 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Disentangled Representations for Domain-generalized Cardiac Segmentation
Aug 26, 2020
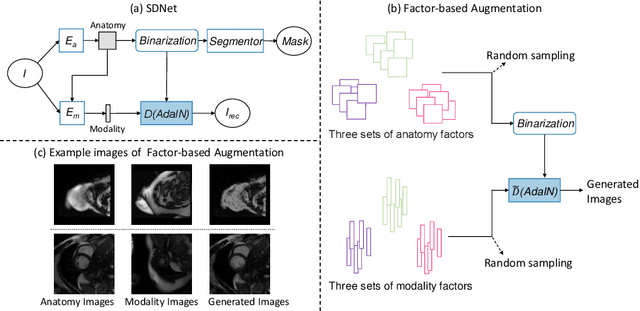
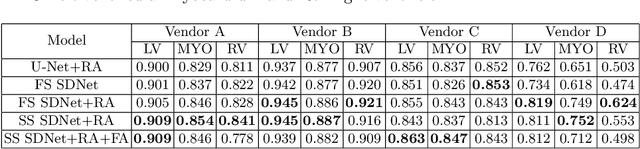
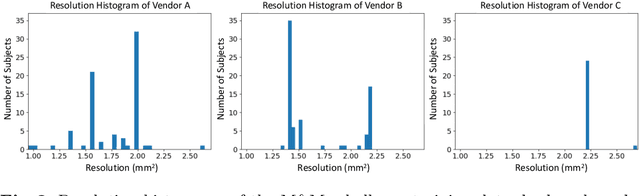
Robust cardiac image segmentation is still an open challenge due to the inability of the existing methods to achieve satisfactory performance on unseen data of different domains. Since the acquisition and annotation of medical data are costly and time-consuming, recent work focuses on domain adaptation and generalization to bridge the gap between data from different populations and scanners. In this paper, we propose two data augmentation methods that focus on improving the domain adaptation and generalization abilities of state-to-the-art cardiac segmentation models. In particular, our "Resolution Augmentation" method generates more diverse data by rescaling images to different resolutions within a range spanning different scanner protocols. Subsequently, our "Factor-based Augmentation" method generates more diverse data by projecting the original samples onto disentangled latent spaces, and combining the learned anatomy and modality factors from different domains. Our extensive experiments demonstrate the importance of efficient adaptation between seen and unseen domains, as well as model generalization ability, to robust cardiac image segmentation.
