 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Exploring Adversarial Fake Images on Face Manifold
Jan 09, 2021
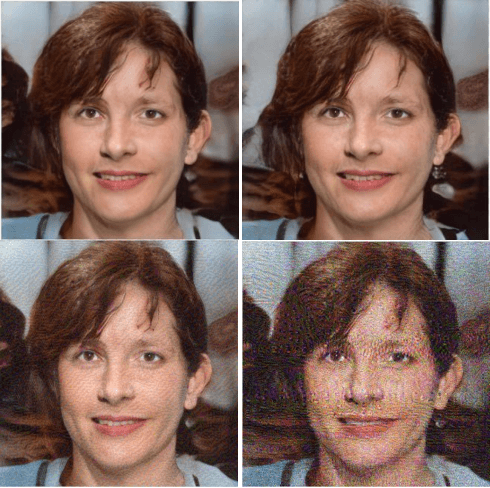
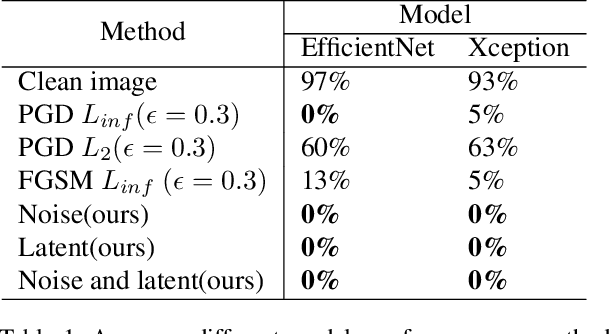
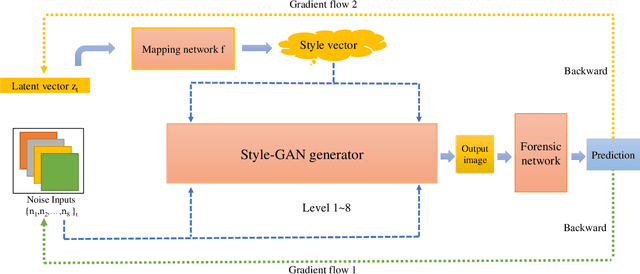
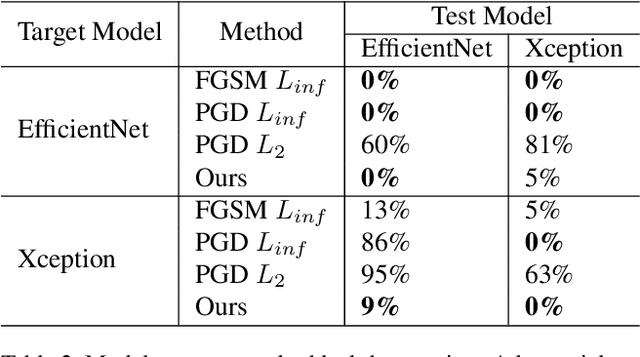
Images synthesized by powerful generative adversarial network (GAN) based methods have drawn moral and privacy concerns. Although image forensic models have reached great performance in detecting fake images from real ones, these models can be easily fooled with a simple adversarial attack. But, the noise adding adversarial samples are also arousing suspicion. In this paper, instead of adding adversarial noise, we optimally search adversarial points on face manifold to generate anti-forensic fake face images. We iteratively do a gradient-descent with each small step in the latent space of a generative model, e.g. Style-GAN, to find an adversarial latent vector, which is similar to norm-based adversarial attack but in latent space. Then, the generated fake images driven by the adversarial latent vectors with the help of GANs can defeat main-stream forensic models. For examples, they make the accuracy of deepfake detection models based on Xception or EfficientNet drop from over 90% to nearly 0%, meanwhile maintaining high visual quality. In addition, we find manipulating style vector $z$ or noise vectors $n$ at different levels have impacts on attack success rate. The generated adversarial images mainly have facial texture or face attributes changing.
