 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Two-Phase Genetic Algorithm for Image Registration
Nov 17, 2017

Image Registration (IR) is the process of aligning two (or more) images of the same scene taken at different times, different viewpoints and/or by different sensors. It is an important, crucial step in various image analysis tasks where multiple data sources are integrated/fused, in order to extract high-level information. Registration methods usually assume a relevant transformation model for a given problem domain. The goal is to search for the "optimal" instance of the transformation model assumed with respect to a similarity measure in question. In this paper we present a novel genetic algorithm (GA)-based approach for IR. Since GA performs effective search in various optimization problems, it could prove useful also for IR. Indeed, various GAs have been proposed for IR. However, most of them assume certain constraints, which simplify the transformation model, restrict the search space or make additional preprocessing requirements. In contrast, we present a generalized GA-based solution for an almost fully affine transformation model, which achieves competitive results without such limitations using a two-phase method and a multi-objective optimization (MOO) approach. We present good results for multiple dataset and demonstrate the robustness of our method in the presence of noisy data.
A novel approach to remove foreign objects from chest X-ray images
Aug 16, 2020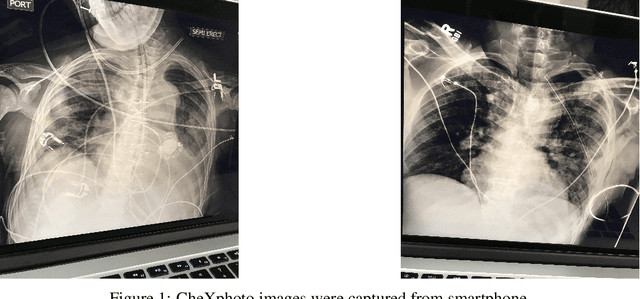


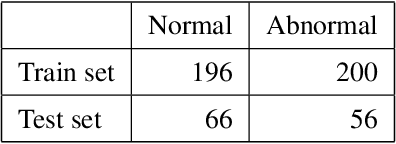
We initially proposed a deep learning approach for foreign objects inpainting in smartphone-camera captured chest radiographs utilizing the cheXphoto dataset. Foreign objects which can significantly affect the quality of a computer-aided diagnostic prediction are captured under various settings. In this paper, we used multi-method to tackle both removal and inpainting chest radiographs. Firstly, an object detection model is trained to separate the foreign objects from the given image. Subsequently, the binary mask of each object is extracted utilizing a segmentation model. Each pair of the binary mask and the extracted object are then used for inpainting purposes. Finally, the in-painted regions are now merged back to the original image, resulting in a clean and non-foreign-object-existing output. To conclude, we achieved state-of-the-art accuracy. The experimental results showed a new approach to the possible applications of this method for chest X-ray images detection.