Vehicle Trajectory Prediction in Crowded Highway Scenarios Using Bird Eye View Representations and CNNs
Aug 26, 2020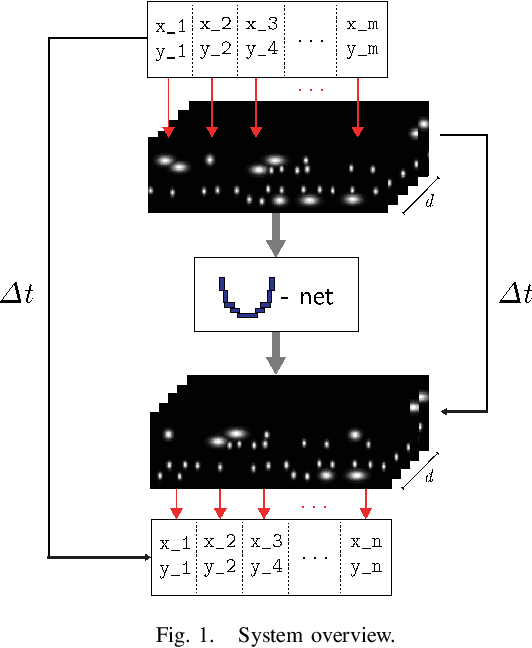
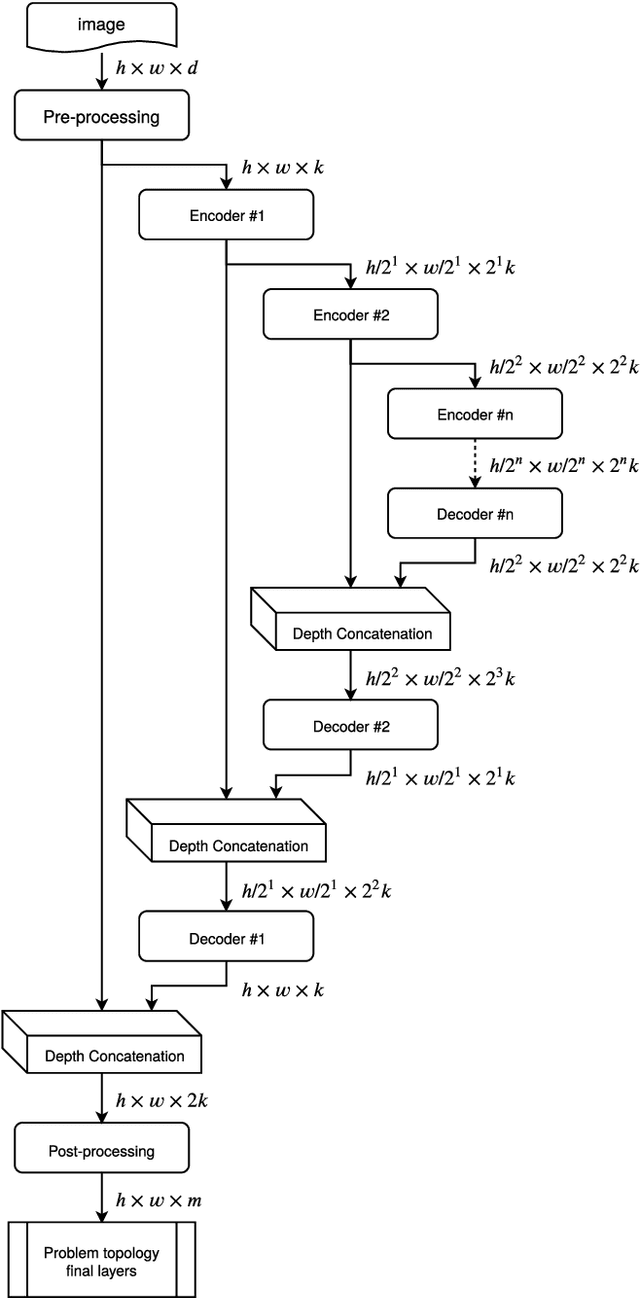

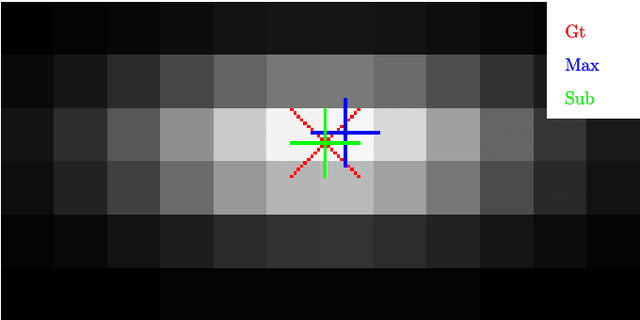
This paper describes a novel approach to perform vehicle trajectory predictions employing graphic representations. The vehicles are represented using Gaussian distributions into a Bird Eye View. Then the U-net model is used to perform sequence to sequence predictions. This deep learning-based methodology has been trained using the HighD dataset, which contains vehicles' detection in a highway scenario from aerial imagery. The problem is faced as an image to image regression problem training the network to learn the underlying relations between the traffic participants. This approach generates an estimation of the future appearance of the input scene, not trajectories or numeric positions. An extra step is conducted to extract the positions from the predicted representation with subpixel resolution. Different network configurations have been tested, and prediction error up to three seconds ahead is in the order of the representation resolution. The model has been tested in highway scenarios with more than 30 vehicles simultaneously in two opposite traffic flow streams showing good qualitative and quantitative results.