Predicting How to Distribute Work Between Algorithms and Humans to Segment an Image Batch
Apr 30, 2019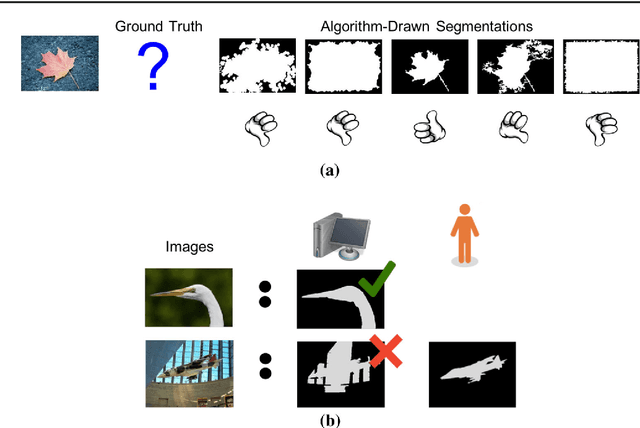
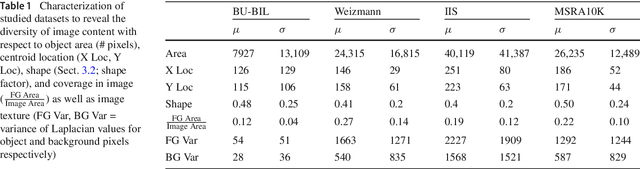
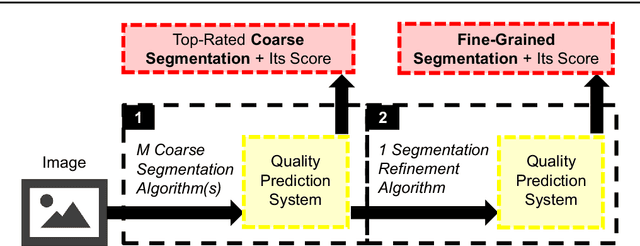

Foreground object segmentation is a critical step for many image analysis tasks. While automated methods can produce high-quality results, their failures disappoint users in need of practical solutions. We propose a resource allocation framework for predicting how best to allocate a fixed budget of human annotation effort in order to collect higher quality segmentations for a given batch of images and automated methods. The framework is based on a prediction module that estimates the quality of given algorithm-drawn segmentations. We demonstrate the value of the framework for two novel tasks related to predicting how to distribute annotation efforts between algorithms and humans. Specifically, we develop two systems that automatically decide, for a batch of images, when to recruit humans versus computers to create 1) coarse segmentations required to initialize segmentation tools and 2) final, fine-grained segmentations. Experiments demonstrate the advantage of relying on a mix of human and computer efforts over relying on either resource alone for segmenting objects in images coming from three diverse modalities (visible, phase contrast microscopy, and fluorescence microscopy).
CLAIRE: A distributed-memory solver for constrained large deformation diffeomorphic image registration
Aug 13, 2018
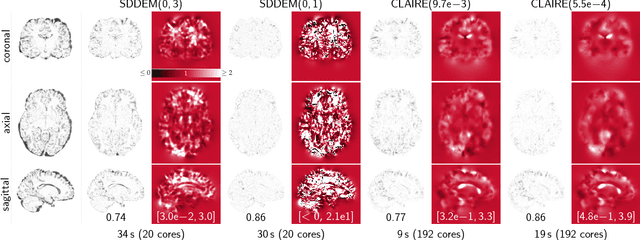

We introduce CLAIRE, a distributed-memory algorithm and software for solving constrained large deformation diffeomorphic image registration problems in three dimensions. We invert for a stationary velocity field that parameterizes the deformation map. Our solver is based on a globalized, preconditioned, inexact reduced space Gauss--Newton--Krylov scheme. We exploit state-of-the-art techniques in scientific computing to develop an effective solver that scales to thousand of distributed memory nodes on high-end clusters. Our improved, parallel implementation features parameter-, scale-, and grid-continuation schemes to speedup the computations and reduce the likelihood to get trapped in local minima. We also implement an improved preconditioner for the reduced space Hessian to speedup the convergence. We test registration performance on synthetic and real data. We demonstrate registration accuracy on 16 neuroimaging datasets. We compare the performance of our scheme against different flavors of the DEMONS algorithm for diffeomorphic image registration. We study convergence of our preconditioner and our overall algorithm. We report scalability results on state-of-the-art supercomputing platforms. We demonstrate that we can solve registration problems for clinically relevant data sizes in two to four minutes on a standard compute node with 20 cores, attaining excellent data fidelity. With the present work we achieve a speedup of (on average) 5x with a peak performance of up to 17x compared to our former work.
