 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Attention-Guided Black-box Adversarial Attacks with Large-Scale Multiobjective Evolutionary Optimization
Jan 19, 2021


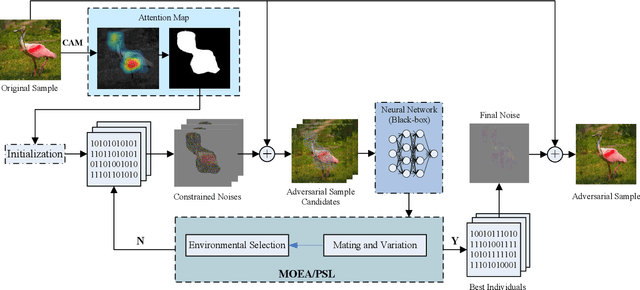
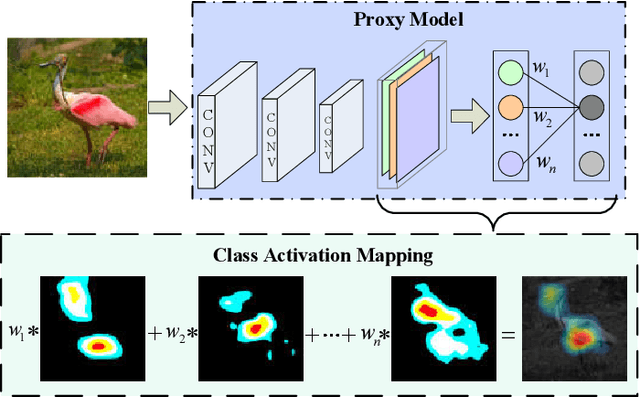
Fooling deep neural networks (DNNs) with the black-box optimization has become a popular adversarial attack fashion, as the structural prior knowledge of DNNs is always unknown. Nevertheless, recent black-box adversarial attacks may struggle to balance their attack ability and visual quality of the generated adversarial examples (AEs) in tackling high-resolution images. In this paper, we propose an attention-guided black-box adversarial attack based on the large-scale multiobjective evolutionary optimization, termed as LMOA. By considering the spatial semantic information of images, we firstly take advantage of the attention map to determine the perturbed pixels. Instead of attacking the entire image, reducing the perturbed pixels with the attention mechanism can help to avoid the notorious curse of dimensionality and thereby improves the performance of attacking. Secondly, a large-scale multiobjective evolutionary algorithm is employed to traverse the reduced pixels in the salient region. Benefiting from its characteristics, the generated AEs have the potential to fool target DNNs while being imperceptible by the human vision. Extensive experimental results have verified the effectiveness of the proposed LMOA on the ImageNet dataset. More importantly, it is more competitive to generate high-resolution AEs with better visual quality compared with the existing black-box adversarial attacks.
