 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Background Splitting: Finding Rare Classes in a Sea of Background
Aug 28, 2020
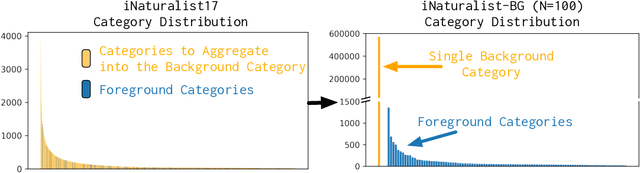
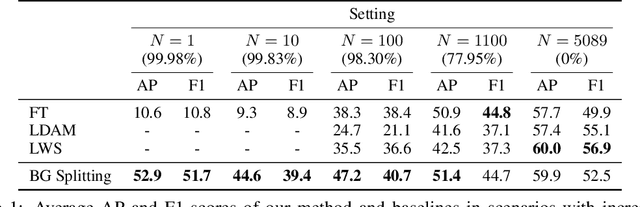
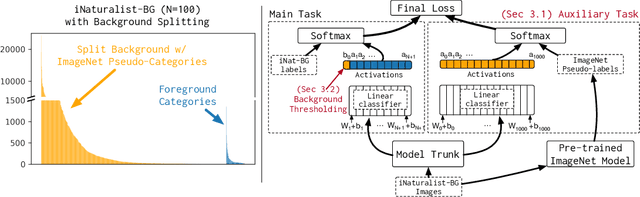

We focus on the real-world problem of training accurate deep models for image classification of a small number of rare categories. In these scenarios, almost all images belong to the background category in the dataset (>95% of the dataset is background). We demonstrate that both standard fine-tuning approaches and state-of-the-art approaches for training on imbalanced datasets do not produce accurate deep models in the presence of this extreme imbalance. Our key observation is that the extreme imbalance due to the background category can be drastically reduced by leveraging visual knowledge from an existing pre-trained model. Specifically, the background category is "split" into smaller and more coherent pseudo-categories during training using a pre-trained model. We incorporate background splitting into an image classification model by adding an auxiliary loss that learns to mimic the predictions of the existing, pre-trained image classification model. Note that this process is automatic and requires no additional manual labels. The auxiliary loss regularizes the feature representation of the shared network trunk by requiring it to discriminate between previously homogeneous background instances and reduces overfitting to the small number of rare category positives. We also show that BG splitting can be combined with other background imbalance methods to further improve performance. We evaluate our method on a modified version of the iNaturalist dataset where only a small subset of rare category labels are available during training (all other images are labeled as background). By jointly learning to recognize ImageNet categories and selected iNaturalist categories, our approach yields performance that is 42.3 mAP points higher than a fine-tuning baseline when 99.98% of the data is background, and 8.3 mAP points higher than SotA baselines when 98.30% of the data is background.
Temporal Dynamic Model for Resting State fMRI Data: A Neural Ordinary Differential Equation approach
Nov 16, 2020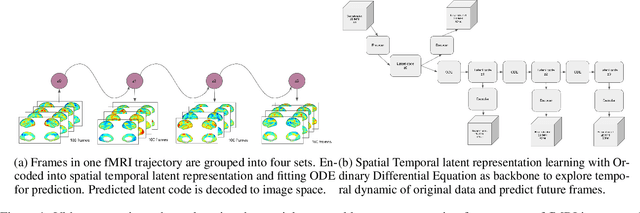


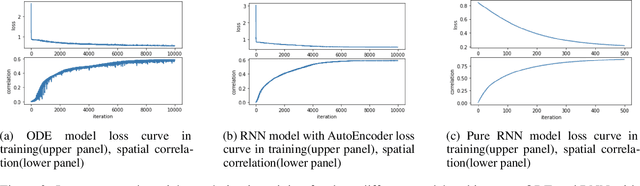
The objective of this paper is to provide a temporal dynamic model for resting state functional Magnetic Resonance Imaging (fMRI) trajectory to predict future brain images based on the given sequence. To this end, we came up with the model that takes advantage of representation learning and Neural Ordinary Differential Equation (Neural ODE) to compress the fMRI image data into latent representation and learn to predict the trajectory following differential equation. Latent space was analyzed by Gaussian Mixture Model. The learned fMRI trajectory embedding can be used to explain the variance of the trajectory and predict human traits for each subject. This method achieves average 0.5 spatial correlation for the whole predicted trajectory, and provide trained ODE parameter for further analysis.
