 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Novel Domain Adaptation Framework for Medical Image Segmentation
Oct 11, 2018
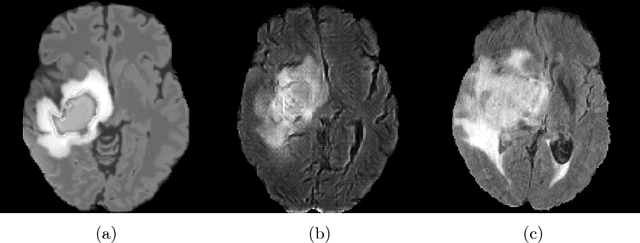
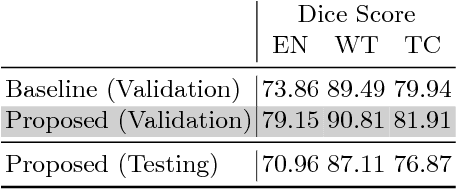
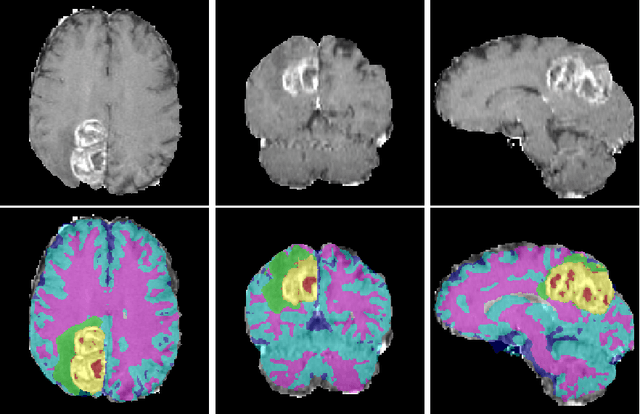
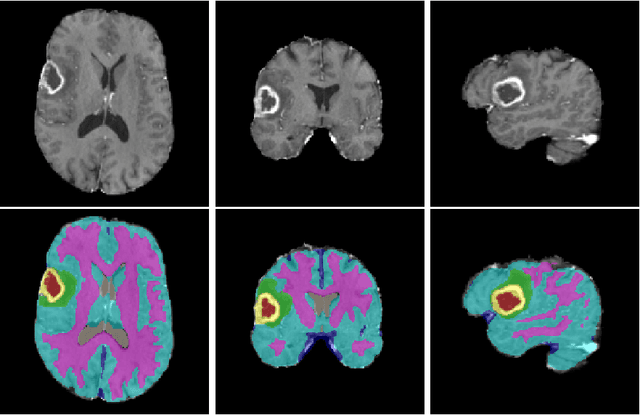
We propose a segmentation framework that uses deep neural networks and introduce two innovations. First, we describe a biophysics-based domain adaptation method. Second, we propose an automatic method to segment white and gray matter, and cerebrospinal fluid, in addition to tumorous tissue. Regarding our first innovation, we use a domain adaptation framework that combines a novel multispecies biophysical tumor growth model with a generative adversarial model to create realistic looking synthetic multimodal MR images with known segmentation. Regarding our second innovation, we propose an automatic approach to enrich available segmentation data by computing the segmentation for healthy tissues. This segmentation, which is done using diffeomorphic image registration between the BraTS training data and a set of prelabeled atlases, provides more information for training and reduces the class imbalance problem. Our overall approach is not specific to any particular neural network and can be used in conjunction with existing solutions. We demonstrate the performance improvement using a 2D U-Net for the BraTS'18 segmentation challenge. Our biophysics based domain adaptation achieves better results, as compared to the existing state-of-the-art GAN model used to create synthetic data for training.
