 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Leveraging SLIC Superpixel Segmentation and Cascaded Ensemble SVM for Fully Automated Mass Detection In Mammograms
Oct 20, 2020
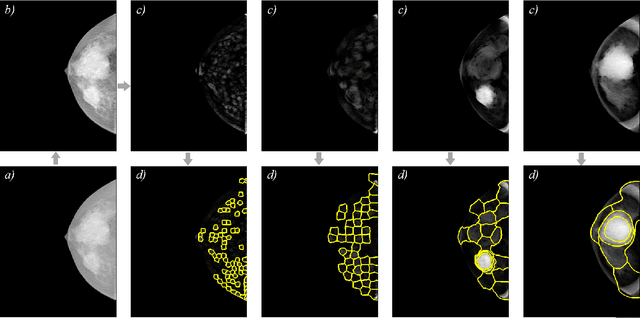

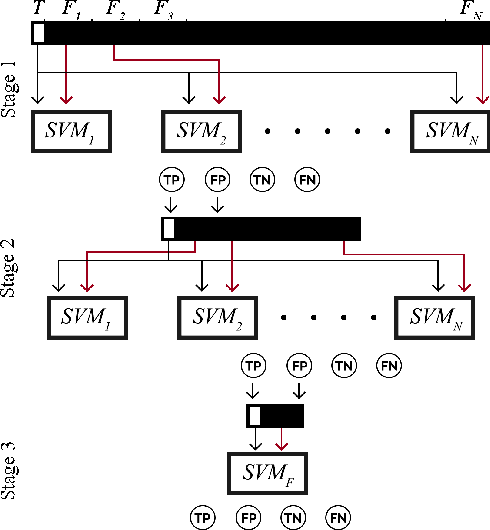
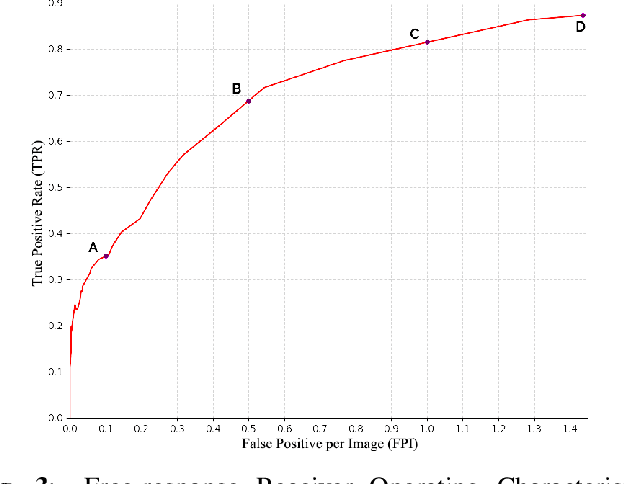
Identification and segmentation of breast masses in mammograms face complex challenges, owing to the highly variable nature of malignant densities with regards to their shape, contours, texture and orientation. Additionally, classifiers typically suffer from high class imbalance in region candidates, where normal tissue regions vastly outnumber malignant masses. This paper proposes a rigorous segmentation method, supported by morphological enhancement using grayscale linear filters. A novel cascaded ensemble of support vector machines (SVM) is used to effectively tackle the class imbalance and provide significant predictions. For True Positive Rate (TPR) of 0.35, 0.69 and 0.82, the system generates only 0.1, 0.5 and 1.0 False Positives/Image (FPI), respectively.