CNN Denoisers as Non-Local Filters: The Neural Tangent Denoiser
Jun 05, 2020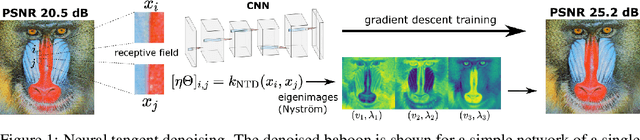
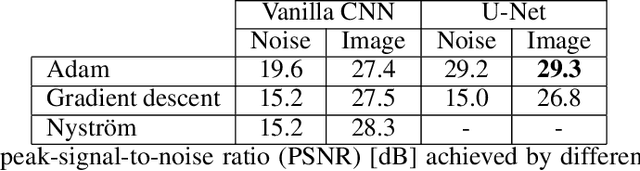

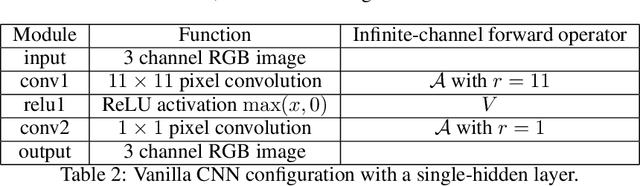
Convolutional Neural Networks (CNNs) are now a well-established tool for solving computational imaging problems. Modern CNN-based algorithms obtain state-of-the-art performance in diverse image restoration problems. Furthermore, it has been recently shown that, despite being highly overparameterized, networks trained with a single corrupted image can still perform as well as fully trained networks, a phenomenon encapsulated in the deep image prior. We introduce a novel interpretation of denoising networks with no clean training data in the context of the neural tangent kernel (NTK), elucidating the strong links with well-known non-local filtering techniques, such as non-local means or BM3D. The filtering function associated with a given network architecture can be obtained in closed form without need to train the network, being fully characterized by the random initialization of the network weights. While the NTK theory accurately predicts the filter associated with networks trained using standard gradient descent, our analysis shows that it falls short to explain the behaviour of networks trained using the popular Adam optimizer. The latter achieves a larger change of weights in hidden layers, adapting the non-local filtering function during training. We evaluate our findings via extensive image denoising experiments.
Back to Event Basics: Self-Supervised Learning of Image Reconstruction for Event Cameras via Photometric Constancy
Sep 17, 2020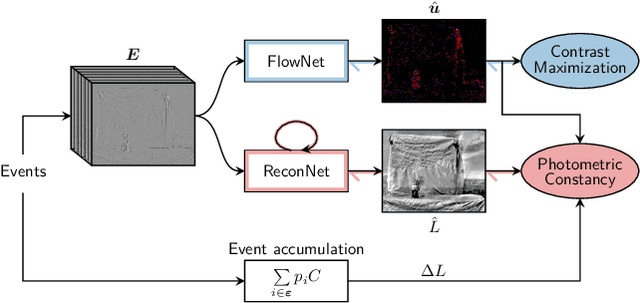

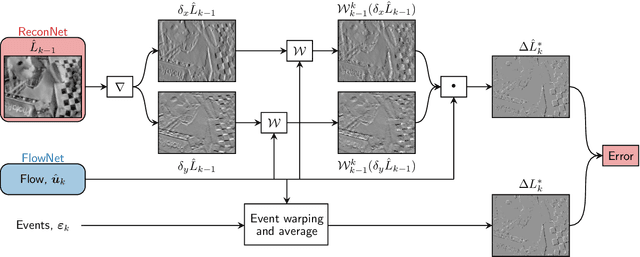
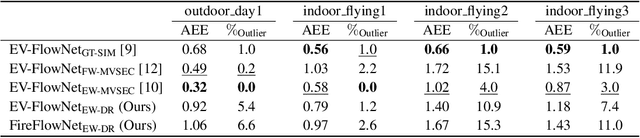
Event cameras are novel vision sensors that sample, in an asynchronous fashion, brightness increments with low latency and high temporal resolution. The resulting streams of events are of high value by themselves, especially for high speed motion estimation. However, a growing body of work has also focused on the reconstruction of intensity frames from the events, as this allows bridging the gap with the existing literature on appearance- and frame-based computer vision. Recent work has mostly approached this intensity reconstruction problem using neural networks trained with synthetic, ground-truth data. Nevertheless, since accurate ground truth is only available in simulation, these methods are subject to the reality gap and, to ensure generalizability, their training datasets need to be carefully designed. In this work, we approach, for the first time, the reconstruction problem from a self-supervised learning perspective. Our framework combines estimated optical flow and the event-based photometric constancy to train neural networks without the need for any ground-truth or synthetic data. Results across multiple datasets show that the performance of the proposed approach is in line with the state-of-the-art.