Refining Image Categorization by Exploiting Web Images and General Corpus
Mar 16, 2017
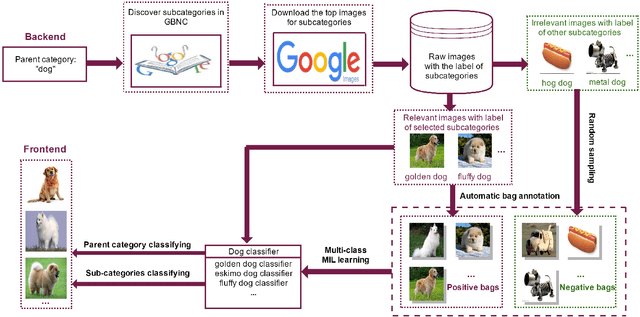
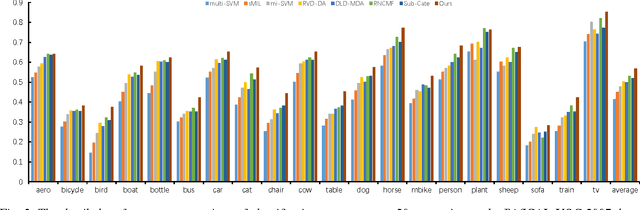
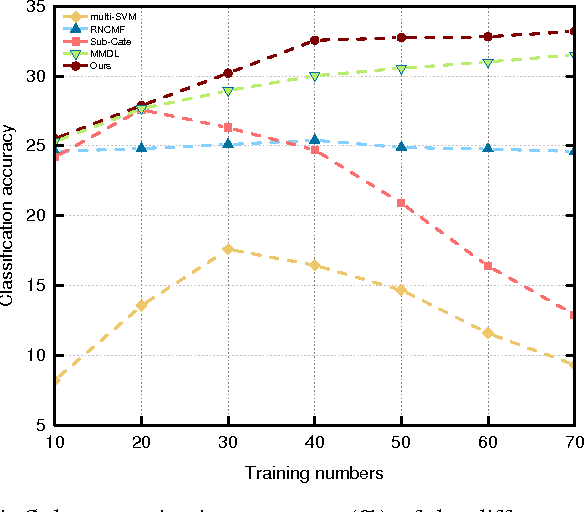
Studies show that refining real-world categories into semantic subcategories contributes to better image modeling and classification. Previous image sub-categorization work relying on labeled images and WordNet's hierarchy is not only labor-intensive, but also restricted to classify images into NOUN subcategories. To tackle these problems, in this work, we exploit general corpus information to automatically select and subsequently classify web images into semantic rich (sub-)categories. The following two major challenges are well studied: 1) noise in the labels of subcategories derived from the general corpus; 2) noise in the labels of images retrieved from the web. Specifically, we first obtain the semantic refinement subcategories from the text perspective and remove the noise by the relevance-based approach. To suppress the search error induced noisy images, we then formulate image selection and classifier learning as a multi-class multi-instance learning problem and propose to solve the employed problem by the cutting-plane algorithm. The experiments show significant performance gains by using the generated data of our way on both image categorization and sub-categorization tasks. The proposed approach also consistently outperforms existing weakly supervised and web-supervised approaches.
Towards an Automated Image De-fencing Algorithm Using Sparsity
Dec 10, 2016

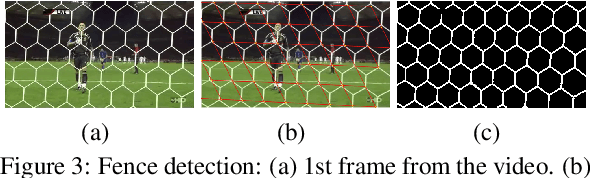

Conventional approaches to image de-fencing suffer from non-robust fence detection and are limited to processing images of static scenes. In this position paper, we propose an automatic de-fencing algorithm for images of dynamic scenes. We divide the problem of image de-fencing into the tasks of automated fence detection, motion estimation and fusion of data from multiple frames of a captured video of the dynamic scene. Fences are detected automatically using two approaches, namely, employing Gabor filter and a machine learning method. We cast the fence removal problem in an optimization framework, by modeling the formation of the degraded observations. The inverse problem is solved using split Bregman technique assuming total variation of the de-fenced image as the regularization constraint.