Deep learning within a priori temporal feature spaces for large-scale dynamic MR image reconstruction: Application to 5-D cardiac MR Multitasking
Oct 02, 2019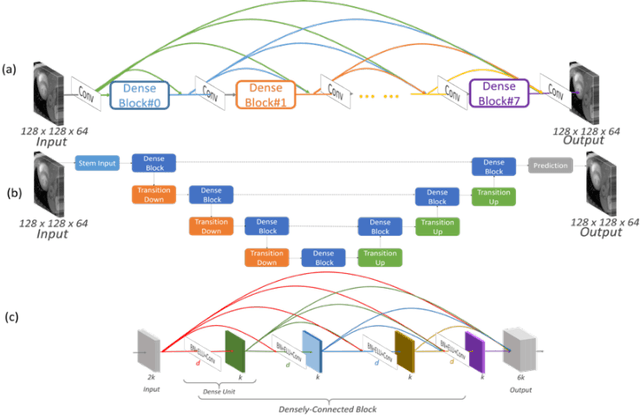
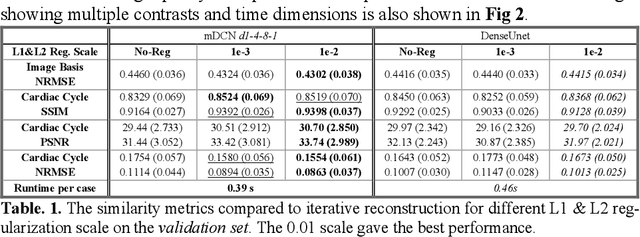
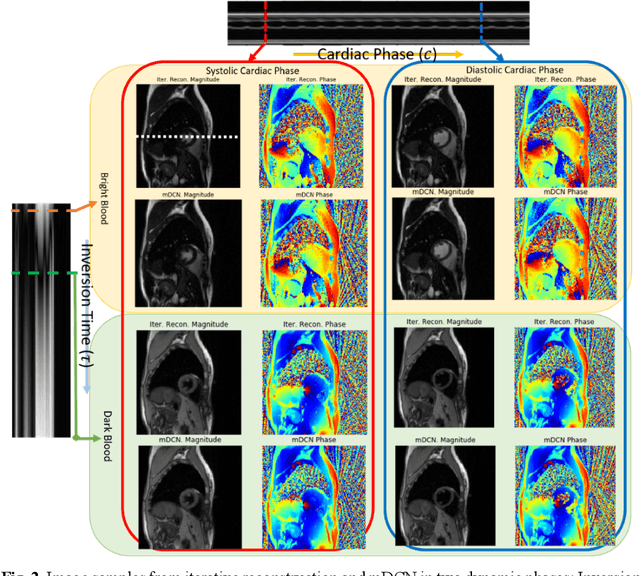
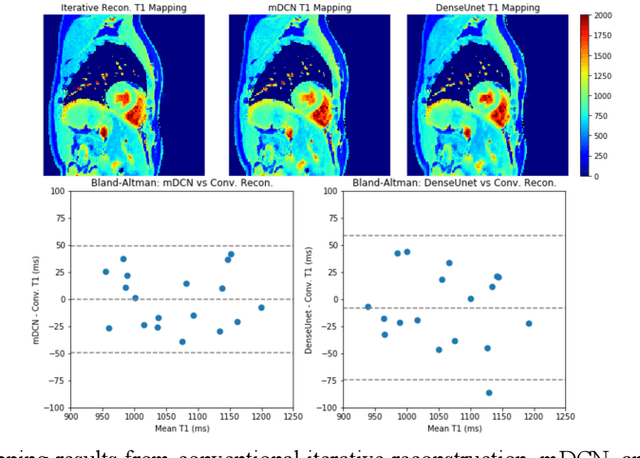
High spatiotemporal resolution dynamic magnetic resonance imaging (MRI) is a powerful clinical tool for imaging moving structures as well as to reveal and quantify other physical and physiological dynamics. The low speed of MRI necessitates acceleration methods such as deep learning reconstruction from under-sampled data. However, the massive size of many dynamic MRI problems prevents deep learning networks from directly exploiting global temporal relationships. In this work, we show that by applying deep neural networks inside a priori calculated temporal feature spaces, we enable deep learning reconstruction with global temporal modeling even for image sequences with >40,000 frames. One proposed variation of our approach using dilated multi-level Densely Connected Network (mDCN) speeds up feature space coordinate calculation by 3000x compared to conventional iterative methods, from 20 minutes to 0.39 seconds. Thus, the combination of low-rank tensor and deep learning models not only makes large-scale dynamic MRI feasible but also practical for routine clinical application.