High Resolution, Deep Imaging Using Confocal Time-of-flight Diffuse Optical Tomography
Jan 27, 2021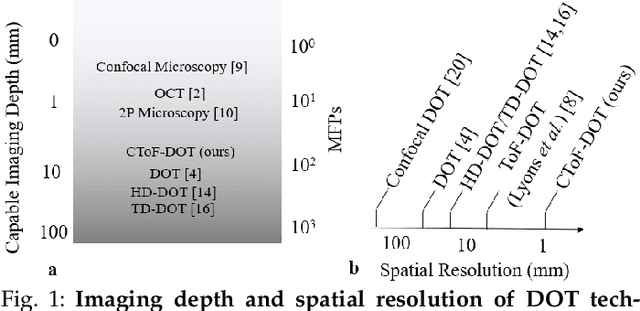
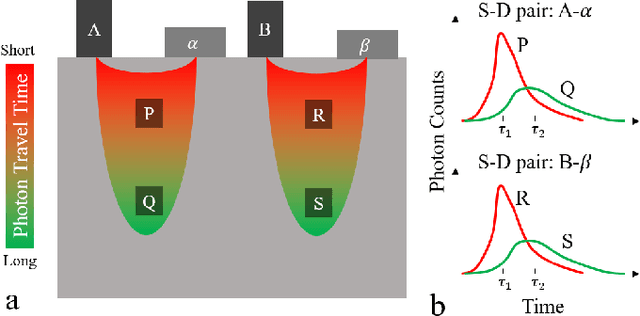
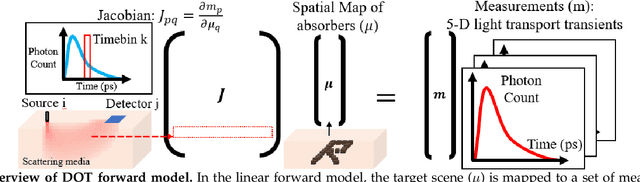
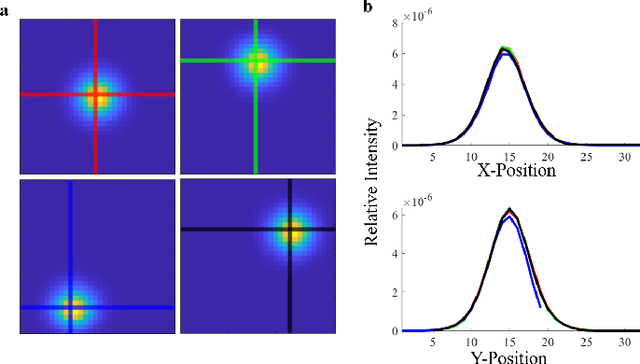
Light scattering by tissue severely limits both how deep beneath the surface one can image, and at what spatial resolution one can obtain from these images. Diffuse optical tomography (DOT) has emerged as one of the most powerful techniques for imaging deep within tissue -- well beyond the conventional $\sim$ 10-15 mean scattering lengths tolerated by ballistic imaging techniques such as confocal and two-photon microscopy. Unfortunately, existing DOT systems are quite limited and achieve only centimeter-scale resolution. Furthermore, they also suffer from slow acquisition times and extremely slow reconstruction speeds making real-time imaging infeasible. We show that time-of-flight diffuse optical tomography (ToF-DOT) and its confocal variant (CToF-DOT), by exploiting the photon travel time information, allow us to achieve millimeter spatial resolution in the highly scattered diffusion regime ($>50$ mean free paths). In addition, we demonstrate that two additional innovations: focusing on confocal measurements, and multiplexing the illumination sources allow us to significantly reduce the scan time to acquire measurements. Finally, we also rely on a novel convolutional approximation that allows us to develop a fast reconstruction algorithm achieving a 100 $\times$ speedup in reconstruction time compared to traditional DOT reconstruction techniques. Together, we believe that these technical advances, serve as the first step towards real-time, millimeter resolution, deep tissue imaging using diffuse optical tomography.