Morphology on categorical distributions
Dec 14, 2020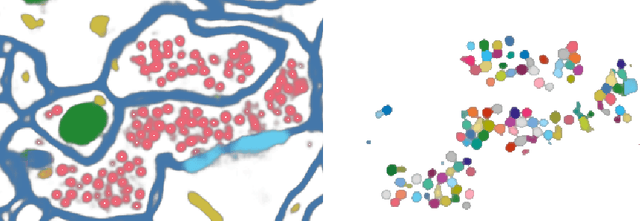
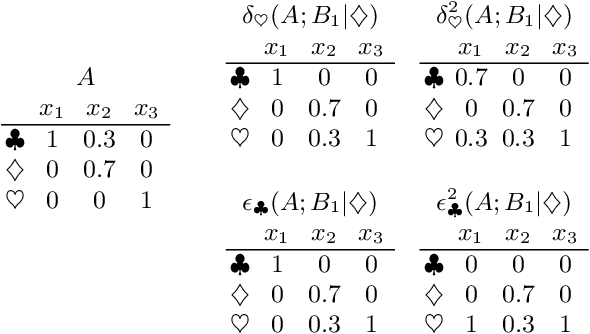
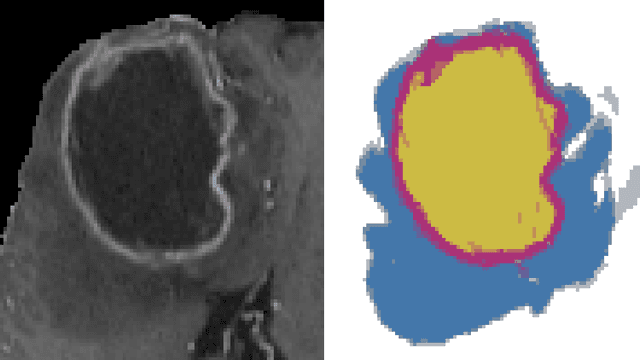
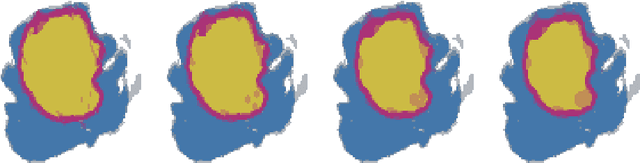
The categorical distribution is a natural representation of uncertainty in multi-class segmentations. In the two-class case the categorical distribution reduces to the Bernoulli distribution, for which grayscale morphology provides a range of useful operations. In the general case, applying morphological operations on uncertain multi-class segmentations is not straightforward as an image of categorical distributions is not a complete lattice. Although morphology on color images has received wide attention, this is not so for color-coded or categorical images and even less so for images of categorical distributions. In this work, we establish a set of requirements for morphology on categorical distributions by combining classic morphology with a probabilistic view. We then define operators respecting these requirements, introduce protected operations on categorical distributions and illustrate the utility of these operators on two example tasks: modeling annotator bias in brain tumor segmentations and segmenting vesicle instances from the predictions of a multi-class U-Net.
One Sparse Perturbation to Fool them All, almost Always!
