 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Multi-Label Image Classification with Regional Latent Semantic Dependencies
Mar 12, 2017
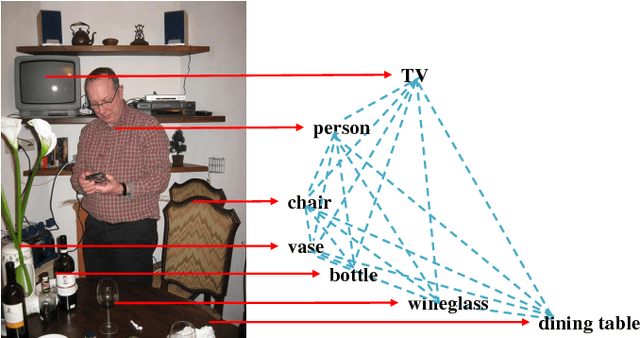
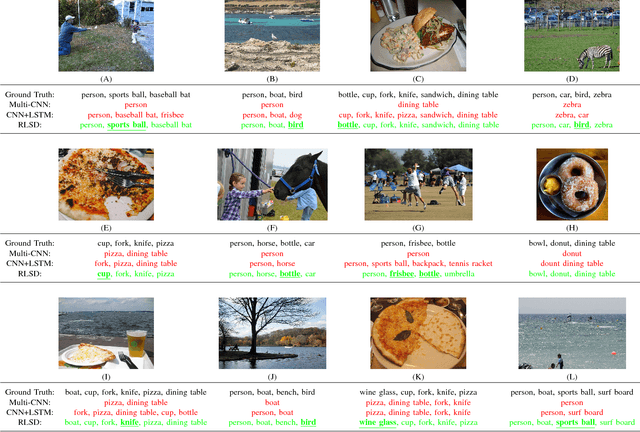

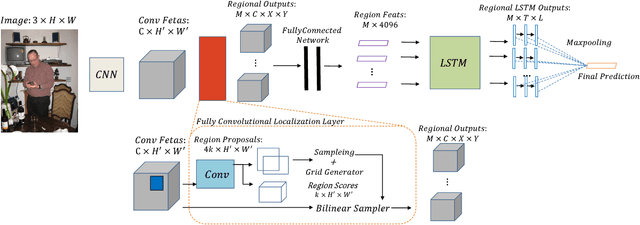
Deep convolution neural networks (CNN) have demonstrated advanced performance on single-label image classification, and various progress also have been made to apply CNN methods on multi-label image classification, which requires to annotate objects, attributes, scene categories etc. in a single shot. Recent state-of-the-art approaches to multi-label image classification exploit the label dependencies in an image, at global level, largely improving the labeling capacity. However, predicting small objects and visual concepts is still challenging due to the limited discrimination of the global visual features. In this paper, we propose a Regional Latent Semantic Dependencies model (RLSD) to address this problem. The utilized model includes a fully convolutional localization architecture to localize the regions that may contain multiple highly-dependent labels. The localized regions are further sent to the recurrent neural networks (RNN) to characterize the latent semantic dependencies at the regional level. Experimental results on several benchmark datasets show that our proposed model achieves the best performance compared to the state-of-the-art models, especially for predicting small objects occurred in the images. In addition, we set up an upper bound model (RLSD+ft-RPN) using bounding box coordinates during training, the experimental results also show that our RLSD can approach the upper bound without using the bounding-box annotations, which is more realistic in the real world.