Bridging the gap between Natural and Medical Images through Deep Colorization
May 21, 2020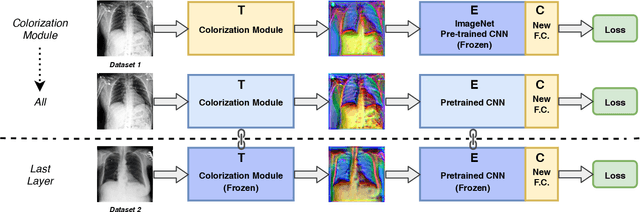
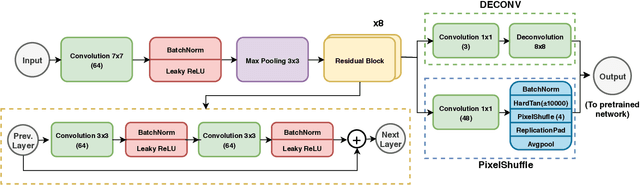
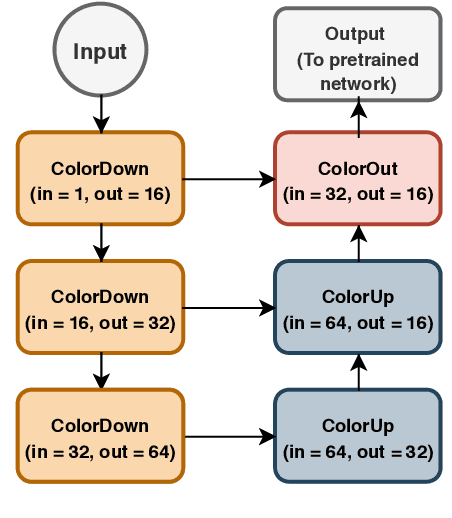
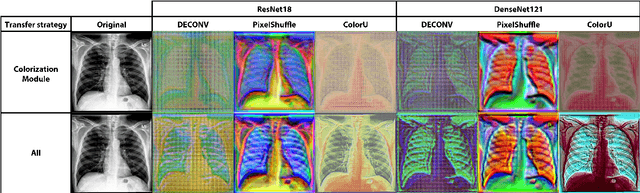
Deep learning has thrived by training on large-scale datasets. However, in many applications, as for medical image diagnosis, getting massive amount of data is still prohibitive due to privacy, lack of acquisition homogeneity and annotation cost. In this scenario, transfer learning from natural image collections is a standard practice that attempts to tackle shape, texture and color discrepancies all at once through pretrained model fine-tuning. In this work, we propose to disentangle those challenges and design a dedicated network module that focuses on color adaptation. We combine learning from scratch of the color module with transfer learning of different classification backbones, obtaining an end-to-end, easy-to-train architecture for diagnostic image recognition on X-ray images. Extensive experiments showed how our approach is particularly efficient in case of data scarcity and provides a new path for further transferring the learned color information across multiple medical datasets.
On Generating Plausible Counterfactual and Semi-Factual Explanations for Deep Learning
Sep 10, 2020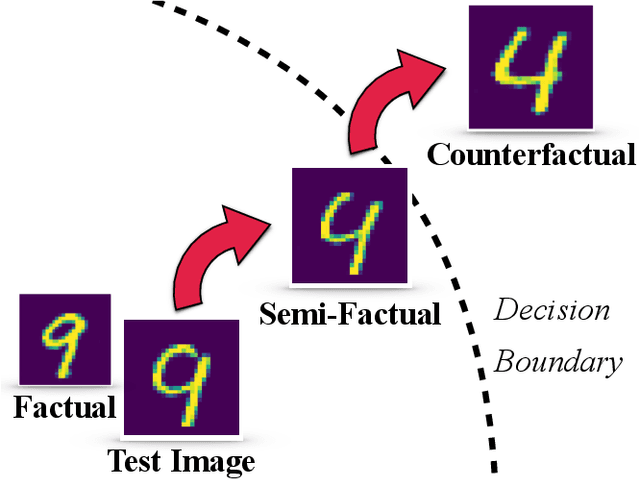
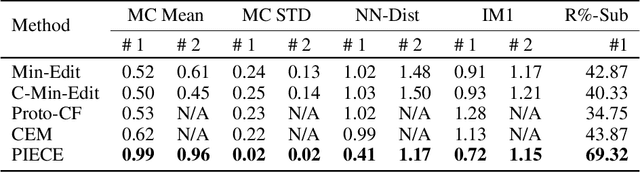
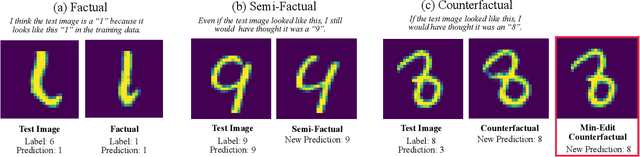
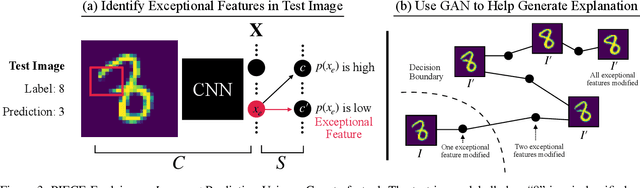
There is a growing concern that the recent progress made in AI, especially regarding the predictive competence of deep learning models, will be undermined by a failure to properly explain their operation and outputs. In response to this disquiet counterfactual explanations have become massively popular in eXplainable AI (XAI) due to their proposed computational