Apr 30, 2020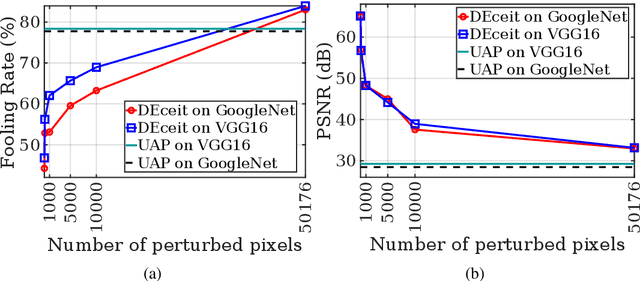
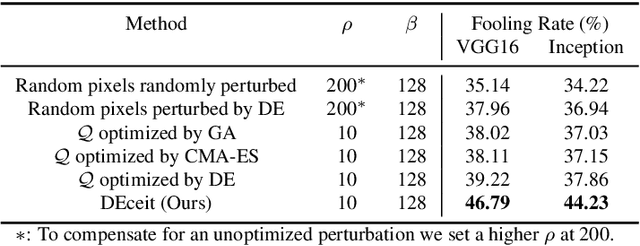
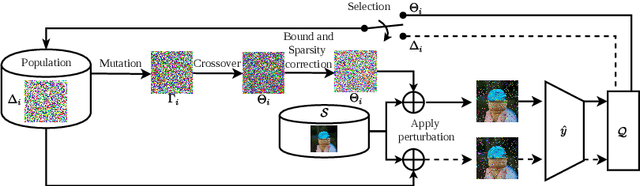
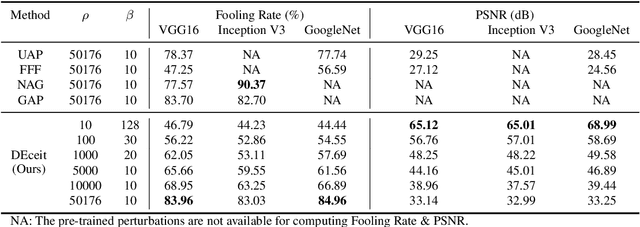
Constructing adversarial perturbations for deep neural networks is an important direction of research. Crafting image-dependent adversarial perturbations using white-box feedback has hitherto been the norm for such adversarial attacks. However, black-box attacks are much more practical for real-world applications. Universal perturbations applicable across multiple images are gaining popularity due to their innate generalizability. There have also been efforts to restrict the perturbations to a few pixels in the image. This helps to retain visual similarity with the original images making such attacks hard to detect. This paper marks an important step which combines all these directions of research. We propose the DEceit algorithm for constructing effective universal pixel-restricted perturbations using only black-box feedback from the target network. We conduct empirical investigations using the ImageNet validation set on the state-of-the-art deep neural classifiers by varying the number of pixels to be perturbed from a meagre 10 pixels to as high as all pixels in the image. We find that perturbing only about 10% of the pixels in an image using DEceit achieves a commendable and highly transferable Fooling Rate while retaining the visual quality. We further demonstrate that DEceit can be successfully applied to image dependent attacks as well. In both sets of experiments, we outperformed several state-of-the-art methods.
Deep Joint Source Channel Coding for WirelessImage Transmission with OFDM
Jan 05, 2021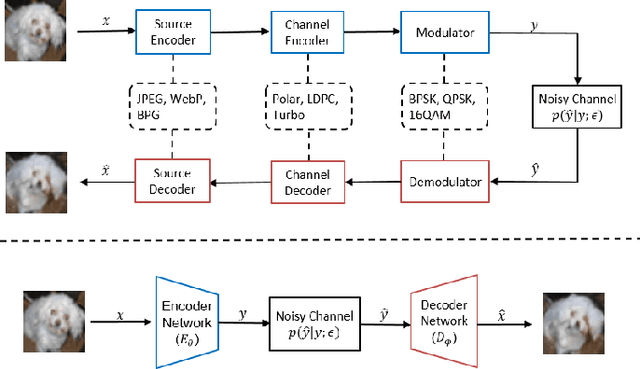
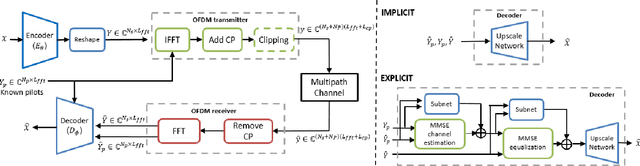
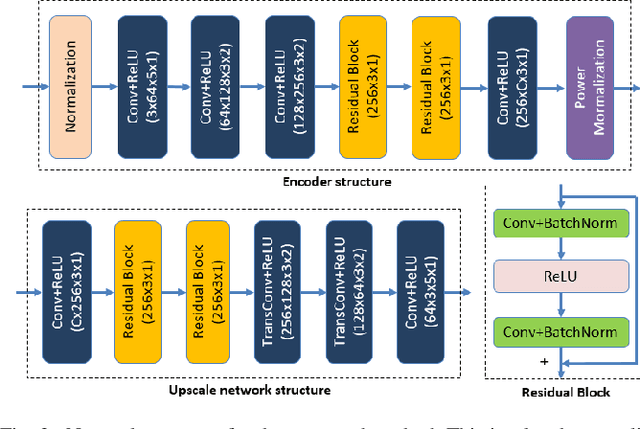
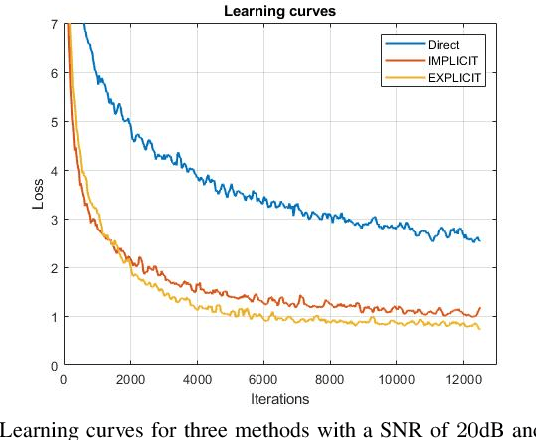
We present a deep learning based joint source channel coding (JSCC) scheme for wireless image transmission over multipath fading channels with non-linear signal clipping. The proposed encoder and decoder use convolutional neural networks (CNN) and directly map the source images to complex-valued baseband samples for orthogonal frequency division multiplexing (OFDM) transmission. The proposed model-driven machine learning approach eliminates