An Efficient Generation Method based on Dynamic Curvature of the Reference Curve for Robust Trajectory Planning
Dec 29, 2020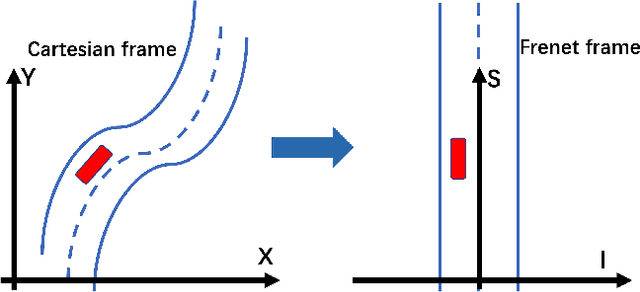
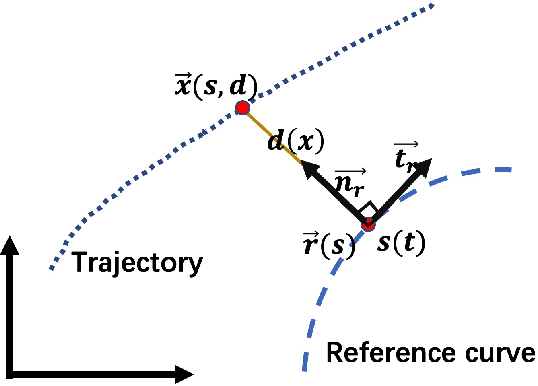
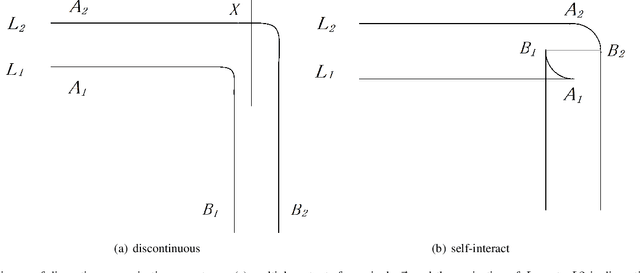
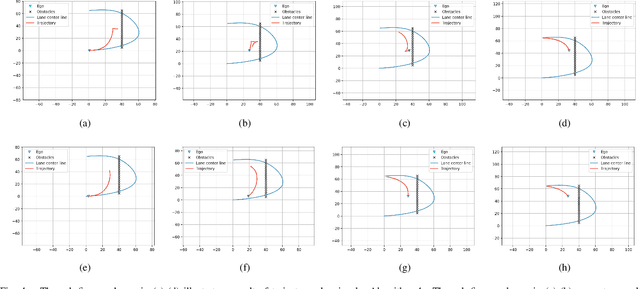
Trajectory planning is a fundamental task on various autonomous driving platforms, such as social robotics and self-driving cars. Many trajectory planning algorithms use a reference curve based Frenet frame with time to reduce the planning dimension. However, there is a common implicit assumption in classic trajectory planning approaches, which is that the generated trajectory should follow the reference curve continuously. This assumption is not always true in real applications and it might cause some undesired issues in planning. One issue is that the projection of the planned trajectory onto the reference curve maybe discontinuous. Then, some segments on the reference curve are not the image of any part of the planned path. Another issue is that the planned path might self-intersect when following a simple reference curve continuously. The generated trajectories are unnatural and suboptimal ones when these issues happen. In this paper, we firstly demonstrate these issues and then introduce an efficient trajectory generation method which uses a new transformation from the Cartesian frame to Frenet frames. Experimental results on a simulated street scenario demonstrated the effectiveness of the proposed method.