psychological, and legal benefits. In contrast however, semifactuals, which are a similar way humans commonly explain their reasoning, have surprisingly received no attention. Most counterfactual methods address tabular rather than image data, partly due to the nondiscrete nature of the latter making good counterfactuals difficult to define. Additionally generating plausible looking explanations which lie on the data manifold is another issue which hampers progress. This paper advances a novel method for generating plausible counterfactuals (and semifactuals) for black box CNN classifiers doing computer vision. The present method, called PlausIble Exceptionality-based Contrastive Explanations (PIECE), modifies all exceptional features in a test image to be normal from the perspective of the counterfactual class (hence concretely defining a counterfactual). Two controlled experiments compare this method to others in the literature, showing that PIECE not only generates the most plausible counterfactuals on several measures, but also the best semifactuals.
Revisiting Stereo Depth Estimation From a Sequence-to-Sequence Perspective with Transformers
Nov 05, 2020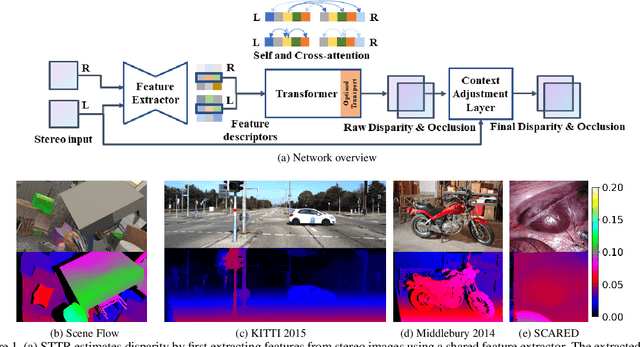
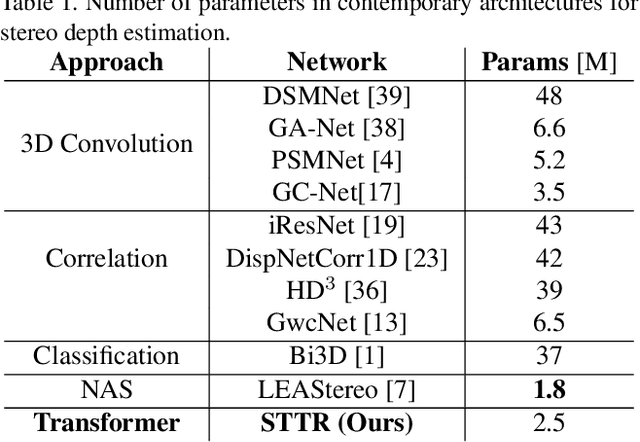
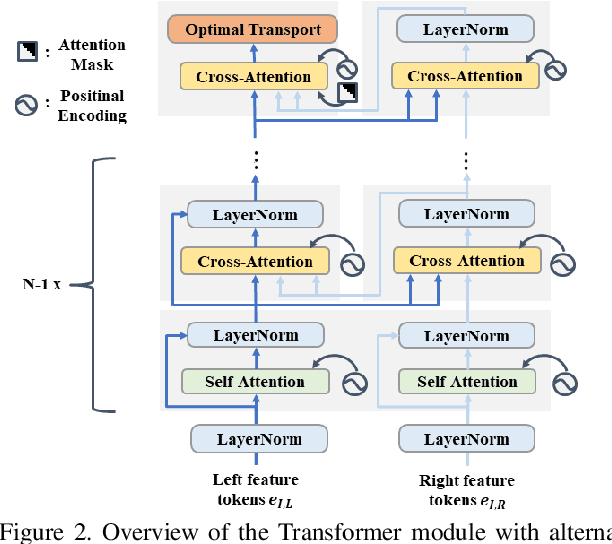
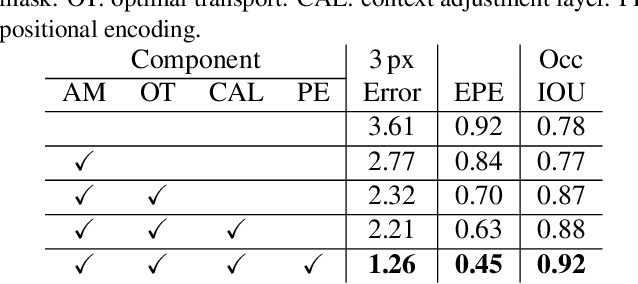
Stereo depth estimation relies on optimal correspondence matching between pixels on epipolar lines in the left and right image to infer depth. Rather than matching individual pixels, in this work, we revisit the problem from a sequence-to-sequence correspondence perspective to replace cost volume construction with dense pixel matching using position information and attention. This approach, named STereo TRansformer (STTR), has several advantages: It 1) relaxes the limitation of a fixed disparity range, 2) identifies occluded regions and