 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Benchmarking Inference Performance of Deep Learning Models on Analog Devices
Dec 16, 2020
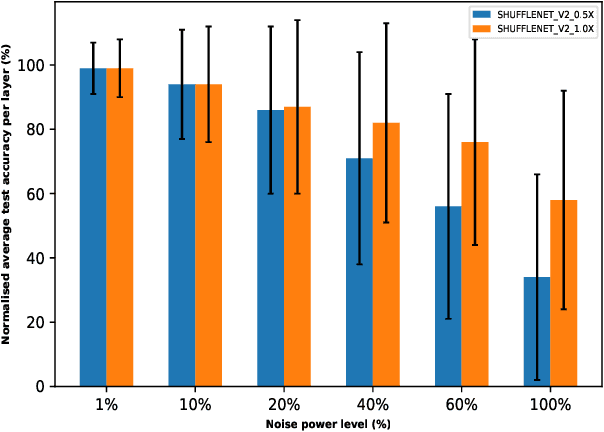
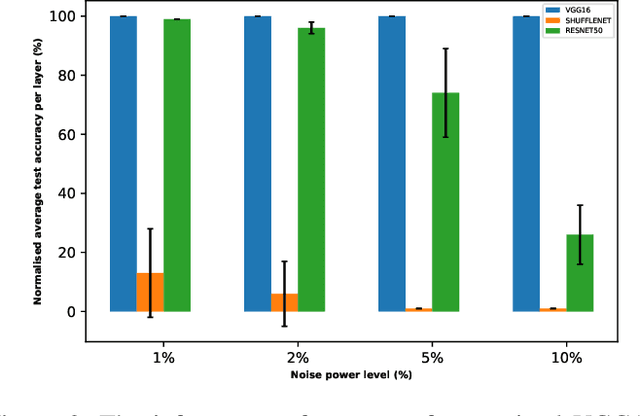
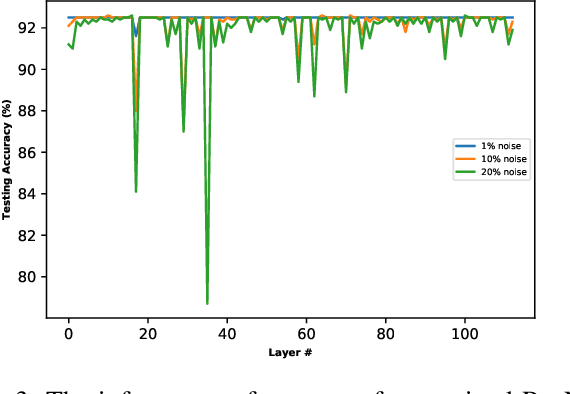
Analog hardware implemented deep learning models are promising for computation and energy constrained systems such as edge computing devices. However, the analog nature of the device and the associated many noise sources will cause changes to the value of the weights in the trained deep learning models deployed on such devices. In this study, systematic evaluation of the inference performance of trained popular deep learning models for image classification deployed on analog devices has been carried out, where additive white Gaussian noise has been added to the weights of the trained models during inference. It is observed that deeper models and models with more redundancy in design such as VGG are more robust to the noise in general. However, the performance is also affected by the design philosophy of the model, the detailed structure of the model, the exact machine learning task, as well as the datasets.