Unsupervised Object Keypoint Learning using Local Spatial Predictability
Nov 25, 2020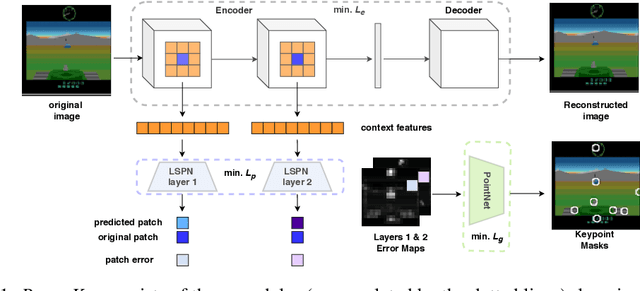
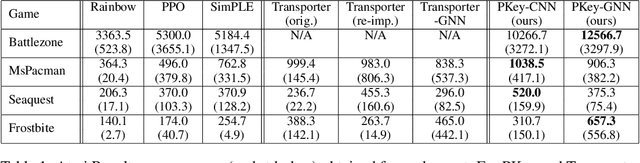

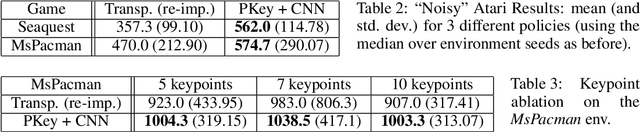
We propose PermaKey, a novel approach to representation learning based on object keypoints. It leverages the predictability of local image regions from spatial neighborhoods to identify salient regions that correspond to object parts, which are then converted to keypoints. Unlike prior approaches, it utilizes predictability to discover object keypoints, an intrinsic property of objects. This ensures that it does not overly bias keypoints to focus on characteristics that are not unique to objects, such as movement, shape, colour etc. We demonstrate the efficacy of PermaKey on Atari where it learns keypoints corresponding to the most salient object parts and is robust to certain visual distractors. Further, on downstream RL tasks in the Atari domain we demonstrate how agents equipped with our keypoints outperform those using competing alternatives, even on challenging environments with moving backgrounds or distractor objects.
Discriminatively Boosted Image Clustering with Fully Convolutional Auto-Encoders
Mar 23, 2017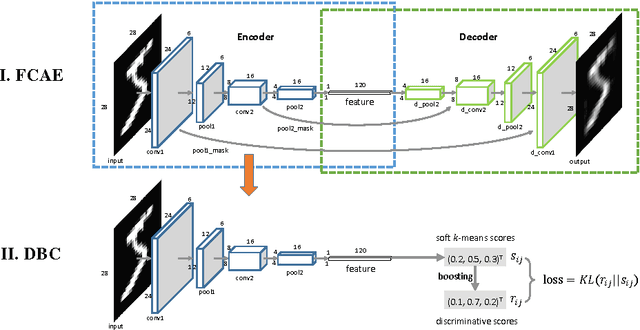

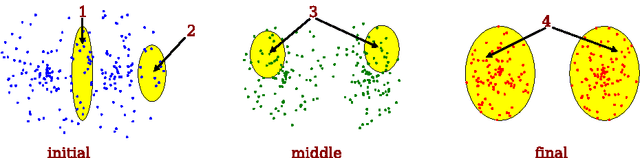
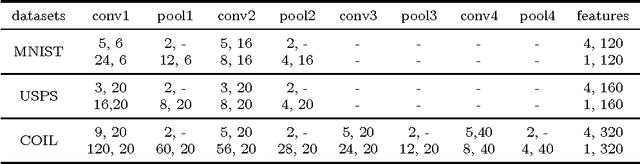
Traditional image clustering methods take a two-step approach, feature learning and clustering, sequentially. However, recent research results demonstrated that combining the separated phases in a unified framework and training them jointly can achieve a better performance. In this paper, we first introduce fully convolutional auto-encoders for image feature learning and then propose a unified clustering framework to learn image representations and cluster centers jointly based on a fully convolutional auto-encoder and soft $k$-means scores. At initial stages of the learning procedure, the representations extracted from the auto-encoder may not be very discriminative for latter clustering. We address this issue by adopting a boosted discriminative distribution, where high score assignments are highlighted and low score ones are de-emphasized. With the gradually boosted discrimination, clustering assignment scores are discriminated and cluster purities are enlarged. Experiments on several vision benchmark datasets show that our methods can achieve a state-of-the-art performance.
