 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Top-1 CORSMAL Challenge 2020 Submission: Filling Mass Estimation Using Multi-modal Observations of Human-robot Handovers
Dec 02, 2020
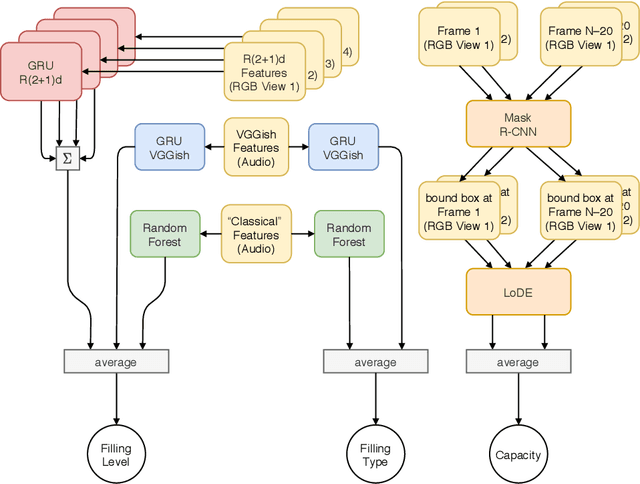
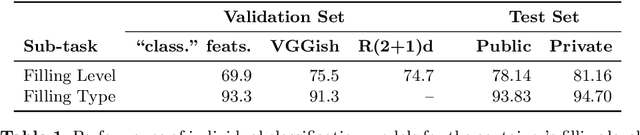
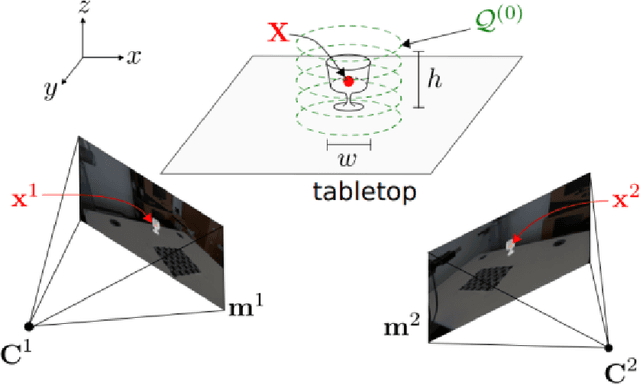
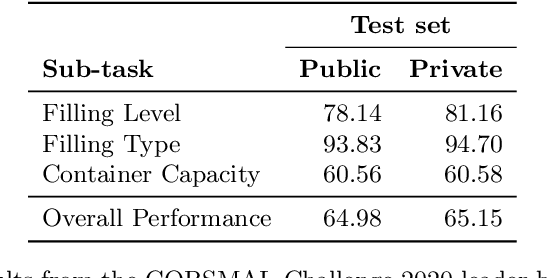
Human-robot object handover is a key skill for the future of human-robot collaboration. CORSMAL 2020 Challenge focuses on the perception part of this problem: the robot needs to estimate the filling mass of a container held by a human. Although there are powerful methods in image processing and audio processing individually, answering such a problem requires processing data from multiple sensors together. The appearance of the container, the sound of the filling, and the depth data provide essential information. We propose a multi-modal method to predict three key indicators of the filling mass: filling type, filling level, and container capacity. These indicators are then combined to estimate the filling mass of a container. Our method obtained Top-1 overall performance among all submissions to CORSMAL 2020 Challenge on both public and private subsets while showing no evidence of overfitting. Our source code is publicly available: https://github.com/v-iashin/CORSMAL
Rethinking CNN-Based Pansharpening: Guided Colorization of Panchromatic Images via GANs
Jun 30, 2020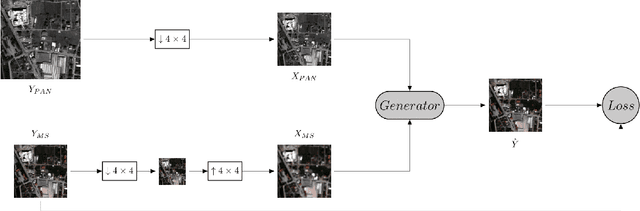


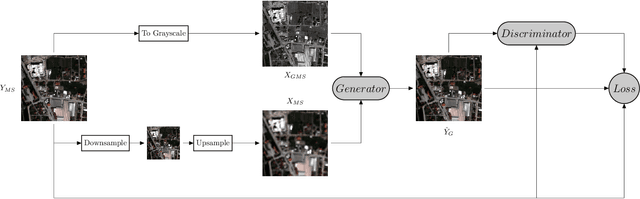
Convolutional Neural Networks (CNN)-based approaches have shown promising results in pansharpening of satellite images in recent years. However, they still exhibit limitations in producing high-quality pansharpening outputs. To that end, we propose a new self-supervised learning framework, where we treat pansharpening as a colorization problem, which brings an entirely novel perspective and solution to the problem compared to