LiveChess2FEN: a Framework for Classifying Chess Pieces based on CNNs
Dec 12, 2020
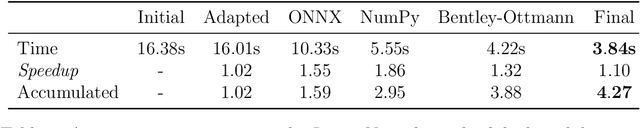
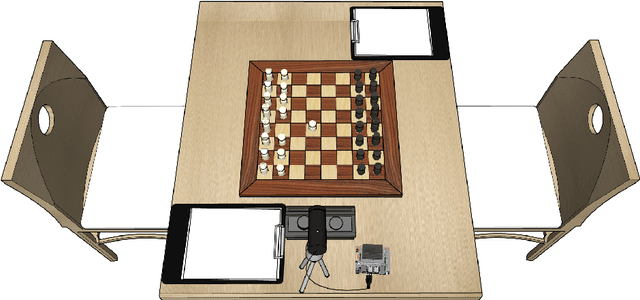
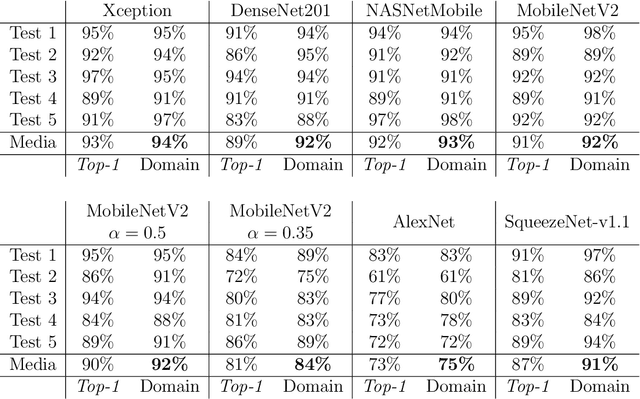
Automatic digitization of chess games using computer vision is a significant technological challenge. This problem is of much interest for tournament organizers and amateur or professional players to broadcast their over-the-board (OTB) games online or analyze them using chess engines. Previous work has shown promising results, but the recognition accuracy and the latency of state-of-the-art techniques still need further enhancements to allow their practical and affordable deployment. We have investigated how to implement them on an Nvidia Jetson Nano single-board computer effectively. Our first contribution has been accelerating the chessboard's detection algorithm. Subsequently, we have analyzed different Convolutional Neural Networks for chess piece classification and how to map them efficiently on our embedded platform. Notably, we have implemented a functional framework that automatically digitizes a chess position from an image in less than 1 second, with 92% accuracy when classifying the pieces and 95% when detecting the board.
Downscaling Attack and Defense: Turning What You See Back Into What You Get
Oct 07, 2020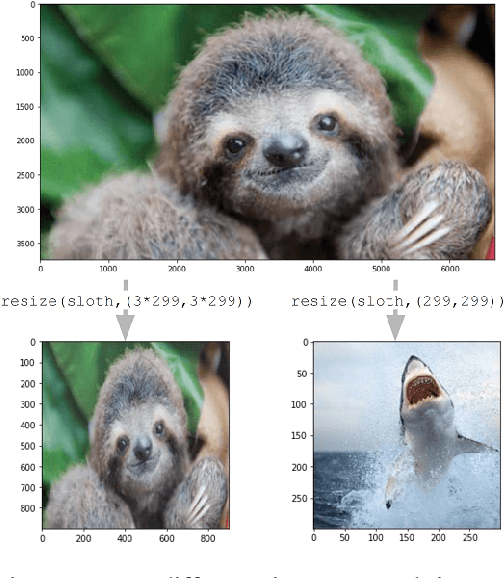
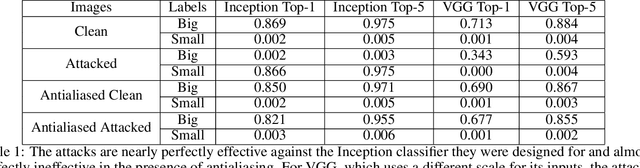
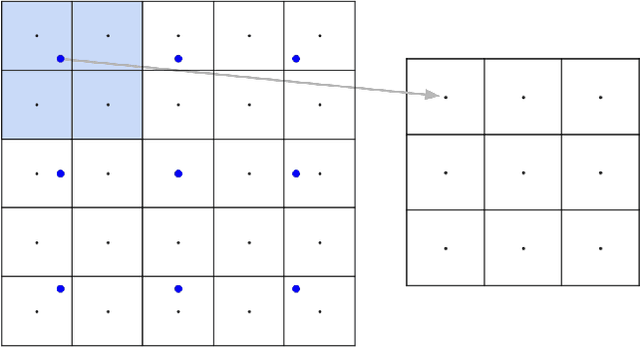
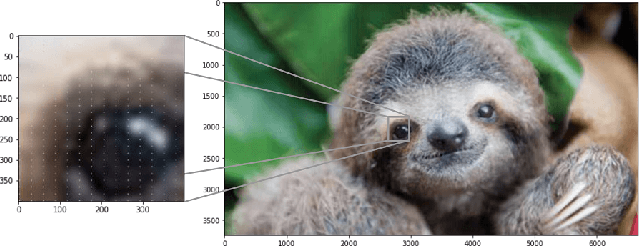
The resizing of images, which is typically a required part of preprocessing for computer vision systems, is vulnerable to attack. Images can be created such that the image is completely different at machine-vision scales than at other scales and the default settings for some common computer vision and machine learning systems are vulnerable. We show that defenses exist and are trivial to administer provided that defenders are aware of the threat. These attacks and defenses help to establish the role of input sanitization in machine learning.