Object-Part Attention Model for Fine-grained Image Classification
Sep 25, 2017
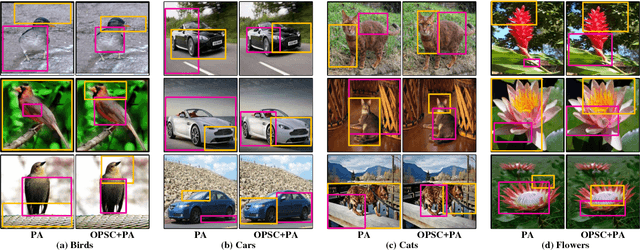

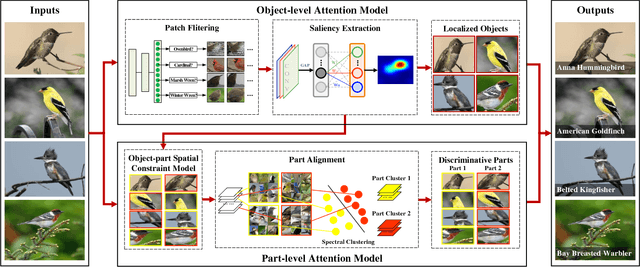
Fine-grained image classification is to recognize hundreds of subcategories belonging to the same basic-level category, such as 200 subcategories belonging to the bird, which is highly challenging due to large variance in the same subcategory and small variance among different subcategories. Existing methods generally first locate the objects or parts and then discriminate which subcategory the image belongs to. However, they mainly have two limitations: (1) Relying on object or part annotations which are heavily labor consuming. (2) Ignoring the spatial relationships between the object and its parts as well as among these parts, both of which are significantly helpful for finding discriminative parts. Therefore, this paper proposes the object-part attention model (OPAM) for weakly supervised fine-grained image classification, and the main novelties are: (1) Object-part attention model integrates two level attentions: object-level attention localizes objects of images, and part-level attention selects discriminative parts of object. Both are jointly employed to learn multi-view and multi-scale features to enhance their mutual promotions. (2) Object-part spatial constraint model combines two spatial constraints: object spatial constraint ensures selected parts highly representative, and part spatial constraint eliminates redundancy and enhances discrimination of selected parts. Both are jointly employed to exploit the subtle and local differences for distinguishing the subcategories. Importantly, neither object nor part annotations are used in our proposed approach, which avoids the heavy labor consumption of labeling. Comparing with more than 10 state-of-the-art methods on 4 widely-used datasets, our OPAM approach achieves the best performance.