Iteratively Optimized Patch Label Inference Network for Automatic Pavement Disease Detection
May 27, 2020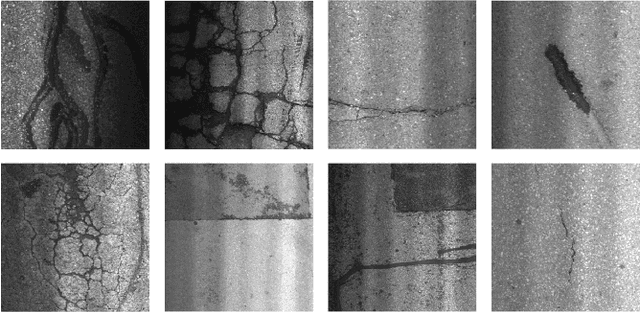
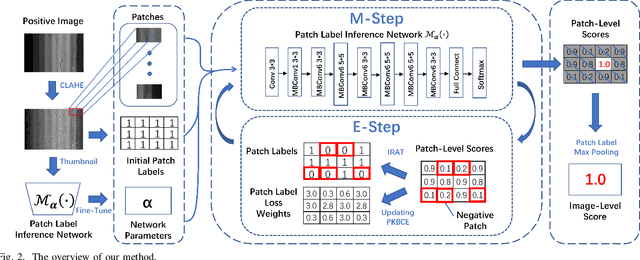
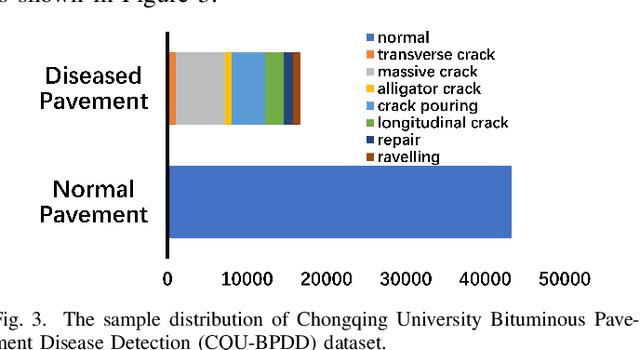
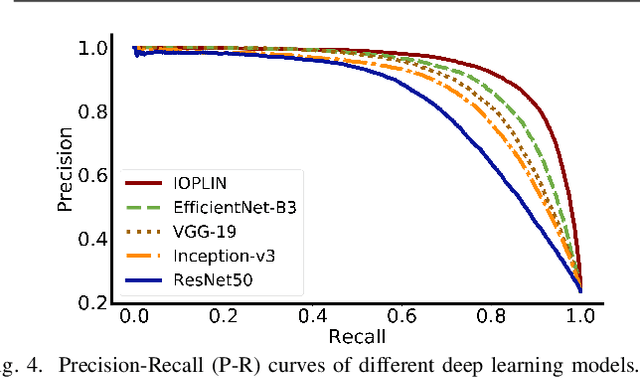
We present a novel deep learning framework named Iteratively Optimized Patch Label Inference Network (IOPLIN) for automatically detecting various pavement diseases not just limited to the specific ones, such as crack and pothole. IOPLIN can be iteratively trained with only the image label via using Expectation-Maximization Inspired Patch Label Distillation (EMIPLD) strategy, and accomplishes this task well by inferring the labels of patches from the pavement images. IOPLIN enjoys many desirable properties over the state-of-the-art single branch CNN models such as GoogLeNet and EfficientNet. It is able to handle any resolution of image and sufficiently utilize image information particularly for the high-resolution ones. Moreover, it can roughly localize the pavement distress without using any prior localization information in training phase. In order to better evaluate the effectiveness of our method in practice, we construct a large-scale Bituminous Pavement Disease Detection dataset named CQU-BPDD consists of 60059 high-resolution pavement images, which are acquired from different areas at different time. Extensive results on this dataset demonstrate the superiority of IOPLIN over the state-of-the-art image classificaiton approaches in automatic pavement disease detection.