Field of Junctions
Nov 27, 2020
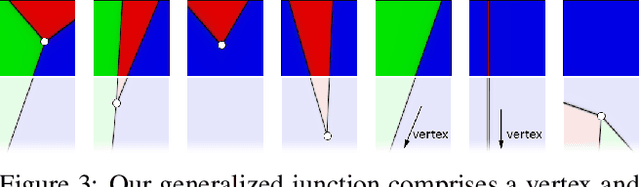


We introduce a bottom-up model for jointly finding many boundary elements in an image, including edges, curves, corners and junctions. The model explains boundary shape in each small patch using a junction with M angles and a freely-moving vertex. Images are analyzed by solving a non-convex optimization problem using purposefully-designed algorithms, cooperatively finding M+2 junction values at every pixel. The resulting field of junctions is simultaneously an edge detector, a corner/junction detector, and a boundary-aware smoothing of regional appearance. We demonstrate how it behaves at different scales, and for both single-channel and multi-channel input. Notably, we find it has unprecedented resilience to noise: It succeeds at high noise levels where previous methods for segmentation and for edge, corner and junction detection fail.
MonoComb: A Sparse-to-Dense Combination Approach for Monocular Scene Flow
Nov 12, 2020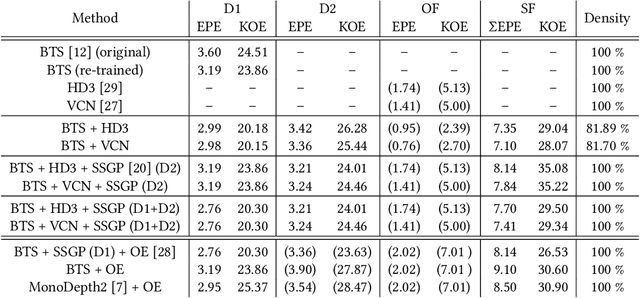


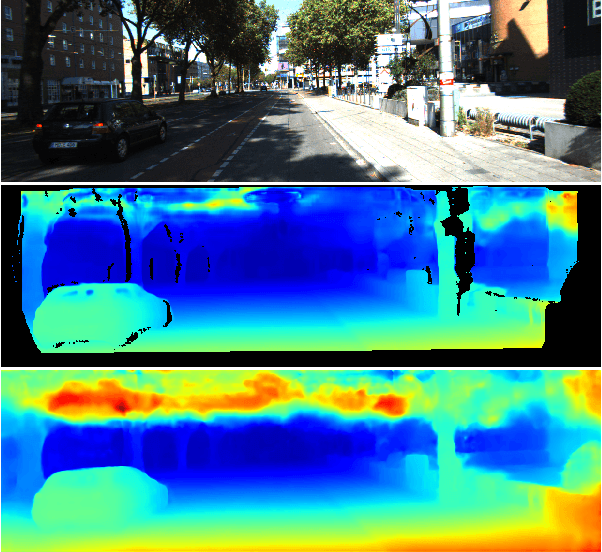
Contrary to the ongoing trend in automotive applications towards usage of more diverse and more sensors, this work tries to solve the complex scene flow problem under a monocular camera setup, i.e. using a single sensor. Towards this end, we exploit the latest achievements in single image depth estimation, optical flow, and sparse-to-dense interpolation and propose a monocular combination approach (MonoComb) to compute dense scene flow. MonoComb uses optical flow to relate reconstructed 3D positions over time and interpolates occluded areas. This way, existing monocular methods are outperformed in dynamic foreground regions which leads to the second best result among the competitors on the challenging KITTI 2015 scene flow benchmark.