A Transferable Anti-Forensic Attack on Forensic CNNs Using A Generative Adversarial Network
Jan 23, 2021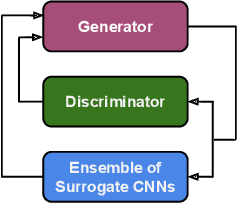
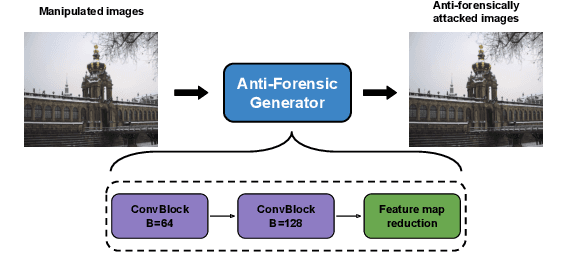
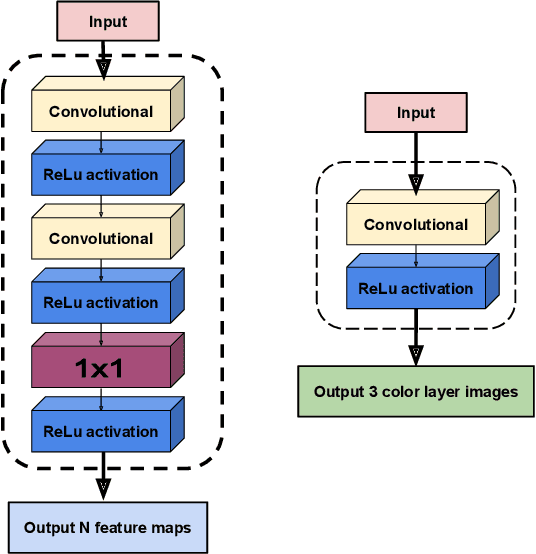
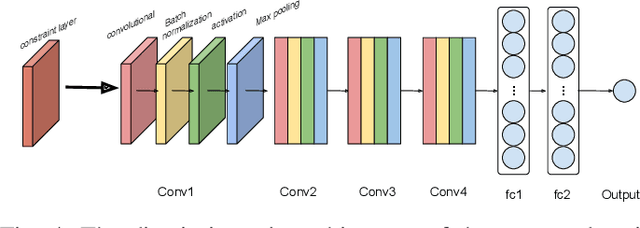
With the development of deep learning, convolutional neural networks (CNNs) have become widely used in multimedia forensics for tasks such as detecting and identifying image forgeries. Meanwhile, anti-forensic attacks have been developed to fool these CNN-based forensic algorithms. Previous anti-forensic attacks often were designed to remove forgery traces left by a single manipulation operation as opposed to a set of manipulations. Additionally, recent research has shown that existing anti-forensic attacks against forensic CNNs have poor transferability, i.e. they are unable to fool other forensic CNNs that were not explicitly used during training. In this paper, we propose a new anti-forensic attack framework designed to remove forensic traces left by a variety of manipulation operations. This attack is transferable, i.e. it can be used to attack forensic CNNs are unknown to the attacker, and it introduces only minimal distortions that are imperceptible to human eyes. Our proposed attack utilizes a generative adversarial network (GAN) to build a generator that can attack color images of any size. We achieve attack transferability through the use of a new training strategy and loss function. We conduct extensive experiment to demonstrate that our attack can fool many state-of-art forensic CNNs with varying levels of knowledge available to the attacker.