High-Resolution Daytime Translation Without Domain Labels
Mar 19, 2020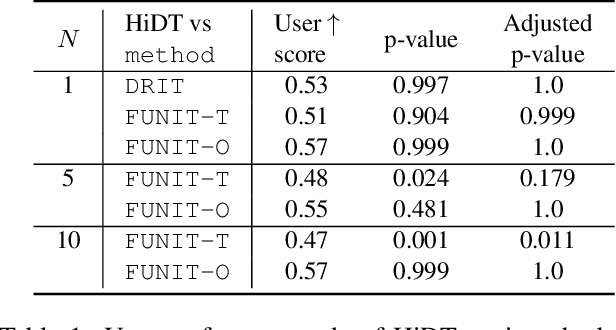
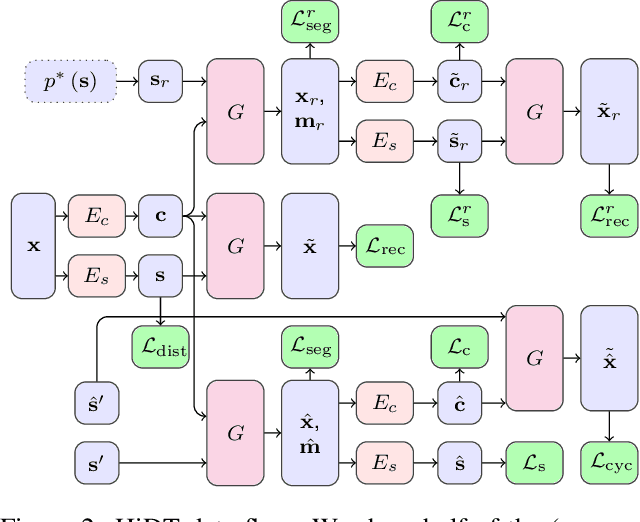
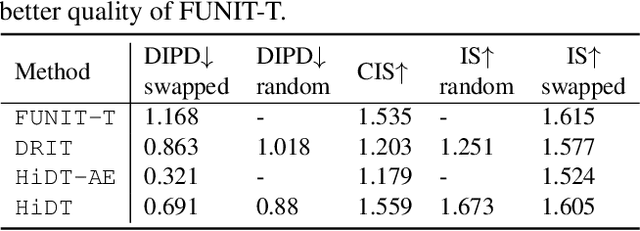
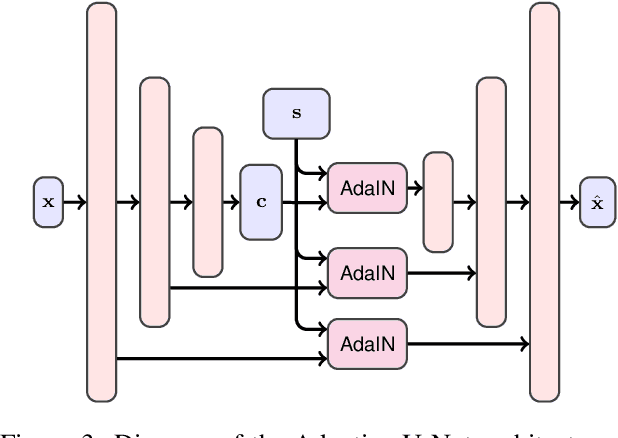
Modeling daytime changes in high resolution photographs, e.g., re-rendering the same scene under different illuminations typical for day, night, or dawn, is a challenging image manipulation task. We present the high-resolution daytime translation (HiDT) model for this task. HiDT combines a generative image-to-image model and a new upsampling scheme that allows to apply image translation at high resolution. The model demonstrates competitive results in terms of both commonly used GAN metrics and human evaluation. Uniquely, this good performance comes as a result of training on a dataset of still landscape images with no daytime labels available. Our results are available at https://saic-mdal.github.io/HiDT/.