Fusion of convolution neural network, support vector machine and Sobel filter for accurate detection of COVID-19 patients using X-ray images
Feb 13, 2021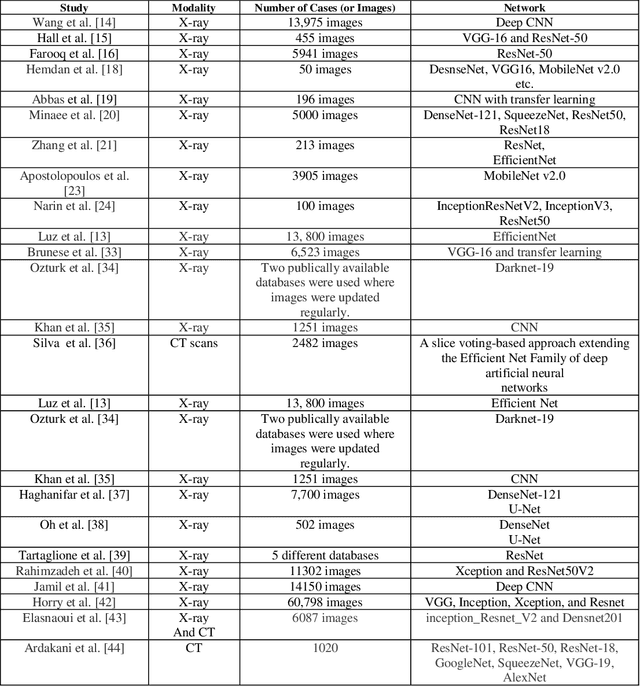
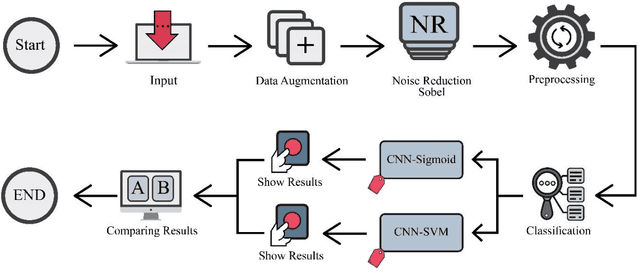
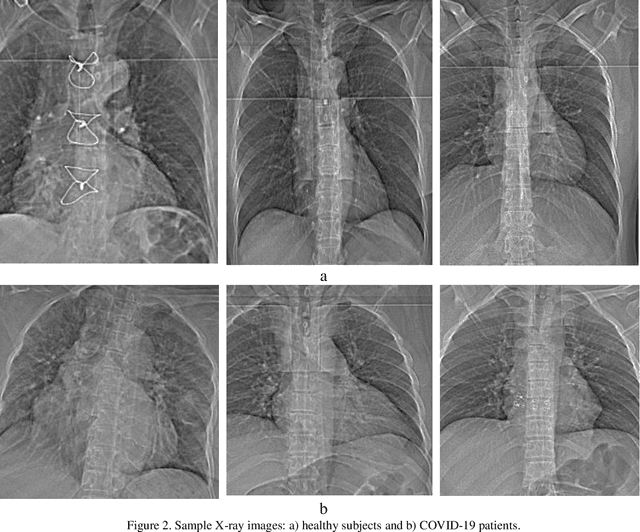
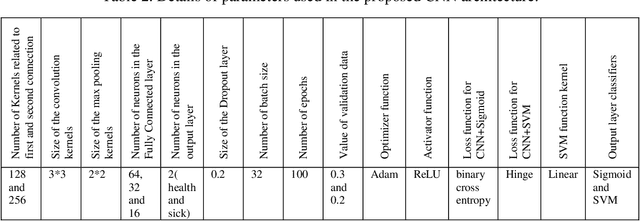
The coronavirus (COVID-19) is currently the most common contagious disease which is prevalent all over the world. The main challenge of this disease is the primary diagnosis to prevent secondary infections and its spread from one person to another. Therefore, it is essential to use an automatic diagnosis system along with clinical procedures for the rapid diagnosis of COVID-19 to prevent its spread. Artificial intelligence techniques using computed tomography (CT) images of the lungs and chest radiography have the potential to obtain high diagnostic performance for Covid-19 diagnosis. In this study, a fusion of convolutional neural network (CNN), support vector machine (SVM), and Sobel filter is proposed to detect COVID-19 using X-ray images. A new X-ray image dataset was collected and subjected to high pass filter using a Sobel filter to obtain the edges of the images. Then these images are fed to CNN deep learning model followed by SVM classifier with ten-fold cross validation strategy. This method is designed so that it can learn with not many data. Our results show that the proposed CNN-SVM with Sobel filtering (CNN-SVM+Sobel) achieved the highest classification accuracy of 99.02% in accurate detection of COVID-19. It showed that using Sobel filter can improve the performance of CNN. Unlike most of the other researches, this method does not use a pre-trained network. We have also validated our developed model using six public databases and obtained the highest performance. Hence, our developed model is ready for clinical application
CLAIRE: A distributed-memory solver for constrained large deformation diffeomorphic image registration