A range characterization of the single-quadrant ADRT
Oct 11, 2020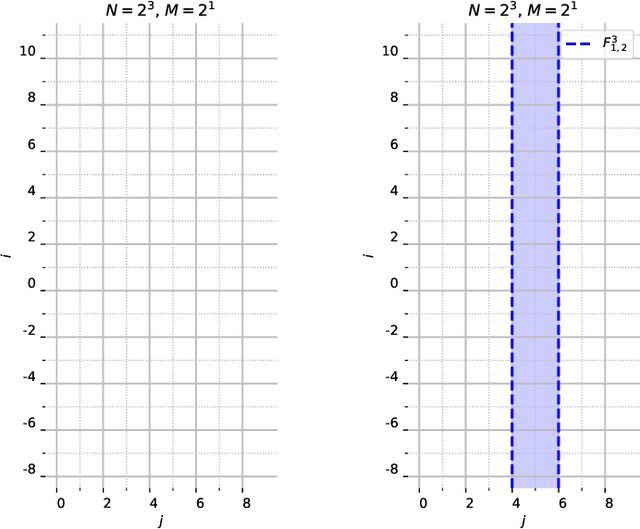
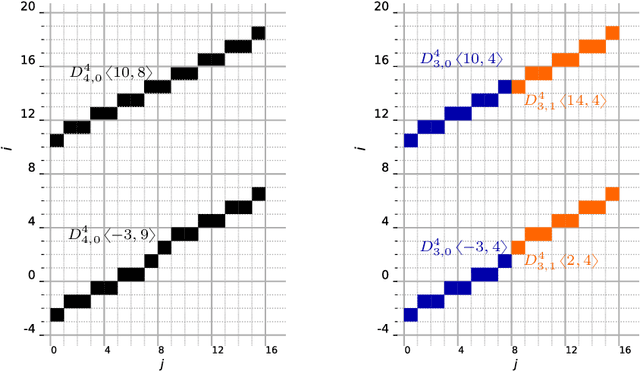
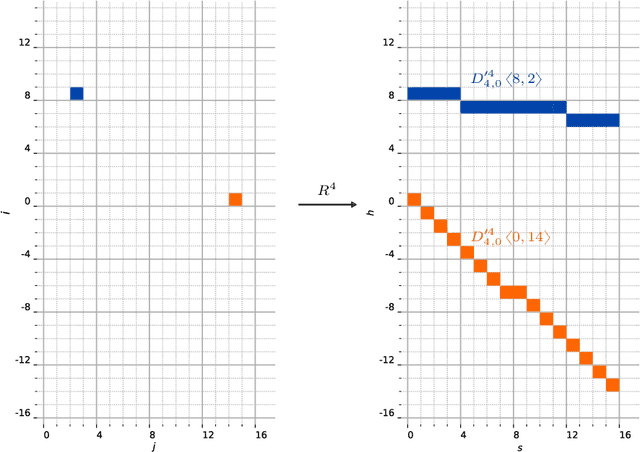
This work characterizes the range of the single-quadrant approximate discrete Radon transform (ADRT) of square images. The characterization is given in the form of linear constraints that ensure the exact and fast inversion formula [Rim, Appl. Math. Lett. 102 106159, 2020] yields a square image in a stable manner. The range characterization is obtained by first showing that the transform is a bijection between images supported on infinite half-strips, then identifying the linear subspaces that stay finitely supported under the inversion formula.