provides confidence of estimation, and 3) imposes uniqueness constraints during the matching process. We report promising results on both synthetic and real-world datasets and demonstrate that STTR generalizes well across different domains, even without fine-tuning. Our code is publicly available at https://github.com/mli0603/stereo-transformer.
Machine Identification of High Impact Research through Text and Image Analysis
May 20, 2020
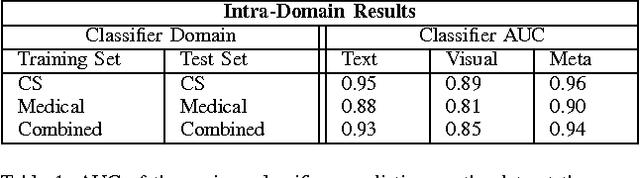
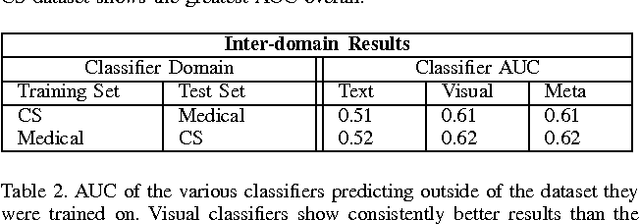
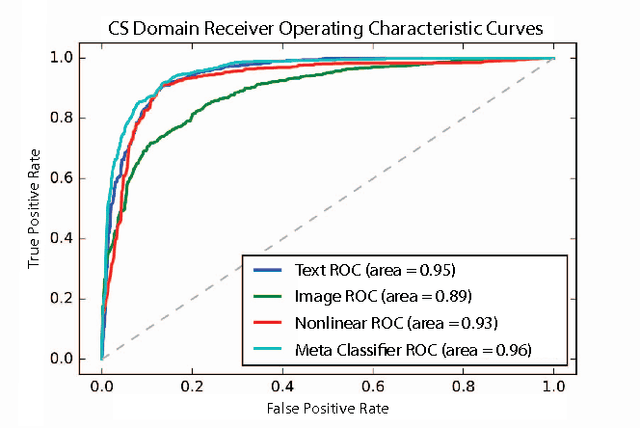
The volume of academic paper submissions and publications is growing at an ever increasing rate. While this flood of research promises progress in various fields, the sheer volume of output inherently increases the amount of noise. We present a system to automatically separate papers with a high from those with a low likelihood of gaining citations as a means to quickly find high impact, high quality research. Our system uses both a visual classifier, useful for surmising a document's overall appearance, and a text classifier, for making content-informed decisions. Current work in the field focuses on small datasets composed of papers from individual conferences. Attempts to use similar techniques on larger datasets generally only considers excerpts of the documents such as the abstract, potentially throwing away valuable data. We rectify these issues by providing a dataset composed of PDF documents and citation counts spanning a decade of output within two separate academic domains: computer science and medicine. This new dataset allows us to expand on current work in the field by generalizing across time and academic domain. Moreover, we explore inter-domain prediction models - evaluating a classifier's performance on a domain it was not trained on - to shed further insight on this important problem.