Aug 13, 2018
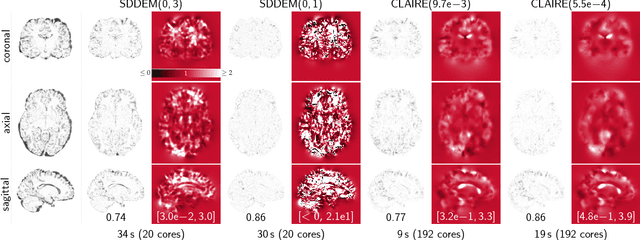

We introduce CLAIRE, a distributed-memory algorithm and software for solving constrained large deformation diffeomorphic image registration problems in three dimensions. We invert for a stationary velocity field that parameterizes the deformation map. Our solver is based on a globalized, preconditioned, inexact reduced space Gauss--Newton--Krylov scheme. We exploit state-of-the-art techniques in scientific computing to develop an effective solver that scales to thousand of distributed memory nodes on high-end clusters. Our improved, parallel implementation features parameter-, scale-, and grid-continuation schemes to speedup the computations and reduce the likelihood to get trapped in local minima. We also implement an improved preconditioner for the reduced space Hessian to speedup the convergence. We test registration performance on synthetic and real data. We demonstrate registration accuracy on 16 neuroimaging datasets. We compare the performance of our scheme against different flavors of the DEMONS algorithm for diffeomorphic image registration. We study convergence of our preconditioner and our overall algorithm. We report scalability results on state-of-the-art supercomputing platforms. We demonstrate that we can solve registration problems for clinically relevant data sizes in two to four minutes on a standard compute node with 20 cores, attaining excellent data fidelity. With the present work we achieve a speedup of (on average) 5x with a peak performance of up to 17x compared to our former work.
Noise Conscious Training of Non Local Neural Network powered by Self Attentive Spectral Normalized Markovian Patch GAN for Low Dose CT Denoising
Nov 11, 2020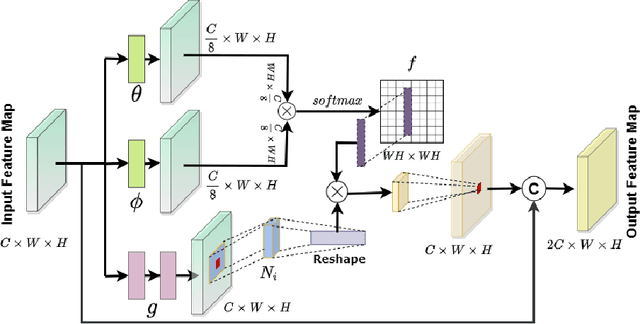
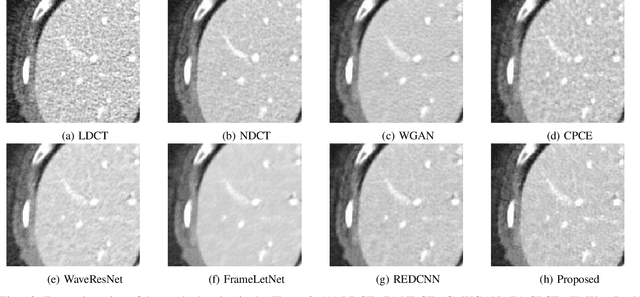
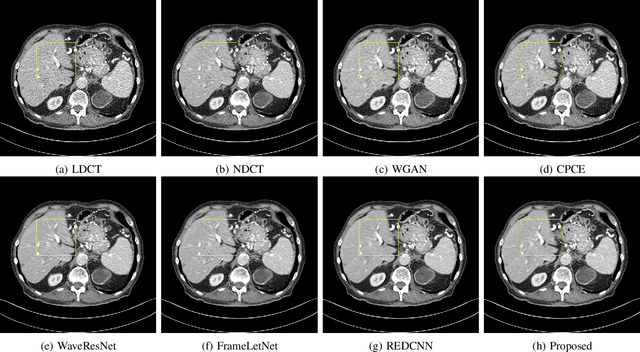
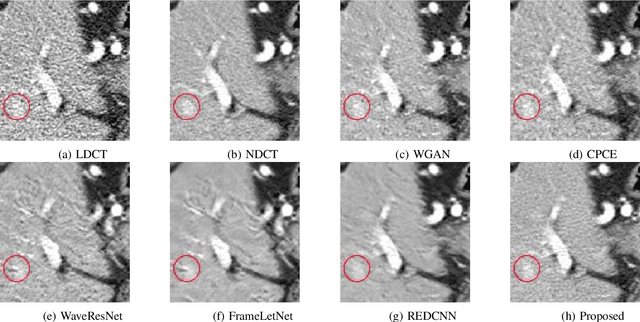