the need for separate source and channel coding while integrating an OFDM datapath to cope with multipath fading channels. The end-to-end JSCC communication system combines trainable CNN layers with non-trainable but differentiable layers representing the multipath channel model and OFDM signal processing blocks. Our results show that injecting domain expert knowledge by incorporating OFDM baseband processing blocks into the machine learning framework significantly enhances the overall performance compared to an unstructured CNN. Our method outperforms conventional schemes that employ state-of-the-art but separate source and channel coding such as BPG and LDPC with OFDM. Moreover, our method is shown to be robust against non-linear signal clipping in OFDM for various channel conditions that do not match the model parameter used during the training.
Line Flow based SLAM
Sep 21, 2020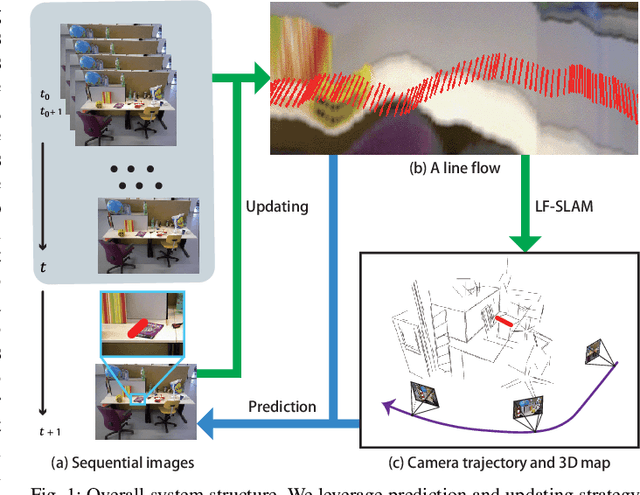
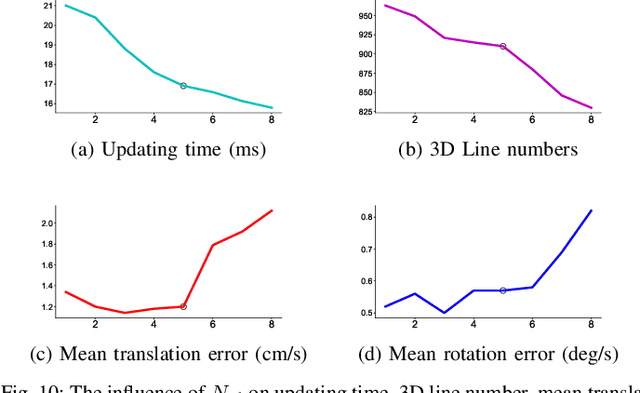

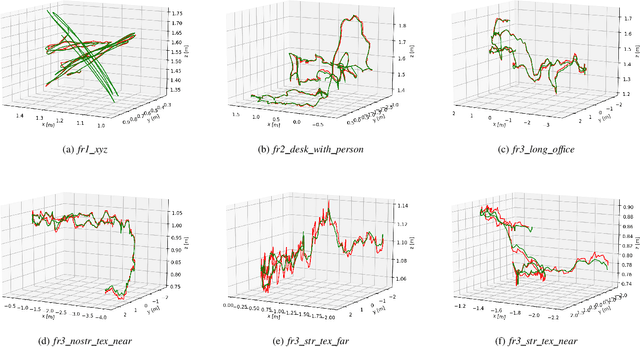
We propose a method of visual SLAM by predicting and updating line flows that represent sequential 2D projections of 3D line segments. While indirect SLAM methods using points and line segments have achieved excellent results, they still face problems in challenging scenarios such as occlusions, image blur, and repetitive textures. To deal with these problems, we leverage line flows which encode the coherence of 2D and 3D line segments in spatial and temporal domains as the sequence of all the 2D line segments corresponding to a specific 3D line segment. Thanks to the line flow representation, the corresponding 2D line segment in a new frame can be predicted based on 2D and 3D line segment motions. We create, update, merge, and discard line flows on-the-fly. We model our Line Flow-based SLAM (LF-SLAM) using a Bayesian network. We perform short-term optimization in front-end, and long-term optimization in back-end. The constraints introduced in line flows improve the performance of our LF-SLAM. Extensive experimental results demonstrate that our method achieves better performance than state-of-the-art direct and indirect SLAM approaches. Specifically, it obtains good localization and mapping results in challenging scenes with occlusions, image blur, and repetitive textures.
