 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Retinal Image Enhancement Technique for Blood Vessel Segmentation Algorithm
Feb 28, 2018
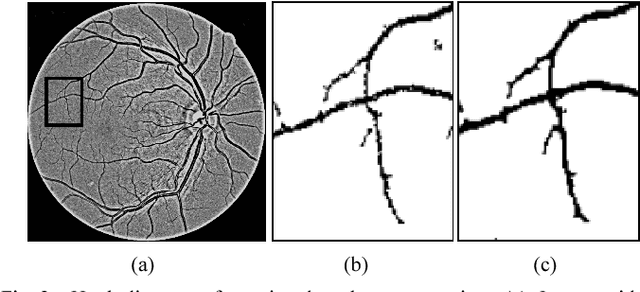
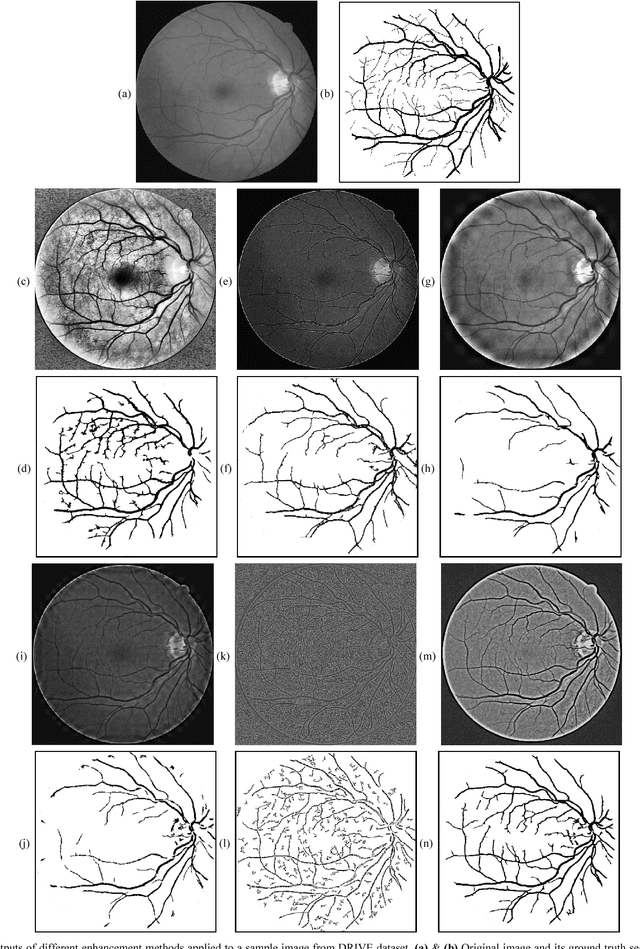
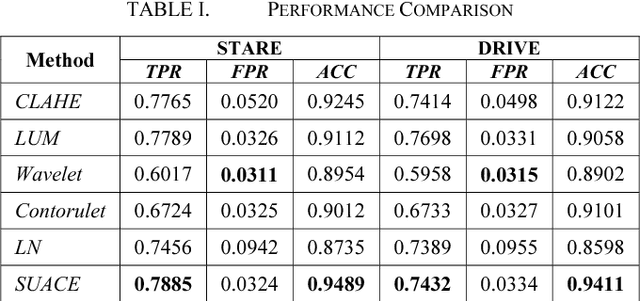
The morphology of blood vessels in retinal fundus images is an important indicator of diseases like glaucoma, hypertension and diabetic retinopathy. The accuracy of retinal blood vessels segmentation affects the quality of retinal image analysis which is used in diagnosis methods in modern ophthalmology. Contrast enhancement is one of the crucial steps in any of retinal blood vessel segmentation approaches. The reliability of the segmentation depends on the consistency of the contrast over the image. This paper presents an assessment of the suitability of a recently invented spatially adaptive contrast enhancement technique for enhancing retinal fundus images for blood vessel segmentation. The enhancement technique was integrated with a variant of Tyler Coye algorithm, which has been improved with Hough line transformation based vessel reconstruction method. The proposed approach was evaluated on two public datasets STARE and DRIVE. The assessment was done by comparing the segmentation performance with five widely used contrast enhancement techniques based on wavelet transform, contrast limited histogram equalization, local normalization, linear un-sharp masking and contourlet transform. The results revealed that the assessed enhancement technique is well suited for the application and also outperforms all compared techniques.