pseudo-Bayesian Neural Networks for detecting Out of Distribution Inputs
Feb 02, 2021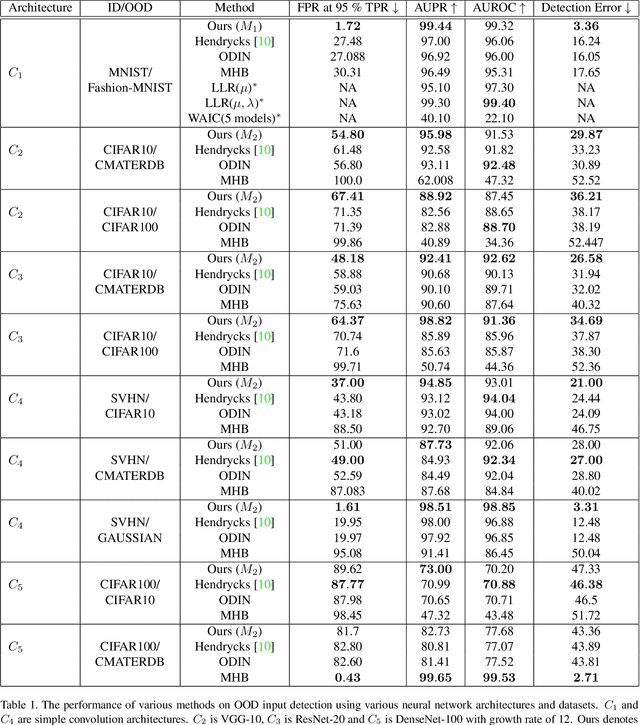
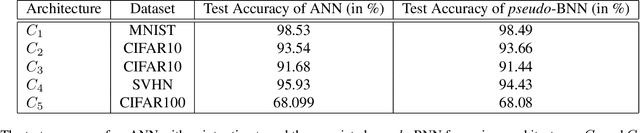
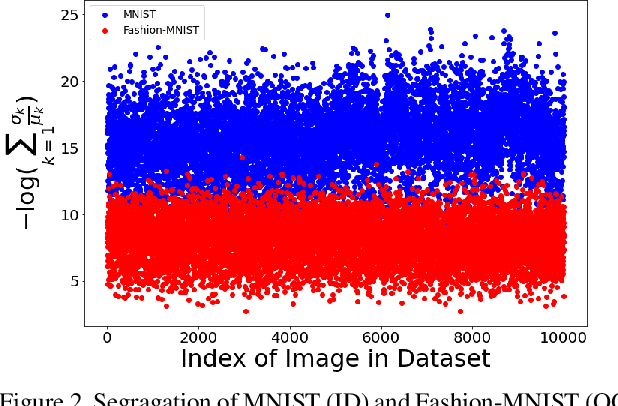
Conventional Bayesian Neural Networks (BNNs) are known to be capable of providing multiple outputs for a single input, the variations in which can be utilised to detect Out of Distribution (OOD) inputs. BNNs are difficult to train due to their sensitivity towards the choice of priors. To alleviate this issue, we propose pseudo-BNNs where instead of learning distributions over weights, we use point estimates and perturb weights at the time of inference. We modify the cost function of conventional BNNs and use it to learn parameters for the purpose of injecting right amount of random perturbations to each of the weights of a neural network with point estimate. In order to effectively segregate OOD inputs from In Distribution (ID) inputs using multiple outputs, we further propose two measures, derived from the index of dispersion and entropy of probability distributions, and combine them with the proposed pseudo-BNNs. Overall, this combination results in a principled technique to detect OOD samples at the time of inference. We evaluate our technique on a wide variety of neural network architectures and image classification datasets. We observe that our method achieves state of the art results and beats the related previous work on various metrics such as FPR at 95% TPR, AUROC, AUPR and Detection Error by just using 2 to 5 samples of weights per input.
Top-DB-Net: Top DropBlock for Activation Enhancement in Person Re-Identification
Oct 12, 2020



Person Re-Identification is a challenging task that aims to retrieve all instances of a query image across a system of non-overlapping cameras. Due to the various extreme changes of view, it is common that local regions that could be used to match people are suppressed, which leads to a scenario where approaches have to evaluate the similarity of images based on less informative regions. In this work, we introduce the Top-DB-Net, a method based on Top DropBlock that pushes the network to learn to focus on the scene foreground, with special emphasis on the most task-relevant regions and, at the same time, encodes low informative regions to provide high discriminability. The Top-DB-Net is composed of three streams: (i) a global stream encodes rich image information from a backbone, (ii) the Top DropBlock stream encourages the backbone to encode low informative regions with high discriminative features, and (iii) a regularization stream helps to deal with the noise created by the dropping process of the second stream, when testing the first two streams are used. Vast experiments on three challenging datasets show the capabilities of our approach against state-of-the-art methods. Qualitative results demonstrate that our method exhibits better activation maps focusing on reliable parts of the input images.