The explosive rise of the use of Computer tomography (CT) imaging in medical practice has heightened public concern over the patient's associated radiation dose. However, reducing the radiation dose leads to increased noise and artifacts, which adversely degrades the scan's interpretability. Consequently, an advanced image reconstruction algorithm to improve the diagnostic performance of low dose ct arose as the primary concern among the researchers, which is challenging due to the ill-posedness of the problem. In recent times, the deep learning-based technique has emerged as a dominant method for low dose CT(LDCT) denoising. However, some common bottleneck still exists, which hinders deep learning-based techniques from furnishing the best performance. In this study, we attempted to mitigate these problems with three novel accretions. First, we propose a novel convolutional module as the first attempt to utilize neighborhood similarity of CT images for denoising tasks. Our proposed module assisted in boosting the denoising by a significant margin. Next, we moved towards the problem of non-stationarity of CT noise and introduced a new noise aware mean square error loss for LDCT denoising. Moreover, the loss mentioned above also assisted to alleviate the laborious effort required while training CT denoising network using image patches. Lastly, we propose a novel discriminator function for CT denoising tasks. The conventional vanilla discriminator tends to overlook the fine structural details and focus on the global agreement. Our proposed discriminator leverage self-attention and pixel-wise GANs for restoring the diagnostic quality of LDCT images. Our method validated on a publicly available dataset of the 2016 NIH-AAPM-Mayo Clinic Low Dose CT Grand Challenge performed remarkably better than the existing state of the art method.
Combating Mode Collapse in GAN training: An Empirical Analysis using Hessian Eigenvalues