Medical Image Synthesis with Context-Aware Generative Adversarial Networks
Dec 16, 2016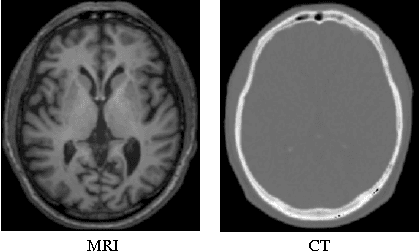
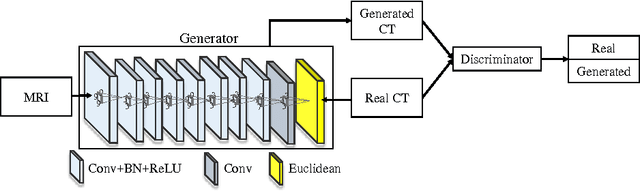
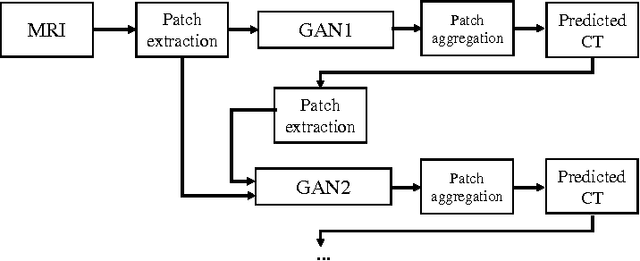
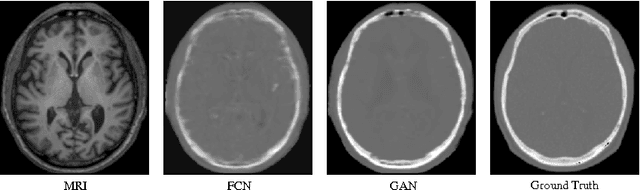
Computed tomography (CT) is critical for various clinical applications, e.g., radiotherapy treatment planning and also PET attenuation correction. However, CT exposes radiation during acquisition, which may cause side effects to patients. Compared to CT, magnetic resonance imaging (MRI) is much safer and does not involve any radiations. Therefore, recently, researchers are greatly motivated to estimate CT image from its corresponding MR image of the same subject for the case of radiotherapy planning. In this paper, we propose a data-driven approach to address this challenging problem. Specifically, we train a fully convolutional network to generate CT given an MR image. To better model the nonlinear relationship from MRI to CT and to produce more realistic images, we propose to use the adversarial training strategy and an image gradient difference loss function. We further apply AutoContext Model to implement a context-aware generative adversarial network. Experimental results show that our method is accurate and robust for predicting CT images from MRI images, and also outperforms three state-of-the-art methods under comparison.