Should Ensemble Members Be Calibrated?
Jan 13, 2021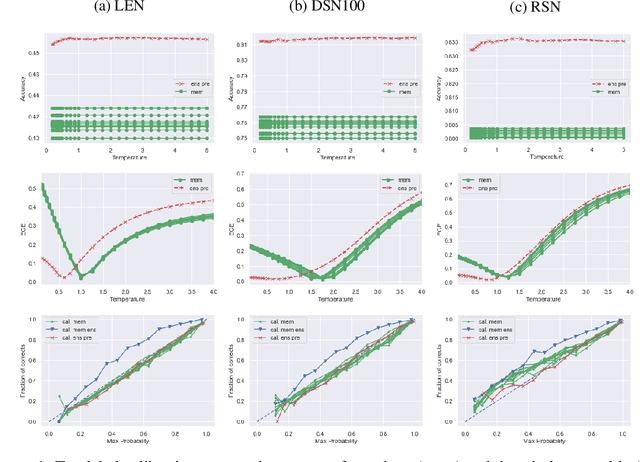
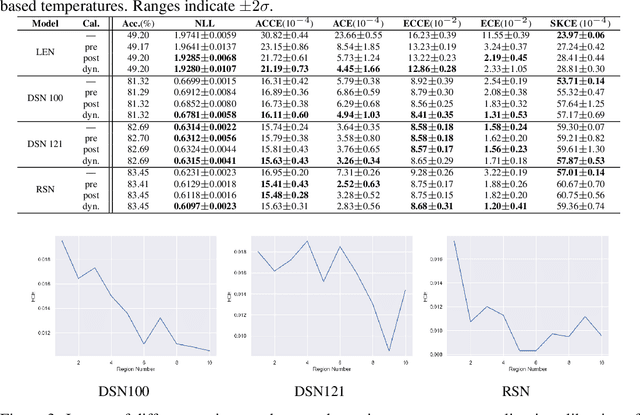
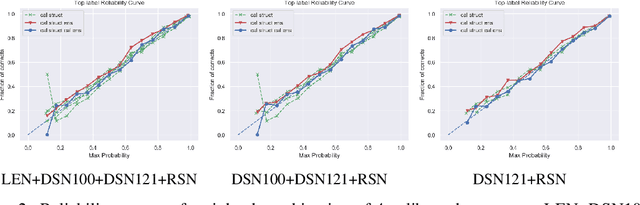
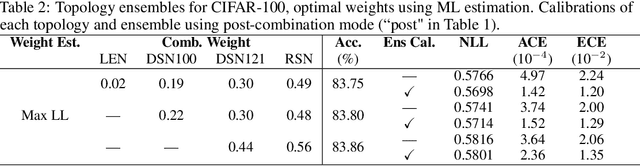
Underlying the use of statistical approaches for a wide range of applications is the assumption that the probabilities obtained from a statistical model are representative of the "true" probability that event, or outcome, will occur. Unfortunately, for modern deep neural networks this is not the case, they are often observed to be poorly calibrated. Additionally, these deep learning approaches make use of large numbers of model parameters, motivating the use of Bayesian, or ensemble approximation, approaches to handle issues with parameter estimation. This paper explores the application of calibration schemes to deep ensembles from both a theoretical perspective and empirically on a standard image classification task, CIFAR-100. The underlying theoretical requirements for calibration, and associated calibration criteria, are first described. It is shown that well calibrated ensemble members will not necessarily yield a well calibrated ensemble prediction, and if the ensemble prediction is well calibrated its performance cannot exceed that of the average performance of the calibrated ensemble members. On CIFAR-100 the impact of calibration for ensemble prediction, and associated calibration is evaluated. Additionally the situation where multiple different topologies are combined together is discussed.