existing methods that base their solution solely on producing a super-resolution version of the multispectral image. Whereas CNN-based methods provide a reduced resolution panchromatic image as input to their model along with reduced resolution multispectral images, hence learn to increase their resolution together, we instead provide the grayscale transformed multispectral image as input, and train our model to learn the colorization of the grayscale input. We further address the fixed downscale ratio assumption during training, which does not generalize well to the full-resolution scenario. We introduce a noise injection into the training by randomly varying the downsampling ratios. Those two critical changes, along with the addition of adversarial training in the proposed PanColorization Generative Adversarial Networks (PanColorGAN) framework, help overcome the spatial detail loss and blur problems that are observed in CNN-based pansharpening. The proposed approach outperforms the previous CNN-based and traditional methods as demonstrated in our experiments.
Suppressing Spoof-irrelevant Factors for Domain-agnostic Face Anti-spoofing
Dec 02, 2020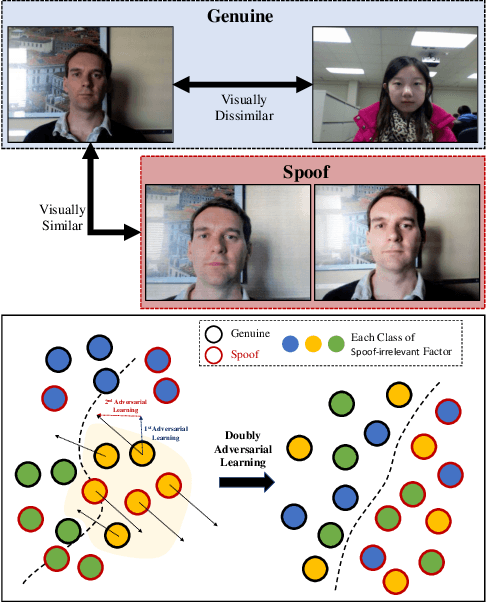
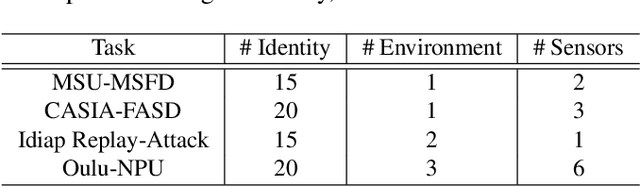
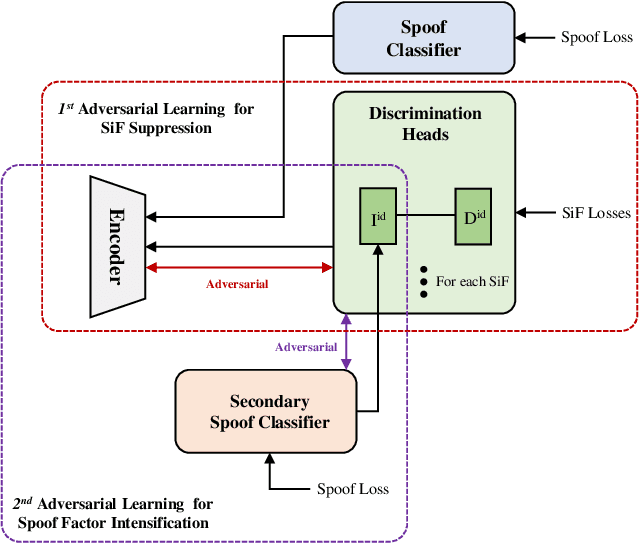
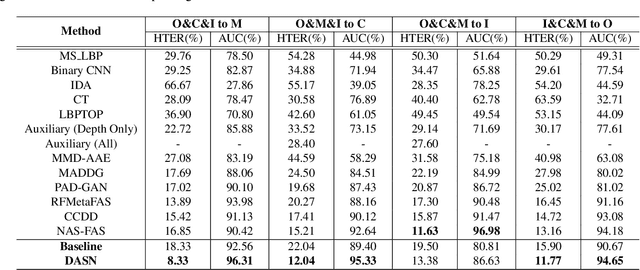
Face anti-spoofing aims to prevent false authentications of face recognition systems by distinguishing whether an image is originated from a human face or a spoof medium. We propose a novel method called Doubly Adversarial Suppression Network (DASN) for domain-agnostic face anti-spoofing; DASN improves the generalization ability to unseen domains by learning to effectively suppress spoof-irrelevant factors (SiFs) (e.g., camera sensors, illuminations). To achieve our goal, we introduce two types of adversarial learning schemes. In the first adversarial learning scheme, multiple SiFs are suppressed by deploying multiple