Improving model calibration with accuracy versus uncertainty optimization
Dec 14, 2020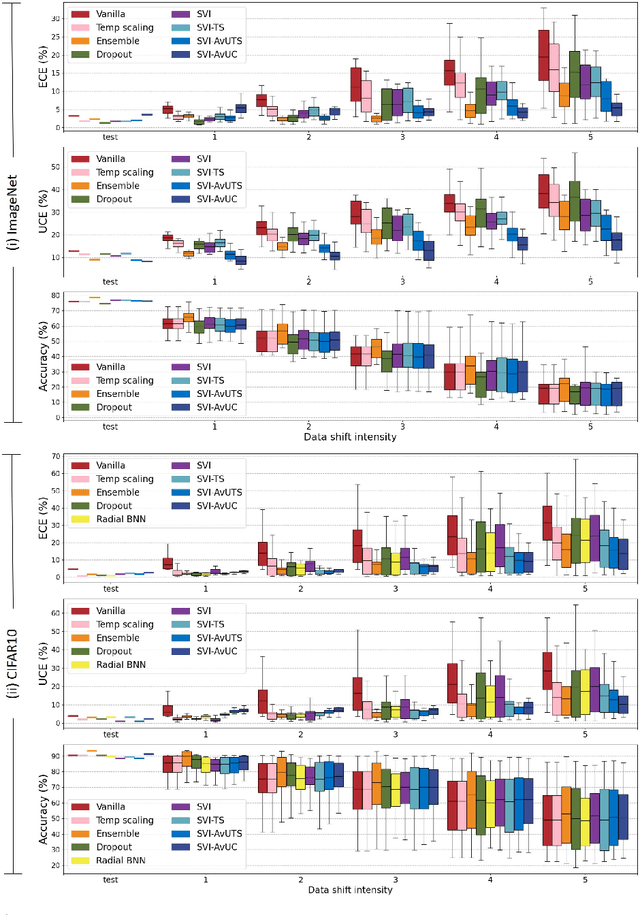

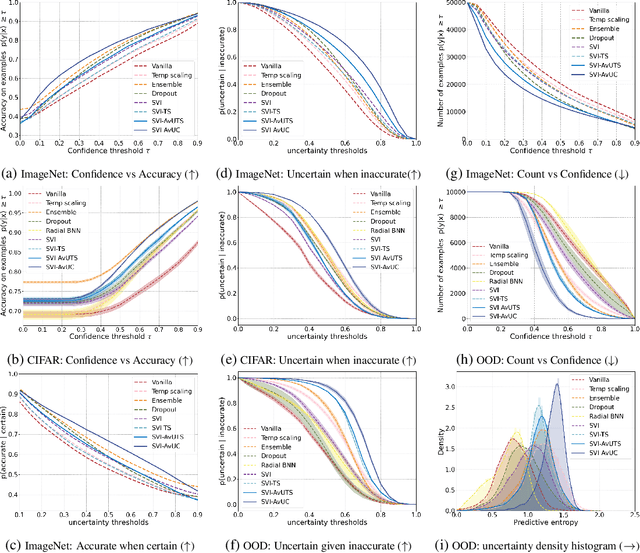

Obtaining reliable and accurate quantification of uncertainty estimates from deep neural networks is important in safety-critical applications. A well-calibrated model should be accurate when it is certain about its prediction and indicate high uncertainty when it is likely to be inaccurate. Uncertainty calibration is a challenging problem as there is no ground truth available for uncertainty estimates. We propose an optimization method that leverages the relationship between accuracy and uncertainty as an anchor for uncertainty calibration. We introduce a differentiable accuracy versus uncertainty calibration (AvUC) loss function that allows a model to learn to provide well-calibrated uncertainties, in addition to improved accuracy. We also demonstrate the same methodology can be extended to post-hoc uncertainty calibration on pretrained models. We illustrate our approach with mean-field stochastic variational inference and compare with state-of-the-art methods. Extensive experiments demonstrate our approach yields better model calibration than existing methods on large-scale image classification tasks under distributional shift.