Dec 17, 2020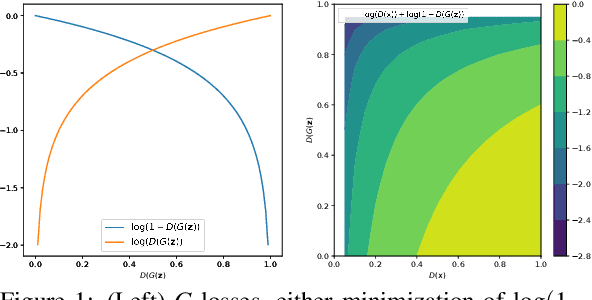
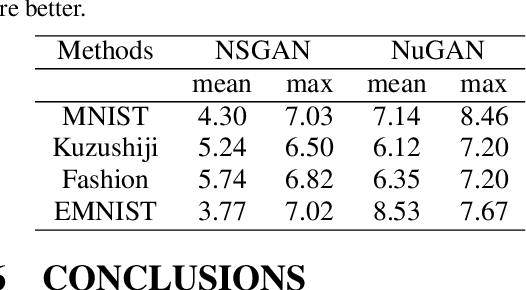
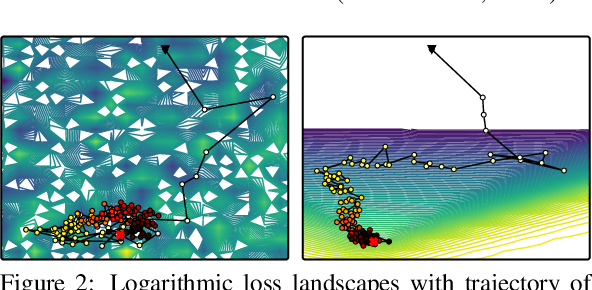
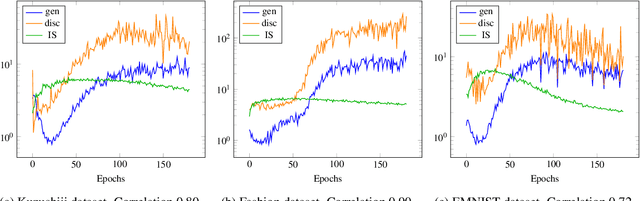
Generative adversarial networks (GANs) provide state-of-the-art results in image generation. However, despite being so powerful, they still remain very challenging to train. This is in particular caused by their highly non-convex optimization space leading to a number of instabilities. Among them, mode collapse stands out as one of the most daunting ones. This undesirable event occurs when the model can only fit a few modes of the data distribution, while ignoring the majority of them. In this work, we combat mode collapse using second-order gradient information. To do so, we analyse the loss surface through its Hessian eigenvalues, and show that mode collapse is related to the convergence towards sharp minima. In particular, we observe how the eigenvalues of the $G$ are directly correlated with the occurrence of mode collapse. Finally, motivated by these findings, we design a new optimization algorithm called nudged-Adam (NuGAN) that uses spectral information to overcome mode collapse, leading to empirically more stable convergence properties.
Firearm Detection via Convolutional Neural Networks: Comparing a Semantic Segmentation Model Against End-to-End Solutions
Dec 17, 2020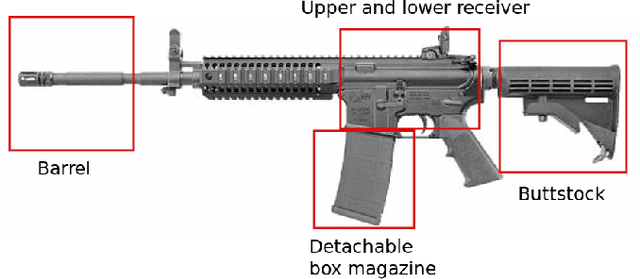
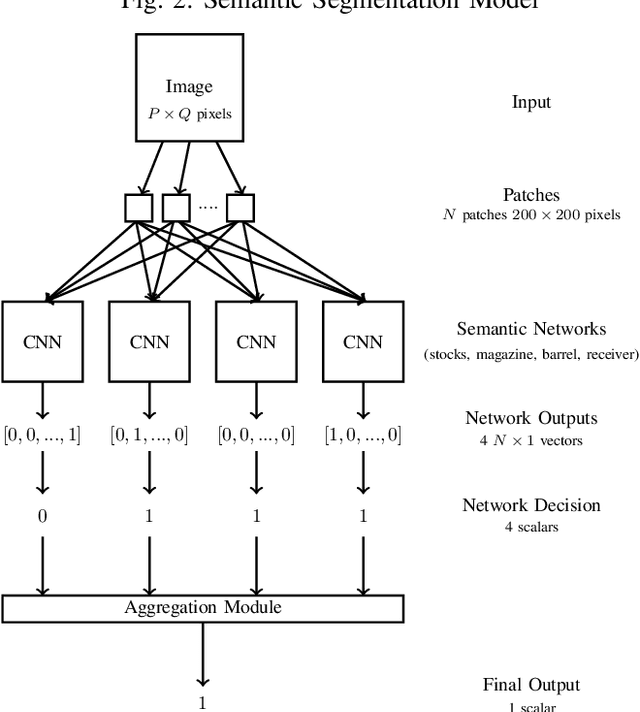
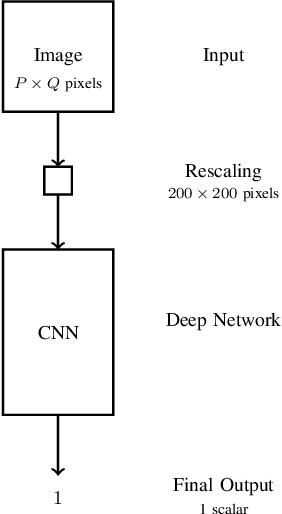

Threat detection of weapons and aggressive behavior from live video can be used for rapid detection and prevention of potentially deadly incidents such as terrorism, general criminal offences, or even domestic violence. One way for achieving this is through the use of artificial intelligence and, in particular, machine learning for image analysis. In this paper we conduct a comparison between a traditional monolithic end-to-end deep learning model and a