discrimination heads that are trained against an encoder. In the second adversarial learning scheme, each of the discrimination heads is also adversarially trained to suppress a spoof factor, and the group of the secondary spoof classifier and the encoder aims to intensify the spoof factor by overcoming the suppression. We evaluate the proposed method on four public benchmark datasets, and achieve remarkable evaluation results. The results demonstrate the effectiveness of the proposed method.
The Utility of Decorrelating Colour Spaces in Vector Quantised Variational Autoencoders
Sep 30, 2020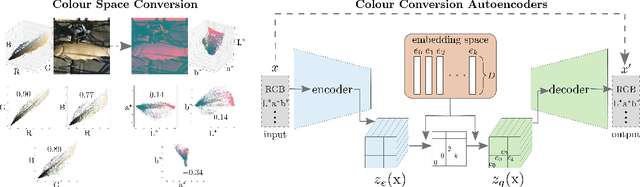
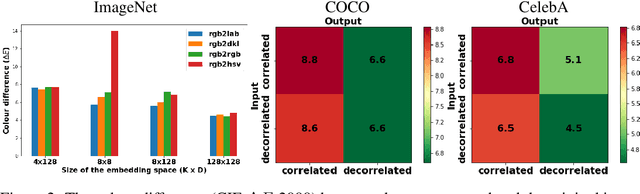
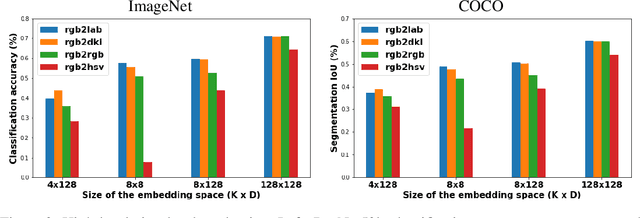
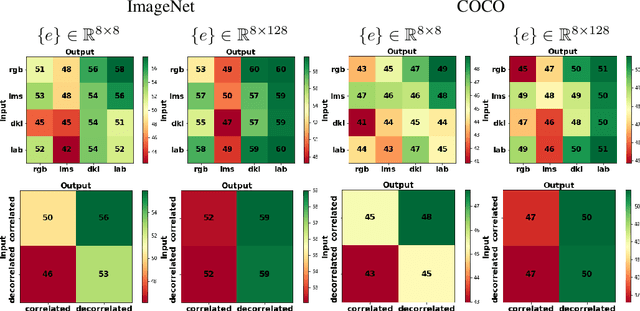
Vector quantised variational autoencoders (VQ-VAE) are characterised by three main components: 1) encoding visual data, 2) assigning $k$ different vectors in the so-called embedding space, and 3) decoding the learnt features. While images are often represented in RGB colour space, the specific organisation of colours in other spaces also offer interesting features, e.g. CIE L*a*b* decorrelates chromaticity into opponent axes. In this article, we propose colour space conversion, a simple quasi-unsupervised task, to enforce a network learning structured representations. To this end, we trained several instances of VQ-VAE whose input is an image in one colour space, and its output in another, e.g. from RGB to CIE L*a*b* (in total five colour spaces were considered). We examined the finite embedding space of trained networks in order to disentangle the colour representation in VQ-VAE models. Our analysis suggests that certain vectors encode hue and others luminance information. We further evaluated the quality of reconstructed images at low-level using pixel-wise colour metrics, and at high-level by inputting them to image classification and scene segmentation networks. We