Real Time Incremental Foveal Texture Mapping for Autonomous Vehicles
Jan 16, 2021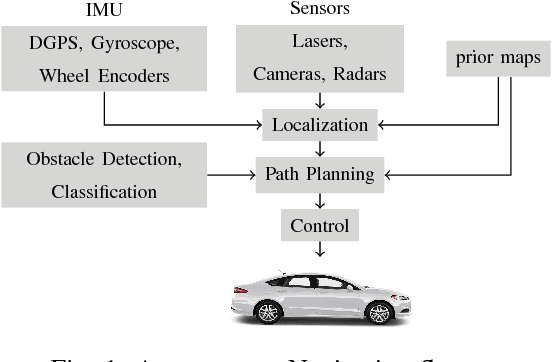
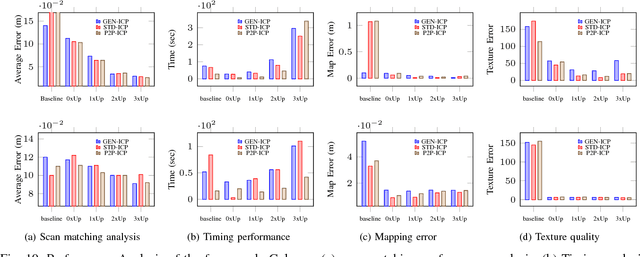
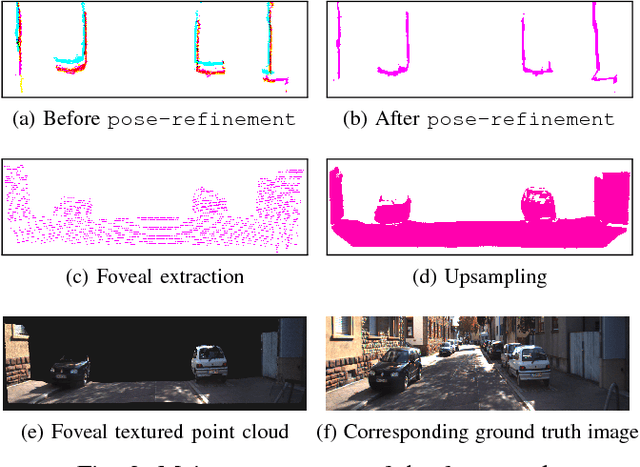
We propose an end-to-end real time framework to generate high resolution graphics grade textured 3D map of urban environment. The generated detailed map finds its application in the precise localization and navigation of autonomous vehicles. It can also serve as a virtual test bed for various vision and planning algorithms as well as a background map in the computer games. In this paper, we focus on two important issues: (i) incrementally generating a map with coherent 3D surface, in real time and (ii) preserving the quality of color texture. To handle the above issues, firstly, we perform a pose-refinement procedure which leverages camera image information, Delaunay triangulation and existing scan matching techniques to produce high resolution 3D map from the sparse input LIDAR scan. This 3D map is then texturized and accumulated by using a novel technique of ray-filtering which handles occlusion and inconsistencies in pose-refinement. Further, inspired by human fovea, we introduce foveal-processing which significantly reduces the computation time and also assists ray-filtering to maintain consistency in color texture and coherency in 3D surface of the output map. Moreover, we also introduce texture error (TE) and mean texture mapping error (MTME), which provides quantitative measure of texturing and overall quality of the textured maps.
Time-Supervised Primary Object Segmentation
Aug 16, 2020



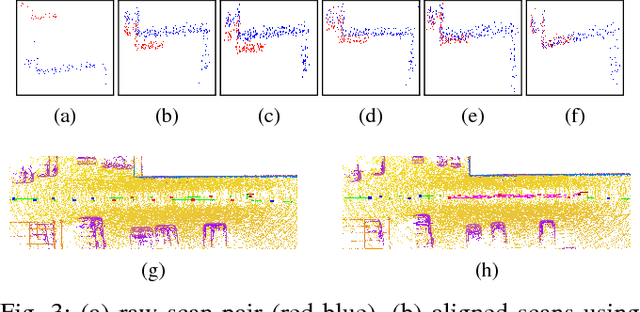
We describe an unsupervised method to detect and segment portions of live scenes that, at some point in time, are seen moving as a coherent whole, which we refer to as primary objects. Our method first segments motions by minimizing the mutual information between partitions of the image domain, which bootstraps a static object detection model that takes a single image as input. The two models are mutually reinforced within a feedback loop, enabling extrapolation to previously unseen classes of objects. Our method requires video for training, but can be used on either static images or videos at inference time. As the volume of our training sets grows, more and more objects are seen moving, thus turning our method into unsupervised (or time-supervised) training to segment primary objects. The resulting system outperforms the state-of-the-art in both video object segmentation and salient object detection benchmarks, even when compared to methods that use explicit manual annotation.