AU-Guided Unsupervised Domain Adaptive Facial Expression Recognition
Dec 18, 2020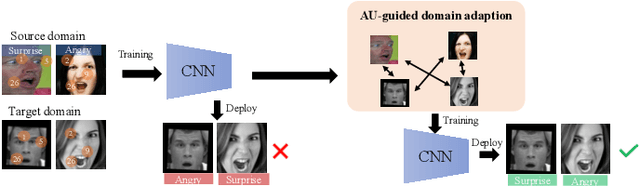
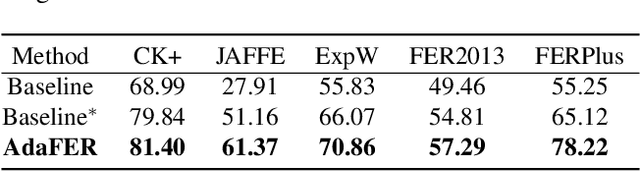
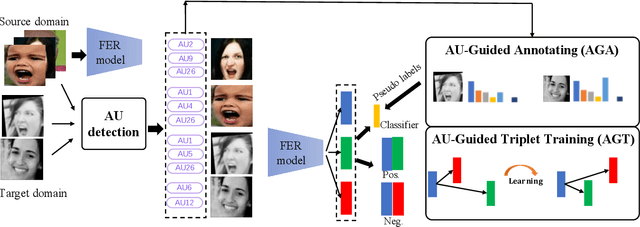
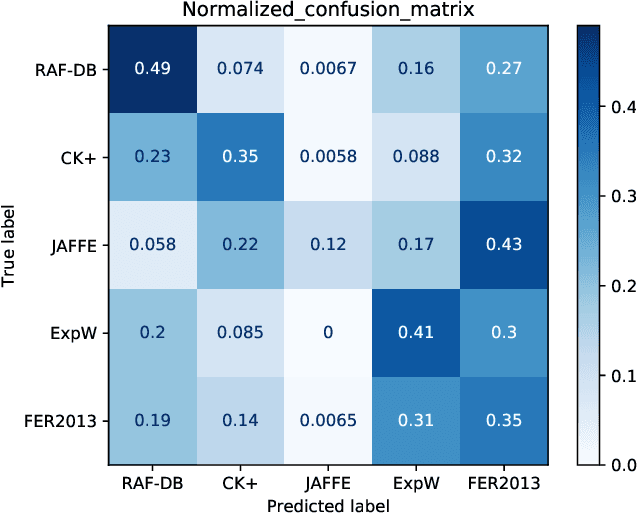
The domain diversities including inconsistent annotation and varied image collection conditions inevitably exist among different facial expression recognition (FER) datasets, which pose an evident challenge for adapting the FER model trained on one dataset to another one. Recent works mainly focus on domain-invariant deep feature learning with adversarial learning mechanism, ignoring the sibling facial action unit (AU) detection task which has obtained great progress. Considering AUs objectively determine facial expressions, this paper proposes an AU-guided unsupervised Domain Adaptive FER (AdaFER) framework. In AdaFER, we first leverage an advanced model for AU detection on both source and target domain. Then, we compare the AU results to perform AU-guided annotating, i.e., target faces that own the same AUs with source faces would inherit the labels from source domain. Meanwhile, to achieve domain-invariant compact features, we utilize an AU-guided triplet training which randomly collects anchor-positive-negative triplets on both domains with AUs. We conduct extensive experiments on several popular benchmarks and show that AdaFER achieves state-of-the-art results on all the benchmarks.