conducted experiments in three benchmark datasets: ImageNet, COCO and CelebA. Our results show, with respect to the baseline network (whose input and output are RGB), colour conversion to decorrelated spaces obtains 1-2 Delta-E lower colour difference and 5-10% higher classification accuracy. We also observed that the learnt embedding space is easier to interpret in colour opponent models.
HDR-GAN: HDR Image Reconstruction from Multi-Exposed LDR Images with Large Motions
Jul 03, 2020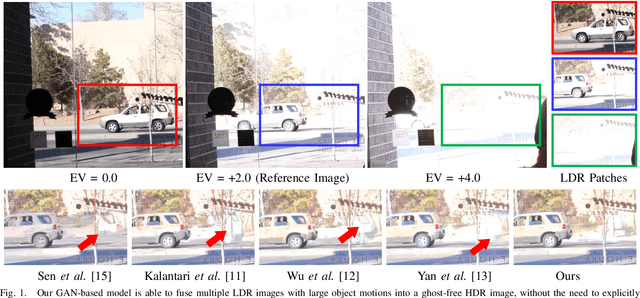
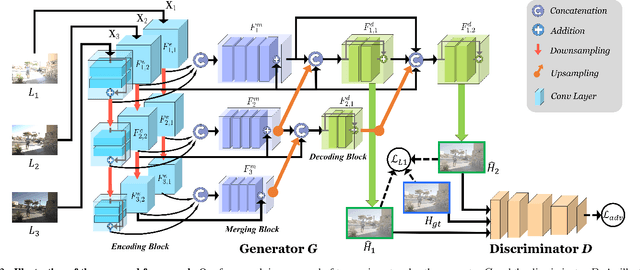

Synthesizing high dynamic range (HDR) images from multiple low-dynamic range (LDR) exposures in dynamic scenes is challenging. There are two major problems caused by the large motions of foreground objects. One is the severe misalignment among the LDR images. The other is the missing content due to the over-/under-saturated regions caused by the moving objects, which may not be easily compensated for by the multiple LDR exposures. Thus, it requires the HDR generation model to be able to properly fuse the LDR images and restore the missing details without introducing artifacts. To address these two problems, we propose in this paper a novel GAN-based model, HDR-GAN, for synthesizing HDR images from multi-exposed LDR images. To our best knowledge, this work is the first GAN-based approach for fusing multi-exposed LDR images for HDR reconstruction. By incorporating adversarial learning, our method is able to produce faithful information in the regions with missing content. In addition, we also propose a novel generator network, with a reference-based residual merging block for aligning large object motions in the feature domain, and a deep HDR supervision scheme for eliminating artifacts of the reconstructed HDR images. Experimental results demonstrate that our model achieves state-of-the-art reconstruction performance over the prior HDR methods on diverse scenes.