Deep Learning Hyperspectral Image Classification Using Multiple Class-based Denoising Autoencoders, Mixed Pixel Training Augmentation, and Morphological Operations
Jul 11, 2018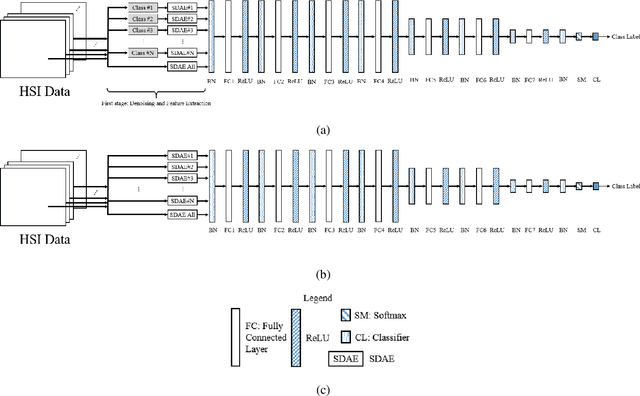

Herein, we present a system for hyperspectral image segmentation that utilizes multiple class--based denoising autoencoders which are efficiently trained. Moreover, we present a novel hyperspectral data augmentation method for labelled HSI data using linear mixtures of pixels from each class, which helps the system with edge pixels which are almost always mixed pixels. Finally, we utilize a deep neural network and morphological hole-filling to provide robust image classification. Results run on the Salinas dataset verify the high performance of the proposed algorithm.
Taking Modality-free Human Identification as Zero-shot Learning
Oct 02, 2020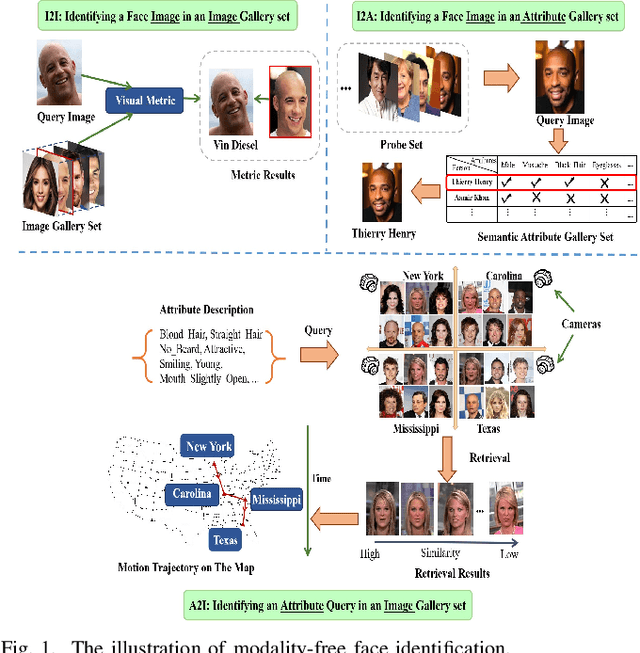
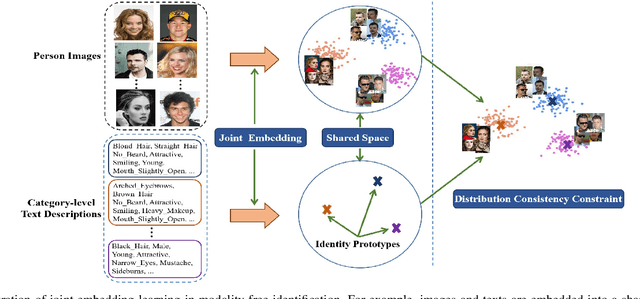
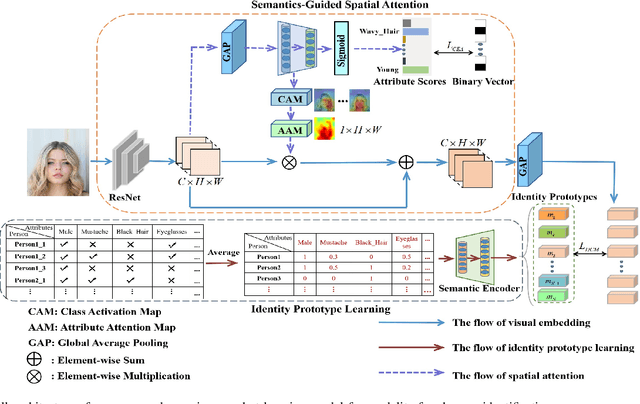

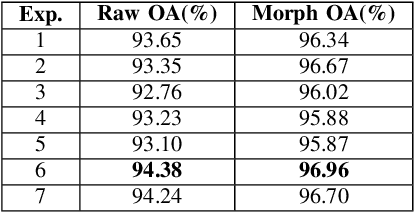
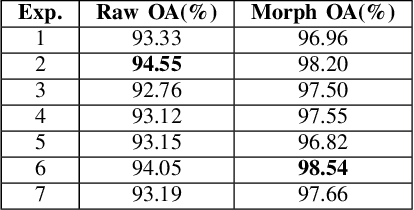
Human identification is an important topic in event detection, person tracking, and public security. There have been numerous methods proposed for human identification, such as face identification, person re-identification, and gait identification. Typically, existing methods predominantly classify a queried image to a specific identity in an image gallery set (I2I). This is seriously limited for the scenario where only a textual description of the query or an attribute gallery set is available in a wide range of video surveillance applications (A2I or I2A). However, very few efforts have been devoted towards modality-free identification, i.e., identifying a query in a gallery set in a scalable way. In this work, we take an initial attempt, and formulate such a novel Modality-Free Human Identification (named MFHI) task as a generic