previously proposed model based on an ensemble of simpler neural networks detecting fire-weapons via semantic segmentation. We evaluated both models from different points of view, including accuracy, computational and data complexity, flexibility and reliability. Our results show that a semantic segmentation model provides considerable amount of flexibility and resilience in the low data environment compared to classical deep model models, although its configuration and tuning presents a challenge in achieving the same levels of accuracy as an end-to-end model.
Predicting How to Distribute Work Between Algorithms and Humans to Segment an Image Batch
Apr 30, 2019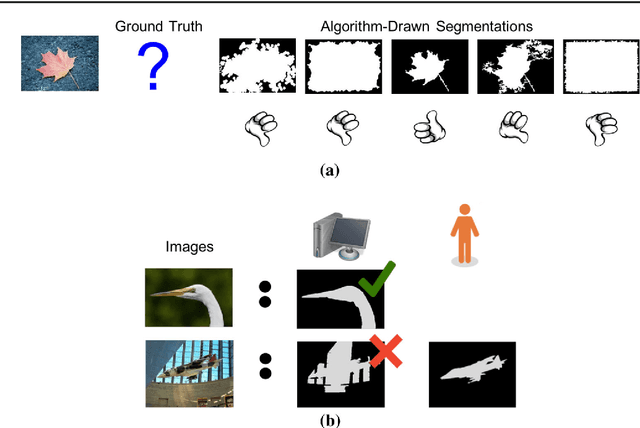
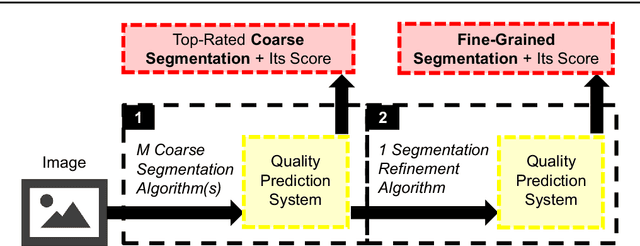

Foreground object segmentation is a critical step for many image analysis tasks. While automated methods can produce high-quality results, their failures disappoint users in need of practical solutions. We propose a resource allocation framework for predicting how best to allocate a fixed budget of human annotation effort in order to collect higher quality segmentations for a given batch of images and automated methods. The framework is based on a prediction module that estimates the quality of given algorithm-drawn segmentations. We demonstrate the value of the framework for two novel tasks related to predicting how to distribute annotation efforts between algorithms and humans. Specifically, we develop two systems that automatically decide, for a batch of images, when to recruit humans versus computers to create 1) coarse segmentations required to initialize segmentation tools and 2) final, fine-grained segmentations. Experiments demonstrate the advantage of relying on a mix of human and computer efforts over relying on either resource alone for segmenting objects in images coming from three diverse modalities (visible, phase contrast microscopy, and fluorescence microscopy).