An improved helmet detection method for YOLOv3 on an unbalanced dataset
Nov 09, 2020
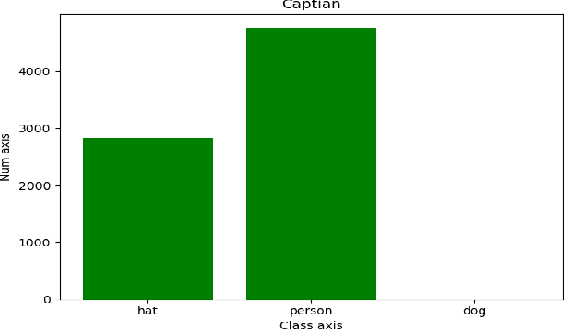
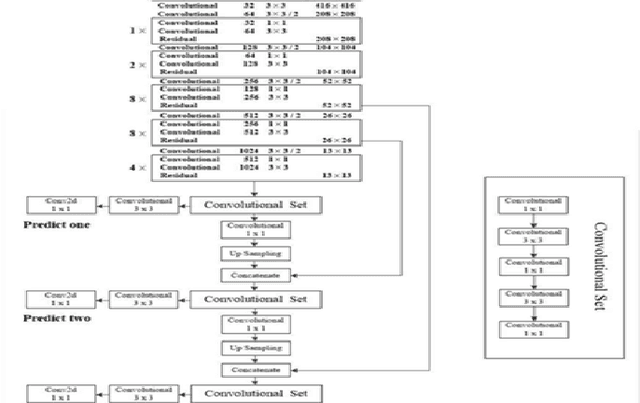

The YOLOv3 target detection algorithm is widely used in industry due to its high speed and high accuracy, but it has some limitations, such as the accuracy degradation of unbalanced datasets. The YOLOv3 target detection algorithm is based on a Gaussian fuzzy data augmentation approach to pre-process the data set and improve the YOLOv3 target detection algorithm. Through the efficient pre-processing, the confidence level of YOLOv3 is generally improved by 0.01-0.02 without changing the recognition speed of YOLOv3, and the processed images also perform better in image localization due to effective feature fusion, which is more in line with the requirement of recognition speed and accuracy in production.
Sparse Convolutions on Continuous Domains for Point Cloud and Event Stream Networks
Dec 02, 2020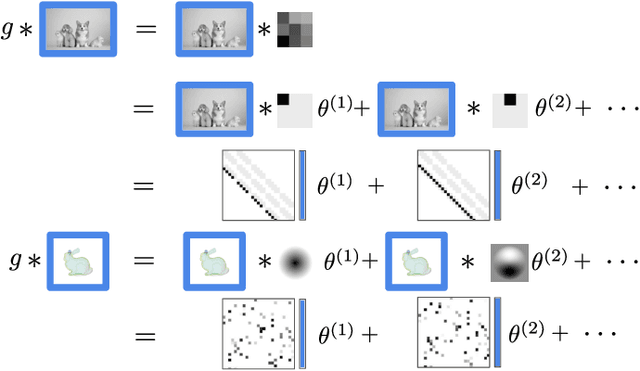
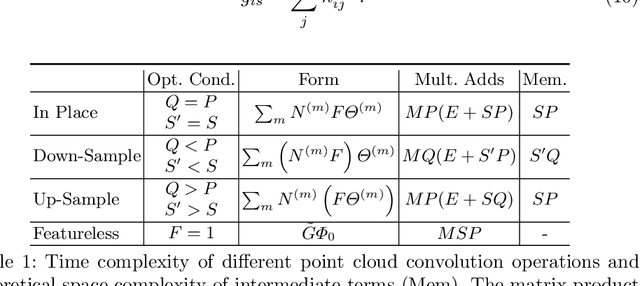
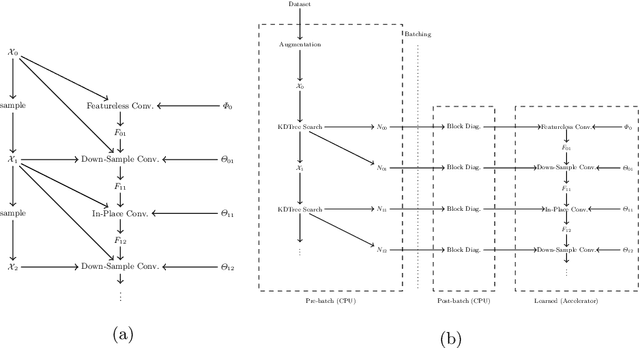
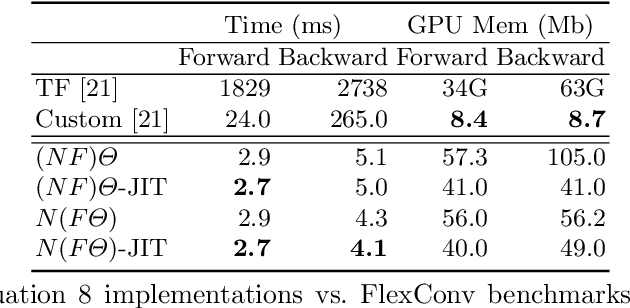
Image convolutions have been a cornerstone of a great number of deep learning advances in computer vision. The research community is yet to settle on an equivalent operator for sparse, unstructured continuous data like point clouds and event streams however. We present an elegant sparse matrix-based interpretation of the convolution operator for these cases, which is consistent with the mathematical definition of convolution and efficient during training. On benchmark point cloud classification problems we demonstrate networks built with these operations can train an order of magnitude or more faster than top existing methods, whilst maintaining comparable accuracy and requiring a tiny fraction of the memory. We also apply our operator to event stream processing, achieving state-of-the-art results on multiple tasks with streams of hundreds of thousands of events.