GMM-Based Generative Adversarial Encoder Learning
Dec 08, 2020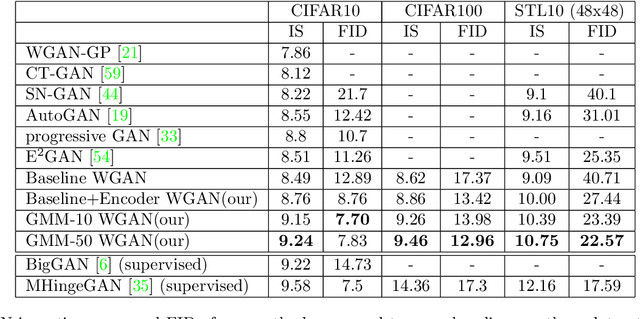
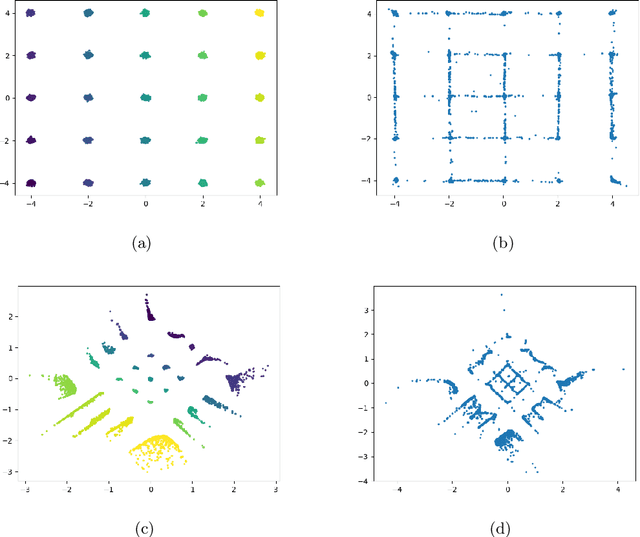
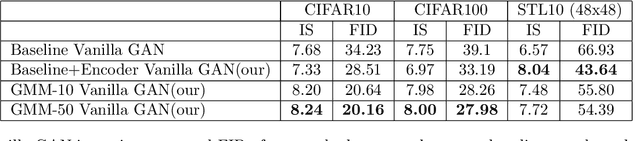
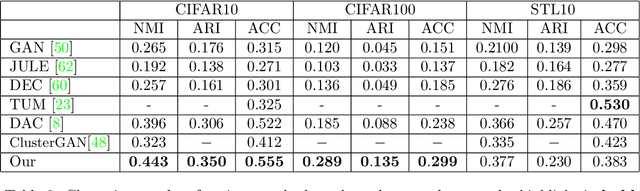
While GAN is a powerful model for generating images, its inability to infer a latent space directly limits its use in applications requiring an encoder. Our paper presents a simple architectural setup that combines the generative capabilities of GAN with an encoder. We accomplish this by combining the encoder with the discriminator using shared weights, then training them simultaneously using a new loss term. We model the output of the encoder latent space via a GMM, which leads to both good clustering using this latent space and improved image generation by the GAN. Our framework is generic and can be easily plugged into any GAN strategy. In particular, we demonstrate it both with Vanilla GAN and Wasserstein GAN, where in both it leads to an improvement in the generated images in terms of both the IS and FID scores. Moreover, we show that our encoder learns a meaningful representation as its clustering results are competitive with the current GAN-based state-of-the-art in clustering.
A Feature Analysis for Multimodal News Retrieval
Jul 13, 2020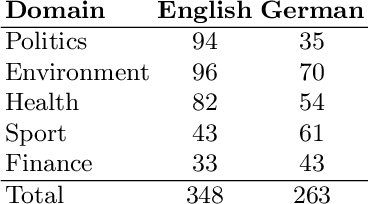

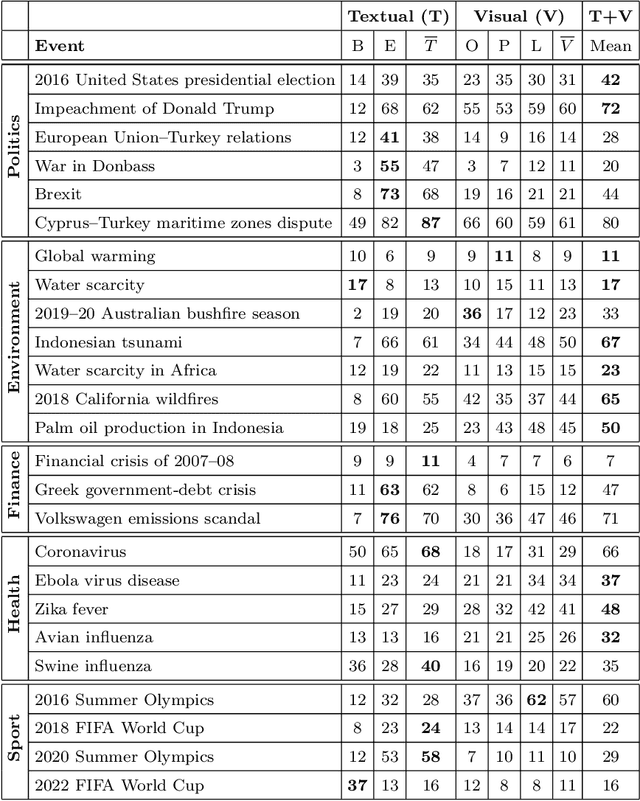
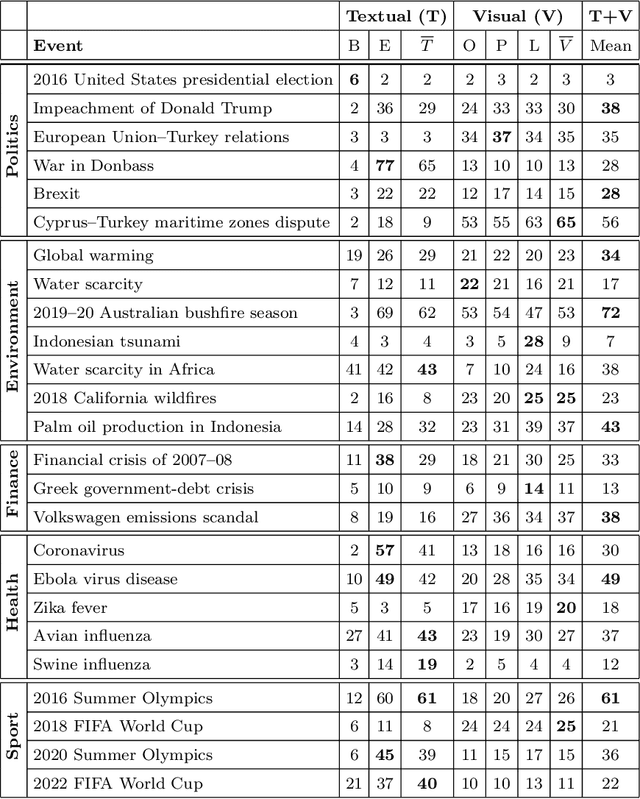