Multi-level Feature Learning on Embedding Layer of Convolutional Autoencoders and Deep Inverse Feature Learning for Image Clustering
Oct 05, 2020

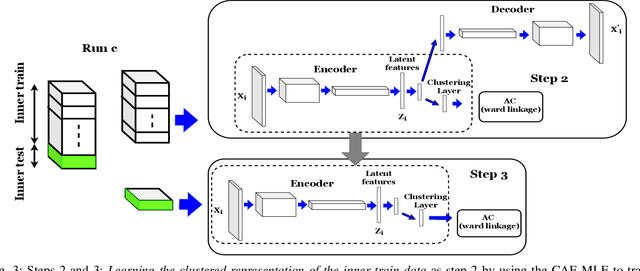
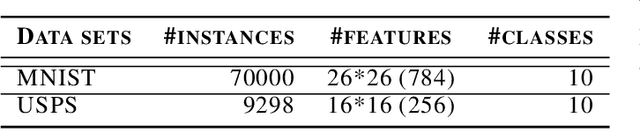
This paper introduces Multi-Level feature learning alongside the Embedding layer of Convolutional Autoencoder (CAE-MLE) as a novel approach in deep clustering. We use agglomerative clustering as the multi-level feature learning that provides a hierarchical structure on the latent feature space. It is shown that applying multi-level feature learning considerably improves the basic deep convolutional embedding clustering (DCEC). CAE-MLE considers the clustering loss of agglomerative clustering simultaneously alongside the learning latent feature of CAE. In the following of the previous works in inverse feature learning, we show that the representation of learning of error as a general strategy can be applied on different deep clustering approaches and it leads to promising results. We develop deep inverse feature learning (deep IFL) on CAE-MLE as a novel approach that leads to the state-of-the-art results among the same category methods. The experimental results show that the CAE-MLE improves the results of the basic method, DCEC, around 7% -14% on two well-known datasets of MNIST and USPS. Also, it is shown that the proposed deep IFL improves the primary results about 9%-17%. Therefore, both proposed approaches of CAE-MLE and deep IFL based on CAE-MLE can lead to notable performance improvement in comparison to the majority of existing techniques. The proposed approaches while are based on a basic convolutional autoencoder lead to outstanding results even in comparison to variational autoencoders or generative adversarial networks.