Memory-Efficient Semi-Supervised Continual Learning: The World is its Own Replay Buffer
Jan 23, 2021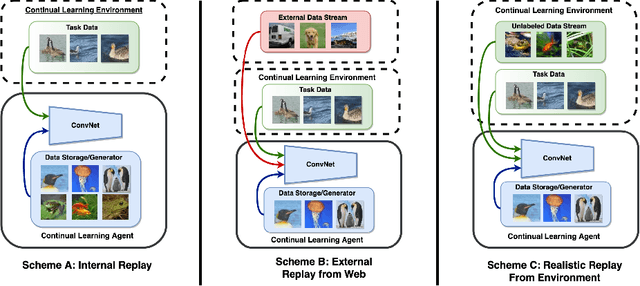
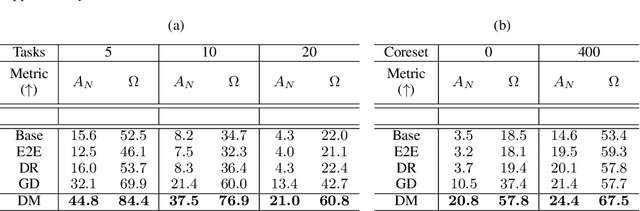
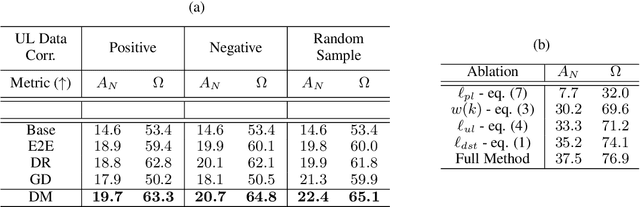
Rehearsal is a critical component for class-incremental continual learning, yet it requires a substantial memory budget. Our work investigates whether we can significantly reduce this memory budget by leveraging unlabeled data from an agent's environment in a realistic and challenging continual learning paradigm. Specifically, we explore and formalize a novel semi-supervised continual learning (SSCL) setting, where labeled data is scarce yet non-i.i.d. unlabeled data from the agent's environment is plentiful. Importantly, data distributions in the SSCL setting are realistic and therefore reflect object class correlations between, and among, the labeled and unlabeled data distributions. We show that a strategy built on pseudo-labeling, consistency regularization, Out-of-Distribution (OoD) detection, and knowledge distillation reduces forgetting in this setting. Our approach, DistillMatch, increases performance over the state-of-the-art by no less than 8.7% average task accuracy and up to a 54.5% increase in average task accuracy in SSCL CIFAR-100 experiments. Moreover, we demonstrate that DistillMatch can save up to 0.23 stored images per processed unlabeled image compared to the next best method which only saves 0.08. Our results suggest that focusing on realistic correlated distributions is a significantly new perspective, which accentuates the importance of leveraging the world's structure as a continual learning strategy.