Edge Network-Assisted Real-Time Object Detection Framework for Autonomous Driving
Aug 17, 2020
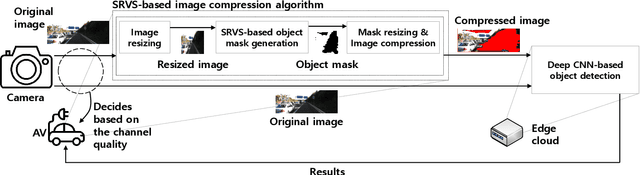
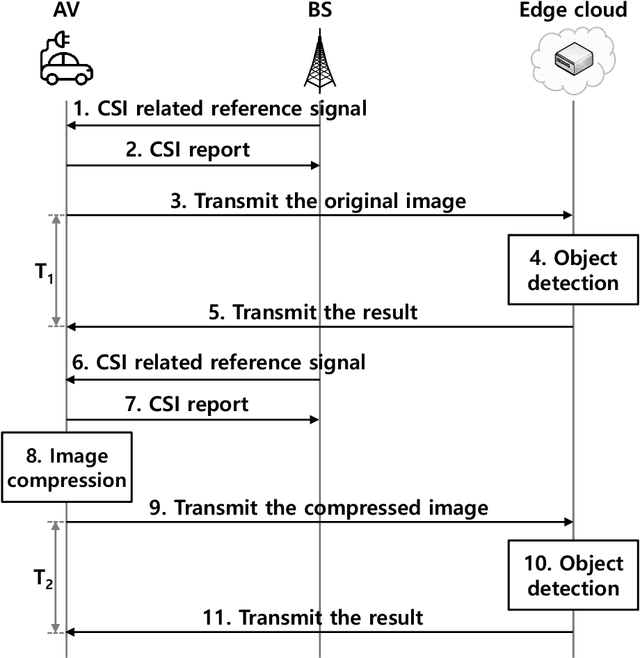
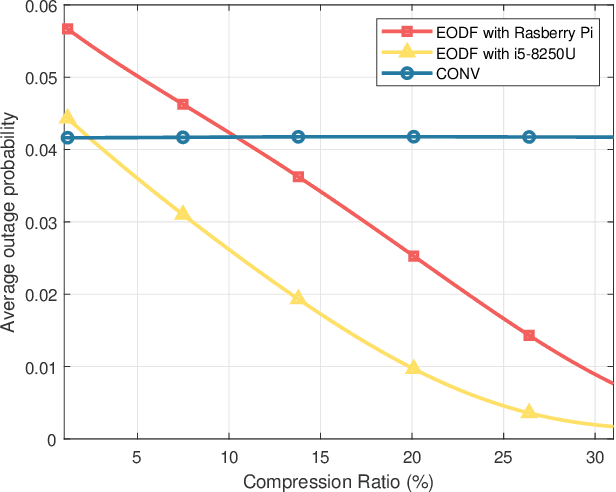
Autonomous vehicles (AVs) can achieve the desired results within a short duration by offloading tasks even requiring high computational power (e.g., object detection (OD)) to edge clouds. However, although edge clouds are exploited, real-time OD cannot always be guaranteed due to dynamic channel quality. To mitigate this problem, we propose an edge network-assisted real-time OD framework~(EODF). In an EODF, AVs extract the region of interests~(RoIs) of the captured image when the channel quality is not sufficiently good for supporting real-time OD. Then, AVs compress the image data on the basis of the RoIs and transmit the compressed one to the edge cloud. In so doing, real-time OD can be achieved owing to the reduced transmission latency. To verify the feasibility of our framework, we evaluate the probability that the results of OD are not received within the inter-frame duration (i.e., outage probability) and their accuracy. From the evaluation, we demonstrate that the proposed EODF provides the results to AVs in real-time and achieves satisfactory accuracy.