On Focal Loss for Class-Posterior Probability Estimation: A Theoretical Perspective
Dec 14, 2020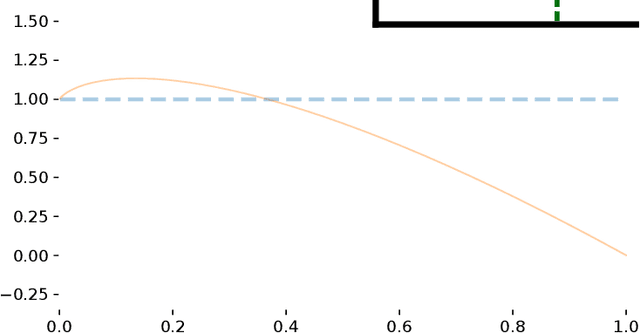
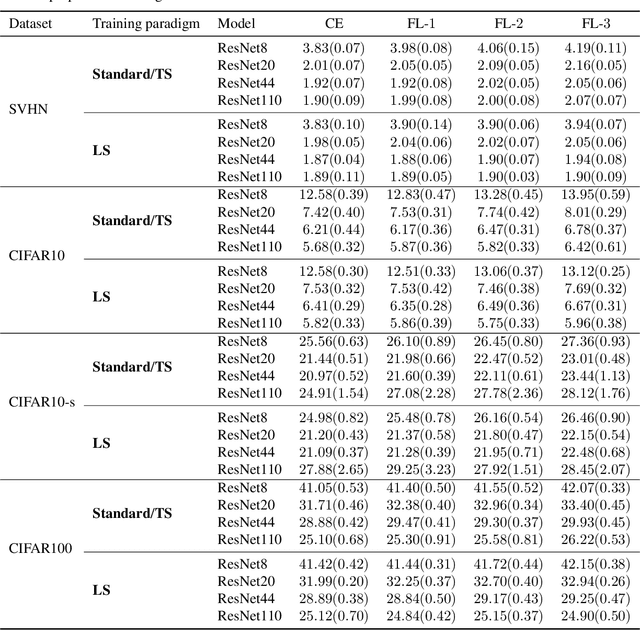
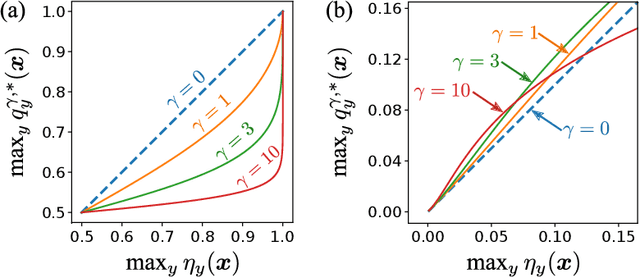
The focal loss has demonstrated its effectiveness in many real-world applications such as object detection and image classification, but its theoretical understanding has been limited so far. In this paper, we first prove that the focal loss is classification-calibrated, i.e., its minimizer surely yields the Bayes-optimal classifier and thus the use of the focal loss in classification can be theoretically justified. However, we also prove a negative fact that the focal loss is not strictly proper, i.e., the confidence score of the classifier obtained by focal loss minimization does not match the true class-posterior probability and thus it is not reliable as a class-posterior probability estimator. To mitigate this problem, we next prove that a particular closed-form transformation of the confidence score allows us to recover the true class-posterior probability. Through experiments on benchmark datasets, we demonstrate that our proposed transformation significantly improves the accuracy of class-posterior probability estimation.
Effective Computer Model For Recognizing Nationality From Frontal Image
Mar 15, 2016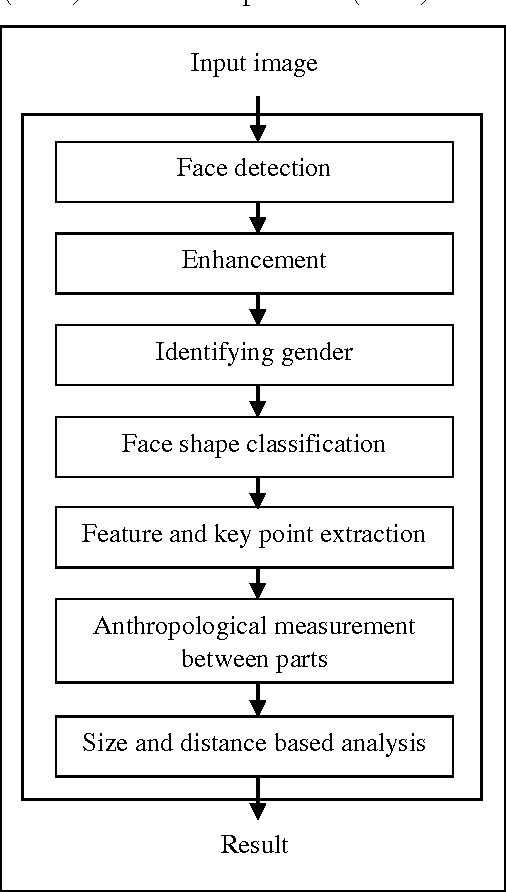



We are introducing new effective computer model for extracting nationality from frontal image candidate using face part color, size and distances based on deep research. Determining face part size, color, and distances is depending on a variety of factors including image quality, lighting condition, rotation angle, occlusion and facial emotion. Therefore, first we need to detect a face on the image then convert an image into the real input. After that, we can determine image candidate gender, face shape, key points and face parts. Finally, we will return the result, based on the comparison of sizes and distances with the sample measurement table database. While we were measuring samples, there were big differences between images by their gender and face shapes. Input images must be the frontal face image that has smooth lighting and does not have any rotation angle. The model can be used in military, police, defense, healthcare, and technology sectors. Finally, Computer can distinguish nationality from the face image.