Content-based information retrieval is based on the information contained in documents rather than using metadata such as keywords. Most information retrieval methods are either based on text or image. In this paper, we investigate the usefulness of multimodal features for cross-lingual news search in various domains: politics, health, environment, sport, and finance. To this end, we consider five feature types for image and text and compare the performance of the retrieval system using different combinations. Experimental results show that retrieval results can be improved when considering both visual and textual information. In addition, it is observed that among textual features entity overlap outperforms word embeddings, while geolocation embeddings achieve better performance among visual features in the retrieval task.
Context Aware Query Image Representation for Particular Object Retrieval
Mar 03, 2017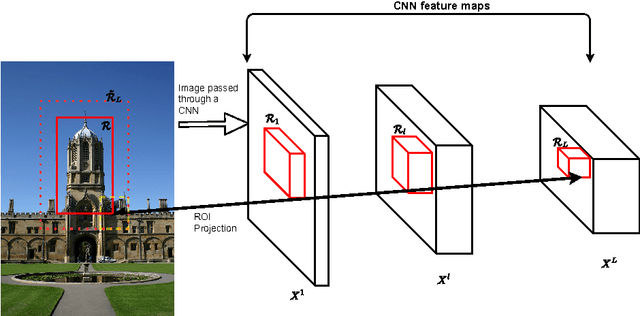

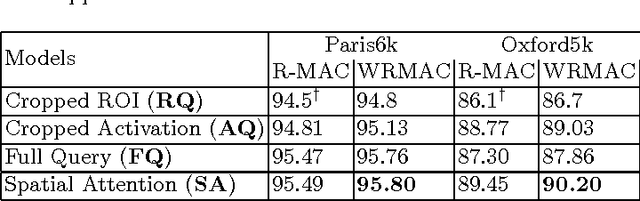
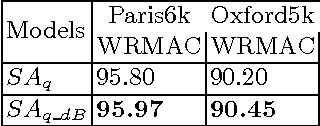
The current models of image representation based on Convolutional Neural Networks (CNN) have shown tremendous performance in image retrieval. Such models are inspired by the information flow along the visual pathway in the human visual cortex. We propose that in the field of particular object retrieval, the process of extracting CNN representations from query images with a given region of interest (ROI) can also be modelled by taking inspiration from human vision. Particularly, we show that by making the CNN pay attention on the ROI while extracting query image representation leads to significant improvement over the baseline methods on challenging Oxford5k and Paris6k datasets. Furthermore, we propose an extension to a recently introduced encoding method for CNN representations, regional maximum activations of convolutions (R-MAC). The proposed extension weights the regional representations using a novel saliency measure prior to aggregation. This leads to further improvement in retrieval accuracy.