Counterfactual Generation with Knockoffs
Feb 01, 2021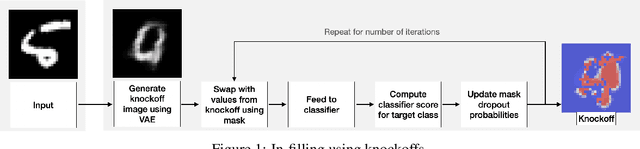
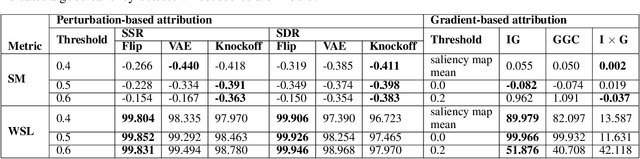

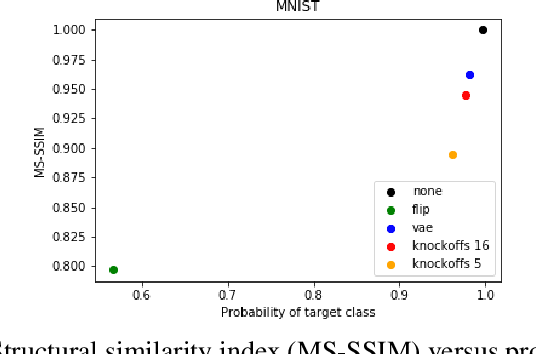
Human interpretability of deep neural networks' decisions is crucial, especially in domains where these directly affect human lives. Counterfactual explanations of already trained neural networks can be generated by perturbing input features and attributing importance according to the change in the classifier's outcome after perturbation. Perturbation can be done by replacing features using heuristic or generative in-filling methods. The choice of in-filling function significantly impacts the number of artifacts, i.e., false-positive attributions. Heuristic methods result in false-positive artifacts because the image after the perturbation is far from the original data distribution. Generative in-filling methods reduce artifacts by producing in-filling values that respect the original data distribution. However, current generative in-filling methods may also increase false-negatives due to the high correlation of in-filling values with the original data. In this paper, we propose to alleviate this by generating in-fillings with the statistically-grounded Knockoffs framework, which was developed by Barber and Cand\`es in 2015 as a tool for variable selection with controllable false discovery rate. Knockoffs are statistically null-variables as decorrelated as possible from the original data, which can be swapped with the originals without changing the underlying data distribution. A comparison of different in-filling methods indicates that in-filling with knockoffs can reveal explanations in a more causal sense while still maintaining the compactness of the explanations.