zero-shot learning model in a scalable way. Meanwhile, it is capable of bridging the visual and semantic modalities by learning a discriminative prototype of each identity. In addition, the semantics-guided spatial attention is enforced on visual modality to obtain representations with both high global category-level and local attribute-level discrimination. Finally, we design and conduct an extensive group of experiments on two common challenging identification tasks, including face identification and person re-identification, demonstrating that our method outperforms a wide variety of state-of-the-art methods on modality-free human identification.
Learning Portrait Style Representations
Dec 08, 2020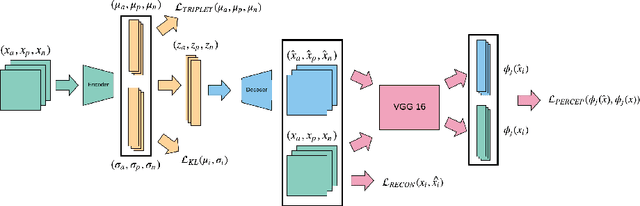

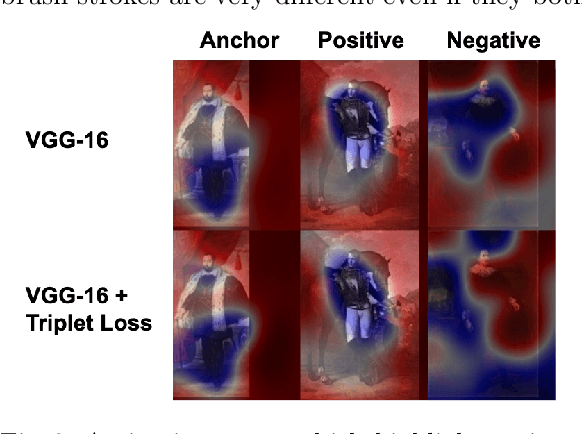

Style analysis of artwork in computer vision predominantly focuses on achieving results in target image generation through optimizing understanding of low level style characteristics such as brush strokes. However, fundamentally different techniques are required to computationally understand and control qualities of art which incorporate higher level style characteristics. We study style representations learned by neural network architectures incorporating these higher level characteristics. We find variation in learned style features from incorporating triplets annotated by art historians as supervision for style similarity. Networks leveraging statistical priors or pretrained on photo collections such as ImageNet can also derive useful visual representations of artwork. We align the impact of these expert human knowledge, statistical, and photo realism priors on style representations with art historical research and use these representations to perform zero-shot classification of artists. To facilitate this work, we also present the first large-scale dataset of portraits prepared for computational analysis.