Multiple VLAD encoding of CNNs for image classification
Jun 30, 2017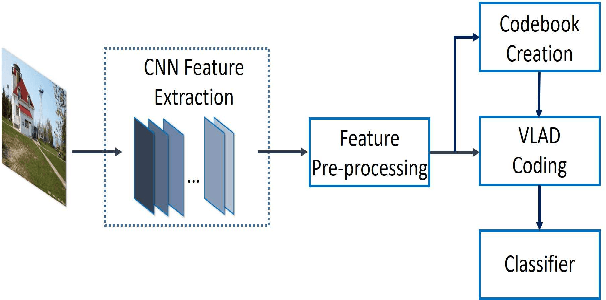
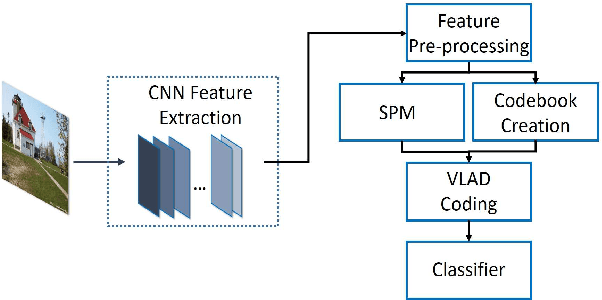


Despite the effectiveness of convolutional neural networks (CNNs) especially in image classification tasks, the effect of convolution features on learned representations is still limited. It mostly focuses on the salient object of the images, but ignores the variation information on clutter and local. In this paper, we propose a special framework, which is the multiple VLAD encoding method with the CNNs features for image classification. Furthermore, in order to improve the performance of the VLAD coding method, we explore the multiplicity of VLAD encoding with the extension of three kinds of encoding algorithms, which are the VLAD-SA method, the VLAD-LSA and the VLAD-LLC method. Finally, we equip the spatial pyramid patch (SPM) on VLAD encoding to add the spatial information of CNNs feature. In particular, the power of SPM leads our framework to yield better performance compared to the existing method.
Kernel Two-Dimensional Ridge Regression for Subspace Clustering
Nov 03, 2020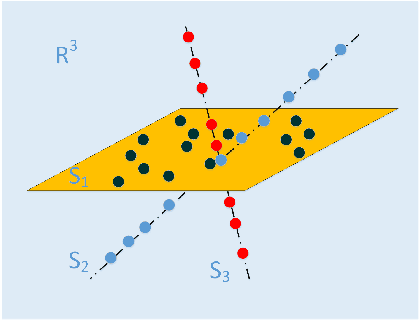


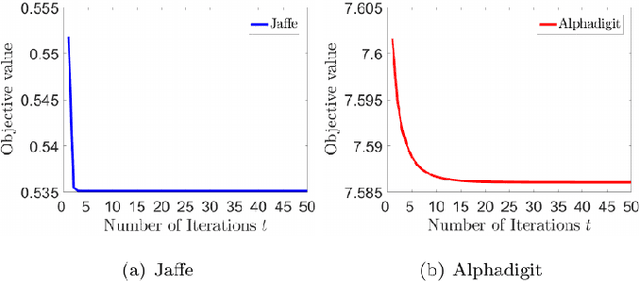
Subspace clustering methods have been widely studied recently. When the inputs are 2-dimensional (2D) data, existing subspace clustering methods usually convert them into vectors, which severely damages inherent structures and relationships from original data. In this paper, we propose a novel subspace clustering method for 2D data. It directly uses 2D data as inputs such that the learning of representations benefits from inherent structures and relationships of the data. It simultaneously seeks image projection and representation coefficients such that they mutually enhance each other and lead to powerful data representations. An efficient algorithm is developed to solve the proposed objective function with provable decreasing and convergence property. Extensive experimental results verify the effectiveness of the new method.