Online Adaptation for Consistent Mesh Reconstruction in the Wild
Dec 06, 2020

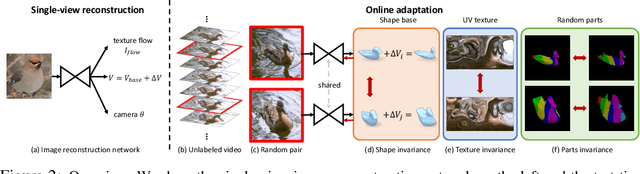
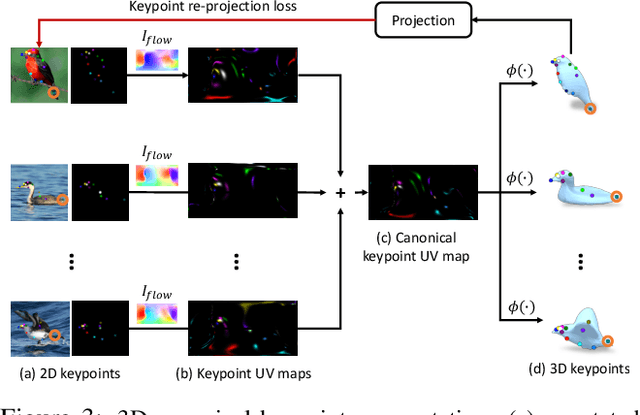
This paper presents an algorithm to reconstruct temporally consistent 3D meshes of deformable object instances from videos in the wild. Without requiring annotations of 3D mesh, 2D keypoints, or camera pose for each video frame, we pose video-based reconstruction as a self-supervised online adaptation problem applied to any incoming test video. We first learn a category-specific 3D reconstruction model from a collection of single-view images of the same category that jointly predicts the shape, texture, and camera pose of an image. Then, at inference time, we adapt the model to a test video over time using self-supervised regularization terms that exploit temporal consistency of an object instance to enforce that all reconstructed meshes share a common texture map, a base shape, as well as parts. We demonstrate that our algorithm recovers temporally consistent and reliable 3D structures from videos of non-rigid objects including those of animals captured in the wild -- an extremely challenging task rarely addressed before.
Multi-frequency image reconstruction for radio-interferometry with self-tuned regularization parameters
Mar 10, 2017
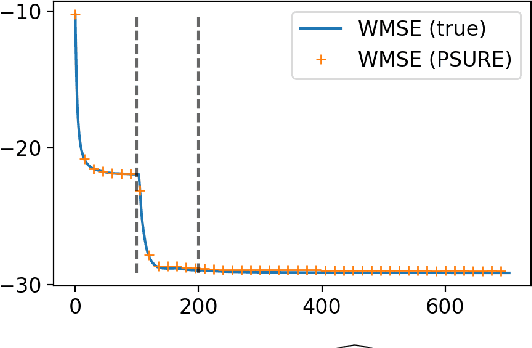
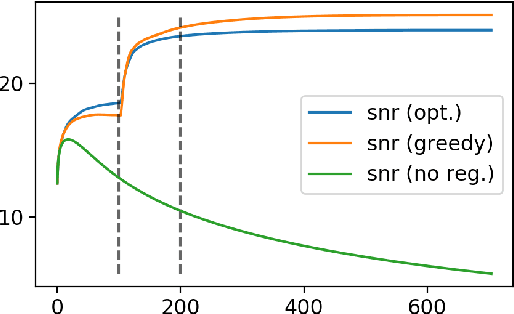
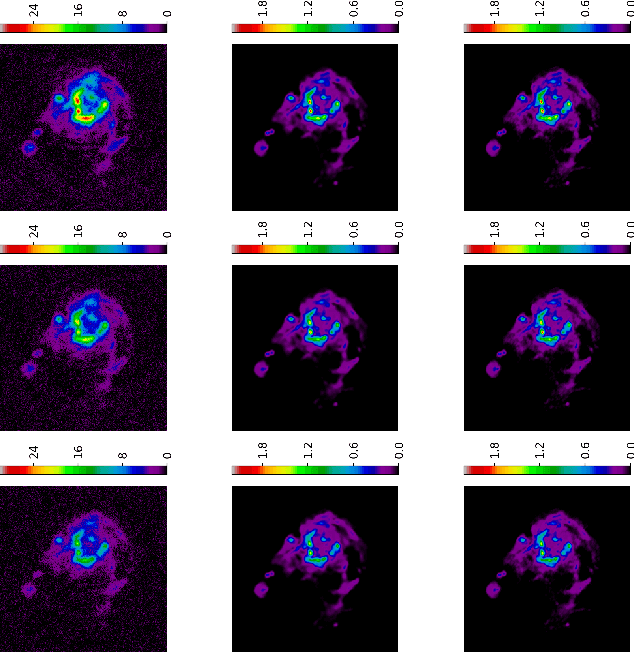