High Order Local Directional Pattern Based Pyramidal Multi-structure for Robust Face Recognition
Dec 12, 2020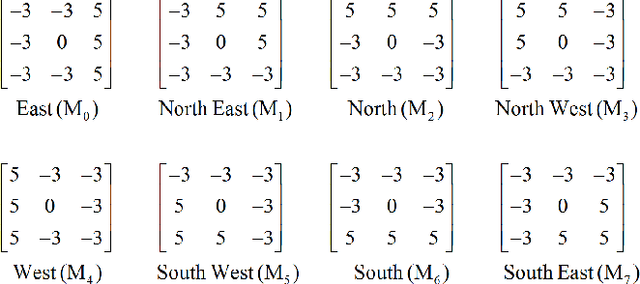
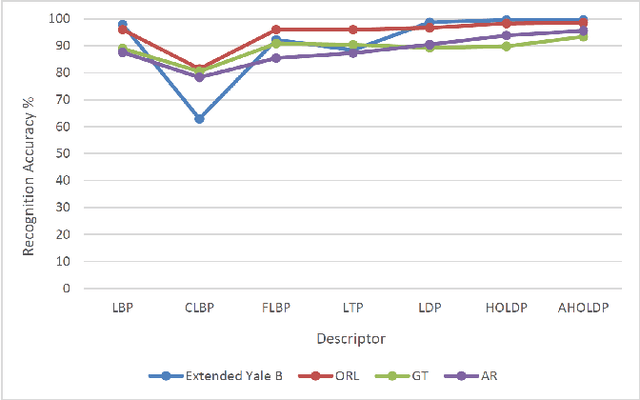

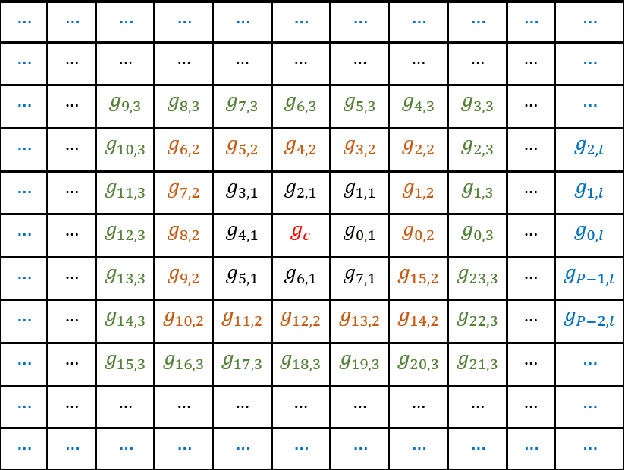
Derived from a general definition of texture in a local neighborhood, local directional pattern (LDP) encodes the directional information in the small local 3x3 neighborhood of a pixel, which may fail to extract detailed information especially during changes in the input image due to illumination variations. Therefore, in this paper we introduce a novel feature extraction technique that calculates the nth order direction variation patterns, named high order local directional pattern (HOLDP). The proposed HOLDP can capture more detailed discriminative information than the conventional LDP. Unlike the LDP operator, our proposed technique extracts nth order local information by encoding various distinctive spatial relationships from each neighborhood layer of a pixel in the pyramidal multi-structure way. Then we concatenate the feature vector of each neighborhood layer to form the final HOLDP feature vector. The performance evaluation of the proposed HOLDP algorithm is conducted on several publicly available face databases and observed the superiority of HOLDP under extreme illumination conditions.