StacMR: Scene-Text Aware Cross-Modal Retrieval
Dec 08, 2020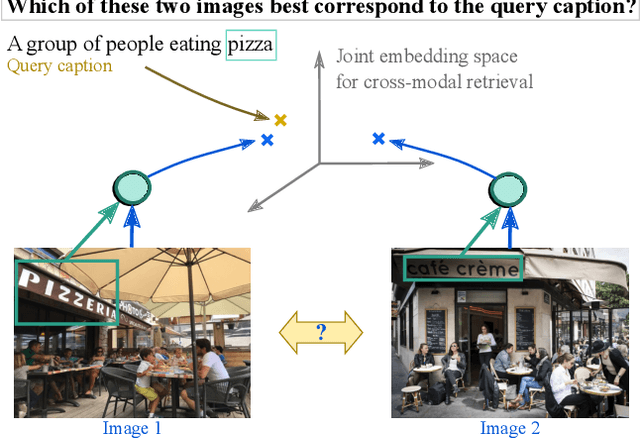

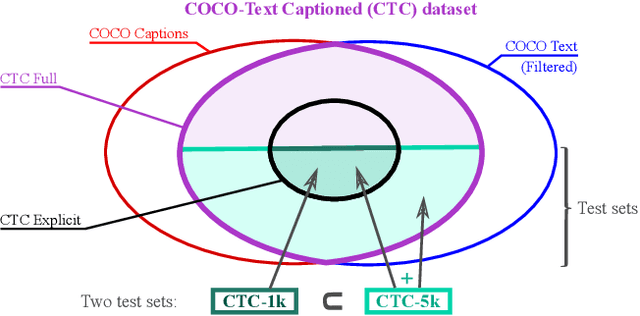
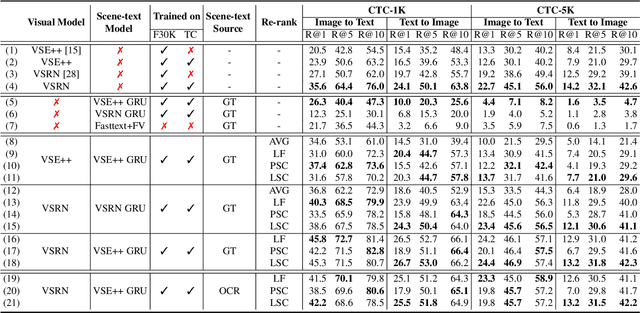
Recent models for cross-modal retrieval have benefited from an increasingly rich understanding of visual scenes, afforded by scene graphs and object interactions to mention a few. This has resulted in an improved matching between the visual representation of an image and the textual representation of its caption. Yet, current visual representations overlook a key aspect: the text appearing in images, which may contain crucial information for retrieval. In this paper, we first propose a new dataset that allows exploration of cross-modal retrieval where images contain scene-text instances. Then, armed with this dataset, we describe several approaches which leverage scene text, including a better scene-text aware cross-modal retrieval method which uses specialized representations for text from the captions and text from the visual scene, and reconcile them in a common embedding space. Extensive experiments confirm that cross-modal retrieval approaches benefit from scene text and highlight interesting research questions worth exploring further. Dataset and code are available at http://europe.naverlabs.com/stacmr