As the world's largest radio telescope, the Square Kilometer Array (SKA) will provide radio interferometric data with unprecedented detail. Image reconstruction algorithms for radio interferometry are challenged to scale well with TeraByte image sizes never seen before. In this work, we investigate one such 3D image reconstruction algorithm known as MUFFIN (MUlti-Frequency image reconstruction For radio INterferometry). In particular, we focus on the challenging task of automatically finding the optimal regularization parameter values. In practice, finding the regularization parameters using classical grid search is computationally intensive and nontrivial due to the lack of ground- truth. We adopt a greedy strategy where, at each iteration, the optimal parameters are found by minimizing the predicted Stein unbiased risk estimate (PSURE). The proposed self-tuned version of MUFFIN involves parallel and computationally efficient steps, and scales well with large- scale data. Finally, numerical results on a 3D image are presented to showcase the performance of the proposed approach.
PerSIM: Multi-resolution Image Quality Assessment in the Perceptually Uniform Color Domain
Nov 18, 2018
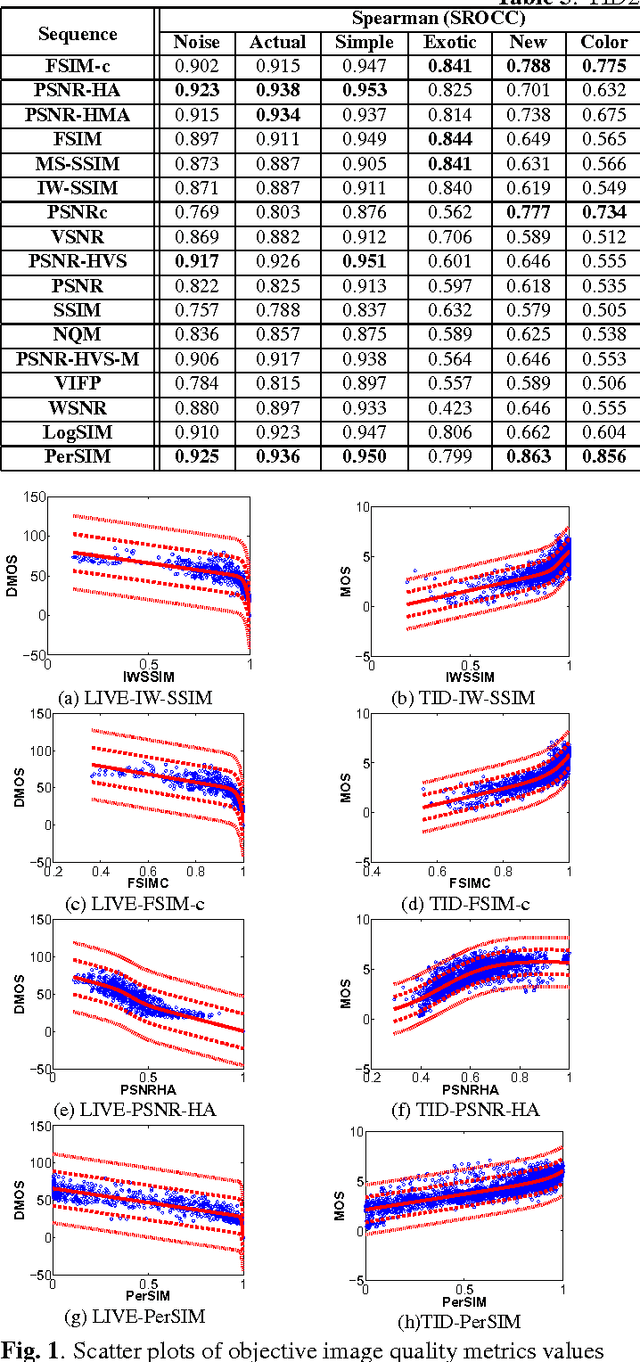
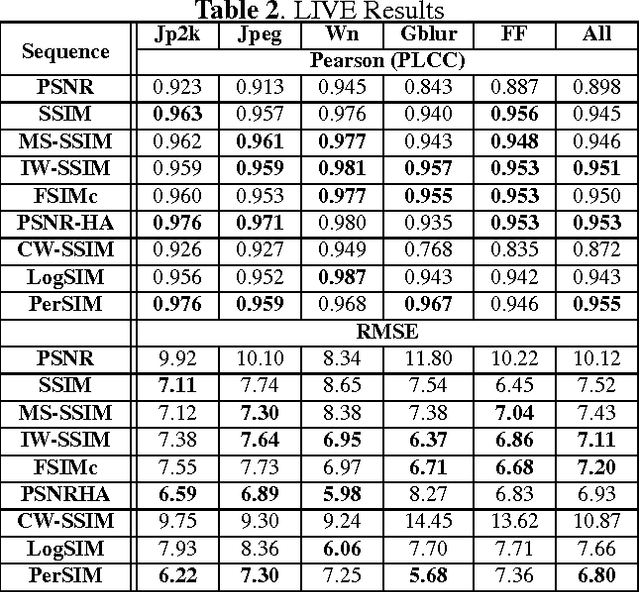
An average observer perceives the world in color instead of black and white. Moreover, the visual system focuses on structures and segments instead of individual pixels. Based on these observations, we propose a full reference objective image quality metric modeling visual system characteristics and chroma similarity in the perceptually uniform color domain (Lab). Laplacian of Gaussian features are obtained in the L channel