Learning Numerical Observers using Unsupervised Domain Adaptation
Feb 22, 2020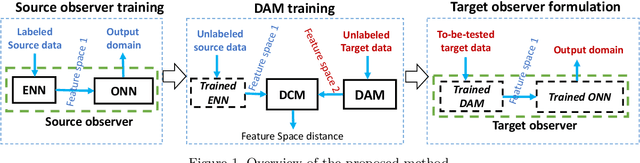
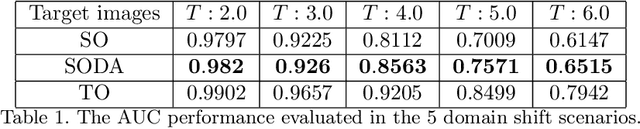
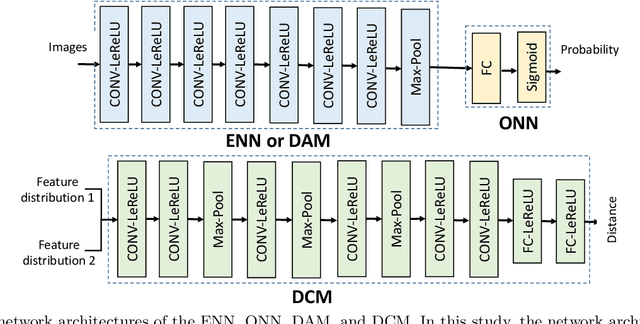
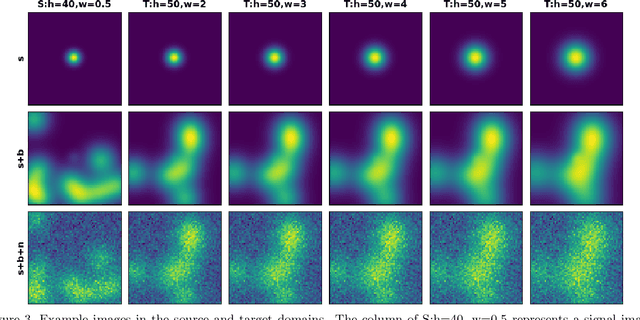
Medical imaging systems are commonly assessed by use of objective image quality measures. Supervised deep learning methods have been investigated to implement numerical observers for task-based image quality assessment. However, labeling large amounts of experimental data to train deep neural networks is tedious, expensive, and prone to subjective errors. Computer-simulated image data can potentially be employed to circumvent these issues; however, it is often difficult to computationally model complicated anatomical structures, noise sources, and the response of real world imaging systems. Hence, simulated image data will generally possess physical and statistical differences from the experimental image data they seek to emulate. Within the context of machine learning, these differences between the sets of two images is referred to as domain shift. In this study, we propose and investigate the use of an adversarial domain adaptation method to mitigate the deleterious effects of domain shift between simulated and experimental image data for deep learning-based numerical observers (DL-NOs) that are trained on simulated images but applied to experimental ones. In the proposed method, a DL-NO will initially be trained on computer-simulated image data and subsequently adapted for use with experimental image data, without the need for any labeled experimental images. As a proof of concept, a binary signal detection task is considered. The success of this strategy as a function of the degree of domain shift present between the simulated and experimental image data is investigated.