Learning to Utilize Correlated Auxiliary Classical or Quantum Noise
Jun 08, 2020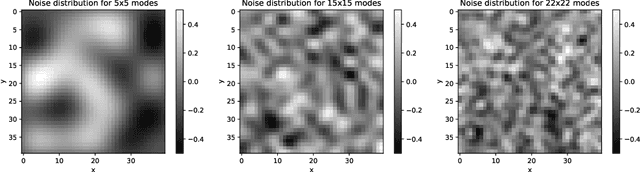
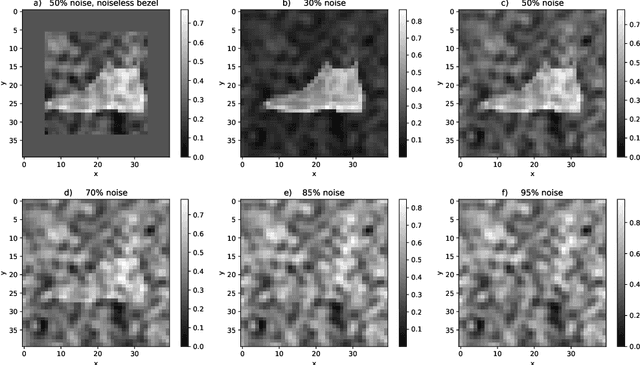
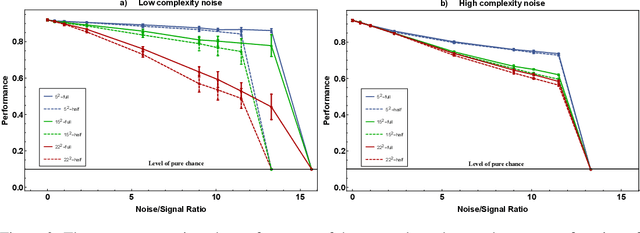
This paper has two messages. First, we demonstrate that neural networks can learn to exploit correlations between noisy data and suitable auxiliary noise. In effect, the network learns to use the correlated auxiliary noise as an approximate key to decipher its noisy input data. Second, we show that the scaling behavior with increasing noise is such that future quantum machines should possess an advantage. For a concrete example, we reduce the image classification performance of convolutional neural networks (CNNs) by adding noise of different amounts and quality to the input images. We then demonstrate that the CNNs are able to partly recover their performance if, along with each noisy image, they are given auxiliary noise that is correlated with the image noise. We analyze the scaling of a CNN ability to learn and utilize these noise correlations as the level, dimensionality, or complexity of the noise is increased. We thereby find numerical and theoretical indications that quantum machines, due to their efficiency in representing complex correlations, could possess a significant advantage over classical machines.