* Accepted on 25th International Conference on Pattern Recognition (ICPR2020)
Information-Theoretic Active Learning for Content-Based Image Retrieval
Sep 07, 2018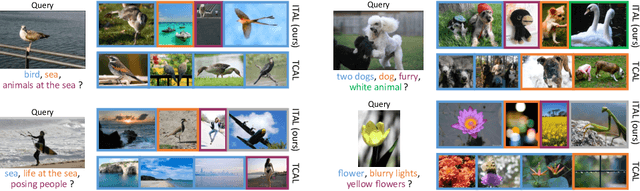
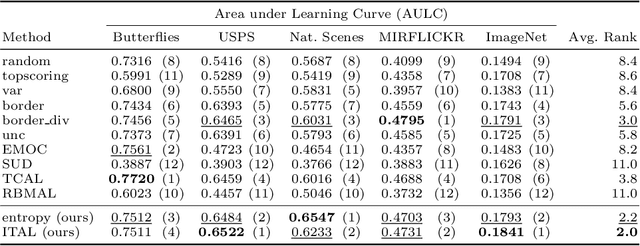
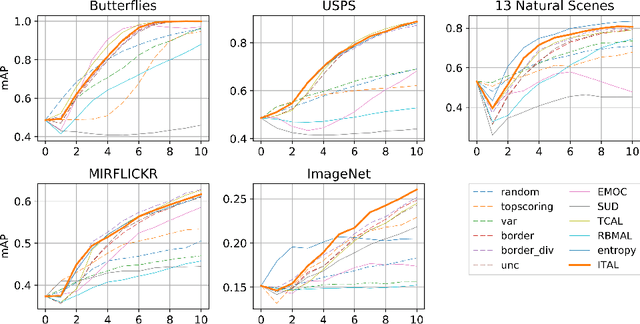
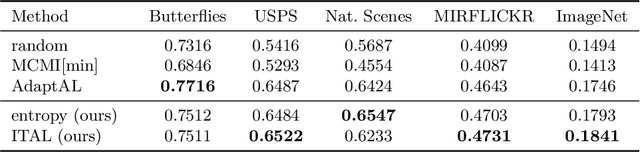
We propose Information-Theoretic Active Learning (ITAL), a novel batch-mode active learning method for binary classification, and apply it for acquiring meaningful user feedback in the context of content-based image retrieval. Instead of combining different heuristics such as uncertainty, diversity, or density, our method is based on maximizing the mutual information between the predicted relevance of the images and the expected user feedback regarding the selected batch. We propose suitable approximations to this computationally demanding problem and also integrate an explicit model of user behavior that accounts for possible incorrect labels and unnameable instances. Furthermore, our approach does not only take the structure of the data but also the expected model output change caused by the user feedback into account. In contrast to other methods, ITAL turns out to be highly flexible and provides state-of-the-art performance across various datasets, such as MIRFLICKR and ImageNet.
Photo-realistic Image Super-resolution with Fast and Lightweight Cascading Residual Network
Mar 06, 2019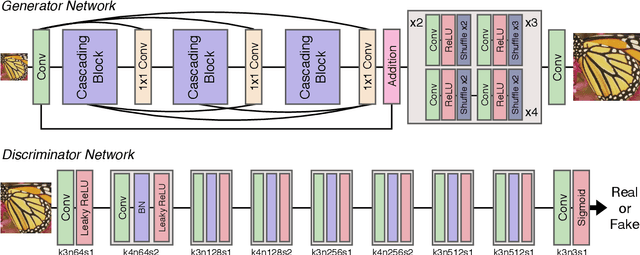
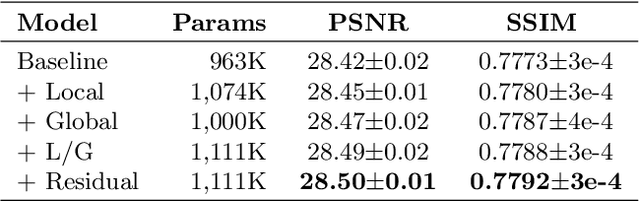
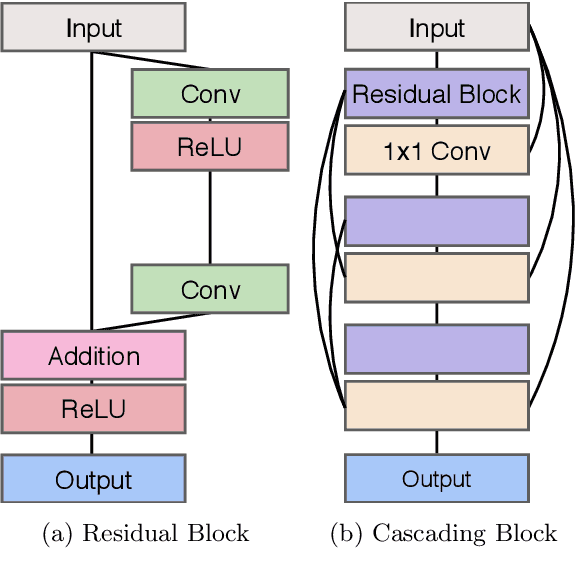

Recent progress in the deep learning-based models has improved single-image super-resolution significantly. However, despite their powerful performance, many models are difficult to apply to the real-world applications because of the heavy computational requirements. To facilitate the use of a deep learning model in such demands, we