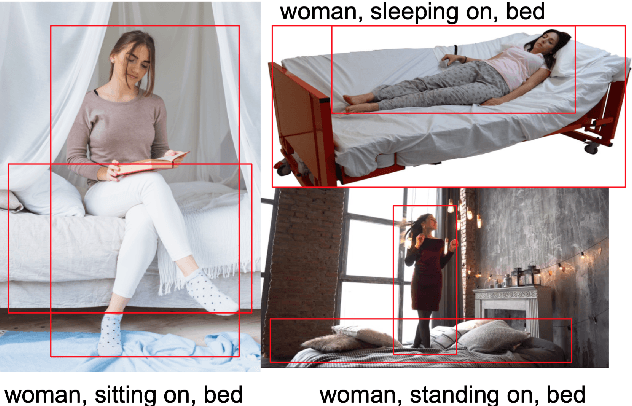
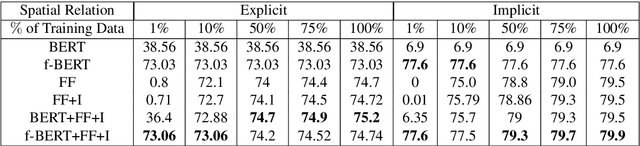


Recognizing spatial relations and reasoning about them is essential in multiple applications including navigation, direction giving and human-computer interaction in general. Spatial relations between objects can either be explicit -- expressed as spatial prepositions, or implicit -- expressed by spatial verbs such as moving, walking, shifting, etc. Both these, but implicit relations in particular, require significant common sense understanding. In this paper, we introduce the task of inferring implicit and explicit spatial relations between two entities in an image. We design a model that uses both textual and visual information to predict the spatial relations, making use of both positional and size information of objects and image embeddings. We contrast our spatial model with powerful language models and show how our modeling complements the power of these, improving prediction accuracy and coverage and facilitates dealing with unseen subjects, objects and relations.
Simple Copy-Paste is a Strong Data Augmentation Method for Instance Segmentation
Dec 13, 2020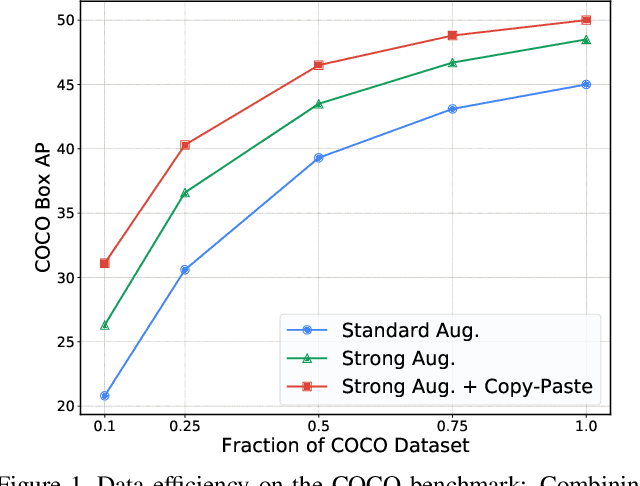
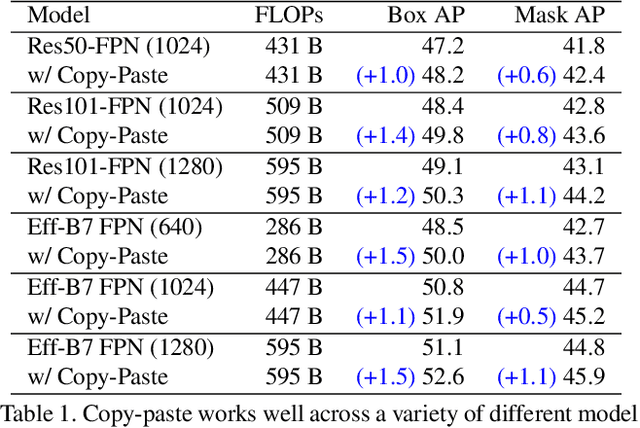

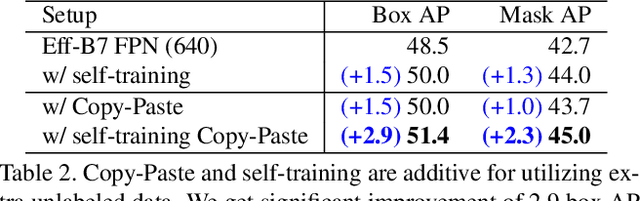
Building instance segmentation models that are data-efficient and can handle rare object categories is an important challenge in computer vision. Leveraging data augmentations is a promising direction towards addressing this challenge. Here, we perform a systematic study of the Copy-Paste augmentation ([13, 12]) for instance segmentation where we randomly paste objects onto an image. Prior studies on Copy-Paste relied on modeling the surrounding visual context for pasting the objects. However, we find that the simple mechanism of pasting objects randomly is good enough and can provide solid gains on top of strong baselines. Furthermore, we show Copy-Paste is additive with semi-supervised methods that leverage extra data through pseudo labeling (e.g. self-training). On COCO instance segmentation, we achieve 49.1 mask AP and 57.3 box AP, an improvement of +0.6 mask AP and +1.5 box AP over the previous state-of-the-art. We further demonstrate that Copy-Paste can lead to significant improvements on the LVIS benchmark. Our baseline model outperforms the LVIS 2020 Challenge winning entry by +3.6 mask AP on rare categories.