New Techniques for Preserving Global Structure and Denoising with Low Information Loss in Single-Image Super-Resolution
Jun 16, 2018
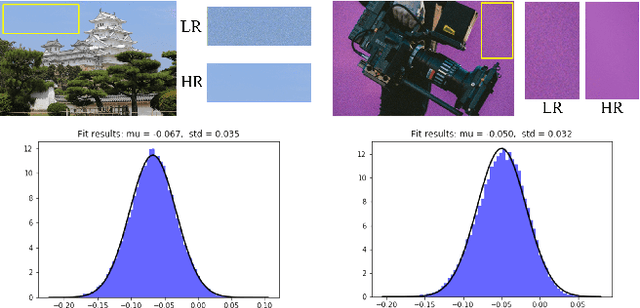
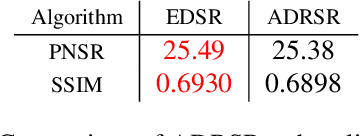
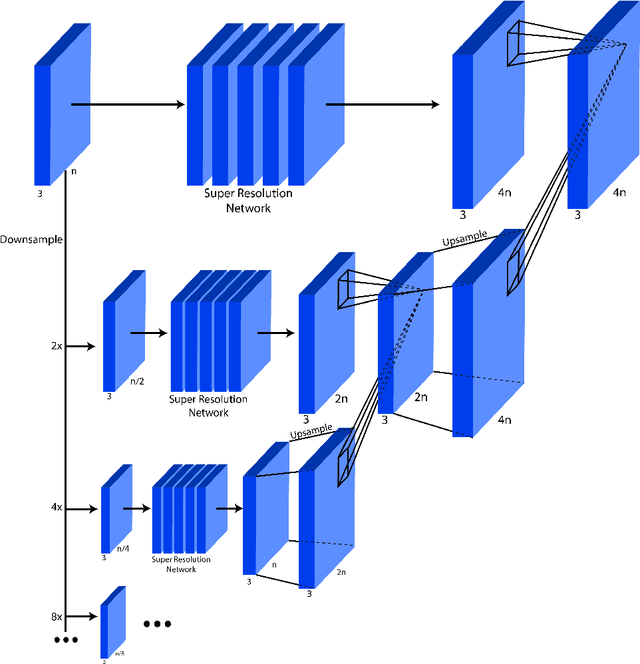
This work identifies and addresses two important technical challenges in single-image super-resolution: (1) how to upsample an image without magnifying noise and (2) how to preserve large scale structure when upsampling. We summarize the techniques we developed for our second place entry in Track 1 (Bicubic Downsampling), seventh place entry in Track 2 (Realistic Adverse Conditions), and seventh place entry in Track 3 (Realistic difficult) in the 2018 NTIRE Super-Resolution Challenge. Furthermore, we present new neural network architectures that specifically address the two challenges listed above: denoising and preservation of large-scale structure.
DAN: A Deformation-Aware Network for Consecutive Biomedical Image Interpolation
Apr 23, 2020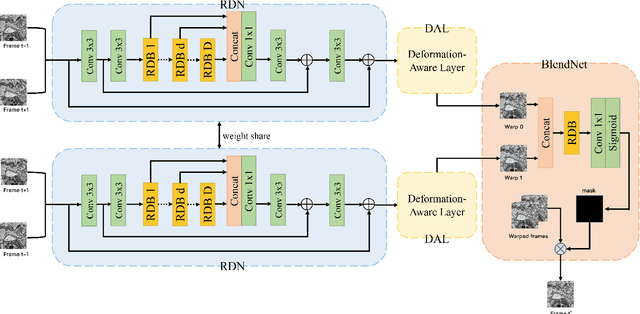
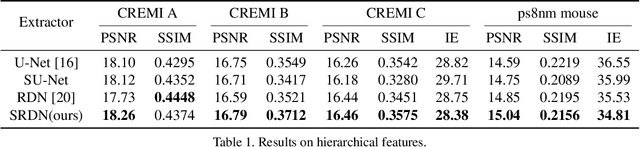
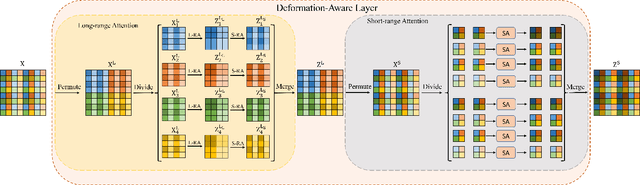
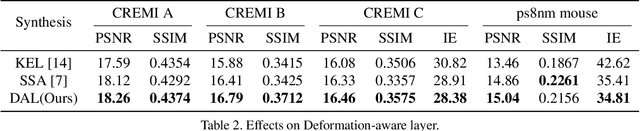
The continuity of biological tissue between consecutive biomedical images makes it possible for the video interpolation algorithm, to recover large area defects and tears that are common in biomedical images. However, noise and blur differences, large deformation, and drift between biomedical images, make the task challenging. To address the problem, this paper introduces a deformation-aware network to synthesize each pixel in accordance with the continuity of biological tissue. First, we develop a deformation-aware layer for consecutive biomedical images interpolation that implicitly adopting global perceptual deformation. Second, we present an adaptive style-balance loss to take the style differences of consecutive biomedical images such as blur and noise into consideration. Guided by the deformation-aware module, we synthesize each pixel from a global domain adaptively which further improves the performance of pixel synthesis. Quantitative and qualitative experiments on the benchmark dataset show that the proposed method is superior to the state-of-the-art approaches.