focus on keeping the model fast and lightweight while maintaining its accuracy. In detail, we design an architecture that implements a cascading mechanism on a residual network to boost the performance with limited resources via multi-level feature fusion. Moreover, we adopt group convolution and weight-tying for our proposed model in order to achieve extreme efficiency. In addition to the traditional super-resolution task, we apply our methods to the photo-realistic super-resolution field using the adversarial learning paradigm and a multi-scale discriminator approach. By doing so, we show that the performances of the proposed models surpass those of the recent methods, which have a complexity similar to ours, for both traditional pixel-based and perception-based tasks.
Sketch Generation with Drawing Process Guided by Vector Flow and Grayscale
Dec 16, 2020
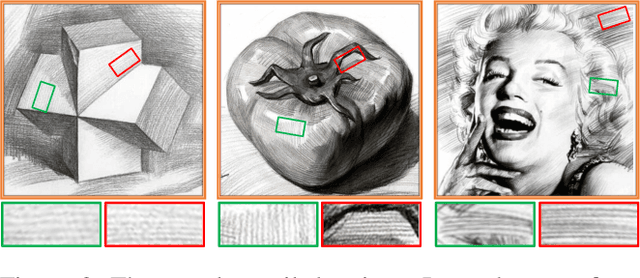
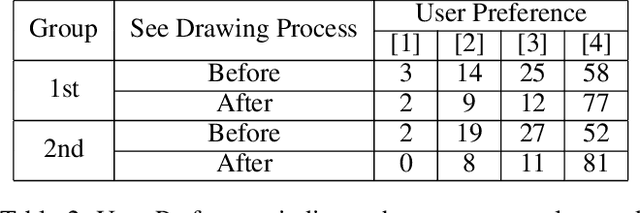
We propose a novel image-to-pencil translation method that could not only generate high-quality pencil sketches but also offer the drawing process. Existing pencil sketch algorithms are based on texture rendering rather than the direct imitation of strokes, making them unable to show the drawing process but only a final result. To address this challenge, we first establish a pencil stroke imitation mechanism. Next, we develop a framework with three branches to guide stroke drawing: the first branch guides the direction of the strokes, the second branch determines the shade of the strokes, and the third branch enhances the details further. Under this framework's guidance, we can produce a pencil sketch by drawing one stroke every time. Our method is fully interpretable. Comparison with existing pencil drawing algorithms shows that our method is superior to others in terms of texture quality, style, and user evaluation.