to model the retinal ganglion cells in human visual system and color similarity is calculated over the a and b channels. In the proposed perceptual similarity index (PerSIM), a multi-resolution approach is followed to mimic the hierarchical nature of human visual system. LIVE and TID2013 databases are used in the validation and PerSIM outperforms all the compared metrics in the overall databases in terms of ranking, monotonic behavior and linearity.
* 5 pages, 1 figure, 3 tables
Anatomy-Aware Siamese Network: Exploiting Semantic Asymmetry for Accurate Pelvic Fracture Detection in X-ray Images
Jul 03, 2020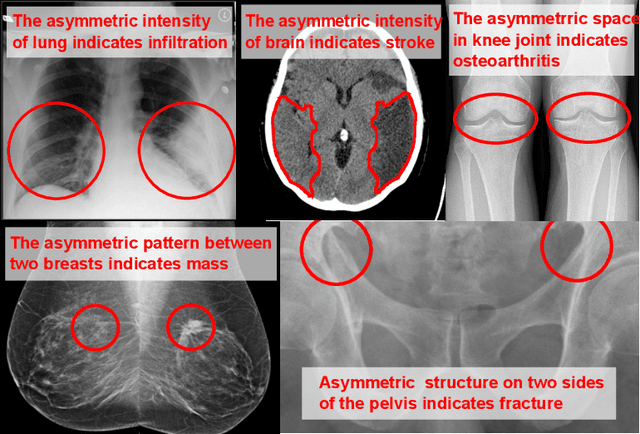
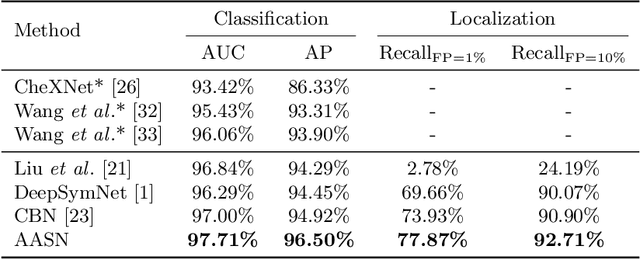
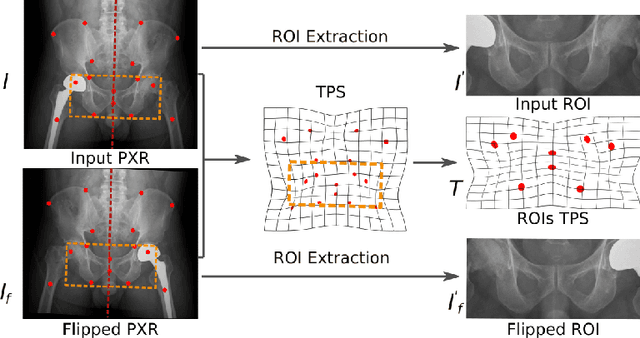
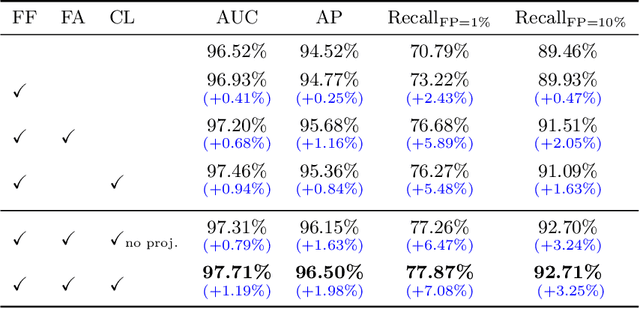
Visual cues of enforcing bilaterally symmetric anatomies as normal findings are widely used in clinical practice to disambiguate subtle abnormalities from medical images. So far, inadequate research attention has been received on effectively emulating this practice in CAD methods. In this work, we exploit semantic anatomical symmetry or asymmetry analysis in a complex CAD scenario, i.e., anterior pelvic fracture detection in trauma PXRs, where semantically pathological (refer to as fracture) and non-pathological (e.g., pose) asymmetries both occur. Visually subtle yet pathologically critical fracture sites can be missed even by experienced clinicians, when limited diagnosis time is permitted in emergency care. We propose a novel fracture detection framework that builds upon a Siamese