Nonnegative Matrix Factorization with Zellner Penalty
Dec 07, 2020
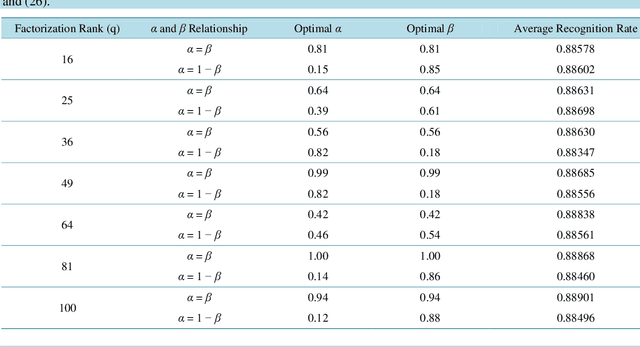
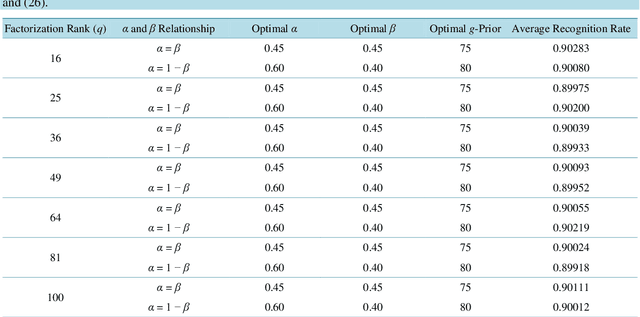
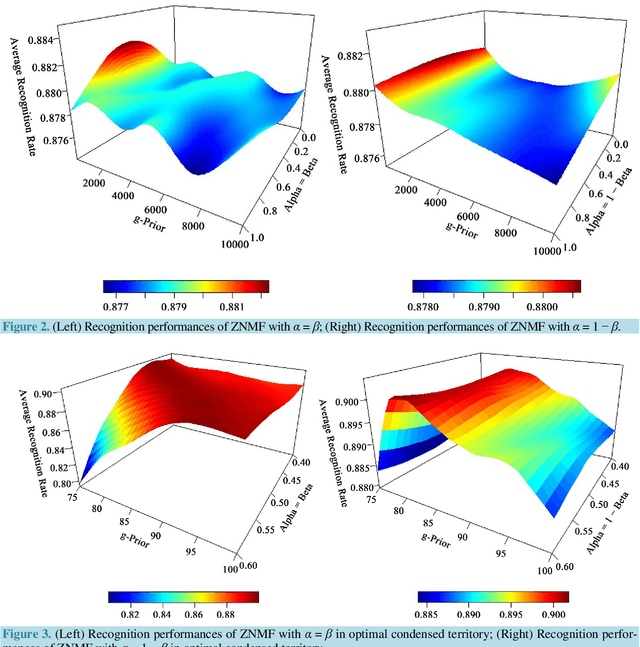
Nonnegative matrix factorization (NMF) is a relatively new unsupervised learning algorithm that decomposes a nonnegative data matrix into a parts-based, lower dimensional, linear representation of the data. NMF has applications in image processing, text mining, recommendation systems and a variety of other fields. Since its inception, the NMF algorithm has been modified and explored by numerous authors. One such modification involves the addition of auxiliary constraints to the objective function of the factorization. The purpose of these auxiliary constraints is to impose task-specific penalties or restrictions on the objective function. Though many auxiliary constraints have been studied, none have made use of data-dependent penalties. In this paper, we propose Zellner nonnegative matrix factorization (ZNMF), which uses data-dependent auxiliary constraints. We assess the facial recognition performance of the ZNMF algorithm and several other well-known constrained NMF algorithms using the Cambridge ORL database.
* 10 pages, 4 figures, 2 tables