Domain-Adversarial Learning for Multi-Centre, Multi-Vendor, and Multi-Disease Cardiac MR Image Segmentation
Aug 26, 2020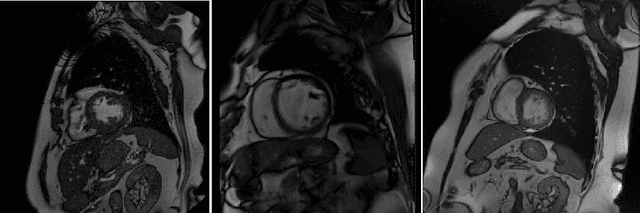
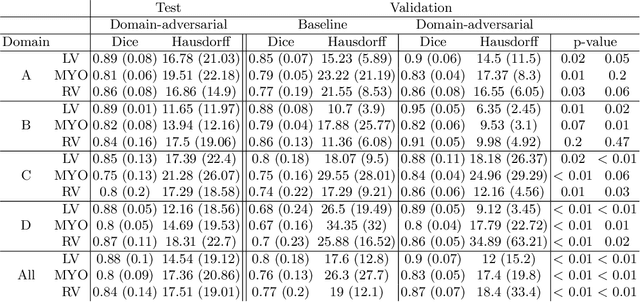
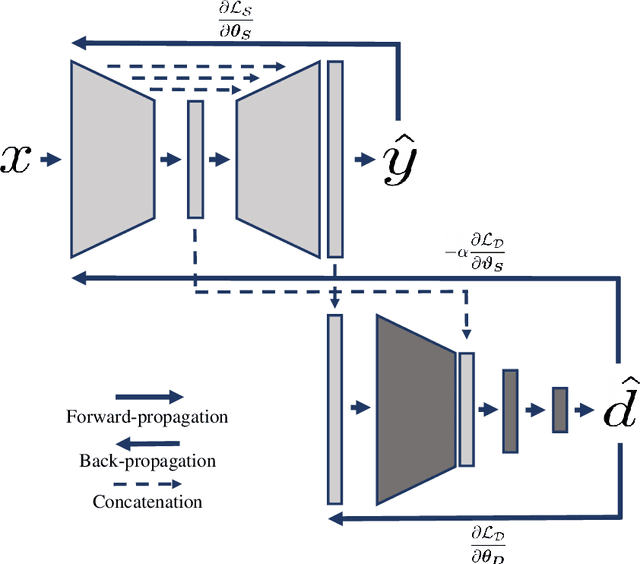
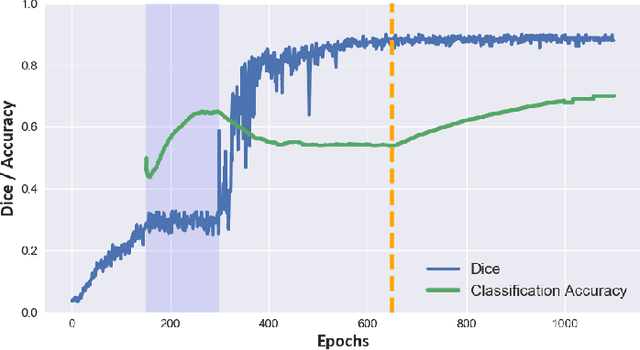
Cine cardiac magnetic resonance (CMR) has become the gold standard for the non-invasive evaluation of cardiac function. In particular, it allows the accurate quantification of functional parameters including the chamber volumes and ejection fraction. Deep learning has shown the potential to automate the requisite cardiac structure segmentation. However, the lack of robustness of deep learning models has hindered their widespread clinical adoption. Due to differences in the data characteristics, neural networks trained on data from a specific scanner are not guaranteed to generalise well to data acquired at a different centre or with a different scanner. In this work, we propose a principled solution to the problem of this domain shift. Domain-adversarial learning is used to train a domain-invariant 2D U-Net using labelled and unlabelled data. This approach is evaluated on both seen and unseen domains from the M\&Ms challenge dataset and the domain-adversarial approach shows improved performance as compared to standard training. Additionally, we show that the domain information cannot be recovered from the learned features.