Fast Fourier Intrinsic Network
Nov 09, 2020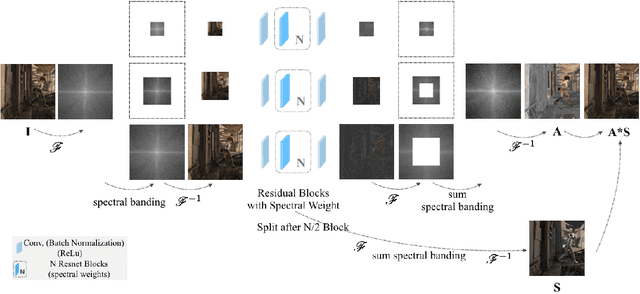
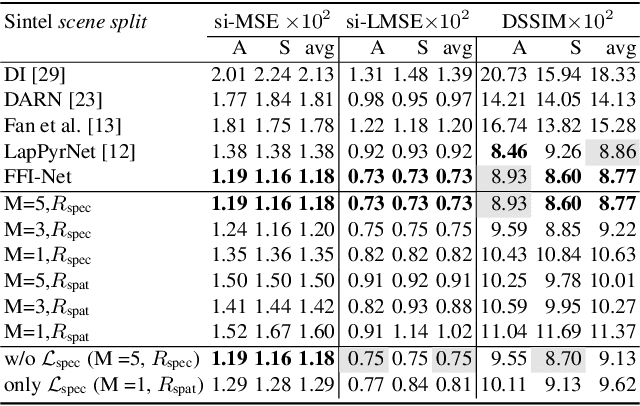
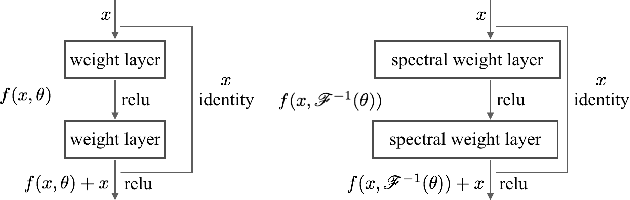
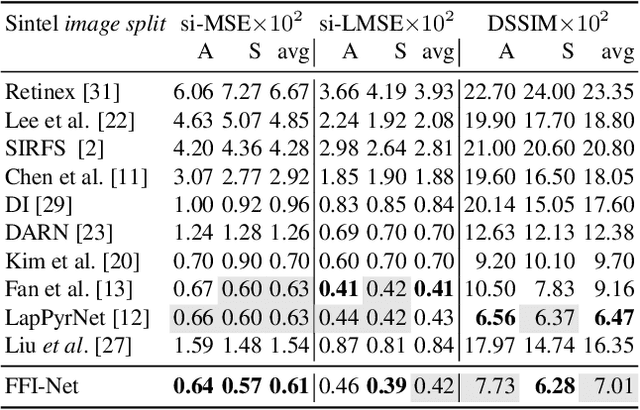
We address the problem of decomposing an image into albedo and shading. We propose the Fast Fourier Intrinsic Network, FFI-Net in short, that operates in the spectral domain, splitting the input into several spectral bands. Weights in FFI-Net are optimized in the spectral domain, allowing faster convergence to a lower error. FFI-Net is lightweight and does not need auxiliary networks for training. The network is trained end-to-end with a novel spectral loss which measures the global distance between the network prediction and corresponding ground truth. FFI-Net achieves state-of-the-art performance on MPI-Sintel, MIT Intrinsic, and IIW datasets.