network enhanced with a spatial transformer layer to holistically analyze symmetric image features. Image features are spatially formatted to encode bilaterally symmetric anatomies. A new contrastive feature learning component in our Siamese network is designed to optimize the deep image features being more salient corresponding to the underlying semantic asymmetries (caused by pelvic fracture occurrences). Our proposed method have been extensively evaluated on 2,359 PXRs from unique patients (the largest study to-date), and report an area under ROC curve score of 0.9771. This is the highest among state-of-the-art fracture detection methods, with improved clinical indications.
MAD-VAE: Manifold Awareness Defense Variational Autoencoder
Oct 31, 2020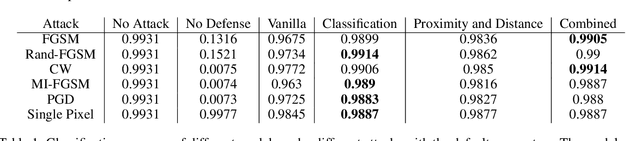


Although deep generative models such as Defense-GAN and Defense-VAE have made significant progress in terms of adversarial defenses of image classification neural networks, several methods have been found to circumvent these defenses. Based on Defense-VAE, in our research we introduce several methods to improve the robustness of defense models. The methods introduced in this paper are straight forward yet show promise over the vanilla Defense-VAE. With extensive experiments on MNIST data set, we have demonstrated the effectiveness of our algorithms against different attacks. Our experiments also include attacks on the latent space of the defensive model. We also discuss the applicability of existing adversarial latent space attacks as they may have a significant flaw.