PanoNet3D: Combining Semantic and Geometric Understanding for LiDARPoint Cloud Detection
Dec 17, 2020

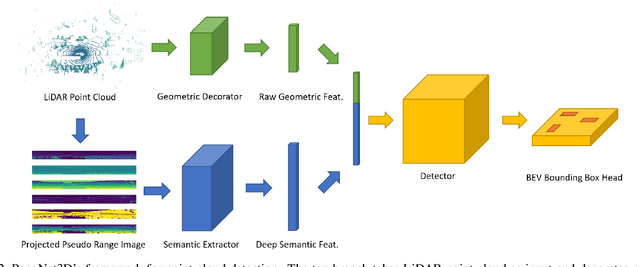

Visual data in autonomous driving perception, such as camera image and LiDAR point cloud, can be interpreted as a mixture of two aspects: semantic feature and geometric structure. Semantics come from the appearance and context of objects to the sensor, while geometric structure is the actual 3D shape of point clouds. Most detectors on LiDAR point clouds focus only on analyzing the geometric structure of objects in real 3D space. Unlike previous works, we propose to learn both semantic feature and geometric structure via a unified multi-view framework. Our method exploits the nature of LiDAR scans -- 2D range images, and applies well-studied 2D convolutions to extract semantic features. By fusing semantic and geometric features, our method outperforms state-of-the-art approaches in all categories by a large margin. The methodology of combining semantic and geometric features provides a unique perspective of looking at the problems in real-world 3D point cloud detection.
Facial Keypoint Sequence Generation from Audio
Nov 02, 2020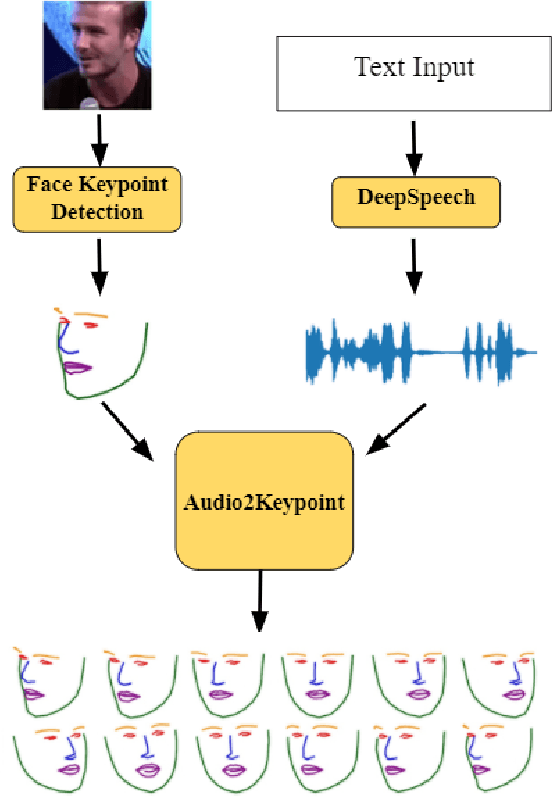
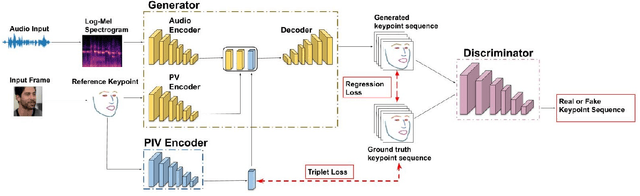
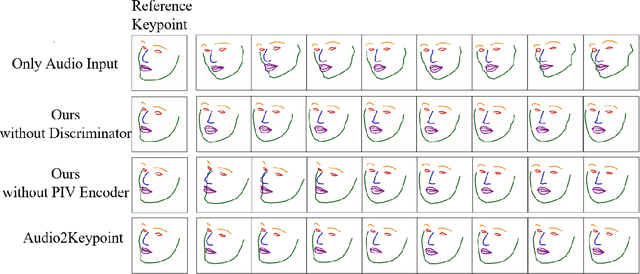
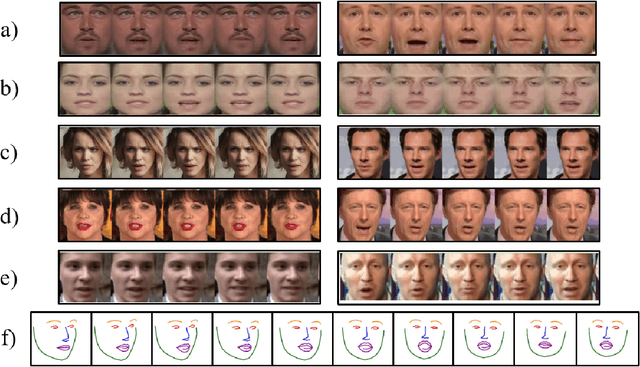
Whenever we speak, our voice is accompanied by facial movements and expressions. Several recent works have shown the synthesis of highly photo-realistic videos of talking faces, but they either require a source video to drive the target face or only generate videos with a fixed head pose. This lack of facial movement is because most of these works focus on the lip movement in sync with the audio while assuming the remaining facial keypoints' fixed nature. To address this, a unique audio-keypoint dataset of over 150,000 videos at 224p and 25fps is introduced that relates the facial keypoint movement for the given audio. This dataset is then further used to train the model, Audio2Keypoint, a novel approach for synthesizing facial