Deep Descriptor Transforming for Image Co-Localization
May 08, 2017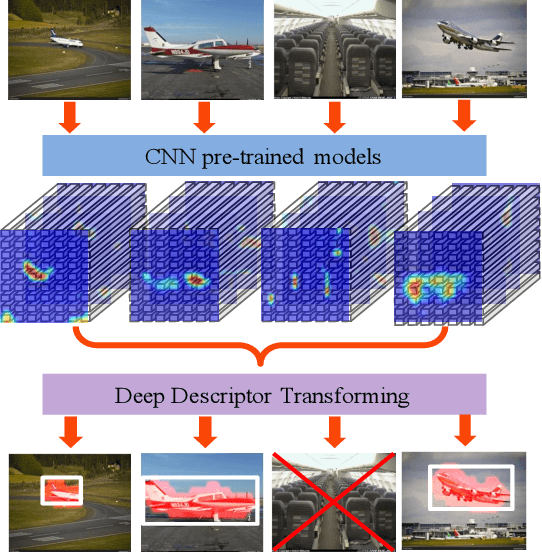
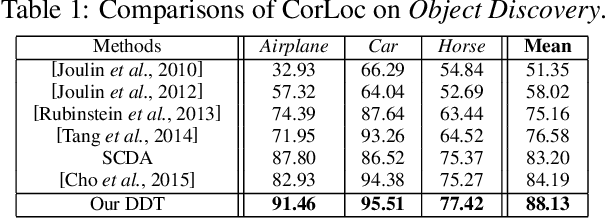
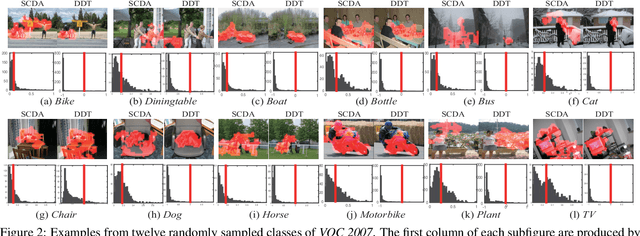

Reusable model design becomes desirable with the rapid expansion of machine learning applications. In this paper, we focus on the reusability of pre-trained deep convolutional models. Specifically, different from treating pre-trained models as feature extractors, we reveal more treasures beneath convolutional layers, i.e., the convolutional activations could act as a detector for the common object in the image co-localization problem. We propose a simple but effective method, named Deep Descriptor Transforming (DDT), for evaluating the correlations of descriptors and then obtaining the category-consistent regions, which can accurately locate the common object in a set of images. Empirical studies validate the effectiveness of the proposed DDT method. On benchmark image co-localization datasets, DDT consistently outperforms existing state-of-the-art methods by a large margin. Moreover, DDT also demonstrates good generalization ability for unseen categories and robustness for dealing with noisy data.
Disentangled Representations for Domain-generalized Cardiac Segmentation
Aug 26, 2020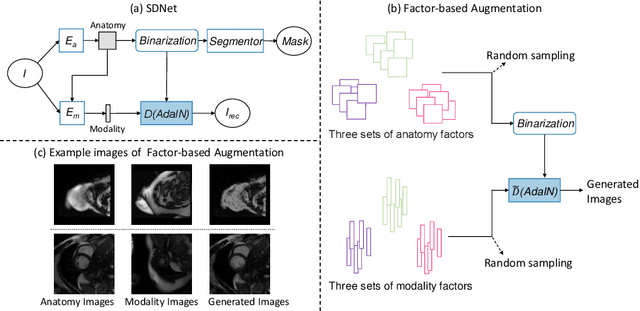
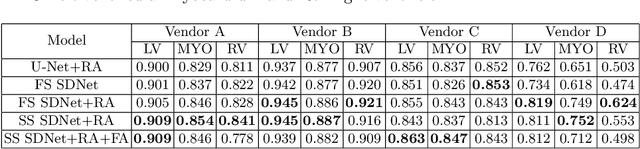
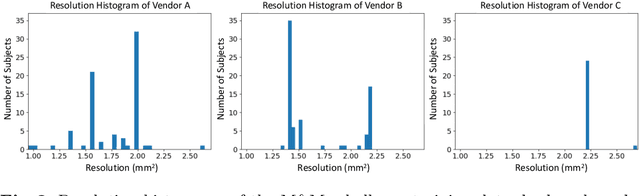
Robust cardiac image segmentation is still an open challenge due to the inability of the existing methods to achieve satisfactory performance on unseen data of different domains. Since the acquisition and annotation of medical data are costly and time-consuming, recent work focuses on domain adaptation and generalization to bridge the gap between data from different populations and scanners. In this paper, we propose two data augmentation methods that focus on improving the domain adaptation and generalization abilities of state-to-the-art cardiac segmentation models. In particular, our "Resolution Augmentation" method generates more diverse data by rescaling images to different resolutions within a range spanning different scanner protocols. Subsequently, our "Factor-based Augmentation" method generates more diverse data by projecting the original samples onto disentangled latent spaces, and combining the learned anatomy and modality factors from different domains. Our extensive experiments demonstrate the importance of efficient adaptation between seen and unseen domains, as well as model generalization ability, to robust cardiac image segmentation.