Depth Completion using Piecewise Planar Model
Dec 06, 2020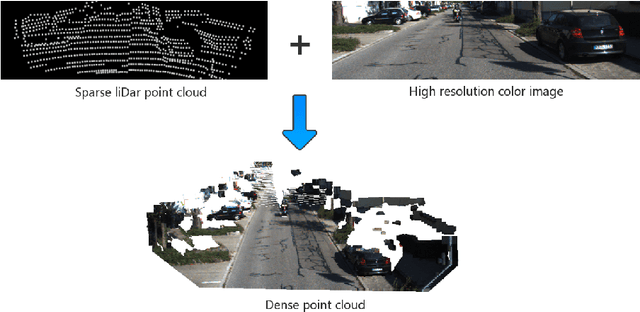


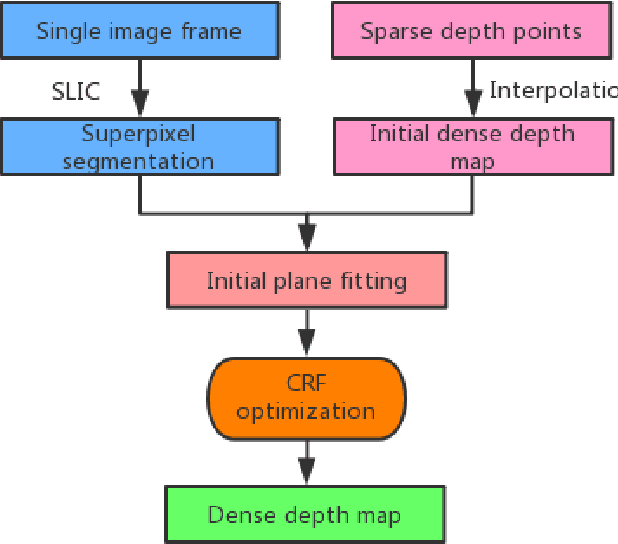
A depth map can be represented by a set of learned bases and can be efficiently solved in a closed form solution. However, one issue with this method is that it may create artifacts when colour boundaries are inconsistent with depth boundaries. In fact, this is very common in a natural image. To address this issue, we enforce a more strict model in depth recovery: a piece-wise planar model. More specifically, we represent the desired depth map as a collection of 3D planar and the reconstruction problem is formulated as the optimization of planar parameters. Such a problem can be formulated as a continuous CRF optimization problem and can be solved through particle based method (MP-PBP) \cite{Yamaguchi14}. Extensive experimental evaluations on the KITTI visual odometry dataset show that our proposed methods own high resistance to false object boundaries and can generate useful and visually pleasant 3D point clouds.
Fault Location Estimation by Using Machine Learning Methods in Mixed Transmission Lines
Nov 06, 2020
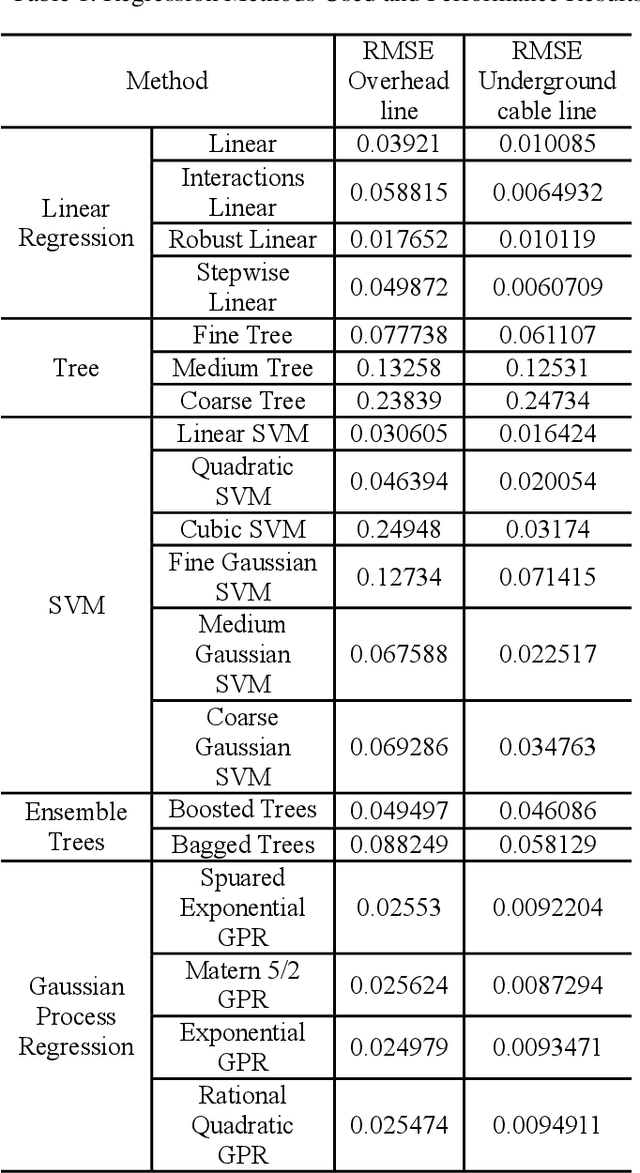
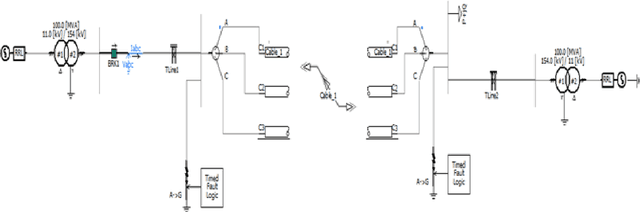
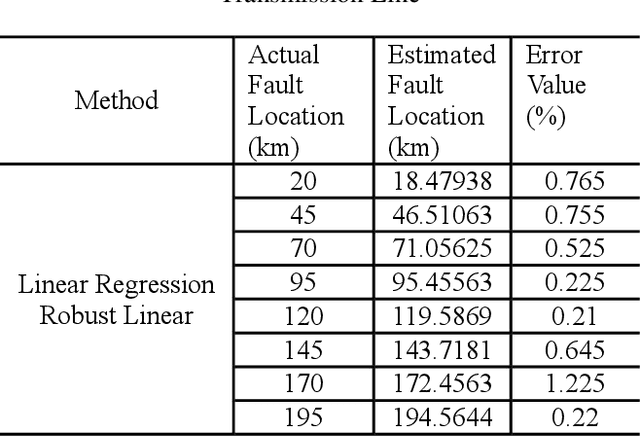
Overhead lines are generally used for electrical energy transmission. Also, XLPE underground cable lines are generally used in the city center and the crowded areas to provide electrical safety, so high voltage underground cable lines are used together with overhead line in the transmission lines, and these lines are called as the mixed lines. The distance protection relays are used to determine the impedance based fault location according to the current and voltage magnitudes in the transmission lines. However, the fault location cannot be correctly detected in mixed transmission lines due to different characteristic impedance per unit length because the characteristic impedance of high voltage cable line is significantly different from overhead line. Thus, determinations of the fault section and location with the distance protection relays are difficult in the mixed transmission lines. In this study, 154 kV overhead transmission line and underground cable line are examined as the mixed transmission line for the distance protection relays. Phase to ground faults are created in the mixed transmission line, and overhead line section and underground cable section are simulated by using PSCAD. The short circuit fault images are generated in the distance protection relay for the overhead transmission line and underground cable transmission line faults. The images include the RX impedance diagram of the fault, and the RX impedance diagram have been detected by applying image processing steps. The regression methods are used for prediction of the fault location, and the results of image processing are used as the input parameters for the training process of the regression methods. The results of regression methods are compared to select the most suitable method at the end of this study for forecasting of the fault location in transmission lines.