keypoint movement to go with the audio. Given a single image of the target person and an audio sequence (in any language), Audio2Keypoint generates a plausible keypoint movement sequence in sync with the input audio, conditioned on the input image to preserve the target person's facial characteristics. To the best of our knowledge, this is the first work that proposes an audio-keypoint dataset and learns a model to output the plausible keypoint sequence to go with audio of any arbitrary length. Audio2Keypoint generalizes across unseen people with a different facial structure allowing us to generate the sequence with the voice from any source or even synthetic voices. Instead of learning a direct mapping from audio to video domain, this work aims to learn the audio-keypoint mapping that allows for in-plane and out-of-plane head rotations, while preserving the person's identity using a Pose Invariant (PIV) Encoder.
Self-Supervised Attention Learning for Depth and Ego-motion Estimation
Apr 27, 2020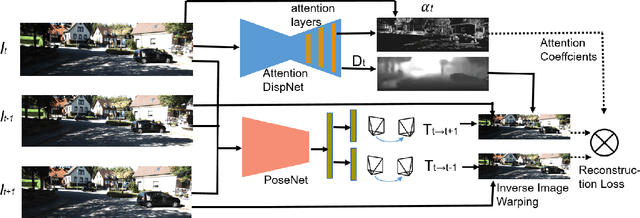
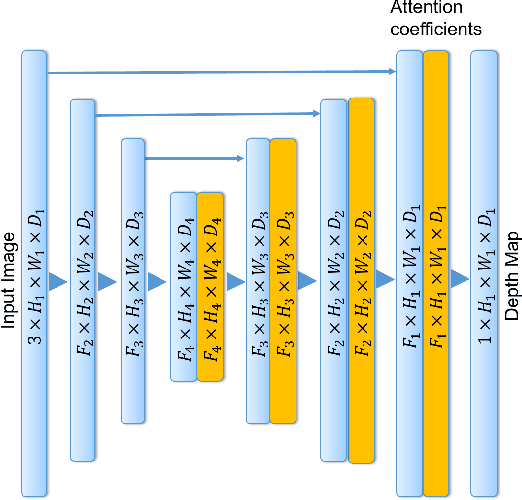

We address the problem of depth and ego-motion estimation from image sequences. Recent advances in the domain propose to train a deep learning model for both tasks using image reconstruction in a self-supervised manner. We revise the assumptions and the limitations of the current approaches and propose two improvements to boost the performance of the depth and ego-motion estimation. We first use Lie group properties to enforce the geometric consistency between images in the sequence and their reconstructions. We then propose a mechanism to pay an attention to image regions where the image reconstruction get corrupted. We show how to integrate the attention mechanism in the form of attention gates in the pipeline and use attention coefficients as a mask. We evaluate the new architecture on the KITTI datasets and compare it to the previous techniques. We show that our approach improves the state-of-the-art results for ego-motion estimation and achieve comparable results for depth estimation.