A Dataset and Benchmark for Malaria Life-Cycle Classification in Thin Blood Smear Images
Feb 17, 2021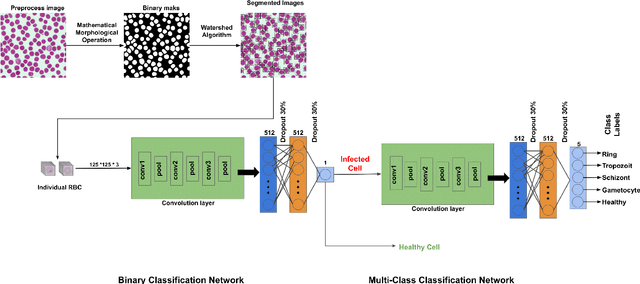
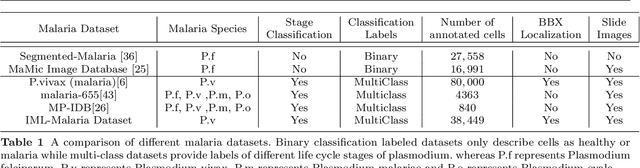
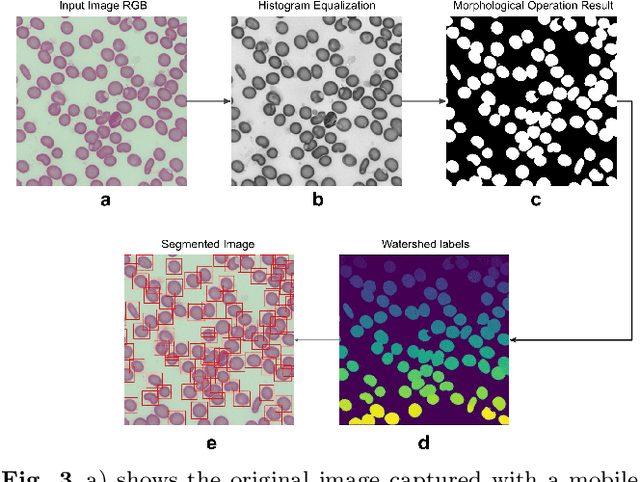
Malaria microscopy, microscopic examination of stained blood slides to detect parasite Plasmodium, is considered to be a gold-standard for detecting life-threatening disease malaria. Detecting the plasmodium parasite requires a skilled examiner and may take up to 10 to 15 minutes to completely go through the whole slide. Due to a lack of skilled medical professionals in the underdeveloped or resource deficient regions, many cases go misdiagnosed; resulting in unavoidable complications and/or undue medication. We propose to complement the medical professionals by creating a deep learning-based method to automatically detect (localize) the plasmodium parasites in the photograph of stained film. To handle the unbalanced nature of the dataset, we adopt a two-stage approach. Where the first stage is trained to detect blood cells and classify them into just healthy or infected. The second stage is trained to classify each detected cell further into the life-cycle stage. To facilitate the research in machine learning-based malaria microscopy, we introduce a new large scale microscopic image malaria dataset. Thirty-eight thousand cells are tagged from the 345 microscopic images of different Giemsa-stained slides of blood samples. Extensive experimentation is performed using different CNN backbones including VGG, DenseNet, and ResNet on this dataset. Our experiments and analysis reveal that the two-stage approach works better than the one-stage approach for malaria detection. To ensure the usability of our approach, we have also developed a mobile app that will be used by local hospitals for investigation and educational purposes. The dataset, its annotations, and implementation codes will be released upon publication of the paper.