From Rain Removal to Rain Generation
Aug 08, 2020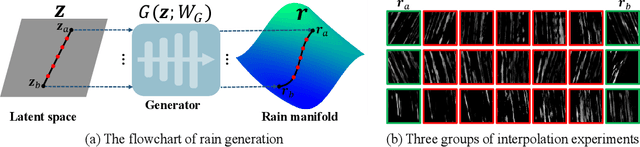
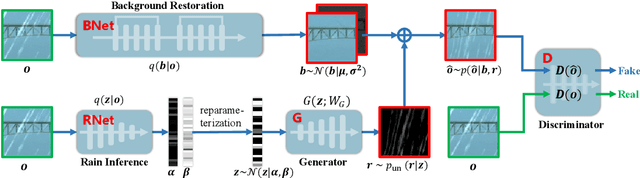
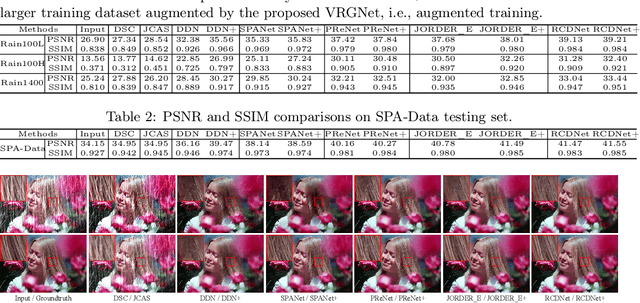

Single image deraining is an important yet challenging issue due to the complex and diverse rain structures in real scenes. Currently, the state-of-the-art performance on this task is achieved by deep learning (DL)-based methods that mainly benefit from abundant pre-collected paired rainy-clean samples either manually synthesized or semi-automatically generated under human supervision. This tends to bring a large labor for data collection and more importantly, such manner neglects to elaborately explore the intrinsic generative mechanism of rain streaks which should be related to the most insightful understanding of the task. Against this issue, we investigate the generative process of rainy image and construct a full Bayesian generative model for generating rains from automatically extracted latent variables that represent physical structural factors for depicting rains, like direction, scale, and thickness. To solve this model, we propose an algorithm where the posteriors of latent variables are parameterized as CNNs and all the involved parameters can be inferred under a concise variational inference framework in a data-driven manner. Especially, the rain layer is modeled as an implicit distribution, parameterized as a generator, which avoids subjective prior assumptions on rains as in traditional model-based methods. More practically, from the learned generator, rain patches can be automatically generated and utilized to simulate diverse training pairs so as to enrich and augment the existing benchmark datasets. Comprehensive experiments substantiate that the proposed model has fine capability of generating plausible samples that not only helps significantly improve the deraining performance of current DL-based single image derainers, but also largely loosens the requirement of large training sample pre-collection for the task.
Rethinking the Form of Latent States in Image Captioning
Jul 26, 2018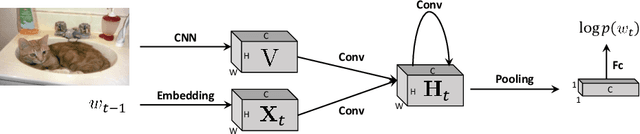
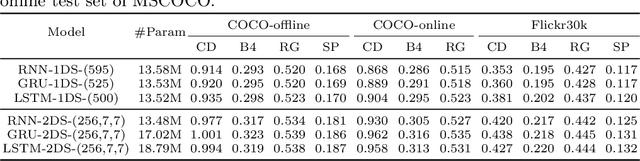


RNNs and their variants have been widely adopted for image captioning. In RNNs, the production of a caption is driven by a sequence of latent states. Existing captioning models usually represent latent states as vectors, taking this practice for granted. We rethink this choice and study an alternative formulation, namely using two-dimensional maps to encode latent states. This is motivated by the curiosity about a question: how the spatial structures in the latent states affect the resultant captions? Our study on MSCOCO and Flickr30k leads to two significant observations. First, the formulation with 2D states is generally more effective in captioning, consistently achieving higher performance with comparable parameter sizes. Second, 2D states preserve spatial locality. Taking advantage of this, we visually reveal the internal dynamics in the process of caption generation, as well as the connections between input visual domain and output linguistic domain.