Efficient Depth Completion Using Learned Bases
Dec 02, 2020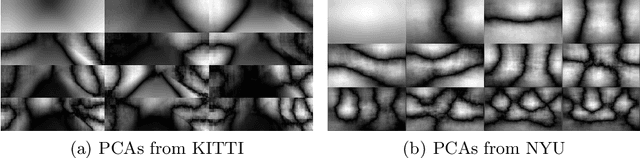



In this paper, we propose a new global geometry constraint for depth completion. By assuming depth maps often lay on low dimensional subspaces, a dense depth map can be approximated by a weighted sum of full-resolution principal depth bases. The principal components of depth fields can be learned from natural depth maps. The given sparse depth points are served as a data term to constrain the weighting process. When the input depth points are too sparse, the recovered dense depth maps are often over smoothed. To address this issue, we add a colour-guided auto-regression model as another regularization term. It assumes the reconstructed depth maps should share the same nonlocal similarity in the accompanying colour image. Our colour-guided PCA depth completion method has closed-form solutions, thus can be efficiently solved and is significantly more accurate than PCA only method. Extensive experiments on KITTI and Middlebury datasets demonstrate the superior performance of our proposed method.
High-Quality Face Image SR Using Conditional Generative Adversarial Networks
Jul 04, 2017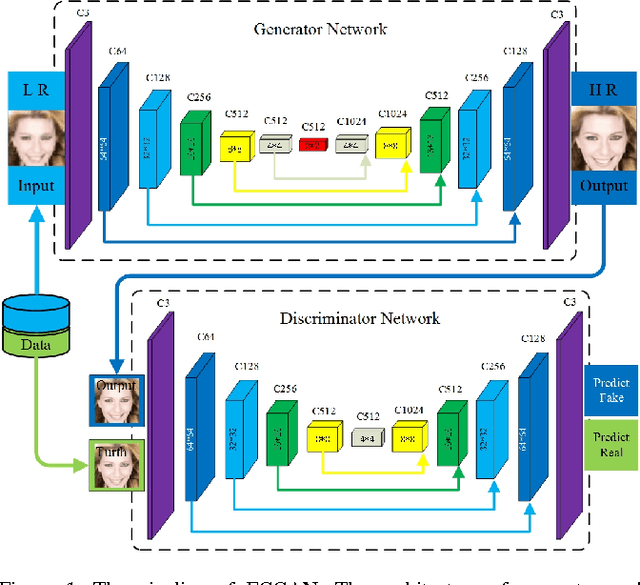



We propose a novel single face image super-resolution method, which named Face Conditional Generative Adversarial Network(FCGAN), based on boundary equilibrium generative adversarial networks. Without taking any facial prior information, our method can generate a high-resolution face image from a low-resolution one. Compared with existing studies, both our training and testing phases are end-to-end pipeline with little pre/post-processing. To enhance the convergence speed and strengthen feature propagation, skip-layer connection is further employed in the generative and discriminative networks. Extensive experiments demonstrate that our model achieves competitive performance compared with state-of-the-art models.