Multiple Infrared Small Targets Detection based on Hierarchical Maximal Entropy Random Walk
Oct 02, 2020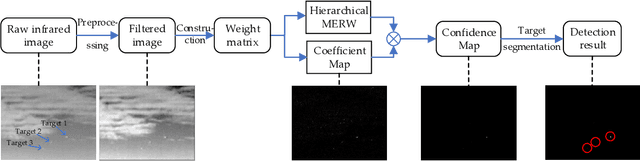

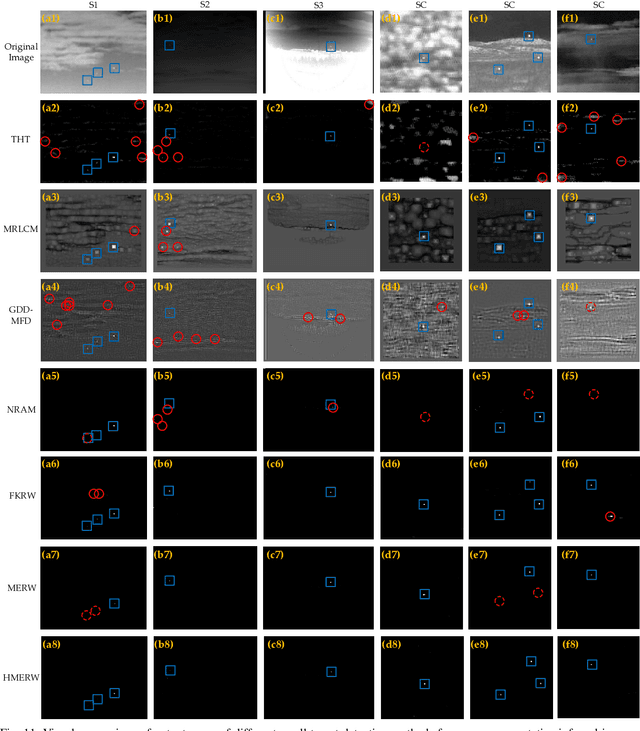
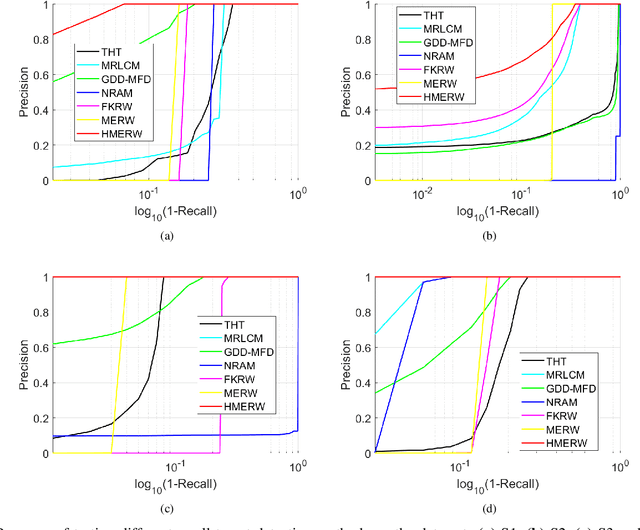
The technique of detecting multiple dim and small targets with low signal-to-clutter ratios (SCR) is very important for infrared search and tracking systems. In this paper, we establish a detection method derived from maximal entropy random walk (MERW) to robustly detect multiple small targets. Initially, we introduce the primal MERW and analyze the feasibility of applying it to small target detection. However, the original weight matrix of the MERW is sensitive to interferences. Therefore, a specific weight matrix is designed for the MERW in principle of enhancing characteristics of small targets and suppressing strong clutters. Moreover, the primal MERW has a critical limitation of strong bias to the most salient small target. To achieve multiple small targets detection, we develop a hierarchical version of the MERW method. Based on the hierarchical MERW (HMERW), we propose a small target detection method as follows. First, filtering technique is used to smooth the infrared image. Second, an output map is obtained by importing the filtered image into the HMERW. Then, a coefficient map is constructed to fuse the stationary dirtribution map of the HMERW. Finally, an adaptive threshold is used to segment multiple small targets from the fusion map. Extensive experiments on practical data sets demonstrate that the proposed method is superior to the state-of-the-art methods in terms of target enhancement, background suppression and multiple small targets detection.