Beyond Single Instance Multi-view Unsupervised Representation Learning
Nov 26, 2020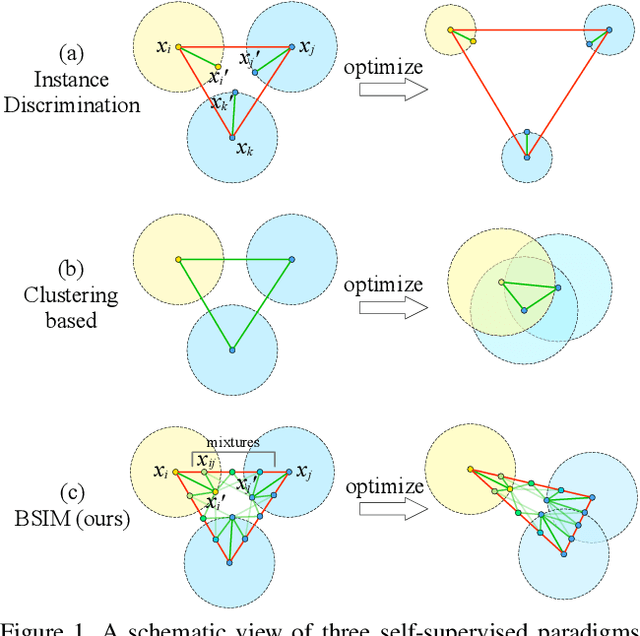
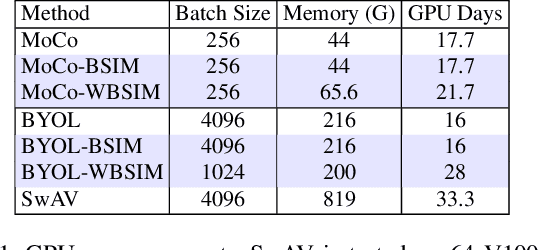
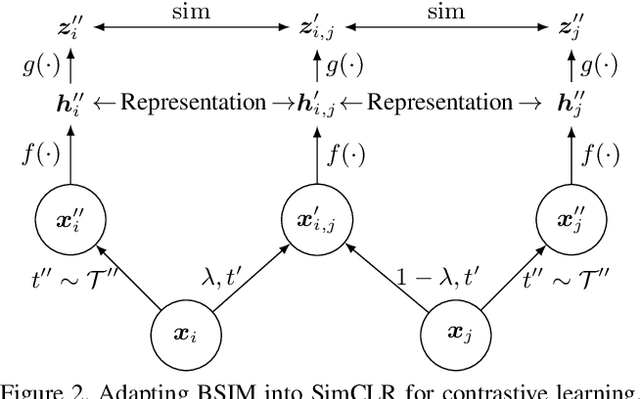
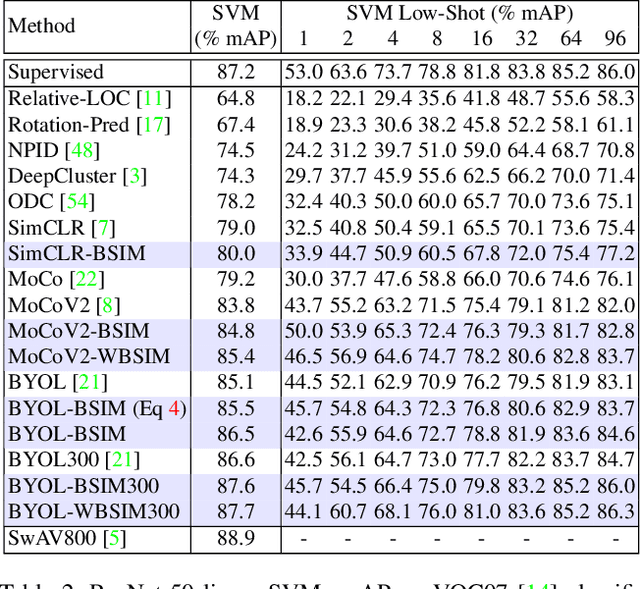
Recent unsupervised contrastive representation learning follows a Single Instance Multi-view (SIM) paradigm where positive pairs are usually constructed with intra-image data augmentation. In this paper, we propose an effective approach called Beyond Single Instance Multi-view (BSIM). Specifically, we impose more accurate instance discrimination capability by measuring the joint similarity between two randomly sampled instances and their mixture, namely spurious-positive pairs. We believe that learning joint similarity helps to improve the performance when encoded features are distributed more evenly in the latent space. We apply it as an orthogonal improvement for unsupervised contrastive representation learning, including current outstanding methods SimCLR, MoCo, and BYOL. We evaluate our learned representations on many downstream benchmarks like linear classification on ImageNet-1k and PASCAL VOC 2007, object detection on MS COCO 2017 and VOC, etc. We obtain substantial gains with a large margin almost on all these tasks compared with prior arts.