Learning Curves for Analysis of Deep Networks
Oct 21, 2020
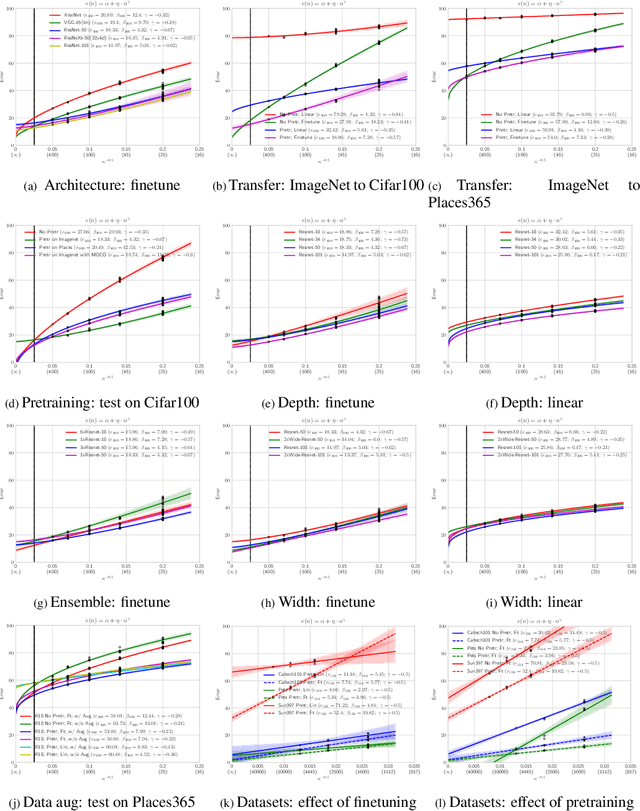

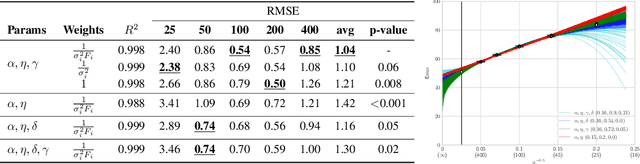
A learning curve models a classifier's test error as a function of the number of training samples. Prior works show that learning curves can be used to select model parameters and extrapolate performance. We investigate how to use learning curves to analyze the impact of design choices, such as pre-training, architecture, and data augmentation. We propose a method to robustly estimate learning curves, abstract their parameters into error and data-reliance, and evaluate the effectiveness of different parameterizations. We also provide several interesting observations based on learning curves for a variety of image classification models.
Delay Differential Neural Networks
Dec 12, 2020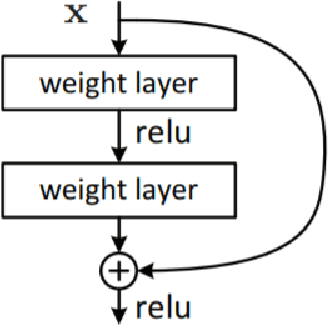
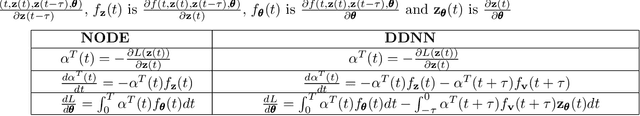
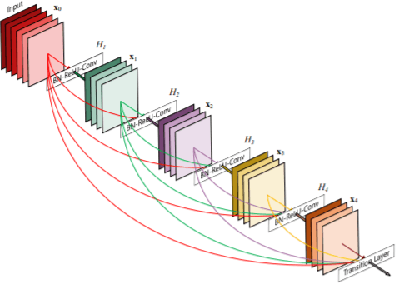

Neural ordinary differential equations (NODEs) treat computation of intermediate feature vectors as trajectories of ordinary differential equation parameterized by a neural network. In this paper, we propose a novel model, delay differential neural networks (DDNN), inspired by delay differential equations (DDEs). The proposed model considers the derivative of the hidden feature vector as a function of the current feature vector and past feature vectors (history). The function is modelled as a neural network and consequently, it leads to continuous depth alternatives to many recent ResNet variants. We propose two different DDNN architectures, depending on the way current and past feature vectors are considered. For training DDNNs, we provide a memory-efficient adjoint method for computing gradients and back-propagate through the network. DDNN improves the data efficiency of NODE by further reducing the number of parameters without affecting the generalization performance. Experiments conducted on synthetic and real-world image classification datasets such as Cifar10 and Cifar100 show the effectiveness of the proposed models.