A New Window Loss Function for Bone Fracture Detection and Localization in X-ray Images with Point-based Annotation
Jan 04, 2021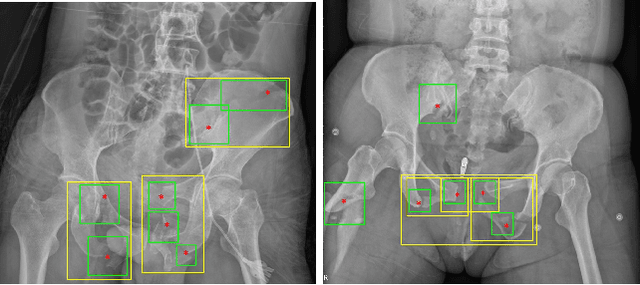
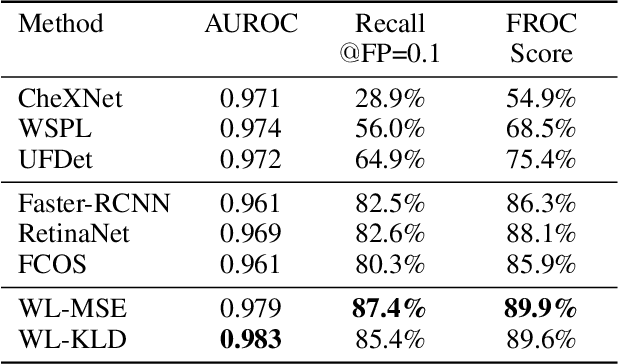
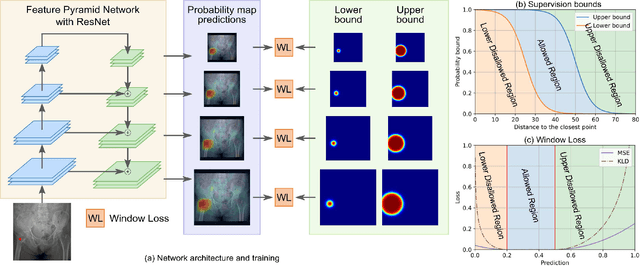
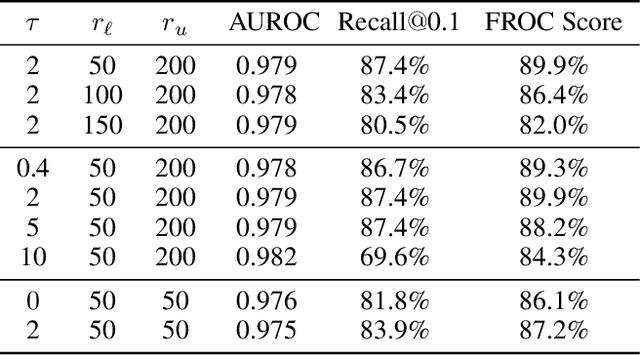
Object detection methods are widely adopted for computer-aided diagnosis using medical images. Anomalous findings are usually treated as objects that are described by bounding boxes. Yet, many pathological findings, e.g., bone fractures, cannot be clearly defined by bounding boxes, owing to considerable instance, shape and boundary ambiguities. This makes bounding box annotations, and their associated losses, highly ill-suited. In this work, we propose a new bone fracture detection method for X-ray images, based on a labor effective and flexible annotation scheme suitable for abnormal findings with no clear object-level spatial extents or boundaries. Our method employs a simple, intuitive, and informative point-based annotation protocol to mark localized pathology information. To address the uncertainty in the fracture scales annotated via point(s), we convert the annotations into pixel-wise supervision that uses lower and upper bounds with positive, negative, and uncertain regions. A novel Window Loss is subsequently proposed to only penalize the predictions outside of the uncertain regions. Our method has been extensively evaluated on 4410 pelvic X-ray images of unique patients. Experiments demonstrate that our method outperforms previous state-of-the-art image classification and object detection baselines by healthy margins, with an AUROC of 0.983 and FROC score of 89.6%.